基于协同拟合的电能计量数据恢复方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明属于用电数据分析处理应用领域,尤其涉及基于协同拟合的电能计量数据恢复 方法。
背景技术
为了实现国家可持续绿色发展,节能减排的战略方针已刻不容缓。电能在我国能源结构 中占有主要地位,电网的精细化管理将有助于国家战略的实施。随着人民生活水平的提高和 工业发展,用户对电网的服务质量也有了更高的要求。得益于新能源技术和网络技术的进步, 传统电网正向能源网络综合发展。多种能源正向电网聚合,使得电能计量的问题变得复杂。 为了提高电能计量的准确性和实时性,先进的通信技术和信息采集技术被用来升级传统的电 能计量设备。但由于计量器的物理误差、通信时延、数据丢包、线路故障等原因,导致部分 计量数据错误、丢失,制约着依赖计量数据集的业务应用与电网的发展。因此电能计量的数 据缺失是一个亟需解决的问题。
用户的用电量会因天气、主观偏好、用电设备改变等引发不确定性和强非线性。仅依 据用户自身的历史计量数据很难精准预测和恢复丢失数据。如何依据用户的特征来恢复计 量数据是需要解决的关键问题。
电网中用户类型繁多,包括普通居民用户、工厂、商场等。矩阵分解方法虽然可以加 快算法速度,但如果使用相同维度的特征值来描述不同类型的用户,势必会造成较大的计 算误差。如何克服用户异构对数据恢复精度的影响也是一项难题。
协同过滤算法可以提高电能计量缺失数据的恢复精度,然而电网中用户数量巨大,如何 从庞大的用户群中快速搜索协同目标也是亟待解决的重要问题。
中国专利申请CN201810958160.5公开了一种多时间尺度时间序列协同预测模型的构建 方法,包括:步骤1),输入用户用电情况随着时间的变化而产生的记录数据,根据所述记 录数据构建相关的时序表示;步骤2),基于步骤1)得到的时序表示,对所有用电数据进行 分析,捕获不同的特征并分析其相对应的变化规律,并以此来构建时间尺度矩阵序列;步 骤3),根据步骤1)和步骤2)的输出,构建用电数据时间序列的预测模型,所述时间序列的 预测模型为多尺度RNN模型;步骤4),根据步骤1)、步骤2)和步骤3)的输出,以及外部因素的输出进行加权融合求解,得到多时间尺度用电时序数据协同预测模型。其存在的不足是采用时序数据进行协同预测,误差较大。
发明内容
针对现有技术存在的问题,本发明提出了一种减少算法复杂度,提高数据恢复精度的 基于协同拟合的电能计量数据恢复方法。
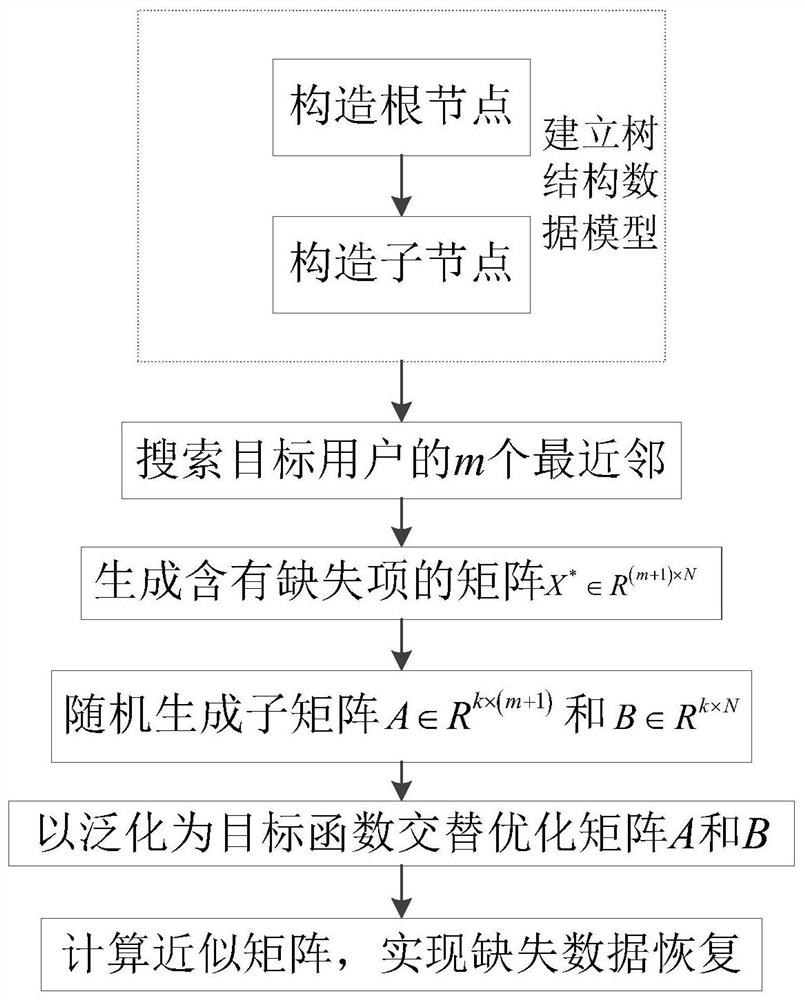
本发明是这样实现的,基于协同拟合的电能计量数据恢复方法,其特征在于:包括以 下步骤:
S1:以电能计量的准确的历史数据为基准建立二叉树数据模型;
S2:搜索目标用户的m个最近邻;
S3:生成含有缺失项的矩阵X
S4:随机生成子矩阵A∈R
S5:以泛化函数为目标函数交替优化矩阵A和B;
S6:计算近似矩阵,实现缺失数据恢复。
所述的建立二叉树数据模型包括
1)构造根节点:以x
2)重复构造子节点:对于深度为h子节点,选取x
p=h mod N+1。
所述的S2搜索目标用户的m个最近邻,是指最近邻搜索,给定一个目标用户,根据其 已有数据,在树结构中首先找到包含此用户的子节点,然后依次回退到父节点,按照欧式 距离,不断查找其最邻近的点。
所述的泛化函数为了求解矩阵分解之后的子矩阵A和B,首先定义损失函数C为:
进一步,为了防止数据的过拟合,引入泛化函数,对式(1)进行修正,可得
式中
所述的计算近似矩阵,是指采用交替最小二乘法分解,根据最小二乘法原理,如果矩阵B 是已知的,那么式(2)对A中任一元素A
式中,X
若令W
A
同理,如果矩阵A是已知的,可求得
B
式中,W
矩阵分解即按照公式(3)和(4)迭代求解,对损失函数进行最小优化,直至获得最优解。
本发明的优点及积极效果为:
在快速高效的恢复电能计量数据的缺失值,为此在二叉树搜索算法和矩阵分解算法的 基础上提出了协同拟合算法。首先建立树形结构的用户历史数据,然后以此获得与数据缺 失用户邻近的用户组,最后运用交替最小二乘矩阵分解算法对缺失数据进行恢复。该方法 在解决数据缺失问题上具有较高的可靠性和精确度。
附图说明
图1是本发明的方法流程框图;
图2是本发明的随机用户协同ALS算法示意图;
图3是本发明的协同拟合ALS算法示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进 行进一步详细说明。
实施例1:
如图1所示,本发明是这样实现的,基于协同拟合的电能计量数据恢复方法,包括以 下步骤:S1:以电能计量的准确的历史数据为基准建立二叉树数据模型;
S2:搜索目标用户的m个最近邻;
S3:生成含有缺失项的矩阵X
S4:随机生成子矩阵A∈R
S5:以泛化函数为目标函数交替优化矩阵A和B;
S6:计算近似矩阵,实现缺失数据恢复。
具体上,
一、数学模型
令U=(u
表1电能计量时间序列数据
令W∈R
设矩阵X∈R
X≈AB
其中,A∈R
用户i与用户i
二、协同拟合算法
1)ALS矩阵分解
当前常用的矩阵分解算法主要有两种,分别是奇异值分解(SVD)和交替最小二乘法分解 (ALS)。SVD要求预先使用加权平均值的方法将矩阵中的缺失值补全,才可进行矩阵分解运 算,算法复杂度较高。而ALS的复杂度则相对较低,它从全局的角度通过一组低维度的隐 语义因子表达数据的特征,进而恢复矩阵中的缺失项。
为了求解矩阵分解之后的子矩阵A和B,首先定义损失函数C为:
进一步,为了防止数据的过拟合,引入泛化函数,对式(1)进行修正,可得
式中
由于估算矩阵与实际矩阵是存在差异的,为了尽可能接近真实数据,需要将损失函数最 小化。根据最小二乘法原理,如果矩阵B是已知的,那么式(2)对A中任一元素A
式中,X
A
同理,如果矩阵A是已知的,可求得
B
式中,W
ALS矩阵分解即按照公式(3)和(4)迭代求解,对损失函数进行最小优化,直至获得最优 解。
2)最近邻算法
在ALS矩阵分解算法中,通过式(3)和(4)可以发现,恢复矩阵的损失函数C与特征值 维度k有密切联系。因用户类型不同,它们的特征维度势必不一致。若在矩阵分解时针对所 有用户均提取相同的特征维度,将会造成误差偏大,影响数据拟合精度。为了提高数据恢 复精度,需要尽可能的避免因特征维度不一致带来的误差。并且高维度的矩阵分解算法也 存在计算复杂度较高的问题。因此需要利用相似用户的数据进行协同拟合,以降低算法复 杂度和实现缺失计量数据的恢复。
最近邻算法旨在为用户找到特征最相似的协同用户。其实现的最简单方法是遍历搜索, 但当电网用户数据量巨大时,此方法将会花费大量的运算时间。针对电网中电能计量数据 具有数据条目远远大于数据维度的特点,基于树型结构的数据模型可以实现最近邻用户的 快速搜索。
以电能计量的准确的历史数据为基准建立二叉树数据模型,其维度与历史采样次数一致, 用N表示。令X
①构造根节点。以x
②重复构造子节点。对于深度为h子节点,选取x
p=h mod N+1
③最近邻搜索。给定一个目标用户,根据其已有数据。在树结构中首先找到包含此用户 的叶节点,然后依次回退到父节点,按照欧式距离,不断查找其最邻近的点。
3)数据恢复算法
设恢复一个用户的缺失数据,需m个用户的数据进行协同拟合,m=M。对本文所提出的数据恢复算法流程如图1所示。
若最近邻搜索采用遍历搜索算法时,其复杂度为O(M),采用二叉树搜索算法时其复杂度 为
4)数值仿真与分析
为了进一步验证所设计的数据恢复算法的有效性,借助于某电网计量中心统计的电能计 量数据集将本文提出的算法与多项式拟合算法进行分析。数据集中M=11397,N=92,缺失 数据约有658项。这些缺失数据不但影响到正常出账业务,而且引起了用户的投诉。
仿真验证中提取测试用户u
表2用户u
采用矩阵分解方法恢复丢失数据的仿真实验中λ=0.001,m=7,数据恢复精度用估计误 差
当ALS算法运行时,若协同用户随机选取,其恢复结果误差值e=1163.627;若协同用户 随机选取,其恢复结果误差值e=0.007。通过算法误差对比和观察图2与图3曲线图,可得 经过改进的协同拟合ALS算法具有较高的恢复精度。进一步说明了用电行为相似的用户, 相互之间的电能计量值相关性密切。另外,在现实生活中,通过最近邻用户的电能计量来 解决用户电量缺失比基于时间序列拟合算法更具有说服力和可靠性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和 原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 基于协同拟合的电能计量数据恢复方法
- 基于小波变换和曲线拟合的畸变信号条件下电能计量方法