一种基于残差和批量归一化的神经网络带噪声纹识别方法
文献发布时间:2023-06-19 11:27:38
技术领域
本发明属声纹识别领域,具体来说涉及一种基于残差和批量归一化的神经网络带噪声纹识别方法。
背景技术
传统声纹识别技术大多数都基于身份识别因子(Identity Vector,I-Vector),但该方法的建模能力还有待优化。近年来,使用深度神经网络(Deep neural network,DNN)来捕捉说话人的语音特征是一大热潮,但该方法在满足训练要求的同时增大了计算复杂度。采用时延神经网络(Time Delayed Neural Network,TDNN)嵌入,并用深层神经网络来训练说话人识别器提取说话人信息的方法可以有效改良DNN。TDNN算法在各方面的性能都强于I-Vector,但当识别环境中出现较强的噪音干扰时,鲁棒性效果不佳,并且随着网络深度的增加,网络容易出现梯度消失和退化现象。
发明内容
本发明的目的在于克服上述缺点而提供的一种能提高噪声环境下时延神经网络的鲁棒性,缓解神经网络退化和梯度消失现象需求,提高声纹识别率的基于残差和批量归一化的神经网络带噪声纹识别方法。
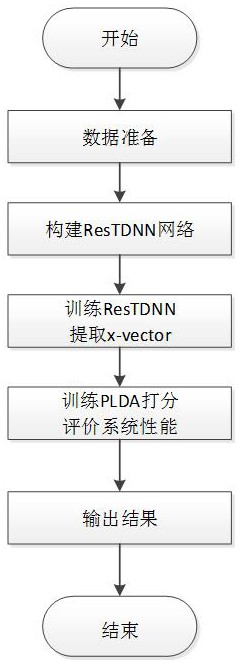
本发明的一种基于残差和批量归一化的神经网络带噪声纹识别方法,包括以下步骤:
(1)数据准备:准备带噪环境下的数据集,对所述语音信号分别提取相应的梅尔倒谱系数(Mel Frequency Cepstral Coefficents,MFCC);
(2)构建ResTDNN(残差时延神经网络)网络结构:设置TDNN1的输出维度和TDNN4的维度一致,均为512维,使其满足恒等跳跃连接映射的要求,在此加入残差模块,残差模块直接在TDNN网络上进行引入,选择两层残差块,设计残差模块结构;
残差模块引入完成后,在ResTDNN中设置5层TDNN层,设置TDNN1的输出维度和TDNN4的维度一致,均为512维,为使其满足恒等跳跃连接映射的要求,在此加入残差模块,在每一个TDNN层之前均设置Relu激活函数和归一化处理,其中TDNN2和TDNN3层是残差模块的卷积层,信息聚合在统计池层后传递到全连接层,在全连接层的处提取映射降至512维的x-vector信息;
(3)ResTDNN构建完成之后,利用自然梯度随机下降法对网络进行训练,训练完成后,通过降维提取的x-vector利用10s左右的语音信息捕捉说话人声纹信息,采用交叉熵损失函数;
(4)用线性判别分析(LDA)进行降维,降维后对x-vector进行长度归一化,训练线性概率分析(PLDA)后,分别计算两条语音分别来自不同空间的似然函数,采用等错误率(EER)和最小检测代价(minDCF)来评价识别系统。
本发明与现有技术相比,具有明显的有益效果,从以上技术方案可知:本发明利用残差神经网络的输入层能对输出层进行不断修正以减少信息损失的特点,以及批量归一化能使每一层的平均值和方差限制在一定范围内,进而提高网络泛化的能力。直接在TDNN的网络中引入残差神经网络和批量归一化处理,形成新的网络框架,从而使声纹识别率在无噪声环境下提高到了96.811%,在有噪声环境下声纹识别率提高到了96.768%,相比TDNN网络提升明显。
附图说明
图1是本发明的流程图。
图2是本发明的残差模块结构图。
图3是本发明的ResTDNN网络模型结构。
具体实施方式
以下结合附图及较佳实施例,对依据本发明提出的一种基于残差和批量归一化的神经网络带噪声纹识别方法的具体实施方式、结构、特征及其功效,详细说明如后。
参见图1,本发明的一种基于残差和批量归一化的神经网络带噪声纹识别方法,包括以下步骤:
(1)数据准备:将混响、噪音以及音乐随机加入到数据集中,得到带噪环境下的数据集,分别对训练集和测试集相关语音文本进行数据预处理、加噪、删除静音和小于5s语音的过程,对所述语音信号分别提取相应的梅尔倒谱系数;
(2)构建ResTDNN网络:
修改残差神经网络的输入层使其能对输出层修正,激活函数采用线性整流函数(Rectified Linear Unit,ReLU),在每一层的激活函数激活前均进行归一化处理,所使用的归一化函数为:
其中:x=(x
其中,拉升参数γ
添加残差单元设计ResTDNN:ResTDNN网络共5层TDNN层。图2为残差模块结构图,特征输入后经过一个卷积层,在每一个卷积层之前均设置Relu激活函数和归一化处理。本实例中,TDNN2和TDNN3层是残差模块的卷积层,将TDNN1的输出维度和TDNN4的维度均设为512维,在此加入残差模块,残差模块直接在TDNN网络上进行引入,选择两层残差块。
图3为ResTDNN网络模型结构。设置ResTDNN网络中的mfcc为23维mfcc,帧长为25ms,在长达3s的滑动窗口处进行平均归一化,采用VAD过滤非语音帧。ResTDNN网络配置如下:
主要功能分成三组,第一组1-5层,在帧级对语音进行上下文拼接处理,TDNN的输入为F维的T个语音帧组成的序列,把以当前t帧为中心输出的5帧拼接成一个新的帧集合t,再以t为中心的上下文4帧为一个新的帧集合t,作为tdnn2层的输入,即在前一层的上下文基础上进行拼接输出,tdnn2的可看到9帧的上下文,tdnn3可看到15帧的上下文,采用恒等短路连接,加入残差,tdnn3的输出与tdnn1的输出进行拼接作为tdnn4的输入。tdnn5无任何附加时间上下文。第二组,第6层,统计池层接收tdnn5的输出作为输入,捕获第5层的信息并计算每个维度的平均值和标准差,统计信息连接在一起来生成3000维向量。第三组,第7-9层,在Relu激活之前,在全连接层实现嵌入提取映射至512维的x-vector,最后,用softmax作为输出层,L为输出层的输出维度;
(3)利用自然梯度随机下降法对网络进行训练。通过降维提取的x-vector利用10s左右的语音信息捕捉说话人声纹信息,采用交叉熵作为损失函数。
(4)训练PLDA进行打分估计,判定系统识别性能。用线性判别分析(LDA)进行降维到150维,降维后对x-vector进行长度归一化,训练PLDA后,通过计算两条语音分别来自不同空间的似然函数来衡量两条语音是否属于同一说话人,采用等错误率(EER)和最小检测代价(minDCF)来评价识别系统的性能。
经测试,在本实施例中,ResTDNN系统在有噪声环境下的声纹识别率高于同噪声条件下的TDNN网络,其中等错误率相对降低
8.9%,minDCF相对下降了19.6%,ResTDNN在有噪声情况下和无噪声环境下的等错误率相差不大,表明了使用ResTDNN的方法使系统的鲁棒性得到了提升,且声纹识别准确率提升明显。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,任何未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 一种基于残差和批量归一化的神经网络带噪声纹识别方法
- 一种基于残差块全卷积神经网络的数据噪声压制方法