具有动态可编程分配方案的高带宽存储器系统
文献发布时间:2023-06-19 11:29:13
发明背景
使用神经网络可以解决一整类复杂的人工智能问题。由于这些问题通常是计算和数据密集型的,硬件解决方案通常有利于提高神经网络的性能。由于这些解决方案通常需要处理大量数据,因此基于存储器的操作的性能至关重要。在实现存储器访问性能和效率要求的同时,创建一个求解神经网络的硬件平台是一项技术挑战。因此,需要一种硬件平台,其具有能够有效执行神经网络处理所需的存储器操作的存储器访问和布局方案。
附图简述
在以下详细描述和附图中公开了本发明的各种实施例。
图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。
图2是示出使用神经网络解决人工智能问题的系统的实施例的框图。
图3是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。
图4是示出用于执行存储器访问的过程的实施例的流程图。
图5是示出用于响应存储器数据请求的过程的实施例的流程图。
图6是示出用于执行存储器访问的过程的实施例的流程图。
详细描述
本发明可以以多种方式实现,包括作为过程;装置;系统;物质的组成;体现在计算机可读存储介质上的计算机程序产品;和/或处理器,例如被配置为执行存储在耦合到处理器的存储器上和/或由该存储器提供的指令的处理器。在本说明书中,这些实现或者本发明可以采取的任何其他形式可以被称为技术。通常,在本发明的范围内,可以改变所公开的过程的步骤顺序。除非另有说明,否则被描述为被配置成执行任务的诸如处理器或存储器的组件可以被实现为在给定时间被临时配置为执行任务的通用组件或者被制造为执行任务的特定组件。如本文所使用的,术语“处理器”指的是被配置成处理数据(例如计算机程序指令)的一个或更多个设备、电路和/或处理核心。
下面提供了本发明的一个或更多个实施例的详细描述以及说明本发明原理的附图。结合这些实施例描述了本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求限定,并且本发明包括许多替代、修改和等同物。为了提供对本发明的全面理解,在以下描述中阐述了许多具体细节。这些细节是出于示例的目的而提供的,并且本发明可以根据权利要求来实施,而不需要这些具体细节中的一些或全部。为了清楚起见,没有详细描述与本发明相关的技术领域中已知的技术材料,以便不会不必要地模糊本发明。
公开了一种高带宽存储器系统。处理器系统的存储器单元围绕处理组件布置。在一些实施例中,处理组件被布置在相对于多个存储器单元的中央位置,该多个存储器单元可以包括独立的北、东、南和西存储器单元。处理组件可以是具有多个处理元件的处理器,其中每个处理元件包括其自己的控制逻辑和矩阵计算引擎。通过应用神经网络来解决复杂的人工智能问题,处理器的处理元件可以并行一起工作。处理元件是所公开的高带宽存储器系统的一部分,用于在存储器和处理组件之间有效地传输数据。处理组件的每个处理元件可以配置有分配方案,以将数据分散在可用的存储器单元中。分配方案是动态可编程的,使得不同的处理元件可以应用相同或不同的分配方案。例如,在各种实施例中,可以使用处理器指令对每个处理元件进行编程,以动态配置该处理元件的分配方案。在各种实施例中,共享相同工作负荷的处理元件可以被编程地配置成利用相同的分配方案,而具有不同工作负荷的处理元件可以被编程地配置成利用不同的分配方案。不同的分配方案有助于防止多个处理元件彼此步调一致地工作。通过改变分配方案,可以更有效地利用存储器单元,并提高存储器性能。例如,通过更平等地利用存储器单元/存储体(memory bank)和存储器端口,可以实现完全或接近完全的带宽利用。此外,当访问存储器时,所公开的发明显著提高了功率节省并减少了等待时间(latency)。在一些实施例中,存储器单元访问单位(accessunit)的大小也是可配置的。例如,存储器单元访问单位的大小可以通过处理器指令以编程方式配置。每个处理元件可以使用可配置的访问单位大小的组向每个存储器单元读取和/或写入数据。此外,存储器访问操作可以跨越多个访问单位,并且引用分配在多个存储器单元中的数据。在各种实施例中,每个存储器访问请求被广播到所有存储器单元,并且每个存储器单元返回部分响应,这些部分响应被组合以实现广播的请求。
在一些实施例中,处理器系统包括多个(a plurality of)存储器单元和耦合到多个存储器单元的处理器。例如,处理器系统包括通信连接到多个存储器单元的处理器。在一些实施例中,存储器单元被布置在处理器的所有侧面上,以帮助最小化从处理器到每个存储器单元的等待时间。多个存储器单元中的每一个包括请求处理单元和多个存储体。例如,请求处理单元接收存储器访问请求,例如读取请求和/或写入请求,并确定是否以及如何处理这些请求。请求处理单元可以确定存储器访问请求的一部分是否可以由存储器单元及其对应的存储体服务。例如,请求处理单元可以将存储器访问请求分解成部分请求,并确定部分请求的哪个子集可以从存储器单元的相应存储体得到服务。在各种实施例中,每个存储器单元可以包括多个存储体,以增加存储器单元的存储器大小。例如,存储器单元可以包括4、8、16、32或其他适当数量的存储体。在一些实施例中,处理器包括多个处理元件。例如,处理器是包括一组处理元件的处理组件。处理元件可以排列成矩阵,例如处理元件的8×8阵列或网格。处理器还包括将多个处理元件通信连接到多个存储器单元的通信网络。例如,诸如片上网络子系统和/或网络接口/总线的通信网络将每个处理元件通信连接到每个存储器单元。在一些实施例中,多个处理元件中的每个处理元件包括控制逻辑单元和矩阵计算引擎。例如,多个处理元件中的第一处理元件包括用于控制第一处理元件的控制逻辑和用于计算矩阵运算的矩阵计算引擎。控制逻辑被配置为使用动态可编程分配方案访问来自多个存储器单元的数据。例如,控制逻辑使用处理器指令来配置,以利用特定的分配方案或模式。该方案可以基于处理元件工作负荷或另一种适当的配置。分配方案确定处理元件专用的存储器地址到存储器单元的存储器位置的映射。
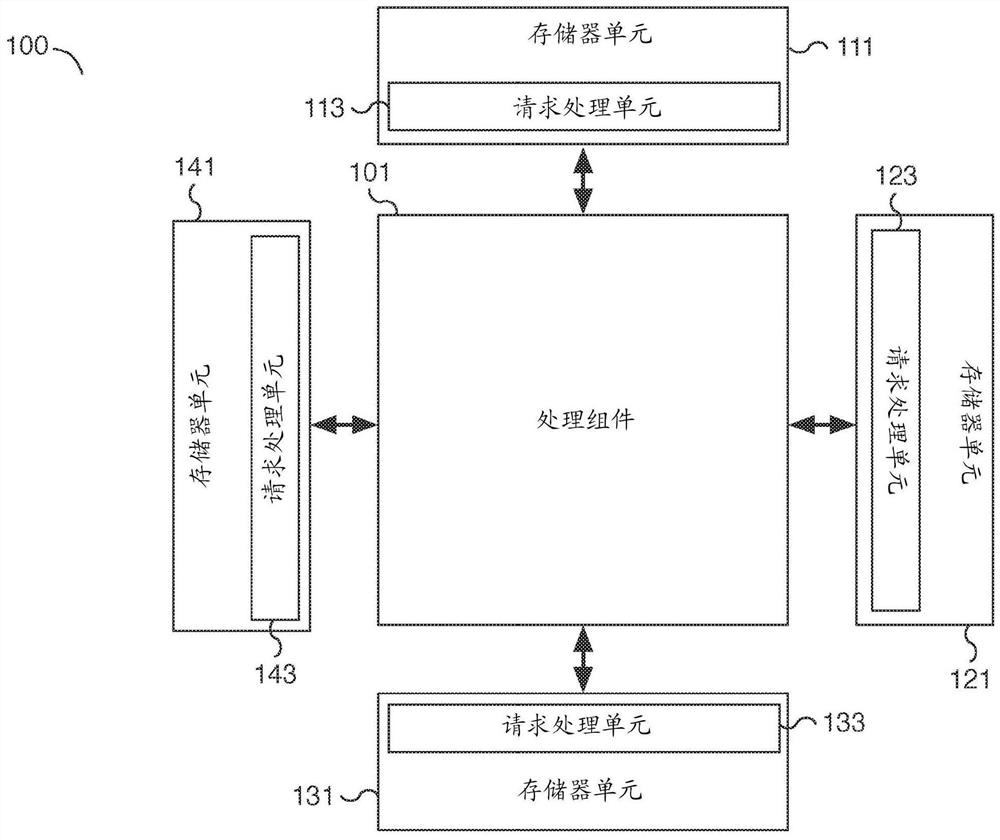
图1是示出使用神经网络解决人工智能问题的系统的实施例的框图。在所示的示例中,系统100是包括处理组件101和存储器单元111、121、131和141的硬件平台。存储器单元111、121、131和141中每一个分别包括请求处理单元113、123、133和143之一。处理组件101通信连接到存储器单元111、121、131和141。处理组件101连接到存储器单元111、121、131和141中的每一个,并且可以同时与它们通信。存储器单元111、121、131和141被定位在处理组件101周围,但是其他布局也是合适的。通过将存储器单元111、121、131和141定位在处理组件101周围,存储器单元111、121、131和141可以被处理组件101同时访问和/或多个连接可以被处理组件101用来与不同的存储器单元111、121、131和141并行通信。在所示的示例中,系统100包括围绕处理组件的四个存储器单元,但是可以适当地使用更少或更多的存储器单元。
在一些实施例中,处理组件101是包括一个或更多个处理元件(未示出)的处理器。每个处理元件可以至少包括用于执行矩阵运算的矩阵计算引擎。处理元件还可以使用通信网络和/或总线(例如片上网络子系统)进行通信连接。用于执行神经网络运算的数据可以从诸如位于处理组件101周围的存储器单元111、121、131和141的存储器单元中检索并写入其中。例如,使用片上网络子系统,存储器访问操作可以从处理组件101的处理元件指向存储器,存储器包括存储器单元111、121、131和141。在一些实施例中,每个处理元件可以被分配特定的工作负荷,并且每个工作负荷可以与存储在存储器中的特定数据集相关联。例如,工作负荷的数据集可以包括激活和/或滤波矩阵数据。在各种实施例中,数据与大型神经网络矩阵相关联,并且可以包括数百个或更多个矩阵元素。相关数据可以跨存储器单元111、121、131和141的不同区域存储。在一些实施例中,数据存储在基于动态可编程分配方案分配在存储器单元111、121、131和141上的访问单位大小的组中。
在一些实施例中,数据可以根据工作负荷或另一个适当的标识符来访问。例如,工作负荷标识符可用于确定如何在不同的可用存储器单元之间分配和检索数据。在各种实施例中,不同的工作负荷被编程为使用不同的分配方案在可用的存储器单元之间分配它们相应的工作负荷数据。例如,每个工作负荷可被动态编程为使用不同的分配方案。在各种实施例中,分配方案使用可配置的有序模式来访问存储器单元。不是对所有工作负荷使用预定义的分配,而是可以对处理元件进行动态编程,以不同于其他处理元件的方式分配数据。这允许存储器单元的更好的利用和效率。在各种实施例中,与存储器访问操作相关联的数据可以驻留在一个或更多个不同的存储器单元中。例如,存储器读取请求可以由位于存储器单元111、121和131中的数据来服务。不同的存储器请求可以由存储器单元121、131和141中的数据来服务。在一些实施例中,诸如可编程散列函数的散列函数用于确定特定工作负荷或标识符的存储器布局方案或访问顺序模式。例如,一个处理元件的存储器读取请求可以使用重复的有序模式来访问存储器单元,该有序模式从存储器单元111开始,接着是存储器单元121、存储器单元131和存储器单元141。不同处理元件的存储器读取请求可以使用不同的可编程重复有序模式,该有序模式从存储器单元141开始,接着是存储器单元121、存储器单元131和存储器单元111。由于数据分配在不同的存储器单元上,存储器请求可以触发来自不同存储器单元的一个或更多个部分响应,每个存储器单元对存储器请求的一部分进行响应。一旦处理元件接收到所有的部分响应,存储器请求就完成了。
在一些实施例中,存储器单元111、121、131和141各自分别包括请求处理单元113、123、133和143之一,以处理存储器访问操作。诸如写入或读取存储器访问操作之类的存储器访问操作可以被分成多个部分访问请求。在一些实施例中,存储器访问操作被一个或更多个请求处理单元(例如请求处理单元113、123、133和/或143)分解或展开成一个或更多个部分访问请求。基于所请求的存储器范围,请求处理单元确定其相关联的存储器单元是否包含所请求的数据。例如,在一些实施例中,存储器请求被广播到所有存储器单元,并由每个存储器单元的相应请求处理单元进行处理。每个请求处理单元分析该请求,并且不同的请求处理单元响应存储器请求的不同部分。例如,请求处理单元仅响应对与其存储器单元相关联的数据或存储器地址的请求。请求处理单元113响应与存储器单元111相关联的请求,请求处理单元123响应与存储器单元121相关联的请求,请求处理单元133响应与存储器单元131相关联的请求,并且请求处理单元143响应与存储器单元141相关联的请求。在存储器访问请求可由特定存储器单元服务的情况下,相关联的请求处理单元可从相关联的存储器单元检索相关数据(或将相关数据写入相关联的存储器单元)。不能由特定存储器单元服务的存储器访问请求可以被忽略,并将由相应的适当存储器单元处理。在一些实施例中,每个存储器单元包含多个存储体,并且请求处理单元可以将部分存储器访问请求导向存储器单元的适当存储体。
在一些实施例中,每个存储器单元使用的数据访问单位的大小是可编程的。例如,存储器单元可以被编程为使用128字节或另一个适当大小的访问单位,使得每一个128字节(或另一个适当的访问单位大小)的新组基于可编程分配方案被存储在不同的存储器单元上。这允许使用可编程大小的访问单位跨不同的存储器单元写入数据。例如,第一访问单位的数据被写入第一存储器单元,第二访问单位的数据被写入第二存储器单元,以此类推,这由分配方案的排序来确定。一旦所有存储器单元都被利用,下一个存储器单元就循环回到第一个存储器单元。在各种实施例中,存储器单元的顺序也可以是可编程的,并且可以使用散列函数来确定。例如,基于散列函数的结果,每个工作负荷可以利用不同的分配顺序来访问存储器单元。
图2是示出使用神经网络解决人工智能问题的系统的实施例的框图。在所示的示例中,系统200是包括处理组件201和存储器单元211的硬件平台的部分描述。附加的存储器单元可以被包括,但未显示。类似地,硬件系统中可包含附加组件,但未显示附加组件。在一些实施例中,处理组件201是图1的处理组件101,存储器单元211是图1的存储器单元111、121、131或141。在各种实施例中,针对处理组件201和存储器单元211描述的功能适用于图2中未示出的连接到处理组件201的其他存储器单元。
在一些实施例中,处理组件201是包括诸如处理元件251、253、255和257的多个处理元件的处理器。附加的处理元件用虚线示出,以反映包括以与处理元件251、253、255和257类似的方式运行的附加处理元件。在图2的图中,仅示出了处理组件201的一部分。处理组件201包括片上网络子系统203以及网络接口205、207和209。片上网络子系统203是通信网络和/或通信总线,其将包括处理元件251、253、255和257在内的处理元件以及诸如网络接口205、207和209的网络接口彼此通信连接。片上网络子系统203可用于处理元件相互通信和/或与诸如存储器单元211的存储器单元通信。网络接口205将处理组件201连接到处理组件201北侧的存储器单元211。例如,处理组件201的处理元件251可以经由片上网络子系统203和网络接口205与存储器单元211接口连接,以从存储器读取和/或写入数据。在各种实施例中,网络接口207用于将处理组件201连接到处理组件201西侧的存储器单元(未示出),并且网络接口209用于将处理组件201连接到处理组件201东侧的存储器单元(未示出)。可以包括附加的网络接口(未示出),以将处理组件201连接到放置在处理组件201南侧的存储器单元。图2的示例集中在处理组件201和单个存储器单元(存储器单元211)之间的接口,但是所公开的技术也适用于其他存储器单元(未示出)。
在一些实施例中,存储器单元211包括请求处理单元213和多个存储体,例如存储体221、223、225和227。请求处理单元213从处理组件201的处理元件接收存储器访问请求。存储器访问请求可以是读取请求和/或写入请求。请求处理单元213分解存储器访问请求,以确定它是否可以被存储器单元211的存储体之一服务,可能是部分服务。尽管图2中示出了四个存储体,但是在各种实施例中,存储器单元211可以包括更少或更多的存储体,例如8、16、32、64或其他适当数量的存储体。在一些实施例中,请求处理单元213将存储器访问请求导向存储器单元211的适当存储体。例如,基于请求的存储器地址,请求处理单元213确定要访问的适当的存储体。在一些实施例中,对于单个存储器访问请求,可以访问存储器单元211的两个或更多个存储体。可以基于散列函数来确定存储器单元和存储体。例如,散列函数可以利用请求访问地址范围的处理元件的工作负荷标识符。在一些实施例中,散列函数检查与存储器访问请求相关联的存储器地址的一组位,例如两位或更多位,以将地址范围映射到存储器单元。
在一些实施例中,存储器读取/写入大小,例如存储器访问单位的大小,可以是可编程的。例如,存储器读取可以被编程为64字节、128字节或其他适当的访问单位大小。请求处理单元213可以通过分析每个传入的存储器访问请求来确定要读取和/或写入的适当字节。在存储器单元(例如存储器单元211)可以服务请求的情况下,存储器请求响应将被返回给处理组件201和适当的请求处理元件。在一些实施例中,请求处理单元213准备响应。例如,准备的响应可以包括从存储体读取的数据。该响应可以是仅满足原始存储器访问请求的一部分的部分响应。负责管理相应存储器地址范围的其他存储器单元(未示出)可以实现附加的部分响应。例如,广播到所有存储器单元的大存储器读取请求可以由多个存储器单元提供的多个部分响应来实现。在一些实施例中,每个部分响应包括可用于对部分响应排序的标识符,例如序列标识符。例如,可能没有按顺序接收部分响应,并且使用标识符对部分响应进行排序,并从多个部分响应中构建完整的响应。
图3是示出使用神经网络解决人工智能问题的处理元件的实施例的框图。在所示的示例中,处理元件300包括控制逻辑301、存储器管理单元303、本地储存存储器305、网络接口307和矩阵计算引擎309。在各种实施例中,一个或更多个处理元件可以在相同的数据集或工作负荷上一起工作,以使用大的工作数据集来求解人工智能程序。在一些实施例中,处理元件300是图1的处理组件101和/或图2的处理组件201的处理元件。在一些实施例中,处理元件300是图2的处理元件251、253、255和/或257或另一个处理元件。
在一些实施例中,本地储存存储器305是用于存储数据(诸如与神经网络运算相关的数据)的存储器暂存器(memory scratchpad)。本地储存存储器305可用于存储通过对存储器访问请求的部分响应而检索的数据。部分响应和相关数据可以被收集并存储在本地储存存储器305中,以构建完整的响应。在一些实施例中,本地储存存储器305由用于快速读写访问的寄存器组成。在各种实施例中,处理元件300的一个或更多个组件,例如矩阵计算引擎309,可以访问本地储存存储器305。例如,矩阵输入数据操作数和/或输出数据结果可以存储在本地储存存储器305中。
在一些实施例中,控制逻辑301是用于指导处理元件300的功能的控制逻辑单元,并且可以用于与处理元件300的组件(例如存储器管理单元303、本地储存存储器305、网络接口307和矩阵计算引擎309)接口连接。在一些实施例中,控制逻辑301可以响应用于将神经网络应用于人工智能问题的处理器指令。例如,控制逻辑301可以用于响应于处理指令,经由网络接口307启动从存储器读取和/或写入数据。在一些实施例中,控制逻辑301用于为矩阵计算引擎309加载和准备操作参数。例如,控制逻辑301可以准备用于计算卷积运算的矩阵操作数。在一些实施例中,控制逻辑301用于帮助处理对存储器数据请求的部分响应。
在一些实施例中,存储器管理单元303用于管理处理元件300的存储器相关功能。例如,存储器管理单元303可以用于对用于从诸如图1的存储器单元111、121、131和/或141的存储器单元读取数据和/或向其写入数据的访问单位大小进行编程。在一些实施例中,大的存储器读取被分成访问单位大小的组,并且可用的存储器单元之一负责服务每个存储器组。按访问单位大小的组将数据分配在存储器单元中,允许更有效地访问存储器,并显著提高存储器利用率。在一些实施例中,存储器管理单元303用于配置散列机制,用于在不同的存储器单元之间分配数据。例如,存储器管理单元303可以管理与可编程散列机制相关联的配置。在一些实施例中,存储器管理单元303是控制逻辑301的一部分。可编程散列机制允许分配模式是可配置的,而不是对所有存储器访问操作使用固定的分配模式。例如,不同的处理元件工作负荷可以使用不同的分配模式。作为一个示例,一个工作负荷可以被配置为使用北、东、南、西模式写入存储器单元,而另一个工作负荷可以被配置为使用南、北、东、西模式写入存储器单元。在各种实施例中,分配方案是动态的,并且可以经由控制逻辑301和存储器管理单元303来动态编程。存储器管理单元303用于帮助将本地存储器地址映射到在不同存储器单元中发现的不同存储器访问单位大小的组。
在一些实施例中,网络接口307用于与诸如用于网络通信的片上网络系统的网络子系统接口连接。在一些实施例中,网络接口307与之通信的网络子系统是图2的片上网络子系统203。来自和去往处理元件300的存储器访问请求(例如读取请求和写入请求)经由网络接口307传输。
在一些实施例中,矩阵计算引擎309是硬件矩阵处理器单元,用于执行矩阵运算,包括与卷积运算相关的运算。例如,矩阵计算引擎309可以是用于执行点积运算的点积引擎。在一些实施例中,支持的卷积运算包括逐深度(depthwise)、逐组(groupwise)、正常、规则、逐点和/或三维卷积等。例如,矩阵计算引擎309可以接收第一输入矩阵,例如表示为三维矩阵的大图像的子集。第一输入矩阵可以具有以下维度:高度x宽度x通道(HWC)、通道x高度x宽度(CHW)或另一适当的布局格式。矩阵计算引擎309还可以接收第二输入矩阵,例如滤波器、核或权重等,以应用于第一输入矩阵。矩阵计算引擎309可用于使用两个输入矩阵执行卷积运算,以确定结果输出矩阵。在一些实施例中,矩阵计算引擎309可以包括输入和/或输出缓冲器,用于加载输入数据矩阵并写出结果数据矩阵。矩阵计算引擎309使用的数据可以从本地储存存储器305和/或诸如图1的存储器单元111、121、131和/或141的外部存储器中读取和/或写入这些存储器。
图4是示出用于执行存储器访问的过程的实施例的流程图。例如,通过使用与人工智能问题和神经网络相关联的数据应用神经网络来解决人工智能问题。数据由诸如图2的处理元件251、253、255和257的处理元件从诸如图1的存储器单元111、121、131和/或141的存储器读取和被写入到这些存储器中。在一些实施例中,图4的过程由图1的处理组件101和/或图2的处理组件201的一个或更多个处理元件来执行。在一些实施例中,图4的过程由图3的处理元件300执行。使用图4的过程,存储在存储器中的数据元素可以分配在多个存储器单元中,以提高存储器的利用率和存储器访问操作的效率。
在401,启动存储器管理。例如,在401配置特定的存储器访问分配方案。该配置可以使用处理器指令来启动,例如指向特定处理元件的指令。分配方案可以与特定的工作负荷(例如特定的人工智能问题和神经网络)相关联。在一些实施例中,初始化包括设置工作负荷标识符。例如,工作负荷标识符可用于配置数据如何分配在多个存储器单元中。工作负荷标识符可以是处理器存储器管理指令的参数。每个工作负荷可以使用不同的分配方案来提高存储器的利用率和效率。处理相同数据集或工作负荷的处理元件可以利用相同的工作负荷标识符来共享数据。通过使用不同的分配模式(例如每个工作负荷使用不同的分配模式)将数据分散到存储器单元,存储在存储器中的数据更有效地分配在所有可用存储器中。在一些实施例中,存储器初始化包括配置存储器访问单位大小。例如,存储器访问单位(如128字节、256字节等)可以配置为使得数据按访问单位大小的组写入每个存储器单元。可以根据情况使用更大或更小的访问单位。访问单位组中的数据存储在同一存储器单元中。在一些实施例中,访问单位大小可使用处理器或处理元件的可编程指令来配置。
在一些实施例中,存储器管理的初始化包括配置或编程用于在存储器单元之间分配数据的散列机制。例如,散列机制可以利用种子(seed)来配置分配方案。在一些实施例中,种子基于从存储器地址指定一组位来确定哪个存储器单元被分配给特定访问单位的数据。例如,散列机制可以指定存储器地址的两位,例如两个高位,并且对指定的位执行逐位运算,以将访问单位映射到存储器单元。在一些实施例中,逐位运算利用异或运算。在一些实施例中,散列机制可以以编程方式配置。例如,处理元件可以被配置成利用指定的散列函数和/或被配置成利用散列函数的某些参数。
在403,向存储器单元广播存储器数据请求。例如,对来自存储器的数据的请求被广播到连接到处理组件的处理元件的所有存储器单元。在一些实施例中,该请求经由网络子系统诸如图2的片上网络子系统203和相应网络接口205、207和/或209传输。在一些实施例中,诸如北、东、南和西存储器单元的四个存储器单元围绕诸如图1的处理组件101的处理组件。在该示例中,所有四个存储器单元,例如存储器单元111、121、131和141,都接收广播的存储器数据请求。在一些实施例中,数据请求是针对大量数据的,并且包括跨越多个访问单位的数据。该请求可以被构造为引用基本存储器地址和大小参数,以确定从基本存储器地址开始请求多少数据。其他存储器引用方案也可能是合适的。在一些实施例中,广播的存储器请求还包括对应于分配方案的映射信息。例如,接收存储器单元可以使用映射信息来确定在401以编程方式配置的散列机制和/或散列机制参数。作为另一个示例,映射信息还可以包括以编程方式配置的访问单位大小。在各种实施例中,存储器数据请求可以被提供给存储器单元用于读取数据或写入数据。
在405,从存储器单元接收部分存储器数据响应。例如,从两个或更多个不同的存储器单元接收两个或更多个部分存储器数据响应。部分响应是对在403广播的存储器数据请求的响应。由于存储器请求跨越多个访问单位,多个存储器单元可以响应,每个存储器单元提供对应于不同访问单位的部分响应,以完成整个请求。每个存储器单元创建与其负责的一个或更多个访问单位相关联的一个或更多个部分响应。例如,与存储器请求相关联的数据可以散布在三个存储器单元中。三个存储器单元中的每一个都以部分存储器数据响应来响应。在405,接收部分存储器响应。在一些实施例中,每个响应包括标识符,例如用于将部分响应组织成完整响应的序列标识符。
在407,完成存储器数据请求处理。例如,部分响应被排序为包括所有请求数据的完整响应。在各种实施例中,仅在接收到所有部分响应之后,处理才完成。例如,包括在部分响应中的序列标识符可以用于确定处理完成。与每个部分响应相关联的数据可以存储在处理元件的本地存储器中,例如图3的本地储存存储器305。在一些实施例中,完整的响应可以被一个以上的处理元件利用。例如,访问相同数据的处理元件可以共享对完整的存储器数据响应的利用。
图5是示出用于响应存储器数据请求的过程的实施例的流程图。例如,存储器单元的请求处理单元利用图5的过程来响应广播的存储器数据请求。请求处理单元分解存储器请求,并确定存储器单元负责哪些访问单位,然后为由存储器单元管理的访问单位准备并发送一个或更多个部分响应。在一些实施例中,图5的过程由图1的请求处理单元113、123、133和/或143和/或图2的请求处理单元213来执行。在一些实施例中,响应于在图4的403广播的存储器数据请求,执行图5的过程。在一些实施例中,使用图5的过程准备的响应在图4的405处由处理元件接收。
在501,接收存储器数据请求。例如,接收跨越多个访问单位的存储器数据请求。一些访问单位与存储器单元相关联,而其他访问单位可以与不同的存储器单元相关联。在各种实施例中,多个存储器单元可以接收与广播的存储器数据请求相同的存储器数据请求。在一些实施例中,存储器数据请求包括基地址(base address)和大小参数,以确定所请求的地址范围。存储器数据请求还可以包括映射信息,以确定用于存储器访问请求的特定存储器分配方案的散列机制和/或散列机制参数。在一些实施例中,存储器数据请求映射信息包括访问单位大小。
在503,存储器数据请求被分解成部分请求。例如,跨越多个访问单位的请求被分成部分请求。在一些实施例中,通过基于配置的访问单位大小将存储器数据请求展开成部分请求来执行分解。例如,跨越三个访问单位的存储器数据请求被分解成三个部分请求,每个访问单位一个部分请求。作为另一个示例,在一些实施例中,每个存储器单元负责多个访问单位。例如,在一个场景中,存储器数据请求跨越平均分配在4个存储器单元中的32个存储器访问单位,每个存储器单元负责8个部分请求。每个部分请求对应于由存储器单元管理的数据的存储器访问单位。
在505,访问相关部分请求的数据。例如,从存储器单元的存储体中检索与部分请求匹配的访问单位的数据(或将该数据写入存储体)。在一些实施例中,存储器单元可以具有多个存储体,并且相应部分请求的数据存储在存储器单元的一个或更多个存储体中。在一些实施例中,所访问的数据响应于从跨越多个访问单位的较大请求分解的部分请求。在存储器访问读取操作的情况下,在部分请求与存储器单元匹配的情况下,从该存储器单元的存储体读取相应的数据。类似地,在存储器访问写入操作的情况下,在部分请求与存储器单元匹配的情况下,相应的数据被写入该存储器单元的存储体。
在一些实施例中,部分请求基于可编程分配方案与相应的存储器单元映射。例如,不同的工作负荷可以使用利用散列机制配置的不同分配方案将数据分配到存储器单元。在各种实施例中,在505,用于所配置的分配方案的散列机制被用于确定接收存储器数据请求的存储器单元是否对部分请求负责。在存储器单元管理部分请求的特定地址范围的情况下,检索(或写入)相应的数据。否则,部分请求被忽略,并将由负责该地址范围的正确存储器单元处理。
在507,准备并发送部分存储器数据响应。例如,从存储器单元读取的数据被打包成与部分请求相关联的响应。在一些实施例中,对应于读取操作准备的响应是部分存储器数据响应,因为它仅包括所请求数据的一部分。在各种实施例中,每个部分响应包括标识符,例如用于将部分响应排序为完整响应的序列标识符。处理元件可以利用每个部分存储器数据响应的标识符来对无序接收的一组部分响应进行排序。该响应被传输到处理组件,以供一个或更多个处理元件接收。在一些实施例中,响应是对应于写入操作的请求被完成的确认。
图6是示出用于执行存储器访问的过程的实施例的流程图。例如,处理元件利用图6的过程来收集对应于读取操作的存储器数据请求的数据。在一些实施例中,诸如图2的处理元件251、253、255或257之一的处理元件从诸如图1的存储器单元111、121、131和/或141的多个存储器单元接收部分存储器数据响应。在一些实施例中,响应于在图4的403广播的存储器数据请求和/或响应于使用图5的过程发送的部分存储器数据响应,执行图6的过程。在一些实施例中,在图4的405和/或407处执行图6的过程,以从各种存储器单元收集部分响应。
在601,接收数据存储器部分响应。例如,接收从存储器单元发送的对数据存储器请求的部分响应。在各种实施例中,响应包括来自同一存储器单元的大小为一个或更多个访问单位的数据。在一些实施例中,响应包括标识符信息,例如可以用于相对于其他部分响应对接收的部分响应进行排序的序列标识符。
在603,识别数据存储器部分响应。例如,使用包括在接收到的部分响应中的标识符,相对于原始数据存储器请求来识别数据存储器部分响应。例如,一个请求可以分解或展开为五个部分请求。在603识别部分响应,以确定它对应于五个部分响应中的哪一个。在一些实施例中,通过检查诸如序列标识符的标识符来执行识别。识别结果可用于确定部分响应相对于其他部分响应的顺序,并从接收到的部分响应集合中重建完整的响应。
在605,数据存储器部分响应被存储在本地存储器中。例如,从存储器中读取的数据是从部分响应的数据有效载荷中提取的,并存储在本地存储器中。在一些实施例中,从本地存储器中分配大小被设定用于所请求的数据的临时缓冲器,以从部分响应中构造完整的响应。由于部分响应可能相对于它们相应的存储器地址被无序接收,所以来自部分响应的数据基于部分响应与原始请求数据的关系被存储在分配的缓冲器中的相应位置。例如,分配大小被设置用于五个部分响应的缓冲器,并且来自接收到的部分响应的数据被写入缓冲器中的相应地址位置,而不管何时接收到部分响应。在一些实施例中,每个部分响应是访问单位大小的响应或访问单位的倍数。在各种实施例中,本地存储器是图3的本地存储器储存器305。使用临时缓冲器,可以从部分响应中重建完整的数据存储器响应。
在607,确定响应是否完整。例如,一旦接收到构建完整响应所需的所有部分响应,则响应是完整的。在响应完整的情况下,处理进行到609。在响应不是完整的情况下,处理循环回到601以接收附加的部分响应。
在609,完成存储器数据请求处理。例如,对应于完整响应的数据可用于额外的计算,例如矩阵计算。在一些实施例中,与完成的响应相关联的数据位于本地存储器中,例如处理元件的本地存储器储存器。完成的响应可以用作处理元件的矩阵计算引擎的输入。在一些实施例中,完成的响应对应于描述神经网络的数据或与人工智能问题相关联的激活数据。
尽管为了清楚理解的目的已经详细描述了前述实施例,但是本发明不限于所提供的细节。有许多实现本发明的替代方式。所公开的实施例是说明性的,而不是限制性的。
- 具有动态可编程分配方案的高带宽存储器系统
- 用于动态可编程分配方案的带交叉开关的高带宽存储系统