在高性能计算环境中支持异构和不对称的双轨架构配置的系统和方法
文献发布时间:2023-06-19 11:32:36
版权声明
本专利文档公开内容的一部分包含受版权保护的素材。版权拥有者不反对任何人对专利文档或专利公开内容按照在专利商标局的专利文件或记录中出现得那样进行的传真复制,但是除此之外在任何情况下都保留所有版权。
优先权要求
本申请要求于2019年8月21日提交的题为“SYSTEM AND METHOD FOR SUPPORTINGHETEROGENEOUS AND ASYMMETRIC DUAL RAIL FABRIC CONFIGURATIONS IN A HIGHPERFORMANCE COMPUTING ENVIRONMENT”、申请号为16/547,329的美国专利申请的优先权权益;本申请还要求于2019年2月4日提交的题为“SYSTEM AND METHOD FOR USINGINFINIBAND ROUTING ALGORITHMS FOR ETHERNET FABRICS IN A HIGH PERFORMANCECOMPUTING ENVIRONMENT”、申请号为16/267,072的美国专利申请的优先权权益;本申请还要求于2019年1月29日提交的题为“SYSTEM AND METHOD FOR A MULTICAST SENDDUPLICATION INSTEAD OF REPLICATION IN A HIGH PERFORMANCE COMPUTINGENVIRONMENT”、申请号为16/261,362的美国专利申请的优先权权益;本申请还要求于2019年8月21日提交的题为“SYSTEM AND METHOD FOR ON-DEMAND UNICAST FORWARDING IN AHIGH PERFORMANCE COMPUTING ENVIRONMENT”、申请号为16/547,332的美国专利申请的优先权权益;本申请还要求于2019年8月21日提交的题为“SYSTEM AND METHOD FOR A SINGLELOGICAL IP SUBNET ACROSS MULTIPLE INDEPENDENT LAYER 2(L2)SUBNETS IN A HIGHPERFORMANCE COMPUTING ENVIRONMENT”、申请号为16/547,335的美国专利申请的优先权权益,这些申请中的每一个通过引用整体并入文本。
本申请与以下申请相关,其中每个申请通过引用整体并入本文:2017年8月31日提交的美国临时专利申请号62/552,818;2018年6月1日提交的美国临时专利申请号62/679,465;2018年8月28日提交的美国专利申请号16/115,138;2018年6月1日提交的美国临时专利申请号62/679,469;2018年6月1日提交的美国临时专利申请号62/679,478;以及美国临时专利申请号。
背景技术
随着更大的云计算体系架构的推出,与传统网络和存储相关联的性能和管理瓶颈已成为重要的问题。人们对使用诸如InfiniBand(IB)和RoCE(聚合以太网上的RDMA(远程直接存储器访问))技术之类的高性能互连作为云计算架构的基础越来越感兴趣。这是本教导的实施例旨在解决的总体领域。
发明内容
用于在高性能计算环境中支持异构(heterogeneous)和不对称(asymmetric)的双轨架构(dual rail configuration)的系统和方法。一种方法可以包括在各自包括一个或多个微处理器的一个或多个计算机处提供:多个主机,该多个主机中的每个主机包括至少一个双端口适配器(dual port adapter);私有架构(private fabric),该私有架构包括两个或更多个交换机;以及公共架构(public fabric),该公共架构包括云架构。可以在该多个主机中的主机处供给工作负载(workload)。可以将放置策略(palcement policy)分配给所供给的工作负载。然后,可以根据该放置策略将所供给的工作负载的在对等节点(peernode)之间的网络流量(network traffic)分配给私有架构和公共架构中的一者或多者。
用于在高性能计算环境中跨多个独立的层2子网(layer 2subnet)支持单个逻辑IP子网的系统和方法。一种方法可以在包括一个或多个微处理器的计算机处提供逻辑设备,该逻辑设备通过层3地址(layer 3address)进行寻址,其中该逻辑设备包括多个网络适配器以及多个交换机,每个网络适配器包括物理端口。该方法可以将多个交换机布置到多个分立的层2子网中。该方法可以在逻辑设备处提供映射表(mapping table)。
在所附的独立权利要求中阐述了本发明的特定方面,在从属权利要求中阐述了各种可选的实施例。
附图说明
图1示出了根据实施例的InfiniBand环境的图示。
图2示出了根据实施例的分区集群环境(partitioned cluster environment)的图示。
图3示出了根据实施例的在网络环境中的树形拓扑(tree topology)的图示。
图4示出了根据实施例的示例共享端口体系架构(shared port architecture)。
图5示出了根据实施例的示例vSwitch体系架构。
图6示出了根据实施例的示例vPort体系架构。
图7示出了根据实施例的具有预填充的LID的示例vSwitch体系架构。
图8示出了根据实施例的具有动态LID分配的示例vSwitch体系架构。
图9示出了根据实施例的具有vSwitch的示例vSwitch体系架构,该vSwitch具有动态LID分配和预填充的LID。
图10示出了根据实施例的示例多子网(multi-subnet)InfiniBand架构。
图11示出了根据实施例的在高性能计算环境中的两个子网之间的互连(interconnection)。
图12示出了根据实施例的在高性能计算环境中经由双端口虚拟路由器配置(dual-port virtual router configuration)的两个子网之间的互连。
图13示出了根据实施例的用于在高性能计算环境中支持双端口虚拟路由器的方法的流程图。
图14示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
图15示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
图16示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
图17示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
图18是用于高性能计算环境中的冗余独立网络的方法的流程图。
图19示出了根据实施例的用于在高性能计算环境中支持轨编号关联性(railnumber association)以进行正确连接的系统。
图20示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
图21示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
图22示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
图23是用于确定用于支持异构和不对称的双轨架构配置的系统内已供给或正在供给的工作负载的放置策略的方法的流程图。
图24是根据实施例的用于确定针对已供给的工作负载或正在供给的工作负载的架构类型的选择的方法的流程图。
图25是根据实施例的用于支持异构和不对称的双轨架构配置的方法的流程图。
图26图示了根据实施例的用于高性能计算环境中的多播发送重复(duplication)而不是复制(replication)的系统。
图27是用于高性能计算环境中的多播发送重复而不是复制的方法的流程图。
图28图示了根据实施例的用于支持链路聚合(LAG,link aggregation)的系统。
图29图示了根据实施例的用于支持多机箱链路聚合(MLAG,multi-chassis linkaggregation)的系统。
图30图示了根据实施例的用于在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的系统。
图31是根据实施例的用于在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的方法的流程图。
具体实施方式
在附图的各图中通过示例而非限制的方式图示了本教导,附图中相同的标号指示类似的元素。应当注意的是,在本公开中对“一个”或“一些”实施例的引用不一定是相同的实施例,并且这种引用意味着至少一个。虽然讨论了特定的实现方案,但是应当理解的是,特定实现方案仅仅是为了说明性目的而提供。相关领域的技术人员将认识到,在不脱离所要求保护的主题的范围和精神的情况下,可以使用其它部件和配置。
贯穿附图和具体实施方式可以使用共同的标号来指示相同的元素;因此,如果元素在其它地方进行了描述,那么在图中使用的标号可以或可以不在特定于该图的具体描述中引用。
根据实施例,本文描述了用于在高性能计算环境中支持异构和不对称的双轨架构配置的系统和方法。
根据实施例,本文描述了在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的系统和方法。
在一些实施例中,本教导的以下描述使用InfiniBand
在一些其它实施例中,以下描述使用RoCE(聚合以太网上的RDMA(远程直接存储器访问))。聚合以太网上的RDMA(RoCE)是一种标准协议,其使得RDMA能够在以太网上进行高效的数据传送,从而允许通过硬件RDMA引擎实现方案进行传输卸载(transport offload),并具有出色的性能。RoCE是InfiniBand贸易协会(IBTA)标准中定义的标准协议。RoCE利用UDP(用户数据报协议)封装,从而使其能够超越层3网络。RDMA是由InfiniBand互连技术本身使用的一项关键能力。InfiniBand和以太网RoCE两者共享公共的用户API,但具有不同的物理层和链路层。
根据实施例,虽然说明书的各部分包含在描述各种实施方式中对InfiniBand架构的引用,但是本领域的普通技术人员将容易理解,本文描述的各种实施例也可以在RoCE架构中实现。
为了满足当前时代(例如,Exascale时代)的云的需求,期望虚拟机能够利用低开销网络通信范例,诸如远程直接存储器访问(RDMA)。RDMA绕过OS堆栈并且直接与硬件通信,因此可以使用像单根I/O虚拟化(SR-IOV)网络适配器这样的直通技术。根据实施例,对于高性能无损互连网络中的适用性可以提供虚拟交换机(vSwitch)SR-IOV体系架构。由于网络重新配置时间对于使实时迁移(live mitigation)成为实用选项是至关重要的,因此,除了网络体系架构之外,还可以提供可伸缩的以及与拓扑无关(topology-agnostic)的动态重新配置机制。
根据实施例,并且除此之外,可以提供使用vSwitch的虚拟化环境的路由策略,并且可以提供用于网络拓扑(例如,胖树拓扑)的高效路由算法。动态重新配置机制可以被进一步微调以使胖树中施加的开销最小化。
根据本教导的实施例,虚拟化可以有益于云计算中的高效资源利用和弹性资源分配。实时迁移使得有可能通过以应用透明的方式在物理服务器之间移动虚拟机(VM)来优化资源使用。因此,虚拟化可以通过实时迁移来实现资源的整合、按需供给以及弹性。
InfiniBand
InfiniBand
InfiniBand
在子网内,可以使用交换机和点对点链路来连接主机。此外,可以存在主管理实体,即子网管理器(SM),其驻留在子网中的指定设备上。子网管理器负责配置、激活和维护IB子网。此外,子网管理器(SM)可以负责在IB架构中执行路由表计算。这里,例如,IB网络的路由的目的在于本地子网中所有源和目的地对之间的恰当的负载平衡。
通过子网管理接口,子网管理器与子网管理代理(SMA)交换被称为子网管理分组(SMP)的控制分组。子网管理代理驻留在每个IB子网设备上。通过使用SMP,子网管理器能够发现架构、配置端节点和交换机,并从SMA接收通知。
根据实施例,IB网络中的子网内路由可以基于存储在交换机中的线性转发表(LFT)。LFT由SM根据使用中的路由机制来计算。在子网中,使用本地标识符(LID)对端节点和交换机上的主机通道适配器(HCA)端口进行寻址。线性转发表(LFT)中的每个条目包括目的地LID(DLID)和输出端口。表中只支持每LID一个条目。当分组到达交换机时,通过在该交换机的转发表中查找DLID来确定其输出端口。路由是确定性的,因为分组在给定的源-目的地对(LID对)之间采取网络中的相同路径。
一般而言,除了主子网管理器之外的所有其它子网管理器都在备用模式下起作用以用于容错。然而,在主子网管理器发生故障的情况下,由备用子网管理器协商新的主子网管理器。主子网管理器还执行对子网的周期性扫描,以检测任何拓扑改变并相应地重新配置网络。
此外,可以使用本地标识符(LID)来寻址子网内的主机和交换机,并且可以将单个子网限制为49151个单播LID。除了作为在子网内有效的本地地址的LID之外,每个IB设备还可以具有64位全局唯一标识符(GUID)。GUID可以被用于形成作为IB层3(L3)地址的全局标识符(GID)。
SM可以在网络初始化时计算路由表(即,子网内每对节点之间的连接/路由)。此外,每当拓扑改变时,都可以更新路由表,以便确保连接性和最佳性能。在正常操作期间,SM可以执行对网络的周期性轻扫描以检查拓扑改变。如果在轻扫描期间发现改变,或者如果SM接收到发信号通知网络改变的信息(俘获(trap)),那么SM可以根据所发现的改变来重新配置网络。
例如,当网络拓扑改变时,诸如当链路断开时、当添加设备时或者当链路被移除时,SM可以重新配置网络。重新配置步骤可以包括在网络初始化期间执行的步骤。此外,重新配置可以具有限于其中发生网络改变的子网的局部范围。此外,用路由器对大型架构进行分段可以限制重新配置的范围。
图1中示出了示例InfiniBand架构,其示出了根据实施例的InfiniBand环境100的图示。在图1所示的示例中,节点A-E(101-105)使用InfiniBand架构120经由相应的主机通道适配器111-115进行通信。根据实施例,各个节点(例如,节点A-E(101-105))可以由各种物理设备来表示。根据实施例,各种节点(例如,节点A-E(101-105))可以由诸如虚拟机的各种虚拟设备来表示。
根据实施例,IB网络可以支持分区作为安全机制,以提供对共享网络架构的系统的逻辑组的隔离。架构中的节点上的每个HCA端口可以是一个或多个分区的成员。分区成员资格由集中式分区管理器管理,集中式分区管理器可以是SM的一部分。SM可以将每个端口上的分区成员资格信息配置为16位分区键(P_Key)的表。SM还可以用分区实施表来配置交换机和路由器端口,其中分区实施表包含与通过这些端口发送或接收数据流量的端节点相关联的P_Key信息。此外,在一般情况下,交换机端口的分区成员资格可以表示与在出口(朝链路)方向上经由该端口路由的LID间接相关联的所有成员资格的联合。
根据实施例,分区是端口的逻辑组,使得组的成员只能与同一逻辑组的其它成员通信。在主机通道适配器(HCA)和交换机处,可以使用分区成员资格信息对分组进行过滤以实施隔离。一旦分组到达传入端口,具有无效分区信息的分组就可以被丢弃。在分区的IB系统中,可以使用分区来创建租户集群。在分区实施就位的情况下,节点不能与属于不同租户集群的其它节点通信。以这种方式,即使存在受损或恶意的租户节点,系统的安全性也能够得到保证。
根据实施例,对于节点之间的通信,除管理队列对(QP0和QP1)以外,队列对(QP)和端到端上下文(EEC)可以被分配给特定分区。然后,可以将P_Key信息添加到所发送的每个IB传输分组。当分组到达HCA端口或交换机时,可以针对由SM配置的表来验证该分组的P_Key值。如果找到无效的P_Key值,那么立即丢弃该分组。以这种方式,只有在共享分区的端口之间才允许通信。
图2中示出了IB分区的示例,其示出了根据实施例的分区的集群环境的图示。在图2所示的示例中,节点A-E(101-105)使用InfiniBand架构120经由相应的主机通道适配器111-115进行通信。节点A-E被布置到分区中,即分区1(130)、分区2(140)和分区3(150)。分区1包括节点A 101和节点D 104。分区2包括节点A 101、节点B 102和节点C 103。分区3包括节点C 103和节点E 105。由于分区的布置,节点D 104和节点E 105不被允许通信,因为这些节点不共享分区。同时,例如,节点A 101和节点C 103被允许通信,因为这些节点都是分区2(140)的成员。
InfiniBand中的虚拟机
在过去的十年中,虚拟化高性能计算(HPC)环境的前景已得到相当大的提高,因为已通过硬件虚拟化支持实际上移除了CPU开销;存储器开销已通过虚拟化存储器管理单元被显著降低;已通过使用快速SAN存储装置或分布式联网文件系统减少了存储开销;并且已通过使用像单根输入/输出虚拟化(SR-IOV)这样的设备直通技术减少了网络I/O开销。现在,云有可能使用高性能互连解决方案来容纳虚拟HPC(vHPC)集群并提供必要的性能。
然而,当与诸如InfiniBand(IB)的无损网络耦合时,某些云功能(诸如虚拟机(VM)的实时迁移)仍然是个问题,这是由于在这些解决方案中使用的复杂的寻址和路由方案。IB是提供高带宽和低延迟的互连网络技术,因此非常适合HPC和其它通信密集型工作负载。
用于将IB设备连接到VM的传统方法是通过利用具有直接分配的SR-IOV。然而,使用SR-IOV来实现被分配有IB主机通道适配器(HCA)的VM的实时迁移已被证明是具有挑战性的。每个IB连接的节点具有三个不同的地址:LID、GUID和GID。当发生实时迁移时,这些地址中的一个或多个改变。与迁移中的VM(VM-in-migration)通信的其它节点会丢失连接性。当发生这种情况时,可以通过向IB子网管理器(SM)发送子网管理(SA)路径记录查询来定位要重新连接到的虚拟机的新地址,来尝试更新丢失的连接。
IB使用三种不同类型的地址。第一种类型的地址是16位本地标识符(LID)。SM向每个HCA端口和每个交换机分配至少一个唯一的LID。LID用于在子网内路由流量。由于LID为16位长,因此可以做出65536个唯一的地址组合,其中只有49151个(0x0001-0xBFFF)可以用作单播地址。因此,可用的单播地址的数量限定了IB子网的最大尺寸。第二种类型的地址是由制造商分配给每个设备(例如,HCA和交换机)和每个HCA端口的64位全局唯一标识符(GUID)。SM可以向HCA端口分配附加的子网唯一GUID,其在使用SR-IOV时是有用的。第三种类型的地址是128位全局标识符(GID)。GID是有效的IPv6单播地址,并且向每个HCA端口分配至少一个。GID是通过组合由架构管理员分配的全局唯一64位前缀和每个HCA端口的GUID地址而形成的。
根据实施例,基于IB的HPC系统中的一些采用胖树拓扑来利用胖树提供的有用属性。这些属性包括完全的二分带宽和固有的容错性,这是由于每个源目的地对之间有多个路径可用。胖树背后的最初想法是,当树朝着拓扑的根移动时,在节点之间采用具有更多可用带宽的较胖链路。较胖链路可以帮助避免上层交换机中的拥塞并且维持二分带宽。
图3示出了根据实施例的网络环境中的树形拓扑的图示。如图3所示,一个或多个端节点201-204可以在网络架构200中被连接。网络架构200可以基于包括多个叶子交换机211-214和多个主干交换机或根交换机231-234的胖树拓扑。此外,网络架构200可以包括一个或多个中间交换机,诸如交换机221-224。
同样如图3所示,端节点201-204中的每个端节点可以是多宿主节点,即,通过多个端口连接到网络架构200的两个或更多个部分的单个节点。例如,节点201可以包括端口H1和H2,节点202可以包括端口H3和H4,节点203可以包括端口H5和H6,并且节点204可以包括端口H7和H8。
此外,每个交换机可以具有多个交换机端口。例如,根交换机231可以具有交换机端口1-2,根交换机232可以具有交换机端口3-4,根交换机233可以具有交换机端口5-6,并且根交换机234可以具有交换机端口7-8。
根据实施例,胖树路由机制是用于基于IB的胖树拓扑的最流行的路由算法之一。胖树路由机制也在OFED(开放架构企业分发——用于构建和部署基于IB的应用的标准软件栈)子网管理器OpenSM中实现。
胖树路由机制的目的在于生成在网络架构中跨链路均匀散布最短路径路由的LFT。该机制按索引次序遍历架构并将端节点的目标LID(以及因此对应的路由)分配给每个交换机端口。对于连接到相同叶子交换机的端节点,索引次序可以取决于该端节点连接到的交换机端口(即端口编号顺序)。对于每个端口,该机制可以维护端口使用计数器,并且可以在每次添加新路由时使用这个端口使用计数器来选择最少使用的端口。
根据实施例,在分区的子网中,不允许不是共同分区的成员的节点进行通信。在实践中,这意味着由胖树路由算法分配的一些路由没有被用于用户流量。当胖树路由机制以与它为其它功能路径所做的那样相同的方式为这些路由生成LFT时,会出现问题。由于节点是按索引的次序进行路由的,因此这种行为会导致链路上的平衡恶化。由于路由可以在分区不知情(oblivious)的情况下执行,因此,一般而言,胖树路由的子网提供分区间不好的隔离。
根据实施例,胖树是可以利用可用网络资源进行伸缩的分层网络拓扑。而且,使用放置在不同级别层次上的商用交换机容易构建胖树。胖树的不同变体通常是可用的,包括k元n级树(k-ary-n-tree)、扩展的广义胖树(XGFT)、平行端口广义胖树(PGFT)和现实生活胖树(RLFT)。
k元n级树是具有k
输入/输出(I/O)虚拟化
根据实施例,I/O虚拟化(IOV)可以通过允许虚拟机(VM)访问底层物理资源来提供I/O的可用性。存储流量和服务器间通信的组合施加可能压倒单个服务器的I/O资源的增加的负载,从而导致处理器在等待数据时的积压和空闲处理器。随着I/O请求数量的增加,IOV可以提供可用性;并且可以提高(虚拟化的)I/O资源的性能、可伸缩性和灵活性,以匹配现代CPU虚拟化中所看到的性能水平。
根据实施例,IOV是期望的,因为它可以允许共享I/O资源并且提供对来自VM的资源的受保护的访问。IOV将暴露于VM的逻辑设备与其物理实现方案解耦。当前,可以存在不同类型的IOV技术,诸如仿真、半虚拟化、直接分配(DA)和单根I/O虚拟化(SR-IOV)。
根据实施例,一种类型的IOV技术是软件仿真。软件仿真可以允许经解耦的前端/后端软件体系架构。前端可以是放置在VM中的、与由管理程序实现的后端进行通信以提供I/O访问的设备驱动器。物理设备共享比率高,并且VM的实时迁移可能只需几毫秒的网络停机时间。然而,软件仿真引入了附加的、不期望的计算开销。
根据实施例,另一种类型的IOV技术是直接设备分配。直接设备分配涉及将I/O设备耦合到VM,其中在VM之间没有设备共享。直接分配或设备直通以最小的开销提供接近本地(near to native)的性能。物理设备绕过管理程序并且直接附连到VM。然而,这种直接设备分配的缺点是有限的可伸缩性,因为在虚拟机之间不存在共享—一个物理网卡与一个VM耦合。
根据实施例,单根IOV(SR-IOV)可以允许物理设备通过硬件虚拟化表现为同一设备的多个独立的轻量级实例。这些实例可以被分配给VM作为直通设备,并作为虚拟功能(VF)被访问。管理程序通过唯一的(每设备的)、全特征(fully featured)物理功能(PF)来访问设备。SR-IOV使纯直接分配的可伸缩性问题变得容易。然而,SR-IOV呈现的问题是它可能会影响VM迁移。在这些IOV技术中,SR-IOV可以扩展PCI Express(PCIe)规范,这意味着允许从多个VM直接访问单个物理设备同时维持接近本地的性能。因此,SR-IOV可以提供良好的性能和可伸缩性。
SR-IOV允许PCIe设备通过向每个顾客分配一个虚拟设备来暴露可以在多个顾客之间共享的多个虚拟设备。每个SR-IOV设备具有至少一个物理功能(PF)和一个或多个相关联的虚拟功能(VF)。PF是由虚拟机监视器(VMM)或管理程序控制的正常PCIe功能,而VF是轻量级的PCIe功能。每个VF都具有其自己的基地址(BAR),并被分配有唯一的请求者ID,该唯一的请求者ID使得I/O存储器管理单元(IOMMU)能够区分来自/去往不同VF的流量流。IOMMU还在PF和VF之间应用存储器和中断转换。
然而,令人遗憾的是,对于在其中数据中心优化期望虚拟机的透明实时迁移的情况,直接设备分配技术对云提供商造成障碍。实时迁移的实质是将VM的存储器内容复制到远程管理程序。然后在源管理程序处暂停VM,并且在目的地处恢复VM的操作。当使用软件仿真方法时,网络接口是虚拟的,因此其内部状态被存储到存储器中并且也被复制。因此,可以使停机时间下降到几毫秒。
然而,当使用诸如SR-IOV的直接设备分配技术时,迁移变得更加困难。在这种情况下,网络接口的完整内部状态不能被复制,因为它与硬件绑定。作为替代,分配给VM的SR-IOV VF被分离(detach),实时迁移将运行,并且新的VF将在目的地处被附连。在InfiniBand和SR-IOV的情况下,该过程会引入在秒的数量级上的停机时间。而且,在SR-IOV共享端口模型中,在迁移之后,VM的地址将改变,从而导致SM中的附加开销以及对底层网络架构的性能的负面影响。
可以存在不同类型的SR-IOV模型,例如,共享端口模型、虚拟交换机模型和虚拟端口模型。
图4示出了根据实施例的示例性共享端口体系架构。如图所示,主机300(例如,主机通道适配器)可以与管理程序310交互,管理程序310可以将各个虚拟功能330、340、350分配给多个虚拟机。同样,物理功能可以由管理程序310处置。
根据实施例,当使用诸如图4所描绘的共享端口体系架构时,主机(例如,HCA)在网络中表现为具有单个共享LID和在物理功能320与虚拟功能330、350、350之间的共享队列对(QP)空间的单个端口。然而,每个功能(即,物理功能和虚拟功能)可以具有其自己的GID。
如图4所示,根据实施例,可以将不同的GID分配给虚拟功能和物理功能,并且特殊队列对QP0和QP1(即,用于InfiniBand管理分组的专用队列对)由物理功能拥有。这些QP也被暴露给VF,但是VF不被允许使用QP0(从VF到QP0的所有SMP都被丢弃),并且QP1可以充当由PF拥有的实际QP1的代理。
根据实施例,共享端口体系架构可以允许不受(通过被分配给虚拟功能而附连到网络的)VM的数量限制的高度可伸缩的数据中心,因为LID空间仅被网络中的物理机器和交换机消耗。
然而,共享端口体系架构的缺点是无法提供透明的实时迁移,从而阻碍了灵活VM放置的可能性。由于每个LID与具体管理程序相关联,并且在驻留于该管理程序上的所有VM之间共享,因此迁移的VM(即,迁移到目的地管理程序的虚拟机)必须将其LID改变为目的地管理程序的LID。此外,作为受限的QP0访问的结果,子网管理器不能在VM内部运行。
图5示出了根据实施例的示例性vSwitch体系架构。如图所示,主机400(例如,主机通道适配器)可以与管理程序410交互,管理程序410可以将各个虚拟功能430、440、450分配给多个虚拟机。同样,物理功能可以由管理程序410处置。虚拟交换机415也可以由管理程序401处置。
根据实施例,在vSwitch体系架构中,每个虚拟功能430、440、450是完整的虚拟主机通道适配器(vHCA),这意味着分配给VF的VM被分配完整的IB地址集合(例如,GID、GUID、LID)以及硬件中的专用QP空间。对于网络的其余部分和SM,HCA 400看起来像经由虚拟交换机415、具有连接到它的附加节点的交换机。管理程序410可以使用PF 420,并且(附连到虚拟功能的)VM使用VF。
根据实施例,vSwitch体系架构提供透明的虚拟化。然而,由于每个虚拟功能都被分配唯一的LID,因此可用LID的数量被迅速消耗。同样,在使用许多LID地址(即,每个物理功能和每个虚拟功能都有一个LID地址)的情况下,必须由SM计算更多的通信路径,并且必须将更多的子网管理分组(SMP)发送到交换机以便更新其LFT。例如,通信路径的计算在大型网络中可能花费几分钟。因为LID空间限于49151个单播LID,并且由于每个VM(经由VF)、物理节点和交换机各自占用一个LID,所以网络中的物理节点和交换机的数量限制了活动VM的数量,并且反之亦然。
图6示出了根据实施例的示例性vPort概念。如图所示,主机300(例如,主机通道适配器)可以与管理程序410交互,管理程序410可以将各个虚拟功能330、340、350分配给多个虚拟机。同样,物理功能可以由管理程序310来处置。
根据实施例,vPort概念被松散地定义以便赋予供应商实现的自由(例如,定义不规定实现方案必须是特定于SRIOV的),并且vPort的目标是使在子网中处置VM的方式标准化。利用vPort概念,可以定义可在空间和性能域二者中都更可伸缩的、类似SR-IOV共享端口的体系架构和类似vSwitch的体系架构二者或这二者的组合。vPort支持可选的LID,并且与共享端口不同,即使vPort不使用专用LID,SM也知道子网中可用的所有vPort。
根据实施例,本公开提供了用于提供具有预填充的LID的vSwitch体系架构的系统和方法。
图7示出了根据实施例的具有预填充的LID的示例性vSwitch体系架构。如图所示,多个交换机501-504可以在网络交换环境600(例如,IB子网)内提供架构(诸如InfiniBand架构)的成员之间的通信。该架构可以包括多个硬件设备,诸如主机通道适配器510、520、530。主机通道适配器510、520、530中的每个又可以分别与管理程序511、521和531交互。每个管理程序又可以与和其交互的主机通道适配器结合设立多个虚拟功能514、515、516、524、525、526、534、535、536并将这多个虚拟功能分配给多个虚拟机。例如,虚拟机1 550可以由管理程序511分配给虚拟功能1 514。管理程序511可以附加地将虚拟机2 551分配给虚拟功能2 515,并且将虚拟机3 552分配给虚拟功能3 516。管理程序531又可以将虚拟机4553分配给虚拟功能1 534。在主机通道适配器中的每个主机通道适配器上,管理程序可以通过全特征物理功能513、523、533来访问主机通道适配器。
根据实施例,交换机501-504中的每个交换机可以包括多个端口(未示出),这些端口在设置线性转发表中被使用以便导引网络交换环境600内的流量。
根据实施例,虚拟交换机512、522和532可以由它们相应的管理程序511、521、531处置。在这样的vSwitch体系架构中,每个虚拟功能是完整的虚拟主机通道适配器(vHCA),这意味着分配给VF的VM被分配完整的IB地址(例如,GID、GUID、LID)集合以及硬件中的专用QP空间。对于网络的其余部分和SM(未示出),HCA 510、520和530看起来像经由虚拟交换机的、具有连接到它们的附加节点的交换机。
根据实施例,本公开提供了用于提供具有预填充的LID的vSwitch体系架构的系统和方法。参考图7,LID被预填充到各个物理功能513、523、533以及虚拟功能514-516、524-526、534-536(甚至那些当前未与活动虚拟机相关联的虚拟功能)。例如,物理功能513被预填充有LID 1,而虚拟功能1 534被预填充有LID 10。当网络被引导(root)时,LID被预填充在启用SR-IOV vSwitch的子网中。即使并非所有的VF都被网络中的VM占用时,所填充的VF也被分配有LID,如图7所示。
根据实施例,非常类似于物理主机通道适配器可以具有多于一个的端口(为了冗余,两个端口是常见的),虚拟HCA也可以用两个端口来表示,并且经由一个、两个或更多个虚拟交换机连接到外部IB子网。
根据实施例,在具有预填充LID的vSwitch体系架构中,每个管理程序可以通过PF为自己消耗一个LID,并为每个附加的VF消耗再多一个LID。在IB子网中的所有管理程序中可用的所有VF的总和给出了被允许在该子网中运行的VM的最大量。例如,在子网中每管理程序具有16个虚拟功能的IB子网中,那么每个管理程序在该子网中消耗17个LID(16个虚拟功能中的每个虚拟功能一个LID加上用于物理功能的一个LID)。在这种IB子网中,单个子网的理论管理程序极限取决于可用单播LID的数量并且是:2891个(49151个可用LID除以每管理程序17个LID),并且VM的总数(即,极限)是46256个(2891个管理程序乘以每管理程序16个VF)。(实际上,这些数字在实际中更小,因为IB子网中的每个交换机、路由器或专用SM节点也消耗LID)。注意的是,vSwitch不需要占用附加的LID,因为它可以与PF共享LID。
根据实施例,在具有预填充LID的vSwitch体系架构中,当网络第一次被引导时,为所有LID计算通信路径。当需要启动新的VM时,系统不必在子网中添加新的LID,否则该动作将导致网络完整的重新配置,包括路径重新计算,这是最耗时的部分。作为替代,在管理程序之一中定位用于VM的可用端口(即,可用的虚拟功能),并且将该虚拟机附连到该可用的虚拟功能。
根据实施例,具有预填充LID的vSwitch体系架构还允许计算和使用不同路径以到达由同一管理程序托管的不同VM的能力。本质上,这允许这样的子网和网络使用类似LID掩码控制(LMC)的特征提供朝向一个物理机器的替代路径,而不受LMC的限制(其要求LID必须是顺序的)约束。当需要迁移VM并将其相关联的LID携带到目的地时,自由使用非顺序的LID是尤其有用的。
根据实施例,以及以上示出的具有预填充LID的vSwitch体系架构的益处,可以考虑某些注意事项。例如,由于LID在网络被引导时被预填充在启用SR-IOV vSwitch的子网中,所以(例如在启动时的)初始路径计算会比不预填充LID花费更长的时间。
根据实施例,本公开提供了用于提供具有动态LID分配的vSwitch体系架构的系统和方法。
图8示出了根据实施例的具有动态LID分配的示例性vSwitch体系架构。如图所示,多个交换机501-504可以在网络交换环境700(例如,IB子网)内提供架构(诸如InfiniBand架构)的成员之间的通信。该架构可以包括多个硬件设备,诸如主机通道适配器510、520、530。主机通道适配器510、520、530中的每个主机通道适配器又可以分别与管理程序511、521、531交互。每个管理程序又可以与和其交互的主机通道适配器结合来设立多个虚拟功能514、515、516、524、525、526、534、535、536并将这多个虚拟功能分配给多个虚拟机。例如,虚拟机1 550可以由管理程序511分配给虚拟功能1514。管理程序511可以附加地将虚拟机2551分配给虚拟功能2 515,并且将虚拟机3 552分配给虚拟功能3 516。管理程序531又可以将虚拟机4 553分配给虚拟功能1 534。在主机通道适配器中的每一个上,管理程序可以通过全特征物理功能513、523、533来访问主机通道适配器。
根据实施例,交换机501-504中的每一个可以包括多个端口(未示出),这些端口在设置线性转发表中被使用以便导引网络交换环境700内的流量。
根据实施例,虚拟交换机512、522和532可以由它们相应的管理程序511、521、531处置。在这样的vSwitch体系架构中,每个虚拟功能是完整的虚拟主机通道适配器(vHCA),这意味着分配给VF的VM被分配完整的IB地址(例如,GID、GUID、LID)集合以及硬件中的专用QP空间。对于网络的其余部分和SM(未示出),HCA 510、520和530看起来像经由虚拟交换机的、具有连接到它们的附加节点的交换机。
根据实施例,本公开提供了用于提供具有动态LID分配的vSwitch体系架构的系统和方法。参考图8,LID被动态分配给各个物理功能513、523、533,其中物理功能513接收LID1、物理功能523接收LID 2并且物理功能533接收LID 3。与活动虚拟机相关联的这些虚拟功能也可以接收动态分配的LID。例如,由于虚拟机1550是活动的并且与虚拟功能1 514相关联,所以虚拟功能514可以被分配LID 5。同样地,虚拟功能2 515、虚拟功能3 516和虚拟功能1 534各自与活动的虚拟功能相关联。由此,这些虚拟功能被分配LID,其中LID 7被分配给虚拟功能2 515、LID 11被分配给虚拟功能3 516、并且LID 9被分配给虚拟功能1 534。与具有预填充LID的vSwitch不同,那些当前未与活动虚拟机相关联的虚拟功能不接收LID分配。
根据实施例,利用动态LID分配,可以实质上减少初始路径计算。当网络第一次被引导并且不存在VM时,那么可以使用相对较少数量的LID来用于初始路径计算和LFT分发。
根据实施例,非常类似于物理主机通道适配器可以具有多于一个的端口(为了冗余两个端口是常见的),虚拟HCA也可以用两个端口来表示,并且经由一个、两个或更多个虚拟交换机连接到外部IB子网。
根据实施例,当在利用具有动态LID分配的vSwitch的系统中创建新的VM时,找到空闲的VM槽以便决定在哪个管理程序上引导新添加的VM,并且也找到未使用的唯一的单播LID。然而,在网络和交换机的LFT中没有用于处置新添加的LID的已知路径。在其中每分钟可以引导几个VM的动态环境中,为了处置新添加的VM而计算新的一组路径是非期望的。在大型IB子网中,计算新的一组路由会花费几分钟,并且每次引导新的VM时这个过程都将不得不重复。
有利地,根据实施例,由于管理程序中的所有VF与PF共享相同的上行链路,所以不需要计算新的一组路由。只需要遍历网络中所有物理交换机的LFT、将转发端口从属于管理程序(VM被创建在该管理程序处)的PF的LID条目复制到新添加的LID、以及发送单个SMP以更新特定交换机的对应LFT块。因此,该系统和方法避免了计算新的一组路由的需要。
根据实施例,在具有动态LID分配体系架构的vSwitch中分配的LID不必是顺序的。当将具有预填充LID的vSwitch中的每个管理程序上的VM上所分配的LID与具有动态LID分配的vSwitch进行比较时,应当注意的是,在动态LID分配体系架构中分配的LID是非顺序的,而被预填充的那些LID本质上是顺序的。在vSwitch动态LID分配体系架构中,当创建新的VM时,在该VM的整个寿命中使用下一个可用的LID。相反,在具有预填充LID的vSwitch中,每个VM继承已经分配给对应VF的LID,并且在没有实时迁移的网络中,连续地附连到给定VF的VM获得相同的LID。
根据实施例,具有动态LID分配体系架构的vSwitch可以以一些附加的网络和运行时SM开销为代价,解决具有预填充LID体系架构模型的vSwitch的缺点。每次创建VM时,用与所创建的VM相关联的新添加的LID来更新子网中的物理交换机的LFT。对于这个操作,需要发送每交换机一个子网管理分组(SMP)。因为每个VM正在使用与其主机管理程序相同的路径,所以类似LMC的功能也不可用。然而,对所有管理程序中存在的VF的总量没有限制,并且VF的数量可以超过单播LID极限的数量。当然,如果是这种情况,那么并不是所有VF都被允许同时附连到活动VM上,然而,当操作接近单播LID极限时,具有更多的备用管理程序和VF增加了分段网络的优化和灾难恢复的灵活性。
图9示出了根据实施例的具有vSwitch的示例性vSwitch体系架构,其中vSwitch具有动态LID分配和预填充LID。如图所示,多个交换机501-504可以在网络交换环境800(例如,IB子网)内提供架构(诸如InfiniBand架构)的成员之间的通信。架构可以包括多个硬件设备,诸如主机通道适配器510、520、530。主机通道适配器510、520、530中的每一个又可以分别与管理程序511、521和531交互。每个管理程序又可以与和其交互的主机通道适配器结合来设立多个虚拟功能514、515、516、524、525、526、534、535、536并将这多个虚拟功能分配给多个虚拟机。例如,虚拟机1 550可以由管理程序511分配给虚拟功能1 514。管理程序511可以附加地将虚拟机2 551分配给虚拟功能2 515。管理程序521可以将虚拟机3 552分配给虚拟功能3 526。管理程序531又可以将虚拟机4 553分配给虚拟功能2 535。在主机通道适配器中的每一个上,管理程序可以通过全特征物理功能513、523、533来访问主机通道适配器。
根据实施例,交换机501-504中的每一个可以包括多个端口(未示出),这些端口在设置线性转发表中被使用以便导引网络交换环境800内的流量。
根据实施例,虚拟交换机512、522和532可以由它们相应的管理程序511、521、531处置。在这样的vSwitch体系架构中,每个虚拟功能是完整的虚拟主机通道适配器(vHCA),这意味着分配给VF的VM被分配完整的IB地址(例如,GID、GUID、LID)集合以及硬件中的专用QP空间。对于网络的其余部分和SM(未示出),HCA 510、520和530看起来像经由虚拟交换机的、具有连接到它们的附加节点的交换机。
根据实施例,本公开提供了用于提供具有动态LID分配和预填充LID的混合vSwitch体系架构的系统和方法。参考图9,管理程序511可以被布置为带有具有预填充LID体系架构的vSwitch,而管理程序521可以被布置为带有具有预填充LID和动态LID分配的vSwitch。管理程序531可以被布置为带有具有动态LID分配的vSwitch。因此,物理功能513和虚拟功能514-516使其LID被预填充(即,即使那些未附连到活动虚拟机的虚拟功能也被分配LID)。物理功能523和虚拟功能1 524可以使其LID被预填充,而虚拟功能2 525和虚拟功能3 526使其LID被动态分配(即,虚拟功能2 525可用于动态LID分配,并且虚拟功能3526由于虚拟机3 552被附连而具有动态分配的LID 11)。最后,与管理程序3 531相关联的功能(物理功能和虚拟功能)可以使其LID被动态分配。这使得虚拟功能1 534和虚拟功能3536可用于动态LID分配,而虚拟功能2 535由于虚拟机4 553被附连到那里所以具有动态分配的LID 9。
根据诸如图9所示的在其中(在任何给定管理程序内独立地或组合地)利用具有预填充LID的vSwitch和具有动态LID分配的vSwitch两者的实施例,每主机通道适配器的预填充LID的数量可以由架构管理员定义,并且可以在0<=预填充的VF<=(每主机通道适配器的)总VF的范围内,并且,可用于动态LID分配的VF可以通过从(每主机通道适配器)VF的总数量减去预填充VF的数量而得出。
根据实施例,非常类似于物理主机通道适配器可以具有多于一个的端口(为了冗余两个端口是常见的),虚拟HCA也可以用两个端口来表示,并且经由一个、两个或更多个虚拟交换机连接到外部IB子网。
根据实施例,除了在单个子网内提供InfiniBand架构之外,本公开的实施例还可以提供跨两个或更多个子网的InfiniBand架构。
图10示出了根据实施例的示例性多子网InfiniBand架构。如图所示,在子网A1000内,多个交换机1001-1004可以在子网A 1000(例如,IB子网)内提供架构(诸如InfiniBand架构)的成员之间的通信。该架构可以包括多个硬件设备,诸如例如通道适配器1010。主机通道适配器1010又可以与管理程序1011交互。该管理程序又可以与和其交互的主机通道适配器结合来设立多个虚拟功能1014。该管理程序可以附加地将虚拟机分配给虚拟功能中的每一个,诸如虚拟机1 1015被分配给虚拟功能1 1014。在主机通道适配器中的每一个上,管理程序可以通过全特征物理功能(诸如物理功能1013)来访问其相关联的主机通道适配器。在子网B 1040内,多个交换机1021-1024可以在子网B 1040(例如,IB子网)内提供架构(诸如InfiniBand架构)的成员之间的通信。该架构可以包括多个硬件设备,诸如例如通道适配器1030。主机通道适配器1030又可以与管理程序1031交互。该管理程序又可以与和其交互的主机通道适配器结合来设立多个虚拟功能1034。管理程序可以附加地将虚拟机分配给虚拟功能中的每一个,诸如虚拟机2 1035被分配给虚拟功能2 1034。在主机通道适配器中的每一个上,管理程序可以通过全特征物理功能(诸如物理功能1033)访问其相关联的主机通道适配器。应当注意的是,虽然在每个子网(即,子网A和子网B)内仅示出一个主机通道适配器,但是应该理解的是,每个子网内可以包括多个主机通道适配器及其对应的部件。
根据实施例,主机通道适配器中的每一个可以附加地与虚拟交换机(诸如虚拟交换机1012和虚拟交换机1032)相关联,并且每个HCA可以被设立为具有如上所述的不同的体系架构模型。虽然图10内的两个子网都被显示为使用具有预填充LID体系架构模型的vSwitch,但这并不意味着暗示所有此类子网配置都会遵循相似的体系架构模型。
根据实施例,每个子网内的至少一个交换机可以与路由器相关联,诸如子网A1000内的交换机1002与路由器1005相关联,并且子网B 1040内的交换机1021与路由器1006相关联。
根据实施例,至少一个设备(例如,交换机、节点等)可以与架构管理器(未示出)相关联。架构管理器可以被用于例如发现子网间架构拓扑、创建架构简档(例如,虚拟机架构简档)、构建与虚拟机相关的数据库对象,这些数据库对象形成用于构建虚拟机架构简档的基础。此外,架构管理器可以针对哪些子网被允许经由哪些路由器端口使用哪些分区编号进行通信来定义合法的子网间连接性。
根据实施例,当始发源(诸如子网A内的虚拟机1)处的流量被寻址到不同子网中的目的地(诸如子网B内的虚拟机2)时,该流量可以被寻址到子网A内的路由器,即路由器1005,路由器1005然后可以经由它与路由器1006的链路将该流量传递到子网B。
根据实施例,双端口路由器抽象(dual port router abstraction)可以提供一种简单的方式用于使得能够基于如下的交换机硬件实现方案(switch hardwareimplementation)来定义子网到子网的路由器功能,该交换机硬件实现方案除了执行正常的基于LRH(本地路由报头)的交换之外还具有进行GRH(全局路由报头)到LRH(本地路由报头)转换能力。
根据实施例,虚拟双端口路由器可以逻辑地连接在对应交换机端口的外部。这种虚拟双端口路由器可以向标准管理实体(诸如子网管理器)提供符合InfiniBand规范的视图。
根据实施例,双端口路由器模型意味着可以以如下方式连接不同的子网,即,其中每个子网完全控制到子网的入口路径中的地址映射以及分组的转发,并且不影响任一不正确地连接的子网内的路由和逻辑连接性。
根据实施例,在涉及不正确地连接的架构的情况下,使用虚拟双端口路由器抽象还可以允许管理实体(诸如子网管理器和IB诊断软件)在存在与远程子网的非预期的物理连接性时正确地表现。
图11示出了根据实施例的在高性能计算环境中的两个子网之间的互连。在利用虚拟双端口路由器进行配置之前,子网A 1101中的交换机1120可以通过交换机1120的交换机端口1121经由物理连接1110以及经由交换机1130的交换机端口1131连接到子网B 1102中的交换机1130。在这样的实施例中,每个交换机端口1121和1131即可以充当交换机端口和路由器端口二者。
根据实施例,这种配置的问题在于管理实体(诸如InfiniBand子网中的子网管理器)不能区分既是交换机端口又是路由器端口的物理端口。在这种情况下,SM可以将该交换机端口视为具有连接到该交换机端口的路由器端口。然而,如果该交换机端口经由例如物理链路连接到具有另一个子网管理器的另一个子网,则子网管理器可以能够在该物理链路上发送发现消息。然而,这样的发现消息在另一个子网上不能被允许。
图12示出了根据实施例的在高性能计算环境中经由双端口虚拟路由器配置的两个子网之间的互连。
根据实施例,在配置之后,可以提供双端口虚拟路由器配置,使得子网管理器看到正确的端节点,从而表明子网管理器所负责的子网的末端。
根据实施例,在子网A 1201中的交换机1220处,交换机端口可以经由虚拟链路1223而连接(即,逻辑上连接)到虚拟路由器1210中的路由器端口1211。虚拟路由器1210(例如,双端口虚拟路由器)(当其在实施例中被示出为在交换机1220的外部时,其逻辑上可以被包含在交换机1220内)还可以包括第二路由器端口:路由器端口II 1212。根据实施例,可以具有两个端的物理链路1203可以经由路由器端口II 1212和包含在子网B 1202中的虚拟路由器1230中的路由器端口II 1232,经由物理链路的第一端将子网A 1201经由物理链路的第二端与子网B 1202连接。虚拟路由器1230可以附加地包括路由器端口1231,路由器端口1231可以经由虚拟链路1233连接(即,逻辑上连接)到交换机1240上的交换机端口1241。
根据实施例,子网A上的子网管理器(未示出)可以检测虚拟路由器1210上的路由器端口1211,作为该子网的由该子网管理器控制的端点。双端口虚拟路由器抽象可以允许子网A上的子网管理器以通常的方式(例如,如按照InifiniBand规范所定义的方式)处理子网A。在子网管理代理级别,可以提供双端口虚拟路由器抽象以使得SM看到正常的交换机端口,并且然后在SMA级别,看到如下抽象:存在连接到该交换机端口的另一个端口,并且这个端口是双端口虚拟路由器上的路由器端口。在本地SM中,可以继续使用常规的架构拓扑(SM将端口视为拓扑中的标准交换机端口),并且因此SM将路由器端口视为末端端口(endport)。在也被配置为两个不同子网中的路由器端口的两个交换机端口之间可以进行物理连接。
根据实施例,双端口虚拟路由器还可以解决物理链路可能被错误地连接到相同子网中的某个其它交换机端口或者连接到不旨在提供到另一个子网的连接的交换机端口的问题。因此,本文描述的方法和系统还提供了关于子网外部的内容的表示。
根据实施例,在子网(诸如子网A)内,本地SM确定交换机端口,并且然后确定连接到该交换机端口的路由器端口(例如,路由器端口1211经由虚拟链路1223连接到交换机端口1221)。由于SM将路由器端口1211视为SM管理的子网的末端,因此SM不能将发现消息和/或管理消息发送超过这个点(例如,发送到路由器端口II 1212)。
根据实施例,上述双端口虚拟路由器提供的益处是双端口虚拟路由器抽象完全由双端口虚拟路由器所属的子网内的管理实体(例如,SM或SMA)管理。通过允许仅在本地侧进行管理,系统不必提供外部独立的管理实体。即,子网到子网连接的每一侧都可以负责配置其自己的双端口虚拟路由器。
根据实施例,在被寻址到远程目的地(即,在本地子网外部)的分组(诸如SMP)到达未经由如上所述的双端口虚拟路由器配置的本地目标端口的情况下,那么该本地端口可以返回指定它不是路由器端口的消息。
本教导的许多特征可以在硬件、软件、固件或其组合中、利用硬件、软件、固件或其组合、或者在硬件、软件、固件或其组合帮助下执行。因此,本教导的特征可以使用(例如,包括一个或多个处理器的)处理系统来实现。
图13示出了根据实施例的用于支持高性能计算环境中的双端口虚拟路由器的方法。在步骤1310处,该方法可以在包括一个或多个微处理器的一个或多个计算机处提供第一子网,第一子网包括:多个交换机,该多个交换机至少包括叶子交换机,其中该多个交换机中的每个交换机包括多个交换机端口;多个主机通道适配器,每个主机通道适配器包括至少一个主机通道适配器端口;多个端节点,其中端节点中的每个端节点与多个主机通道适配器中的至少一个主机通道适配器相关联;以及子网管理器,该子网管理器在多个交换机和多个主机通道适配器中的一个上运行。
在步骤1320处,该方法可以将多个交换机中的交换机上的多个交换机端口中的交换机端口配置为路由器端口。
在步骤1330处,该方法可以将被配置为路由器端口的交换机端口逻辑地连接到虚拟路由器,该虚拟路由器包括至少两个虚拟路由器端口。
冗余的完全独立和半独立网络
根据实施例,关键任务系统应该在预期的响应时间内和为系统定义的总体性能约束下始终正确地工作并向正确的客户端提供具有正确数据的相关服务。
根据实施例,对于实现为分布式计算机集群的系统,这还意味着集群中所需的计算机集合之间的通信必须始终是正常操作的(operational)。
根据实施例,网络通信系统正常操作的理想前提是,就正确的部件和连接器经由正确的线缆连接,并且所有涉及的部件以正确的方式被配置而言,诸如主机适配器和交换机的部件之间的所有物理连接都是正确的。
然而,根据实施例,由于硬件部件可能发生故障,并且操作员可能并且确实会犯错,因此在正常情况下,要求没有通信仅依赖于任何单个故障点。如果发生故障或错误而无法经由一个部件和通信路径进行通信,那么至关重要的是,必须检测到这一点,并立即或至少在未正常操作的通信路径对系统操作或响应时间有任何重大影响之前将通信故障转移到替代的冗余通信路径。
此外,根据实施例,每当出现故障使得如果在发生第二故障的情况下将使部分或全部当前通信易受攻击,那么重要的是,应尽快进行相关的维修操作和/或可以使用附加的备份解决方案来防止服务完全丧失。
根据实施例,另一方面是由于系统和应用软件很少没有出错,并且随着时间的推移常常需要增强系统特征,因此重要的是可以升级系统中的各种软件部件而不会造成任何中断。在分布式集群系统中,这通常意味着“滚动升级(rolling upgrade)”模型,其中冗余部件按严格顺序进行升级,使得系统始终以所需的部件集合和所需的通信完全正常操作。
此外,根据实施例,为了增强系统的能力和/或扩展系统的能力,就附加硬件部件和/或用功能更强的硬件部件替换现有硬件部件而言,可以进行物理改变。这样的升级也可能意味着系统中有新的软件和/或固件。
然而,新的软件和固件版本以及新的硬件版本带来了引入新的或更早的未检测到的错误的风险以及在集群中的相同或不同节点之间的不同软件/固件部件之间存在互操作性问题的风险。因此,在理想情况下,操作系统的能力不应该取决于在整个系统中仅使用单一类型的软件,也不应该取决于成功地从一个软件版本升级到另一个软件版本。为了实现这一点,一种方法是确保所需的服务可以通过两组不同类型的硬件部件和用不同组的软件和固件以冗余的方式实现,并且或者在不同组的冗余部件之间根本不存在任何依赖关系,或者仅存在最少且定义非常明确且受控的依赖关系。
根据实施例,这样的系统的一个示例是使用由不同的计算机类型并且使用不同的软件实现的地理上分开的系统,但是其中备份数据可能使用对任一系统具有最小的依赖性的中立格式在系统之间传输。该示例的一个较不严格的版本是,主站点和备份站点正在使用同一类型的装备,但不在同一时间升级。因此,通常,备份站点继续使用版本N,直到已在主站点处为版本N+1建立了足够的置信度为止。
根据实施例,另一种方法是使得同一功能的若干独立实现方案并行地操作。这种方案已用于太空任务,其中不同团队彼此独立地开发了关键部件的多个版本。适用于集群通信基础设施的这种方案的不那么极端的版本是拥有两个独立的网络,每个网络都由来自不同供应商的装置(硬件和软件/固件)实现,但是在成对的计算机之间的通信可以在两个网络基础设施之间进行故障转移。然后,可以将这种用于网络冗余的方案正交应用于是否在集群内使用了不同类型的计算机和主机软件,以便在此级别上也提供类似种类的独立性和冗余性。
根据实施例,从务实的角度来看,即使在设计关键任务的、高可用性系统时,成本和复杂度仍然也是重要的因素。因此,不同的部署可以使用不同级别的冗余和不同级别的多种基础设施类型(即,如果一个以上),以适合相关系统部署的预算和风险情况。
根据实施例,当完全冗余的私有架构被实现为单个子网时,仍然遭受管理和拥塞问题/错误以及由链路故障和从一个冗余部分到另一个冗余部分的重新配置引起的“干扰”的传播。
根据实施例,为了提供两个(或更多个)完全独立或半独立的架构,主机可以包括与每个架构的冗余连接,以便在一对主机各自丢失到不同的独立架构的单个连接的情况下防止连接丢失。
根据实施例,一个挑战是提供两个架构之间的冗余连接,该连接独立于每个架构的正常管理,并且在不存在其它选项时用于数据通信。
图14示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
根据实施例,可以提供两个或更多个轨(rail),诸如轨A 1401和轨B 1421。虽然未示出,但是每个独立的轨可以包括一个或多个互连的交换机以及多播代理(MC代理),诸如MC代理1402和MC代理1422。另外,每个轨可以包括高可用性路径服务(HAPS),诸如HAPS1403和HAPS 1423。轨可以连接到多个主机,诸如主机1 1430至主机N 1440。虽然未示出,但是每个主机可以包括经由一个或多个主机通道适配器连接到轨的一个或多个端节点。另外,端节点可以包括一个或多个虚拟机,如以上关于虚拟化环境所描述的(例如,利用虚拟交换机、虚拟端口或如上所述或本质上类似的其它类似体系架构)。根据实施例,每个主机可以包括多路径选择部件,诸如MPSelect 1431和MPSelect 1441。
根据实施例,术语“轨”可以被用于区分于主机而识别两者、两个或更多个独立的架构/子网以及冗余连接/链路。每个轨可以在端节点之间提供冗余的、分离的、点对点(用于单播)或点对多点(多播)流量。
根据实施例,轨A和轨B可以经由一个或多个轨间链路(IRL)连接。
根据实施例,术语“IRL”(轨间链路)可以被认为类似于交换机间链路(ISL)。然而,IRL可以受限制地使用,因为它不属于任一个轨。
根据实施例,术语“MC代理”可以指多播代理。MC代理可以包括高可用性部件,该部件将所选择的多播分组从一个轨转发到另一个轨(例如,ARP(地址解析协议)请求)。
根据实施例,术语“HAPS”可以指HA(高可用)路径服务。HAPS可以包括高可用性部件,该部件在一个轨的上下文内操作,但与另一个轨中的对等方通信,以便每当需要/要求两个主机进行通信时经由(一个或多个)IRL进行单播数据流量转发。
根据实施例,术语“MPSelect”可以指基于主机的HA/多路径逻辑,用于选择哪个轨用于与不同的对等主机的不同连接。
根据实施例,在单个机架拓扑中,机架内的两个叶子交换机可以表示两个轨(即,两个轨按照硬件而被分开的最小拓扑)。叶子交换机之间可以至少有两个IRL。在InfiniBand拓扑的情况下,每个叶子交换机可以是具有嵌入式子网管理器的单个子网,该子网管理器始终是每个相应轨的主子网管理器。
根据实施例,在多机架拓扑中,每个机架中的两个叶子交换机可以表示两个轨。单个机架中的每个叶子交换机表示不同的轨。每个机架中至少有一个主干交换机。主干的集合被划分为两组——每个轨有一个组。可以对双机架和三机架配置进行特殊处理,以避免任何轨中单个主干是SPOF(单点故障)。一个轨中的叶子交换机连接到同一轨中的所有主干(但不连接到其它轨的主干)。来自每个轨的两对或更多对主干之间有M>1个IRL。在InfiniBand拓扑的情况下,可以提供冗余SM,其位于每个轨内的两个或更多个交换机(或可能的专用主机)上。
根据实施例,在单机架和多机架拓扑中,胖树路由可以忽略轨间链路。在InfiniBand拓扑的情况下,不同的轨被配置有不同的M_Key(管理密钥),从而确保跨IRL之间没有子网管理器交互/干扰。
根据实施例,“HA路径服务”(HAPS)可以跟踪每个子网中完整的HCA节点和端口群体。(这可能还包括用于处理具有多个HCA配置的主机的系统映像GUID)。
根据实施例,HAPS可以使用来自SA或特殊协议的GID在服务中(GID-in-service)/GID停止服务(GID-out-of-service)事件通知。在HAPS被实现为基于主机的服务(其可能与(一个或多个)MC代理实例共置(co-located))的情况下,那么默认情况下不需要特殊协议来跟踪节点群体,但是HAPS然后将具有受相关HCA端口可以成为其成员的分区所限制的范围。
根据实施例,与主SM共置的HAPS实现方案可以与SM具有更直接的交互,并且不限于仅表示特定分区。
根据实施例,HAPS可以跟踪每个L2子网中具有“交叉链路”端口的交换机,并确保正确的连接性。这类似于“内部子网管理器”如何确保对等路由器端口之间的正确连接。
根据实施例,HAPS可以为需要经由交叉链路进行单播转发的“远程LID”建立单播LID转发。原则上,这可以在相关L2子网中“独立”于主SM完成。要求是可以指示SM(配置策略以使用特定的LID范围,但仍基于单独的配置参数为每个交换机设置“LinearFDBTop”值。以这种方式,每个L2子网中的主SM将在不重叠的LID范围内操作,但是每个L2子网中的交换机仍将能够转发DLID值在属于另一个(冗余)L2子网的范围中的单播分组。
根据实施例,只要LID范围边界在线性转发表(LFT)块边界上对齐,那么HAPS就可能独立于本地子网中的主SM(并与其并发)更新LFT块以跨连接管理单播。实际的更新可以直接经由SMP操作执行,或者经由交换机上的特殊代理来执行。
根据实施例,替代方案是HAPS请求本地SM考虑相关的交叉链路端口,以表示当前经由该交叉链路端口进行远程连接所需的所有远程LID。(这类似于路由器端口的处理,但是路由器端口只需要在常规子网发现/初始化过程期间处理的单个LID,而这将是全新的SM操作)。
根据实施例,可以向本地主SM/SA提供反映相关DLID的远程PortGID的路径记录(类似于“内部子网管理器”如何在基于路由器的上下文中向本地主SM提供用于远程端口的路径记录)。在没有路由器端口的情况下,SA然后可以能够基于供应的信息来查找路径记录,但可以能够理解交叉链路端口是本地子网中的“本地目的地”。
根据实施例,如果该单播交叉链路处理与不需要路径记录查询的方案相结合(例如,参见于2017年1月26日提交的题为“SYSTEM AND METHOD FOR SUPPORTING NODE ROLEATTRIBUTES IN A HIGH PERFORMANCE COMPUTING ENVIRONMENT”、申请号为15,416,899的美国专利申请和题为“Filtering Redundant Packets in Computer NetworkEquipments”的美国专利No.7,991,006,这些申请通过引用并入本文),那么本地SM/SA根本不需要知道到远程PortGUID的路径。
图15示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
根据实施例,该图示出了用于在高性能计算环境中支持冗余独立网络的单个机架实现方案。
根据实施例,在单个机架拓扑内,机架可以包括两个或更多个叶子交换机1512-1513。机架可以附加地并且可选地包括多个其它交换机1511。这些附加的交换机是可选的,因为单个机架拓扑的最小基本配置是两个叶子交换机。
根据实施例,在具有通过一组交换机间链路(ISL)或轨内链路(IRL)互连的两个叶子交换机的单个机架拓扑内,可以通过将叶子交换机分区,或者通过将每个叶子交换机分配给不同的轨来定义两个或更多个轨。
根据实施例,在没有将叶子交换机分区的情况下,通常取决于对分组缓冲区分配和交换机硬件资源组织的特定于交换机硬件的限制,对哪些端口编号可以被用于ISL可能存在限制。
根据实施例,在这种情况下,每个叶子交换机1512和1513表示单独的轨,其中ISL表示IRL。在InfiniBand架构的特定情况下,每个叶子交换机表示具有作为主子网管理器的嵌入式子网管理器的单个子网。
根据实施例,在每个叶子交换机上的端口被分区成使得在每个叶子交换机内提供两个轨的情况下,每个叶子交换机处的端口总数被划分为两个分区,其中每个分区表示独立或半独立的轨。在RoCE架构分区内,对于哪些端口编号可以被用于ISL可能又一次存在限制。(默认情况下,相同的端口集将在分区和未分区的叶子交换机的情况下用于ISL。)
根据实施例,为了减少在较小(例如,四分之一机架)配置中实现RoCE架构以及从基于私有架构的系统访问客户端网络所需的交换机数量,叶子交换机(例如,叶子交换机上的端口)可以被分区,并用于将私有RoCE架构实现为表示私有RoCE架构的一个物理分区(即,一组物理端口/连接器)以及表示对客户端网络(例如,现场部署的数据中心网络)的访问的另一个不重叠的分区。因此,每个这样的物理地分区的交换机都可以具有两个不重叠的端口集,其中只有专用于私有RoCE架构的端口集将被允许表示RoCE架构内的连接(反之亦然)。
图16示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
根据实施例,在多机架拓扑中,可以有X个机架,其中每个机架包括多个交换机,包括至少一个叶子交换机。在所描绘的实施例中,系统1600包括X个机架,包括机架1 1610、机架2 1620、机架X-11630和机架X 1640。每个机架包括多个交换机:机架1包括叶子交换机1612-1613和主干交换机1611,机架2包括叶子交换机1622-1623和主干交换机1621,机架X-1包括叶子交换机1632-1633和主干交换机1631,以及机架X包括叶子交换机1642-1643和主干交换机1641。每个主干交换机还连接到两个轨间链路,如图中所示。
根据实施例,在多机架拓扑中,每个机架包括至少两个叶子交换机,并且其中叶子交换机属于单独的轨。在该图中,每个交换机所属的轨由每个交换机中所示的“1”或“2”表示。同样,在多机架拓扑中,每个机架中至少有一个主干交换机。主干交换机集被划分为两组,每个轨一组。一个轨中的叶子交换机连接到同一轨的所有主干交换机,但不连接到不同轨的主干交换机。每个轨的两对或更多对主干交换机之间可能有大于1的M个IRL。在InfiniBand拓扑中,每个轨内两个或更多个交换机(或专用主机)上的冗余子网管理器。
根据实施例,每个机架中的每个叶子交换机具有一组上行链路,这些上行链路分布在架构中的所有主干交换机当中。通常取决于对分组缓冲区分配和交换机硬件资源组织的特定于交换机硬件的限制,对哪些端口编号可以被用于上行链路可能存在限制。每个主干交换机都有分布在架构中的所有叶子交换机之间的多个下行链路。
根据实施例,只要仅主干交换机提供下行链路连接性,那么不同端口之间的特性就不必有任何差异。然而,由于并非所有主干端口都会在特定配置中被利用(连接),因此仍然可能存在限制哪些端口编号可以被用于下行链路的理由。
根据实施例,在多机架配置的情况下,通常不使用分区的叶子交换机。然而,如上所述,单个机架配置可以使用或者可以不使用分区的叶子交换机。因此,在单机架配置情况下的架构定义也可以包括关于所使用的叶子交换机配置是否被分区的信息。然而,基于扩展现有单个机架配置而创建的较小的多机架配置也可以在一个或多个机架内使用分区的叶子交换机。
根据实施例,单机架拓扑和多机架拓扑二者都可以支持两个不同的实施例,即完全独立的轨和半独立的轨。
根据实施例,对于完全独立的轨拓扑,每个轨由一组独立的交换机组成,并且属于不同轨的交换机端口之间不存在连接。这种情况的典型的用例是每个服务器有两个或更多个双端口适配器。
根据实施例,在这种情况下,每个服务器(例如,主机)可以具有到每个轨的冗余连接。因此,就任何服务器的单个适配器或单个适配器端口而言,没有任何单点故障会导致对应的服务器无法发送和接收任何单独的架构轨上的数据流量。
根据实施例,如果两个服务器不都具有到至少一个公共轨的连接,那么这对服务器(或任何一对VM——该对服务器中的每个服务器上一个VM)不能属于同一逻辑集群(其中集群节点之间需要基于架构的通信)。
根据实施例,在每个服务器中的适配器的非重叠子集连接到轨的非重叠集合的情况下(即,不存在具有连接到多于一个非重叠轨集合的端口的适配器),那么不同的轨在通信协议以及软件和固件版本(包括交换机固件、架构管理软件、适配器固件和适配器驱动器软件)方面也是独立的。
根据实施例,本文描述的系统和方法可以附加地支持半独立的轨。
根据实施例,在半独立的轨拓扑中,每个轨由一组独立的交换机组成,并且在正常情况下,属于不同轨的交换机端口之间不存在用于数据流量的连接。然而,“休眠”物理连接可能存在于不同轨中的交换机之间,以便用于在成对的服务器之间提供连接,否则这些成对的服务器将无法通信,因为它们都不具有到同一轨的可操作的连接。可以通过IRL或其它方式来实现这种连接。
根据实施例,用于这种配置的典型用例是当每个服务器通常仅具有单个双端口适配器时,其中每个适配器端口连接到不同轨中的叶子交换机。在这种情况下,任何服务器的任何单个端口/链接故障都将意味着它无法发送或接收对应的架构轨上的数据流量。
根据实施例,如果两个服务器不都具有到至少一个公共轨的连接,那么可以利用不同轨中的交换机之间的“休眠”连接中的一些连接来重新建立该特定服务器对之间的连接,或者替代地,该对服务器(或任何一对VM——该对服务器中的每个服务器上一个VM)不能属于同一逻辑集群(其中集群节点之间需要基于架构的通信)。
图17示出了根据实施例的用于在高性能计算环境中支持冗余独立网络的系统。
更具体而言,该图示出了具有IRL网关的双轨拓扑。
根据实施例,可以提供两个或更多个轨,诸如轨A 1701和轨B 1721。虽然未示出,但是每个独立的轨可以包括一个或多个互连的交换机,以及多播代理(MC代理),诸如MC代理1702和MC代理1722。另外,每个轨可以包括高可用性路径服务(HAPS),诸如HAPS 1703和HAPS 1723。轨可以连接到多个主机,诸如主机11730至主机N 1740。虽然未示出,但是每个主机可以包括经由一个或多个主机通道适配器连接到轨的一个或多个端节点。另外,端节点可以包括一个或多个虚拟机,如以上关于虚拟化环境所描述的(例如,利用虚拟交换机、虚拟端口或如上所述或本质上类似的其它类似体系架构)。根据实施例,每个主机可以包括多路径选择部件,诸如MPSelect 1731和MPSelect 1741。
根据实施例,不是轨间链路1705-1708的直接的交换机到交换机连接,而是可以提供多个网关实例1750和1752,其中每个网关实例提供分组处理引擎1751和1753。
根据实施例,可以在拓扑中的节点(诸如网关节点)处提供分组处理引擎(PPS)。
根据实施例,为了增加冗余架构之间的独立性水平,可以使用双端口高性能分组处理引擎(PPS),而不是直接的交换机-交换机链路,以用于控制和数据流量二者。
根据实施例,这些种类的分组处理引擎可以以可扩展的方式用于附加的多个目的。这些PPS可以被用于在不同系统实例之间提供防火墙。PPS可以被用于提供到云/数据中心网络的网关,以连接不同的私有架构。PPS可以被用于在IB和基于Enet(以太网)的私有架构之间提供网关。PPS可以被用于在私有架构和客户端网络之间提供网关。
根据实施例,系统和方法可以跟踪物理和逻辑连接。这可以通过利用对连接的末端端口和交换机间的连接进行叶子交换机监视来实现。另外,系统和方法可以利用分层查询和报告方案,以便将关于所有相关端节点和端口的所有相关连接和活跃性信息分发给所有相关对等节点。这样的报告还可以包括与本地叶子交换机具有完全连接但中间架构中的连接受到限制的节点和端口。
此外,系统和方法可以利用适配器/NIC固件/驱动器活动检查方案来检测和报告节点死亡(除了链路故障之外),以减少/避免对附加对等点检查的需要,另外促进路径重新平衡和故障转移。
根据实施例,系统和方法可以支持多播、地址解析和路径选择。幂等多播操作(如ARP)可以在多个轨上并行完成。为了确保多播的“至少一次”语义,允许选择性复制,或者多播流量可以使用扩展协议,该协议允许接收者仅处理单个MC消息一次。可以通过不同轨上的多个接口来响应对同一节点的多个并发地址解析请求,然后请求者可以选择用于进一步的通信的轨。
图18是根据实施例的用于在高性能计算环境中的冗余独立网络的方法的流程图。
在步骤1810处,该方法可以在包括一个或多个微处理器的计算机处提供一个或多个交换机,一个或多个机架(所述一个或多个机架中的每个机架包括所述一个或多个交换机中的一组交换机,所述一个或多个交换机中的每组交换机包括至少一个叶子交换机),多个主机通道适配器(所述多个主机通道适配器中的至少一个包括固件和处理器),以及多个主机。
在步骤1820处,该方法可以供给两个或更多个轨,所述两个或更多个轨在所述多个主机之间提供冗余连接。
在步骤1830处,该方法可以将所述多个主机之间的数据流量隔离到所述两个或更多个轨中的轨。
根据实施例,当实现高可用性集群网络/架构时,重要的是,以最小化架构的一个区域中的问题传播到架构的其它冗余区域的风险的方式来实现冗余。
同样,根据实施例,当在架构内需要恢复或故障转移动作时,重要的是,这些动作不会在控制平面或数据平面基础设施上施加可能导致严重性能或前进进度问题的负载。
根据实施例,为了允许系统规模扩展并且还与遗留的高可用性主机通信运行时系统兼容,每个主机可以具有到架构的冗余接口连接,并且每个这样的冗余接口可以到达冗余架构中的任何其它接口。具体地,这意味着如果两个主机各自在一个接口上有问题,那么它们仍应能够使用剩余的正常操作的接口进行通信。因此,接口冗余可以应用于每个单独的主机,并且不依赖于其它主机上哪些接口是可用的。
根据实施例,每当主机接口或交换机发生故障时,就可能重新建立相关的通信,而不依赖于使用哪个接口来发起这种通信。这意味着网络级冗余不能基于其中注入到网络之一中的分组可以被转发到另一个网络的两个完全独立的网络。因此,为了在最大化冗余联网部件之间的独立性的同时支持遗留的HA通信方案,可以使用“半独立的轨”模型。
“半独立”的HA架构的目标:
根据实施例,每个冗余主机接口应连接到HA架构中的独立L2子网(又称为“轨”)。
根据实施例,在两个L2子网之间可以存在单个广播域(broadcast domain),该广播域允许来自单个接口的ARP请求到达所有其它可操作主机接口,而与每个这样的接口直接连接到哪个L2子网无关。
根据实施例,只要L2子网中的至少一个L2子网具有针对每个主机的至少一个连接的且可操作的接口,那么主机之间的数据流量(例如,RDMA)就不应跨越L2子网之间。
根据实施例,每当需要通信的任何一对主机不都能在单个L2子网上的接口之间建立数据流量时,那么就应该为相关主机之间所需的数据流量建立L2子网之间的路径。
根据实施例,即使每个主机上的默认决定涉及不同的“轨”,每个主机上的主机栈也能够容易地确定使用哪个接口来与特定的其它主机进行通信。
根据实施例,在InfiniBand的情况下,主机应该不能发起跨越L2子网边界的SA请求。
根据实施例,主机应该不能使得拥塞从一个L2子网扩展到另一个L2子网。
InfiniBand架构的具体实现方面:
HA路径服务(HAPS):
根据实施例,“HA路径服务”(HAPS)可以跟踪每个子网中完整的HCA节点和端口群体。(这可能还包括用于处理具有多个HCA配置的主机的系统映像GUID)。
根据实施例,HAPS可以使用来自SA或特殊协议的服务中GID在服务中/GID停止服务事件通知。在HAPS被实现为基于主机的服务(其可能与(一个或多个)MC代理实例共置)的情况下,那么默认情况下不需要特殊协议来跟踪节点群体,但是HAPS然后将具有受相关HCA端口可以成为其成员的分区所限制的范围。
根据实施例,与主SM共置的HAPS实现可以与SM具有更直接的交互,并且不限于仅表示特定分区。
根据实施例,HAPS可以跟踪每个L2子网中具有“交叉链路”端口的交换机,并确保正确的连接性。这类似于“内部子网管理器”如何确保对等路由器端口之间的正确连接。
根据实施例,HAPS可以为需要经由交叉链路进行单播转发的“远程LID”建立单播LID转发。原则上,这可以“独立”于相关L2子网中的主SM完成。要求是可以指示SM(配置策略以使用特定的LID范围,但仍基于单独的配置参数为每个交换机设置“LinearFDBTop”值。以这种方式,每个L2子网中的主SM将在不重叠的LID范围内操作,但是每个L2子网中的交换机仍将能够转发DLID值在属于另一个(冗余)L2子网的范围中的单播分组。
根据实施例,只要LID范围边界在线性转发表(LFT)块边界上对齐,那么HAPS就可能独立于本地子网中的主SM(并与其并发)更新LFT块以跨连接来管理单播。实际的更新可以直接经由SMP操作执行,或者经由交换机上的特殊代理来执行。
根据实施例,替代方案是HAPS请求本地SM考虑相关的交叉链路端口,以表示当前经由该交叉链路端口进行远程连接所需的所有远程LID。(这类似于路由器端口的处理,但是路由器端口只需要在常规子网发现/初始化过程期间处理的单个LID,而这将是全新的SM操作)。
根据实施例,可以向本地主SM/SA提供反映相关DLID的远程PortGID的路径记录(类似于“内部子网管理器”如何在基于路由器的上下文中向本地主SM提供用于远程端口的路径记录)。在没有路由器端口的情况下,SA然后可以能够基于供应的信息来查找路径记录,但可以能够理解交叉链路端口是本地子网中的“本地目的地”
根据实施例,如果该单播交叉链路处理与不需要路径记录查询的方案相结合,那么本地SM/SA根本不需要知道到远程PortGUID的路径。
“交叉链路”端口的识别和处理:
根据实施例,在默认情况下,可以在将提供任何交叉链路连接之前和/或在任一L2子网中激活任何SM之前,使用不重叠的M_Key范围来设置冗余InfiniBand L2子网。以这种方式,每个冗余子网中的SM将不会尝试发现或配置超越本地子网中连接到邻居冗余子网的交换机端口以外的任何东西。
根据实施例,预计不可以在不显著中断正常操作的情况下将现有的基于可操作的单子网的系统转换成双L2子网配置。因此,预计这种重新配置将在维护窗口中进行,在维护窗口中预计系统服务将不是正常操作的。
根据实施例,使用特定于供应商的SMA属性,还将可以建立以下协议,该协议使得能够将交换机明确配置为属于特定的冗余L2子网,以及哪些交换机端口编号应表示与对等冗余L2子网的交叉链路连接。
根据实施例,特定于供应商的SMA属性的使用将类似于“内部子网管理器”处理虚拟路由器端口的方式。然而,由于在这种情况下不存在路由器端口或端口虚拟化,因此实现方案将大不相同。
根据实施例,基于详细的配置信息以及可能依赖于节点描述子串,即使不使用特殊的特定于供应商的SMA属性,也可以识别和处理交叉链路端口,但这将更复杂,并且也更容易出现配置错误。
以太网(私有)架构的具体实现方面:
根据实施例,互连架构内的冗余应尽可能确保一个冗余部分中的故障/问题不会传播到其它部分。最终,这意味着在物理上和逻辑上独立的基础设施。然而,这样做的代价是,每个节点都会具有到每个这样的独立架构的冗余连接,否则显著降低对各自具有单个链路问题的两个或更多个服务器之间的连接进行恢复的能力。通过利用新方法在两个独立子网之间提供以太网链路连接,而不影响每个单独子网的管理或故障遏制,可以同时解决两个目标。
根据实施例,可以使用具有生成树(spanning tree)和链路聚合变体的组合的常规以太网单播转发方案来实现以太网私有架构,或者可以以与在单个IB子网中实现IB分组的转发相同的方式使用各个单播目的地地址的显式转发来实现以太网私有架构。
根据实施例,在显式转发各个单播地址的情况下,高级方案如下:
根据实施例,从交换机的相关集合中收集就交换机端口之间以及交换机端口与末端端口之间的端口-端口连接而言的完整拓扑。(优化可以包括仅在最初的完整发现之后收集拓扑增量。)
根据实施例,拓扑信息被变换成可以由用于对应的InfiniBand架构的相同路由逻辑(又称路由引擎)处理的格式。
根据实施例,路由引擎使用拓扑以及允许物理末端端口进行通信的(例如,VLAN)策略(以及类似于IB架构情况的其它相关的优化和平衡标准)并为拓扑中的每个交换机实例生成末端端口地址到端口映射元组的列表。
根据实施例,得到的(增量)转发条目列表被分发给交换机(即,需要更新的交换机)。
根据实施例,在任何情况下都可以使用遗留的以太网方案来实现多播,用于末端端口成员资格处理以及MC分组的转发。
多播代理服务:
根据实施例,与InfiniBand情况相同/相似的考虑是适用是。如果代理的MC分组中的L2源地址与对应的ARP请求“发送者硬件地址”不同,那么ARP请求可以被丢弃,或者单播ARP响应的生成可能导致错误的L2目的地地址。与InfiniBand情况一样,为了避免依赖特殊的主机栈处理,最好的方案是代理能够以与另一个L2子网中的原始发送者对应的源L2地址发出所代理的MC分组。
HA路径服务(HAPS):
根据实施例,“HA路径服务”-HAPS可以跟踪每个子网中的完整的末端端口群体。
根据实施例,可以在两个子网之间关联属于相同的NIC或相同的主机的端口。
根据实施例,如在IB情况下,可以识别主机对仅在经由两个子网之间的交叉链路转发相关单播流量的情况下才能够通信的情况。
根据实施例,在将显式末端端口地址转发用于单播流量的情况下,那么处理将与IB情况非常相似。然而,在遗留以太网单播转发的情况下,并且在通常情况下,这可能还需要用于单播流量的代理类型网关功能。
根据实施例,由于以太网架构内的单播转发是基于MAC的,因此对用于各种L2子网的MAC范围没有限制。唯一的限制是每个主机端口应具有至少在相关站点/域内唯一的MAC。在私有架构的情况下,那么相关域是两个冗余的L2子网。
根据实施例,在交换机可以基于L2和/或L3地址执行转发的情况下,也可以使用基于L3(IP)地址而不是L2 MAC的转发。
“交叉链路”端口的识别和处理:
根据实施例,基于各个交换机被配置为属于不同的“轨”并结合来自每个交换机的邻居连接信息,可以识别属于同一轨/子网(胖树)拓扑的交换机-交换机连接以及预期的(或偶然的)交叉链路连接。
根据实施例,然后对于单播或多播连接的正常转发,将永远不考虑交叉链路连接,但是在明确的末端端口地址转发的情况下,预期的交叉连接将用于备份的轨间路径。如上所述,当使用遗留的以太网单播转发方案时,使用交叉链路通常将需要代理/网关功能,以用于不同轨之间的多播和单播转发二者。
根据实施例,当为基于RoCE的RDMA流量配置以太网交换机和NIC时,通常以“无损”模式配置相关链路,其中每当可用的分组接收缓冲区容量低于某个阈值时,下游交换机或NIC端口将向上游发送交换机或NIC端口生成“暂停帧”。然后,发送端口将停止(暂停)在相关优先级(如果有的话)上发送更多分组,直到下游端口再次具有高于某个阈值的缓冲区容量为止。
根据实施例,与其它联网技术一样,分组流控制可能导致整个网络的背压,必须以无死锁的方式来路由无损RoCE架构拓扑。同样,应相互独立地具有转发进度的流必须使用不同的优先级。
根据实施例,在双轨拓扑的情况下,有必要确保就无死锁而言仅必须考虑单个轨的内部拓扑。通过将交叉链路配置为“有损”(即,下游交换机端口将不发送暂停帧),可以在不考虑由交叉链路连接的(一个或多个)轨中的拓扑的情况下在每个轨中提供拓扑的无死锁路由。替代地,从无死锁的路由角度来看,交叉链路端口将被视为本地轨内的末端端口,因此交叉链路端口不能成为可能导致死锁的任何循环依赖性的一部分。
根据实施例,无损交叉链路配置还将暗示在一个轨中的拥塞不会扩展到另一个轨。因此,满足了冗余轨之间独立性的关键要求。
根据实施例,私有InfiniBand或RoCE物理架构配置(如本文所使用的,术语“架构”或“私有架构”可以指基于私有InfiniBand或RoCE的架构)是按照特定数量的机架定义的,每个机架都有一组相关联的交换机,其中每个此类相关联的交换机都有特定的角色(叶子或主干)。
根据实施例,以及在较小的配置(例如,四分之一机架)中从基于私有架构的系统访问客户端网络,一种方案是将用于实现私有架构的叶子交换机“分区”成表示私有架构的一个物理分区(即,一组物理端口/连接器)以及表示访问客户端网络(例如,现场部署的数据中心网络)的另一个非重叠分区。因此,每个这样的物理分区的交换机将具有两组不重叠的端口,其中只有专用于私有架构的一组端口将被允许表示私有架构内的连接(反之亦然)。
根据实施例,在多机架配置的情况下,通常不使用分区的叶子交换机。然而,如上所述,单个机架配置可以使用或可以不使用分区的叶子交换机。因此,在单机架配置的情况下,架构定义还将包括关于所使用的叶子交换机配置是否被分区的信息。然而,基于扩展现有单个机架配置而创建的较小的多机架配置也可以在一个或多个机架内使用分区的叶子交换机。
根据实施例,为了支持具有两个或更多个独立网络或“架构轨”或简单地“轨”的架构配置,每个交换机还将与轨编号相关联。因此,每个这样的“轨”将表示具有独立于其它轨的连接和流量模式的一个或多个交换机的拓扑。(即,在正常情况下,一个轨中的交换机与另一个轨中的另一个交换机之间没有用于数据流量的链接。)
根据实施例,私有架构定义促进以下高级特征:
·可以在运行时自动检查所有已定义交换机的存在和可用性,并且可以立即报告异常。
·可以根据其在整个架构中的角色和连接,自动定义和验证每个交换机(和本地交换机端口)的配置。
·可以根据每种系统的预定义规则来验证整个架构的物理连接。
·可以自动检测并报告架构中交换机之间的不正确和/或降级的连接(即线缆放置不正确和/或链路数量不足),同时通过防止将不正确的连接用于数据流量(例如,以防止潜在的分组转发环路或死锁)来确保没有其它负面影响。
ο特殊情况是由于错误率高而导致链接被禁用的情况
·可以报告私有架构内定义的交换机与表示该定义的架构中意外设备的另一个交换机或其它网络设备之间的任何连接,并防止其影响架构的操作。
根据实施例,以上概述的基本架构定义集中在交换机拓扑上,并且不与应该(或可以是)架构的一部分的服务器的数量和/或类型相关。因此,在默认情况下,各种架构配置类型所表示的最大数量内的任何数量的物理服务器都可以存在于架构中。同样,可以动态添加和移除此类服务器,而不会影响基本架构定义。然而,在每天添加、移除或更换物理服务器的意义上,几乎不存在任何使这种基于私有架构的系统非常动态的情况。通常预计物理配置在数周和数月内保持不变。
根据实施例,基于预计服务器配置在相当长的时间段内保持稳定,可以用定义系统中和/或每个机架内将存在的服务器的预计数量和类型的参数来可选地扩展架构定义。
根据实施例,该扩展的架构定义促进了以下附加的高级特征:
·可以在运行时自动检查所有已定义服务器的存在和可用性(在与私有架构的连接方面),并且可以立即报告异常。
·可以检测并立即报告在当前定义的架构配置中非预计的服务器(类型和/或数量)的存在(在与私有架构的连接方面)。
·附加策略可以决定是否应为数据流量接受意外的服务器类型或过多数量,但默认设置为“报告并接受”。
·在具有分区的叶子交换机的单机架配置的情况下,服务器和私有架构之间观察到的连接可以与对应的服务器和客户端网络之间观察到的连接关联(即,只要存在用于服务器到客户端网络的连接的策略)。
ο可以识别连接到客户端网络但未连接到私有架构的任何服务器(同样另一种方式用于应该具有客户端网络连接的服务器)。
ο除了本地机架中的服务器与客户端网络之间的连接之外,还可以监视客户端网络交换机分区的上行链路连接。
根据实施例,在“单轨”系统的情况下,所支持的拓扑可以被划分为两个主要类别:
·具有通过一组交换机间链路(ISL)互连的两个叶子交换机的单机架拓扑
ο在没有进行叶子交换机分区的情况下:
·通常取决于对分组缓冲区分配和交换机硬件资源组织的特定于交换机硬件的限制,对哪些端口编号可以被用于ISL可能存在限制。
ο在对叶子交换机进行分区的情况下:
·交换机端口的整个集合被划分为两个分区
·在RoCE架构分区内,对哪些端口编号可以被用于ISL可能再次存在限制。(默认情况下,在分区和未分区的叶子交换机两种情况下,同一组端口将被用于ISL。)
·对于客户端网络分区,对于哪些端口将用于本地服务器连接以及哪些端口将用于上行链路,可能也存在限制或默认设置。
·多机架拓扑(多达N个机架),其中每个机架至少具有两个叶子交换机,并且其中两个或更多个主干交换机位于独立的机架中。
ο每个机架中的每个叶子交换机都有一组上行链路,这些上行链路分布在架构中的所有主干交换机之间。
·通常取决于对分组缓冲区分配和交换机硬件资源组织的特定于交换机硬件的限制,对哪些端口编号可以被用于上行链路可能存在限制。
ο每个主干交换机都有多个下行链路,这些下行链路分布在架构中的所有叶子交换机之间。
·只要主干交换机应仅提供下行链路连接,不同端口之间的特性就不会存在任何差异。然而,由于并非所有主干端口都可以在特定配置中使用(连接),因此仍然可能存在限制哪些端口编号可以被用于下行链路的理由。
根据实施例,在多轨拓扑的情况下,每个单独的架构轨可以对应于如上所述的单个机架或多机架拓扑。然而,在每个机架内,不同的叶子交换机可能属于不同的轨,并且主干交换机的整个集合可以在所定义的轨之间划分。为了增加每个轨内的冗余级别和双向带宽,多轨配置中跨所有轨的交换机总数可能比对应的单轨配置中更高。
根据实施例,存在用于架构轨独立性的两种主要模型:完全独立的轨和半独立的轨。
·完全独立的轨:
ο每个轨由一组独立的交换机组成,并且属于不同轨的交换机端口之间没有连接。
ο这种情况的典型用例是每个服务器有两个或更多个双端口适配器。
·在这种情况下,每个服务器可以具有与每个轨的冗余连接。因此,就任何服务器的单个适配器或单个适配器端口而言,没有任何单点故障可能导致对应的服务器不能发送和接收任何架构轨上的数据流量。
ο如果两个服务器不都具有到至少一个公共轨的连接,那么这对服务器(或任何一对VM——该对服务器中的每个服务器上一个VM)不能属于同一逻辑集群(其中集群节点之间需要基于架构的通信)。
ο在每个服务器中的适配器的非重叠子集连接到轨的非重叠集合的情况下(即,不存在具有连接到多于一个非重叠轨集合的端口的适配器),不同的轨在通信协议以及软件和固件版本(包括交换机固件、架构管理软件、适配器固件和适配器驱动器软件)方面也是独立的。
·半独立的轨:
ο每个轨由一组独立的交换机组成,并且在正常情况下,属于不同轨的交换机端口之间不存在用于数据流量的连接。然而,“休眠”物理连接可能存在于不同轨中的交换机之间,以便用于在成对的服务器之间提供连接,否则这些成对的服务器将无法通信,因为它们都不具有到同一轨的可操作的连接。
ο用于这种配置的典型用例是当每个服务器通常仅具有单个双端口适配器时,其中每个适配器端口连接到不同轨中的叶子交换机。
·在这种情况下,任何服务器的任何单个端口/链接故障都将意味着它无法发送或接收对应的架构轨上的数据流量。
ο如果两个服务器不都具有到至少一个公共轨的连接,那么可以利用不同轨中的交换机之间的“休眠”连接中的一些连接来重新建立该对特定服务器对之间的连接,或者替代地,该对服务器(或任何一对VM——该对服务器中的每个服务器上一个VM)不能属于同一逻辑集群(其中集群节点之间需要基于架构的通信)。
根据实施例,每个交换机可以具有关于其所属的架构类型以及其在架构中的自己的角色和轨关联性的持久性知识。
根据实施例,每个交换机可以具有关于所定义的架构中的所有其它交换机的身份、角色和轨关联性的持久性知识。
根据实施例,每个交换机能够经由导出的LLDP类型信息向直接连接的对等端口反映其与架构相关的配置信息。
根据实施例,单个机架架构中的每个叶子交换机可以具有关于与另一个叶子交换机的所需ISL连接(如果有的话)的先验知识。
根据实施例,单个机架架构中的每个分区的叶子交换机可以跟踪哪些端口属于哪个分区,并将分区类型作为导出的LLDP类型信息的一部分而反映。
根据实施例,多机架架构中的每个叶子交换机可以具有关于到架构中的主干交换机的所需上行链路连接的先验知识。
根据实施例,多机架架构中的每个主干交换机可以具有关于到架构中的叶子交换机的所需下行链路连接的先验知识。
根据实施例,每个交换机能够为每个操作交换机端口确定邻居连接,而无需启用穿过该端口的任何数据流量。
根据实施例,每个交换机可以能够动态确定所发现的邻居连接是否表示该交换机的合法连接,并且如果是,那么应如何配置本地端口。
根据实施例,每个交换机可以能够根据用于相关合法连接的先验规则来动态地配置交换机端口,并且还可以在允许经过该端口的数据流量之前将该配置与相关对等端口同步。
根据实施例,每个交换机可以与架构中的所有其它交换机动态共享其物理邻居连接。
根据实施例,每个交换机可以监视其与管理网络上的任何其它定义的交换机进行通信的能力。
根据实施例,每个交换机可以与架构中的所有其它交换机动态地共享它能够与之通信的其它交换机的列表。
根据实施例,每个交换机应该提供日志信息,该日志信息反映物理连接的变化以及这种连接在合法、不正确或降级方面的状态,以及在管理网络上与架构中其它交换机通信的能力的变化。
根据实施例,在架构级别,应该存在关于架构级别连接问题的协调的日志记录和事件报告,包括交换机对/集合之间缺乏管理连接以及对于特定交换机完全失去从架构其余部分的可达性。
根据实施例,应该支持如意外丢失与特定交换机的架构级别的接触(即,超过预计的重启时段)之类的紧急事件,作为自动服务请求(ASR)。
根据实施例,叶子交换机可以根据关于架构中预计和要求的服务器存在和连接的策略(如果存在的话)来监视物理服务器连接。
根据实施例,分区的叶子交换机应该能够根据关于架构中预计和要求的服务器存在的策略(如果存在的话)来监视到服务器的客户端网络连接。
根据实施例,在多轨架构配置的情况下,每个交换机可以确保所有正常连接都在属于同一轨的交换机之间。
根据实施例,在半独立的多轨架构配置的情况下,必须验证不同轨中的交换机之间的任何物理连接以符合要求的轨间连接,并且然后在正常情况下该连接不应该用于数据流量。
针对不同交换机角色和拓扑的架构连接检查:
根据实施例,每个单独的交换机可以根据其角色以及它所属的架构配置/拓扑的类型来验证该交换机具有正确的连接:
·单机架、单轨配置中的分区的叶子交换机:
ο交换机分区中至少应该有N1-1个表示ISL的端口。
·如果对哪些端口编号可以用作ISL存在限制,那么表示ISL的所有端口都必须在相关的端口集合中。
·最多应该有N1-2个ISL。
ο交换机分区中最多可以有N2个端口连接到主机适配器端口。
ο每个ISL必须连接到具有叶子交换机角色的已分区的单个远程交换机,其中对等端口被配置为ISL,并且其中远程交换机属于同一单个架构实例。
·单机架、单轨配置中的叶子交换机(未分区):
ο至少应该有N3-1个表示ISL的端口。
·如果对哪些端口编号可以用作ISL存在限制,那么表示ISL的所有端口都必须在相关的端口集合中。
·最多应该有N3-2个ISL
·最多可以有N4个端口连接到主机适配器端口。
·每个ISL必须连接到具有叶子交换机角色的未分区的单个远程交换机,其中对等端口被配置为ISL,并且其中远程交换机属于同一单个架构实例。
·多机架、单轨配置中的叶子交换机:
ο至少应该有N5-1个表示上行链路的端口。
·如果对哪些端口编号可以用作上行链路存在限制,那么表示上行链路的所有端口都必须在相关的端口集合中。
·最多应该有N5-2上行链路
ο最多可以有N6个端口连接到主机适配器端口。
ο每个上行链路必须连接到具有主干交换机角色且属于同一单个架构实例的交换机。
ο必须存在到为架构实例定义的每个主干交换机的上行链路连接。
ο上行链路集合必须在为架构实例定义的所有主干交换机之间平均划分。
·多机架、单轨配置中的主干交换机:
ο所有连接的端口都应表示到被定义为同一架构实例的一部分的叶子交换机的下行链路。
·如果对哪些端口编号可以用作下行链路存在限制,那么表示下行链路的所有端口都必须在相关的端口集合内。
ο应该没有端口连接到主机端口。
ο可以存在至少一个连接为架构实例定义的每个叶子交换机的下行链路。
ο下行链路集合必须在为架构实例定义的所有叶子交换机之间平均划分。
根据实施例,对于多轨架构配置,连接规则与上述单轨配置相同,但是具有附加规则,即所有这样的连接必须属于同一轨。因此,在只有两个叶子交换机的单机架情况下,要求可能是根本不应该连接任何ISL(完全独立的轨),或者这样的ISL应该表示“休眠连接”(半独立的轨)。
根据实施例,就服务器连接而言,连接检查可以确保各个服务器根据定义的单轨或多轨策略具有到架构的冗余连接。
根据实施例,不符合以上规则的连接将被记录和报告,并且将不被启用用于数据流量。
根据实施例,丢失的连接将被记录并报告,并且所涉及的交换机(或服务器)将被认为具有降级的(或不完整的)连接。
根据实施例,有效连接将被用于根据针对单个或多个架构轨内的相关拓扑而定义的配置和路由/转发策略来实现架构中的数据流量。
实现方案:
根据实施例,物理架构连接控制实现方案具有以下部件:
·基于交换机的本地链路监视(LLM)守护程序,其跟踪本地链路状态、远程连接(如果有的话)以及本地流量和错误计数器。
·基于交换机的物理连接控制(PCC)守护程序,其从LLM接收本地带内架构连接信息,并且基于此确定本地连接是否符合该交换机实例的要求(相对于其在整个架构配置中的角色),并且如果是,那么应为相关的交换机端口应用哪种高级配置类型。
·硬件(HW)配置守护程序(HWCD),其根据由PCC为交换机提供的高级配置类型和具有经过验证的远程连接的每个连接端口来配置交换机和交换机端口(使用特定于交换机HW平台的接口)。
·架构可用性和同步守护程序(FAS),其在架构中的所有已定义的交换机之间同步架构配置信息和相关联的策略。FAS还跟踪架构中所有已定义的交换机在管理网络上的可达性,并协调每个交换机上PCC实例之间的信息分发。
根据实施例,基于当前定义的持久性架构配置信息和本地交换机的角色信息,PCC通过将从LLM接收到的邻居连接信息与由配置和角色信息以及先验连接规则定义的预期连接进行关联来不断地评估当前的本地连接。
根据实施例,由于默认情况下所有最近训练的链路将不具有启用的数据流量,因此不符合相关规则的任何连接将被保留在该状态中。然而,每当连接符合相关规则,PCC就将指示HWCD根据确定的合法链路类型(即,主机链路、ISL、上行链路或下行链路)来配置和启用端口。
根据实施例,当PCC已经评估新训练的链路时,相关的连接信息经由FAS被分发到架构中的所有其它交换机上的所有其它PCC。
根据实施例,架构中所有交换机上的FAS将不断地监视管理网络上所有其它交换机是否可达,并将当前状态报告给当前的主FAS。
根据实施例,与主FAS共置的PCC将在任何时间点评估来自其同伴PCC实例以及FAS的带内和管理网络连接信息的完整集合。基于此评估并基于为缺乏连接或可达性而定义的超时时段,主PCC将生成警报事件和相关的ASR。
图19示出了根据实施例的用于在高性能计算环境中支持轨编号关联性以进行正确连接的系统。
根据实施例,在系统1900中,支持许多机架,包括机架1 1910、机架2 1920、机架31930和机架4 1940。每个机架可以支持多个交换机,既包括叶子交换机(即,直接连接到HCA(未示出)的那些交换机)又包括多个主干交换机(不是叶子交换机的每个交换机)。这些包括叶子交换机1912-1913、1922-1923、1932-1933和1942-1943,以及主干交换机1911、1921、1931和1941。
根据实施例,系统1900是多轨拓扑,其中每个轨表示不同的架构。在图19中所示的系统中,有两个独立的轨,即轨1和轨2(如图中所示)。
根据实施例,为了支持具有两个或更多个独立网络或“架构轨”或简单地“轨”的架构配置,每个交换机还将与轨编号(例如,如所示的1和2)相关联。然后每个这样的“轨”将表示具有独立于其它轨的连接和流量模式的一个或多个交换机的拓扑。(即,在正常情况下,一个轨中的交换机与另一个轨中的另一个交换机之间没有用于数据流量的数据链路)。(然而,可以存在用于管理流量的轨间链路)。
根据实施例,所描绘的轨是完全独立的轨,因为每个轨由一组独立的交换机组成,并且属于不同轨的交换机端口之间没有连接。这种情况的典型用例是每个服务器有两个或更多个双端口适配器。在这种情况下,每个服务器(未示出)可以具有到每个轨的冗余连接。因此,就任何服务器的单个适配器或单个适配器端口而言,没有任何单点故障会导致对应的服务器无法发送和接收任何架构轨上的数据流量。
根据实施例,如果两个服务器不都具有到至少一个公共轨的连接,那么这对服务器(或任何一对VM——该对服务器中的每个服务器上一个VM)不能属于同一服务器逻辑集群(其中集群节点之间需要基于架构的通信)。
根据实施例,在每个服务器中的适配器的非重叠子集连接到轨的非重叠集合的情况下(即,不存在具有连接到多于一个非重叠轨集合的端口的适配器),不同的轨在通信协议以及软件和固件版本(包括交换机固件、架构管理软件、适配器固件和适配器驱动器软件)方面也是独立的。
异构和不对称的双轨配置
根据实施例,在大多数情况下,使用私有RDMA架构进行与各种类型的高性能计算(HPC)相关的通信以及高性能、高可用性数据库和其它数据服务的系统可以还具有到不同网络的连接,例如,该不同网络用于客户端访问或用于访问系统外部的资源——包括整个互联网上的资源。
根据实施例,例如,这种系统的特殊情况是基于云的系统,其中整个云可以包括经由全球云网络连接的数以万计的服务器(即,数百至数千个服务器机架)。在整个云中,可能存在较小的岛或POD(交付点)(例如,紧密相邻的8至32个服务器机架集合),其中服务器还通过基于RoCE、InfiniBand的高性能RDMA架构或高性能RDMA的其它实现方案而互连。根据实施例,POD可以指一起工作以提供联网服务的网络、计算、存储和应用部件的模块。POD可以包括例如多个机架、服务器、交换机、网络和基础设施。POD可以被设计为被卷入、被连接和被立即启动和运行。POD可以包括例如完整的数据中心,或者它还可以表示更大安装中的扩展的粒度单元。
根据实施例,传统上,相对于可以经由高性能专用RDMA架构实现的性能而言,全球云网络的性能较差。部分原因是由于云网络中的基本链路速度可能低于专用RDMA架构中提供的速度(例如,25Gb/s vs 100Gb/s),而且——特别是——由于云网络内针对访问控制和防火墙规则实施的严格规则意味着每个单独的网络分组的全状态防火墙处理的方案导致往返每个节点的较低的总体分组速率,以及通信节点之间显著增加的消息时延。然而,随着“最新技术”链路速度增加以及片上逻辑功能的集成水平在每一个新的硬件世代中都增加,通常依赖于经由专用、私有RDMA架构进行通信的工作负载变得越来越可能还将能够利用云网络进行具有“合理”性能的基于RDMA的通信。
根据实施例,这种网络的另一方面是可以有效通信的节点数量以及可以如何灵活分配用于特定分布式工作负载的节点方面的可伸缩性。全球云网络的主要优势在于,它允许任何节点与任何其它节点进行通信,因此提供了终极的节点分配灵活性。然而,这种全球连接还意味着交换机跳数方面的距离较长,这在正常情况下增加了消息时延,并且由于网络内不同流之间的拥塞还会增加降低性能的风险。因此,为了减少消息时延和独立工作负载之间的拥塞风险,用于分布式工作负载的节点分配算法通常可以尝试在网络的相邻部分(即,就交换机跳数而言相邻)分配节点。
然而,根据实施例,由于单个芯片上逻辑集成水平的不断提高,当前,可以提供通过无阻塞全交叉开关互连的多于一百个的100Gb/s端口作为单个交换机芯片。因此,在完全无阻塞的胖树拓扑中,可以在仅三个交换机跳的距离内进行通信的节点数量的量级为数千个。因此,可以在云内构建非常大的POD,其中POD中所有服务器之间存在云网络以及私有RDMA架构连接,并且其中任何此类服务器之间的最大距离只有三个交换机跳。
根据实施例,虽然云网络基础设施可以变得也可用于使用高性能RDMA通信的工作负载,但是私有、专用RDMA架构仍可能具有不平凡(non-trival)的性能优势。因此,在云中的各个POD内使用私有RDMA架构可以除提供云网络之外还提供辅助的、性能更高的通信基础设施,这对于许多工作负载而言都是有意义的。
根据实施例,原则上可以将通过云网络以及通过私有RDMA架构二者来连接服务器的POD视为“完全独立的双轨”配置的示例,其中云网络以及私有RDMA架构各自可以表示单个轨,或者可能还表示半独立甚至完全独立的双轨配置。然而,其中每个服务器具有连接到具有双叶子交换机的单个交换网络基础设施和共享主干交换机基础设施的双端口的传统高可用性配置可以是一种典型的情况。尽管如此,由于成本限制以及在每个这样的轨内提供甚至冗余服务器连接的交换机和线缆数量方面的复杂性,每个这样的轨也可能以非冗余的方式实现,其中服务器具有一个适配器和单个端口连接到云网络,并且另一个适配器和单个端口连接到私有RDMA架构。
然后,根据实施例,云网络和私有RDMA架构表示异构且不对称的双轨配置:它们二者都表示到POD中所有服务器的完全连接(即,在非降级的情况下),并且它们二者都可以在POD中的任何一对服务器之间实现基于RDMA的相关通信,但是最好的情况通信性能可能在两个轨之间是不同的。在典型情况下,私有RDMA架构可以提供最佳(预期)性能,因此将成为POD内基于RDMA的通信的主要选择。
然而,根据实施例,例如,在以下潜在场景中,也可以为基于RDMA的通信选择云网络:a)当需要基于RDMA的通信的一对节点不能在私有RDMA架构上通信时;b)当属于不同POD的节点之间需要基于RDMA的通信时;c)当私有RDMA架构上的当前相关负载(足够)高并且云网络上的当前相关负载(足够)低,使得单个POD内的一对节点之间的有效通信性能在云网络上比在私有RDMA架构上更好时;或者d)当相关工作负载的SLA(服务水平协议)指示不需要或不允许使用由私有RDMA架构提供的优质通信服务时。
根据实施例,不对称的双轨系统的实现方案包括各种管理模块。这些管理模块可以包括例如分布式工作负载放置协调器(DWPO),以及连接和轨选择管理器(CRSM)。DWPO通常是整个云工作负载管理基础设施的一部分,并负责将分布式工作负载中的各个逻辑节点分配给云/数据中心中的物理节点。逻辑节点可以被实现为物理节点OS内的容器、物理节点上的由管理程序控制的虚拟机,或者物理节点上的裸机OS/系统映像。
根据实施例,DWPO可以使用与工作负载相关联的放置策略信息,以便决定是否需要(或期望)单个POD内的放置,并且如果是,那么需要(或期望)工作负载内的各个逻辑节点对之间的哪种邻接关系。邻接参数和要求可以包括时延目标以及预期的流量模式和体量。
根据实施例,基于将工作负载的放置策略信息与当前利用率水平和以及与现有工作负载相关联的SLA关联,DWPO可以根据当前正被编排的工作负载的严格SLA来确定最佳工作量或放置。在一些情况下,这可能意味着现有工作负载被重新组织。新工作负载的放置以及现有工作负载的潜在重新组织可以包括单个POD或多个POD,以及具有私有RDMA架构或不具有私有RDMA架构的POD,这取决于可用资源以及相关的SLA要求。
根据实施例,CRSM具有作为整个云工作负载管理基础设施的组成部分的一个集中式部件,以及与每个逻辑节点中的通信运行时系统集成的另一个部件。
根据实施例,可以是集中式的CRSM可以与DWPO协作,以便根据相对于每个逻辑节点应该与之通信的对等逻辑节点的主要轨选择和连接参数策略来确定用于分布式工作负载内各个逻辑节点的连接策略。在最简单的情况下,此策略可以是使用默认参数并使用首选的轨(即,如果存在,通常使用私有RDMA架构),只要该轨为相关对等节点提供连接即可。在更复杂的场景中,单个或一组逻辑节点对可能对每个方向都具有明确的轨选择策略和连接参数策略。
根据实施例,每个逻辑节点CRSM实例将使用来自中央CRSM的策略信息,以便建立和维持与相关对等节点的相关连接。节点本地CRSM实例还将能够根据当前可用的连接和相关轨上的负载,并根据针对整个工作负载以及与相关各个对等节点通信所存在的SLA约束,来为各个对等节点调整连接设置。
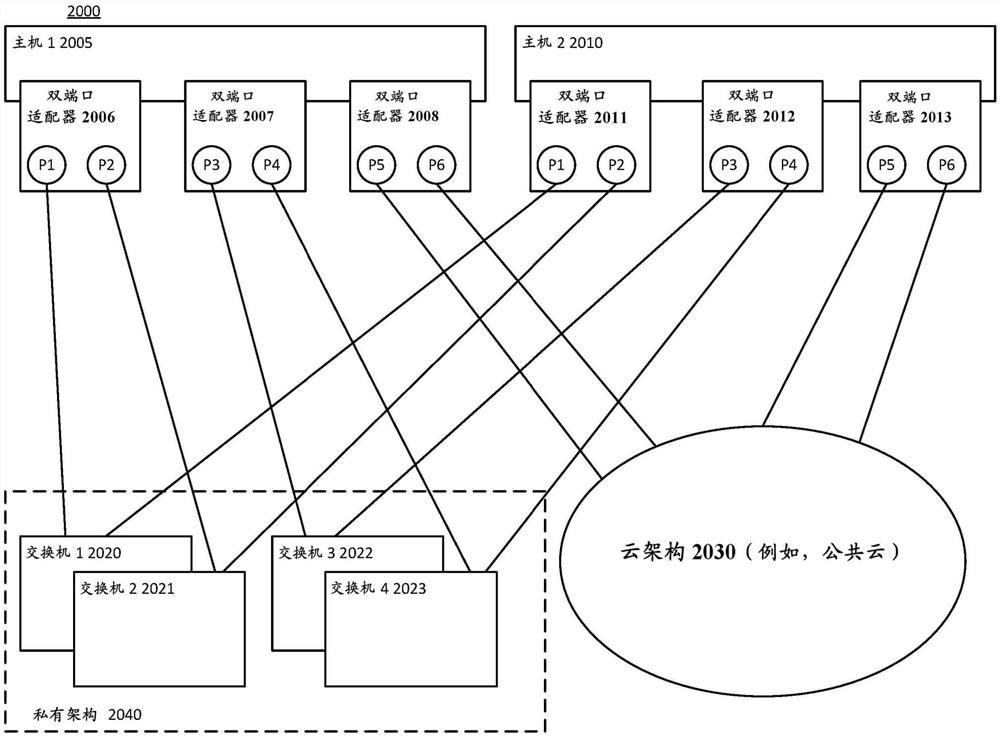
图20示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
根据实施例,在系统2000内,可以支持多个主机节点,诸如主机节点1 2005和主机节点2 2010。每个主机节点可以包括多个双端口适配器(例如,双端口网络适配器),诸如主机节点1上的双端口适配器2006、2007和2008,以及主机节点2上的双端口适配器2011、2012和2013。每个双端口适配器可以提供两个端口,主机节点可以通过这两个端口连接到一个或多个网络,诸如私有架构2040和云架构2030(诸如公共云)。如图所示,私有架构2040包括例如两组重叠的交换机,交换机1 2020和交换机2 2021,以及交换机3 2022和交换机42023,其中这样的成对的交换机表示私有架构内的完全独立的轨。
根据实施例,每个主机节点可以各自包括多个双端口适配器。例如,在所示的实施例中,每个主机节点支持三个双端口适配器。在这三个双端口适配器中,每个主机节点上的两个双端口适配器可以连接到私有架构2040,留下一个适配器连接到云架构2030。以这种方式,每个主机节点可以经由具有两个完全独立的轨(即,交换机1和交换机2,以及交换机3和交换机4,其中每对重叠的交换机表示完全独立的轨)的私有架构连接,并且也可以经由云架构连接。
如果需要,可以多次复制该附图的修改版本(例如,下面的“中”和“小”),以表明私有架构本身可以是半独立和完全独立的,并且还有主机连接可以从一个端口连接到云且一个端口连接到私有架构的单个适配器变化到具有连接私有架构中的不同完全独立的轨的不同适配器以及连接云的多个适配器的多个双端口适配器。
根据实施例,取决于网络内的流量流的类型,可以确定任何给定的分组应当利用私有架构。在私有架构内,提供两个完全独立的轨,其中每个轨可以连接到主机节点处单独的双端口适配器。在一些实施例中,私有架构比云架构提供更高和更安全的性能,但是通常具有更少的资源,因此使得私有架构内的流更加昂贵。
根据实施例,私有架构是完全受控的并且是冗余的。另一方面,由于云架构的性质,通常认为它不是被完全控制,但它可以提供冗余连接。然后,根据实施例,让至少两个架构(私有和公共)提供不对称方案,其中每个主机中的两个适配器表示与私有架构中的两个轨的完全冗余连接,其中第三个适配器提供公共云内的某一(潜在的冗余)连接。通过具有与云的冗余连接,这为主机之间的流量流提供了替代的选项。
根据实施例,工作负载(例如,包括例如在图20所示的两个主机节点上实现,并且以VM可以彼此通信的方式进行部署和配置的多个虚拟机)可以部署在图20所示的环境内。对于给定的工作负载,可以将策略与已部署的工作负载相关联(例如,命令这样的工作负载的分组应利用高级私有RDMA架构的“金卡”工作负载策略,或者例如,命令这样的工作负载的分组利用任何可用带宽(例如,如果私有可用则使用私有,否则使用公共云)的“经济”工作负载策略)。因此,在确定对于系统中的任何给定工作负载应使用哪种类型的连接时,可以考虑这些不同的工作负载策略。例如,如果第一工作负载包括高“金卡”工作负载策略,那么该工作负载内的分组可能会严格在私有架构内分配和供给。替代地,如果另一个工作负载包括较低的“经济”工作负载策略,那么与此类工作负载相关联的分组可以尝试利用私有架构,但也可以利用公共云进行连接。
图21示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
根据实施例,在系统2100内,可以支持多个主机节点,诸如主机节点1 2105和主机节点2 2110。每个主机节点可以包括多个双端口适配器(例如,双端口网络适配器),诸如主机节点1上的双端口适配器2106和2108,以及主机节点2上的双端口适配器2111和2113。每个双端口适配器可以提供两个端口,主机节点可以通过这两个端口连接到一个或多个网络,诸如私有架构2140和云架构2130(诸如公共云)。如图所示,私有架构2140包括例如一组重叠的交换机,交换机1 2120和交换机2 2121,其中每个交换机表示私有架构2140内的半独立的轨。
根据实施例,每个主机节点可以各自包括多个双端口适配器。例如,在所示的实施例中,每个主机节点支持两个双端口适配器。在这两个双端口适配器中,每个主机节点上的一个双端口适配器可以连接到私有架构2140,留下另一个适配器连接到云架构2130。以这种方式,每个主机节点可以经由具有两个半独立的轨(即,交换机1和交换机2)的私有架构而连接,并且也可以经由云架构而连接。
图22示出了根据实施例的用于支持异构和不对称的双轨架构配置的系统。
根据实施例,在系统2200内,可以支持多个主机节点,诸如主机节点1 2205和主机节点2 2210。每个主机节点可以包括多个双端口适配器(例如,双端口网络适配器),诸如主机节点1上的双端口适配器2206和主机节点2上的双端口适配器2211。每个双端口适配器可以提供两个端口,主机节点可以通过这两个端口连接到一个或多个网络,诸如私有架构2240和云架构2230(诸如公共云)。如图所示,私有架构2240包括例如交换机2220,其中该交换机表示私有架构2240内的单个轨。
根据实施例,每个主机节点可以各自包括多个双端口适配器。例如,在所示的实施例中,每个主机节点支持一个双端口适配器。在该双端口适配器内,一个端口可以连接到表示一个轨的私有架构,而另一个端口可以经由表示另一个轨的云架构连接。
图23是用于确定用于支持异构和不对称的双轨架构配置的系统内已供给或正在供给的工作负载的放置策略的方法的流程图。根据实施例,工作负载可以包括多个主机,其中主机可以包括多个物理主机和/或多个虚拟机。
根据实施例,在步骤2300处,可以提供供给的工作负载(已经被供给的工作负载,或者正在被供给的工作负载)。
根据实施例,在步骤2310处,可以检查工作负载以确定与所供给的工作负载相关联的放置策略。
根据实施例,在步骤2315处,该方法可以确定工作负载的放置策略是否指定严格在单个POD内的连接。
根据实施例,在步骤2320处,如果放置策略如此指示在单个POD内的严格放置,那么可以将单个pod内的计算节点分配给所供给的工作负载。
根据实施例,在步骤23250处,如果放置策略没有指示单个POD内的严格放置,那么可以在不考虑POD的情况下将计算节点分配给工作负载。
图24是根据实施例的用于确定针对已供给的工作负载或正在供给的工作负载内的特定通信的架构类型的选择的方法的流程图。
在步骤2400处,根据实施例,该方法可以确定是否满足条件集合中的任何一个,其中条件集合包括:1)是否禁止工作负载使用私有架构?;2)对等(即,目标)节点是否属于不同的POD?;3)对等节点当前是否在私有架构上/经由私有架构不可用?以及4)私有架构上的当前负载是否高于设置的阈值,并且云架构上的负载是否低于另一个设置的阈值?
根据实施例,在2410处,该方法可以确定步骤2400的任何条件是否为真。
根据实施例,如果步骤2400的一个或多个条件为真,那么在步骤2420处,该方法可以设置经由云架构到目标节点(对等节点)的通信。
根据实施例,如果步骤2400的条件都不为真,那么在步骤2430处,该方法可以建立经由私有架构到目标节点(对等节点)的通信。
图25是根据实施例的用于支持异构和不对称的双轨架构的方法的流程图。
在步骤2510处,该方法可以在包括一个或多个微处理器的计算机处提供多个主机、私有架构以及公共架构,该多个主机中的每个主机包括至少一个双端口适配器,该私有架构包括两个或更多个交换机,该公共架构包括云架构。
在步骤2520处,该方法可以在多个主机中的一个主机处供给工作负载。
在步骤2530处,该方法可以将放置策略分配给所供给的工作负载。
在步骤2540处,该方法可以根据放置策略将所供给的工作负载的在对等节点之间的网络流量分配给私有架构和公共架构中的一者或多者。
因此,从一个角度出发,已经描述了用于在高性能计算环境中支持异构和不对称的双轨架构配置的系统和方法。一种方法包括在各自包括一个或多个微处理器的一个或多个计算机处提供:多个主机(该多个主机中的每个主机包括至少一个双端口适配器),私有架构(该私有架构包括两个或更多个交换机),以及公共架构(该公共架构包括云架构)。可以在多个主机中的主机处供给工作负载。可以将放置策略分配给所供给的工作负载。然后,可以根据放置策略将所供给的工作负载的对等节点之间的网络流量分配给私有架构和公共架构中的一个或多个。
根据实施例,在电信通信系统中,高可用性的问题几十年来一直是最重要的,并且“运营商等级系统”的概念已经意味着在恢复服务之前故障切换时间非常短的系统。在此类系统中使用的一种技术是基于协议扩展在双独立网络上重复所有网络流量,该协议扩展使接收者过滤传入流量,使得即使已接收到两个副本,也只向上转发一个逻辑分组到网络栈。在非常高带宽的无损互连架构中,由于过度使用架构中的网络带宽以及所涉及的服务器上的IO带宽,这种重复在一般情况下是不可行的。然而,通过选择性地将此类技术用于多播流量,有可能显著减少在独立子网之间进行显式多播复制的需要或(因为各个多播消息已在网络中丢失而)遭遇超时情况。重要的一点是,可以在保留每个潜在的接收者“最多一次”接收到单个多播消息的关键语义的同时实现这一点。
根据实施例,多播消息的发送者基于多播发送操作是否表示幂等操作(idempotent operation)来对多播发送操作进行分类,在幂等操作中,如果(一个或多个)接收者节点处理正在被发送的多播消息的多于一个副本,不存在负面影响。在这种情况下,两个或更多个独立的多播消息可以经由一个或多个本地接口来发送,并且针对一个或多个单独的多播地址。然而,如果消息不表示幂等操作,那么仅当消息被封装在具有以唯一方式识别特定逻辑消息实例的封装报头的网络分组中时,才能发送同一消息的多个副本。封装报头中的标识符将表示特定于发送者的单调递增数字,使得接收者可以确保随后接收到的具有相同标识编号的消息不会被转发到更高级别的协议栈和/或任何接收应用。
根据实施例,该方案的一方面在于,在使用基于多播的请求和基于单播的响应的应用级别协议的情况下,相同的封装方案也可以被用于单播响应以允许响应者并行发送多个副本,而没有使请求者混淆多个副本的风险。替代地,响应者可以发送仅单个普通单播响应,并且在这种情况下,请求者负责发送在封装报头中带有新实例号的新多播请求。在这种情况下,特定于客户端/应用的协议负责处理由于在客户端/应用层重试而导致的重复消息。
根据实施例,在未被分类为幂等或非幂等的多播流量的情况下,默认策略可以是使用该封装方案(即,默认逻辑网络接口将在默认情况下提供此功能)。在这种情况下,可以为知道替代方案并能够进行正确分类的客户端/应用提供不同的逻辑接口。
替代地,根据实施例,默认接口可以提供遗留功能,然后将仅为经由特殊逻辑接口显式请求该功能的客户端/应用提供封装的流量。
根据实施例,发送者节点可以具有持久性的“系统映像世代编号”,每当相关节点启动时该系统映像世代编号就递增并持久性地存储。另外,每个发送者节点将具有“当前消息序列编号”,该当前消息序列编号对经由逻辑接口发送的表示封装和重复的每个消息而递增。即,对于一组重复消息,当前消息序列编号对每个重复消息是相同的。然后,封装报头中的消息标识就是“系统映像世代编号”和“当前消息序列编号”的组合(级联)。然后,接收节点在接收到同一消息的至少两个副本(都是副本)时,可以忽略后来到达的消息并将其丢弃。
根据实施例,在某些实施例中,针对重复消息仅生成一个序列编号,而与正在使用多少个副本无关。然而,可以通过留下一些位(例如,仅一个位)对在其上发送消息的轨编号进行编码对这进行扩展。这在评估流量时可能具有一定的价值,并且还有助于获得关于两个轨之间的轨间链路的潜在使用的更多信息。然而,要求接收者将同一消息的两个(或更多个)重复版本识别为副本,以防止将多个版本传递给接收应用。
根据实施例,发送者节点可以重复多播消息,并在该发送者节点可以访问的两个或更多个独立或半独立的轨中的每一个上发送多播消息的每个副本。
根据实施例,在相关发送者节点丢失了永久性“系统映像世代编号”的情况下,将执行特殊的过程以确保所有可能的接收者得到通知并能够重置相关发送者节点的任何预期的当前标识编号。在高度可用的集群配置的上下文中,“系统映像世代编号”的处理通常可以是将节点包括在逻辑集群中的过程的一部分。因此,只要节点不被包括在集群中,其它节点就将不会从该节点接受任何传入的多播分组,而与该分组相关联的“系统映像世代编号”无关。集群成员资格处理协议可能出于各种原因而决定从集群中排除节点,但特别是无法与该节点进行通信的情况下(例如,由于该节点崩溃或出于某种原因而重新启动)。在这种情况下,集群成员资格决定可以被传达给其余集群成员,并且可以暗示与被排除节点的所有通信(包括多播通信)都将被立即停止。每当被排除的节点重新启动或出于任何原因而试图(重新)加入集群时,作为相关集群成员资格加入协议的一部分,该节点都可以协商其“系统映像世代编号”。以这种方式,该节点可以基于从持久性存储装置中检索到的世代编号而呈现其当前的下一世代编号,或者如果本地没有新的世代编号可用于该节点,那么该节点可以从集群成员资格控制系统中获取一个新的世代编号。在任一情况下,集群成员资格控制系统都可以确保不会使用任何冲突的世代编号。
根据实施例,每个接收者可以为每个发送者维护动态状态信息,其中发送者节点的ID与当前期望的消息标识符被保持在一起。具有表示较高编号的封装报头的到达消息将被接受并转发,而具有已接收到的标识符(即,比当前期望值低的值)的消息将被丢弃。
根据实施例,为了更容易地将表示封装的和重复的消息的分组与标准网络流量分开,该协议可以在基本分组层处使用替代协议标识符(例如,在数据链路层使用特殊的分组/协议类型字段)。替代地,可以分配一组专用的多播地址以实现这种重复协议,然后将原始多播地址传送为被包括在封装报头中。
图26图示了根据实施例的用于高性能计算环境中的多播发送重复而不是复制的系统。具体地,该图示出了在一个轨上的这种实现方案,而未示出其它轨。
根据实施例,系统2600可以包括多个交换机,诸如主干交换机2611、2621、2631和2641,以及叶子交换机2612-2613、2622-2623、2632-2633和2642-2643。这些交换机可以互连多个节点2650-2653。
根据实施例,发送者节点2650可以包括持久性的“系统映像世代编号”2654,该系统映像世代编号在每次节点启动时就递增并被持久性地存储。另外,发送者节点2650可以包括“当前消息序列编号”2655,该当前消息序列编号针对经由表示封装和重复的逻辑接口发送的每组多播消息而递增。被发送并寻址到多播地址(例如,MGID)的多播分组2655可以包括表示“系统映像世代编号”和“当前消息序列编号”的组合的封装报头。
根据实施例,每个接收者可以为发送者节点2650维护动态状态信息,其中发送者节点的ID与当前期望的消息标识符被保持在一起。具有表示更高编号的封装报头的到达消息将被接受并转发(因为它表示新消息),而具有已接收到的标识符或值小于预期消息标识符的消息将被丢弃,因为该封装报头表示已经被接收到的消息。
图27是用于高性能计算环境中的多播发送重复而不是复制的方法的流程图。
根据实施例,在步骤2710处,一种方法可以提供多个交换机、多个主机,该多个主机经由多个交换机互连,其中多个主机中的主机包括多播发送者节点,该发送者节点包括系统映像世代模块和当前消息序列模块。
根据实施例,在步骤2720处,该方法可以将多个交换机组织成两个轨,该两个或更多个轨在多个主机之间提供冗余连接。
根据实施例,在步骤2730处,方法可以由多播发送者节点发送寻址到多播地址的两个重复的多播分组,其中该两个或更多个重复的多播分组中的每一个在两个轨中的不同轨上被发送。接收节点可以接收同一多播分组的两个版本,但是只有一个版本可以被传递到处理封装报头的层上方的通信栈/客户端。
根据实施例,在步骤2740处,该方法可以在多个主机中的主机接收到两个或更多个重复的多播分组中的两个或更多个时,在传递给通信栈之前丢弃该两个或更多个接收到的多播分组中除第一个以外的所有分组。
跨多个独立的层2(L2)子网的单个逻辑IP子网
根据实施例,系统和方法可以通过允许多个末端端口同时表示相同的IP地址来跨物理上独立的L2子网提供虚拟的单个IP子网。
根据实施例,高可用性网络接口模型是基于链路聚合(LAG)的模型。在该模型中,主机栈看到一个逻辑端口,并且底层的驱动软件和适配器和交换机固件确保不同的流在可用链路之间负载平衡,并且当前被映射到故障链路的流被故障转移到剩余的可操作链路。通过引入支持多机箱LAG(MLAG)的交换机,这种HA模型可以跨多个交换机应用,这意味着根本没有单点故障。然而,这种模型也意味着冗余交换机/网络之间的紧密集成,因此违反了独立网络的目标。替代模型是完全不使用任何LAG协议,而是允许主机侧接口经由多个本地网络端口实现单个IP地址。以这种方式,传出的流量可以使用相关逻辑组中的任何端口,并且针对特定目的地IP地址的传入流量将在组中的任何端口上被接受。在所涉及的网络完全独立的情况下,主机侧操作可能必须选择不同的源端口(又称为不同的轨)以用于重试消息。
根据实施例,呈现给通用主机栈的接口模型仍可以与LAG/MLAG情况下的接口模型相同(即,存在具有单个源IP地址的单个本地网络端口)。
根据实施例,然后将单个本地IP(L3)地址与每个本地末端端口的硬件地址相关联。
根据实施例,接口驱动器可以跟踪各个本地末端端口是否连接到相同或独立的L2子网,并相应地处理传入和传出ARP(地址解析协议)请求。在传出ARP请求的情况下,接口驱动器可以经由每个本地端口来发送一个多播请求。在传入ARP请求的情况下,接口驱动器将经由请求所到达的本地端口来发送单个单播ARP响应。在网络上发送的ARP响应的硬件地址将始终是对应的本地末端端口的硬件地址。
根据实施例,与远程IP地址一起提供给本地主机栈的硬件地址是特殊值,本地接口驱动器可以使用该特殊值来查找要经由一个或多个本地末端端口用于远程IP地址的“真正”HW地址。
根据实施例,用于远程IP地址的本地末端端口和远程硬件地址是本地接口驱动器可以随时间动态地调整以实现最佳可用性和最佳负载均衡的动态实体。
图28示出了根据实施例的用于支持链路聚合(LAG)的系统。
根据实施例,网络分组(诸如分组1 2801)可以被引导到逻辑设备(诸如逻辑设备12810(例如,链路聚合设备))中。该分组在通过逻辑设备之前可以(例如,在分组报头中)包含本地源IP地址(SIP1)、目的地IP地址(DIP1)和目的地MAC(介质访问控制)地址(DMAC1)/与它们相关联。
根据实施例,逻辑设备可以与它自己的地址相关联,诸如IP地址IP1,该IP地址IP1例如可以包括层3地址。
根据实施例,逻辑设备可以附加地包括一个或多个物理网络适配器设备(未示出),其中每个物理网络适配器可以具有一个或多个物理端口(AP1、AP2…APn),每个物理端口可以具有它们自己的MAC(L2)地址(未示出)但是共享逻辑设备2810的单个IP地址(IP1)。
根据实施例,分组2 2802在通过逻辑设备之后,除了目的地MAC地址(DMAC2)之外,还可以在报头中包括例如本地源IP地址(SIP2)和目的地IP地址(DIP2)。在实施例中,在LAG情况下,这些地址可以与通过逻辑设备之前的分组中的地址相同,即SIP1与SIP2相同,DIP1与DIP2相同,并且DMAC1与DMAC2相同。
根据实施例,逻辑设备例如基于负载平衡来决定在哪个轨/端口上将分组2发出到交换机1 2820上的端口(例如,SP1-1至SP1-6)中的目的地端口。
图29示出了根据实施例的用于支持多机箱链路聚合(MLAG)的系统。
根据实施例,网络分组(诸如分组1 2901)可以被引导到逻辑设备(诸如逻辑设备12910(例如,链路聚合设备))中。该分组在通过逻辑设备之前可以(例如,在分组报头中)包括本地源IP地址(SIP1)、目的地IP地址(DIP1)和目的地MAC(介质访问控制)地址(DMAC1)/与它们相关联。
根据实施例,逻辑设备可以与它自己的地址相关联,诸如IP地址IP1,该IP地址IP1例如可以包括层3地址。
根据实施例,逻辑设备可以附加地包括一个或多个物理网络适配器设备(未示出),其中每个物理网络适配器各自具有一个或多个物理端口(AP1、AP2…APn),每个物理端口可以具有它们自己的MAC(L2)地址(未示出)但是共享逻辑设备2910的单个IP地址(IP1)。
根据实施例,分组2 2902在通过逻辑设备之后,除了目的地MAC地址(DMAC2)之外,还可以在报头中包括例如本地源IP地址(SIP2)和目的地IP地址(DIP2)。在实施例中,在LAG情况下,这些地址可以与通过逻辑设备之前的分组中的地址相同,即SIP1与SIP2相同,DIP1与DIP2相同,并且DMAC1与DMAC2相同。
根据实施例,逻辑设备例如基于负载平衡来决定在哪个轨/端口上将分组2发出到交换机1 2920上的端口(例如,SP1-1至SP1-6)或交换机2 2930的端口(例如,SP2-1至SP2-6)中的目的地端口。
根据实施例,在MLAG场景中,交换机(交换机1和交换机2)可以附加地包括交换机之间的一个或多个控制链路。由于这些控制链路,多个交换机可以表现为单个实体,但仍比仅提供一个交换机的LAG实施例提供了增强的冗余。
图30示出了根据实施例的用于在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的系统。
根据实施例,网络分组(诸如分组1 3001)可以被引导到逻辑设备(诸如逻辑设备13010(例如,链路聚合设备))中。该分组在通过逻辑设备之前可以(例如,在分组报头中)包括本地源IP地址(SIP1)、目的地IP地址(DIP1)和目的地MAC(介质访问控制)地址(DMAC1)/与它们相关联。
根据实施例,逻辑设备可以与它自己的地址相关联,诸如IP地址IP1,该IP地址IP1例如可以包括层3地址。
根据实施例,逻辑设备可以附加地包括一个或多个物理网络适配器设备(未示出),其中每个物理网络适配器各自具有一个或多个物理端口(AP1、AP2…APn),每个物理端口可以具有它们自己的MAC(L2)地址(未示出),并且每个物理端口可以具有它们自己的特定于网络的IP地址(未示出)和轨号关联(未示出)。
根据实施例,分组2 3002在通过逻辑设备之后,除了目的地MAC地址(DMAC2)之外,还可以在报头中包括例如本地源IP地址(SIP2)和目的地IP地址(DIP2)。
根据实施例,基于映射功能3011,基于在映射功能内对输入目的地IP(DIP1)和输入目的地MAC地址(DMAC1)的查找,目的地IP(DIP2)和目的地MAC地址(DMAC2)可以包括新地址。源IP地址可以保持不变,即SIP1可以与SIP2相同。
然后,根据实施例,基于映射功能,分组可以从单个层3地址(逻辑设备的IP1)被路由到多个层2子网,诸如由可以被视为MLAG场景的交换机1 3020和交换机2 3030以及可以被视为LAG场景的交换机3 3040表示的子网。
根据实施例,在MLAG场景中,交换机(交换机1和交换机2)可以附加地包括交换机之间的一个或多个控制链路。由于这些控制链路,多个交换机可以表现为单个实体,但仍比仅提供一个交换机的LAG实施例提供了增强的冗余。
根据实施例,虽然所示系统示出了具有支持两个L2子网(一个经由MLAG以及另一个经由LAG)的L3地址的单个逻辑设备,但是本领域的普通技术人员将容易认识到单个逻辑设备支持多个L2子网(诸如n个MLAG子网和m个LAG子网)的不同的和多样的场景,使得n和m的总和大于2。
根据实施例,逻辑设备例如基于负载平衡来决定在哪个轨/端口上将分组2发出到交换机1 3020上的端口(例如,SP1-1至SP1-6)或交换机2 2300上的端口(例如,SP2-1至SP2-6)上的目的地端口。
根据实施例,诸如图30中描述的系统之类的系统可以支持传出映射功能。在这种情况下,系统和方法基于逻辑目的地MAC来查找目的地描述。然后,该系统和方法可以从目的地描述中检索当前的物理设备和端口以及远程物理IP和物理MAC。然后,在发送分组之前,可以使用本地和远程物理地址更新分组报头。
根据实施例,诸如图30中描述的系统之类的系统可以支持传入映射功能。在这种情况下,该方法和系统可以查找与该物理设备相关联的逻辑设备描述和在其上接收到传入分组的端口。然后,该方法和系统可以验证用于接收物理端口的正确的(一个或多个)物理目的地地址被包含在分组报头中。然后,在将分组报头转发到主机栈中的通用IP层之前,可以更新分组报头以反映本地设备的逻辑IP。
根据实施例,诸如图30中所描述的系统之类的系统可以支持传出ARP(地址解析协议)请求。在这种情况下,该系统和方法可以为与逻辑设备相关联的每个物理端口生成ARP请求多播分组。然后,可以填入每个ARP请求多播分组中对应物理端口的相关源地址。然后,该系统和方法可以从对应的物理端口发送每个ARP请求多播分组。
根据实施例,诸如图30中所描述的系统之类的系统可以支持传入ARP(地址解析协议)请求。该系统和方法可以验证物理端口上的传入ARP请求所请求的IP是否与该物理端口相关联的逻辑设备的逻辑IP对应。然后,该系统和方法可以在接收到ARP请求的物理端口上发送ARP响应,其中ARP响应将逻辑设备IP地址反映为发送者IP地址,并且其中发送者硬件地址包括物理端口MAC地址以及物理端口IP地址。
根据实施例,诸如图30中所描述的系统之类的系统可以支持传入ARP(地址解析协议)响应。该系统和方法可以验证目标IP和硬件地址是否与接收物理端口物理IP和物理MAC地址对应。该系统和方法可以记录来自ARP响应的发送者硬件地址的物理IP和MAC地址,并将它们与由ARP响应中的发送者IP地址识别的目的地逻辑IP地址相关联。然后,该系统和方法可以生成逻辑MAC地址,以表示逻辑目的地IP地址到相关物理端口以及目的地物理IP和MAC地址的映射。可以使用逻辑IP地址和相关的逻辑MAC地址来更新ARP表。
图31是根据实施例的用于在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的方法的流程图。
在步骤3110处,该方法可以在包括一个或多个微处理器的计算机处提供逻辑设备,该逻辑设备通过层3地址进行寻址,其中该逻辑设备包括多个网络适配器以及多个交换机,每个网络适配器包括物理端口。
在步骤3120处,该方法可以将多个交换机布置到多个分立的层2子网中。
在步骤3130处,该方法可以在逻辑设备处提供映射表。
因此,从一个角度来看,已经描述了用于在高性能计算环境中跨多个独立的层2子网支持单个逻辑IP子网的系统和方法。一种方法可以在包括一个或多个微处理器的计算机处提供逻辑设备,该逻辑设备通过层3地址进行寻址,其中该逻辑设备包括多个网络适配器以及多个交换机,每个网络适配器包括物理端口。该方法可以将多个交换机布置到多个分立的层2子网中。该方法可以在逻辑设备处提供映射表。
虽然上面已经描述了本发明的各种实施例,但是应当理解的是,它们是作为示例而非限制来呈现的。实施例被选择和描述是为了解释所教导的技术的原理及其实际应用。实施例说明了系统和方法,其中通过提供新的和/或改进的特征和/或提供诸如降低资源利用、增加容量、改进效率和减少延迟之类的益处来利用当前教导的技术改进系统和方法的性能。
在一些实施例中,本发明的特征全部或部分地在包括处理器、诸如存储器的存储介质和用于与其它计算机通信的网卡的计算机中实现。在一些实施例中,本教导的特征在分布式计算环境中实现,其中一个或多个计算机集群通过诸如局域网(LAN)、交换机架构网络(例如,InfiniBand)或广域网(WAN)之类的网络连接。分布式计算环境可以使所有计算机位于单个位置,或者在通过WAN连接的不同远程地理位置处具有计算机的集群。
在一些实施例中,本发明的特征全部或部分地在云中实现,作为基于使用Web技术以自助服务、计量方式向用户递送的共享的弹性资源的云计算系统的一部分或作为其服务。存在云的五个特征(由国家标准与技术研究院定义:按需自助服务;广泛的网络接入;资源池化;快速弹性;以及测量服务)。云部署模型包括:公共、私有和混合。云服务模型包括软件即服务(SaaS)、平台即服务(PaaS)、数据库作为服务(DBaaS)和基础设施即服务(IaaS)。如本文所使用的,云是硬件、软件、网络和Web技术的组合,其以自助服务、计量方式向用户递送共享的弹性资源。除非另有说明,否则如本文所使用的,云包括公共云、私有云和混合云实施例,以及所有云部署模型,包括但不限于云SaaS、云DBaaS,云PaaS和云IaaS。
在一些实施例中,使用硬件、软件、固件或其组合的辅助来实现本教导的特征。在一些实施例中,使用被配置或编程为执行当前教导的方案的一个或多个功能的处理器来实现本教导的特征。在一些实施例中,处理器是被设计为执行本文描述的功能的单芯片或多芯片处理器、数字信号处理器(DSP)、片上系统(SOC)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其它可编程逻辑设备、状态机、离散门或晶体管逻辑、分立硬件部件或其任意组合。在一些实现方案中,本教导的特征可以由特定于给定功能的电路实现。在其它实现方案中,特征可以在处理器中实现,该处理器被配置为使用例如存储在计算机可读存储介质上的指令来执行。
在一些实施例中,本教导的特征结合在软件和/或固件中,用于控制处理和/或联网系统的硬件,并且用于使处理器和/或网络能够利用当前教导的方案的特征与其它系统交互。这种软件或固件可以包括但不限于应用代码、设备驱动器、操作系统、虚拟机、管理程序、应用编程接口、编程语言和执行环境/容器。基于本公开的教导,适当的软编码件可以由熟练的程序员容易地准备,这对于软件领域的技术人员来说是清楚的。
在一些实施例中,本教导包括计算机程序产品,其是具有存储在其上/其中的指令的存储介质或计算机可读介质(介质),指令可以被用于编程或以其它方式配置诸如计算机之类的系统,以执行当前教导的方案的任何处理或功能。存储介质或计算机可读介质可包括但不限于任何类型的盘,包括软盘、光盘、DVD、CD-ROM、微驱动器和磁光盘、ROM、RAM、EPROM、EEPROM、DRAM、VRAM、闪存设备、磁卡或光卡、纳米系统(包括分子存储器IC),或适于存储指令和/或数据的任何类型的介质或设备。在特定的实施例中,存储介质是非瞬态存储介质或非瞬态计算机可读介质。在一些实施例中,计算机可读介质包括瞬态介质,诸如传输信号或载波。这样的瞬态介质可以作为单个计算机系统的部件之间的传输的一部分出现,和/或可以作为多个计算机系统之间的传输的一部分出现。
前面的描述并非旨在是详尽的或限于所公开的精确形式。此外,在使用特定系列的事务和步骤描述了本教导的实施例的情况下,本领域技术人员应当清楚的是,范围不限于所描述的事务和步骤系列。另外,在已经使用硬件和软件的特定组合描述了本教导的实施例的情况下,应当认识到的是,硬件和软件的其它组合也在范围内。另外,虽然各种实施例描述了本教导的特征的特定组合,但是应当理解的是,相关领域的技术人员将清楚,特征的不同组合在本公开的范围内,使得一个实施例的特征可以结合到另一实施例中。而且,相关领域的技术人员将清楚的是,在不脱离所要求保护的主题的精神和范围的情况下,可以在形式、细节、实现方案和应用中进行各种添加、减少、删除、变化以及其它修改和改变。本发明的更广泛的精神和范围旨在由以下权利要求及其等同物限定。
本公开的各方面在以下编号的条款中阐述:
1、一种用于在高性能计算环境中支持异构和不对称的双轨配置的系统,包括:
计算机,所述计算机包括一个或多个微处理器;
多个主机,所述多个主机中的每个主机包括双端口适配器;
第一轨,包括私有架构,所述私有架构包括布置在两个或更多个机架中的多个交换机,所述两个或更多个机架中的每个机架包括所述多个交换机中的一组交换机;
第二轨,包括公共架构,所述公共架构包括云架构;以及
分布式工作负载放置协调器;
其中,所述多个主机中的主机经由所述主机的双端口适配器的第一端口连接到第一轨;
其中,所述多个主机中的所述主机经由所述主机的所述双端口适配器的第二端口连接到第二轨;
其中,在所述多个主机中的所述主机处供给工作负载;
其中,将放置策略分配给所供给的工作负载;
其中,所述分布式工作负载放置协调器根据所述放置策略将分配给所供给的工作负载的放置策略用于将所供给的工作负载的网络流量分配给包括所述私有架构的第一轨和包括所述公共架构的第二轨中的一者或多者。
2、如子句1所述的系统,
其中,所述私有架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载在所述私有架构内提供冗余连接。
3、如子句2所述的系统,
其中,分配给所供给的工作负载的所述放置策略是高优先级放置策略。
4、如子句3所述的系统,
其中,所供给的工作负载的网络流量被严格分配在所述私有架构内。
5、如前述任何一项子句所述的系统,
其中,所述公共架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载在所述公共架构内提供冗余连接。
6、如子句5所述的系统,
其中,分配给所供给的工作负载的所述放置策略是低优先级放置策略。
7、如子句6所述的系统,
其中,所供给的工作负载的网络流量被分配在所述公共架构内和所述私有架构内。
8、一种用于在高性能计算环境中支持冗余独立网络的方法,包括:
在包括一个或多个微处理器的计算机处提供;
多个主机,所述多个主机中的每个主机包括双端口适配器,
第一轨,包括私有架构,所述私有架构包括布置在两个或更多个机架中的多个交换机,所述两个或更多个机架中的每个机架包括所述多个交换机中的一组交换机,
第二轨,包括公共架构,所述公共架构包括云架构,以及
分布式工作负载放置协调器;
经由所述多个主机中的主机的双端口适配器的第一端口将所述主机连接到第一轨;
经由所述多个主机中的所述主机的所述双端口适配器的第二端口将所述主机连接到第二轨;
在所述多个主机中的所述主机处供给工作负载;
为所供给的工作负载分配放置策略;
基于分配给所供给的工作负载的所述放置策略,由所述分布式工作负载放置协调器根据所述放置政策将所供给的工作负载的网络流量分配给包括所述私有架构的第一轨和包括所述公共架构的第二轨中的一者或多者。
9、如子句8所述的方法,
其中,所述私有架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载提供冗余连接。
10、如子句9所述的方法,
其中,分配给所供给的工作负载的所述放置策略是高优先级放置策略。
11、如子句10所述的方法,
其中,所供给的工作负载的在对等节点之间的网络流量被严格供给在所述私有架构内。
12、如子句8至11中的任一项所述的方法,
其中,所述公共架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载提供冗余连接。
13、如子句12所述的方法,
其中,分配给所供给的工作负载的放置策略是低优先级放置策略。
14、如子句13所述的方法,
其中,所供给的工作负载的在对等节点之间的网络流量被分配在所述公共架构内。
15、一种计算机可读介质,其上承载有用于在高性能计算环境中支持异构和不对称的双轨配置的指令,所述指令在由计算机读取并执行时,使所述计算机执行包括以下各项的步骤:
在包括一个或多个微处理器的计算机处提供;
多个主机,所述多个主机中的每个主机包括双端口适配器,
第一轨,包括私有架构,所述私有架构包括布置在两个或更多个机架中的多个交换机,所述两个或更多个机架中的每个机架包括所述多个交换机中的一组交换机,
第二轨,包括公共架构,所述公共架构包括云架构,以及
分布式工作负载放置协调器;
经由所述多个主机中的主机的双端口适配器的第一端口将所述主机连接到第一轨;
经由所述多个主机中的所述主机的所述双端口适配器的第二端口将所述主机连接到第二轨;
在所述多个主机中的所述主机处供给工作负载;
为所供给的工作负载分配放置策略;
基于分配给所供给的工作负载的所述放置策略,由所述分布式工作负载放置协调器根据所述放置政策将所供给的工作负载的网络流量分配给包括所述私有架构的第一轨和包括所述公共架构的第二轨中的一者或多者。
16、如子句15所述的计算机可读介质,
其中,所述私有架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载提供冗余连接。
17、如子句9所述的计算机可读介质,
其中,分配给所供给的工作负载的放置策略是高优先级放置策略。
18、如子句10所述的计算机可读介质,
其中,所供给的工作负载的在对等节点之间的网络流量被严格供给在所述私有架构内。
19、如子句15至18中的任一项所述的计算机可读介质,
其中,所述公共架构提供两个或更多个轨,所述两个或更多个轨为所供给的工作负载提供冗余连接。
20、如子句19所述的计算机可读介质,
其中,分配给所供给的工作负载的放置策略是低优先级放置策略;并且
其中,所供给的工作负载的在对等节点之间的网络流量被分配在所述公共架构内。
- 在高性能计算环境中支持异构和不对称的双轨架构配置的系统和方法
- 用于支持高性能计算环境中的双端口虚拟路由器的系统和方法