基于众核处理器的视频分析加速方法及系统
文献发布时间:2023-06-19 11:32:36
技术领域
本发明属于监控视频快速实时分析技术领域,具体地涉及一种基于众核处理器的视频分析加速方法及系统。
背景技术
智能视频分析系统能够对视频区域内出现的运动目标自动识别出目标类型并跟踪,对目标进行标记并画出目标运动轨迹,能够同时监测同一场景里多个目标,可以根据防范目标的特点进行灵活设置;它能够适应不同的环境变化,包括光照、四季、昼夜、晴雨等,并能够很好地抗摄像头抖动。其改变了以往视频“被动”监控的状态,不仅仅局限于提供视频画面,而且能主动对视频信息进行智能分析,识别和区分物体,可自定义事件类型,一旦发现异常情况或者突发事件能及时的发出警报,其在安防领域的应用必然有助于克服了人力疲惫的局限性,从而更加有效地协助安全人员处理突发事件。
目前,对GMM算法应用与机器学习、神经网络等多个方面,基于大多的GMM算法优化的基础之上,在全新的申威SW26010国产平台上以新的视觉实现并行化GMM算法的加速方法,具有良好的可扩展性,选用基于GMM的运动目标检测能够很好的展现加速效果。
背景减除法是十分有效的运动对象检测的方法,算法思想是利用背景的参数模型来近似背景图像的像素值,通过当前帧分离得到背景图和运动区域,背景图像是需要随着光照等外部因素的变化而更新模型的参数。混合高斯模型(GMM)是背景减除法中最常用的模型,GMM是通过高斯概率密度函数来描述同一事物的多种状态模型,能够有效提取运动前景和背景。
GMM模型的应用场景有语音识别和运动目标检测等,在公共场合的智能视频监控也越来越多,为了满足大型公众场所的监控视频快速实时分析的要求,需要在异构众核处理器上实现通用加速算法。本发明因此而来。
发明内容
针对上述存在的技术问题,本发明提出了一种基于众核处理器的视频分析加速方法,在异构众核处理器上实现通用加速方法,在读取帧采用了双缓冲的机制,实现主从核并行化,从核计算期间,主核预取下一帧数据。在图像解码环节,对图像数据进行划分,使用窗口滑动机制,合理调度从核计算资源。
本发明的技术方案是:
一种基于众核处理器的视频分析加速方法,包括众核处理器,所述众核处理器的视频分析加速方法包括以下步骤:
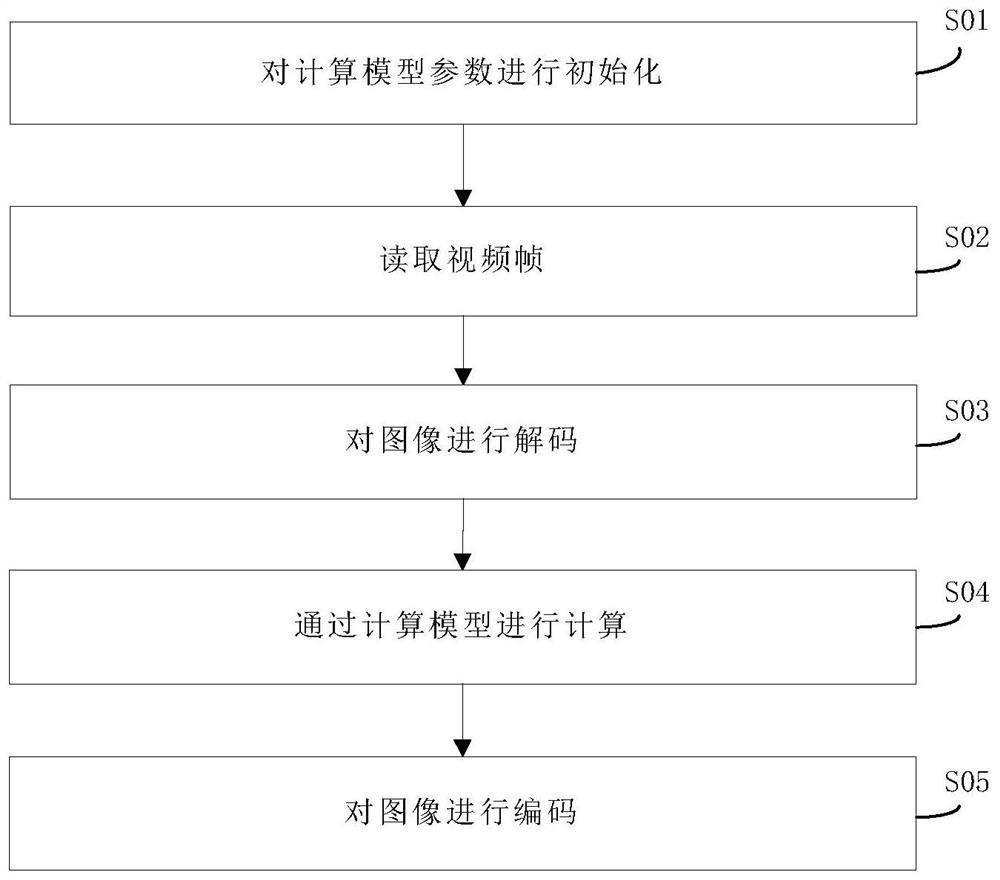
S01:对计算模型参数进行初始化;
S02:读取视频帧,所述读取视频帧时,主核在回送从核数据的并行程序异步通信等待期间,计算存储一帧图像所需的内存空间大小;在内存中创建两块所需内存空间大小的内存空间,分别标记为第一内存空间和第二内存空间,当第n次计算时,若n为奇数时使用第一内存空间发送数据到从核,异步等待,此时第二内存存储下一帧的图像数据;若 n为偶数时则与之相反,依次交替;从核上创建一个相同空间的内存空间,从核计算完成一帧的图像数据后直接取得下一帧的图像数据;
S03:对图像进行解码;
S04:通过计算模型进行计算;
S05:对图像进行编码。
优选的技术方案中,所述步骤S01中还包括,将每个像素点的计算模型参数放至在从核的局部缓存上。
优选的技术方案中,所述步骤S05中对图像进行编码时,主核对图像数据进行划分,包括:每次计算模型迭代前得到一个视频帧,根据图像像素的宽度设置滑动窗口的大小,将图像像素的宽度作为一个数据块;在数据块分配完成后,通知从核进行数据读取运算,每次每个从核读取一个数据块和对应的计算模型参数矩阵,当某个从核计算完成后通过DMA将计算结果和更新的模型参数传回主核,再取下一次的计算区域,直到计算完成为止;从核计算过程中主核处于等待状态,直到所有的从核计算任务完成,主核汇聚当前帧的前景图像并写入新的计算模型参数值,进行编码转化写入视频,再读取下一帧视频。
优选的技术方案中,当存在多个核组数时,对每一帧的视频图像按照行进行分割处理,当多个核组同时工作时,进程为0的负责视频流的编码、解码和视频帧的转码,剩余的核组进行计算模型计算,每个核组再依次取得对0号进程所分配的像素坐标区域的像素值,模型参数矩阵存储在每个主核的主存中,取得任务的主核再划分数据块,分配给自己的从核阵列进行计算。
本发明还公开了一种基于众核处理器的视频分析加速系统,包括众核处理器和视频分析加速系统,所述视频分析加速系统包括以下模块:
参数初始化模块:对计算模型参数进行初始化;
视频帧读取模块:读取视频帧,所述读取视频帧时,主核在回送从核数据的并行程序异步通信等待期间,计算存储一帧图像所需的内存空间大小;在内存中创建两块所需内存空间大小的内存空间,分别标记为第一内存空间和第二内存空间,当第n次计算时,若n为奇数时使用第一内存空间发送数据到从核,异步等待,此时第二内存存储下一帧的图像数据;若 n为偶数时则与之相反,依次交替;从核上创建一个相同空间的内存空间,从核计算完成一帧的图像数据后直接取得下一帧的图像数据;
图像解码模块:对图像进行解码;
模型计算模块:通过计算模型进行计算;
图像编码模块:对图像进行编码。
优选的技术方案中,所述参数初始化模块中还包括,将每个像素点的计算模型参数放至在从核的局部缓存上。
优选的技术方案中,所述图像编码模块中对图像进行编码时,主核对图像数据进行划分,包括:每次计算模型迭代前得到一个视频帧,根据图像像素的宽度设置滑动窗口的大小,将图像像素的宽度作为一个数据块;在数据块分配完成后,通知从核进行数据读取运算,每次每个从核读取一个数据块和对应的计算模型参数矩阵,当某个从核计算完成后通过DMA将计算结果和更新的模型参数传回主核,再取下一次的计算区域,直到计算完成为止;从核计算过程中主核处于等待状态,直到所有的从核计算任务完成,主核汇聚当前帧的前景图像并写入新的计算模型参数值,进行编码转化写入视频,再读取下一帧视频。
优选的技术方案中,当存在多个核组数时,对每一帧的视频图像按照行进行分割处理,当多个核组同时工作时,进程为0的负责视频流的编码、解码和视频帧的转码,剩余的核组进行计算模型计算,每个核组再依次取得对0号进程所分配的像素坐标区域的像素值,模型参数矩阵存储在每个主核的主存中,取得任务的主核再划分数据块,分配给自己的从核阵列进行计算。
与现有技术相比,本发明的优点是:
1、本发明在异构众核处理器上实现通用加速方法,在读取帧采用了双缓冲的机制,实现主从核并行化,从核计算期间,主核预取下一帧数据,缓冲机制的加入使得并行程序运行时间明显减少。
2、在图像解码环节,对图像数据进行划分,使用窗口滑动机制,合理调度从核计算资源,数据的划分平衡了从核计算量的负载均衡,大大缩短了运行时间。
附图说明
下面结合附图及实施例对本发明作进一步描述:
图1为本发明基于众核处理器的视频分析加速方法的流程图;
图2为本发明基于众核处理器的视频分析加速系统的原理框图;
图3为本实施例视频分析的检测流程;
图4为本实施例双缓冲机制示意图;
图5为本实施例滑动窗口分配图;
图6为本实施例352*240视频流提取前景的效果;
图7为本实施例800*600视频流提取前景的效果;
图8为本实施例576*1024视频流提取前景的效果。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进行进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例:
下面结合附图,对本发明的较佳实施例作进一步说明。
如图1所示,一种基于众核处理器的视频分析加速方法,包括众核处理器,所述众核处理器的视频分析加速方法包括以下步骤:
S01:对计算模型参数进行初始化;
S02:读取视频帧,所述读取视频帧时,主核在回送从核数据的并行程序异步通信等待期间,计算存储一帧图像所需的内存空间大小;在内存中创建两块所需内存空间大小的内存空间,分别标记为第一内存空间和第二内存空间,当第n次计算时,若n为奇数时使用第一内存空间发送数据到从核,异步等待,此时第二内存存储下一帧的图像数据;若 n为偶数时则与之相反,即若n为偶数时使用第二内存空间发送数据到从核,异步等待,此时第一内存存储下一帧的图像数据,依次交替;从核上创建一个相同空间的内存空间,从核计算完成一帧的图像数据后直接取得下一帧的图像数据;
S03:对图像进行解码;
S04:通过计算模型进行计算;
S05:对图像进行编码。
这里的计算模型可以为混合高斯模型(GMM)等其他的计算模型,本实施例以混合高斯模型(GMM)为例进行说明,模型参数主要有均值、方差矩阵。
一较佳的实施例中,步骤S01中还包括,将每个像素点的计算模型参数放至在从核的局部缓存上。更加方便模型计算,节省了模型参数更迭的回送主核的时间。
一较佳的实施例中,步骤S05中对图像进行编码时,主核对图像数据进行划分,使用窗口滑动机制,合理调度从核计算资源。划分方法包括以下步骤:
每次计算模型迭代前得到一个视频帧,根据图像像素的宽度设置滑动窗口的大小,将图像像素的宽度作为一个数据块;在数据块分配完成后,通知从核进行数据读取运算,每次每个从核读取一个数据块和对应的计算模型参数矩阵,当某个从核计算完成后通过DMA将计算结果和更新的模型参数传回主核,再取下一次的计算区域,直到计算完成为止;从核计算过程中主核处于等待状态,直到所有的从核计算任务完成,主核汇聚当前帧的前景图像并写入新的计算模型参数值,进行编码转化写入视频,再读取下一帧视频。
一较佳的实施例中,当存在多个核组数时,对每一帧的视频图像按照行进行分割处理,当多个核组同时工作时,进程为0的负责视频流的编码、解码和视频帧的转码,剩余的核组进行计算模型计算,每个核组再依次取得对0号进程所分配的像素坐标区域的像素值,模型参数矩阵存储在每个主核的主存中,取得任务的主核再划分数据块,分配给自己的从核阵列进行计算。不同的核组之间不需要交换高斯模型参数,模型参数矩阵存储每个MPE自己主存中,从而减少的核组之间的通信次数。
如图2所示,本发明还公开了一种基于众核处理器的视频分析加速系统,包括众核处理器和视频分析加速系统,提供视频流结构,接入公众场合的监控实现实时分析,能够对公众场合的人流量等关键数据进行统计,用于资源的合理调度。可以对底层视频流编码解码FFMPEG软件库进行对SW26010的适配,在X86、NMS架构下有单指令多命令等加速,可以结合申威异构众核处理器进一步进行加速。
视频分析加速系统包括以下模块:
参数初始化模块:对计算模型参数进行初始化;
视频帧读取模块:读取视频帧,所述读取视频帧时,主核在回送从核数据的并行程序异步通信等待期间,计算存储一帧图像所需的内存空间大小;在内存中创建两块所需内存空间大小的内存空间,分别标记为第一内存空间和第二内存空间,当第n次计算时,若n为奇数时使用第一内存空间发送数据到从核,异步等待,此时第二内存存储下一帧的图像数据;若 n为偶数时则与之相反,依次交替;从核上创建一个相同空间的内存空间,从核计算完成一帧的图像数据后直接取得下一帧的图像数据;
图像解码模块:对图像进行解码;
模型计算模块:通过计算模型进行计算;
图像编码模块:对图像进行编码。
在一具体的实施例中,如图3所示,将每个像素点的模型参数放至在从核的局部缓存上(LDM),更加方便模型计算,节省了模型参数更迭的回送主核的时间。在读取帧的模块环节和读取视频帧,通过移植的FFMPEG视频编码解码库来实现对图像的解码过程,通常像素编码选用YUV格式转化成RGB格式进行计算。模型计算是由从核阵列(CPEs)负责,主核负责帧的读取和保存,将RGB格式数据划分送到从核的局部缓存上,从核获取数据计算模型参数迭代,将模型分类得到的视频格式转化成GRAY像素格式,最后通过DMA方式将结果回送到主核的主存中。图像的编码是利用FFMPEG库将像素格式GRAY直接转化成YUV格式,进行视频编码,最后封装到视频容器中。在读取帧采用了双缓冲的机制,实现在主从核并行化,从核计算期间,主核预取下一帧数据。在图像解码环节,对图像数据进行划分,使用窗口滑动机制,合理调度从核计算资源。
从核(CPE)阵列计算过程中,主核(MPE)一直处于等待状态,我们在此引入双缓冲区的机制,双缓冲是在并行程序异步等待期间,通过空间换时间的思想,依据图像的视频大小计算需要存储一帧图像所需的内存空间大小,dWidth*dHeight*4字节的内存空间,dWidth、dHeight分别为图像的宽度和高度,在内存中开辟两块如上相同大小的内存空间,分别标号为内存1和内存2,当第n次计算时,n为奇数使用内存1发送数据到从核,异步等待,此时内存2存储下一针需要的图像数据,当n为偶数则与之相反,依次交替。我们在主核的主存空间划分通过开辟新的缓冲区使得等待程序提前处理下一次不依赖上一次结果的计算。图4为双缓冲模型,算法思想是基于主核和从核同时运行,主核算法是在回送从核数据的异步通信等待期间,加入新的任务,使得主核在等待期间进行下一帧图像预加载。从核上同样开辟一个相同空间的内存空间,从核计算完成一帧的视频图像可以直接取得下一帧的图像,无需再异步等待。MPE和CPE对双缓冲的优化,在读取的不是第一帧和最后一帧的情况下,CPE计算期间MPE保存上一帧的前景视频流,同时预取下一帧数据解码传入下一次从核计算预取缓冲区,创建两个缓冲区,改变以往从核运算时主核是处于等待状态的计算资源闲置,从而减少主从核的串行等待时间,使得CPE尽可能地处于计算状态。
数据的划分平衡从核计算量的负载均衡,图5是滑动窗口分配图,每次GMM迭代前得到一个视频图像帧,MPE对图像进行数据划分,针对神威每个CPE的LDM都是64KB的大小限制,按照视频像素的宽度为一个数据块,每滑动窗口的大小为1*dWidth,一共有dHeight个数据块。在数据块分配完成以后,通知从核进行数据读取运算,每次每个从核读取1*dWidth的RGB和对应的混合高斯模型参数矩阵,当某个CPE计算完成后通过DMA(直接存储器访问)将计算结果和更新的模型参数传回主核,再去跨64行取的下一次的计算区域。例如从核号为0的窗口,每次滑动的间距是64行,第一次计算第0号数据块,第二次计算第64号数据块,直到没有任务可以计算为止。从核计算过程中主核处于等待状态,直到所有的从核计算任务完成,主核汇聚当前帧的前景图像并写入新的混合高斯模型参数值,进行编码转化写入视频,再去读取下一帧视频。
多核组并行化算法如下:
在多节点的并行方案采用的是对每一帧的视频图像分割处理,为了保证视频图像尽可能地连续存储要求,按照行的性质进行划分。当并行的节点有n个时候,即有4n个核组同时工作,进程为0的负责视频流的编码解码和视频帧的转码,则剩余的4n-1的核组进行高斯模型计算。每个核组再依次取得对0号进程所分配的像素坐标区域的像素值,多核的并行化比从核的并行化多了独立的内存空间,又由于高斯模型参数对于每个像素点的独立性,不同的核组之间不需要交换高斯模型参数,模型参数矩阵存储每个MPE自己主存中,从而减少的核组之间的通信次数。取得任务的主核再分划数据块,分配给自己的从核阵列进行计算。
表1展示了在不同平台单元上GMM检测的运行时间,在单核组上计算能力上也有很好的加速效果,同时加入了双缓冲的对比。对比了不同架构的Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz处理器,实验结果证明video1、video2、video3不同视频流在SW26010的处理,双缓冲的加入相比没有双缓冲的并行程序分别提升了24.4%、43.7%、29.6%的性能提升。下表所示双缓冲机制的加入使得并行程序运行时间明显减少。
表1 运动目标检测在不同架构下和优化后的运行时间对比
本实验选取了1、2、4、8个节点上进行并行程序的测试,即有1、4、8、16、32个核组的实验数据。表2显示了在不同核组数下对不同视频流处理的程序运行时间记录,证明了GMM模型应用在“神威太湖之光”上拥有良好的可扩展性。结合图6、7、8不同视频流提取前景的效果,从中我们可以看出,在计算量不变的前提下,随着核组个数的增加,程序的运行时间逐渐缩短。初段的加速比明显高于后端的加速比例,原因是随着核组数量的增加,不同的MPE之间通信次数也再增加,同时对于同一视频流的每一帧像素大小固定,而主核个数增加使得划分的数据块大小逐渐减小,不利于DMA的大数据块传输。
表2 不同核组数下运行的时间结果
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 基于众核处理器的视频分析加速方法及系统
- 基于异构众核处理器的卷积加速方法