一种歌曲推荐方法、系统、智能设备及存储介质
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及儿歌推荐技术领域,尤指一种歌曲推荐方法、系统、智能设备及存储介质。
背景技术
现有的歌曲推荐方法有很多,主流音乐推荐技术是通过大量的用户行为数据、社交数据、用户画像等数据使用协同算法分类判断,实现推荐,如spotify,虾米音乐等。但该方法对于很多垂直型或相对小众型用户的应用,如儿歌就不太适用,因为用户数据很少甚至没有,就无法根据用户行为、数据等做推荐或推荐的精度较低。因此,需要一种精度更高,且不需要获取用户的行为、数据等,便能够进行歌曲推荐的方法。
发明内容
本发明的目的是提供一种歌曲推荐方法、系统、智能设备及存储介质,该方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
本发明提供的技术方案如下:
本发明提供一种歌曲推荐方法,包括步骤:
对目标类型歌曲进行细分类;
获取各个细分类下的若干个歌曲文件,并将所述歌曲文件转换成训练声谱图;
建立歌曲分类模型,并通过所述训练声谱图对所述歌曲分类模型进行训练;
获取用户选择的目标类型下的当前歌曲,并将所述当前歌曲对应的声谱图输入训练好的所述歌曲分类模型,获得所述当前歌曲对应的当前细分类;
根据所述当前细分类进行歌曲推荐。
具体的,可以对一个大类型的歌曲进行细分类,如可以将儿歌分成摇篮曲、游戏歌、数数歌、问答歌、绕口令、连锁调、谜语歌、颠倒歌、字头歌、故事类、抒情类、幼儿园、胎教音乐、睡眠歌、磨耳朵、动画歌、贝瓦儿歌、三字经、古诗歌、英文儿歌、古典音乐等21个分类。当然,也可以按照其它标准进行分类。
在获取各个细分类下的若干个歌曲文件作为训练集时,为了提高模型的精准度,应每个细分类选择较多的歌曲文件。以上述儿歌为例,在本实施例中,每个细分类选择50个mp3歌曲文件,共1050个mp3文件。
音频文件内包含的信息很多,为了提取特征并去噪,可以把音频转换为图像形式,利用傅里叶变换法,将音频信号转换为频域,用这种方法处理1050个MP3音频文件,将每首歌提取转换成声谱图。声谱图就是声音频率的频谱随着时间变化的可视化表示,图谱中颜色的深浅表示该频率下的声音大小。
在本实施例中,歌曲分类模型为Tensorflow卷积神经网络模型,在进行分类时,声谱图像将被转换成一个表示每个像素的颜色的数字矩阵,之后数据经过卷积层、池化层以及全连接层等处理后转换成softmax分类器,这个分类器是一个由多个数字(如与儿歌细分类对应的21个数字)组成的向量,包含了卷积神经网络模型将各个歌曲细分类分配给声谱图的概率,最后选择其中最大概率位置的分类为最终识别分类。在其它实施例中,还可以选用其它类似神经网络模型进行歌曲分类。
通过对目标类型歌曲进行细分类,并获取各个细分类下的若干个歌曲文件,再将歌曲文件转换成训练声谱图,能够对歌曲分类模型进行训练;在用户选择目标类型下的一首歌曲时,将当前歌曲对应的声谱图输入到训练好的歌曲分类模型中,便能获得当前歌曲对应的当前细分类,从而可以根据当前细分类进行歌曲推荐。由于本方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,使得该方案的推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
进一步地,所述的通过所述训练声谱图对所述歌曲分类模型进行训练之后,还包括步骤:
通过训练好的所述歌曲分类模型对存储的目标类型下的所有歌曲进行细分类;
为每个细分类建立歌曲相似模型,并通过所述歌曲相似模型提取各个细分类下所有歌曲的特征向量;
所述的获得所述当前歌曲对应的当前细分类之后,还包括步骤:
通过所述当前细分类对应的所述歌曲相似模型提取所述当前歌曲对应的特征向量:
将所述当前歌曲对应的特征向量与所述当前细分类下的所有歌曲的特征向量进行比较,获得相似度最高的目标歌曲并进行推荐。
具体的,为了更准确的推荐目标歌曲,可以在训练好歌曲分类模型时,对存储的目标类型下的所有歌曲进行细分类,并为每个细分类建立歌曲相似模型,再通过歌曲相似模型提取各个细分类下所有歌曲的特征向量;在确定当前歌曲的细分类后,通过当前细分类对应的歌曲相似模型提取当前歌曲对应的特征向量,将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,能够获得相似度最高的目标歌曲进行推荐,从而提高推荐的精准度。
进一步地,通过余弦相似性算法对所述当前歌曲对应的特征向量与所述当前细分类下的所有歌曲的特征向量进行比较;
将最大余弦相似性的歌曲作为目标歌曲进行推荐。
具体的,可以通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较。余弦相似性算法是将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来衡量这两个向量的相似性;夹角越小,余弦值越接近于1,两个向量就越相似。因此,可以用余弦相似性做为主要指标来对歌曲的相似度进行比较,将最大余弦相似性的歌曲作为目标歌曲进行推荐。
进一步地,所述的获取各个细分类下的若干个歌曲文件,并将所述歌曲文件转换成训练声谱图,具体包括:
提取所述歌曲文件内的预设时间段的音频;
将所述预设时间段的音频转换成完整声谱图;
将所述完整声谱图平分成预设数量的所述训练声谱图;
所述的将所述当前歌曲对应的声谱图输入训练好的所述歌曲分类模型,具体包括:
提取所述当前歌曲的预设时间段的音频;
将所述当前歌曲对应的预设时间段的音频转换成预设数量的声谱图;
将所述当前歌曲对应的预设数量的声谱图输入训练好的所述歌曲分类模型。
具体的,为了保证数据的统一性,可以提取歌曲文件内的预设时间段的音频,并将预设时间段的音频转换成完整声谱图,再将完整声谱图平分成预设数量的所述训练声谱图。例如以上述的儿歌分类为例,可以每首歌曲提取约2分钟的音频,然后转换成声谱图,然后将图片分256x 256像素的正方图,每张图大概5秒的音频,一首歌曲大概24张声谱图,处理分割后总共大概有25200张图,并为每张图做一个标签,标注分类。通过将每首歌拆分成24张声谱图,能够提高模型训练的精准度,避免偶然性。当然,在其它实施例中,可以根据实际需求进行声谱图的不同拆分。
进一步地,所述的通过所述歌曲相似模型提取各个细分类下所有歌曲的特征向量,具体包括:
提取各个细分类下所有歌曲的预设时间段的音频;
将各个细分类下所有歌曲对应的预设时间段的音频转换成预设数量的声谱图;
通过所述歌曲相似模型提取各个细分类下与各个歌曲的预设数量的声谱图对应的预设数量的特征向量;
计算各个细分类下各个歌曲的平均向量;
所述的通过所述当前细分类对应的所述歌曲相似模型提取所述当前歌曲对应的特征向量,具体包括:
通过所述当前细分类对应的所述歌曲相似模型提取与所述当前歌曲的预设数量的声谱图对应的预设数量的特征向量;
计算所述当前歌曲对应的平均向量;
所述的将所述当前歌曲对应的特征向量与所述当前细分类下的所有歌曲的特征向量进行比较,具体包括:
将所述当前歌曲对应的平均向量与所述当前细分类下的各个歌曲的平均向量进行比较。
具体的,在提取特征向量时,为了提高精度,避免偶然性,可以按照同样方法获得一首歌对应的24个特征向量,再求得每首歌的平均向量,以平均向量作为评价标准来评价不同歌曲之间的相似度,能够做到最优推荐。
另外,本发明还提供一种歌曲推荐系统,包括:
第一分类模块,用于对目标类型歌曲进行细分类;
获取模块,与所述第一分类模块连接,用于获取各个细分类下的若干个歌曲文件,并将所述歌曲文件转换成训练声谱图;
训练模块,与所述获取模块连接,用于建立歌曲分类模型,并通过所述训练声谱图对所述歌曲分类模型进行训练;
推荐模块,与所述训练模块连接,用于获取用户选择的目标类型下的当前歌曲,并将所述当前歌曲对应的声谱图输入训练好的所述歌曲分类模型,获得所述当前歌曲对应的当前细分类,再根据所述当前细分类进行歌曲推荐。
通过第一分类模块对目标类型歌曲进行细分类,并通过获取模块获取各个细分类下的若干个歌曲文件,再将歌曲文件转换成训练声谱图,能够通过训练模块对歌曲分类模型进行训练;在用户选择目标类型下的一首歌曲时,可以通过推荐模块将当前歌曲对应的声谱图输入到训练好的歌曲分类模型中,便能获得当前歌曲对应的当前细分类,从而可以根据当前细分类进行歌曲推荐。由于本方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,使得该方案的推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
进一步地,还包括:
第二分类模块,用于通过训练好的所述歌曲分类模型对存储的目标类型下的所有歌曲进行细分类;
第一提取模块,用于为每个细分类建立歌曲相似模型,并通过所述歌曲相似模型提取各个细分类下所有歌曲的特征向量;
第二提取模块,用于通过所述当前细分类对应的所述歌曲相似模型提取所述当前歌曲对应的特征向量;
比较模块,用于将所述当前歌曲对应的特征向量与所述当前细分类下的所有歌曲的特征向量进行比较,获得相似度最高的目标歌曲,所述推荐模块推荐所述目标歌曲。
具体的,为了更准确的推荐目标歌曲,可以在训练好歌曲分类模型时,通过第二分类模块对存储的目标类型下的所有歌曲进行细分类,并为每个细分类建立歌曲相似模型,再通过第一提取模块提取各个细分类下所有歌曲的特征向量;在确定当前歌曲的细分类后,可以通过第二提取模块提取当前歌曲对应的特征向量,再通过比较模块将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,能够获得相似度最高的目标歌曲进行推荐,从而提高推荐的精准度。
进一步地,所述比较模块通过余弦相似性算法对所述当前歌曲对应的特征向量与所述当前细分类下的所有歌曲的特征向量进行计算,并将最大余弦相似性的歌曲作为目标歌曲。
具体的,可以通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较。余弦相似性算法是将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来衡量这两个向量的相似性;夹角越小,余弦值越接近于1,两个向量就越相似。因此,可以用余弦相似性做为主要指标来对歌曲的相似度进行比较,将最大余弦相似性的歌曲作为目标歌曲进行推荐。
另外,本发明还提供一种智能设备,包括:
存储器,用于存放运行程序;
处理器,用于执行所述存储器内存放的运行程序,实现上述的歌曲推荐方法所述执行的操作。
另外,本发明还提供一种存储介质,所述存储介质中存储有至少一条指令,所述指令由处理器加载并执行以实现上述的歌曲推荐方法所执行的操作。
根据本发明提供的一种歌曲推荐方法、系统、智能设备及存储介质,通过对目标类型歌曲进行细分类,并获取各个细分类下的若干个歌曲文件,再将歌曲文件转换成训练声谱图,能够对歌曲分类模型进行训练;在用户选择目标类型下的一首歌曲时,将当前歌曲对应的声谱图输入到训练好的歌曲分类模型中,便能获得当前歌曲对应的当前细分类,从而可以根据当前细分类进行歌曲推荐。由于本方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,使得该方案的推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对本方案的上述特性、技术特征、优点及其实现方式予以进一步说明。
图1是本发明实施例的整体流程示意图;
图2是本发明另一个实施例的流程示意图;
图3是本发明实施例的系统结构示意图;
图4是本发明实施例的智能设备结构示意图。
附图标号:1-第一分类模块;2-获取模块;3-训练模块;4-推荐模块;5-第二分类模块;6-第一提取模块;7-第二提取模块;8-比较模块;100-存储器;200-处理器;300-通信接口;400-通信总线;500-输入/输出接口。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
实施例1
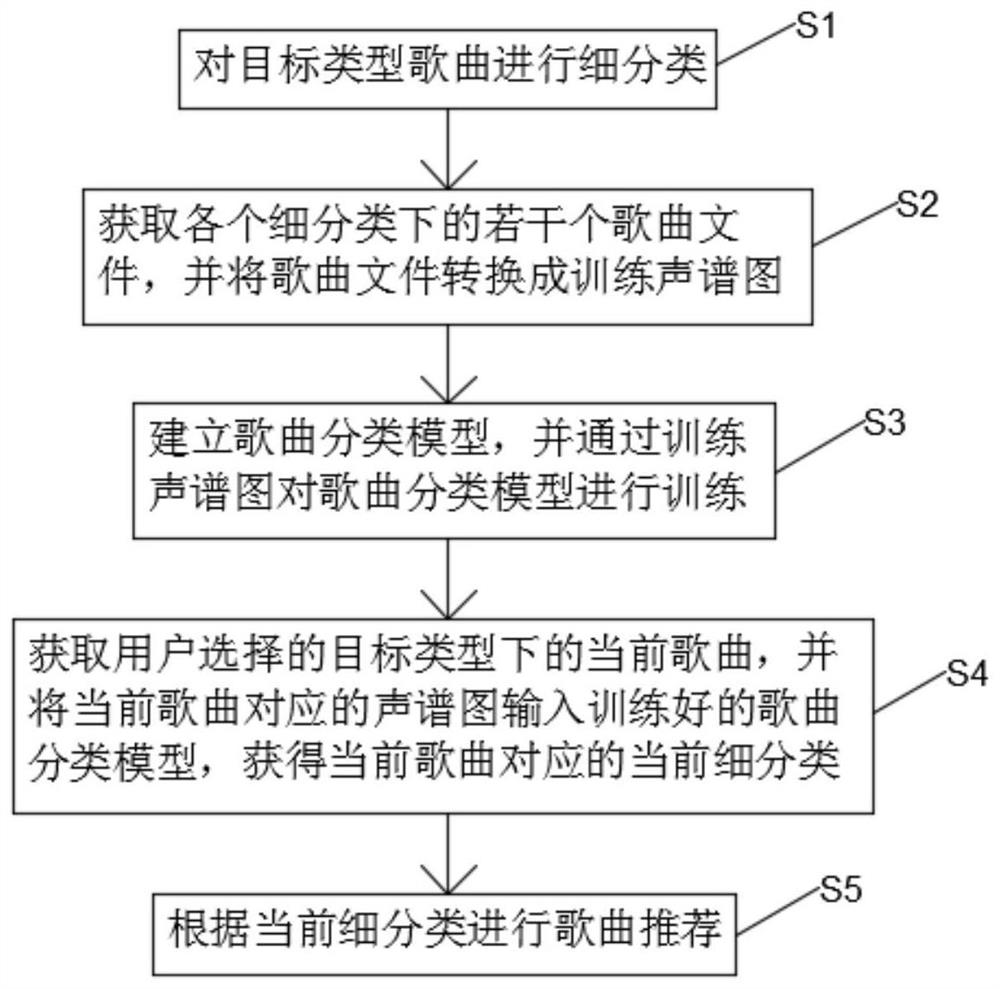
本发明的一个实施例,如图1所示,本发明提供一种歌曲推荐方法,包括步骤:
S1、对目标类型歌曲进行细分类。
具体的,可以对一个大类型的歌曲进行细分类,如可以将儿歌分成摇篮曲、游戏歌、数数歌、问答歌、绕口令、连锁调、谜语歌、颠倒歌、字头歌、故事类、抒情类、幼儿园、胎教音乐、睡眠歌、磨耳朵、动画歌、贝瓦儿歌、三字经、古诗歌、英文儿歌、古典音乐等21个分类。当然,也可以按照其它标准进行分类。
S2、获取各个细分类下的若干个歌曲文件,并将歌曲文件转换成训练声谱图。
在获取各个细分类下的若干个歌曲文件作为训练集时,为了提高模型的精准度,应每个细分类选择较多的歌曲文件。以上述儿歌为例,在本实施例中,每个细分类选择50个mp3歌曲文件,共1050个mp3文件。
音频文件内包含的信息很多,为了提取特征并去噪,可以把音频转换为图像形式,利用傅里叶变换法,将音频信号转换为频域,用这种方法处理1050个MP3音频文件,将每首歌提取转换成声谱图。声谱图就是声音频率的频谱随着时间变化的可视化表示,图谱中颜色的深浅表示该频率下的声音大小。
S3、建立歌曲分类模型,并通过训练声谱图对歌曲分类模型进行训练。
在本实施例中,歌曲分类模型为Tensorflow卷积神经网络模型,在进行分类时,声谱图像将被转换成一个表示每个像素的颜色的数字矩阵,之后数据经过卷积层、池化层以及全连接层等处理后转换成softmax分类器,这个分类器是一个由多个数字(如与儿歌细分类对应的21个数字)组成的向量,包含了卷积神经网络模型将各个歌曲细分类分配给声谱图的概率,最后选择其中最大概率位置的分类为最终识别分类。在其它实施例中,还可以选用其它类似神经网络模型进行歌曲分类。
S4、获取用户选择的目标类型下的当前歌曲,并将当前歌曲对应的声谱图输入训练好的歌曲分类模型,获得当前歌曲对应的当前细分类。
S5、根据当前细分类进行歌曲推荐。
通过对目标类型歌曲进行细分类,并获取各个细分类下的若干个歌曲文件,再将歌曲文件转换成训练声谱图,能够对歌曲分类模型进行训练;在用户选择目标类型下的一首歌曲时,将当前歌曲对应的声谱图输入到训练好的歌曲分类模型中,便能获得当前歌曲对应的当前细分类,从而可以根据当前细分类进行歌曲推荐。由于本方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,使得该方案的推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
实施例2
本发明的一个实施例,如图2所示,在实施例1的基础上,通过训练声谱图对歌曲分类模型进行训练之后,还包括步骤:
S31、通过训练好的歌曲分类模型对存储的目标类型下的所有歌曲进行细分类。
S32、为每个细分类建立歌曲相似模型,并通过歌曲相似模型提取各个细分类下所有歌曲的特征向量。
获得当前歌曲对应的当前细分类之后,还包括步骤:
S41、通过当前细分类对应的歌曲相似模型提取当前歌曲对应的特征向量。
S42、将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,获得相似度最高的目标歌曲并进行推荐。
具体的,为了更准确的推荐目标歌曲,可以在训练好歌曲分类模型时,对存储的目标类型下的所有歌曲进行细分类,并为每个细分类建立歌曲相似模型,再通过歌曲相似模型提取各个细分类下所有歌曲的特征向量;在确定当前歌曲的细分类后,通过当前细分类对应的歌曲相似模型提取当前歌曲对应的特征向量,将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,能够获得相似度最高的目标歌曲进行推荐,从而提高推荐的精准度。
优选的,通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较;将最大余弦相似性的歌曲作为目标歌曲进行推荐。
具体的,可以通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较。余弦相似性算法是将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来衡量这两个向量的相似性;夹角越小,余弦值越接近于1,两个向量就越相似。因此,可以用余弦相似性做为主要指标来对歌曲的相似度进行比较,将最大余弦相似性的歌曲作为目标歌曲进行推荐。
实施例3
本发明的一个实施例,在实施例2的基础上,获取各个细分类下的若干个歌曲文件,并将歌曲文件转换成训练声谱图,具体包括:
提取歌曲文件内的预设时间段的音频;将预设时间段的音频转换成完整声谱图;将完整声谱图平分成预设数量的训练声谱图。
将当前歌曲对应的声谱图输入训练好的歌曲分类模型,具体包括:
提取当前歌曲的预设时间段的音频;将当前歌曲对应的预设时间段的音频转换成预设数量的声谱图;将当前歌曲对应的预设数量的声谱图输入训练好的歌曲分类模型。
具体的,为了保证数据的统一性,可以提取歌曲文件内的预设时间段的音频,并将预设时间段的音频转换成完整声谱图,再将完整声谱图平分成预设数量的训练声谱图。例如以上述的儿歌分类为例,可以每首歌曲提取约2分钟的音频,然后转换成声谱图,然后将图片分256x 256像素的正方图,每张图大概5秒的音频,一首歌曲大概24张声谱图,处理分割后总共大概有25200张图,并为每张图做一个标签,标注分类。通过将每首歌拆分成24张声谱图,能够提高模型训练的精准度,避免偶然性。当然,在其它实施例中,可以根据实际需求进行声谱图的不同拆分。
优选的,通过歌曲相似模型提取各个细分类下所有歌曲的特征向量,具体包括:
提取各个细分类下所有歌曲的预设时间段的音频;将各个细分类下所有歌曲对应的预设时间段的音频转换成预设数量的声谱图;通过歌曲相似模型提取各个细分类下与各个歌曲的预设数量的声谱图对应的预设数量的特征向量;计算各个细分类下各个歌曲的平均向量。
通过当前细分类对应的歌曲相似模型提取当前歌曲对应的特征向量,具体包括:
通过当前细分类对应的歌曲相似模型提取与当前歌曲的预设数量的声谱图对应的预设数量的特征向量;计算当前歌曲对应的平均向量。
将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,具体包括:
将当前歌曲对应的平均向量与当前细分类下的各个歌曲的平均向量进行比较。
具体的,在提取特征向量时,为了提高精度,避免偶然性,可以按照同样方法获得一首歌对应的24个特征向量,再求得每首歌的平均向量,以平均向量作为评价标准来评价不同歌曲之间的相似度,能够做到最优推荐。
实施例4
本发明的一个实施例,如图3所示,本发明还提供一种歌曲推荐系统,包括第一分类模块1、获取模块2、训练模块3和推荐模块4。
第一分类模块1用于对目标类型歌曲进行细分类。
具体的,可以对一个大类型的歌曲进行细分类,如可以将儿歌分成摇篮曲、游戏歌、数数歌、问答歌、绕口令、连锁调、谜语歌、颠倒歌、字头歌、故事类、抒情类、幼儿园、胎教音乐、睡眠歌、磨耳朵、动画歌、贝瓦儿歌、三字经、古诗歌、英文儿歌、古典音乐等21个分类。当然,也可以按照其它标准进行分类。
获取模块2与第一分类模块1连接,用于获取各个细分类下的若干个歌曲文件,并将歌曲文件转换成训练声谱图。
在获取各个细分类下的若干个歌曲文件作为训练集时,为了提高模型的精准度,应每个细分类选择较多的歌曲文件。以上述儿歌为例,在本实施例中,每个细分类选择50个mp3歌曲文件,共1050个mp3文件。
音频文件内包含的信息很多,为了提取特征并去噪,可以把音频转换为图像形式,利用傅里叶变换法,将音频信号转换为频域,用这种方法处理1050个MP3音频文件,将每首歌提取转换成声谱图。声谱图就是声音频率的频谱随着时间变化的可视化表示,图谱中颜色的深浅表示该频率下的声音大小。
训练模块3与获取模块2连接,用于建立歌曲分类模型,并通过训练声谱图对歌曲分类模型进行训练。
在本实施例中,歌曲分类模型为Tensorflow卷积神经网络模型,在进行分类时,声谱图像将被转换成一个表示每个像素的颜色的数字矩阵,之后数据经过卷积层、池化层以及全连接层等处理后转换成softmax分类器,这个分类器是一个由多个数字(如与儿歌细分类对应的21个数字)组成的向量,包含了卷积神经网络模型将各个歌曲细分类分配给声谱图的概率,最后选择其中最大概率位置的分类为最终识别分类。在其它实施例中,还可以选用其它类似神经网络模型进行歌曲分类。
推荐模块4与训练模块3连接,用于获取用户选择的目标类型下的当前歌曲,并将当前歌曲对应的声谱图输入训练好的歌曲分类模型,获得当前歌曲对应的当前细分类,再根据当前细分类进行歌曲推荐。
通过第一分类模块1对目标类型歌曲进行细分类,并通过获取模块2获取各个细分类下的若干个歌曲文件,再将歌曲文件转换成训练声谱图,能够通过训练模块3对歌曲分类模型进行训练;在用户选择目标类型下的一首歌曲时,可以通过推荐模块4将当前歌曲对应的声谱图输入到训练好的歌曲分类模型中,便能获得当前歌曲对应的当前细分类,从而可以根据当前细分类进行歌曲推荐。由于本方案不需要获取用户行为、数据等,便能够根据歌曲本身的特征进行相似推荐,使得该方案的推荐精度更高,适用范围更广,能够满足不同类型人群的需求。
实施例5
本发明的一个实施例,如图3所示,在实施例4的基础上,歌曲推荐系统还包括第二分类模块5、第一提取模块6、第二提取模块7和比较模块8。
第二分类模块5用于通过训练好的歌曲分类模型对存储的目标类型下的所有歌曲进行细分类。
第一提取模块6用于为每个细分类建立歌曲相似模型,并通过歌曲相似模型提取各个细分类下所有歌曲的特征向量.
第二提取模块7用于通过当前细分类对应的歌曲相似模型提取当前歌曲对应的特征向量。
比较模块8用于将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,获得相似度最高的目标歌曲,推荐模块推荐目标歌曲。
具体的,为了更准确的推荐目标歌曲,可以在训练好歌曲分类模型时,通过第二分类模块5对存储的目标类型下的所有歌曲进行细分类,并为每个细分类建立歌曲相似模型,再通过第一提取模块6提取各个细分类下所有歌曲的特征向量;在确定当前歌曲的细分类后,可以通过第二提取模块7提取当前歌曲对应的特征向量,再通过比较模块8将当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较,能够获得相似度最高的目标歌曲进行推荐,从而提高推荐的精准度。
优选的,比较模块8通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行计算,并将最大余弦相似性的歌曲作为目标歌曲。
具体的,可以通过余弦相似性算法对当前歌曲对应的特征向量与当前细分类下的所有歌曲的特征向量进行比较。余弦相似性算法是将向量根据坐标值,绘制到向量空间中,求得它们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来衡量这两个向量的相似性;夹角越小,余弦值越接近于1,两个向量就越相似。因此,可以用余弦相似性做为主要指标来对歌曲的相似度进行比较,将最大余弦相似性的歌曲作为目标歌曲进行推荐。
另外,为了保证数据的统一性,可以提取歌曲文件内的预设时间段的音频,并将预设时间段的音频转换成完整声谱图,再将完整声谱图平分成预设数量的训练声谱图。例如以上述的儿歌分类为例,可以每首歌曲提取约2分钟的音频,然后转换成声谱图,然后将图片分256x 256像素的正方图,每张图大概5秒的音频,一首歌曲大概24张声谱图,处理分割后总共大概有25200张图,并为每张图做一个标签,标注分类。通过将每首歌拆分成24张声谱图,能够提高模型训练的精准度,避免偶然性。同时,在提取特征向量时,为了提高精度,避免偶然性,可以按照同样方法获得一首歌对应的24个特征向量,再求得每首歌的平均向量,以平均向量作为评价标准来评价不同歌曲之间的相似度,能够做到最优推荐。
实施例6
如图4所示,本发明实施例还提供一种智能设备,包括存储器100和处理器200,存储器100用于存放运行程序,处理器200用于执行存储器内存放的运行程序,以实现实施例1至实施例3任一实施例所述的歌曲推荐方法执行的操作。
具体的,智能设备还可以包括通信接口300、通信总线400和输入/输出接口500,其中,处理器200、存储器100、输入/输出接口500和通信接口300通过通信总线400完成相互间的通信。
通信总线400是连接所描述的元素的电路并且在这些元素之间实现传输。例如,处理器200通过通信总线400从其它元素接收到命令,解密接收到的命令,根据解密的命令执行计算或数据处理。存储器100可以包括程序模块,例如内核(kernel),中间件(middleware),应用程序编程接口(Application Programming Interface,API)和应用。该程序模块可以是有软件、固件或硬件、或其中的至少两种组成。输入/输出接口500转发用户通过输入输出设备(例如感应器、键盘、触摸屏)输入的命令或数据。通信接口300将该电子设备与其它网络设备、用户设备、网络进行连接。例如,通信接口300可以通过有线或无线连接到网络以连接到外部其它的网络设备或用户设备。无线通信可以包括以下至少一种:无线保真(WiFi),蓝牙(BT),近距离无线通信技术(NFC),全球卫星定位系统(GPS)和蜂窝通信等等。有线通信可以包括以下至少一种:通用串行总线(USB),高清晰度多媒体接口(HDMI),异步传输标准接口(RS-232)等等。网络可以是电信网络和通信网络。通信网络可以为计算机网络、因特网、物联网、电话网络。智能设备可以通过通信接口300连接网络,智能设备和其它网络设备通信所用的协议可以被应用、应用程序编程接口(API)、中间件、内核和通信接口至少一个支持。
实施例7
本发明实施例还提供一种存储介质,存储介质中存储有至少一条指令,指令由处理器加载并执行以实现实施例1至实施例3任一实施例的歌曲推荐方法所执行的操作。例如,计算机可读存储介质可以是只读内存(ROM)、随机存取存储器(RAM)、只读光盘(CD-ROM)、磁带、软盘和光数据存储设备等。它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种歌曲推荐方法、系统、智能设备及存储介质
- 一种歌曲推荐方法和歌曲推荐系统