一种自主分离的NVMe PRP获取加速方法
文献发布时间:2023-06-19 11:42:32
技术领域
本发明涉及存储领域,具体是一种自主分离的NVMe PRP获取加速方法。
背景技术
NVMe SSD是遵循非易失性内存主机控制器接口规范(Non-Volatile Memoryexpress)的固态驱动器(Solid State Disk)。SSD由控制器和存储器组成。一个优秀的NVMeSSD的控制器,能够充分利用PCIE通道的低延时以及并行性,在可控制的存储成本下,极大地提升固态硬盘的读写性能,降低由于AHCI接口带来的高延时,彻底解放SATA时代固态硬盘的极致性能。
在NVMe SSD和主机的数据交互中,PRP Entry和PRP List是不可或缺的关键因素。控制器获取Host的PRP Entry和PRP List的方式决定了SSD的性能。传统的NVMe SSD控制器中,多采用软件获取PRP Entry的方式,此方式对于命令处理有较大的延时。所以PRP Entry和PRP List的获取方式显得尤为重要。
PRP是指物理区域页面(Physical Region Range),PRP Entry实质是本质就是一个64位内存物理地址,只不过把这个物理地址分成两部分:页起始地址和页内偏移。最后两bit是0,说明PRP表示的物理地址只能四字节对齐访问。PRP页内偏移可以是0,也可以是个非零的值。
PRP Entry描述的是一段连续的物理内存的起始地址。如果需要描述若干个不连续的物理内存,则需要若干个PRP Entry。把若干个PRP Entry链接起来,就成了PRP List。
LBA是逻辑区块地址(Logical Block Address),LBA是描述计算机存储设备上数据所在区块的通用机制,一般用在像硬盘这样的辅助记忆设备。LBA Format是指LBA格式,根据不同的LBA格式,LBA Format可以是4K或其他数值,Number LBA是指LBA序号。
发明内容
本发明要解决的技术问题是提供一种自主分离的NVMe PRP获取加速方法,本方法可以显著提高固件对PRP Entry和PRP List的处理速度,为PRP Entry和PRP List的使用提供更高的便利性。
为了解决所述技术问题,本发明采用的技术方案是:一种自主分离的NVMe PRP获取加速方法,包括以下步骤:
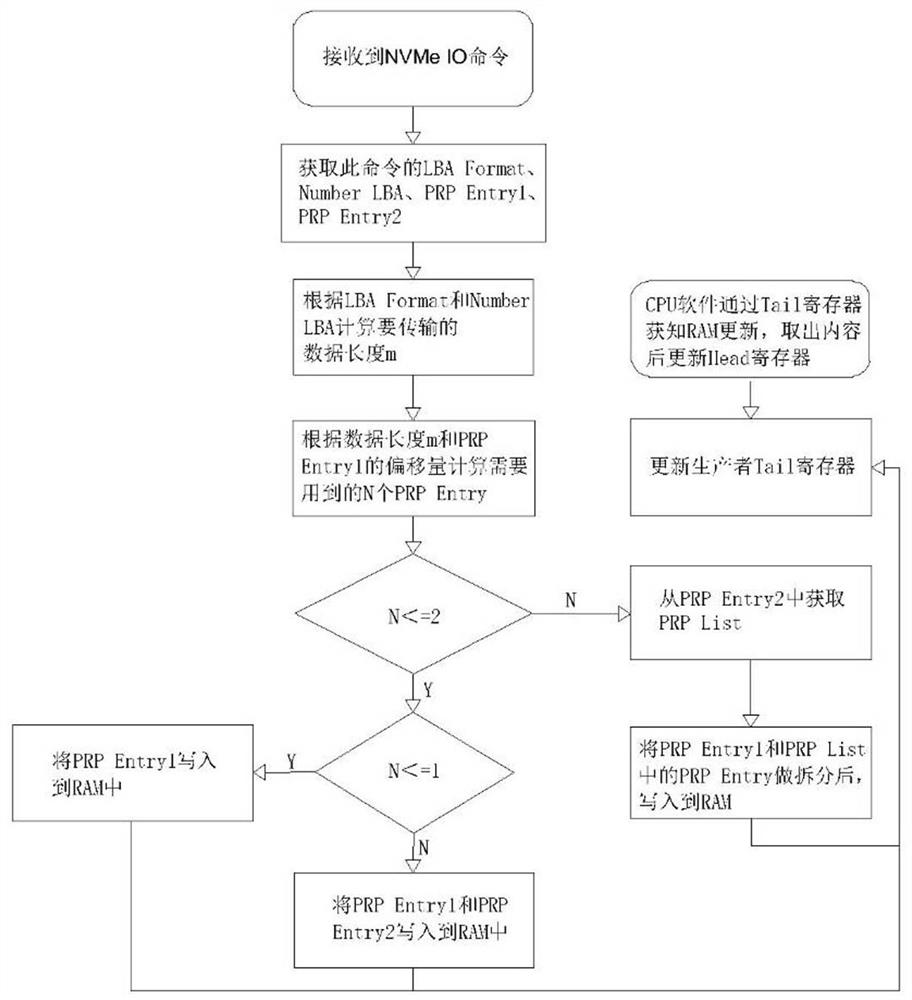
S01)、接收NVMe IO命令;
S02)、获取NVMe IO命令中的LBA Format、Number LBA、PRP Entry1、PRP Entry2,根据LBA Format和Number LBA计算要传输的数据长度m,m=LBA Format*Number LBA;
S03)、根据数据长度m和PRP Entry1的偏移量计算需要用到的N个PRP Entry,PRPEntry1的偏移量为0时,N=m/4K,PRP Entry1的偏移量不为0时,N=m/4K+1;
S04)、判断N≤2是否成立:
若N≤2不成立,从PRP Entry2中获取PRP List,将PRP Entry2和PRP List中的PRPEntry做拆分后,写入到RAM;
若N≤2成立,继续判断N≤1是否成立,若N≤1成立,将PRP Entry1写入到RAM中,若N≤1不成立,将PRP Entry1和PRP Entry2写入到RAM中。
进一步的,将NVMe IO命令中的PRP Entry1、PRP Entry2分别称为地址P1、地址P2,当P1偏移量为0时:
在m等于4k的情况下,使用P1即可传输完所有数据,将P1传输长度标记为L1,L1=4K,将P1和L1放入RAM队列中,传输数据长度为L1=4K;
在m等于8k的情况下,使用P1和P2即可传输完所有数据,将P1传输长度标记为L1,L1=4K;P2传输长度标记为L2,L2=4K,将P1、L1和P2、L2放入RAM队列中,传输数据长度为L1+L2=4K+4K=8K;
在m大于8k的情况下,使用P1和P2无法传输所有数据,则向PRP Entry2中按照q =(m-4k)/4k的数量获取PRR List,获取下来的PRP List中含有q个PRP Entry,记为P1、P2、···Pq,将各个PRP Entry传输长度都记为Lq,Lq=4K,此时将P1、L1和所有PRP Entry及其传输长度全部写入RAM队列,传输数据长度记为L,
进一步的,将NVMe IO命令中的PRP Entry1、PRP Entry2分别称为地址P1、地址P2,当P1偏移量不为0时,将P1偏移量记为O1:
则在m等于4k的情况下,使用P1、P2即可传输完所有数据,将P1传输长度标记为L1,L1=4K -O1,将P2传输长度记为L2,L2=O1,将P1、L1和P2、L2放入RAM队列中,传输数据长度为L1+L2=4K-O1+O1=4K;
在m等于8k的情况下,使用P1和P2无法传输所有数据,P1的传输长度记为L1,L1=4k-O1,向PRP Entry2中按照q = 2获取PRR List,获取下来的PRP List中含有2个PRPEntry且第一个PRP Entry记为Pq1,它的传输长度记为Lq1,Lq1=O1,将第一个PRP Entry加上O1的偏移记为Pq2,它的传输长度记为Lq2,Lq2=4k-O1,将第二个PRP Entry记为Pq3,它的传输长度记为Lq3,Lq3=O1;此时将P1、L1和所有Pqn、Lqn写RAM队列,n∈[1,3],传输数据长度为L1 + L2 + L3 = 4K-O1+O1+4K-O1+O1=8k;
在m大于8k的情况下,使用P1和P2无法传输所有数据,P1的传输长度记为L1,L1=4k-O1,向PRP Entry2中按照q = (m-4k)/4k + 1的数量获取PRR List,获取下来的PRPList中含有q个PRP Entry且第一个PRP Entry记为Pq1,它的传输长度记为Lq1,Lq1=O1,将第一个PRP Entry加上O1的偏移记为Pq2,它的传输长度记为Lq2,Lq2=4k-O1,将第二个PRPEntry记为Pq3,它的传输长度记为Lq3,Lq3=O1,将第二个PRP Entry加上O1的偏移记为Pq4,它的传输长度记为Lq4,Lq4=O1,依次类推,直到将最后一个PRP Entry拆分为Pqn和Lqn,将P1、L1和所有Pqi、Lqi写RAM队列,n∈[1,n],传输数据长度为L1 +
进一步的,所述方法在SSD控制器单独设置的硬件模块中运行,硬件模块自带RAM,获取的NVMe PRP及其传输长度写入硬件模块自身的RAM中。
进一步的,硬件模块使用Tail寄存器表征队列的生产者指针,当硬件模块写入RAM时,更新此寄存器;CPU使用Head寄存器表征消费者指针,当软件读出RAM时,更新Head寄存器。
进一步的,LBA Format为4K。
本发明的有益效果:本发明充分考虑了PRP Entry1对齐和不对齐时的各种传输长度。能够获取准确获取PRP Entry个数并将其自主拆分为可以传输不同长度数据的地址。有效减少了软件拆分PRP Entry的步骤,也就将传统的CPU获取PRP Entry方式进行了替代,加速了软件对于NVMe 命令中PRP的获取,减少了IO命令处理的延时。本发明采用单独的硬件实施本方法,可以显著提高固件对PRP Entry和PRP List的处理速度,为软件对于PRPEntry和PRP List的使用提供更高的便利性。
附图说明
图1为本方法的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
实施例1
本实施例公开一种自主分离的NVMe PRP获取加速方法,如图1所示,包括以下步骤:
S01)、接收NVMe IO命令;
S02)、获取NVMe IO命令中的LBA Format、Number LBA、PRP Entry1、PRP Entry2,根据LBA Format和Number LBA计算要传输的数据长度m,m=LBA Format*Number LBA;
S03)、根据数据长度m和PRP Entry1的偏移量计算需要用到的N个PRP Entry,PRPEntry1的偏移量为0时,N=m/4K,PRP Entry1的偏移量不为0时,N=m/4K+1;
S04)、判断N≤2是否成立:
若N≤2不成立,从PRP Entry2中获取PRP List,将PRP Entry2和PRP List中的PRPEntry做拆分后,写入到RAM;
若N≤2成立,继续判断N≤1是否成立,若N≤1成立,将PRP Entry1写入到RAM中,若N≤1不成立,将PRP Entry1和PRP Entry2写入到RAM中。
本实施例中,物理内存页为4K,则一个PRP Entry在偏移为0的情况下,可传输4K大小的数据。控制器收到NVMe IO命令时,该IO命令中含有PRP Entry1和PRP Entry2,在此分别称为地址P1、地址P2;含有Number LBA称作为nlb;也有nsid,通过nsid则可以获取到该命令所在ns的LBA Format。本实施例中,LBA Format为4K,则要传输的Data长度m=nlb*4K。
本实施例所述方法在SSD控制器单独设置的硬件模块中运行,硬件模块自带RAM,获取的NVMe PRP及其传输长度写入硬件模块自身的RAM中。
硬件模块使用Tail寄存器表征队列的生产者指针,当硬件模块写入RAM时,更新此寄存器;CPU使用Head寄存器表征消费者指针,当软件读出RAM时,更新Head寄存器。
当P1偏移量为0时:
在m等于4k的情况下,使用P1即可传输完所有数据,将P1传输长度标记为L1,L1=4K,此时硬件模块将P1和L1放入RAM队列中,传输数据长度为L1=4K,更新Tail寄存器。
在m等于8k的情况下,使用P1和P2即可传输完所有数据,将P1传输长度标记为L1,L1=4K;P2传输长度标记为L2,L2=4K,Entry,记为P1、P2、···Pq,将各个PRP Entry传输长度都记为Lq,Lq=4K,此时硬件模块将P1、L1和P2、L2放入RAM队列中,传输数据长度为L1+L2=4K+4K=8K,更新Tail寄存器。
在m大于8k的情况下,使用P1和P2无法传输所有数据,则向PRP Entry2中按照q =(m-4k)/4k的数量获取PRR List,获取下来的PRP List中含有q个PRP Entry,记为P1、P2、···Pq,将各个PRP Entry传输长度都记为Lq,Lq=4K,此时硬件模块将P1、L1和所有PRP Entry及其传输长度全部写入RAM队列,传输数据长度记为L,
当P1偏移量不为0时,将P1偏移量记为O1:
则在m等于4k的情况下,使用P1、P2即可传输完所有数据,将P1传输长度标记为L1,L1=4K -O1,将P2传输长度记为L2,L2=O1,此时硬件模块将P1、L1和P2、L2放入RAM队列中,传输数据长度为L1+L2=4K-O1+O1=4K,更新Tail寄存器。
在m等于8k的情况下,使用P1和P2无法传输所有数据,P1的传输长度记为L1,L1=4k-O1,向PRP Entry2中按照q = 2获取PRR List,获取下来的PRP List中含有2个PRPEntry且第一个PRP Entry记为Pq1,它的传输长度记为Lq1,Lq1=O1,将第一个PRP Entry加上O1的偏移记为Pq2,它的传输长度记为Lq2,Lq2=4k-O1,将第二个PRP Entry记为Pq3,它的传输长度记为Lq3,Lq3=O1;此时硬件模块将P1、L1和所有Pqn、Lqn写RAM队列,n∈[1,3],传输数据长度为L1 + L2 + L3 = 4K-O1+O1+4K-O1+O1=8k,更新Tail寄存器。在此过程中,硬件模块将3个PRP Entry自主拆分为4组Pi、Li,i={1,q1, q2, q3}。
在m大于8k的情况下,使用P1和P2无法传输所有数据,P1的传输长度记为L1,L1=4k-O1,向PRP Entry2中按照q = (m-4k)/4k + 1的数量获取PRR List,获取下来的PRPList中含有q个PRP Entry且第一个PRP Entry记为Pq1,它的传输长度记为Lq1,Lq1=O1,将第一个PRP Entry加上O1的偏移记为Pq2,它的传输长度记为Lq2,Lq2=4k-O1,将第二个PRPEntry记为Pq3,它的传输长度记为Lq3,Lq3=O1,将第二个PRP Entry加上O1的偏移记为Pq4,它的传输长度记为Lq4,Lq4=O1,依次类推,直到将最后一个PRP Entry拆分为Pqn和Lqn,将P1、L1和所有Pqi、Lqi写RAM队列,n∈[1,n],传输数据长度为L1 +
在此过程中,总共有n+1组Pi、Li,硬件模块将q+1个PRP Entry自主拆分为n+1组Pi、Li,n=2q,i={1,q1, q2, ···,qn}。
本实施例所述方法充分考虑了PRP Entry1对齐和不对齐时的各种传输长度。能够获取准确获取PRP Entry个数并将其自主拆分为可以传输不同长度数据的地址。有效减少了软件拆分PRP Entry的步骤,也就将传统的CPU获取PRP Entry方式进行了替代,加速了软件对于NVMe 命令中PRP的获取,减少了IO命令处理的延时。
以上描述的仅是本发明的基本原理和优选实施例,本领域技术人员根据本发明做出的改进和替换,属于本发明的保护范围。
- 一种自主分离的NVMe PRP获取加速方法
- 一种NVMe固态硬盘写加速的方法