管理完成时刻的存储控制器及其操作方法
文献发布时间:2023-06-19 11:45:49
相关申请的交叉引用
本申请要求于2019年12月23日在韩国知识产权局提交的韩国专利申请No.10-2019-0172650的优先权,该申请的公开以引用方式全文并入本文中。
技术领域
根据本公开的方法、装置和设备涉及一种半导体存储器,并且更具体地说,涉及一种管理完成时刻的存储控制器及其操作方法。
背景技术
半导体存储器装置分为易失性存储器装置和非易失性存储器装置,在易失性存储器装置中,存储的数据在断电时消失,在非易失性存储器装置中,即使断电,存储的数据也会被保留。闪速存储器作为一种非易失性存储器装置被广泛地用作大容量存储介质。现有接口(如串行高级技术连接(SATA)接口、快速外围组件互连(PCIe)接口和串行连接SCSI(SAS)接口)适用于诸如基于闪速存储器的固态驱动器(SSD)的数据存储装置,但对数据存储装置的应用有一个基本的限制。
因此,正在开发针对基于非易失性存储器的存储装置优化的快速非易失性存储器(NVMe)接口。然而,随着应用了NVMe接口的存储装置的性能提高,管理处理后的数据的主机的开销也增加了。通常,这导致主机在管理处理后的数据的同时会使主机将要处理的另一处理延迟。
发明内容
一方面是提供一种存储控制器及其操作方法,所述存储控制器管理完成时刻,使得在基于主机的延迟信息确定的时刻写完成。
根据示例性实施例的一方面,提供了一种操作存储控制器的方法,所述存储控制器被配置为与包括提交队列和完成队列的主机通信,所述方法包括步骤:从主机接收提交队列门铃;响应于接收到的提交队列门铃,从主机的提交队列取回包括延迟的第一命令;处理取回的第一命令;以及在基于延迟的时刻将指示完全处理第一命令的第一完成写至主机的完成队列。
根据示例性实施例的另一方面,提供了一种操作存储控制器的方法,所述存储控制器被配置为与包括提交队列和完成队列的主机通信,所述方法包括步骤:从主机接收第一提交队列门铃和第二提交队列门铃;响应于接收到的第一提交队列门铃,从主机的提交队列取回包括第一延迟的第一命令;响应于接收到的第二提交队列门铃,从主机的提交队列取回包括第二延迟的第二命令;处理取回的第一命令;在基于第一延迟的第一时刻将指示完全处理第一命令的第一完成写至主机的完成队列中;处理取回的第二命令;以及在基于第二延迟的第二时刻,将指示完全处理第二命令的第二完成写至主机的完成队列中。
根据示例性实施例的又一方面,提供了一种存储控制器,包括:命令管理器,其从主机接收第一提交队列门铃,响应于接收到的第一提交队列门铃从主机的提交队列取回包括第一延迟的第一命令,并且基于第一延迟确定将第一完成写至主机的完成队列的第一时刻,第一完成指示完全处理第一命令;以及直接存储器访问(DMA)引擎,其被配置为从命令管理器接收请求处理第一命令的请求信号,响应于请求信号基于DMA转移转移第一命令请求的数据,以及将指示完全处理第一命令的完成信号输出至命令管理器。
附图说明
通过参照附图详细描述示例性实施例,以上和其它方面将变得清楚,其中:
图1是示出根据实施例的存储系统的框图;
图2是示出根据实施例的图1的存储系统的主机的框图;
图3是示出根据实施例的图1的存储系统的存储控制器的框图;
图4是示出根据实施例的存储系统的操作方法的流程图;
图5是示出根据实施例的图4的操作方法中的待写至提交队列中的命令的信息的图;
图6A是示出根据实施例的执行图4的操作方法的存储系统的框图;
图6B是示出根据实施例的图6A的存储系统的主机和存储控制器的处理的时序图;
图7A是示出根据实施例的执行图4的操作方法的存储系统的框图;
图7B是示出根据实施例的图7A的存储系统的主机和存储控制器的处理的时序图;
图8A是示出根据实施例的执行图4的操作方法的存储系统的框图;
图8B是示出根据实施例的图8A的存储系统的主机和存储控制器的处理的时序图;
图9是示出根据实施例的存储系统的操作方法的流程图;
图10是示出根据实施例的执行图9的操作方法的存储系统的框图;
图11是示出根据实施例的存储系统的操作方法的流程图;
图12是示出根据实施例的执行图11的操作方法的存储系统的框图;
图13是示出根据实施例的主机的处理的时序图。
具体实施方式
下面,将详细和清楚地描述各个实施例,使得本领域普通技术人员可以容易地实施各种实施例。
图1是示出根据实施例的存储系统的框图。参照图1,存储系统1可以包括主机10和存储装置100。在示例性实施例中,存储系统1可以是计算系统,其被配置为处理各种信息,诸如个人计算机(PC)、笔记本、笔记本电脑、服务器、工作站、平板PC、智能电话、数码相机或者黑盒子。
主机10可以控制存储系统1的整体操作。例如,主机10可以将数据存储至存储装置100中,或者可以读取存储在存储装置100中的数据。主机10可以包括主机处理器11和主机存储器缓冲器12。
主机处理器11可以是控制存储系统1的操作的装置。例如,主机处理器11可以包括输出用于处理数据的命令(例如,读命令或写命令)的中央处理单元(CPU)。
主机存储器缓冲器12可以包括命令缓冲器12a和直接存储器访问(DMA)缓冲器12b。主机存储器缓冲器12可以是存储主机10处理的数据的装置。命令缓冲器12a可以包括提交队列SQ和完成队列CQ。提交队列SQ可以存储主机处理器11产生的命令。完成队列CQ可以存储指示完全处理了命令的完成。
DMA缓冲器12b可以存储基于直接存储器访问(DMA)转移处理的数据。直接存储器访问转移可以表示在主机处理器11的中央处理单元不干预的情况下,将数据按照直接存储器访问方式转移。
在示例性实施例中,主机处理器11可以产生关于主机想要接收完成的时间点的延迟信息(下文中称作“延迟”)。主机处理器11可以将包括延迟的命令写至提交队列SQ中。
在主机10的控制下,存储装置100可以存储数据,或者可以将存储的数据提供至主机10。存储装置100可以包括存储控制器110和非易失性存储器装置120。
存储控制器110可以将数据存储至非易失性存储器装置120中,或者可以读存储在非易失性存储器装置120中的数据。在存储控制器110的控制下,非易失性存储器装置120可以存储数据,或者可以输出存储的数据。例如,非易失性存储器装置120可以包括存储数据的NAND闪速存储器。非易失性存储器装置120可以是一种即使断电也保留存储在其中的数据的装置,诸如相变随机存取存储器(PRAM)、磁性RAM(MRAM)、电阻RAM(RRAM)或者铁电RAM(FRAM)等。
存储控制器110可以包括命令管理器111和DMA引擎112。命令管理器111可以是管理从主机10接收的命令的装置。命令管理器111可以包括延迟计算器111a和定时控制器111b。延迟计算器111a可以基于命令中包括的延迟的信息计算写完成的时间点。定时控制器111b可以基于由延迟计算器111a计算的时间点确定写完成的时刻。DMA引擎112可以对主机10输出的命令执行直接存储器访问操作。
如上所述,根据实施例,可以通过产生包括处理完成的时间点的信息的延迟和在基于延迟确定的时刻写所述完成来提供管理写所述完成的时刻的存储系统1。
图2是示出根据实施例的图1的存储系统1的主机的框图。参照图2,主机10可以包括主机处理器11、主机存储器缓冲器12、存储接口电路13和主机总线14。主机总线14可以包括连接主机处理器11、主机存储器缓冲器12和存储接口电路13的装置。
主机处理器11可以输出包括延迟的命令。主机处理器11可以接收指示完全处理命令的完成。除输出命令和接收完成之外,主机处理器11可以执行单独的处理。主机存储器缓冲器12可以包括命令缓冲器12a和DMA缓冲器12b。命令缓冲器12a可以包括提交队列SQ和完成队列CQ。
主机10可以通过存储接口电路13与存储装置100通信。在示例性实施例中,存储接口电路13可以基于快速非易失性存储器(NVMe)接口实施为转移命令。另外,存储接口电路13可以实施为基于直接存储器访问转移与非易失性存储器装置120通信。
图3是示出根据实施例的图1的存储系统1的存储控制器的框图。参照图3,存储控制器110可以包括命令管理器111、DMA引擎112、处理器113、静态随机存取存储器(SRAM)114、只读存储器(ROM)115、错误校正码(ECC)引擎116、主机接口电路117、非易失性存储器接口电路118和存储控制器总线119。存储控制器总线119可以是将存储控制器110中包括的命令管理器111、DMA引擎112、处理器113、静态随机存取存储器(SRAM)114、只读存储器(ROM)115、ECC引擎116、主机接口电路117和非易失性存储器接口电路118互相连接的装置。命令管理器111和DMA引擎112的特征与参照图1描述的那些相似,因此,为了简洁和避免冗余,将省略重复的描述。
处理器113可以控制存储控制器110的整体操作。SRAM 114可以用作存储控制器110的缓冲器存储器、高速缓冲存储器或者工作存储器。ROM 115可以存储固件形式的用于存储控制器110操作的各种信息。ECC引擎116可以检测和校正从非易失性存储器装置120读取的数据的错误。
在示例性实施例中,命令管理器111和DMA引擎112可以以软件、硬件或者其组合的方式实施。例如,ROM 115可以存储命令管理器111的操作方法和DMA引擎112的操作方法。SRAM 114可以存储从主机10接收的命令和DMA引擎112处理的数据。处理器113从ROM115中读操作方法(例如,程序代码)和执行操作方法,以控制命令管理器111和DMA引擎112。
存储控制器110可以通过主机接口电路117与主机10通信。在示例性实施例中,主机接口电路117可以实施为基于NVMe接口转移完成。另外,主机接口电路117可以实施为基于直接存储器访问转移与主机10通信。
存储控制器110可以通过非易失性存储器接口电路118与非易失性存储器装置120通信。在示例性实施例中,非易失性存储器接口电路118可以实施为基于直接存储器访问转移与非易失性存储器装置120通信。
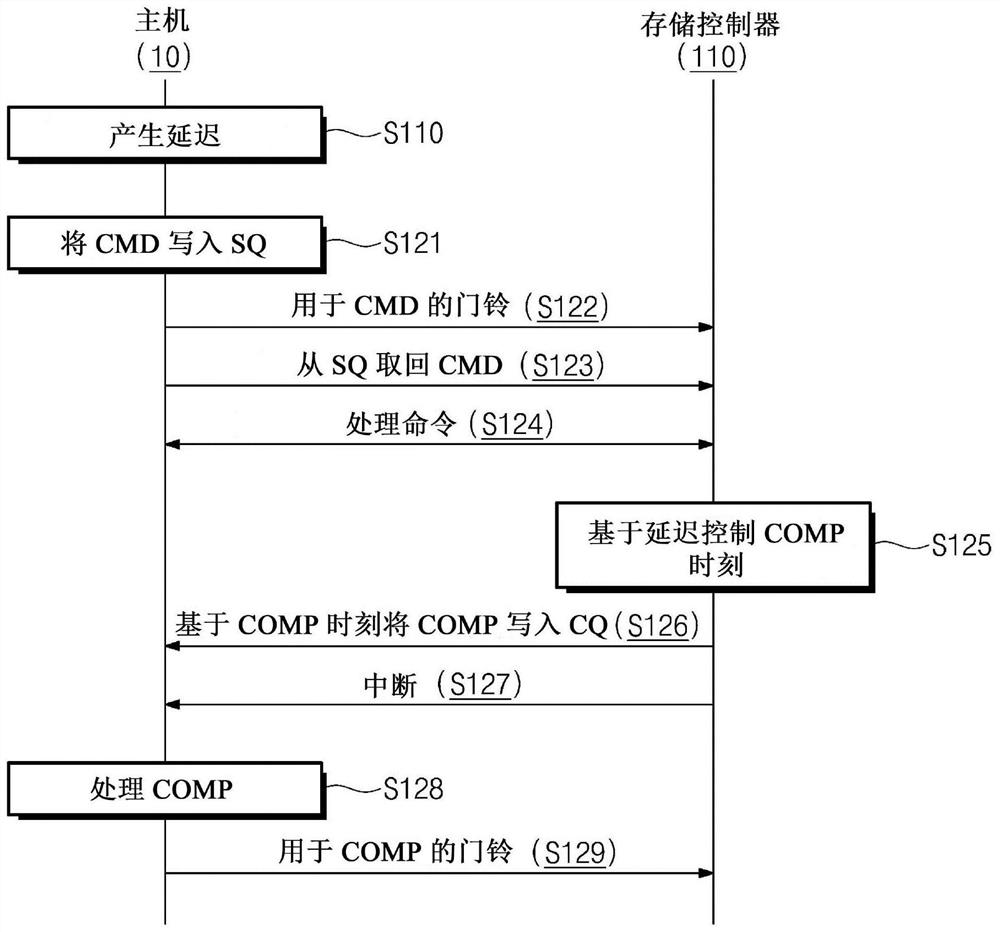
图4是示出根据实施例的存储系统的操作方法的流程图。图4中例示了包括主机10和存储控制器110的存储系统1的操作方法。
在操作S110中,主机10可以产生延迟。延迟可以包括关于主机想要存储控制器110将完成COMP写至主机10的完成队列CQ的时间点的信息。主机10可以控制关于延迟中包括的时间点的信息,因此可以在对主机10执行的另一处理的影响较小的时间点接收完成COMP。也就是说,主机10可以通过控制接收完成COMP的时刻有效地执行任何其它处理。
在一些示例性实施例中,延迟可以包括处理延迟PL。处理延迟PL可以指示从当存储控制器110取回存储在提交队列SQ中的命令CMD的时间点至当指示完全处理命令CMD的完成COMP写入完成队列CQ中的时间点的时间段。将参照图6A和图6B一起更完全地描述如何基于处理延迟PL确定时刻。
在一些示例性实施例中,延迟可以包括间隔延迟IL。间隔延迟IL可以指示从当另一完成写入完成队列CQ中的时间点至当完成COMP写入完成队列CQ中的时间点的时间间隔(或者时间段)。换句话说,间隔延迟IL可以指示从一个完成COMP至另一个完成COMP(即,完成至完成)的时间间隔。在这种情况下,可以在将指示命令CMD已完全处理的完成COMP写入完成队列CQ的操作之前执行将指示另一命令已完全处理的另一完成写入完成队列CQ的操作。将参照图7A和图7B一起更完全地描述如何基于间隔延迟IL确定时刻。
在一些示例性实施例中,延迟可以包括处理延迟PL和间隔延迟IL二者。可以基于处理延迟PL和间隔延迟IL确定将完成COMP写至完成队列CQ的时刻。这一点将参照图8A和图8B一起更完全地描述。
在操作S121中,主机10可以将命令CMD写至提交队列SQ。在这种情况下,命令CMD可以包括在操作S110中产生的延迟。命令CMD可以是用于将数据存储在非易失性存储器装置120中或者读存储在非易失性存储器装置120中的数据的命令。
在操作S122中,主机10可以将提交队列门铃转移至存储控制器110。提交队列门铃可以是指示命令CMD被写至提交队列SQ中的信号。所述信号向存储控制器110指示存在待处理的命令。
在操作S123中,存储控制器110可以响应于在操作S122中接收的提交队列门铃取回写入提交队列SQ中的命令CMD。在这种情况下,取回命令CMD可以表示存储控制器110找回存储在提交队列SQ中的命令CMD。在一些示例性实施例中,提交队列SQ可以通过存储控制器110的取回操作清空。提交队列SQ的清空状态可以表示新命令能够写入提交队列SQ中的状态。
在操作S124中,存储控制器110可以处理在操作S123中取回的命令CMD。在示例性实施例中,命令CMD请求的数据可以按照直接存储器访问方式转移。
在操作S125中,存储控制器110可以基于在操作S123中取回的命令CMD中包括的延迟确定将完成COMP写入完成队列CQ中的时刻。在一些示例性实施例中,操作S125可以与操作S124并行地执行。
在操作S126中,存储控制器110可以基于在操作S125中确定的时刻将完成COMP写至完成队列CQ。在这种情况下,可以在取回的命令CMD的处理(S124)完成之后执行操作S126。
在操作S127中,存储控制器110可以产生通知主机10完成COMP已写入完成队列CQ中的中断。存储控制器110可以将产生的中断输出至主机10。在一些示例性实施例中,存储控制器110可以产生指示多个完成已被写入多个完成队列中的中断,即,批中断。例如,在执行操作S126之后不立即输出中断,存储控制器110可以在另一完成写至完成队列CQ中之后将输出中断。
在操作S128中,主机10可以响应于操作S127中接收的中断处理完成COMP。主机10可以获得指示在操作S121中命令CMD请求的操作已完成的信息。在示例性实施例中,主机10可以清空对应于中断的完成队列CQ。完成队列CQ的清空状态可以表示新完成能够被写入完成队列CQ中的状态。在操作S121中,主机10可以将另一命令分配至对应于命令CMD的提交队列SQ和完成队列CQ。
在操作S129中,主机10可以产生向存储控制器110通知写入完成队列CQ中的完成COMP被处理的完成队列门铃。主机10可以将产生的完成队列门铃输出至存储控制器110。在示例性实施例中,接收完成队列门铃的存储控制器110可以将指示已完全处理与命令CMD不同的命令的另一完成写至完成队列CQ。
如上所述,根据实施例,可以有一种在基于主机10产生的延迟确定的时刻将完成COMP写至完成队列CQ的存储系统的操作方法。另外,可以提供一种基于NVMe接口管理写完成COMP的时刻的存储系统的操作方法。
图5是示出根据实施例的图4的操作方法中的待写至提交队列中的命令的信息的图。图5中例示了主机10产生的命令CMD的信息。命令CMD可以具有给定容量的区域/大小。例如,命令CMD可以具有64字节的容量。一般的命令CMD可以包括作为与数据处理无关的区域的保留区域。例如,在图5所示的示例中,保留区域可以是从字节8至字节15的区域。
根据实施例,可以提供在保留区域中包括延迟的存储系统1。例如,在一些示例性实施例中,命令CMD的保留区域的对应于字节8至字节11的范围的区域可以包括处理延迟PL。在一些示例性实施例中,命令CMD的保留区域的对应于字节12至字节15的范围的区域可以包括间隔延迟IL。然而,这仅是示例,并且如上所述,在一些示例性实施例中,可以仅提供处理延迟PL或者间隔延迟IL之一。此外,在一些示例性实施例中,分配至处理延迟PL和间隔延迟IL的命令CMD的特定字节可以与图5所示的那些不同。
图6A是示出根据实施例的执行图4的操作方法的存储系统的框图。图6A中例示了基于处理延迟PL确定时刻的存储系统。存储系统可包括主机10、存储控制器110和非易失性存储器装置120。
主机10可以包括主机处理器11、命令缓冲器12a和DMA缓冲器12b。命令缓冲器12a可以包括存储命令CMD的提交队列SQ和存储完成COMP的完成队列CQ。
主机处理器11可以产生处理延迟PL。处理延迟PL可以指示从当存储控制器110取回存储在提交队列SQ中的命令CMD时的时间点至当存储控制器110将指示命令CMD被完全处理的完成COMP写至完成队列CQ中时的时间点的时间段。
主机处理器11可以将包括处理延迟PL的命令CMD写至提交队列SQ中。主机处理器11可以将指示命令CMD被写至提交队列SQ中的提交队列SQ门铃输出至命令管理器111。
主机处理器11可以响应于从命令管理器111接收到的中断处理存储在完成队列CQ中的完成COMP。主机处理器11可以将指示写入完成队列CQ中的完成COMP已由主机处理的完成队列CQ门铃输出至命令管理器111。
命令管理器111可以包括延迟计算器111a、定时控制器111b、门铃寄存器电路111c、命令取回电路111d、完成产生器111e和中断产生器111f。
延迟计算器111a可以基于命令CMD中包括的处理延迟PL计算写完成COMP的时间点。在示例性实施例中,延迟计算器111a可以通过从当取回命令CMD时的时间点加上对应于处理延迟PL的时间段来计算写完成COMP的时间点。定时控制器111b可以基于由延迟计算器111a计算的时间点确定写完成COMP的时刻。
门铃寄存器电路111c可以从主机处理器11接收提交队列SQ门铃和完成队列CQ门铃。门铃寄存器电路111c可以控制命令取回电路111d,以响应于提交队列门铃取回命令CMD。响应于完成队列CQ门铃,门铃寄存器电路111c可以将指示完成队列CQ为空的信号输出至完成产生器111e。
命令取回电路111d可以在门铃寄存器电路111c的控制下取回存储在提交队列SQ中的命令CMD。命令取回电路111d可以基于取回的命令CMD输出请求DMA引擎112处理数据的信号。
完成产生器111e可以从DMA引擎112接收指示对应于命令CMD的数据已完全处理的信号。完成产生器111e可以响应于指示数据已完全处理的信号产生完成COMP。完成产生器111e可以基于定时控制器111b确定的时刻将完成COMP写至完成队列CQ。完成产生器111e可以将指示已写完成COMP的信号输出至中断产生器111f。
中断产生器111f可以响应于指示已写完成COMP的信号产生中断。中断产生器111f可以将产生的中断输出至主机处理器11。
DMA引擎112可以从命令取回电路111d接收请求数据处理的请求信号。DMA引擎112可以与DMA缓冲器12b和非易失性存储器装置120连接。
不用主机处理器11直接控制,DMA引擎112可以将数据存储至非易失性存储器装置120中,或者可以读存储在非易失性存储器装置120中的数据。也就是说,可以基于直接存储器访问转移在DMA缓冲器12b与非易失性存储器装置120之间处理对应于命令CMD的数据。在完成对应于命令CMD的数据的处理之后,DMA引擎112可以将指示数据处理完成的完成信号输出至完成产生器111e。
如上所述,根据实施例,可以提供其中主机10产生处理延迟PL并且在基于处理延迟PL确定的时刻写完成COMP的存储系统。
图6B是示出根据实施例的执行图6A的操作方法的存储系统的主机和存储控制器的处理的时序图。参照图6A和图6B,主机10可以按次序执行以下步骤:产生处理延迟PL;将命令CMD写至提交队列SQ中;以及输出指示已写命令CMD的提交队列SQ门铃。
存储控制器110可以按次序执行以下步骤:接收提交队列SQ门铃;取回命令CMD;以及基于直接存储器访问转移处理由命令CMD请求的数据。在这种情况下,作为现有技术的存储系统中在完成数据处理之后立即写完成COMP的替代,存储控制器110可以在基于处理延迟PL确定的完成时间点Tc写完成COMP。换句话说,存储控制器110可以延迟写完成COMP直到主机10准备好接收完成COMP。基于处理延迟PL确定的完成时间点Tc可以是从当从提交队列SQ中取回命令CMD时的取回时间点Tf过去了对应于处理延迟PL的时间段的时间点。在完成时间点Tc,存储控制器110可以将完成COMP写至完成队列CQ。
存储控制器110可以在存储控制器110在完成时间点Tc将完成COMP写至完成队列CQ中之后输出中断。主机10可以接收中断和在接收中断之后处理写至完成队列CQ中的完成COMP。主机10可以输出完成队列CQ门铃,并且存储控制器110可以接收CQ门铃。在这种情况下,当主机10处理完成COMP时的时间点可以是在主机10将另一命令CMD写至提交队列SQ之前确定的时间点。由于主机10控制时间点以精确处理完成COMP,主机10可以在处理完成COMP之前执行另一处理而不受阻碍。
图7A是示出根据实施例的执行图4的操作方法的存储系统的框图。图7A中例示了基于间隔延迟IL确定时刻的存储系统。DMA缓冲器12b、定时控制器111b、门铃寄存器电路111c、命令取回电路111d、完成产生器111e、中断产生器111f、DMA引擎112和非易失性存储器装置120的特征与参照图6A描述的那些相似,因此,为了简洁和避免冗余,将省略重复的描述。
主机10可以包括主机处理器11、命令缓冲器12a和DMA缓冲器12b。命令缓冲器12a可以包括还存储另一命令(下文中称作“前一个命令”)的提交队列SQ以及还存储另一完成(下文中称作“前一个完成”)的完成队列CQ。在这种情况下,另一完成COMPx(下文中称作“前一个完成COMPx”)可以指示所述前一个命令已完全处理。
主机处理器11可以产生间隔延迟IL。间隔延迟IL可以指示从当所述前一个完成COMPx写至完成队列CQ时的时间点至当完成COMP写至完成队列CQ时的时间点的时间间隔(或者时间段)。在这种情况下,可以在写所述完成COMP的操作之前执行写所述前一个完成COMPx的操作。
主机处理器11可以将包括间隔延迟IL的命令CMD写至提交队列SQ。主机处理器11可以将指示命令CMD被写至提交队列SQ中的提交队列SQ门铃输出至命令管理器111。
延迟计算器111a可以基于在命令CMD中包括的间隔延迟IL计算写完成COMP的时间点。在示例性实施例中,延迟计算器111a可以通过从写所述前一个完成COMPx的时间点加上对应于间隔延迟IL的时间段来计算写完成COMP的时间点。
如上所述,根据实施例,可以提供在基于间隔延迟IL确定的时刻写完成COMP的存储系统。
图7B是示出根据实施例的执行图7A的操作方法的存储系统的主机和存储控制器的处理的时序图。参照图7A和图7B,主机10可以按次序执行以下步骤:产生间隔延迟IL;将命令CMD写至提交队列SQ;以及输出指示已写命令CMD的提交队列SQ门铃。
存储控制器110可以在另一完成时间点Tcx(下文中称作“前一个完成时间点Tcx”)写所述前一个完成COMPx。所述前一个完成时间点Tcx可以是基于主机10产生的另一延迟确定的时间点。换句话说,所述前一个完成时间点Tcx可以是基于用于主机10产生的前一个命令(例如,具有图6A和图6B所示的处理延迟PL的先前产生的命令)的前一个延迟确定的时间点。存储控制器110可以按次序执行以下步骤:接收提交队列SQ门铃;取回命令CMD;以及基于直接存储器访问转移处理命令CMD请求的数据。
在这种情况下,在完成数据处理之后不立即写完成COMP,存储控制器110可以在基于间隔延迟IL确定的完成时间点Tc写完成COMP。基于间隔延迟IL确定的完成时间点Tc可以是当从所述前一个完成时间点Tcx过去了对应于间隔延迟IL的时间段时的时间点。存储控制器110可以在这样确定的时间点Tc写完成COMP。
存储控制器110可以在存储控制器110在完成时间点Tc将完成COMP写至完成队列CQ之后输出中断。主机10可以接收中断并且在接收中断之后处理写至完成队列CQ中的完成COMP。主机10可以输出完成队列CQ门铃,并且存储控制器110可以接收CQ门铃。在这种情况下,当主机10处理完成COMP时的时间点可以是在主机10将另一命令CMD写至提交队列SQ之前确定的时间点。由于主机10精确地控制处理完成COMP的时间点,因此在处理所述前一个完成COMPx之后和处理完成COMP之前,主机10可以执行另一处理而不受阻碍。可替换地,可以根据用于执行另一处理的时间点调整间隔延迟IL。
图8A是示出根据实施例的执行图4的操作方法的存储系统的框图。图8A中例示了基于处理延迟PL和间隔延迟IL确定时刻的存储系统。DMA缓冲器12b、定时控制器111b、门铃寄存器电路111c、命令取回电路111d、完成产生器111e、中断产生器111f、DMA引擎112和非易失性存储器装置120的特征与参照图6A描述的那些相似,因此,为了简洁和避免冗余,将省略重复的描述。
主机处理器11可以产生处理延迟PL和间隔延迟IL。主机处理器11可以将包括处理延迟PL和间隔延迟IL的命令CMD写至提交队列SQ中。主机处理器11可以将指示命令CMD被写至提交队列SQ中的提交队列SQ门铃输出至命令管理器111。
延迟计算器111a可以基于命令CMD中包括的处理延迟PL和间隔延迟IL计算写完成COMP的时间点。在一些示例性实施例中,延迟计算器111a可以通过从当取回命令CMD时的时间点Tf加上对应于处理延迟PL的时间段来计算第一时间点Tcp。延迟计算器111a可以通过从写所述前一个完成COMPx的时间点Tcx加上对应于间隔延迟IL的时间段来计算第二时间点Tci。
定时控制器111b可以基于由延迟计算器111a计算的第一时间点Tcp和第二时间点Tci确定写完成COMP的时刻。在一些示例性实施例中,当第一时间点Tcp和第二时间点Tci相同时,定时控制器111b可以确定等于第二时间点Tci的第一时间点Tcp作为写完成COMP的时刻。
在一些示例性实施例中,当第二时间点Tci落后于第一时间点Tcp时,定时控制器111b可以确定第二时间点Tci作为写完成COMP的时刻。在图8B的示例中示出这一点。
在一些示例性实施例中,与图8B的示例中示出的不同,当第一时间点Tcp落后于第二时间点Tci时,定时控制器111b可以请求延迟计算器111a计算第三时间点。第三时间点可以落后于第一时间点Tcp和第二时间点Tci,并且可以基于间隔延迟IL计算第三时间点。
例如,延迟计算器111a可以通过从用于写在所述前一个完成COMPx之后写的特定命令(未示出)的时间点加上对应于间隔延迟IL的时间段来计算第三时间点。当第三时间点落后于第一时间点时,定时控制器111b可以确定第三时间点作为写完成COMP的时刻。换句话说,存储控制器110可以保持完成COMP直到第三时间点。
如上所述,根据实施例,可以提供其中主机10产生处理延迟PL和间隔延迟IL并且在基于处理延迟PL和间隔延迟IL确定的时刻写完成COMP的存储系统。
图8B是示出根据实施例的执行图8A的操作方法的存储系统的主机和存储控制器的处理的时序图。参照图8A和图8B,主机10可以按次序执行以下步骤:产生处理延迟PL和间隔延迟IL;将命令CMD写至提交队列SQ中;以及输出指示写了命令CMD的提交队列SQ门铃。
存储控制器110可以在所述前一个完成时间点Tcx写所述前一个完成COMPx。存储控制器110可以按次序执行以下步骤:接收提交队列SQ门铃;取回命令CMD;以及基于直接存储器访问转移处理命令CMD请求的数据。
存储控制器110可以基于处理延迟PL和间隔延迟IL确定写完成COMP的时刻。存储控制器110可以通过从当从提交队列SQ取回命令CMD时的取回时间点Tf加上对应于处理延迟PL的时间段来计算处理完成时间点Tcp。存储控制器110可以通过从所述前一个完成时间点Tcx加上对应于间隔延迟IL的时间段来计算间隔完成时间点Tci。
在示例性实施例中,存储控制器110可以基于处理完成时间点Tcp和间隔完成时间点Tci确定写完成COMP的时刻。例如,当间隔完成时间点Tci落后于处理完成时间点Tcp时,存储控制器110可以确定间隔完成时间点Tci作为写完成COMP的时刻。在图8B的示例中示出了这一点。
然而,与图8B所示的示例不同,当处理完成时间点Tcp与间隔完成时间点Tci相同时,存储控制器110可以确定处理完成时间点Tcp作为写完成COMP的时刻。另外,与图8B所示的示例不同,当处理完成时间点Tcp落后于间隔完成时间点Tci时,存储控制器110可以将从用于写在所述前一个完成COMPx之后写的特定完成(未示出)的时间点加上对应于间隔延迟IL的时间段获得的时间点确定为写完成COMP的时刻。存储控制器110可以在(图8B所示的示例中)这样确定的时间点Tci写完成COMP。
存储控制器110可以在存储控制器110在完成时间点Tci(图8B所示的示例)将完成COMP写至完成队列CQ中之后输出中断。主机10可以接收中断并且在接收中断之后处理写至完成队列CQ中的完成COMP。主机10可以输出完成队列CQ门铃,并且存储控制器110可以接收CQ门铃。
图9是示出根据实施例的存储系统的操作方法的流程图。图9中例示了包括主机20和存储控制器210的存储系统的操作方法。
在操作S210中,主机20可以产生第一处理延迟PL1和第二处理延迟PL2以及第一间隔延迟IL1和第二间隔延迟IL2。第一处理延迟PL1和第一间隔延迟IL1是对应于第一命令CMD1的延迟。第二处理延迟PL2和第二间隔延迟IL2是对应于第二命令CMD2的延迟。
在示例性实施例中,第一命令CMD1可以在第二命令CMD2之前处理。例如,第一命令CMD1可以在第二命令CMD2之前取回。可以在对应于第二命令CMD2的第二完成COMP2之前写对应于第一命令CMD1的第一完成COMP1。第一间隔延迟IL1可以对应于从当写第一完成COMP1之前写的另一完成时的时间点至写第一完成COMP1的时间点的间隔。第二间隔延迟IL2可以对应于从当写第一完成COMP1时的时间点至写第二完成COMP2的时间点的间隔。
在操作S221中,主机20可以将包括第一处理延迟PL1和第一间隔延迟IL1的第一命令CMD1写至提交队列SQ。在操作S222中,存储控制器210可以取回写至提交队列SQ的第一命令CMD1。
在操作S231中,主机20可以将包括第二处理延迟PL2和第二间隔延迟IL2的第二命令CMD2写至提交队列SQ。在操作S232中,存储控制器210可以取回写至提交队列SQ的第二命令CMD2。
在操作S223中,存储控制器210可以基于直接存储器访问转移处理第一命令CMD1请求的数据。在操作S224中,存储控制器210可以基于第一处理延迟PL1和第一间隔延迟IL1确定写第一完成COMP1的时刻。第一完成COMP1可以指示第一命令CMD1被完全处理。在操作S225中,存储控制器210可以基于在操作S224中确定的时刻将第一完成COMP1写至完成队列CQ中。
在操作S233中,存储控制器210可以基于直接存储器访问转移处理第二命令CMD2请求的数据。在操作S234中,存储控制器210可以基于第二处理延迟PL2和第二间隔延迟IL2确定写第二完成COMP2的时刻。第二完成COMP2可以指示第二命令CMD2被完全处理。在操作S235中,存储控制器210可以基于在操作S234中确定的时刻将第二完成COMP2写至完成队列CQ。
如上所述,根据实施例,可以提供一种存储系统的操作方法,在所述存储系统中,主机20产生与不同命令CMD1和CMD2关联的延迟PL1、PL2、IL1和IL2,在基于第一处理延迟PL1和第一间隔延迟IL1确定的时刻将第一完成COMP1写至完成队列CQ,并且在基于第二处理延迟PL2和第二间隔延迟IL2确定的时刻将第二完成COMP2写至完成队列CQ。
图10是示出根据实施例的执行图9的操作方法的存储系统的框图。图10中例示了确定写分别对应于不同的命令CMD1和CM2的不同的完成COMP1和COMP2的时刻的存储系统。DMA缓冲器22b、DMA引擎212和非易失性存储器装置220的特征与图6A的DMA缓冲器12b、DMA引擎112和非易失性存储器装置120的特征相似,因此,为了简洁和避免冗余,将省略重复的描述。
主机20可以包括主机处理器21、命令缓冲器22a和DMA缓冲器22b。主机处理器21可以产生第一处理延迟PL1和第一间隔延迟IL1,其包括关于处理第一命令CMD1的时刻和写第一完成COMP1的时刻的信息。主机处理器21可以产生第二处理延迟PL2和第二间隔延迟IL2,其包括关于处理第二命令CMD2的时刻和写第二完成COMP2的时刻的信息。
主机处理器21可以将包括第一处理延迟PL1和第一间隔延迟IL1的第一命令CMD1写至提交队列SQ。命令管理器211可以取回写至提交队列SQ中的第一命令CMD1。主机处理器21可以将包括第二处理延迟PL2和第二间隔延迟IL2的第二命令CMD2写至提交队列SQ中。命令管理器211可以取回写至提交队列SQ的第二命令CMD2。
命令管理器211可以请求DMA引擎212处理与第一命令CMD1关联的数据。当与第一命令CMD1关联的数据被完全处理时,命令管理器211可以根据基于如上讨论的第一处理延迟PL1和第一间隔延迟IL1的时刻将指示与第一命令CMD1关联的数据被完全处理的第一完成COMP1写至完成队列CQ。
命令管理器211可以请求DMA引擎212处理与第二命令CMD2关联的数据。当与第二命令CMD2关联的数据被完全处理时,命令管理器211可以根据基于如上讨论的第二处理延迟PL2和第二间隔延迟IL2的时刻将指示与第二命令CMD2关联的数据被完全处理的第二完成COMP2写至完成队列CQ。
图11是示出根据实施例的存储系统的操作方法的流程图。图11中例示了包括主机处理器31、主机存储器缓冲器32、命令管理器311和DMA引擎312的存储系统的操作方法。
在操作S310中,主机处理器31可以产生第一处理延迟PL1和第二处理延迟PL2以及第一间隔延迟IL1和第二间隔延迟IL2。在这种情况下,对应于第一处理延迟PL1的时间段可以比对应于第二处理延迟PL2的时间段更长。也就是说,处理第一命令CMD1所花费的时间段可以比处理第二命令CMD2所花费的时间段更长。
在操作S321中,主机处理器31可以将包括第一处理延迟PL1和第一间隔延迟IL1的第一命令CMD1写至主机存储器缓冲器32的提交队列SQ。在操作S322中,命令管理器311可以取回写至提交队列SQ的第一命令CMD1。
在操作S331中,主机处理器31可以将包括第二处理延迟PL2和第二间隔延迟IL2的第二命令CMD2写至主机存储器缓冲器32的提交队列SQ。在操作S332中,命令管理器311可以取回写至提交队列SQ中的第二命令CMD2。在这种情况下,操作S332可以在操作S322之后执行。也就是说,命令管理器311可以取回第一命令CMD1,并且可以随后取回第二命令CMD2。
在操作S340中,命令管理器311可以基于第一处理延迟PL1和第二处理延迟PL2产生第一命令CMD1和第二命令CMD2的优先级。第一命令CMD1和第二命令CMD2的优先级可以指示首先处理第一命令CMD1和第二命令CMD2中的哪一个。
在示例性实施例中,命令管理器311可以确定优先级,使得首先处理对应于相对短的时间段的处理延迟的命令。例如,在对应于第一处理延迟PL1和第二处理延迟PL2的时间段分别为100μs和10μs的情况下,命令管理器311可以确定第二命令CMD2是要在第一命令CMD1之前处理的命令。换句话说,命令管理器311可以基于第一处理延迟PL1和第二处理延迟PL2确定将首先处理第一命令CMD1和第二命令CMD2中的第二命令CMD2。
在示例性实施例中,可以基于在操作S340中确定的优先级确定处理第一命令CMD1和第二命令CMD2的次序。例如,当对应于第二处理延迟PL2的时间段比对应于第一处理延迟PL1的时间段更短时(如图11所示的示例),可以在其中处理第一命令CMD1的操作S323至操作S327之前执行其中处理第二命令CMD2的操作S333至操作S337。也就是说,基于确定的优先级,可以在与第一命令CMD1关联的数据之前处理与在第一命令CMD1之后取回的第二命令CMD2关联的数据。
例如,与图11所示的示例不同,当对应于第一处理延迟PL1的时间段比对应于第二处理延迟PL2的时间段更短时(即,PL1<PL2),可以在其中处理第二命令CMD2的操作S333至操作S337之前执行其中处理第一命令CMD1的操作S323至操作S327。也就是说,基于确定的优先级,可以在与第二命令CMD2关联的数据之前处理与第一命令CMD1关联的数据。
返回图11,在操作S333中,命令管理器311可以请求DMA引擎312处理与第二命令CMD2关联的数据。在操作S334中,DMA引擎312可以基于直接存储器访问转移处理第二命令CMD2请求的数据。在操作S335中,DMA引擎312可以向命令管理器311通知已完全处理与第二命令CMD2关联的数据。
在操作S336中,命令管理器311可以基于第二处理延迟PL2和第二间隔延迟IL2确定写第二完成COMP2的时刻。在操作S337中,命令管理器311可以基于操作S336中确定的时刻将第二完成COMP2写至主机存储器缓冲器32的完成队列CQ。
在操作S323中,命令管理器311可以请求DMA引擎312处理与第一命令CMD1关联的数据。在操作S324中,DMA引擎312可以基于直接存储器访问转移处理第一命令CMD1请求的数据。在操作S325中,DMA引擎312可以向命令管理器311通知已完全处理与第一命令CMD1关联的数据。
在操作S326中,命令管理器311可以基于第一处理延迟PL1和第一间隔延迟IL1确定写第一完成COMP1的时刻。在操作S327中,命令管理器311可以基于操作S326中确定的时刻将第一完成COMP1写至主机存储器缓冲器32的完成队列CQ。
如上所述,根据实施例,可以提供基于处理延迟PL1和PL2确定命令CMD1和CMD2中的将首先处理的命令(即,命令CMD1和CMD2的优先级)的存储系统的操作方法。
图12是示出根据实施例的执行图11的操作方法的存储系统的框图。图12中例示了基于处理延迟PL1和PL2确定命令CMD1和CMD2中的将首先处理的命令的存储系统的操作方法。
存储系统可包括主机处理器31、主机存储器缓冲器32、命令管理器311和DMA引擎312。主机存储器缓冲器32可以包括命令缓冲器32a和DMA缓冲器32b。DMA缓冲器32b、DMA引擎312和非易失性存储器装置320的特征与图6A的DMA缓冲器12b、DMA引擎112和非易失性存储器装置120的特征相似,因此,为了简洁和避免冗余,将省略重复的描述。
主机处理器31可以产生与第一命令CMD1和第二命令CMD2关联的第一处理延迟PL1和第二处理延迟PL2以及第一间隔延迟IL1和第二间隔延迟IL2。在这种情况下,对应于第二处理延迟PL2的时间段可以比对应于第一处理延迟PL1的时间段更短(即,PL1>PL2)。
主机处理器31可以将包括第一处理延迟PL1和第一间隔延迟IL1的第一命令CMD1写至提交队列SQ。命令管理器311可以从提交队列SQ取回第一命令CMD1。主机处理器31可以将包括第二处理延迟PL2和第二间隔延迟IL2的第二命令CMD2写至提交队列SQ。命令管理器311可以从提交队列SQ取回第二命令CMD2。
命令管理器311可以包括延迟计算器311a、定时控制器311b以及优先级确定电路311g。优先级确定电路311g可以基于第一处理延迟PL1和第二处理延迟PL2确定第一命令CMD1和第二命令CMD2中的将被首先处理的命令。
例如,优先级确定电路311g可以比较分别对应于第一处理延迟PL1和第二处理延迟PL2的时间段。优先级确定电路311g可以确定对应于相对短的时间段的处理延迟的第二命令CMD2,作为将在第一命令CMD1之前处理的命令。在该示例中,由于PL1>PL2,优先级确定电路311g可以确定在处理第一命令CMD1之前将首先处理第二命令CMD2。
图13是示出根据实施例的主机的处理的时序图。图13中例示了示出主机处理器根据不同的完成控制方法执行的处理的时序图TD1、TD2和TD3。
处理“A”至处理“C”可以是不与写命令和处理完成关联的处理,并且主机处理器分开执行它们。切换成本可以表示切换主机处理器执行的处理花费的时间段。中断处理可以表示其中主机处理器响应于中断处理写至完成队列的完成的处理。
第一时序图TD1示出了在现有技术存储系统中主机处理器执行的处理。在这种情况下,可以不基于延迟确定当写完成时的时刻。主机处理器可以每“8”个周期周期性地处理完成。主机处理器的整体性能可能由于完成处理的负担而降低。
第二时序图TD2示出了在现有技术的存储系统中执行的由存储系统的主机处理器合并的并且处理多个完成的处理。由于多个完成的合并和处理,其中处理了完成的第二时序图TD2的时间段T2可以比其中处理了完成的第一时序图TD1的时间段T1更长。然而,因为可以缩短不必要的切换成本,应用第二时序图TD2的主机处理器可以比应用第一时序图TD1的主机处理器更快地处理处理“A”至处理“C”。
第三时序图TD3示出了根据各个示例实施例的存储系统的主机处理器基于延迟管理完成时刻执行的处理。就第二时序图TD2而言,因为存在不考虑主机处理器执行的处理而合并的处理后的完成,处理“A”至处理“C”可能被延迟并处理,并且可能出现不必要的切换成本X1和X2。
应用第三时序图TD3的主机处理器可以在基于延迟确定的时刻处理完成,因此,可以防止出现不必要的切换成本X1和X2。另外,因为最小化了完成处理对处理“A”至处理“C”的影响,所以应用了第三时序图TD3的主机处理器可以比应用了第二时序图TD2的主机处理器更快地处理处理“A”至处理“C”。
在示例性实施例中,可以提供基于延迟控制完成时刻并且合并和处理多个完成的存储系统。例如,参照第三时序图TD3,可以在当完成处理“C”时的时间点PCD3之后合并和处理多个完成。根据以上描述,由于处理“A”至处理“C”处理的速度提高,并且在不存在待处理的处理的时间段中存在未处理的合并和处理的完成,因此可以提供能够最小化发生切换成本和提高整体性能的存储系统。
根据各个实施例,提供了一种管理完成时刻使得在基于主机的延迟信息确定的时刻写完成的存储控制器及其操作方法。
另外,根据各个实施例,提供了一种存储控制器及其操作方法,在所述存储控制器中,控制了写完成的时刻,并且写完成对将在主机进行处理的处理过程的影响减小,并且主机的处理执行速度提高。
虽然已经参考本发明构思的示例性实施例描述了本发明构思,但是对于本领域的普通技术人员来说,显而易见的是,在不偏离本发明构思在以下权利要求中所述的精神和范围得到情况下可以对本发明构思进行各种改变和修改。
- 管理完成时刻的存储控制器及其操作方法
- 包括存储器控制器和电源管理电路的装置及其操作方法