模型验证方法、装置及电子设备
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及AI(Artificial Intelligence,人工智能)技术领域,尤其涉及模型验证方法、装置及电子设备。
背景技术
深度学习是ML(Machine Learning,机器学习)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标—人工智能。
深度学习平台训练出来的模型经过一系列转化封装操作后形成最终的算法包,算法包便可落地到推理产品中进行应用,但是在真正的落地到产品中使用之前,一般会进行模型的效果验证。现有的验证方案主要有如下两种:
方案一,使用独立的推理平台进行模型验证,预先定义好一张用于模型验证的GPU(Graphics Processing Unit,图形处理单元)卡可以同时加载的算法的数量,具体的操作流程如下:
步骤01:在模型训练平台上训练出模型,导出模型到本地,进行转化、封装、组件和引擎的添加,最终打包成算法包;
步骤02:将算法包导入到独立的推理平台中,申请一张模型验证GPU卡,在申请到的GPU卡上启动该算法的推理应用进行模型验证;
步骤03:当需要同时验证多个算法时,根据预先定义的一张模型验证GPU卡上可以加载的算法的数量,优先占满一张GPU卡资源。
方案二,模型训练平台中集成推理应用,预先定义好一张训练GPU卡可以同时加载的算法数量,具体的操作流程如下:
步骤01:模型训练平台训练出模型,直接在平台上进行模型转化,转化为GPU应用类型的算法包;
步骤02:模型训练平台上操作进行算法包的验证,在没有该模型验证的GPU卡的情况下,平台会为模型验证任务申请一张训练GPU卡,并将需要验证的算法包加载到申请到的训练GPU卡上,启动推理应用进行模型验证;
步骤03:当需要同时验证多个算法时,根据预先定义的一张训练GPU卡上可以加载的算法的数量,优先占满一张GPU卡资源。
上述两个方案的缺陷如下:
一、预先定义好一张模型验证或者训练GPU卡可以同时加载的算法数量,无法自动满足全新类型GPU卡的情况,需要针对全新的GPU重新定义这个预设值;
二、预先定义好一张模型验证或者训练GPU卡可以同时加载的算法数量,达不到最大化的资源的使用率,当算法大小减小时,不能自动加载更多的算法进行模型验证,而当算法大小变大时,则预先定义的算法数量将无法满足;
三、采用独立的推理平台需要增加额外的服务器,增加成本。
发明内容
本发明实施例提出模型验证方法、装置及电子设备,以提高对GPU资源的利用率。
本发明实施例的技术方案是这样实现的:
一种模型验证方法,该方法包括:
接收针对第一模型的模型验证任务;
在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务;
判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上。
所述判断是否查找到之后进一步包括:
若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的图形处理单元卡中,查找满足如下第二条件的图形处理单元卡:图形处理单元卡的空闲算力的大小不小于所述加载第一模型所需的算力大小;
判断是否查找到满足第二条件的图形处理单元卡,若查找到,则将第一模型加载到查找到的图形处理单元卡上进行模型验证。
所述判断是否查找到满足第二条件的图形处理单元卡之后进一步包括:
若未查找到,则向图形处理单元资源池申请用于模型验证的图形处理单元卡;
判断是否申请到,若申请到,则创建进程,并将第一模型加载到申请到的图形处理单元卡上,采用该进程对第一模型进行模型验证。
所述判断是否申请到之后进一步包括:
若未申请到,则在已申请到的用于模型验证的各图形处理单元卡中,查找满足如下第三条件的图形处理单元卡:假设将该图形处理单元卡上的一个或多个进程关闭后,该图形处理单元卡的空闲算力的大小不小于加载第一模型所需的算力大小;
判断是否查找到满足第三条件的图形处理单元卡,若查找到,则关闭查找到的图形处理单元卡上所述一个或多个进程,并将第一模型加载到该图形处理单元卡上进行模型验证。
所述接收针对第一模型的模型验证任务之后、在当前所有进程中查找满足如下第一条件的进程之前进一步包括:
判断当前是否存在已申请到的用于模型验证的图形处理单元卡,若不存在,则向图形处理单元资源池申请用于模型验证的图形处理单元卡;若存在,执行所述在当前所有进程中查找满足如下第一条件的进程的动作。
所述接收针对第一模型的模型验证任务之前进一步包括:
接收针对第一模型的模型训练请求,向图形处理单元资源池申请训练图形处理单元卡,申请到后,创建模型训练进程。
一种模型验证装置,该装置包括:
模型验证任务接收模块,用于接收针对第一模型的模型验证任务;
模型验证任务处理模块,用于在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务;判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上。
所述模型验证任务处理模块判断是否查找到之后进一步用于:
若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的图形处理单元卡中,查找满足如下第二条件的图形处理单元卡:图形处理单元卡的空闲算力的大小不小于所述加载第一模型所需的算力大小;判断是否查找到满足第二条件的图形处理单元卡,若查找到,则将第一模型加载到查找到的图形处理单元卡上进行模型验证。
所述模型验证任务处理模块判断是否查找到满足第二条件的图形处理单元卡之后进一步用于:
若未查找到,则向图形处理单元资源池申请用于模型验证的图形处理单元卡;判断是否申请到,若申请到,则创建进程,并将第一模型加载到申请到的图形处理单元卡上,采用该进程对第一模型进行模型验证。
所述模型验证任务处理模块判断是否申请到之后进一步用于:
若未申请到,则在已申请到的用于模型验证的各图形处理单元卡中,查找满足如下第三条件的图形处理单元卡:假设将该图形处理单元卡上的一个或多个进程关闭后,该图形处理单元卡的空闲算力的大小不小于加载第一模型所需的算力大小;判断是否查找到满足第三条件的图形处理单元卡,若查找到,则关闭查找到的图形处理单元卡上所述一个或多个进程,并将第一模型加载到该图形处理单元卡上进行模型验证。
所述模型验证任务处理模块在当前所有进程中查找满足如下第一条件的进程之前进一步用于:
判断当前是否存在已申请到的用于模型验证的图形处理单元卡,若不存在,则向图形处理单元资源池申请用于模型验证的图形处理单元卡;若存在,执行所述在当前所有进程中查找满足如下第一条件的进程的动作。
一种电子设备,包括如上任一所述的模型验证装置。
本发明实施例中,当接收到针对第一模型的模型验证任务时,若当前存在针对第一模型的模型验证进程且该进程仍能被调度任务,则无需向GPU资源池申请GPU卡,直接将第一模型的验证任务调度到该进程上即可,从而最大化地利用了本地已申请到的GPU资源,提高了对GPU资源的利用率。
附图说明
图1为本发明一实施例提供的模型验证方法流程图;
图2为本发明另一实施例提供的模型验证方法流程图;
图3为本发明又一实施例提供的模型验证方法流程图;
图4为本发明又一实施例提供的模型验证方法流程图;
图5为本发明又一实施例提供的模型验证方法流程图;
图6为本发明又一实施例提供的模型验证方法流程图;
图7为本发明实施例提供的模型验证装置的结构示意图。
具体实施方式
下面结合附图及具体实施例对本发明再作进一步详细的说明。
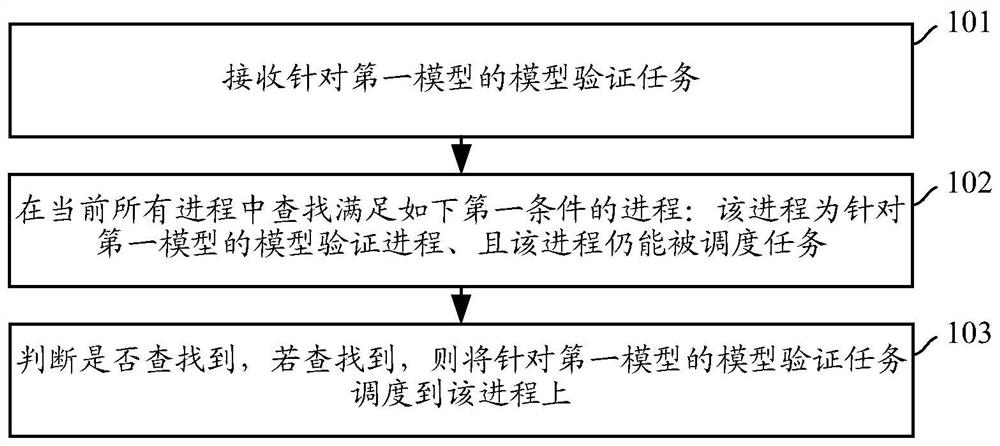
图1为本发明一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤101:接收针对第一模型的模型验证任务。
步骤102:在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
步骤103:判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上。
上述实施例中,当接收到针对第一模型的模型验证任务时,若当前存在针对第一模型的模型验证进程且该进程仍能被调度任务,则无需向GPU资源池申请GPU卡,直接将第一模型的验证任务调度到该进程上即可,从而最大化地利用了本地已申请到的GPU资源,提高了对GPU资源的利用率;
且,上述实施例自动支持不同新类型的GPU卡资源,如NVIDIA Tesla T4、P40、P100、V100等,无需人工干预调整预设值,节省人力,更加自动化;
且,上述实施例支持各种大小的模型的验证,不受模型大小的限制,更加人性化和自动化;
另外,推理后台模块可内嵌在模型训练后台模块中,节省了单独配置推理平台硬件资源的成本。
图2为本发明另一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤201:接收针对第一模型的模型验证任务。
步骤202:在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
步骤203:判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上;若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的GPU卡中,查找满足如下第二条件的GPU卡:GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤204:判断是否查找到满足第二条件的GPU卡,若查找到,则将第一模型加载到查找到的GPU卡上进行模型验证。
上述实施例中,当接收到针对第一模型的模型验证任务时,若当前不存在针对第一模型的模型验证进程,或者虽存在但该进程已不能再被调度任务,则查找满足:空闲算力的大小不小于加载第一模型所需的算力大小的GPU卡,若查找到,则将第一模型加载到查找到的GPU卡上进行模型验证,此时也无需向GPU资源池申请GPU卡,从而最大化地利用了本地已申请到的GPU资源,提高了对GPU资源的利用率。
图3为本发明又一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤301:接收针对第一模型的模型验证任务。
步骤302:在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
步骤303:判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上;若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的GPU卡中,查找满足如下第二条件的GPU卡:GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤304:判断是否查找到满足第二条件的GPU卡,若查找到,则将第一模型加载到查找到的GPU卡上进行模型验证;若未查找到,则向GPU资源池申请用于模型验证的GPU卡。
步骤305:判断是否申请到,若申请到,则创建进程,并将第一模型加载到申请到的GPU卡上,采用该进程对第一模型进行模型验证。
上述实施例中,当接收到针对第一模型的模型验证任务时,在确定:当前不存在针对第一模型的模型验证进程,或者虽存在但该进程已不能再被调度任务,且,已申请到的所有用于模型验证的GPU卡的空闲算力的大小都小于加载第一模型所需的算力大小时,再向GPU资源池申请GPU卡,从而保证了对本地已申请到的GPU资源的最大化的利用。
图4为本发明又一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤401:接收针对第一模型的模型验证任务。
步骤402:在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
步骤403:判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上;若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的GPU卡中,查找满足如下第二条件的GPU卡:GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤404:判断是否查找到满足第二条件的GPU卡,若查找到,则将第一模型加载到查找到的GPU卡上进行模型验证;若未查找到,则向GPU资源池申请用于模型验证的GPU卡。
步骤405:判断是否申请到,若申请到,则创建进程,并将第一模型加载到申请到的GPU卡上,采用该进程对第一模型进行模型验证;若未申请到,则在已申请到的用于模型验证的各GPU卡中,查找满足如下第三条件的GPU卡:假设将该GPU卡上的一个或多个任务列表为空的进程关闭后,该GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤406:判断是否查找到满足第三条件的GPU卡,若查找到,则关闭查找到的GPU卡上所述一个或多个任务列表为空的进程,并将第一模型加载到该GPU卡上进行模型验证。
上述实施例中,当接收到针对第一模型的模型验证任务时,在确定:当前不存在针对第一模型的模型验证进程,或者虽存在但该进程已不能再被调度任务,且,已申请到的所有用于模型验证的GPU卡的空闲算力的大小都小于加载第一模型所需的算力大小,且向GPU资源池申请GPU卡失败时,则将已申请到的用于模型验证的GPU卡中任务列表为空的一个或多个进程关闭,以使得该GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小,然后将第一模型加载到该GPU卡上进行模型验证,从而在不影响已有模型验证进程的正常执行的前提下,最大化地利用了GPU资源。
图5为本发明又一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤501:接收针对第一模型的模型验证任务。
步骤502:判断当前是否存在已申请到的用于模型验证的GPU卡,若不存在,则向GPU资源池申请用于模型验证的GPU卡。
步骤503:若存在,在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
步骤504:判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上。
上述实施例中,当接收到针对第一模型的模型验证任务时,先判断当前是否存在已申请到的用于模型验证的GPU卡,若不存在,则向GPU资源池申请GPU卡,若存在且当前存在针对第一模型的模型验证进程且该进程仍能被调度任务,则无需向GPU资源池申请GPU卡,直接将第一模型的验证任务调度到该进程上即可,从而最大化地利用了本地已申请到的GPU资源,提高了对GPU资源的利用率。
图6为本发明又一实施例提供的模型验证方法流程图,其具体步骤如下:
步骤601:模型训练客户端作为操作入口,在做好前期准备工作(如:训练数据集准备)之后,启动模型训练,向模型训练后台模块发送针对第一模型的模型训练请求;模型训练后台模块接收该模型训练请求,调用GPU资源池接口向GPU资源池发送训练GPU卡申请。
步骤602:GPU资源池接收该训练GPU卡申请,分配训练GPU卡,并创建针对第一模型的模型训练进程;模型训练后台模块接收到该模型训练进程上报的第一模型训练完成消息,将第一模型放入推理后台模块的模型仓库。
GPU资源池接收训练GPU卡申请后,要先判断自身是否剩余训练GPU卡,若是,则创建针对第一模型的模型训练进程。
步骤603:模型训练客户端接收用户输入的针对第一模型的模型验证请求,将该请求转发给模型训练后台模块,模型训练后台模块调用推理后台模块接口向推理后台模块派发针对第一模型的模型验证任务。
用户可通过模型训练客户端访问模型仓库,查看模型仓库中的各个模型,若需要对某个模型进行验证,则在该客户端上输入针对该模型的模型验证请求。
步骤604:推理后台模块接收针对第一模型的模型验证任务,判断当前自身是否存在用于模型验证的GPU卡,若是,执行步骤606;否则,执行步骤605。
步骤605:推理后台模块向GPU资源池发送模型验证GPU卡申请,GPU资源池接收该申请,创建进程,并分配用于模型验证的GPU卡,该进程将第一模型加载到该GPU卡上,开始对第一模型进行验证,本流程结束。
GPU资源池会设置用于模型验证的GPU卡的分配上限,若已分配出的用于模型验证的GPU卡的数目超出该上限,则不再分配用于模型验证的GPU卡。本步骤中,若GPU资源池已分配出的用于模型验证的GPU卡的数目超出该上限,则会通知推理后台模块,推理后台模块再通知模型训练后台模块,模型训练后台模块再通过模型训练客户端通知用户模型验证失败,并告知原因。
进程创建后会注册到模型验证节点管理模块,此后,模型验证节点管理模块可实时从进程获取模型验证进展状态、GPU卡的使用状态等,推理后台模块再从模型验证节点管理模块实时获取模型验证进展状态、GPU卡的使用状态等。
步骤606:推理后台模块在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务。
进程仍能被调度任务指的是,还可将任务调度到该进程上,例如:该进程的任务队列还未满。
步骤607:推理后台模块判断是否查找到,若是,执行步骤608;否则,执行步骤609。
步骤608:推理后台模块将针对第一模型的模型验证任务调度到该进程上,本流程结束。
步骤609:推理后台模块计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的GPU卡中,查找满足如下第二条件的GPU卡:GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤610:推理后台模块判断是否查找到,若是,执行步骤611;否则,执行步骤612。
步骤611:推理后台模块为针对第一模型的模型验证任务指定进程,该进程将第一模型加载到查找到的GPU卡上,开始对第一模型进行验证,本流程结束。
步骤612:推理后台模块向GPU资源池发送模型验证GPU卡申请,GPU资源池接收该申请,判断已分配出的用于模型验证的GPU卡的数目是否达到预设上限,若是,执行步骤614;否则,执行步骤613。
GPU资源池会设置用于模型验证的GPU卡的分配上限,若已分配出的用于模型验证的GPU卡的数目超出该上限,则不再分配用于模型验证的GPU卡。
步骤613:GPU资源池创建进程,并分配用于模型验证的GPU卡,该进程将第一模型加载到该GPU卡上,开始对第一模型进行验证,本流程结束。
步骤614:GPU资源池向推理后台模块发送分配失败通知,推理后台模块接收该通知在已申请到的用于模型验证的各GPU卡中,查找满足如下第三条件的GPU卡:假设将该GPU卡上的一个或多个任务列表为空的进程关闭后,该GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小。
步骤615:推理后台模块判断是否查找到,若查找到,则关闭查找到的GPU卡的一个或多个任务列表为空的进程,以使得该GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小,将第一模型加载到该GPU卡上进行模型验证。
本步骤中,若推理后台模块未查找到满足第三条件的GPU卡,则通知模型训练后台模块模型验证失败,并告知失败原因,模型训练后台模块再通过模型训练客户端通知用户。
图7为本发明实施例提供的模型验证装置的结构示意图,该装置主要包括:模型验证任务接收模块71和模型验证任务处理模块72,其中:
模型验证任务接收模块71,用于接收针对第一模型的模型验证任务。
模型验证任务处理模块72,用于在当前所有进程中查找满足如下第一条件的进程:该进程为针对第一模型的模型验证进程、且该进程仍能被调度任务;判断是否查找到,若查找到,则将针对第一模型的模型验证任务调度到该进程上。
上述实施例中,当接收到针对第一模型的模型验证任务时,若当前存在针对第一模型的模型验证进程且该进程仍能被调度任务,则无需向GPU资源池申请GPU卡,直接将第一模型的验证任务调度到该进程上即可,从而最大化地利用了本地已申请到的GPU资源,提高了对GPU资源的利用率。
一可选实施例中,模型验证任务处理模块72判断是否查找到之后进一步用于:若未查找到,则计算加载第一模型所需的算力大小,并在已申请到的用于模型验证的GPU卡中,查找满足如下第二条件的GPU卡:GPU卡的空闲算力的大小不小于所述加载第一模型所需的算力大小;判断是否查找到满足第二条件的GPU卡,若查找到,则将第一模型加载到查找到的GPU卡上进行模型验证。
一可选实施例中,模型验证任务处理模块72判断是否查找到满足第二条件的GPU卡之后进一步用于:若未查找到,则向GPU资源池申请用于模型验证的GPU卡;判断是否申请到,若申请到,则创建进程,并将第一模型加载到申请到的GPU卡上,采用该进程对第一模型进行模型验证。
一可选实施例中,模型验证任务处理模块72判断是否申请到之后进一步用于:若未申请到,则在已申请到的用于模型验证的各GPU卡中,查找满足如下第三条件的GPU卡:假设将该GPU卡上的一个或多个任务列表为空的进程关闭后,该GPU卡的空闲算力的大小不小于加载第一模型所需的算力大小;判断是否查找到满足第三条件的GPU卡,若查找到,则关闭查找到的GPU卡上所述一个或多个任务列表为空的进程,并将第一模型加载到该GPU卡上进行模型验证。
一可选实施例中,模型验证任务处理模块72在当前所有进程中查找满足如下第一条件的进程之前进一步用于:判断当前是否存在已申请到的用于模型验证的GPU卡,若不存在,则向GPU资源池申请用于模型验证的GPU卡;若存在,执行所述在当前所有进程中查找满足如下第一条件的进程的动作。
本发明实施例还提供一种电子设备,包括如上所述的模型验证装置。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 模型验证方法、装置、电子设备和存储介质
- 模型验证方法、装置及电子设备