再犯罪风险预警混合属性数据处理方法、介质和设备
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及数据预处理领域,特别涉及一种再犯罪风险预警混合属性数据处理方法、介质和设备。
背景技术
接受过监狱改造的特殊人群,导致其再犯罪的因素各不相同,如糟糕的成长环境、畸形的人生观、出狱后难以适应当今社会等。而不同的再犯罪因素,其犯罪的动机及其对社会带来的危害程度也有不同。因此,根据不同犯人的特征,利用无监督聚类对目标人群进行划分,再分别讨论导致各类人群再犯罪的因素及其危害程度,能够使预测的结果更加精准,较好的降低了预测算法对某一类特定人群的偏见。
然而,由于再犯罪风险预警数据规模大,样本维度高,现有模型对较高纬度的数据进行处理具有较高的难度及较低的分析能力。并且,数据即包含连续型属性又包含分类型属性,而目前现有技术对数据进行聚类分析主要是针对连续型属性,而针对分类型属性进行聚类分析的技术较少,极少聚类分析技术能够同时处理连续型属性和分类型属性,并且它们存在对初始聚类中心的选择敏感,易使聚类结果陷入局部最优并造成聚类效果上下起伏较大的情况、难以描述样本和聚类中心之间的相异度以及样本之间的差异、未考虑到不同的条件属性的重要程度的不同对结果的影响等。
发明内容
本发明的第一目的在于克服现有技术的缺点与不足,提供一种再犯罪风险预警混合属性数据处理方法,该方法可以降低数据的维度,实现对预警数据的有效处理分析,基于该方法获取到的数据,能够使得再犯罪风险预警的准确度更高以及预警的速度更快。
本发明的第二目的在于提供一种再犯罪风险预警混合属性数据处理装置。
本发明的第三目的在于提供一种存储介质。
本发明的第四目的在于提供一种计算设备。
本发明的第一目的通过下述技术方案实现:一种再犯罪风险预警混合属性数据处理方法,包括步骤:
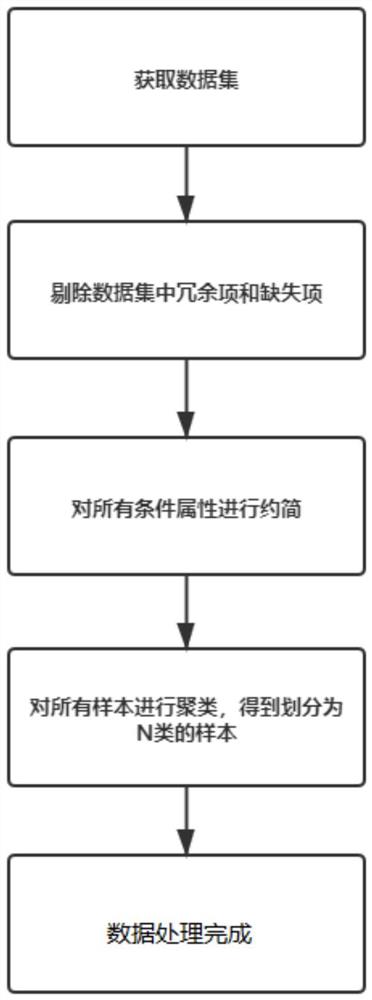
步骤S1、获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员;
步骤S2、对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;
步骤S3、对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;
步骤S4、针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。
优选的,步骤S2中,对于剔除冗余项和缺失项的数据集,首先判断其是否为协调的数据集,若否,则将其转换成协调的数据集,具体如下:
步骤S21、针对于剔除冗余项和缺失项的数据集,确定是否存在条件属性取值完全相同的样本,若是,则表示数据集为不协调的数据集;
步骤S22、将数据集中,条件属性取值完全相同的样本替换成一个样本,该替换得到的样本决策属性的值取为:上述条件属性取值完全相同的样本中,对应决策属性出现次数最多的值,从而转换得到协调的数据集。
优选的,步骤S3中对于协调的数据集中的各条件属性,进行约简处理的过程如下:
步骤S31、对于协调的数据集中的每个条件属性,首先逐个判断每个条件属性删除后对决策属性是否满足单点分布以及删除每个条件属性前后数据集的等价类的个数是否相等;
若删除条件属性后满足单点分布或者删除条件属性前后数据集的等价类个数相等,则判断对应条件属性为冗余属性;
否则,则判断对应条件属性为非冗余属性;
步骤S32、根据协调的数据集中的每个条件属性的判定结果,确定协调的数据集中的每个条件属性是否均为非冗余;
若否,则删除被判定为冗余的条件属性,然后进入步骤S33;
若是,则结束约简处理,得到约简处理后的数据集;
步骤S33、针对于协调数据集中所保留的每个条件属性,重新逐个判断每个条件属性删除后对决策属性是否满足单点分布和/或删除每个条件属性前后数据集的等价类的个数是否发生变化,以判定每个条件属性是否为冗余条件属性;然后返回步骤S32。
优选的,步骤S4中,针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性,通过改进后的聚类算法对样本进行聚类,具体如下:
步骤S41、首先计算数据集中各属性所含的信息熵,并根据信息熵计算各属性的权值;
步骤S42、从数据集中选取N个样本作为初始聚类中心;
步骤S43、计算所有聚类中心和数据集中的每个样本的距离,并将每个样本划分至与其距离最近的聚类中心中;
步骤S44、根据各样本与其所属类的聚类中心之间的距离,计算目标函数F的值,并判断目标函数F的值是否与上一次结果相同;
若是,则证明聚类结果已经趋于稳定,则聚类结束;
若否,更新各类的聚类中心的值,回到步骤S43。
更进一步的,步骤S41中计算数据集中各属性所含的信息熵和权值的公式如下:
对于某一连续型属性j而言,
其中,e
对于某一分类型属性j而言,
其中,e
对于某一属性j而言,
其中,ω
更进一步的,步骤S42、从数据集中选取N个样本作为初始聚类中心的具体过程如下:先从数据集中随机选取任意一个样本作为第1个初始聚类中心,然后从数据集中选取与已有的初始聚类中心集的距离之和最远的样本作为一个新的聚类中心,不断迭代直到初始聚类中心的个数达到N个。
更进一步的,对于任意一个聚类中心K
对于任意一个聚类中心K
其中,聚类中心K
其中,
样本与聚类中心的距离为:
其中,x
步骤S44中,目标函数F为:
本发明的第二目的通过以下技术方案实现:一种再犯罪风险预警混合属性数据处理装置,包括:
获取模块,用于获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员;
预处理模块,用于对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;
约简处理模块,用于对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;
聚类模块,用于针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。
本发明的第三目的通过以下技术方案实现:一种存储介质,包括处理器以及用于存储处理器可执行程序的存储器,其特征在于,所述处理器执行存储器存储的程序时,实现本发明第一目的所述的再犯罪风险预警混合属性数据处理方法。
本发明的第四目的通过以下技术方案实现:一种计算设备,存储有程序,所述程序被处理器执行时,实现本发明第一目的所述的再犯罪风险预警混合属性数据处理方法。
本发明相对于现有技术具有如下的优点及效果:
(1)本发明再犯罪风险预警混合属性数据处理方法,获取数据样本构成数据集;首先对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;接着对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集,最后对属性约简后的数据集进行聚类。本发明方法中,通过数据预处理和约简处理,能够将数据集中存在缺失的属性以及冗余的属性进行有效去除,因此可以有效降低数据的维度,实现对预警数据的有效处理分析,基于该方法获取到的数据,能够使得再犯罪风险预警的分类准确度更高以及分类的速度更快。
(2)本发明再犯罪风险预警混合属性数据处理方法中,采用改进的聚类算法对约简处理后的数据集进行样本的聚类,相比传统的聚类算法,本发明优化后的聚类算法不再采用随机生成N个初始聚类中心的方法,而是选择了N个距离最远的点作为初始聚类中心,使得所选取的N个初始聚类中心能有较大的相异度,使其能够避免陷入局部最优的情况,并使算法的计算结果更加稳定,不会因为随机选取初始聚类中心而使聚类结果差异较大;基于此,本发明方法同时对连续型属性和分类型属性数据进行划分,进一步提高了再犯罪风险预警的分类准确度。
(3)本发明再犯罪风险预警混合属性数据处理方法中,采用等价类和单点分布对所有条件属性进行约简,可以有效的判断各属性所隐含的信息的多少而不需要任何先验知识。同时,对数据的维度进行约简,能够在保证数据集所含信息量不变的前提下剔除冗余属性,有效的提高了模型的运行效率,并提高了模型的准确率。
(4)本发明再犯罪风险预警混合属性数据处理方法中,采用了一种新的度量分类型属性与聚类中心距离的方式,能够更加准确的度量分类型属性与聚类中心之间的距离,并且使分类型属性的距离度量方式与连续型属性的距离度量方式统一,使聚类结果更加准确,同时更加具有说服力。相比传统聚类算法中通过使用海明距离公式计算分类型属性与聚类中心的距离,由于海明距离公式仅仅采用简单的0-1匹配方式描述样本与聚类中心之间的距离,这种方式难以准确刻画样本和聚类中心的相异度。
(5)本发明再犯罪风险预警混合属性数据处理方法中,通过信息熵描述了各属性的信息量,并根据各属性所含信息量的多少为其赋予相应的权值,使得能够更加准确的描述各属性的重要程度,使最终的聚类结果更加准确。
附图说明
图1是本发明方法流程图。
图2是本发明方法中样本属性约简流程图。
图3是本发明方法中样本聚类的流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
本实施例公开了一种再犯罪风险预警混合属性数据处理方法,该方法能够有效的对数据的维度进行约简,剔除掉冗余属性,并能有效的将所有接受过监狱改造的特殊人群进行分类,能够有效的对这类型的数据进行处理,如图1所示,包括步骤:
步骤S1、获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员。
如表1中,假设样本集中包括以下样本,各样本的数据如下:
表1
步骤S2、对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项;本实施例中,冗余项可以是指样本中对再犯罪预测结果没有影响的属性;缺失项可以是指样本某属性值为空,对于存在大量缺失值的属性给予剔除。
本步骤中,对于剔除冗余项和缺失项的数据集,首先判断其是否为协调的数据集,若否,则将其转换成协调的数据集,具体如下:
步骤S21、针对于剔除冗余项和缺失项的数据集,确定是否存在条件属性取值完全相同的样本,若是,则表示数据集为不协调的数据集;
步骤S22、将数据集中,条件属性取值完全相同的样本替换成一个样本,该替换得到的样本决策属性的值取为:上述条件属性取值完全相同的样本中,对应决策属性出现次数最多的值,从而转换得到协调的数据集。
例如在表1中,编号为No
表2
步骤S3、对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;如图2所示,具体如下:
步骤S31、对于协调的数据集中的每个条件属性,首先逐个判断每个条件属性删除后对决策属性是否满足单点分布以及删除每个条件属性前后数据集的等价类的个数是否相等;
若删除条件属性后满足单点分布或者删除条件属性前后数据集的等价类个数相等,则判断对应条件属性为冗余属性;
否则,则判断对应条件属性为非冗余属性;
例如针对于表2中指示的协调数据集,假设删除条件属性“性别”,剩余条件属性“文化程度”及“犯罪类型”,然而此时存在两个样本No
同理,假设删除条件属性“文化程度”,剩余条件属性“性别”及“犯罪类型”,此时所有样本的条件属性取值均不完全相等,因此其满足单点分布,因此条件属性“文化程度”为冗余属性。
步骤S32、根据协调的数据集中的每个条件属性的判定结果,确定协调的数据集中的每个条件属性是否均为非冗余;
若否,则删除被判定为冗余的条件属性,然后进入步骤S33;
若是,则结束约简处理,得到约简处理后的数据集。
步骤S33、针对于协调数据集中所保留的每个条件属性,重新逐个判断每个条件属性删除后对决策属性是否满足单点分布和/或删除每个条件属性前后数据集的等价类的个数是否发生变化,以判定每个条件属性是否为冗余条件属性;然后返回步骤S32。
例如表2中的数据集经过步骤S31的处理后,协调数据集中所保留的条件属性为“性别”及“犯罪类型”,针对于此时的协调数据集,进行如下处理:
假设删除条件属性“性别”,剩余条件属性“犯罪类型”,此时样本No
同理,假设删除条件属性“犯罪类型”,剩余条件属性“性别”,此时样本No
因此表2的数据集在步骤S33处理后,确定数据集中的所有条件属性均为非冗余属性,再返回步骤S32执行时,结束约简处理,得到约简处理后的数据集,如表3中所示:
表3
步骤S4、针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。本实施例中,在本实施例中,N的取值设定为2~4。通过改进后的聚类算法(如改进后的K-prototypes聚类算法)对样本进行聚类,如表4中,假设经过步骤S3的属性约简后的样本集中包括以下属性和样本,各样本的数据如下:
表4
其中,表4中,身高和年龄为连续型属性,性别和犯罪类型为分类型属性。本实施例中,样本的连续型属性可以包括身高、体重、年龄、出生日期、犯罪日期和文化程度等;分类型属性可以包括性别、婚姻状况、政治面貌、犯罪前科的犯罪类型等。
在本实施例中,需要将所有样本的连续型属性进行归一化,最终得到的结果如表5所示:
表5
本实施例中,通过改进后的聚类算法对样本进行聚类,如图3所示,具体如下:
步骤S41、首先计算数据集中各属性所含的信息熵,并根据信息熵计算各属性的权值;本实施例中,计算数据集中各属性所含的信息熵和权值的公式如下:
对于某一连续型属性j而言,
其中,e
对于某一分类型属性j而言,
其中,e
对于某一属性j而言,
其中,ω
步骤S42、从数据集中选取N个样本作为初始聚类中心;具体如下:先从数据集中随机选取任意一个样本作为第1个初始聚类中心,然后从数据集中选取与已有的初始聚类中心集的距离之和最远的样本作为一个新的聚类中心,不断迭代直到初始聚类中心的个数达到N个。
在本实施例中,若N=2,则在步骤S42中选择出2个初始聚类中心;先随机选择出第一个聚类中心后,再在样本集中选择出与第一个聚类中心距离最远的样本作为第二个聚类中心。
若N=3,则在步骤S42中选择出3个初始聚类中心;先随机选择一个初始聚类中心,再在数据集中选择出与第一个聚类中心距离最远的样本作为第二个初始聚类中心。当选择出第二个聚类中心后,在数据集中选择出与第一个初始聚类中心和第二个初始聚类中心距离之和最大的样本作为第三个初始聚类中心。
本实施例中,对于任意一个聚类中心K
对于任意一个聚类中心K
其中,聚类中心K
其中,
实施例中,样本与聚类中心的距离为:
其中,x
其中,第m种连续型属性的权值ω
其中:
其中,e
E
Y
I为样本集中样本的个数。
基于如表1中所示的数据,对于连续型属性身高而言,即m为1时,
其中
最终,e
同理得到,对于连续性属性性别而言,即m为2时,
e
对于分类型属性性别而言,即l为1时,t
其中,
同理得到,当l为2时,即分类型属性为犯罪类型对应的E
基于上述求取到的信息熵可得,第一种连续型属性,即身高的权值ω
同理,第2种连续型属性即年龄的权值ω
ω
第1种分类型属性即性别的权值ω
ω
第2种分类型属性即犯罪类型的权值ω
ω
在本实施例中,暂定聚类中心的个数N=2。如果首先随机选取No
其中,第1、2种连续型属性分别为身高和年龄属性。
基于上述,该聚类中心所属类的第l种分类型属性为:
即l=1时,
即l=2时,
其中,第1、2种分类型属性分别为性别和犯罪类型分类型属性。
然后,分别计算样本No
本实施例中设定γ=1。
基于上述求取样本与聚类中心距离公式,对于样本No
同理,样本No
d(No
同理,样本No
d(No
同理,样本No
d(No
同理,样本No
d(No
同理,样本No
d(No
基于上述计算可得,样本No
步骤S43、计算所有聚类中心和数据集中的每个样本的距离,并将每个样本划分至与其距离最近的聚类中心中;
基于上述表4、表5中的数据,在本实施例中,计算各样本与各聚类中心之间的距离,例如针对训练样本No
d(No
d(No
因此将样本No
同理计算No
步骤S44、根据各样本与其所属类的聚类中心之间的距离,计算目标函数F的值,并判断目标函数F的值是否与上一次结果相同;
若是,则证明聚类结果已经趋于稳定,则聚类结束;
若否,更新各类的聚类中心的值,回到步骤S43。
步骤S44中,目标函数F为:
本实施例中,步骤S44具体执行过程如下,
步骤S441、根据上述计算目标函数公式计算目标函数的值,并判断其与上次目标函数的值是否保持一致,则进入步骤S444;否则执行步骤S442。
步骤S442、针对于各类中的连续性属性,每个连续型属性的更新结果为该类中所有样本在该连续性属性上的平均值,即:
其中n
针对各类的聚类结果,每个分类型属性的更新方式为获取各个聚类中的所有样本的每个分类型属性的值,统计该类中每种分类型属性所能取的值中各个值出现的频率:
其中
步骤S443、将上述获取到的
步骤S444、至此,所有样本被划分至N类中,完成了数据的处理,对所有样本进行了分类,获得了数据的分布情况,对样本的特征进行了抽取,便于更进一步获得有用的信息。
本领域技术人员可以理解,实现本实施例方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,相应的程序可以存储于计算机可读存储介质中。应当注意,尽管在附图中以特定顺序描述了本实施例1的方法操作,但是这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,描绘的步骤可以改变执行顺序,有些步骤也可以同时执行。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
实施例2
本实施例公开一种再犯罪风险预警混合属性数据处理装置,包括:
获取模块,用于获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员;
预处理模块,用于对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;
约简处理模块,用于对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;
聚类模块,用于针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。
本实施例上述各个模块的具体实现可以参见上述实施例1,在此不再一一赘述。需要说明的是,本实施例提供的装置仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
实施例3
本实施例公开了一种存储介质,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现实施例1所述的再犯罪风险预警混合属性数据处理方法,如下:
获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员;
对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;
对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;
针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。
上述各步骤的具体实现过程参见实施例1,此处不再赘述。
在本实施例中,存储介质可以是磁盘、光盘、计算机存储器、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、U盘、移动硬盘等介质。
实施例4
本实施例公开了一种计算设备,存储有程序,所述程序被处理器执行时,实现实施例1所述的再犯罪风险预警混合属性数据处理方法,如下:
获取数据样本构成数据集;其中,样本包括有犯罪前科且再犯罪人员及有犯罪前科却不再犯罪人员;
对数据集中的各样本进行初步的数据预处理,剔除数据集中的冗余项和缺失项,然后将数据集转换为协调的数据集;
对于协调的数据集中的各条件属性,进行约简处理,删除协调的数据集中的冗余属性,得到属性约简后的数据集;
针对于属性约简后的数据集,根据其中样本的连续型属性和分类型属性对样本进行聚类,定义获取到的聚类数目为N,N为常量,即属性约简后的数据集中所有样本被聚类为N类。
上述各步骤的具体实现过程参见实施例1,此处不再赘述。
本实施例中,计算设备可以是台式电脑、笔记本电脑、智能手机、PDA手持终端、平板电脑等终端设备。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 再犯罪风险预警混合属性数据处理方法、介质和设备
- 一种设备风险预警方法、装置、终端设备及存储介质