基于场景特征提取的场景描述信息确定方法及装置
文献发布时间:2023-06-19 12:14:58
技术领域
本发明涉及一种图像识别技术领域,特别是涉及一种基于场景特征提取的场景描述信息确定方法及装置。
背景技术
随着计算机处理能力的快速发展,计算机视觉已经成为计算机对世界信息进行处理的重要组成部分,即通过计算机代替人类视觉提取场景信息作为图像或视频数据进行处理,从而完成对场景中不同目标对象的特征内容的提取。其中,对于场景特征可以通过全景分割技术提取不同场景中所对应目标对象的图像特征,并结合场景描述信息对图像特征进行描述,从而实现对场景图像中不同目标对象的视觉认知,即表示为场景描述信息。
目前,现有对场景特征的提取通常基于全景分析技术中的语义分割以及实例分割从场景图像中提取包含颜色、前景对象的图像特征,并按照不同颜色对图像特征区分不同的场景描述信息,但是,语义分割无法确定场景图像中的图像类别、数量,实例分割无法确定场景图像中的后景对象的提取,导致降低了不同目标对象对应场景描述信息的准确性,从而无法确保场景图像中不同目标对象的目标对象确定场景描述信息的精准性,影响场景图像语义分割的使用效率。
发明内容
有鉴于此,本发明提供一种基于场景特征提取的场景描述信息确定方法及装置,主要目的在于解决现有无法确保场景图像中不同目标对象的目标对象确定场景描述信息的精准性的问题。
依据本发明一个方面,提供了一种基于场景特征提取的场景描述信息确定方法,包括:
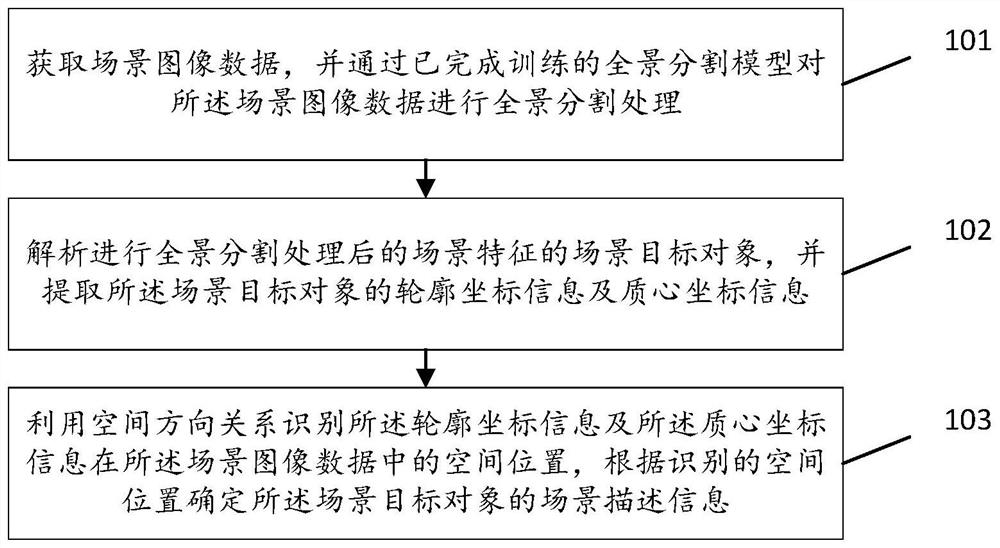
获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;
解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;
利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系。
进一步地,所述通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理之前,所述方法还包括:
获取全景分割训练数据集,并基于深度卷积神经网络模型构建全景分割模型,其中,所述全景分割模型中包括基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层,以及基于语义分割、实例分割融合构建的输出层;
根据所述所述全景分割训练数据集对所述全景分割模型进行训练的过程中,在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练,得到完成模型训练的全景分割模型,所述通道注意力机制为通过压缩处理不同场景特征通道,并为压缩后的场景特征通道分配权重。
进一步地,所述在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练包括:
在融合多尺度上下文信息层中,利用压缩函数在可分离卷积处对场景特征通道进行压缩处理,得到所述场景特征通道的压缩实数,所述压缩函数为
通过在预设非线性函数中加入所述压缩实数对所述场景特征通道中的特征层进行权重加权,对完成权重加权的场景特征通道进行模型训练。
进一步地,所述解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息包括:
确定进行全景分割处理后的场景特征的二值图像类别,根据所述二值图像类别确定所述场景特征的场景目标对象,所述场景目标对象包括前景目标对象或后景目标对象;
连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息。
进一步地,所述连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息之后,所述方法还包括:
若所述场景目标对象为前景目标对象,则基于预设视觉数据库提取与所述前景目标对象匹配的语义信息标注于所述质心坐标信息处;
若所述场景目标对象为后景目标对象,则根据所述后景目标对象的先验知识计算所述后景目标对象的语义阈值,并结合所述二值图像类别、所述语义阈值从预设视觉数据库中提取与所述后景目标对象匹配的语义信息标注于所述质心坐标信息处。
进一步地,所述利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息包括:
获取空间方向中已定义的参考目标的参考质心坐标信息、参考轮廓极值坐标信息,并利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息相对于所述参考轮廓极值坐标信息、所述参考质心坐标信息的空间位置;
基于所述空间位置统计分别属于前景目标对象、后景目标对象的语义信息所对应的数量,确定为所述场景目标对象的场景描述信息。
进一步地,所述根据识别的空间位置确定所述场景目标对象的场景描述信息之后,所述方法还包括:
获取进行全景分割处理过程中的处理参数,所述处理参数包括语义分割结果、数据标注平均交并比;
基于所述语义分割结果中的标记为正的正场景图像数据、标记为负的负场景图像数据、标记为负的正场景图像数据、以及所述数据标注平均并交比计算所述全景分割处理的性能指标;
若所述性能指标符合预设性能指标阈值,则输出所述场景描述信息。
依据本发明另一个方面,提供了一种基于场景特征提取的场景描述信息确定装置,包括:
获取模块,用于获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;
解析模块,用于解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;
确定模块,用于利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系。
进一步地,所述装置还包括:
构建模块,用于获取全景分割训练数据集,并基于深度卷积神经网络模型构建全景分割模型,其中,所述全景分割模型中包括基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层,以及基于语义分割、实例分割融合构建的输出层;
训练模块,用于根据所述所述全景分割训练数据集对所述全景分割模型进行训练的过程中,在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练,得到完成模型训练的全景分割模型,所述通道注意力机制为通过压缩处理不同场景特征通道,并为压缩后的场景特征通道分配权重。
进一步地,所述训练模块包括:
生成单元,用于在融合多尺度上下文信息层中,利用压缩函数在可分离卷积处对场景特征通道进行压缩处理,得到所述场景特征通道的压缩实数,所述压缩函数为
训练单元,用于通过在预设非线性函数中加入所述压缩实数对所述场景特征通道中的特征层进行权重加权,对完成权重加权的场景特征通道进行模型训练。
进一步地,所述解析模块包括:
第一确定单元,用于确定进行全景分割处理后的场景特征的二值图像类别,根据所述二值图像类别确定所述场景特征的场景目标对象,所述场景目标对象包括前景目标对象或后景目标对象;
第二确定单元,用于连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息。
进一步地,所述装置还包括:标注模块,
所述标注模块,用于若所述场景目标对象为前景目标对象,则基于预设视觉数据库提取与所述前景目标对象匹配的语义信息标注于所述质心坐标信息处;
所述标注模块,还用于若所述场景目标对象为后景目标对象,则根据所述后景目标对象的先验知识计算所述后景目标对象的语义阈值,并结合所述二值图像类别、所述语义阈值从预设视觉数据库中提取与所述后景目标对象匹配的语义信息标注于所述质心坐标信息处。
进一步地,所述确定模块包括:
获取单元,用于获取空间方向中已定义的参考目标的参考质心坐标信息、参考轮廓极值坐标信息,并利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息相对于所述参考轮廓极值坐标信息、所述参考质心坐标信息的空间位置;
确定单元,用于基于所述空间位置统计分别属于前景目标对象、后景目标对象的语义信息所对应的数量,确定为所述场景目标对象的场景描述信息。
进一步地,所述装置还包括:计算模块,输出模块,
所述获取模块,还用于获取进行全景分割处理过程中的处理参数,所述处理参数包括语义分割结果、数据标注平均交并比;
所述计算模块,用于基于所述语义分割结果中的标记为正的正场景图像数据、标记为负的负场景图像数据、标记为负的正场景图像数据、以及所述数据标注平均并交比计算所述全景分割处理的性能指标;
所述输出模块,还用于若所述性能指标符合预设性能指标阈值,则输出所述场景描述信息。
根据本发明的又一方面,提供了一种存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述基于场景特征提取的场景描述信息确定方法对应的操作。
根据本发明的再一方面,提供了一种终端,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述基于场景特征提取的场景描述信息确定方法对应的操作。
借由上述技术方案,本发明实施例提供的技术方案至少具有下列优点:
本发明提供了一种基于场景特征提取的场景描述信息确定方法及装置,与现有技术相比,本发明实施例通过获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系,对场景图像数据的语义分割更加灵活,以增加对场景描述信息的方式实现对场景图像信息中语义分割的目的性,确保场景图像中不同目标对象的目标对象确定场景描述信息的精准性,大大扩大了对场景图像数据进行分割后的使用效率。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明实施例提供的一种基于场景特征提取的场景描述信息确定方法流程图;
图2示出了本发明实施例提供的一种全景分割模型网络结构图;
图3示出了本发明实施例提供的一种引入注意力机制的层级处理过程示意图;
图4示出了本发明实施例提供的一种可分离卷积处加入注意力机制结构示意图;
图5示出了本发明实施例提供的一种场景描述信息输出示意图;
图6示出了本发明实施例提供的一种基于场景特征提取的场景描述信息确定装置组成框图;
图7示出了本发明实施例提供的一种终端的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明实施例提供了一种基于场景特征提取的场景描述信息确定方法,如图1所示,该方法包括:
101、获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理。
其中,所述场景图像数据为针对不同场景待进行场景描述信息确定的图像数据,本发明实施例中的场景包括但不限于城市街道、广场等,可以通过摄像设备之间拍摄,也可以从存储场景图像数据库中获取进行知识确定的场景图像数据,并通过全景分割模型对场景图像数据进行全景分割处理,得到场景特征。本发明实施例中,全景分割模型可以为任意一种卷积神经网络模型进行构建,例如,可以基于深度卷积神经网络(deep convolutionalneural network,DCNN)模型构建的,并且了结合自下而上的Bottom-up方法,如基于DCNN构建Panoptic-DeepLab网络全景分割模型,使得构建的全景分割模型中包括特征层、基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层、基于语义分割、实例分割融合构建的输出层、浅层特征与深层特征融合的上采样解码器等,为了使全景分割模型中各通道间的信息充分力用,提高网络特征的提取能力,全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的,即通过注意力机制建立对象间的依赖性关系,使得全景分割模型能够通过注意力机制增加对特征的学习强相关性。
需要说明的是,引入深度卷积神经网络模型中的注意力机制可以使得神经网络具备专注于其输入(或特征)子集的能力,即选择特定的输入,本发明实施例中则为特定任务后的输入层,从而使得在结合基于语义分割、实例分割融合构建的输出层,处理得到完成语义分割的场景特征。
102、解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息。
本发明实施例中,为了实现对场景图像信息中场景描述信息的确定,在进行全景分割处理后,对得到的场景特征进行解析,解析出场景特征的场景目标对象,场景目标对象用于表示场景图像中语言分割各个部分所对应的目标对象,例如街景图像中,进行全景分割处理后得到的场景特征包含不同标注的语义分割的图像特征,图像特征仅仅标识分割出的形状区域,通过不同颜色进行体现,但是对于属于背景部分的图像特征,仍然会被按照不同颜色进行区别,因此,解析场景特征的场景目标对象,即为对分割后的场景特征进行前景目标对象或后景目标对象的确定,从而增加了对场景描述信息确定的有效性。其中,前景目标对象为场景图像在空间关系中属于视觉前端部分的图像对象,例如街道图像中的车辆,行人等,后景目标对象为场景图像在空间关系中属于视觉后端部分的图像对象,例如街道图像中的蓝天白云等,本发明实施例不做具体限定。另外,在解析出需要作为场景描述信息确定的目标的场景目标对象后,需要提取场景目标对象的轮廓坐标信息、以及质心坐标信息,即轮廓坐标信息为描述场景目标对象轮廓的坐标信息,质心坐标信息为描述场景目标对象质心位置的坐标信息。
需要说明的是,根据场景特征解析出的场景目标对象可以为1个或多个,从而对应提取的轮廓坐标信息及质心坐标信息可以为1个或多个场景目标对象对应的坐标集,从而进行空间位置的识别。
103、利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息。
本发明实施例中,所述场景描述信息用于表示场景目标对象处于场景图像中不同空间位置的视觉认知,例如街道图像中场景目标对象为车辆、栏杆、行人,则场景描述信息为马路左边1个栏杆,马路上3辆车,因此,可以通过空间方向关系识别轮廓坐标信息及质心坐标信息相对于场景图像中的空间位置,从而确定出场景描述信息。其中,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系,即利用空间方向关系判断轮廓坐标信息、质心坐标信息相对于四个象限区域中不同空间方向的空间位置,从而统计确定得到每个场景目标对象的场景描述信息。
需要说明的是,空间方向关系中定义一个参考目标的参考质心坐标信息,以便在识别轮廓坐标信息、质心坐标信息的空间位置时,基于此参考质心坐标信息确定不同空间方向的空间位置,本发明实施例不做具体限定。
在一个本发明实施例中,为了进一步说明及限定,所述通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理之前,所述方法还包括:获取全景分割训练数据集,并基于深度卷积神经网络模型构建全景分割模型,其中,所述全景分割模型中包括基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层,以及基于语义分割、实例分割融合构建的输出层;根据所述所述全景分割训练数据集对所述全景分割模型进行训练的过程中,在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练,得到完成模型训练的全景分割模型,所述通道注意力机制为通过压缩处理不同场景特征通道,并为压缩后的场景特征通道分配权重。
为了提高全景分割模型的分割准确性,避免仅仅采用语义分割、实例分割对场景图像数据分割的局限性,利用深度卷积神经网络模型构建全景分割模型,并进行训练过程的优化。其中,全景分割训练数据集为待对全景分析模型进行训练的数据集,可以为任意一种形式的语义理解数据集,例如已公开的Cityscapes数据集,是一个关于城市街道场景的语义理解图片数据集,它主要包含来自50个不同城市的街道场景,拥有34类标签的5000张在城市环境中驾驶场景的高质量像素级注释图像,其中,包含2975张训练图像,500张验证图像和1525张测试图像,分辨率为2048*1024,本发明实施例不做具体限定。本发明实施例中,构建如图2所示的深度卷积神经网络模型,其中,全景分割模型中包括基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层,以及基于语义分割、实例分割融合构建的输出层,具体的,基于空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)构建的融合多尺度上下文信息层为使用不同空洞率并行结构提取并融合多尺度深层特征上下文信息得到的,基于语义分割、实例分割融合构建的输出层为通过融合语义分割、实例分割得到的,通过投票输出分割完成的场景特征,当然,构建的全景分割模型中还包括可以实现在ImageNet数据集上进行预训练编码器主干提取的特征层、特定于不同分割任务的输入层以及浅层特征与深层特征融合的上采样解码器,从而大大的提高了全景分割模型的灵活性、分割精度。并且,在对模型训练过程中,在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制,所述通道注意力机制为通过压缩处理不同场景特征通道,并为压缩后的场景特征通道分配权重,从而实现模型中通道信息的利用率,提高模型的学习能力。
需要说明的是,如图2所示的全景分割模型网络结构图,本发明实施例中的全景分割模型中的语义分割与实例分割所对应的网络部分采用相同结构的主干网络Backone、ASPP和解码器,从而使网络梯度更加均衡,网络收敛更快。其中,主干网络Backone部分表示使用ImageNet数据集预训练的语义分割网络,并且在最后一层卷积层采用空洞卷积扩大感受视野,并分别将1/4和1/8特征层与解码器中相同分辨率特征层进行跳接融合,从而弥补下采样过程中细节信息的损失以融合多尺度信息,并结合ASPP对所给定的特定输入特征层以不同的采样率并行空洞卷积进行采样,从而实习融合多尺度上下文信息。其中,SemanticPrediction为语义分割网络输出层,Instance Center Prediction是预测每个实例对象的质心位置,Instance Center Regression是指每个实例对于质心的偏移量来表征一个实例,Semantic Decoder与Instance Decoder在每一步上采样之后进行融合主干网络特征和进行可分离卷积操作降低计算量。
在一个本发明实施例中,为了进一步限定及说明,所述在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练包括:在融合多尺度上下文信息层中,利用压缩函数在可分离卷积处对场景特征通道进行压缩处理,得到所述场景特征通道的压缩实数,所述压缩函数为
本发明实施例中,为了更好地增强学习相关性,在基于空洞空间卷积池化金字塔ASPP构建的融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制,即为过对特征层各场景特征通道的信息进行提取,以提高网络的特征表示能力,并且可以根据特征对场景特征通道进行调整,实现有目的性的学习特征层全局信息并加强有用的信息特征。
具体的,如图3所示的引入注意力机制的层级处理过程示意图,c
在一个本发明实施例中,为了进一步限定及说明,所述解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息包括:确定进行全景分割处理后的场景特征的二值图像类别,根据所述二值图像类别确定所述场景特征的场景目标对象,所述场景目标对象包括前景目标对象或后景目标对象;连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息。
本发明实施例中,由于场景特征仅仅体现为对图像中不同语义进行分割特征结果,为了实现对场景图像中场景描述信息的确定,基于场景特征的二值图像类别确定场景目标对象。其中,场景特征的二值图像类别的确定过程,具体为通过全景分割模型处理过程中,按照作为二值图像的场景图像数据的每个像素分配的一个语义标签和实例id,确定场景图像数据的二值图像的数值,其中,语义标签为语义类别,实例id为相同场景物的不同编号。另外,由于二值图像只有两个值,0和1,0代表黑,1代表白,或者说0表示背景,而1表示前景,从而根据分割处理后的场景图像数据中的二值图像的数值确定二值图像类别,1或0的分类,确定场景特征是属于前景目标对象还是属于后景目标对象。另外,为了提取准确的属于前景目标对象或后景目标对象的轮廓坐标信息及质心坐标信息,基于opencv软件库对已完成语义分割且作为二值图像的前景目标对象或后景目标对象进行轮廓连通,从而基于连通的轮廓确定各个轮廓点轮廓坐标信息以及质心坐标信息。
需要说明的是,在通过全景分割模型进行分割处理过程中,完成语义分割后,结合opencv软件库对分割后属于前景目标对象或后景目标对象的场景特征进行不同颜色、语义名称标注,从而得到场景描述信息的基础内容。
在一个本发明实施例中,为了进一步限定及说明,所述连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息之后,所述方法还包括:若所述场景目标对象为前景目标对象,则基于预设视觉数据库提取与所述前景目标对象匹配的语义信息标注于所述质心坐标信息处;若所述场景目标对象为后景目标对象,则根据所述后景目标对象的先验知识计算所述后景目标对象的语义阈值,并结合所述二值图像类别、所述语义阈值从预设视觉数据库中提取与所述后景目标对象匹配的语义信息标注于所述质心坐标信息处。
本发明实施例中,为了实现对场景描述信息确定的准确性,需要对前景目标对象或后景目标对象进行不同方式的语义信息标注,具体的,若场景目标对象为前景目标对象,则基于预设视觉数据库,即为opencv软件库中提取与前景目标对象匹配的语义信息标注于质心坐标信息处,若场景目标对象为后景目标对象,则根据后景目标对象的先验知识计算后景目标对象的语义阈值,并结合二值图像类别、语义阈值从预设视觉数据库,即为opencv软件库中提取与后景目标对象匹配的语义信息标注于质心坐标信息处。其中,语义分割部分可以通过循环迭代器将每个前景目标对象分批次传入赋予颜色的渲染模块,在最大连通域中标注语义信息,实例分割部分根据实例id和语义标签将每个实例,使用循环迭代器传入实例分割颜色渲染模块并为每个实例标注名称。由于区分前景目标对象或后景目标对象的不同,针对后景目标对象,首先,确定后景目标对象在场景图像数据中的先验知识;其次,根据先验知识计算每种后景目标对象的语义阈值;最后,根据迭代器传入的二值图像类别、语义阈值及预设视觉数据库opencv软件库提取每个连通域的坐标,并在各连通域的质心坐标处标注语义信息。
在一个本发明实施例中,为了进一步限定及说明,所述利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息包括:获取空间方向中已定义的参考目标的参考质心坐标信息、参考轮廓极值坐标信息,并利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息相对于所述参考轮廓极值坐标信息、所述参考质心坐标信息的空间位置;基于所述空间位置统计分别属于前景目标对象、后景目标对象的语义信息所对应的数量,确定为所述场景目标对象的场景描述信息。
本发明实施例中,为了准确实现对空间位置的确定,从而识别出基于空间位置确定的场景描述信息,在基于空间方向关系识别轮廓坐标信息、质心坐标信息时,首先定义在空间方向中的一个参考目标或参考轮廓,例如,在街景图像中,定义马路为参考目标,则可获取参考目标的参考质心坐标信息、参考轮廓极值坐标信息。结合参考质心坐标、参考轮廓极值坐标信息、空间方向关系识别轮廓坐标信息及质心坐标信息相对于参考质心坐标信息、参考轮廓极值坐标信息的空间位置,即包括在参考质心坐标的左侧、右侧等空间位置等。其中,空间方向关系包括针对前景目标对象的空间位置判断关系,以及后景目标对象的空间位置判断关系。具体的,由于后景目标对象包括如建筑物、绿化带、人行道等场景特征,则当作为参考目标的路的参质心坐标O的坐标信息为(x1,y1),后景目标对象O′的质心坐标信息为(x2,y2),若x
需要说明的是,如图5所示的场景描述信息输出示意图,确定空间位置后,基于空间位置统计分别属于前景目标对象、后景目标对象的语义信息所对应的数量,确定场景目标对象的场景描述信息,即为街景图像中包含路,1个人,3个汽车,建筑物,2个交通标志,红绿灯,绿化带,6个杆,4个人行道,植被,栏杆,路上有1个红绿灯,路旁边有植被,路左方有1个绿化带,2个人行道,左方人行道上有1个人,1个汽车,2个交通标志,4个杆,1个栏杆,路右方有1个建筑物,2个人行道,右方人行道上有,2个汽车1个杆。其中,将确定的空间位置按照不同的场景特征的存储在不同的列表中,从而按照场景特征的顺序进行统计数量,例如,存储在路上、路左方、路右方、左方人行道和右方人行道的场景特征列表中,此场景特征列表为预先定义,且建立索引,将每次遍历的场景目标对象的空间位置所对应的语义信息存放到列表中,获取全部语义信息后,统计数量生成存储在一个列表中的场景描述信息,本发明实施例不做具体限定。
在一个本发明实施例中,为了进一步限定及说明,所述根据识别的空间位置确定所述场景目标对象的场景描述信息之后,所述方法还包括:获取进行全景分割处理过程中的处理参数,所述处理参数包括语义分割结果、数据标注平均交并比;基于所述语义分割结果中的标记为正的正场景图像数据、标记为负的负场景图像数据、标记为负的正场景图像数据、以及所述数据标注平均并交比计算所述全景分割处理的性能指标;若所述性能指标符合预设性能指标阈值,则输出所述场景描述信息。
本发明实施例中,为了提高模型预测的准确性,从而实现场景描述信息的准确输出,在确定场景描述信息之后,通过计算性能指标判断是否输出场景描述信息。其中,在进行全景分割处理时,分别计算分割质量(segmentation quality,SQ)、识别质量(recognition quality,RQ)全景分割质量(panoptic segmentation,PQ)。
需要说明的是,可以通过基于语义分割结果中的标记为正的正场景图像数据、标记为负的负场景图像数据、标记为负的正场景图像数据、以及数据标注平均并交比计算全景分割处理的性能指标,即通过公式(1)、(2)、(3)分别计算。其中,
本发明实施例提供了一种基于场景特征提取的场景描述信息确定方法,与现有技术相比,本发明实施例通过获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系,对场景图像数据的语义分割更加灵活,以增加对场景描述信息的方式实现对场景图像信息中语义分割的目的性,确保场景图像中不同目标对象的目标对象确定场景描述信息的精准性,大大扩大了对场景图像数据进行分割后的使用效率。
进一步的,作为对上述图1所示方法的实现,本发明实施例提供了一种基于场景特征提取的场景描述信息确定装置,如图6所示,该装置包括:
获取模块21,用于获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;
解析模块22,用于解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;
确定模块23,用于利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系。
进一步地,所述装置还包括:
构建模块,用于获取全景分割训练数据集,并基于深度卷积神经网络模型构建全景分割模型,其中,所述全景分割模型中包括基于空洞空间卷积池化金字塔构建的融合多尺度上下文信息层,以及基于语义分割、实例分割融合构建的输出层;
训练模块,用于根据所述所述全景分割训练数据集对所述全景分割模型进行训练的过程中,在融合多尺度上下文信息层中的可分离卷积处引入通道注意力机制并完成所述全景分割模型训练,得到完成模型训练的全景分割模型,所述通道注意力机制为通过压缩处理不同场景特征通道,并为压缩后的场景特征通道分配权重。
进一步地,所述训练模块包括:
生成单元,用于在融合多尺度上下文信息层中,利用压缩函数在可分离卷积处对场景特征通道进行压缩处理,得到所述场景特征通道的压缩实数,所述压缩函数为
训练单元,用于通过在预设非线性函数中加入所述压缩实数对所述场景特征通道中的特征层进行权重加权,对完成权重加权的场景特征通道进行模型训练。
进一步地,所述解析模块包括:
第一确定单元,用于确定进行全景分割处理后的场景特征的二值图像类别,根据所述二值图像类别确定所述场景特征的场景目标对象,所述场景目标对象包括前景目标对象或后景目标对象;
第二确定单元,用于连通所述场景目标对象的轮廓,确定所述场景目标对象的轮廓坐标信息及质心坐标信息。
进一步地,所述装置还包括:标注模块,
所述标注模块,用于若所述场景目标对象为前景目标对象,则基于预设视觉数据库提取与所述前景目标对象匹配的语义信息标注于所述质心坐标信息处;
所述标注模块,还用于若所述场景目标对象为后景目标对象,则根据所述后景目标对象的先验知识计算所述后景目标对象的语义阈值,并结合所述二值图像类别、所述语义阈值从预设视觉数据库中提取与所述后景目标对象匹配的语义信息标注于所述质心坐标信息处。
进一步地,所述确定模块包括:
获取单元,用于获取空间方向中已定义的参考目标的参考质心坐标信息、参考轮廓极值坐标信息,并利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息相对于所述参考轮廓极值坐标信息、所述参考质心坐标信息的空间位置;
确定单元,用于基于所述空间位置统计分别属于前景目标对象、后景目标对象的语义信息所对应的数量,确定为所述场景目标对象的场景描述信息。
进一步地,所述装置还包括:计算模块,输出模块,
所述获取模块,还用于获取进行全景分割处理过程中的处理参数,所述处理参数包括语义分割结果、数据标注平均交并比;
所述计算模块,用于基于所述语义分割结果中的标记为正的正场景图像数据、标记为负的负场景图像数据、标记为负的正场景图像数据、以及所述数据标注平均并交比计算所述全景分割处理的性能指标;
所述输出模块,还用于若所述性能指标符合预设性能指标阈值,则输出所述场景描述信息。
本发明实施例提供了一种基于场景特征提取的场景描述信息确定装置,与现有技术相比,本发明实施例通过获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系,对场景图像数据的语义分割更加灵活,以增加对场景描述信息的方式实现对场景图像信息中语义分割的目的性,确保场景图像中不同目标对象的目标对象确定场景描述信息的精准性,大大扩大了对场景图像数据进行分割后的使用效率。
根据本发明一个实施例提供了一种存储介质,所述存储介质存储有至少一可执行指令,该计算机可执行指令可执行上述任意方法实施例中的基于场景特征提取的场景描述信息确定方法。
图7示出了根据本发明一个实施例提供的一种终端的结构示意图,本发明具体实施例并不对终端的具体实现做限定。
如图7所示,该终端可以包括:处理器(processor)302、通信接口(CommunicationsInterface)304、存储器(memory)306、以及通信总线308。
其中:处理器302、通信接口304、以及存储器306通过通信总线308完成相互间的通信。
通信接口304,用于与其它设备比如客户端或其它服务器等的网元通信。
处理器302,用于执行程序310,具体可以执行上述基于场景特征提取的场景描述信息确定方法实施例中的相关步骤。
具体地,程序310可以包括程序代码,该程序代码包括计算机操作指令。
处理器302可能是中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路。终端包括的一个或多个处理器,可以是同一类型的处理器,如一个或多个CPU;也可以是不同类型的处理器,如一个或多个CPU以及一个或多个ASIC。
存储器306,用于存放程序310。存储器306可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
程序310具体可以用于使得处理器302执行以下操作:
获取场景图像数据,并通过已完成训练的全景分割模型对所述场景图像数据进行全景分割处理,所述全景分割模型为在融合多尺度上下文信息过程中引入通道注意力机制进行模型训练得到的;
解析进行全景分割处理后的场景特征的场景目标对象,并提取所述场景目标对象的轮廓坐标信息及质心坐标信息;
利用空间方向关系识别所述轮廓坐标信息及所述质心坐标信息在所述场景图像数据中的空间位置,根据识别的空间位置确定所述场景目标对象的场景描述信息,所述空间方向关系用于表征按照四个象限区域定义的空间方向的对比关系。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 基于场景特征提取的场景描述信息确定方法及装置
- 一种根据当前场景及其描述信息生成下一场景的方法