基于知识蒸馏的信息检索方法
文献发布时间:2023-06-19 12:22:51
技术领域
本发明属于信息检索领域,尤其涉及一种基于知识蒸馏的信息检 索方法。
背景技术
随着互联网的普及和发展,人们可以接触到非常丰富的资源。对 于某些人们想要了解的领域以及相关知识,人们可以选择信息检索来 获取相关的知识。为了提升检索效率,优化检索效果,可以利用人工 智能技术辅助信息检索,以帮助人们更快更好地获取想要知道的相关 知识。
然而,现存的许多模型和方法存在着精度与速度两者不可兼得的 问题。精度较高的模型往往有着大量的参数需要进行计算,导致检索 延时大幅度提高,而速度较快的检索模型由于其更加看重速度,其精 度也会有着一定的损失。
鉴于此,我们基于知识蒸馏(KD,knowledge distillation)的方 法,利用精度较高的教师模型进行辅助训练精度稍低但是速度却快许 多的学生模型,以期望得到速度变化不大但精度却提升较多的一个新 的学生模型,以此来达到检索效果提升的目的。
发明内容
本发明的目的在于提供一种基于知识蒸馏的信息检索方法,从而 方便人们更加高效地进行信息检索。
本发明解决其技术问题采用的技术方案如下:一种基于知识蒸馏 的信息检索方法,包括以下步骤:
1)训练教师模型:基于交叉熵损失函数,利用训练集T来训练教 师模型。
2)训练集段落重排序:使用步骤1)训练后的教师模型,对训 练集T
3)训练学生模型:利用训练集T,计算学生模型的交叉熵损失L
4)利用学生模型进行信息检索:利用学生模型计算用户查询所 对应的段落的评分,将评分最高的段落作为查询答案。
进一步地,步骤1)所述的教师模型的训练,具体为:
训练集T为
Teacher(Q,d)=BERT-CAT(Q,d)=BERT([CLS;Q;SEP;d])
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS和SEP表示BERT中的特殊词条,“;”表示拼接操作,下标1表示 取CLS词条,W表示一个权重矩阵。
之后,对训练集T中每个查询及其所对应正例和负例的三元组,使 用该教师模型计算正例得分P
P
N
再通过正负例得分计算相应的交叉熵损失:
最后通过最小化交叉熵损失来优化教师模型,训练得到最终的教 师模型。
进一步地,步骤2)所述的训练集段落重排序,具体为:
利用教师模型对训练集T
基于步骤1)所训练的教师模型Teacher,对于训练集T
S=Teacher(Q,D)={s
其中,s
进一步地,步骤3)所述的学生模型的训练,具体为:
首先,选择BERT-DOT模型和ColBERT模型作为学生模型Student。
BERT-DOT模型是BERT-CAT模型的简化,将拼接操作改成了内 积计算,其计算查询Q与段落d之间相关性的评分公式为:
r
r
BERT-DOT(Q,d)=r
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS表示特殊词条,“;”表示拼接操作,下标1表示取CLS词条,W表 示一个权重矩阵,·表示内积运算。
该BERT-DOT模型检索效果相比于教师模型会稍差,但计算速度 会大幅度提升。
ColBERT是BERT-DOT的一种变体,其在顶层多加了一层最大池 化的计算,显著提高了检索效果,其计算查询Q与段落d之间相关性 的评分公式为:
r
r
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS表示特殊词条,“;”表示拼接操作,rep(MASK)表示多个MASK词 条拼接而成的词条集,下标1表示取CLS词条,W表示一个权重矩 阵,·表示内积运算。
该ColBERT模型相对于BERT-DOT模型能提升检索效果,计算速 度与BERT-DOT模型类似。
之后,对训练集T中每个查询及其所对应正例和负例的三元组,使 用学生模型计算正例得分P
P
N
其中,Student代表BERT-DOT模型和ColBERT模型。
之后通过正负例得分计算相应的交叉熵损失:
接着是计算重排序序列的列表置换损失函数。
根据步骤2)所得的重排序段落训练集T
使用学生模型重新计算所有段落相对于查询Q的得分,得到一个新 的分数列表:
S′=Student(Q,D
根据该列表,得到查询置换的概率:
之后最大化每个查询置换概率的对数似然,即最小化列表置换损 失函数:
最小化损失Loss2能够使学生模型计算出的同一个段落集对查询 的相关性的排序结果更加接近教师模型,从而提升学生模型检索效果。
最后,将两部分损失加权求和作为模型的损失:
Loss=Loss1+αLoss2
其中,α为权重参数。
进一步地,所述步骤4)具体为:
利用学生模型进行信息检索。
在步骤3)训练得到学生模型后,使用该学生模型对测试集中相 应查询所对应的段落集进行重排序,获取排行最高的段落作为查询答 案,以此来测试模型的效果。
对于用户给定的问题,在语料库中初步筛选出相应段落,再用学 生模型计算段落相对于问题的得分,根据得分的高低将相应用户所需 要的答案量的答案提供给用户。
本发明方法与现有技术相比具有的有益效果:
1.本方法依靠人工智能方法进行信息检索,减少人工工作,更加 系统、科学。
2.本方法的流程可以依靠机器学习自动完成,无需人工干预,减 轻用户负担。
3.本方法在神经网络中引入知识蒸馏方法,可以充分利用教师模 型的检索效果,以此优化了学生模型的检索效果。
4.本方法预测准确率较高,能够较准确检索出用户想要检索出来 的结果。
5.本方法具有良好的可扩展性,针对不同领域,可以选用不同领 域的检索数据进行训练,在不同领域的检索效果都可以得到响应的提 升并且不会造成太多检索延时增加。
附图说明
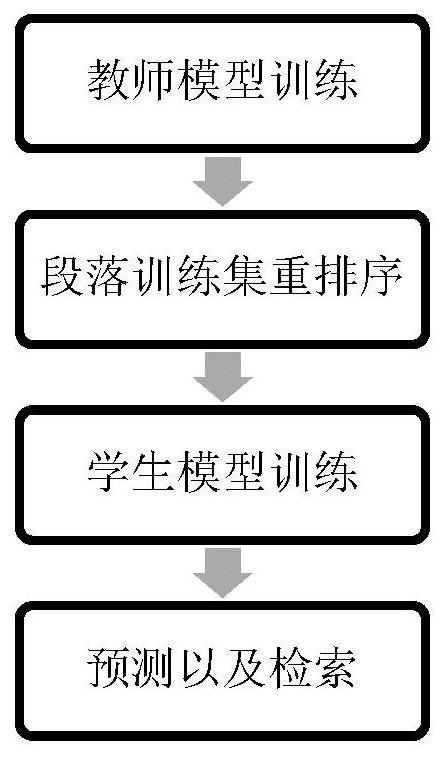
图1是本发明方法总体流程图;
图2是本发明实施例提供的学生模型训练过程中知识蒸馏模型 结构。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1所示,本发明提供一种基于知识蒸馏的信息检索方法,包 括以下步骤:
1)训练教师模型:基于交叉熵损失函数,利用训练集T来训练教 师模型。
2)训练集段落重排序:使用步骤1)训练后的教师模型,对训 练集T
3)训练学生模型:利用训练集T,计算学生模型的交叉熵损失L
4)利用学生模型进行信息检索:利用学生模型计算用户查询所 对应的段落的评分,将评分最高的段落作为查询答案。
进一步地,步骤1)所述的教师模型的训练,具体为:
训练集T为
Teacher(Q,d)=BERT-CAT(Q,d)=BERT([CLS;Q;SEP;d])
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS和SEP表示BERT中的特殊词条,“;”表示拼接操作,下标1表示 取CLS词条,W表示一个权重矩阵。
之后,对训练集T中每个查询及其所对应正例和负例的三元组,使 用该教师模型计算正例得分P
P
N
再通过正负例得分计算相应的交叉熵损失:
最后通过最小化交叉熵损失来优化教师模型,训练得到最终的教 师模型。
进一步地,步骤2)所述的训练集段落重排序,具体为:
利用教师模型对训练集T
基于步骤1)所训练的教师模型Teacher,对于训练集T
S=Teacher(Q,D)={s
其中,s
进一步地,步骤3)所述的学生模型的训练,如图2所示,具体为:
首先,选择BERT-DOT模型和ColBERT模型作为学生模型Student。
BERT-DOT模型是BERT-CAT模型的简化,将拼接操作改成了内 积计算,其计算查询Q与段落d之间相关性的评分公式为:
r
r
BERT-DOT(Q,d)=r
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS表示特殊词条,“;”表示拼接操作,下标1表示取CLS词条,W表 示一个权重矩阵,·表示内积运算。
该BERT-DOT模型检索效果相比于教师模型会稍差,但计算速度 会大幅度提升。
ColBERT是BERT-DOT的一种变体,其在顶层多加了一层最大池 化的计算,显著提高了检索效果,其计算查询Q与段落d之间相关性 的评分公式为:
r
r
其中,BERT是一种基于Transformer的双向编码表示语言模型, CLS表示特殊词条,“;”表示拼接操作,rep(MASK)表示多个MASK词 条拼接而成的词条集,下标1表示取CLS词条,W表示一个权重矩 阵,·表示内积运算。
该ColBERT模型相对于BERT-DOT模型能提升检索效果,计算速 度与BERT-DOT模型类似。
之后,对训练集T中每个查询及其所对应正例和负例的三元组,使 用学生模型计算正例得分P
P
N
其中,Student代表BERT-DOT模型和ColBERT模型。
之后通过正负例得分计算相应的交叉熵损失:
接着是计算重排序序列的列表置换损失函数。
根据步骤2)所得的重排序段落训练集T
使用学生模型重新计算所有段落相对于查询Q的得分,得到一个新 的分数列表:
S′=Student(Q,D
根据该列表,得到查询置换的概率:
之后最大化每个查询置换概率的对数似然,即最小化列表置换损 失函数:
最小化损失Loss2能够使学生模型计算出的同一个段落集对查询 的相关性的排序结果更加接近教师模型,从而提升学生模型检索效果。
最后,将两部分损失加权求和作为模型的损失:
Loss=Loss1+αLoss2
其中,αα为权重参数。
进一步地,所述步骤4)具体为:
利用学生模型进行信息检索。
在步骤3)训练得到学生模型后,使用该学生模型对测试集中相 应查询所对应的段落集进行重排序,获取排行最高的段落作为查询答 案,以此来测试模型的效果。
对于用户给定的问题,在语料库中初步筛选出相应段落,再用学 生模型计算段落相对于问题的得分,根据得分的高低将相应用户所需 要的答案量的答案提供给用户。
实施例
下面结合本发明的方法详细说明本实施例实施的具体步骤,如下:
在本实施例中,将本发明的方法应用于MS MARCO数据集,对其中 的查询的相关段落进行检索。
1)训练集包含了640000项数据,其中包含320000的查询以及相 对应的320000的正例和320000的负例。
2)段落训练集包含800000项数据,其中包含80000的查询以及 相对应的80000的正例和720000的负例。
3)测试集总共有6669195项数据,其中包含6980个查询,每个 查询对应平均1000个段落,大部分查询对应的段落都包含至少一个 正例段落。
将这些1)和2)的数据集按照本方法进行训练,其中α取值为0.1, 在3)的测试集上进行测试,计算每个方法的mrr@10,Recall@50, Recall@200,Recall@1000这四个值,其结果如表1所示。
表1预测结果评估
对于知识蒸馏模型,不同α值的mrr@10结果如表2所示。
表2模型对比结果(不同α)
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施 例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员, 在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技 术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同 变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据 本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及 修饰,均仍属于本发明技术方案保护的范围内。
- 基于知识蒸馏的信息检索方法
- 基于知识内在涵义的知识信息检索方法及其系统