一种知识驱动型的文本到图像生成方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明属于图像生成技术领域,尤其是涉及以先验知识作为驱动的多阶段逐步优化的一种知识驱动型的文本到图像生成方法。
背景技术
文本生成图像(Text-to-Image Generation,T2I)是涉及语言和图像的多模态任务。给出一段描述,文本生成图像技术将生成这段描述相对应的图像,即“依文绘图”,它是“看图说话”的逆过程。近些年来,随着生成对抗网络的日渐发展,文本到图像的生成技术也得以迅猛进步。
目前,大多数现有的T2I模型通常使用编码器-解码器架构将文本描述转换为合成的图像。文本生成图像的主要挑战是如何有效、准确地将文本信息映射到一个有效的视觉空间中,在此基础上合成具有照片真实感和语义一致性的图像。为此,早期的方法使用对抗生成网络的编码器-解码器结构,在该结构中,使用鉴别器来判断生成的图像是否真实,至此为单阶段文本生成图像的方式。在最近的一些方法中,单阶段的生成方式扩展为多阶段逐步优化的方式,这种多阶段方式直观地模仿人的绘画,即先画草图,然后不断地修改优化。
尽管文本生成图像技术已经取得很大的进步,但是其性能仍然不能令人满意,特别是与无条件的图像生成和图像到图像的生成任务相比,这主要归因于如下三方面:第一,根据文本信息生成图像会引入很多随机性,未被提及的图像属性将有更多样化的表示,这就导致合成图像与真实图像之间往往会存在巨大的差距;第二,大多数现有的文本生成图像技术仅以给定文本为条件生成图像,并未考虑到先验图像分布和已知的视觉环境来进行更加合理的图像生成;第三,文本生成图像技术的现有评估指标(如IS和FID)基本上是为视觉质量评估而设计的,而合成图像和描述之间的语义一致性被忽略从而导致无法评估;因此引入图像先验知识对于生成更加符合常识的图像十分重要,同时引入新的语义一致性评价标准对于文本生成图像领域来说十分必要。
发明内容
本发明的目的在于针对现有技术存在的上述问题,提供以先验知识作为驱动的多阶段逐步优化的一种基于图像先验知识的文本生成图像方法,该方法以对抗生成网络为基础,可以有效提升生成图像的合理性;同时引入一种“伪图灵测试”的语义一致性度量标准,更加准确地度量根据文本生成的图像的质量。
本发明包括以下步骤:
1)输入一段语言描述和一个随机噪声;
2)提取语言的全局特征和单词特征;
3)对于全局语言特征进行重采样得到新的全局语言特征;
4)拼接全局语言特征与随机噪声,得到初始图像特征;
5)从视觉知识库中获得先验知识并进行整合,得到视觉特征;
6)将初始图像特征与视觉先验特征进行融合,通过卷积模块得到第一阶段的图像;
7)将上一阶段的图像特征与视觉先验特征融合后,与单词特征进行多模态融合得到当前阶段的图像特征,并通过卷积模块得到当前阶段的图像;
8)进行生成图像与输入文本之间语义一致性的评价。
在步骤1)中,所述语言描述最大长度可设为40,噪声维度可设为256;
在步骤2)中,所述提取语言的全局特征和单词特征,可利用在CUB或者COCO数据集上训练好的双向LSTM提取文本的全局特征和单词特征,首先通过双向LSTM提取语言的全局特征
在步骤3)中,所述重采样具体过程如下:
步骤3-1,基于全局语言特征f
步骤3-2,从高斯分布
在步骤4)中,所述得到初始图像特征的具体步骤为:拼接语言特征
其中,
在步骤5),所述视觉知识库由训练集中与文本描述最相近的M张图像构成,并利用在ImageNet上训练好的ResNet50分别提取每个图像关键特征F
所述从视觉知识库中获得先验知识并进行整合,得到视觉特征的具体方法可为:
用语言特征f
α=Softmax(W
其中,W
根据下列算式通过强读取(Hard-Reading)得到视觉特征
β
在步骤7)中,所述融合可利用Dynamic Memory方式对多模态特征进行融合;所述卷积模块的训练过程中可采用Adam优化器,设置初始学习率和批处理大小分别为0.0002和20。
在步骤8)中,所述评价的指标包括IS(Inception Score)、FID(FréchetInception Distance)、PTT(Pseudo Turing Test);
使用PTT进行语义一致性的评价,具体过程如下:
步骤8-1,在CUB或COCO数据集上训练好的图像描述生成模型ShowAttendTell(XuK,et al.Show,attend and tell:Neural image caption generation with visualattention,2015)与BUTD(Anderson P,et al.Bottom-up and top-down attention forimage captioning and visual question answering,2018)作为“专家”来描述生成的图像,衡量“专家”的描述内容与生成前输入的描述内容的一致性;
步骤8-2,使用在CUB或COCO数据集上训练好的Bi-LSTM与InceptionV3分别提取输入文本和生成图像的全局特征,衡量两者的余弦相似度。
本发明通过引入视觉知识库(VKB)为图像生成提供额外的先验知识,视觉知识库将以key-value的形式被存储以便于知识读取操作。为更好地利用先验知识,提供两种新的相关知识读取方式:弱读取(Soft-Reading)和强读取(Hard-Reading)。最后,设计一种“伪图灵测试”(Pseudo Turing Test,PTT)的语义一致性度量标准,在不同多媒体任务(例如图像字幕生成、文本匹配等)的“专家”的帮助下,直接或间接地评估合成图像与给定文本的语义一致性。
采用上述方案后,本发明的有益效果是:
(1)本发明提供一种用于文本生成图像的知识驱动型对抗生成网络,该网络旨在利用图像先验知识逐步优化图像生成质量,通过弱读取或强读取的先验知识整合方式,使得生成的图像逼真且合理。
(2)本发明提供一种“伪图灵测试”的度量标准,可以更加方便、有效地评价给定描述与生成图像的语义一致性,一定程度上解决先前使用纯视觉质量评估的窘境。
附图说明
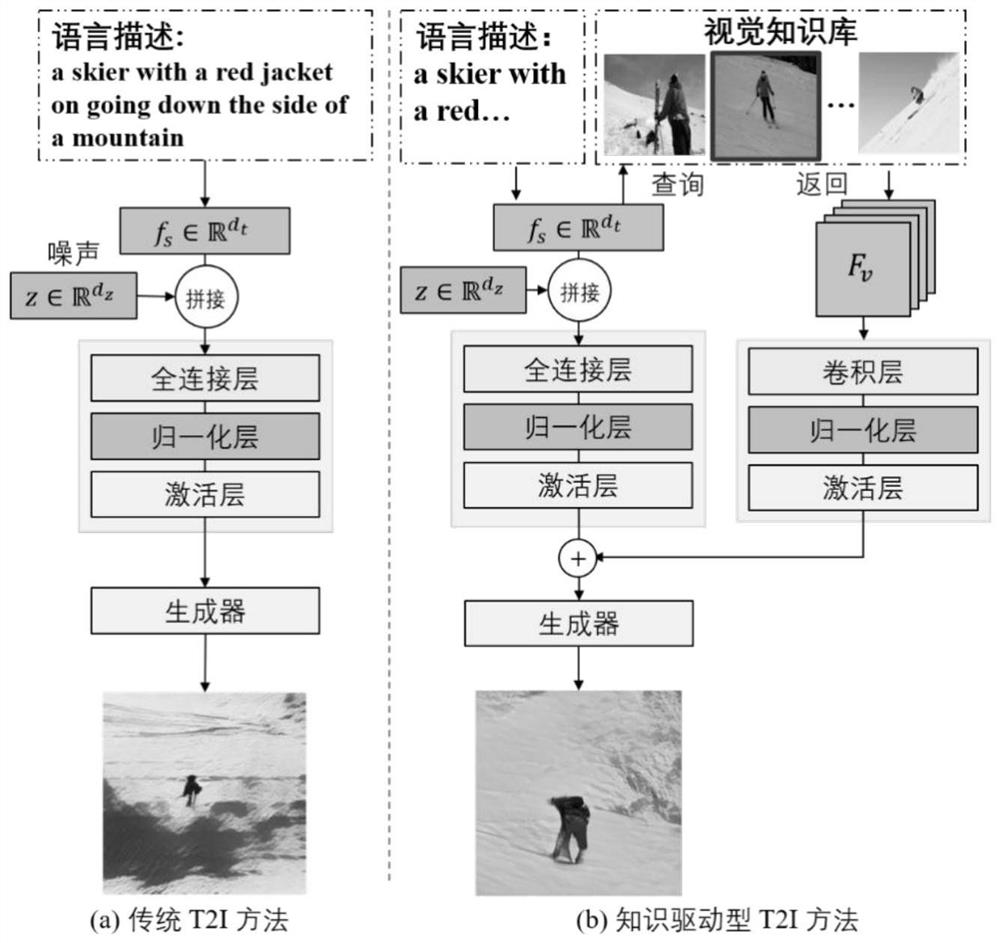
图1是本发明的基本流程图;左图为传统文本生成图像流程,右图为知识驱动型的文本生成图像流程;
图2是视觉知识库构建示意图;
图3是知识驱动型文本生成图像的网络架构图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
步骤1,设置输入大的语言描述最大长度为40,噪声维度为256;
步骤2,提取语言的全局特征
步骤3,对于全局语言特征f
步骤4,拼接语言特征
其中,
步骤5,用语言特征f
α=Softmax(W
其中,W
β
步骤6,将初始图像特征
步骤7,上一阶段的图像特征
步骤8,出常见的IS、FID评价指标外,使用提出的PTT进行生成图像与输入文本之间语义一致性的评估。
步骤2中利用在CUB或者COCO数据集上上训练好的双向LSTM提取文本的全局特征和单词特征。
步骤3中的重采样具体过程如下:
步骤3-1,基于全局语言特征f
步骤3-2,从高斯分布
步骤5中的视觉知识库由训练集中与文本描述最相近的M张图像构成。并利用在ImageNet上训练好的ResNet50分别提取每个图像关键特征F
步骤7中利用DynamicMemory方式对多模态特征进行融合。
所述卷积神经网络的训练过程中采用Adam优化器,设置初始学习率和批处理大小分别为0.0002和20。
步骤8中使用PseudoTuringTest(PTT)进行语义一致性的评价。具体过程如下:
步骤8-1,在CUB或COCO数据集上训练好的图像描述生成模型ShowAttendTell(XuK,et al.Show,attendandtell:Neural image caption generation withvisualattention,2015)与BUTD(Anderson P,et al.Bottom-up and top-down attention forimage captioning and visual question answering,2018)作为“专家”来描述生成的图像,衡量“专家”的描述内容与生成前输入的描述内容的一致性;
步骤8-2,使用在CUB或COCO数据集上训练好的Bi-LSTM与InceptionV3分别提取输入文本和生成图像的全局特征,衡量两者的余弦相似度;
步骤8-3,用生成图像在100个(其中,1个为输入文本,其余99个是随机的数据集中其他文本)文本中检索匹配文本,计算R-precision。
如图1所示,本发明提供一种用于基于先验知识的文本生成图像方法(右图),与传统的文本生成图像方法(左图)相比,本发明在生成过程中引入图像先验知识,使得生成的图像更加逼真、更加符合常识,相当于人类在进行绘画之前已经拥有一定的知识存储,因此在绘画时会绘出更加符合事实的图像。本发明的实现包括如下步骤:
一、视觉知识库的构建
如图2所示为视觉知识库(VKB)的构建示意图,视觉知识库的构建将有利于本发明提出的知识驱动型文本生成图像方法(KD-GAN)的实施。对于每个文本-图像对,即一个自然语言描述和相应的真实图像,VKB包含一个由M个相关图像组成的小型知识库,该知识库将用作该文本-图像对的先验知识,这些先验知识通过文本到文本的匹配过程收集得到。
首先,给定一个文本-图像对,利用预先训练好的语言编码器分别提取该文本-图像对中的文本和训练集中文本的句子特征,计算它们之间的余弦相似度,从而检索出与给定文本最相关的M个描述;然后,将这些被选取的句子对应的图像作为参考知识,形成该文本-图像对的小型知识库。然后,KD-GAN可以根据不同的策略读取训练或测试过程中的图像信息。
为有利于后续的知识读取,上述得到的视觉知识将通过key-value的形式进行存储。使用ResNet50将每个图像编码为key和value特征,将ResNet50最后一个池化层之后得到的特征向量作为key用于查询,将最后一个卷积得到的特征图作为value用于读取。通过上述过程,一个给定的文本-图像对由两部分组成:
得到上述视觉知识库后,F
二、模型实施过程
2.1模型的输入:
如图3所示为模型的网络架构图,可以看出模型的输入为一段语言描述和一个随机噪声
2.2语言特征编码器:
对于输入的语言描述,首先通过双向LSTM(可参见A.Graves andJ.Schmidhuber.Framewise phoneme classification with bidirectional lstm andother neural network architectures.In Neural networks.2005.)提取语言的全局特征
2.3条件增强:
对于得到的语言描述的全局特征表示,通过条件增强(ConditioningAugmentation,CA)进行重采样。对于语言全局特征
2.4初始图像生成:
初始阶段使用DM-GAN(可参见M.Zhu,P.Pan,W.Chen,and Y.Yang.Dm-gan:Dynamicmemory generative adversarial networks for text-to-image synthesis.InCVPR.2019)来生成初始图像。具体来说,对于条件增强后的全局语言描述特征CA(f
其中,σ表示激活函数,||表示拼接操作,
在得到初始隐藏状态后,将从视觉知识库中获得先验知识并进行整合,本发明提出两种读取整合先验知识的方式,分别为弱读取和强读取。弱读取估计句子与对应小型知识库中每个知识的相关性,然后返回所有知识特征的加权和。即给定句子全局特征
α=Softmax(W
其中,W
其中,F
其中,
得到句子相应的先验知识后,将其与初始隐藏状态
其中,Up表示一种用于融合先验知识特征和潜在状态的上采样卷积层。
2.5多阶段图像优化及生成:
根据上述生成的初始图像,KD-GAN进行多阶段优化生成以获得更高质量的图像,对于第i个阶段,首先将
其中,MultimodalFusion可以是任何多模态融合方式,这里使用Dynamic Memory方式(可参见M.Zhu,P.Pan,W.Chen,andY.Yang.Dm-gan:Dynamic memory generativeadversarial networks for text-to-image synthesis.In CVPR.2019)进行融合。与初始阶段一样,使用基于CNN的解码器生成相应图像
其中,设i=1,2、
2.6多阶段判别器:
对于每个阶段,设置相应的判别器用于判断该阶段生成图像的真假,这里使用与DM-GAN类似的基于CNN的编码器,用来计算该阶段所生成图像为真的得分,该分值用于后续损失函数的计算。
三、模型训练过程
3.1损失函数的计算:
模型的损失函数
其中,D
μ(f
3.2模型训练参数设置:
在训练过程中,使用Adam优化器,并设置学习率为0.0002,超参为β
3.3模型的训练:
对于模型的训练,首先将输入的图片和语言经过步骤二得到模型的输出结果,接着通过步骤3.1来计算模型的损失函数,最后,利用损失函数的梯度反向传播来更新步骤二中的模型参数,训练和迭代过程的设置如步骤3.2所描述。最终完成整个模型的训练。
四、模型评价:
IS和FID是T2I中广泛使用的两个指标,都旨在评估合成图像的清晰度和多样性,这两个指标的公式如下:
FID=||μ
其中,
尽管IS和FID被广泛使用,但是它们都是为视觉质量评估而设计的,提出一种叫做“伪图灵测试”(PTT)的质量评估方式,旨在测量文本描述与生成图像之间的语义一致性。PTT包括两个图像字幕伪专家ShowAttendTell和UpDown,间接评估生成图像在语义上是否与给定的句子一致。两位伪专家对不同的T2I方法生成的图像进行重新描述,然后用BLEU,CIDEr和ROUGE来衡量重新描述的图像与输入文本的匹配程度。
此外还提供另外一种伪专家用来进行文本到图像的匹配,叫做
这里用余弦相似度来定义相关性,即
五、模型部署过程:
在经过步骤三的模型训练后,对于训练完毕的模型,将输入的语言经过步骤二即可得到模型的输出作为相对应的生成结果,即输入某段语言描述,模型输出最符合描述的图像。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 一种知识驱动型的文本到图像生成方法
- 一种结合文本双曲分段知识嵌入多重知识图谱的问答方法