用于提供匿名患者数据集的方法和系统
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及一种用于以数字形式提供患者数据集的计算机实现的方法和一种相应的系统,所述方法和系统例如能够用于设定医疗设备的参数和/或用于训练医疗设备的人工智能模块。
背景技术
在多个临床应用和系统中使用结构化的数据集。所述数据集涉及以下患者或人员,关于所述患者或人员存在病例研究。项目例如能够包括不同的医学研究,所述医学研究涉及特定的主题或特定的医学情况。医学研究能够通过不同的医学机构执行。所述医疗机构例如具有医院、研究机构或实验室。医学研究通常具有大量的患者病例研究。与此相应地,项目能够包括大量具有相应的患者数据集的病例研究。项目在此通常涉及特定的医学情况,例如心脏梗塞或前列腺肥大。项目的多个结构化的数据集能够存储在中央或分布式数据库中以进行进一步评估。患者数据包含敏感的个人数据,尤其是健康数据,所述数据必须匿名化以进行进一步评估,以便能够确保相关的患者的匿名性。在此能够防止:各个数据集可能被隔离,所述数据集允许能够识别相应的患者或相应的人员。此外能够确保:涉及相同的数据的两个不同的数据集能够链接或联接。
此外能够防止:敏感属性的值能够从其它属性的值中推导出。能够对于多个医疗应用和医疗设备评估匿名化的数据,而无法获取关于患者或人员的身份的结论,匿名化的数据内容基于所述患者或人员的个人数据。
用于匿名化患者数据的传统的方法基于所谓的k-匿名性。k-匿名性是用于评估聚合数据的匿名性的一种形式化标准。在此,数据集的不同的属性首先分为非敏感属性和敏感属性。敏感属性包括关于相应的患者的个人数据,例如关于疾病的信息。敏感属性表示关于人员的值得保护的信息。非敏感属性包括该人员的一般个人特征,例如相应的人员的年龄和/或性别。非敏感属性就其而言又能够分为标识符和准标识符。标识符本身适用于明确地识别特定的人员或特定的患者。与此相反,准标识符与数据集内的其它数据结合,必要时使用其它数据集,适合用于识别所涉及的患者。k匿名化的目的是改变多个数据集,使得无法区分所述数据集。为此,直接的标识符被删除或隐蔽(例如,姓名或患者ID被假名替换),而准标识符被更改或隐蔽,使得不能强调数据集(例如,非常年轻或非常年长的人员与区间相关联,而不是提及特定的年龄)。如果每个数据点与至少k-1个其它数据点无法区分,则所产生的数据集被称为k-匿名的。数据的匿名性在此如下实现:在敏感属性值与在组内的人员的各个数据点之间没有明确的关联性是可能的。为了执行数据库内容的匿名化,其中所述数据库内容包括属于一个项目的多个患者数据集,通常需要的是,在匿名化之前对要匿名化的整体数据库内容进行耗费的数据预处理,以便能够为患者数据集的准标识符获得适宜的泛化限制。然而,如果连续地生成数据,例如基于所生成的传感器数据的连续的数据流,则对数据库内容的这种数据预处理是不可行的。如果数据库内容过大,预处理通常在实践中是难以执行的。在许多应用情况中,关于特定的项目的项目数据源的数据库内容包括数TB(兆兆字节)。更困难的是,大部分由医疗机构所使用的系统仅允许相对较慢的数据交换。在许多医疗机构,例如医院中,使用所谓的PACS(Picture Archiving andCommunication System,图片存档和通信系统)系统。所述系统尤其包括也适用于检测和交换数字图像数据的图像存档和通信系统。
由于现有的非常大的数据量以及传统的数据库系统的受限的数据传输速度,因此,用于获得匿名化和模糊化参数的数据预处理非常耗时或者在实践中难以执行,并且在许多应用情况中甚至是不可行的。
发明内容
因此,本发明的一个目的是,提供一种允许以有效的方式匿名化现有的患者数据集的方法和系统。
根据本发明,所述目的通过具有在权利要求1中给出的特征的计算机实现的方法以及通过具有在权利要求15中给出的特征的相应的系统来实现。
因此,本发明提供一种用于提供匿名化的患者数据集的计算机实现的方法,所述方法包括以下步骤:
分析统计学人口数据,以用于确定模糊化参数,和
匿名化含有准标识符作为属性的患者数据集,其方式为:借助于所确定的模糊化参数来模糊化患者数据集的准标识符,以用于生成匿名化的患者数据集。
根据本发明的计算机实现的方法的一个优点在于,为了确定模糊化参数,不需要对项目数据源的数据库内容进行数据预处理,而是为此能够采用可用的统计学数据库。因此能够以有效的方式确定模糊化参数,而这不会受到常规的PACS系统的技术限制的阻碍。以这种方式,即使使用更少的计算资源,患者数据集的匿名化也能够以更高的速度进行。因此,计算机实现的方法比传统的匿名化方法明显更快,并且也需要使用更少的资源,尤其是更少的计算和存储资源。网络安全和数据保护方面也发挥了作用,因为较少地暴露和较少地处理患者数据。
在根据本发明的计算机实现的方法的一个可行的实施形式中,将患者数据集的准标识符模糊化,其方式为:将准标识符的值泛化成包括其的泛化区间。
在根据本发明的计算机实现的方法的另一可行的实施形式中,将患者数据集的准标识符模糊化,其方式为:至少部分地删除或掩蔽准标识符的值的一个或多个字符。
在根据本发明的计算机实现的方法的另一可行的实施形式中,将患者数据集的准标识符模糊化,其方式为:在算术或逻辑运算中以改变值改变准标识符的值。在一个可行的实现方案中,在此,改变值能够通过随机值形成。
在根据本发明的计算机实现的方法的另一可行的实施形式中,通过分析统计学人口数据确定的模糊化参数给出用于泛化准标识符的泛化区间的区域范围。
在根据本发明的计算机实现的方法的另一可行的实施形式中,通过分析统计学人口数据确定的模糊化参数给出准标识符的值的要删除或掩蔽的字符的数量和/或位置。
在根据本发明的计算机实现的方法的另一可行的实施形式中,通过分析统计学人口数据确定的模糊化参数给出用于改变准标识符的值的改变值。
在根据本发明的计算机实现的方法的一个可行的实施形式中,患者数据集具有不同类型的属性。在一个可行的实施形式中,所述属性包括标识符、准标识符以及敏感属性。在此,标识符本身适用于明确地识别相应的患者。与此相反,准标识符仅与其它数据结合地适用于明确地识别相应的患者。敏感属性包括相应的患者的要保护的个人数据。
在根据本发明的计算机实现的方法的另一可行的实施形式中,在匿名化患者数据集时,包含在患者数据集中的标识符被自动删除或掩蔽。
因此已经能够确保一定的数据安全性。
在根据本发明的计算机实现的方法的另一可行的实施形式中,从项目数据源中读出患者数据集。项目数据源能够具有中央数据库或者是分布式数据库。
在根据本发明的计算机实现的方法的另一可行的实施形式中,基于传感器数据实时地自动生成患者数据集。
在根据本发明的计算机实现的方法的另一可行的实施形式中,将从项目数据源中读取的患者数据集和/或基于传感器数据生成的患者数据集作为数据流为了其匿名化连续地借助于所确定的模糊化参数模糊化,以用于生成匿名化的患者数据集。在此生成的匿名化的患者数据集优选存储在匿名数据库中,以用于进一步评估。
在根据本发明的计算机实现的方法的另一可行的实施形式中,匿名化的患者数据集形成具有集群大小的集群,其中所有模糊化的准标识符都是相同的。
在根据本发明的计算机实现的方法的另一可行的实施形式中,基于从一个或多个统计学数据库中读取的统计学人口数据来计算人口期望值,所述人口期望值对于在项目附属区域内的人群给出下述人员的数量,所述人员符合匿名化的患者数据集的根据模糊化选项来模糊化的准标识符。
在根据本发明的计算机实现的方法的另一可行的实施形式中,借助于模糊化参数对患者数据集的准标识符进行模糊化,使得计算出的人口期望值大于在匿名化的患者数据集内的集群的可选的集群大小。
在根据本发明的计算机实现的方法的另一可行的实施形式中,存储在匿名的数据库中的匿名化的患者数据集用作为训练数据,以用于训练人工智能模块,尤其用于训练人工神经网络。
在根据本发明的计算机实现的方法的另一可行的实施形式中,根据存储在匿名数据库中的匿名化的患者数据集自动地设定用于检查患者的医疗设备的设备参数。
在根据本发明的计算机实现的方法的另一可行的实施形式中,患者的患者数据集的属性至少部分地通过传感器来检测。
在根据本发明的计算机实现的方法的另一可行的实施形式中,患者数据集的属性包括文本数据、音频数据和/或图像数据。
根据本发明的计算机实现的方法能够通过相应的程序来执行,所述程序存储在计算机程序产品或计算机可读的存储介质中或通过数据载体信号来传输并且被读取,以用于通过数据处理单元的处理器来执行。
根据另一方面,本发明提供一种具有权利要求15中给出的特征的用于提供匿名化的患者数据的系统。
因此,本发明提供一种用于提供匿名化的患者数据的系统,所述系统具有数据处理单元,所述数据处理单元适合于分析人口数据,以确定模糊化参数,并且对从项目数据源中读取的患者数据集进行匿名化,以生成匿名化的患者数据集,其方式为:借助于所确定的模糊化参数将所读取的患者数据集的准标识符模糊化。
附图说明
在下文中参考示例性实施形式详细地阐述本发明的更大的细节,所述示例性实施形式在附图中示出。
所附的附图是为了能够更好地理解本发明并且是本公开文献的一部分。附图图解说明本发明的实施形式,并且应与说明书一起详细描述本发明的原理。本发明的其它实施形式和本发明的许多预期的优点可通过参考附图进行的描述中明显识别出。此外,相同的附图标记表示相同或相似的部分。
方法步骤的编号应便于理解,并且除非明确说明或清楚地暗示相反内容,否则不应解释为所标识的步骤必须根据其附图标记的编号来执行。同样地,一些或者甚至所有方法步骤能够同时执行、以重叠的方式执行或依次执行。
图1示出用于示出根据本发明的用于提供匿名化的患者数据的系统的一个可行的实施形式的方框图;
图2示意性地示出可行的应用实施例,所述应用实施例使用通过根据本发明的系统匿名化的患者数据;
图3示出用于示出根据本发明的用于提供匿名化的患者数据集的计算机实现的方法的一个实施例的流程图;
图4示意性地示出具有患者数据集的表格,以用于阐述根据本发明的计算机实现的方法以及根据本发明的用于提供匿名化的患者数据的系统的运行模式。
具体实施方式
图1示出根据本发明的用于提供匿名化的患者数据P-DS的系统1的一个可行的实施形式的方框图。系统1具有带有一个或多个处理器的数据处理单元2,如在图1中示意性示出的。数据处理单元2具有第一数据处理级2A,所述第一数据处理级设计为用于,能够分析人口数据,以确定模糊化参数OP。此外,数据处理单元2具有第二数据处理级2B,所述第二数据处理级将患者数据集P-DS匿名化,以生成匿名化的患者数据集P-DS’。为此,数据处理单元2的第二数据处理级2B使用模糊化参数OP,所述模糊化参数由第一数据处理级2A通过分析人口数据生成。在图1中示出的实施例中,能够从系统1的项目数据源3中读取要匿名化的患者数据集P-DS。项目数据源3能够存储多个不同的患者数据集P-DS,所述患者数据集属于一个项目,例如关于特定的医学情况的项目,所述医学情况例如为心脏梗塞或前列腺肥大。患者数据集P-DS作为数据流DS输送给数据处理单元2的第二数据处理级2B。第二数据处理级2B对所输送的患者数据集P-DS进行匿名化,其方式为:将患者数据集P-DS的准标识符Q-ID借助于所确定的模糊化参数OP自动地模糊化。在一个可行的实施形式中,以这种方式匿名化的患者数据集P-DS’能够存储在匿名数据库4中,以用于进一步评估。例如,能够将匿名化的患者数据集P-DS’输送给另一数据处理单元5,以进行进一步的分析和评估。数据处理单元5例如能够在另外的医学研究过程中对匿名化的患者数据集P-DS’进行分析。为了匿名化从项目数据源3中读取的患者数据集P-DS,使用通过数据处理单元2的第一数据处理级2A基于统计学人口数据所确定的模糊化参数OP。为此,第一数据处理级2A访问至少一个统计学数据库6,如在图1中所示出的。在此能够涉及可公开访问的统计学数据库6。为了确定模糊化参数OP,因此不需要对患者数据集P-DS进行数据预处理,所述患者数据集例如位于项目数据源3中。在根据本发明的系统1中省去如其在传统方法中所需的昂贵的数据预处理,如这在图1中所示出的。对患者数据集P-DS进行实际分析的第二数据处理级2B处理数据流DS,所述数据流通过从项目数据源3中读取患者数据集P-DS而生成,或者替选地也基于传感器数据产生。在图1中示出的实施例中,不同的传感器7-1、7-2、...、7-n能够生成关于患者的可行的属性的传感器数据。基于传感器数据,数据处理单元8实时地生成患者数据集P-DS,所述患者数据集作为数据流DS输送给系统1的数据处理单元2的第二数据处理级2B,如在图1中示意性地示出的。
图4示意性地以表格的方式示出多个患者数据集P-DS,所述患者数据集例如存储在项目数据源3中。项目数据源3能够是医疗机构的中央数据库或者也能够通过分布式数据库形成。项目包括非常大量的不同的患者数据集P-DS。项目在此优选涉及特定的医学主题或特定的医学情况。患者数据集P-DS能够通过不同的医疗组织单位生成,例如医院、研究实验室或研究机构。每个患者数据集P-DS包括不同类型的属性。如在图4中示出的,患者数据集P-DS包括标识符ID,所述标识符本身适用于能够明确地识别相应的患者。用于标识符ID的示例例如是患者的姓名或明确的患者编号。此外,每个患者数据集P-DS包括一个或多个准标识符Q-ID,所述准标识符分别与其它数据相结合地适用于识别相应的患者。准标识符Q-ID是不允许单独地识别患者的属性,但是与通常可访问的数据结合能够实现明确的关联性。如在图4中示出的,患者数据集P-DS包括m个准标识符Q-ID。用于准标识符Q-ID的示例是患者的性别(男性/女性)和患者的年龄以及例如患者的地址的邮政编码PLZ。除了准标识符Q-ID之外,每个患者数据集P-DS还包含敏感属性,所述敏感属性包括相应的患者的个人数据。敏感属性包括特别是值得保护的个人信息,例如患者的疾病,例如流感或癌症。
数据处理单元2的数据处理级2B将患者数据集P-DS匿名化,其方式为:将其准标识符Q-ID借助于所确定的模糊化参数OP模糊化或隐蔽,以生成相应的匿名化的患者数据集P-DS’。根据准标识符Q-ID的类型,模糊化能够以不同的方式进行。例如在一个可行的实施形式中,患者数据集P-DS的准标识符Q-ID能够被模糊化,其方式为:其值被泛化成包含其的泛化区间。如果例如患者的年龄是35岁,该准标识符Q-ID的值能通过位于30至40岁之间的区间来泛化。因此,该泛化区间的范围是十年。用于泛化准标识符“年龄”的泛化区间的区域范围或取值范围形成可行的模糊化参数OP。例如年龄为35岁的目标人员或患者的年龄例如也能够通过位于30和35岁包含边界值之间的泛化区间来泛化。在这种情况下,用于泛化年龄信息的模糊化参数OP仅为五年。根据患者数据集的准标识符“年龄”因此被模糊化,其方式为:根据模糊化参数OP将准标识符“年龄”的值(年龄信息)泛化成包含其。在这种情况下,模糊化参数OP给出用于泛化准标识符“年龄”的泛化区间的区域范围或取值范围。借助根据本发明的系统1,通过数据处理单元2的第一数据处理级2A通过分析统计学人口数据来确定模糊化参数OP。所述统计学人口数据能够从可公开访问的统计学数据库6中读取。
在另一可行的实施形式中,将患者数据集P-DS的准标识符Q-ID模糊化,其方式为:至少部分地删除或掩蔽准标识符Q-ID的值的一个或多个字符。如果准标识符Q-ID例如由五位的邮政编码PLZ构成,例如能够删除或掩蔽邮政编码PLZ的1、2、3或4位字符,以便能够将其部分地隐蔽或模糊化。例如,患者“Charles”的邮政编码PLZ“80333”能够被模糊化为“8033*”或“803**”或“80***”或“8****”。此外,模糊化参数OP也能够给出:哪个位置或字符部位被模糊化。通常,较低的字符部位的模糊化引起比较高的字符部位的模糊化更少的模糊化。如果例如仅对邮政编码PLZ的最后一位字符进行模糊化,则隐蔽的程度低于例如删除或掩蔽邮政编码PLZ的第一位字符的情况。
在另一可行的实施形式中,将患者数据集P-DS的准标识符Q-ID模糊化,其方式为:借助改变值改变准标识符Q-ID的值。该变化值也能够是随机值。
能够使用不同类型的技术来模糊化。在基于聚合的方法中,原始的患者数据集的各个数据点或数据字段能够聚合成组,因此使得难以重新识别以及确定或可靠地估计各个人员或患者的属性值。
在基于随机的模糊化方法中,能够基于随机地改变患者数据集的各个属性,使得重新识别和可靠地估计各个患者的属性值变得更加困难。
此外还能够使用基于合成的模糊化方法。在此,首先形成原始数据的统计学模型。随后根据该模型生成新的合成数据,所述合成数据尽可能地再现原始数据,然而不再具有关于相应的患者的个人参考。
通过数据处理单元2的第二级2B对患者数据集进行匿名化能够包含静态匿名化和动态匿名化。在动态匿名化的情况下,根据特定标准对连续的数据流DS进行匿名化。在静态匿名化的情况下,能够根据预先确定的标准对完全已知的数据集进行匿名化。交互式匿名化也是可行的。例如,通过用户定义的对现有的数据库表格的查询能够基于噪声匿名化。
为了通过数据处理单元2的第二数据处理级2B将患者数据集P-DS匿名化,优选地,在所输送的患者数据集P-DS中包含的所有明确的标识符ID被自动删除或掩蔽。附加存在的准标识符Q-ID借助于确定相关的模糊化参数OP被自动地模糊化或隐蔽。根据准标识符Q-ID的类型,这能够根据所确定的相关的模糊化参数OP以不同的方式进行。从项目数据源3中读取的患者数据集P-DS和/或基于传感器数据生成的患者数据集P-DS作为数据量DS为了其匿名化连续地借助于所确定的模糊化参数OP被模糊化,以生成匿名化的患者数据集P-DS’,如在图1中示意性地示出的。匿名化的患者数据集P-DS’优选存储在匿名数据库4中,以用于进一步评估和分析。
所分析的患者数据集P-DS形成具有集群大小K的集群C,其中所有模糊化的准标识符Q-ID都是相同的。在一个可行的实施形式中,能够通过数据处理级2A基于从统计学数据库6中读取的静态人口数据来计算人口期望值E。对于在项目的项目附属区域内的人口,该人口期望值E给出以下人员的数量,所述人员符合匿名化的患者数据集P-DS’的根据模糊化选项来模糊化的准标识符Q-ID。患者数据集的准标识符Q-ID优选借助于模糊化参数OP来模糊化,使得所计算的人口期望值E大于在匿名化的患者数据集P-DS’内的集群C的可选的集群大小K。
存储在匿名数据库4中的匿名化的患者数据集P-DS’能够用于不同的应用。例如,所述匿名化的患者数据集能够通过另一数据处理单元5用于医学研究。为此,所存储的匿名化的患者数据集P-DS’能够借助附加的匿名化的数据来进一步评估。
图2示意性地示出存储在匿名化数据库4中的匿名化的患者数据集P-DS’的可行的应用。在一个可行的实施形式中,匿名化的患者数据集P-DS’能够用作为用于训练人工智能模块(KIM)9的训练数据。随后人工智能模块9能够用于基于另外的匿名化的患者数据集的医学诊断。此外,匿名化的患者数据集P-DS’还能够用于设定医疗设备10的设备参数,所述医疗设备用于检查患者或样本。此外,匿名化的患者数据集P-DS’也能够用于确定医疗诊断,尤其能够通过使用匿名化的患者数据集P-DS’,在医院的信息技术基础设施外部进行诊断。
在根据本发明的系统1的可行的实施形式中,患者数据集的属性,如其在图4中以表格形式示出的,至少部分地通过传感器的方式检测到。例如,能够借助于系统1的读取单元从患者的患者随身携带的识别机构中读取患者的标识符ID。患者必要时还能够随身携带直接测量和监控身体功能并且转发患者数据的可穿戴设备。此外,例如能够从RFID标签中读取标识符ID。
也能够通过传感器或借助于读取单元检测患者的准标识符Q-ID,并且作为准标识符Q-ID存储在患者的相应的患者数据集P-DS中。患者数据集P-DS的属性,意即除了文本数据之外,标识符ID、准标识符Q-ID和敏感属性还能够包括音频数据和/或图像数据。音频数据和图像数据例如是对于在项目中在检查的特定的医学情况重要的传感器数据。例如能够检查音频数据心音,以用于检查心脏梗塞的医学情况。其它示例例如是EKG数据等。除了音频数据之外,图像数据也能够形成属性,所述属性在放射检查过程中生成。所述图像数据例如包括患者的CT数据或X射线数据。此外,例如也能够将患者的生物特征数据评估为用于识别患者的标识符ID。例如,指纹数据形成能够用作为患者的明确的标识符ID的图像数据。通过传感器检测到的数据,例如图像数据也能够在数据处理过程中进行评估,以便能够自动地确定相关的人员的准标识符Q-ID。例如能够从患者的面部图像中确定其性别。用于准标识符Q-ID的典型的示例例如是患者的年龄、体重、性别或血型、检查类型或检查日期。所述准标识符Q-ID借助于模糊化参数OP进行模糊化,以便能够防止反向识别或重新识别患者。这借助于基于统计学人口数据确定的模糊化参数OP进行。
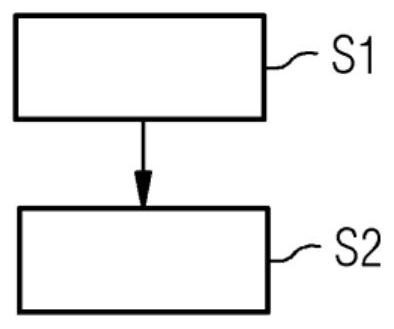
图3示出用于示出根据本发明的用于提供匿名化的患者数据集P-DS’的计算机实现的方法的一个可行的实施形式的流程图。在示意性流程图中,计算机实现的方法基本上包括两个主要步骤S1、S2。
在第一步骤S1中,分析统计学人口数据,以确定模糊化参数OP。例如,从统计学数据库6中读取统计学人口数据并且对其进行分析,以便能够从中获取模糊化参数OP。例如,模糊化参数OP能够给出用于泛化准标识符“年龄”的泛化区间的范围或区域范围。模糊化参数OP例如给出:区域范围包括10年、5年或者还有仅3年。
在另一步骤S2中,将包含准标识符Q-ID作为属性的患者数据集P-DS’匿名化,其方式为:借助于在步骤S1中确定的模糊化参数OP将患者数据集P-DS的准标识符Q-ID模糊化或隐蔽,以用于生成匿名化的患者数据集P-DS’。例如,患者在其患者数据集P-DS中的年龄信息能够被泛化,其方式为:代替精确的年龄信息,仅给出相应的年龄区间。为了在步骤S2中将患者数据集P-DS匿名化,将准标识符Q-ID模糊化并且优选自动地删除或完全掩蔽标识符ID。
在步骤S2中生成的匿名化的患者数据集P-DS’优选存储在相应的匿名数据库4中,以用于进一步评估和使用。例如,所存储的匿名化的患者数据集P-DS’用于训练人工神经网络KNN(作为人工智能模块9的示例)或用于设定医疗设备的设备参数,如结合图2所描述的。借助根据本发明的计算机实现的方法,如在根据图3示出的流程图中示意性地示出的,能够执行K-匿名化过程,其方式为:具体的数据库的特定的特性,例如在项目数据源3中包含的数据库内容本身并不重要,而是仅在相应的项目的附属区域内在总人口内的数据值的参数分布是重要的。能够评估该参数分布,以用于确定在匿名化的患者数据集P-DS’内的集群C的集群大小K。为此,从统计学数据库6中读取项目附属区域内的统计学人口数据,并且通过数据处理级2A进行评估,以便能够获取相应的模糊化参数OP。例如,能够从统计学数据库6中读取附属区域内人员的年龄分布。然后将在人口内人员的年龄分布用于确定泛化区间的区域范围。
在一个可行的实施形式中,能够基于从统计学数据库6中读取的统计学人口数据来计算人口期望值E。该人口期望值作为在项目附属区域内的人群给出以下人员的数量,所述人员根据模糊化选项实际符合匿名化的患者数据集P-DS’的模糊化的准标识符Q-ID。模糊化选项包括关于不同的准标识符Q-ID的模糊化的组合。
这将在下文中借助一个简单的示例进一步解释。例如,特定的医疗机构,例如医院的附属区域是已知的。此外,例如,关于用于特定的项目的特定的区域的附属区域能够包括在其中例如居住500万人的区域。在特定的医学状况或特定的医学情况中,例如,在预设的年龄范围内的男性(占人口的一半)的发病率为100000分之5。年龄范围例如包括居住在相关的区域中的5%的人员。在该简单的示例中,在相应的集群C中患者的期望值E(泛化的年龄男性)为:
在该简单的示例中,在项目的附属区域中的人员数量A为500万,其中一半的居民符合属性男性,其发病率为
一般而言,能够从在附属区域中的人员数量乘以关于患者数据集P-DS的不同的属性的不同的期望值E的乘积来计算总人口期望值E。
以这种方式计算出的人口期望值E优选与在匿名化的患者数据集P-DS内的集群C的集群大小K进行比较。借助于模糊化参数OP进行模糊化或隐蔽以该方式进行,使得所计算出的人口期望值E
因此,准标识符优选以如下方式被模糊化,适用:
E
其中E
在根据本发明的方法中能够使用具有适宜的模糊化参数OP的不同的模糊化技术,其中模糊化参数OP始终通过分析统计学人口数据而推导出,所述统计学人口数据可用地存在于统计学数据库6中。在匿名化的患者数据集P-DS’中的集群C的大小在此根据所计算出的统计学期望值E
计算机实现的方法允许:执行k-匿名化,而不必执行项目数据源3的数据内容的数据预处理。因此明显简化和加速了匿名化过程。此外,也能够在患者数据集P-DS的连续的数据流DS中执行匿名化。匿名化有效地并且节省资源地基于公开可用的统计学人口数据进行,所述统计学人口数据能够经由云或互联网以很少的访问时间从至少一个统计学数据库6中读取。统计学人口数据尤其包括在人口内关于一个或多个属性的静态分布。
在一个可行的实施形式中,在患者数据集P-DS的步骤S2中进行实际的匿名化之前,确定模糊化参数OP,以用于分析统计学人口数据。在另一可行的实施形式中,只要在统计学数据库6中的相关的参数的统计学分布发生变化,那么也能够在步骤S2中的匿名化过程期间在后台动态地调整模糊化参数OP。根据应用情况,也能够使用在其中相应地设定匿名化的患者数据集P-DS’的医疗设备的反向耦合,以便能够调整模糊化参数OP。
借助根据本发明的系统,匿名化的患者数据集P-DS’能够被公开访问,而不需要在项目内的所有检查研究的数据已经是可用的。根据本发明的系统还能够处理患者数据集P-DS的连续的数据流DS,其例如基于传感器数据或读取数据实时地生成或者从数据库中读取。根据本发明的方法和系统1适合于将具有任意数量的不同的属性的任意的患者数据集P-DS有效地匿名化,进而为研究的进一步评估提供基础。此外,匿名化的患者数据集P-DS’能够用作为训练数据或用于设定设备参数。模糊化参数OP的确定在此能够在匿名化之前进行,或者也能够在正在进行的匿名化期间在后台并行地进行。根据本发明的方法的一个优点因此也在于,模糊化参数OP能够与将患者数据集P-DS匿名化并行地在后台确定或更新。因此,根据本发明的系统1在一个可行的实施形式中也是能够实时的,意即也包含传感器数据作为属性的实时生成的患者数据集P-DS能够被实时地模糊化,以生成匿名化的患者数据集P-DS’。
根据本发明的方法能够以多种不同方式用于各种不同的应用情况。在不同的附图中示出的实施形式包含在其它实施形式中能够相互组合的特征。根据本发明的用于提供匿名化的患者数据集P-DS’的计算机实现的方法和根据本发明的系统1不局限于在图1至图4中示出的实施例。其它应用形式和实施形式是可行的。例如,匿名化的患者数据集P-DS’也能够以相应地标记为匿名化的方式写回到项目数据源3中。
匿名化的患者数据集P-DS’还能够经由用户接口,例如图形用户界面GUI显示给用户,例如显示给相应的医学研究项目的项目经理。在一个可行的实施形式中,在此使用的模糊化参数OP也经由这样的用户接口显示在显示单元上,并且必要时能够交互式地对其进行进一步调整。
在另一可行的实施形式中,附加地根据预设的或输入的安全等级SK调整模糊化参数OP。在此,与不太敏感的患者数据集P-DS相比,高度敏感的数据在更大的范围中被模糊化或隐蔽。在该实施形式中,附加地根据安全等级SK调整或再调节通过分析统计学人口数据确定的模糊化参数OP。
- 用于为驾驶自动化系统提供智能超驰的系统和方法
- 风电场飞行信标系统以及具有飞行信标系统的风电场和用于为风电场提供信标的方法
- 用于针对在安全系统键区上显示的文本来定制和提供自动化语音提示的系统和方法
- 一种备份数据集挂载方法和备份数据集快速恢复、挂载系统
- 包括呼吸面具和装载装置的组件,用于装载呼吸面具的方法和用于提供呼吸面具的方法
- 用于匿名化数据集的系统和方法
- 用于匿名化数据集的系统和方法