一种用于余弦距离最近邻搜索的存内计算架构及操作方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及存储、计算、电路领域,实现了用于余弦距离最近邻搜索的存内计算架构及操作方法。
背景技术
在人工智能时代,各种二值神经网络(Binary Neural Networks,BNN)及超高维度向量计算(Hyperdimensional Computing,HDC)已经被证明可以高效地应用于不同实际场景如:物体追踪,声音识别,图像聚类等等。而其中基于余弦近似搜索被广泛研究于算法层面,并基于现今冯-诺依曼计算机架构来完成其操作。然而,受限于现有计算机架构,进行此操作会造成极大的能耗和延时。
虽然近年来,各种存内计算单元的设计已经被广泛提出,解决了传统冯-诺依曼计算机架构的延时和能耗问题,并且利用存内计算单元,实现了汉明码计算。但基于余弦距离的存内计算单元的相关工作仍十分稀缺,目前仅有利用存算单元来实现HDC的近似余弦相似计算,而相关实现并不适用于更广泛的应用如二值神经网络。
尽管余弦近似搜索已经在应用层面被证实其价值,加上存内计算单元能突破传统冯-诺依曼计算机架构所造成的延时能耗等负面影响,相关实现仍然十分稀少。
发明内容
本发明的目的在于针对现有技术的不足,提供一种用于余弦距离最近邻搜索的存内计算架构及操作方法,能耗、延时以及鲁棒性等指标与现在仅有的工作相比有所提升。
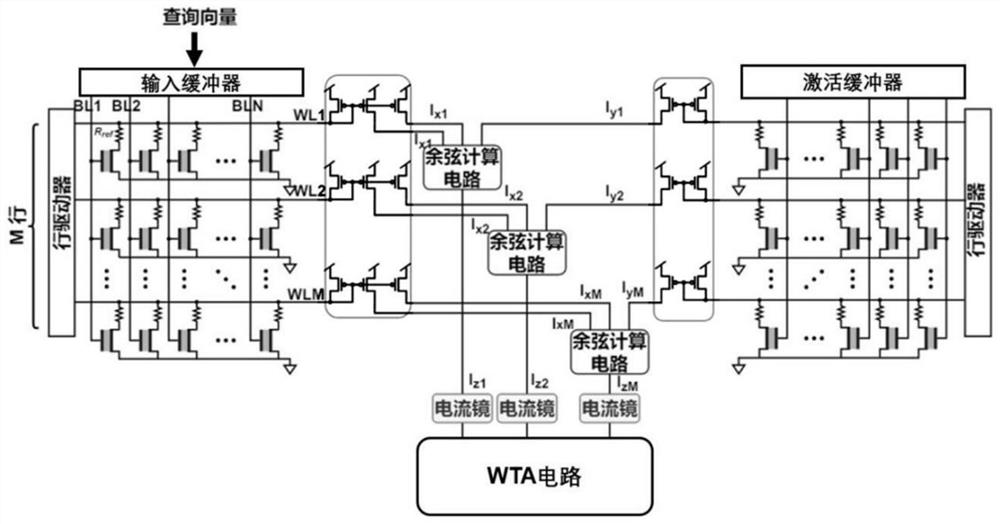
本发明提供一种用于余弦距离最近邻搜索的存内计算架构,包括两个基于FeFET的存储阵列、Translinear电路和WTA电路,两个存储阵列分别为第一存储阵列和第二存储阵列;
所述存储阵列包括若干存储行,每个存储行由若干存储单元并联形成,所述存储单元包括电连接的FeFET和电阻,同一个存储阵列中每个存储行存有不同的存储向量;
两个存储阵列中的存储行一一对应,对应的两个存储行所存的存储向量相同;
输入向量经所述第一存储阵列,输出所述输入向量与所有所述第一存储阵列的存储向量的内积X;
所述第二存储阵列输出其存储向量中所有向量元素的平方和Y;
所述第一存储阵列和所述第二存储阵列的输出值分别经电流镜输入所述Translinear电路;
所述Translinear电路输出X
所述WTA电路用于选出所有存储行对应的X
进一步地,所述存储阵列具有M个存储行;所述存储行具有N个存储单元;
所述存储单元中的电阻电连接FeFET的漏极;
所述存储行的所有电阻背向对应FeFET一端相连构成所述存储行的行线WL;
所述存储行的所有FeFET的源极相连后,直接接地或通过开关接地;
所述存储阵列中每列存储单元中所有的FeFET的栅极相连,作为所述输入向量对应的位线BL。
进一步地,所述第一存储阵列和所述第二存储阵列的对应存储行具有一个共用的Translinear电路;
所述第一存储阵列每个存储行的输出通过电流镜拷贝至少两份后输入该行对应的Translinear电路;
所述第二存储阵列每个存储行的输出通过电流镜拷贝一份后输入该行对应的Translinear电路。
进一步地,所有Translinear电路的输出分别经电流镜拷贝一份后输入所述WTA电路,所述WTA电路的每个输入对应一个输出,其中输入的最大值对应的输出拥有最大值,输入的其他值对应的输出拥有极小值。
进一步地,所述输入向量为二值输入向量,所述第二存储阵列输出所述存储向量中‘1’的个数。
进一步地,对于向量元素个数增加n倍,调整每个存储单元中的电阻的阻值相应增加n倍。
进一步地,所述存储单元中的所述电阻为百万欧姆量级。
本发明还提供一种如上所述存内计算架构的操作方法,该方法包括:
步骤1,对每个存储单元中的FeFET进行写入操作;
步骤2,搜索开始时,将第一存储阵列中的每列对应的位线BL置为输入向量每个元素对应的电压值,所述第一存储阵列的存储行对应的字线WL输出所述输入向量和所述存储行存有的存储向量的内积X对应的电流I
进一步地,所述步骤1具体为:通过对FeFET的栅极施加不同的电压脉冲,实现FeFET存储‘1’或‘0’。
本发明的有益效果如下:
1)本发明首次提出在余弦距离数学表达式上非近似的余弦距离最近邻搜索的存内计算架构及操作方法;
2)本发明在搜索能耗、搜索延时和芯片面积三大指标均有降低;
3)本发明在考虑了FeFET误差,晶体管误差和供电电源误差下,仍鲁棒性佳;
4)本发明提出利用1FeFET1R的电阻实现可拓展性存内架构;
5)本发明提出了使用O(N)型WTA电路而不需使用传统“树形”WTA,大量节约了延时和能耗。
附图说明
图1是存内计算架构整体结构示意图;
图2是本发明使用的Translinear电路结构示意图;
图3是本发明使用的O(N)WTA电路结构示意图;
图4为存内计算架构操作方法流程图;
图5是实现X
图6是在随机数据下,NN搜索,即WTA输出结果示意图;
图7是增加向量长度的能耗、延时仿真结果示意图;
图8是在向量长度为1024比特下增加架构的行数的能耗、延时仿真结果示意图;
图9是在100次蒙特卡洛仿真下,考虑了FeFET本身误差、晶体管10%的大小以及10%阈值电压误差,和10%的供电电源误差下本发明的输出示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
请参阅图1,一种用于余弦距离最近邻搜索的存内计算架构,包括两个基于FeFET的存储阵列、Translinear电路和O(N)WTA电路,两个存储阵列分别为第一存储阵列和第二存储阵列;存储阵列包括若干存储行,每个存储行由若干存储单元并联形成,存储单元包括FeFET和电阻,每个FeFET的漏极接电阻,形成1FeFET1R结构,同一存储阵列中每个存储行存有不同的存储向量。对于1FeFET1R单元在制造上的可行性,已在非专利文献1(Analog In-memory Computing in FeFET-based 1T1R Array for Edge AI Applications,Symposiumon VLSI Technology,2021)给出。
两个存储阵列中的存储行一一对应,对应的两个存储行所存的存储向量相同。
输入向量经第一存储阵列,输出输入向量与所有存储向量的内积X;第二存储阵列输出存储向量中所有向量元素的平方和Y。
第一存储阵列和第二存储阵列的输出值分别经电流镜输入Translinear电路;Translinear电路输出X
接下来将说明以Translinear电路实现余弦距离最近邻搜索的原理,推导如下:
(1)将余弦计算的数学表达式先进行平方,即:
(2)由于输入向量
(3)至此,Translinear X
(4)进一步地,
(5)进一步地,为了计算二值向量中‘1’的个数,将第二存储阵列中不同列的BL全部置为‘1’即可。
为了计算输入向量与存储向量之间的内积,本发明构建1FeFET1R存储单元,存储单元中的电阻连接FeFET的漏极,每个存储行的所有存储单元中的电阻另一端相连形成一向量,同时于此向量中的每个FeFET的栅极输入‘1’或‘0’,即可与FeFET中所存的‘1’或‘0’进行‘与’操作。每个存储行的所有存储单元中的所有FeFET的源极相连后,直接接地或通过开关接地。
由(4)推导知:余弦表达式通过平方,再将分母约化为
两个存储阵列的对应存储行具有一个共用的Translinear电路;第一存储阵列每个存储行的输出通过电流镜拷贝至少两份后输入该行对应的Translinear电路;第二存储阵列每个存储行的输出通过电流镜拷贝一份后输入该行对应的Translinear电路。
所有Translinear电路的输出分别经电流镜拷贝一份后输入WTA电路,WTA电路的每个输入对应一个输出,其中输入的最大值对应的输出拥有最大值,输入的其他值对应的输出拥有极小值。
此外,对于向量元素个数增加n倍,调整每个存储单元中的电阻的阻值相应增加n倍。通过此存储单元结构内的大电阻,使架构工作电流小,进而使架构鲁棒性佳。
对本发明的存内计算架构作进一步说明:
1、由两个基于FeFET的存储阵列计算出Translinear电路输入
如图1所示,存储阵列中的一个存储单元为电阻R
在搜索阶段时,将其输入,即每列BL维持高电平,WL输出其对应存储行存有的存储向量中所有向量元素的平方和Y对应的电流I
2、Translinear电路表达平方除法的电路如图2所示,其运输准确的工作电流范围经验证为纳安培(nA)级别,如图5所示;基于存储单元的1FeFET1R结构以及Translinear电路运算有效范围的限制,本发明进一步地提出通过调节存储单元中电阻阻值以确保电流量级不变的同时能拓展向量长度,即:
即,当存储向量与输入向量元素个数增加n倍,相应调整所有存储单元中电阻的阻值相应增加n倍。
3、Translinear电路接收了三个输入端口I
请参阅图4,本发明还提出一种上述存内计算架构的操作方法,该方法包括:
步骤1,对每个存储单元中的FeFET进行写入操作,具体为:通过对FeFET的栅极施加不同的电压脉冲,实现FeFET存储‘1’或‘0’。
具体地,在搜索开始前,对于两个存储阵列,通过由每列FeFET栅极组成的BL,分别写入二值向量元素;‘0’用-4V电压脉冲写入,‘1’用+4V电压脉冲写入。将向量元素写入于两个存储阵列后,开始搜索过程。
步骤2,搜索开始时,将第一存储阵列中的每列对应的位线BL置为输入向量每个元素对应的电压值,第一存储阵列的存储行对应的字线WL输出输入向量和存储行存有的存储向量的内积X对应的电流I
具体地,搜索时,通过由每列FeFET栅极组成的BL,写入搜索向量的向量元素,1V表示‘1’,0V表示‘0’。对于FeFET实现内积功能,说明如下:
当输入‘1’且FeFET单元内存的数值为‘1’时,将输出大电流;其余三种情况,输入‘1’存‘0’、输入‘0’存‘1’、输入‘0’存‘0’,皆输出小电流,借此实现了向量内积
步骤3,Translinear电路输出X
具体地,Translinear电路输出的I
本发明的功能和效果通过以下仿真实验进一步说明展示:
1.仿真条件
实验使用基于物理电路的兼容SPECTRE和SPICE模型对由1FeFET1R存储单元组成的存储阵列、Translinear电路、WTA电路组成的余弦距离最近邻搜索的存内计算架构进行仿真,其中FeFET是基于Preisach模型,该模型实现了高效的设计与分析,已广泛应用于FeFET电路设计中。利用PTM45-HP作为其余PMOS、NMOS晶体管的仿真模型。
2.仿真结果
(1)NN搜索结果
图6给出了在随机输入情况,即存在相近以及余弦值为零的情况下,NN搜索,即WTA输出的结果。输出最大电流为相应存储向量与输入向量余弦值最大的向量,其余波形为相应存储向量与输入向量余弦值次大到最小的最近邻搜索电流结果。
(2)图5给出了平方除法的Translinear电路运算最佳范围。此结果为固定I
(3)能耗和延時:
将本发明结果与非专利文献2(G.Karunaratne et al.,“Robust high-dimensional memory-augmented neural networks,”Nature Communications,vol.2,Apr.2021.)中提出的适用于HDC的近似余弦搜索进行对比,得到了90.5倍每单元能耗的下降,和333倍输出延时的下降。
(4)消耗面积:
本发明的面积消耗相比于非专利文献3(M.Imani et al.,“Exploringhyperdimensional associative memory,”in HPCA.IEEE,2017,pp.445–456.)有显著减少,主要是因为对于NN搜索,本发明使用1FeFET1R结构,由非专利文献4(T.Soliman etal.,“Ultra-lowpower flexible precision fefet based analog in-memorycomputing,”in IEDM,2020.)大大降低FeFET的输出电流偏差,因此不需要使用‘树形’的WTA(Winner-Take-All)/LTA(Loser-Take-All)结构进行NN搜索,进而大幅减少晶体管数量。
(5)可扩展性:
图7是当拓展向量长度从64比特每向量到1024比特每向量,对于本发明的能耗和延时几乎没有影响,是因为通过调整存储单元中电阻阻值。图8是向量长度为1024比特下增加架构的行数的能耗、延时仿真结果,对于拓展行数,能耗呈现线性上升;延时则不受影响,验证了WTA的拓展性。说明了对于HDC的余弦近似搜索,本发明是可行的。
(6)鲁棒性:
图9旨在说明本发明的鲁棒性。在考虑了FeFET、晶体管、供电电源误差的100次蒙特卡罗仿真下,本发明仍能保持10%内的误差结果,原因在于,因利用1FeFET1R结构大大降低了FeFET的输出偏差;并且,10%的误差为HDC可接受范围内,见非专利文献2,3。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。
- 应用于神经网络的存内计算架构的操作方法、装置和设备
- 一种用于部署深度学习网络的存内计算架构和加速方法