一种生产单细胞蛋白的方法及碳固定系统
文献发布时间:2023-06-19 18:35:48
技术领域
本公开属于微生物和基因工程技术领域,具体来说,本公开涉及一种生产单细胞蛋白的方法及碳固定系统。
背景技术
单细胞蛋白(Single Cell Protein,SCP)又称微生物蛋白、菌体蛋白,是利用各种基质大规模培养细菌、酵母菌、霉菌、微型藻等而获得的微生物蛋白。单细胞蛋白的化学组成中一般以蛋白质、脂肪为主,含粗蛋白50%~85%,并且氨基酸组分齐全,还含维生素、无机盐、脂肪和糖类等,其营养价值优于鱼粉和大豆粉。单细胞蛋白不仅能制成“人造肉”,供人们直接食用,还常作为食品添加剂,用以补充蛋白质或维生素、矿物质等。目前,已发现藻类、细菌和高等真菌均可生产SCP产品。其中,通过微生物大量表达合成蛋白质,或者将整个菌体作为单细胞蛋白,有望突破传统的农业和养殖业限制,实现一种高效、快速、节能、减废的绿色饲料蛋白生产方式。
氢氧化细菌(Hydrogen-oxidizing bacteria)是能够利用H
专利文献1公开了一种使用化能自养微生物来从工业废物俘获碳的系统和方法。系统包括工业源;以及包括微生物的生物反应器。生物反应器被供给有来自源的废物流,该废物流向微生物提供碳;并且也被供给有氢原料。微生物从氢原料获取能量,通过化能自养将提供的碳转换为化学产物。该方法虽然能够将工业废物中的碳氧化物转化为诸如羟基链烷酸酯类、聚羟基链烷酸酯类的有机化合物,然而,其化能自养微生物存在对氢原料的利用率低,转化有机化合物的效率需提高的问题。并且,该微生物反应器未用于生产单细胞蛋白,无法实现对单细胞蛋白的高效生产。
专利文献2公开了将如可再生H
引用文献:
专利文献1,CN103958687A
专利文献2,CN110678539A
发明内容
鉴于现有技术存在的问题,例如,微生物以H
第一方面,本公开提供了一种生产单细胞蛋白的方法,其中,所述方法包括以下步骤:
向包含重组氢氧化细菌的发酵培养基中通入作为能源的第一气体,和作为碳源的第二气体;对重组氢氧化细菌进行发酵培养,使重组氢氧化细菌合成单细胞蛋白;
其中,所述重组氢氧化细菌包括通过氢氧化反应产生能量的氢元件,和通过固碳反应合成目标产物的固碳元件;
并且,与野生型氢氧化细菌相比,所述重组氢氧化细菌具有如下(i)-(ii)中至少一项所示的特性:
(i)氢元件中一个或多个与氢氧化反应相关的蛋白活性,或蛋白编码基因的表达水平被增强;
(ii)固碳元件中一个或多个与固碳反应相关的蛋白活性,或蛋白编码基因的表达水平被增强。
在一些实施方式中,根据本公开所述的方法,其中,所述发酵培养的温度为25-35℃,所述发酵培养的pH为5.5-8.0。
在一些实施方式中,根据本公开所述的方法,其中,所述第一气体包含氢气和氧气,所述第二气体包含二氧化碳,所述氢气、氧气和二氧化碳的体积比为(4-7):1:1;优选7:1:1;
优选地,所述第一气体和所述第二气体混合通入发酵培养基;每分钟向所述发酵培养基通入所述第一气体和所述第二气体的混合气体的体积,与容置所述发酵培养基的反应内腔的体积比为(2-5):10。
在一些实施方式中,根据本公开所述的方法,其中,所述发酵培养基是包含磷酸盐的发酵培养基,所述磷酸盐的浓度为25-35mM;
可选地,所述磷酸盐选自磷酸二氢钾、磷酸氢二钾、磷酸二氢钠、磷酸氢二钠中的一种或两种以上的组合;
优选地,所述发酵培养基中还包含亚铁盐;更优选地,所述亚铁盐为硫酸亚铁,所述硫酸亚铁的浓度为30-60mg/l。
在一些实施方式中,根据本公开所述的方法,其中,所述与固碳反应相关的蛋白包括核酮糖-1,5-二磷酸羧化酶/加氧酶;可选地,所述与固碳反应相关的蛋白还包括分子伴侣;优选地,所述分子伴侣选自GroES和GroEL中的至少一种。
在一些实施方式中,根据本公开所述的方法,其中,所述核酮糖-1,5-二磷酸羧化酶/加氧酶包括如(a
(a
(a
(a
(a
(a
(a
可选地,所述重组氢氧化细菌包含如下(b
(b
(b
(b
可选地,所述重组氢氧化细菌包含如下(c
(c
(c
(c
在一些实施方式中,根据本公开所述的方法,其中,所述重组氢氧化细菌包含表达核酮糖-1,5-二磷酸羧化酶/加氧酶的重组表达载体;优选地,所述重组氢氧化细菌包含表达核酮糖-1,5-二磷酸羧化酶/加氧酶、GroES和GroEL的重组表达载体;
优选地,所述重组表达载体的核苷酸序列如SEQ ID NO:11或SEQ ID NO:12所示。
在一些实施方式中,根据本公开所述的方法,其中,所述与氢氧化反应相关的蛋白包括氢化酶;优选地,所述重组氢氧化细菌中氢化酶的编码基因与强启动子相连接。
在一些实施方式中,根据本公开所述的方法,其中,所述重组氢氧化细菌为贪铜菌属细菌;优选地,所述重组氢氧化细菌为钩虫贪铜菌或其衍生菌株。
第二方面,本公开提供了一种碳固定系统,其中,所述碳固定系统包括:
反应容器,具有容置发酵培养基的内腔,所述发酵培养基中包含重组氢氧化细菌;
通气单元,所述通气单元用于向所述发酵培养基内通入作为能源的第一气体和作为碳源的第二气体;
并且,与野生型氢氧化细菌相比,所述重组氢氧化细菌具有如下(i)-(ii)中至少一项所示的特性:
(i)氢元件中一个或多个与氢氧化反应相关的蛋白活性,或蛋白编码基因的表达水平被增强;
(ii)固碳元件中一个或多个与固碳反应相关的蛋白活性,或蛋白编码基因的表达水平被增强。
在一些实施方式中,本公开提供的生产单细胞蛋白的方法,通过选择性加强重组氢氧化细菌中利用氢产生能量的氢元件,和参与合成目标产物的固碳元件,能够提高重组氢氧化细菌对氢气的利用效率和固碳反应的效率,显著提高对单细胞蛋白的生产速率,得到高产的单细胞蛋白,具有产量高、技术简单、容易控制等优点。
在一些实施方式中,本公开提供的生产单细胞蛋白的方法,对发酵培养基的物质、含量,气体通气量、发酵培养条件进行优化,得到适于本公开中的重组氢氧化细菌生产、代谢的最适条件,单细胞蛋白的高效、快速生产提供所需的培养环境。
在一些实施方式中,本公开提供的碳固定系统,能够实施本公开中的生产单细胞蛋白的方法,得到高产率的单细胞蛋白。
附图说明
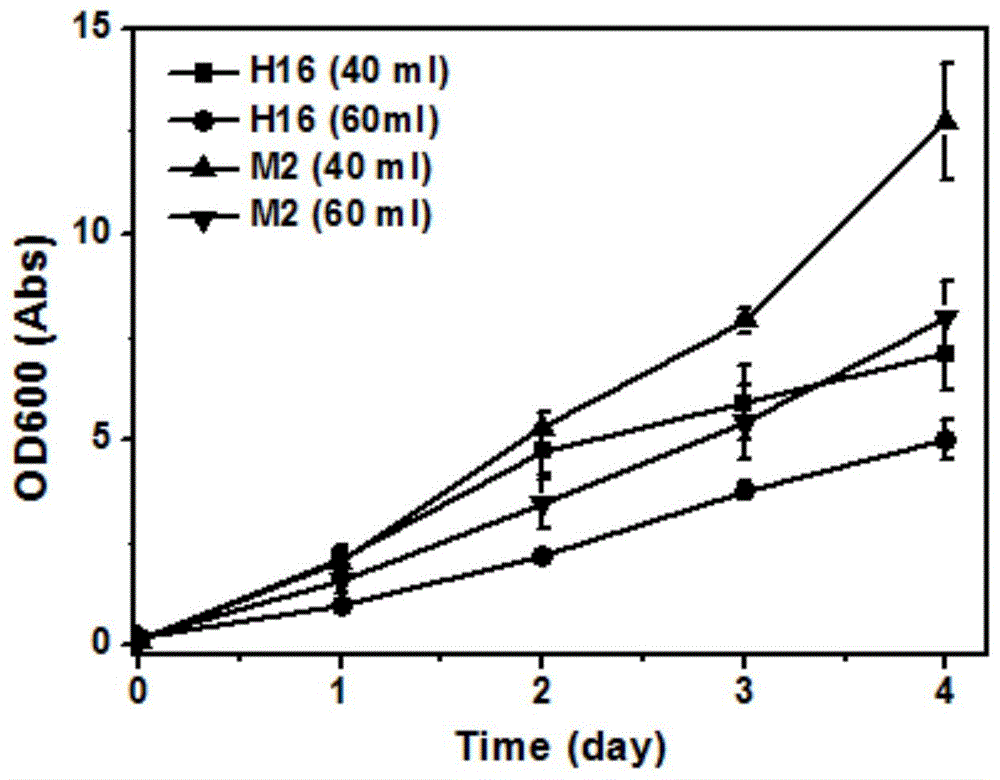
图1示出了在反应内腔的不同顶部空间下H16及M2的生长曲线(OD
图2示出了不同培养基条件下M2的生长曲线(OD
图3示出了不同M2菌株与M3菌株在同一培养基下的生长曲线(OD
图4示出了不同气体比例条件下M3菌株的生长曲线(OD
图5示出了不同混合气体流速条件下M3的生长曲线(OD
具体实施方式
当在权利要求和/或说明书中与术语“包含”联用时,词语“一(a)”或“一(an)”可以指“一个”,但也可以指“一个或多个”、“至少一个”以及“一个或多于一个”。
如在权利要求和说明书中所使用的,词语“包含”、“具有”、“包括”或“含有”是指包括在内的或开放式的,并不排除额外的、未引述的元件或方法步骤。
在整个申请文件中,术语“约”表示:一个值包括测定该值所使用的装置或方法的误差的标准偏差。
虽然所公开的内容支持术语“或”的定义仅为替代物以及“和/或”,但除非明确表示仅为替代物或替代物之间相互排斥外,权利要求中的术语“或”是指“和/或”。
当用于权利要求书或说明书时,选择/可选/优选的“数值范围”既包括范围两端的数值端点,也包括相对于前述数值端点而言,所述数值端点中间所覆盖的所有自然数。
如本公开所使用的,术语“野生型”指在自然界中可以找到的对象。例如,一种可以从自然界的一个来源中分离出来并且在实验室中没有被人类有意修改的多肽、多核苷酸序列或微生物是天然存在的。如本公开所用的,“天然存在”和“野生型”是同义词。
如本公开所使用的,术语“微生物”是肉眼难以观测的微小生物的总称,包括细菌、真菌等等。由于微生物的表面积与体积比很大,能够快速与外界环境进行物质交换,产生代谢产物。本公开中的微生物特指能够发酵培养,产生糖类、脂质、氨基酸、核苷酸等代谢产物的发酵微生物。
如本公开所使用的,术语“氢氧化细菌”(Hydrogen-oxidizing bacteria)利用氢气作为电子供体,将二氧化碳还原为有机物。氢氧化细菌为兼性化能自养细菌,其包括通过氢氧化反应产生能量的氢元件,和通过固碳反应合成目标产物的固碳元件。
示例性的,氢氧化细菌包括但不限于假单胞菌属(Pseudomonas)、副球菌属(Paracoccus)、黄杆菌属(Flavobacterium)、分支杆菌属(Mycobacterium)、产碱菌属(Alcaligenes)、诺卡氏菌属(Nocardia)、醋酸杆菌属(Acetobacter)、棒杆菌属(Corynebacterium)、贪铜菌属(Cupriavidus)等。在一些实施方式中,氢氧化细菌为贪铜菌属(Cupriavidus)细菌。在一些具体的实施方式中,氢氧化细菌为钩虫贪铜菌(Cupriavidusnecator)。
如本公开所使用的,术语“重组微生物”是以基因工程方法对野生型微生物或亲本微生物进行改造,得到的不同于野生型微生物或亲本微生物的改造的微生物。实施方案包括但不限于引入微生物的外源基因、可操作地连接到异源启动子的内源蛋白质编码序列和具有经修改的蛋白质编码序列的基因。重组基因保存在微生物的基因组、微生物中的质粒或微生物中的噬菌体上。
在一个具体的实施方式中,本公开中的“重组微生物”为“重组氢氧化细菌”。
如本公开所使用的,术语“衍生菌株”包括其中一个或多个内源基因或序列被缺失或修饰和/或一个或多个外源基因或序列被引入的修饰的生物体。
如本公开所使用的,术语“异养”指代不能合成生物从二氧化碳生存和生长所需的所有有机化合物,并且必须利用有机化合物进行生长的生物。
如本公开所使用的,术语“自养”指代能合成生物从二氧化碳生存和生长所需的所有有机化合物,并且可利用其进行生长的生物。
如本公开所使用的,术语“核酮糖-1,5-二磷酸羧化酶/加氧酶”(Ribulose-1,5-bisphosphate carboxylase/oxygenase,Rubisco)是光合作用固定CO
如本公开所使用的,术语“分子伴侣”(Chaperone)又称为侣伴蛋白(molecularchaperone),是一类协助细胞内分子组装和协助蛋白质折叠的蛋白质。GroES、GroEL是来源于大肠杆菌的分子伴侣,在肽链的折叠过程中发挥重要作用,能够促进蛋白的正确折叠、组装。
如本公开所使用的,术语“氢化酶”以H
如本公开所使用的,术语“超氧化物歧化酶”(Superoxide dismutase,SOD)是生物体内存在的一种抗氧化金属酶,它能够催化超氧阴离子自由基歧化生成氧和过氧化氢。
如本公开所使用的,术语“过氧化氢酶”是一类广泛存在于生物体中的抗氧化剂,其作用是催化过氧化氢转化为水和氧气的反应。
如本公开所使用的,术语“编码基因”是指能够通过一定的规则指导蛋白的合成DNA分子,蛋白编码基因指导蛋白合成的过程一般包括以双链DNA为模板的转录过程和以mRNA为模板的翻译过程。编码基因含有CDS序列(Coding Sequence),能够指导编码蛋白质的mRNA的产生。
如本公开所使用的,术语“表达”包括涉及RNA产生及蛋白产生的任何步骤,包括但不限于:转录、转录后修饰、翻译、翻译后修饰和分泌。
如本公开所使用的,术语“多肽”、“酶”、“多肽或酶”、“多肽/酶”具有相同的含义,其在本公开中可以互换。前述术语是指一种由和很多氨基酸通过肽键组成的聚合物,其可能含有或可能不含有如磷酸基和甲酰基的修饰。
如本公开所使用的,术语“酶活性”“蛋白活性”也被表述为“比活力”或“比活度”,其在本公开中具有相同的含义,可以互换使用。其是指每毫克多肽(酶、蛋白)的酶活力(U/mg)、蛋白活力(U/mg)。
如本公开所使用的,术语“可操作地连接”是指如下的构造:调控序列相对于多核苷酸的编码序列安置在适当位置,从而使得该调控序列指导该编码序列的表达。示例性的,所述调控序列可以选自启动子和/或增强子编码的序列。
如本公开所使用的,术语“基因工程改造”是指任何对野生型菌株或亲本菌株进行的遗传操作,包括但不限于各种分子生物学手段。本公开中的术语“修饰”、“基因编辑”、“基因改造”、“基因工程改造”可相互替换。
如本公开所使用的,术语“内源的”指在生物体或细胞内自然表达或产生的多核苷酸、多肽或其他化合物。也就是说,内源性多核苷酸、多肽或其他化合物不是外源的。例如,当细胞最初从自然界分离时,细胞中存在一种“内源性”多核苷酸或多肽。
如本公开所使用的,术语“外源的”指在需要表达的特定细胞或有机体中天然发现或表达的任何多核苷酸或多肽。外源多核苷酸、多肽或其他化合物不是内源性的。
如本公开所使用的,术语“氨基酸突变”或“核苷酸突变”,包括“取代、重复、缺失或添加一个或多个氨基酸或核苷酸”。在本公开中,术语“突变”是指核苷酸序列或者氨基酸序列的改变。在一个具体的实施方式中,术语“突变”是指“取代”。
在一个实施方式中,本公开的“突变”可以选自“保守突变”。在本公开中,术语“保守突变”是指可正常维持蛋白质的功能的突变。保守突变的代表性例子为保守置换。
如本公开所使用的,术语“保守置换”涉及用具有类似侧链的氨基酸残基替换氨基酸残基。本领域已经定义了具有类似侧链的氨基酸残基家族,并且包括具有碱性侧链(例如赖氨酸、精氨酸和组氨酸)、酸性侧链(例如天冬氨酸和谷氨酸)、不带电极性侧链(例如甘氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、酪氨酸、和半胱氨酸)、非极性侧链(例如丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、蛋氨酸和色氨酸)、β-支链(例如苏氨酸、缬氨酸和异亮氨酸)和芳香侧链(例如酪氨酸、苯丙氨酸、色氨酸和组氨酸)。如本公开所使用的,“保守置换”通常在蛋白质的一个或多个位点上交换一种氨基酸。这种取代可以是保守的。作为被视作保守置换的置换,此外,保守突变还包括起因于基因所来源的个体差异、株、种的差异等天然产生的突变。
如本公开所使用的,术语“多核苷酸”指由核苷酸组成的聚合物。多核苷酸可以是单独片段的形式,也可以是更大的核苷酸序列结构的一个组成部分,其是从至少在数量或浓度上分离一次的核苷酸序列衍生而来的,能够通过标准分子生物学方法(例如,使用克隆载体)识别、操纵以及恢复序列及其组分核苷酸序列。当一个核苷酸序列通过一个DNA序列(即A、T、G、C)表示时,这也包括一个RNA序列(即A、U、G、C),其中“U”取代“T”。换句话说,“多核苷酸”指从其他核苷酸(单独的片段或整个片段)中去除的核苷酸聚合物,或者可以是一个较大核苷酸结构的组成部分或成分,如表达载体或多顺反子序列。多核苷酸包括DNA、RNA和cDNA序列。“重组多核苷酸”属于“多核苷酸”中的一种。
如本公开所使用的,术语“载体”指的是DNA构建体,其含有与合适的控制序列可操作地连接的DNA序列,从而在合适的宿主中表达目的基因。“重组表达载体”指用于表达例如编码所需多肽的多核苷酸的DNA结构。重组表达载体可包括,例如包含i)对基因表达具有调控作用的遗传元素的集合,例如启动子和增强子;ii)转录成mRNA并翻译成蛋白质的结构或编码序列;以及iii)适当的转录和翻译起始和终止序列的转录亚单位。重组表达载体以任何合适的方式构建。载体的性质并不重要,并可以使用任何载体,包括质粒、病毒、噬菌体和转座子。用于本公开的可能载体包括但不限于染色体、非染色体和合成DNA序列,例如细菌质粒、噬菌体DNA、酵母质粒以及从质粒和噬菌体DNA的组合中衍生的载体,来自如牛痘、腺病毒、鸡痘、杆状病毒、SV40和伪狂犬病等病毒的DNA。
如本公开所使用的,术语“引入”包括“转染”、“转化”或“转导”并且指代将核酸序列并入至真核或原核细胞中,在所述真核或原核细胞,核酸序列可并入至所述细胞的基因组(例如,染色体、质粒、质体或线粒体DNA)中,转化成能独立复制的复制子,或独立于细胞的基因组表达。“转染”、“转化”或“转导”的方法包括但不限于电穿孔法、磷酸钙(CaPO
如本公开所使用的,术语“培养”指代使细胞(例如微生物细胞)群体在合适的生长条件下、在液态或固态培养基中生长。
如本公开所使用的,术语“产率”具有本领域技术人员普遍理解的意思,即生成目标产物所消耗的底物占总的底物的百分比。在本公开中,“目标产物产率”和“底物转化率”可以相互替代使用。
如本公开所使用的,术语“产量”指代由进料产生的产物相对于如果所有进料物质转化为产物将产生的物质总量的量。举例来说,氨基酸产率可以表示为相对于如果100%的进料转化为氨基酸的理论产率,所产生的氨基酸的%。
本公开的重组微生物的培养可以根据本领域的常规方法进行,包括但不限于孔板培养、摇瓶培养、批次培养、连续培养和分批补料培养等,并可以根据实际情况适当地调整各种培养条件如温度、时间和培养基的pH值等。
除非另外定义或由背景清楚指示,否则在本公开中的全部技术与科学术语具有如本公开所属领域的普通技术人员通常理解的相同含义。
本公开提供的生产生产单细胞蛋白的方法,包括如下步骤:
向包含重组氢氧化细菌的发酵培养基中通入作为能源的第一气体,和作为碳源的第二气体;对重组氢氧化细菌进行发酵培养,使重组氢氧化细菌合成单细胞蛋白;
其中,所述重组氢氧化细菌包括通过氢氧化反应产生能量的氢元件,和通过固碳反应合成目标产物的固碳元件;并且,与野生型氢氧化细菌相比,所述重组微生物具有如下(i)-(ii)中至少一项所示的特性:
(i)氢元件中一个或多个与氢氧化反应相关的蛋白活性,或蛋白编码基因的表达水平被增强;(ii)固碳元件中一个或多个与固碳反应相关的蛋白活性,或蛋白编码基因的表达水平被增强。
本公开提供的生产单细胞蛋白的方法,通过使用氢元件、固碳元件加强的重组氢氧化细菌,具有提高的氢能源利用效率和固碳反应效率,能够实现对单细胞蛋白的高效生产,具有重要的工业应用价值。
在一些实施方式中,第一气体包含氢气和氧气,第二气体包括二氧化碳。发酵培养基中的重组氢氧化细菌以氢气为能源,以二氧化碳为碳源,通过卡尔文循环等固碳反应过程合成单细胞蛋白。其中,第一气体可以仅包含氢气和氧气,或者是含有其他气体的混合气体。第二气体可以是仅含有二氧化碳的混合气体,或者是含有其他种类气体的混合气体。例如,第二气体为包含二氧化碳气体的空气等气体。
进一步的,氢气、氧气和二氧化碳的体积比为(4-7):1:1。示例性的,氢气、氧气和二氧化碳的体积比为4:1:1、5:1:1、6:1:1、7:1:1等等。作为优选的实施方式,氢气、氧气和二氧化碳的体积比为7:1:1。
包含氢气、氧气的第一气体,与包含二氧化碳的第二气体可以彼此独立的通入发酵培养基中,也可以混合后向发酵培养基中通入混合气体。在一些优选地实施方式中,第一气体与第二气体混合通入发酵培养基,其中,每分钟向所述发酵培养基通入所述第一气体和所述第二气体的混合气体的体积,与容置所述发酵培养基的反应内腔的体积比为(2-5):10。示例性的,当反应内腔的体积为100ml,第一气体和第二气体的混合气体的流速为20-50ml/min,进一步的,通入混合气体的流速为20ml/min、25ml/min、30ml/min、35ml/min、40ml/min、50ml/min等等。作为优选的实施方式,混合气体的流速为20ml/min。通过控制混合气体通入发酵培养基中的流速,对于提高重组氢氧化细菌的生长速率,进而提高目标单细胞蛋白的产量和生产速率具有重要意义。
通过优化第一气体、第二气体的通入方式,混合气体流速,以及氢气、氧气和二氧化碳通入的体积比,使发酵培养基中重组氢氧化细菌保持高密度生长、并具有高的代谢活性,以实现对目标产物的高转化速率,得到产量显著提高的单细胞蛋白。
在一些实施方式中,对重组氢氧化细菌进行发酵培养温度为25-35℃,示例性的,发酵培养的温度为26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃等等。在一些优选的实施方式中,发酵培养的温度为30℃。在一些实施方式中,发酵培养的pH为5.5-8.0,示例性的,发酵培养的pH为5.5-6,6-6.5,6.5-7,7-7.5,7.5-8等等。在一些优选地实施方式中,发酵培养的pH为6.0-7.0。本公开中的发酵培养条件适合重组氢氧化细菌保持高的生产、代谢活性,实现对单细胞蛋白的生物量积累。
在一些实施方式中,发酵培养基包含磷酸盐。其中,发酵培养基中磷酸盐的浓度为25-35mM,示例性的,发酵培养基中磷酸盐的浓度为26mM、28mM、29mM、30mM、32mM、34mM等等。在一些优选的实施方式中,发酵培养基中磷酸盐的浓度30mM。在一些具体的实施方式中,所述磷酸盐选自磷酸二氢钾、磷酸氢二钾、磷酸二氢钠、磷酸氢二钠中的一种或两种以上的组合。在一些优选的实施方式中,磷酸盐为磷酸二氢钠、磷酸氢二钠中的一种或两种。
进一步的,发酵培养基中还包含镍、亚铁、铁、钙、镁等离子。在一些优选的实施方式中,发酵培养基中包含亚铁盐。示例性的,亚铁盐为氯化亚铁、硫酸亚铁等。在一些优选的实施方式中,亚铁盐为硫酸亚铁,发酵培养基中硫酸亚铁的浓度为30-60mg/l,示例性的,发酵培养基中硫酸亚铁的浓度为35mg/l、38mg/l、40mg/l、42mg/l、45mg/l、48mg/l、50mg/l、52mg/l、54mg/l、56mg/l、57mg/l、59mg/l等等。在一些优选的实施方式中,发酵培养基中硫酸亚铁的浓度为50mg/l。
本公开中的发酵培养基适于重组氢氧化细菌的自养培养,能够维持重组氢氧化细菌的快速生长、代谢。
在另外一些实施方式中,发酵培养基中还可以包含其他种类的磷酸盐,或其他种类的亚铁盐,只要其能够形式适于重组氢氧化细菌的生长、代谢的营养环境即可。
在一些实施方式中,本公开使用重组氢氧化细菌生产目标的单细胞蛋白,重组氢氧化细菌包括通过氢氧化反应产生能量的氢元件,和通过固碳反应合成目标产物的固碳元件。并且,与野生型氢氧化细菌相比,所述重组微生物具有如下(i)-(ii)中至少一项所示的特性:
(i)氢元件中一个或多个与氢氧化反应相关的蛋白活性,或蛋白编码基因的表达水平被增强;(ii)固碳元件中一个或多个与固碳反应相关的蛋白活性,或蛋白编码基因的表达水平被增强。
重组氢氧化细菌具有加强的氢元件,以及固碳元件,其利用氢气代谢生产能量的利用率提高,可为固碳元件提供丰富的能量来源,进一步加强固碳元件合成目标产物的反应效率,使重组氢氧化细菌合成目标产物的产量和速率显著提升。
在一些实施方式中,与固碳反应相关的蛋白包括核酮糖-1,5-二磷酸羧化酶/加氧酶,核酮糖-1,5-二磷酸羧化酶/加氧酶是卡尔文循环固定CO
在一些可选地实施方式中,核酮糖-1,5-二磷酸羧化酶/加氧酶为包含如SEQ IDNO:1所示氨基酸序列的,并且具有核酮糖-1,5-二磷酸羧化酶/加氧酶活性的多肽。作为优选,核酮糖-1,5-二磷酸羧化酶/加氧酶的氨基酸序列如SEQ ID NO:1所示。
在一些可选地实施方式中,核酮糖-1,5-二磷酸羧化酶/加氧酶为如SEQ ID NO:1所示氨基酸序列经过取代、重复、缺失或添加一个或多个氨基酸,且具有核酮糖-1,5-二磷酸羧化酶/加氧酶活性的多肽。
在一些可选地实施方式中,核酮糖-1,5-二磷酸羧化酶/加氧酶是由于与SEQ IDNO:2所示的核苷酸序列具有至少90%的序列同一性的序列编码的,具有核酮糖-1,5-二磷酸羧化酶/加氧酶活性的多肽。示例性的,编码核酮糖-1,5-二磷酸羧化酶/加氧酶的核苷酸序列与SEQ ID NO:2所示序列具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性。
在一些具体的实施方式中,通过向氢氧化细菌中导入外源的核酮糖-1,5-二磷酸羧化酶/加氧酶的编码基因,以上调氢氧化细菌中核酮糖-1,5-二磷酸羧化酶/加氧酶的表达水平。进一步的,是通过向氢氧化细菌中导入核苷酸序列如SEQ ID NO:2所示的编码基因。
在一些优选的实施方式中,与固碳反应相关的蛋白还包括GroES、GroEL,GroES、GroEL是促进核酮糖-1,5-二磷酸羧化酶/加氧酶的蛋白折叠、组装的分子伴侣,可促进核酮糖-1,5-二磷酸羧化酶/加氧酶形成正确的空间构象,从而使其具有高的酶活性。
在一些可选地实施方式中,GroES为包含如SEQ ID NO:3所示氨基酸序列的,并且具有GroES蛋白活性的多肽。作为优选,GroES的氨基酸序列如SEQ ID NO:3所示。GroEL为包含如SEQ ID NO:5所示氨基酸序列的,并且具有GroEL蛋白活性的多肽。作为优选,GroEL的氨基酸序列如SEQ ID NO:5所示。
在一些可选地实施方式中,GroES为如SEQ ID NO:3所示氨基酸序列经过取代、重复、缺失或添加一个或多个氨基酸,且具有GroES蛋白活性的多肽。GroEL为如SEQ ID NO:5所示氨基酸序列经过取代、重复、缺失或添加一个或多个氨基酸,且具有GroEL蛋白活性的多肽。
在一些可选地实施方式中,GroES是由与SEQ ID NO:4所示的核苷酸序列具有至少90%的序列同一性的序列编码的,具有GroES蛋白活性的多肽。示例性的,编码GroES的核苷酸序列与SEQ ID NO:4所示序列具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性。GroEL是由与SEQ ID NO:6所示的核苷酸序列具有至少90%的序列同一性的序列编码的,具有GroEL蛋白活性的多肽。示例性的,编码GroEL的核苷酸序列与SEQ ID NO:6所示序列具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%的序列同一性。
在一些具体的实施方式中,通过向氢氧化细菌中导入外源的GroES、GroEL的编码基因,实现在氢氧化细菌中表达GroES、GroEL,从而促进核酮糖-1,5-二磷酸羧化酶/加氧酶的蛋白折叠、组装。进一步的,是通过向氢氧化细菌中导入核苷酸序列如SEQ ID NO:4所示的编码基因,以及核苷酸序列如SEQ ID NO:6所示的编码基因。
在一些实施方式中,所述重组氢氧化细菌包含表达核酮糖-1,5-二磷酸羧化酶/加氧酶的重组表达载体;利用重组表达载体提高重组氢氧化氢细菌内核酮糖-1,5-二磷酸羧化酶/加氧酶的表达水平。在一些优选地实施方式中,所述重组氢氧化细菌包含表达核酮糖-1,5-二磷酸羧化酶/加氧酶、GroES和GroEL的重组表达载体。利用包含核酮糖-1,5-二磷酸羧化酶/加氧酶、GroES和GroEL的重组表达载体,能够在重组氢氧化氢细菌内高水平表达具有正确空间结构的核酮糖-1,5-二磷酸羧化酶/加氧酶。
在一些具体的实施方式中,所述重组表达载体的核苷酸序列如SEQ ID NO:7或SEQID NO:8所示。
在一些实施方式中,与氢氧化反应相关的蛋白包括氢化酶。氢化酶能够以氢气为电子供体,通过氧化氢气代谢产生能量,用于卡尔文循环等固碳反应。重组氢氧化细菌中氢化酶的酶活性提高,或氢化酶的编码基因的表达水平提高,能够提高氢氧化细菌对氢气的利用率,进而提高重组氢氧化细菌内代谢氢产生的能量,促进固碳反应的发生。
在一些实施方式中,氢氧化细菌内的氢化酶包括但不限于:膜连接氢化酶(MBH)、可溶性氢化酶(SH)、调节性氢化酶(RH)、假设性氢化酶(Hy4)。此处的氢元件为膜连接氢化酶(MBH)及可溶性氢化酶(SH)。在一些实施方式中,重组氢氧化细菌中与氢氧化反应相关的蛋白活性,或蛋白编码基因的表达水平被增强,是指膜连接氢化酶(MBH)、可溶性氢化酶(SH)中的一种或两种酶的活性增强或表达水平增强。
优选地,所述重组氢氧化细菌中氢化酶的编码基因与强启动子相连接。示例性的,将氢化酶的编码基因的启动子优化为BBa_J23119,以提高重组氢氧化细菌中氢化酶的表达水平。
在一些实施方式中,所述重组氢氧化细菌为贪铜菌属细菌。在一些优选地实施方式中,所述重组氢氧化细菌为钩虫贪铜菌或其衍生菌株。在另外一些实施方式中,重组氢氧化细菌还可以是其他种类的氢氧化细菌,例如,假单胞菌属细菌、棒杆菌属细菌等等。
本公开中的生产单细胞蛋白的方法,通过调整氢气、氧气和二氧化碳的通入比例,以及三者的混合气体的通入速度,使重组氢氧化细菌生长7天后OD
本公开的碳固定系统包括:
反应容器,具有容置发酵培养基的内腔,所述发酵培养基中包含重组氢氧化细菌;
通气单元,所述通气单元用于向所述发酵培养基内通入作为能源的第一气体和作为碳源的第二气体。
在一些实施方式中,第一气体包含氢气和氧气,第二气体包括二氧化碳。发酵培养基中的重组氢氧化细菌以氢气为能源,以二氧化碳为碳源,通过卡尔文循环等固碳反应过程合成单细胞蛋白。其中,第一气体可以仅包含氢气和氧气,或者是含有其他气体的混合气体。第二气体可以是仅含有二氧化碳的混合气体,或者是含有其他种类气体的混合气体。例如,第二气体为包含二氧化碳气体的空气等气体。
本公开中的碳固定系统对氢能源的利用效率高,固碳反应的效率高,包含重组氢氧化细菌的碳固定系统具有显著提高的目标产物的产量和生产速率,适合对单细胞蛋白的规模化生产。
在一些实施方式中,反应容器具有容置发酵培养基内腔,以及将反应容器的内腔与外界连通的第一连通口。电解单元和通气单元可以通过连通口与内腔中的发酵培养基接触,提供重组氢氧化细菌所需要的氢气和二氧化碳气体。本公开中的反应容器可以是能够实现重组氢氧化细菌的发酵培养的任意类型的生物反应器。
进一步的,反应容器上还开设有用于向内腔中通入发酵培养基的第二连通口。第一连通口和第二连通口可以是同一开口或是不同开口。在一些可选地实施方式中,通过第二连通口,可以向反应内腔中周期性地提供发酵培养基。
通气单元用于向发酵培养基内通入第一气体和第二气体。在一些实施方式中,第一气体和第二气体彼此独立地通入发酵培养基中,通气单元包括用于通入第一气体的第一通气组件和用于通入气体的第二通气组件。其中,第一通气组件包括伸入发酵培养基中的第一管路,以及与所述管路相连接的第一储气瓶;第二通气组件包括伸入发酵培养基中的第二管路,以及与所述管路相连接的第二储气瓶。第一储气瓶中储存有包含氢气和氧气的第一气体,第二储气瓶中储存有包含二氧化碳的第二气体。在一定的压力条件下,第一气体和第二气体分别经第一管路和第二管路输送至发酵培养基中,为重组氢氧化细菌提供氢能源和碳原料。
在另外一些实施方式中,第一气体和第二气体混合后通入发酵培养基中,通气单元包括用于通入混合气体的混合通气组件。混合通气组件包括伸入发酵培养基中的第三管路,以及与所述管路相连接的第三储气瓶。第三储气瓶中可以是储存按比例混合的氢气、氧气、二氧化碳;或者是按比例向第三储气瓶内输送氢气、氧气、二氧化碳,使三者在储气瓶内混合形成混合气体。在一定的压力条件下,混合气体按照一定的流速通入发酵培养基中,为重组氢氧化细菌提供适宜的能源和碳源条件。
本公开的碳固定系统只需将装置安装好,添加好所需培养基、转接较低浓度重组氢氧化细菌发酵培养后即可获得高产量目标产物,具有产量高、技术简单、容易控制等优点,适宜推广。
在本领域,用于操纵微生物的方法是已知的,如《分子生物学现代方法》(OnlineISBN:9780471142720,John Wiley and Sons,Inc.)、《微生物代谢工程:方法和规程》(Qiong Cheng Ed.,Springer)和《系统代谢工程:方法和规程》(Hal S.Alper Ed.,Springer)等出版物中被解释。
在本公开中,核苷酸或氨基酸的编号的含义如下:
SEQ ID NO:1所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的第一亚基的氨基酸序列;
SEQ ID NO:2所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的伴侣蛋白的氨基酸序列;
SEQ ID NO:3所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的第二亚基的氨基酸序列;
SEQ ID NO:4所示的序列是来源于C.necator H16的GroES的氨基酸序列;
SEQ ID NO:5所示的序列是来源于C.necator H16的GroEL的氨基酸序列;
SEQ ID NO:6所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的第一亚基的核苷酸序列;
SEQ ID NO:7所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的伴侣蛋白的核苷酸序列;
SEQ ID NO:8所示的序列是来源于Synechococcus sp.pcc 7002的核酮糖-1,5-二磷酸羧化酶/加氧酶的第二亚基的核苷酸序列;
SEQ ID NO:9所示的序列是来源于C.necator H16的GroES的核苷酸序列;
SEQ ID NO:10所示的序列是来源于C.necator H16的GroEL的核苷酸序列;
SEQ ID NO:11所示的序列重组质粒pBBR-SpRubisco的核苷酸序列;
SEQ ID NO:12所示的序列重组质粒pBBR-SypRubisco-CnGroESL的核苷酸序列。
实施例
本公开的其他目的、特征和优点将从以下详细描述中变得明显。但是,应当理解的是,详细描述和具体实施例(虽然表示本公开的具体实施方式)仅为解释性目的而给出,因为在阅读该详细说明后,在本公开的精神和范围内所作出的各种改变和修饰,对于本领域技术人员来说将变得显而易见。
本实施例中所用到的实验技术与实验方法,如无特殊说明均为常规技术方法,例如下列实施例中未注明具体条件的实验方法,通常按照常规条件如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring Harbor Laboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。
除非另有说明,以下实施例中使用的原料和试剂均为市售商品,或者可以通过已知方法制备。
本发明实施例中使用的部分材料信息如下:
pET20b、pET28a载体,Novagen,Madison,WI;
大肠杆菌表达菌BL21(DE3),Invitrogen,Carlsbad,CA;
实施例1:重组氢氧化细菌的构建
(1)在野生型Cupriavidus necator H16菌株的基础上,采用pK18mobsacB质粒敲除了两个限制性内切酶基因H16_A0006和H16_A0008-9后,获得M1菌株(Cupriavidusnecator H16ΔH16_A0006ΔH16_A0008-9)。
(2)在M1菌株的基础上,把氢元件的启动子(具体为膜连接氢化酶(MBH)及可溶性氢化酶(SH)的启动子)优化为BBa_J23119,获得M2菌株。
(3)选择Synechococcus sp.pcc 7002的Rubisco,先利用PCR扩增把Rubisco大小亚基(GenBank:CP000951.1)从基因组上克隆下来,利用双酶切(酶切位点为NdeI及SacI),连接转化至pBBR-MCS质粒骨架上,构成重组质粒pBBR-SpRubisco。
把来源于C.necator H16的分子伴侣GroES及GroEL基因利用同样的方式连接至上述质粒上,构建重组质粒pBBR-SypRubisco-CnGroESL。
把pBBR-SypRubisco-CnGroESL通过接合转移方式转入至M2菌株中,获得M3菌株。
实施例2:通气产单细胞蛋白体积确定
此处氢气来源为氢气发生器,二氧化碳及氧气为气瓶,调整通气比例H
结果如图1所示,M2在40ml培养基2的条件下展现出较好结果,4天OD
实施例3:M2菌株通气发酵产单细胞蛋白培养基优化
此处氢气来源为氢气发生器,二氧化碳及氧气为气瓶,调整通气比例H
M3菌株以培养基3为基础于M2菌株相同条件下培养。每隔24h采集并测定吸光值。
结果如图2、图3所示,M2在培养基3的条件下7天OD
实施例4:工程菌株M3气体比例优化
调整通气比例H
结果如图4所示,通气比例H
实施例5:工程菌株M3气体流速优化
通气比例H
结果如图5所示,混合气流速为20ml/min时M3展示出最佳的生长曲线。
以上,对本公开的实施方式进行了说明。但是,本公开不限定于上述实施方式。凡在本公开的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
序列表
<110> 中国科学院天津工业生物技术研究所
<120> 一种生产单细胞蛋白的方法及碳固定系统
<130> 6A17-2163693I
<160> 12
<170> SIPOSequenceListing 1.0
<210> 1
<211> 471
<212> PRT
<213> Synechococcus PCC7002
<400> 1
Met Val Gln Thr Lys Ser Ala Gly Phe Asn Ala Gly Val Gln Asp Tyr
1 5 10 15
Arg Leu Thr Tyr Tyr Thr Pro Asp Tyr Thr Pro Lys Asp Thr Asp Leu
20 25 30
Leu Ala Cys Phe Arg Met Thr Pro Gln Pro Gly Val Pro Pro Glu Glu
35 40 45
Cys Ala Ala Ala Val Ala Ala Glu Ser Ser Thr Gly Thr Trp Thr Thr
50 55 60
Val Trp Thr Asp Gly Leu Thr Asp Leu Asp Arg Tyr Lys Gly Arg Cys
65 70 75 80
Tyr Asn Val Glu Pro Val Pro Gly Glu Asp Asn Gln Tyr Phe Cys Phe
85 90 95
Val Ala Tyr Pro Leu Asp Leu Phe Glu Glu Gly Ser Val Thr Asn Val
100 105 110
Leu Thr Ser Leu Val Gly Asn Val Phe Gly Phe Lys Ala Leu Arg Ala
115 120 125
Leu Arg Leu Glu Asp Ile Arg Phe Pro Val Ala Leu Ile Lys Thr Tyr
130 135 140
Gln Gly Pro Pro His Gly Ile Thr Val Glu Arg Asp Leu Leu Asn Lys
145 150 155 160
Tyr Gly Arg Pro Leu Leu Gly Cys Thr Ile Lys Pro Lys Leu Gly Leu
165 170 175
Ser Ala Lys Asn Tyr Gly Arg Ala Val Tyr Glu Cys Leu Arg Gly Gly
180 185 190
Leu Asp Phe Thr Lys Asp Asp Glu Asn Ile Asn Ser Gln Pro Phe Met
195 200 205
Arg Trp Arg Asp Arg Phe Leu Phe Val Gln Glu Ala Ile Glu Lys Ser
210 215 220
Gln Ala Glu Thr Asn Glu Val Lys Gly His Tyr Leu Asn Val Thr Ala
225 230 235 240
Gly Thr Cys Glu Glu Met Leu Lys Arg Ala Glu Phe Ala Lys Glu Ile
245 250 255
Gly Thr Pro Ile Ile Met His Asp Phe Leu Thr Gly Gly Phe Thr Ala
260 265 270
Asn Thr Thr Leu Ala Lys Trp Cys Arg Asp Asn Gly Val Leu Leu His
275 280 285
Ile His Arg Ala Met His Ala Val Ile Asp Arg Gln Lys Asn His Gly
290 295 300
Ile His Phe Arg Val Leu Ala Lys Cys Leu Arg Leu Ser Gly Gly Asp
305 310 315 320
His Leu His Ser Gly Thr Val Val Gly Lys Leu Glu Gly Asp Arg Ala
325 330 335
Ala Thr Leu Gly Phe Val Asp Leu Met Arg Glu Asp Tyr Val Glu Glu
340 345 350
Asp Arg Ser Arg Gly Val Phe Phe Thr Gln Asp Tyr Ala Ser Leu Pro
355 360 365
Gly Thr Met Pro Val Ala Ser Gly Gly Ile His Val Trp His Met Pro
370 375 380
Ala Leu Val Glu Ile Phe Gly Asp Asp Ser Cys Leu Gln Phe Gly Gly
385 390 395 400
Gly Thr Leu Gly His Pro Trp Gly Asn Ala Pro Gly Ala Thr Ala Asn
405 410 415
Arg Val Ala Leu Glu Ala Cys Val Gln Ala Arg Asn Glu Gly Arg Ser
420 425 430
Leu Ala Arg Glu Gly Asn Asp Val Leu Arg Glu Ala Gly Lys Trp Ser
435 440 445
Pro Glu Leu Ala Ala Ala Leu Asp Leu Trp Lys Glu Ile Lys Phe Glu
450 455 460
Phe Asp Thr Val Asp Thr Leu
465 470
<210> 2
<211> 134
<212> PRT
<213> Synechococcus PCC7002
<400> 2
Met Glu Phe Lys Lys Val Ala Lys Glu Thr Ala Ile Thr Leu Gln Ser
1 5 10 15
Tyr Leu Thr Tyr Gln Ala Val Arg Leu Ile Ser Gln Gln Leu Ser Glu
20 25 30
Thr Asn Pro Gly Gln Ala Ile Trp Leu Gly Glu Phe Ser Lys Arg His
35 40 45
Pro Ile Gln Glu Ser Asp Leu Tyr Leu Glu Ala Met Met Leu Glu Asn
50 55 60
Lys Glu Leu Val Leu Arg Ile Leu Thr Val Arg Glu Asn Leu Ala Glu
65 70 75 80
Gly Val Leu Glu Phe Leu Pro Glu Met Val Leu Ser Gln Ile Lys Gln
85 90 95
Ser Asn Gly Asn His Arg Arg Ser Leu Leu Glu Arg Leu Thr Gln Val
100 105 110
Asp Ser Ser Ser Thr Asp Gln Thr Glu Pro Asn Pro Gly Glu Ser Asp
115 120 125
Thr Ser Glu Asp Ser Glu
130
<210> 3
<211> 111
<212> PRT
<213> Synechococcus PCC7002
<400> 3
Met Lys Thr Leu Pro Lys Glu Lys Arg Tyr Glu Thr Leu Ser Tyr Leu
1 5 10 15
Pro Pro Leu Ser Asp Gln Gln Ile Ala Arg Gln Val Gln Tyr Met Met
20 25 30
Asp Gln Gly Tyr Ile Pro Gly Ile Glu Phe Glu Lys Asp Pro Thr Pro
35 40 45
Glu Leu His His Trp Thr Leu Trp Lys Leu Pro Leu Phe Asn Ala Ser
50 55 60
Ser Ala Gln Glu Val Leu Asn Glu Val Arg Glu Cys Arg Ser Glu Tyr
65 70 75 80
Ser Asp Cys Tyr Ile Arg Val Val Gly Phe Asp Asn Ile Lys Gln Cys
85 90 95
Gln Thr Val Ser Phe Ile Val Tyr Lys Pro Asn Gln Thr Arg Tyr
100 105 110
<210> 4
<211> 96
<212> PRT
<213> Cupriavidus necator H16
<400> 4
Met Asn Leu Arg Pro Leu His Asp Arg Val Ile Val Lys Arg Leu Asp
1 5 10 15
Asn Glu Thr Lys Thr Ala Ser Gly Ile Val Ile Pro Asp Asn Ala Ala
20 25 30
Glu Lys Pro Asp Gln Gly Glu Val Leu Ala Ile Gly Pro Gly Lys Lys
35 40 45
Asp Asp Lys Gly Asn Asn Ile Ala Leu Asp Val Lys Val Gly Asp Arg
50 55 60
Val Leu Phe Gly Lys Tyr Ala Gly Gln Ala Val Lys Val Glu Gly Gln
65 70 75 80
Glu Leu Leu Val Met Arg Glu Glu Asp Ile Met Ala Val Val Asn Lys
85 90 95
<210> 5
<211> 547
<212> PRT
<213> Cupriavidus necator H16
<400> 5
Met Ala Ala Lys Asp Val Val Phe Gly Asp Ala Ala Arg Ala Lys Met
1 5 10 15
Val Glu Gly Val Asn Ile Leu Ala Asn Ala Val Lys Val Thr Leu Gly
20 25 30
Pro Lys Gly Arg Asn Val Val Leu Glu Arg Ser Phe Gly Gly Pro Thr
35 40 45
Val Thr Lys Asp Gly Val Ser Val Ala Lys Glu Ile Glu Leu Lys Asp
50 55 60
Lys Leu Gln Asn Met Gly Ala Gln Met Val Lys Glu Val Ala Ser Lys
65 70 75 80
Thr Ser Asp Asn Ala Gly Asp Gly Thr Thr Thr Ala Thr Val Leu Ala
85 90 95
Gln Ser Ile Val Arg Glu Gly Met Lys Tyr Val Ala Ala Gly Met Asn
100 105 110
Pro Met Asp Leu Lys Arg Gly Ile Asp Lys Ala Val Thr Ala Ala Val
115 120 125
Glu Glu Leu Lys Lys Val Ser Lys Pro Thr Thr Thr Ser Lys Glu Ile
130 135 140
Ala Gln Val Gly Ala Ile Ser Ala Asn Ser Asp Thr Ser Ile Gly Glu
145 150 155 160
Arg Ile Ala Glu Ala Met Asp Lys Val Gly Lys Glu Gly Val Ile Thr
165 170 175
Val Glu Asp Gly Lys Ser Leu Ala Asp Glu Leu Glu Val Val Glu Gly
180 185 190
Met Gln Phe Asp Arg Gly Tyr Leu Ser Pro Tyr Phe Ile Asn Asn Pro
195 200 205
Glu Lys Gln Val Val Gln Leu Asp Ser Pro Phe Val Leu Leu Phe Asp
210 215 220
Lys Lys Val Ser Asn Ile Arg Asp Leu Leu Pro Val Leu Glu Gln Val
225 230 235 240
Ala Lys Ala Gly Arg Pro Leu Leu Ile Ile Ala Glu Asp Val Glu Gly
245 250 255
Glu Ala Leu Ala Thr Leu Val Val Asn Asn Ile Arg Gly Ile Leu Lys
260 265 270
Thr Ala Ala Val Lys Ala Pro Gly Phe Gly Asp Arg Arg Lys Ala Met
275 280 285
Leu Glu Asp Ile Ala Ile Leu Thr Gly Gly Thr Val Ile Ala Glu Glu
290 295 300
Ile Gly Leu Thr Leu Glu Lys Ala Gly Leu Asn Asp Leu Gly Gln Ala
305 310 315 320
Lys Arg Ile Glu Ile Gly Lys Glu Asn Thr Ile Ile Ile Asp Gly Ala
325 330 335
Gly Asp Ala Gly Ala Ile Glu Gly Arg Val Lys Gln Ile Arg Ala Gln
340 345 350
Ile Glu Glu Ala Thr Ser Asp Tyr Asp Arg Glu Lys Leu Gln Glu Arg
355 360 365
Val Ala Lys Leu Ala Gly Gly Val Ala Val Ile Lys Val Gly Ala Ala
370 375 380
Thr Glu Val Glu Met Lys Glu Lys Lys Ala Arg Val Glu Asp Ala Leu
385 390 395 400
His Ala Thr Arg Ala Ala Val Glu Glu Gly Ile Val Pro Gly Gly Gly
405 410 415
Val Ala Leu Leu Arg Ala Arg Ala Ala Ile Ser Ala Leu Thr Gly Glu
420 425 430
Asn Ala Asp Gln Asn Ala Gly Ile Lys Ile Val Leu Arg Ala Met Glu
435 440 445
Glu Pro Leu Arg Gln Ile Val Leu Asn Ala Gly Glu Glu Ala Ser Val
450 455 460
Val Val Ala Lys Val Ile Glu Gly Lys Gly Asn Tyr Gly Tyr Asn Ala
465 470 475 480
Ala Ser Gly Glu Tyr Gly Asp Leu Val Glu Met Gly Val Leu Asp Pro
485 490 495
Thr Lys Val Thr Arg Thr Ala Leu Gln Asn Ala Ala Ser Val Ala Ser
500 505 510
Leu Met Leu Thr Thr Asp Cys Ala Val Ala Glu Ser Pro Lys Asp Glu
515 520 525
Ser Ala Pro Ala Met Pro Gly Gly Met Gly Gly Met Gly Gly Met Glu
530 535 540
Gly Met Met
545
<210> 6
<211> 1416
<212> DNA
<213> Synechococcus PCC7002
<400> 6
atggttcaga ccaaatctgc tgggtttaat gccggtgtac aggactaccg cctgacttac 60
tacacccccg attacacccc gaaagatacc gacttactcg cttgtttccg gatgactccc 120
caacctggag tcccccccga agaatgtgct gcggctgttg cggctgaatc ttctaccggt 180
acttggacca ctgtatggac cgatggttta actgacctcg accgctacaa gggtcgttgc 240
tacaatgttg aacccgttcc cggtgaagac aaccaatatt tctgtttcgt tgcttacccc 300
ctcgatctgt ttgaagaagg ttctgtaacc aacgttttga cttccttggt tggtaacgta 360
ttcggtttta aagcgctgcg tgccctgcgc ctcgaagata tccgcttccc cgttgcgtta 420
atcaaaactt accaagggcc tccccacggg atcactgtag agcgtgacct cctcaacaag 480
tatggtcgtc ctctcctcgg ttgtacgatt aagccgaagc tcggtctgtc tgcgaagaac 540
tacggtcgtg cggtttatga atgtctccgt ggtggtcttg acttcaccaa agatgacgaa 600
aacatcaact ctcagccttt catgcgttgg cgcgatcgct tcctgttcgt tcaagaagct 660
atcgaaaaat cccaagctga aaccaacgaa gttaagggtc actaccttaa cgtcaccgct 720
ggcacttgcg aagaaatgct caagcgggct gaattcgcta aggaaatcgg cactcccatc 780
atcatgcacg acttcttaac tggtggtttc actgcgaata ctacccttgc gaagtggtgt 840
cgtgataacg gcgttctgct ccacatccac cgggcaatgc acgcggtaat cgaccgtcag 900
aagaaccacg gtattcactt ccgcgttctc gctaagtgtc tccgcctctc tggtggtgac 960
cacctccact ccggtacggt tgttggtaag ctcgaaggcg atcgcgccgc caccctcggt 1020
ttcgtagacc tgatgcgtga agactacgtt gaagaagatc gttctcgcgg tgtattcttc 1080
acccaagact acgcttctct ccccggcacc atgcctgtgg cttccggtgg tatccacgta 1140
tggcacatgc ctgccctcgt tgaaatcttc ggcgacgatt cctgcctcca gtttggtggt 1200
ggtaccctcg gtcacccctg gggtaacgca cctggtgcaa ctgcaaaccg tgttgctctg 1260
gaagcttgtg ttcaagctcg taacgaaggt cgcagcctgg cccgtgaagg taatgatgtc 1320
ctccgtgaag caggtaagtg gtcgcctgaa ttggcagccg ccctcgacct gtggaaggaa 1380
atcaagttcg aattcgatac cgttgacact ctctaa 1416
<210> 7
<211> 405
<212> DNA
<213> Synechococcus PCC7002
<400> 7
atggagttta aaaaagttgc gaaggaaacg gccatcactt tgcaaagcta tttgacctac 60
caagcggtgc gtctaattag tcagcagctt agtgaaacca atcctggaca ggcgatttgg 120
ctaggagagt tctctaaacg tcatccaatt caggaaagtg atctttacct cgaagcgatg 180
atgctagaaa acaaagagct cgtcctcaga atcctgacgg tgcgagaaaa ccttgcggaa 240
ggagttctgg agtttttgcc agaaatggtc ctcagccaaa tcaagcagtc caatggaaac 300
catcgccgtt ctttattaga gcgtttaact caagttgatt cttcatcaac tgatcagact 360
gaacctaacc ctggtgagtc tgatacttca gaagattctg aataa 405
<210> 8
<211> 336
<212> DNA
<213> Synechococcus PCC7002
<400> 8
atgaaaactt tacctaaaga aaagcgttac gaaactcttt cttacttgcc ccccctcagc 60
gaccagcaaa tcgctcgcca agtccagtac atgatggatc aaggctatat tcctggtatc 120
gagttcgaaa aagatccgac tcctgaactc caccactgga cactgtggaa gctgcccctt 180
ttcaacgcaa gctctgctca agaagtactc aacgaagtgc gtgagtgccg tagtgaatat 240
tctgactgct acatccgtgt tgttggtttc gacaacatca agcagtgcca aaccgttagc 300
ttcatcgttt acaagcccaa ccaaacccgt tactaa 336
<210> 9
<211> 291
<212> DNA
<213> Cupriavidus necator H16
<400> 9
atgaatctgc gtcctttgca cgaccgcgtg atcgtgaagc gtctggacaa cgaaaccaag 60
accgcgtccg gtatcgtgat tcccgacaac gctgccgaga agcccgatca aggcgaagtg 120
ctggcaatcg gtcctggcaa gaaggatgac aagggcaaca acatcgccct cgacgtcaag 180
gtcggtgacc gcgtgctgtt cggcaagtac gccggccagg ccgtgaaggt ggaaggccag 240
gaactgctgg tcatgcgcga agaagacatc atggccgtgg tgaacaagta a 291
<210> 10
<211> 1644
<212> DNA
<213> Cupriavidus necator H16
<400> 10
atggcagcta aagacgtagt gttcggcgac gccgcacgtg ccaagatggt cgaaggcgtg 60
aacatcctcg ccaacgcagt caaggtgacc ctgggcccga agggccgcaa cgtggtgctg 120
gagcgcagct tcggcggccc gaccgtgacc aaggacggcg tgtccgtggc caaggaaatc 180
gagctgaagg acaagctgca gaacatgggc gcccagatgg tcaaggaagt ggcttccaag 240
accagcgaca acgccggtga cggtaccacc accgctaccg tgctggccca gtcgatcgtg 300
cgcgaaggca tgaagttcgt tgccgccggc atgaacccga tggacctgaa gcgcggcatc 360
gacaaggctg ttgccgccgc cgtggaagag ctgaagaagg tcagcaagcc caccaccacc 420
agcaaggaaa tcgcccaggt tggcgcgatc tcggccaaca gcgacacctc catcggtgag 480
cgcatcgccg aagccatgga caaggtcggc aaggaaggcg tgatcacggt tgaagacggc 540
aagtcgctgg ccgacgagct ggaagtcgtg gaaggcatgc agttcgaccg cggctatctg 600
tcgccgtact tcatcaacaa cccggaaaag caggttgtcc agctggacaa cccgttcgtg 660
ctgctgttcg acaagaagat cagcaacatc cgcgacctgc tgccggtgct ggagcaagtg 720
gccaaggccg gccgcccgct gctgatcgtc gctgaagacg tcgagggcga agccctggcg 780
accctagtgg tcaacaacat ccgtggcatc ctgaagaccg ccgccgtcaa ggccccgggc 840
ttcggcgacc gccgcaaggc catgctggaa gacatcgcca tcctgaccgg cggcaccgtc 900
atcgctgaag aaatcggcct gacgctggaa aaggctggcc tgaacgacct gggccaggcc 960
aagcgcatcg agatcggcaa ggaaaacacc atcatcatcg acggcgccgg cgacgcagct 1020
gcgatcgaag gccgcgtcaa gcaaatccgc gcccagatcg aagaagcgac ctcggactac 1080
gaccgtgaga agctgcaaga gcgcgtggcc aagctggccg gcggtgttgc cgtgatcaag 1140
gttggcgctg ccaccgaagt cgaaatgaag gaaaagaagg cccgcgtgga agacgccctg 1200
cacgccaccc gcgctgcggt ggaagaaggc atcgtccccg gcggtggtgt ggccctgctg 1260
cgtgcccgcg ctgcgatctc ggcactgacc ggcgaaaacg ccgaccagaa cgccggtatc 1320
aagatcgtgc tgcgcgccat ggaagagccg ctgcgccaga tcgtgctgaa cgccggtgaa 1380
gaagcttcgg tggtcgttgc caaggttatc gaaggcaagg gcaactacgg ctacaacgcc 1440
gcttcgggcg agtacggcga cctggtggaa atgggcgtgc tggacccgac caaggtcacc 1500
cgcaccgcac tgcagaacgc cgcttcggtg gcttcgctga tgctgaccac cgactgcgca 1560
gttgccgaat cgccgaagga agaatcggct ccggcaatgc cgggcggcat gggcggcatg 1620
ggcggcatgg aaggcatgat gtaa 1644
<210> 11
<211> 6314
<212> DNA
<213> Artificial Sequence
<220>
<223> 重组质粒序列
<400> 11
ctttcgtttt atctgttgtt tgtcggtgaa cgctctctac tagagtcaca ctggctcacc 60
ttcgggtggg cctttctgcg tttataccta gggcgttcgg ctgcggctgg cgctgggcct 120
gtttctggcg ctggacttcc cgctgttccg tcagcagctt ttcgcccacg gccttgatga 180
tcgcggcggc cttggcctgc atatcccgat tcaacggccc cagggcgtcc agaacgggct 240
tcaggcgctc ccgaagatct cgggccgtct cttgggcttg atcggccttc ttgcgcatct 300
cacgcgctcc tgcggcggcc tgtagggcag gctcataccc ctgccgaacc gcttttgtca 360
gccggtcggc cacggcttcc ggcgtctcaa cgcgctttga gattcccagc ttttcggcca 420
atccctgcgg tgcataggcg cgtggctcga ccgcttgcgg gctgatggtg acgtggccca 480
ctggtggccg ctccagggcc tcgtagaacg cctgaatgcg cgtgtgacgt gccttgctgc 540
cctcgatgcc ccgttgcagc cctagatcgg ccacagcggc cgcaaacgtg gtctggtcgc 600
gggtcatctg cgctttgttg ccgatgaact ccttggccga cagcctgccg tcctgcgtca 660
gcggcaccac gaacgcggtc atgtgcgggc tggtttcgtc acggtggatg ctggccgtca 720
cgatgcgatc cgccccgtac ttgtccgcca gccacttgtg cgccttctcg aagaacgccg 780
cctgctgttc ttggctggcc gacttccacc attccgggct ggccgtcatg acgtactcga 840
ccgccaacac agcgtccttg cgccgcttct ctggcagcaa ctcgcgcagt cggcccatcg 900
cttcatcggt gctgctggcc gcccagtgct cgttctctgg cgtcctgctg gcgtcagcgt 960
tgggcgtctc gcgctcgcgg taggcgtgct tgagactggc cgccacgttg cccattttcg 1020
ccagcttctt gcatcgcatg atcgcgtatg ccgccatgcc tgcccctccc ttttggtgtc 1080
caaccggctc gacgggggca gcgcaaggcg gtgcctccgg cgggccactc aatgcttgag 1140
tatactcact agactttgct tcgcaaagtc gtgaccgcct acggcggctg cggcgcccta 1200
cgggcttgct ctccgggctt cgccctgcgc ggtcgctgcg ctcccttgcc agcccgtgga 1260
tatgtggacg atggccgcga gcggccaccg gctggctcgc ttcgctcggc ccgtggacaa 1320
ccctgctgga caagctgatg gacaggctgc gcctgcccac gagcttgacc acagggattg 1380
cccaccggct acccagcctt cgaccacata cccaccggct ccaactgcgc ggcctgcggc 1440
cttgccccat caattttttt aattttctct ggggaaaagc ctccggcctg cggcctgcgc 1500
gcttcgcttg ccggttggac accaagtgga aggcgggtca aggctcgcgc agcgaccgcg 1560
cagcggcttg gccttgacgc gcctggaacg acccaagcct atgcgagtgg gggcagtcga 1620
aggcgaagcc cgcccgcctg ccccccgagc ctcacggcgg cgagtgcggg ggttccaagg 1680
gggcagcgcc accttgggca aggccgaagg ccgcgcagtc gatcaacaag ccccggaggg 1740
gccacttttt gccggagggg gagccgcgcc gaaggcgtgg gggaaccccg caggggtgcc 1800
cttctttggg caccaaagaa ctagatatag ggcgaaatgc gaaagactta aaaatcaaca 1860
acttaaaaaa ggggggtacg caacagctca ttgcggcacc ccccgcaata gctcattgcg 1920
taggttaaag aaaatctgta attgactgcc acttttacgc aacgcataat tgttgtcgcg 1980
ctgccgaaaa gttgcagctg attgcgcatg gtgccgcaac cgtgcggcac cctaccgcat 2040
ggagataagc atggccacgc agtccagaga aatcggcatt caagccaaga acaagcccgg 2100
tcactgggtg caaacggaac gcaaagcgca tgaggcgtgg gccgggctta ttgcgaggaa 2160
acccacggcg gcaatgctgc tgcatcacct cgtggcgcag atgggccacc agaacgccgt 2220
ggtggtcagc cagaagacac tttccaagct catcggacgt tctttgcgga cggtccaata 2280
cgcagtcaag gacttggtgg ccgagcgctg gatctccgtc gtgaagctca acggccccgg 2340
caccgtgtcg gcctacgtgg tcaatgaccg cgtggcgtgg ggccagcccc gcgaccagtt 2400
gcgcctgtcg gtgttcagtg ccgccgtggt ggttgatcac gacgaccagg acgaatcgct 2460
gttggggcat ggcgacctgc gccgcatccc gaccctgtat ccgggcgagc agcaactacc 2520
gaccggcccc ggcgaggagc cgcccagcca gcccggcatt ccgggcatgg aaccagacct 2580
gccagccttg accgaaacgg aggaatggga acggcgcggg cagcagcgcc tgccgatgcc 2640
cgatgagccg tgttttctgg acgatggcga gccgttggag ccgccgacac gggtcacgct 2700
gccgcgccgg tagcacttgg gttgcgcagc aacccgtaag tgcgctgttc cagactatcg 2760
gctgtagccg cctcgccgcc ctataccttg tctgcctccc cgcgttgcgt cgcggtgcat 2820
ggagccgggc cacctcgacc tgaatggaag cttggattct caccaataaa aaacgcccgg 2880
cggcaaccga gcgttctgaa caaatccaga tggagttctg aggtcattac tggatctatc 2940
aacaggagtc caagcgagct ctcgaacccc agagtcccgc cattattgca attaataaac 3000
aactaacgga caattctacc taacacagga tgaggatcgt ttcgcatgat tgaacaagat 3060
ggattgcacg caggttctcc ggccgcttgg gtggagaggc tattcggcta tgactgggca 3120
caacagacaa tcggctgctc tgatgccgcc gtgttccggc tgtcagcgca ggggcgcccg 3180
gttctttttg tcaagaccga cctgtccggt gccctgaatg aactgcagga cgaggcagcg 3240
cggctatcgt ggctggccac gacgggcgtt ccttgcgcag ctgtgctcga cgttgtcact 3300
gaagcgggaa gggactggct gctattgggc gaagtgccgg ggcaggatct cctgtcatct 3360
caccttgctc ctgccgagaa agtatccatc atggctgatg caatgcggcg gctgcatacg 3420
cttgatccgg ctacctgccc attcgaccac caagcgaaac atcgcatcga gcgagcacgt 3480
actcggatgg aagccggtct tgtcgatcag gatgatctgg acgaagagca tcaggggctc 3540
gcgccagccg aactgttcgc caggctcaag gcgcgcatgc ccgacggcga ggatctcgtc 3600
gtgacccatg gcgatgcctg cttgccgaat atcatggtgg aaaatggccg cttttctgga 3660
ttcatcgact gtggccggct gggtgtggcg gaccgctatc aggacatagc gttggctacc 3720
cgtgatattg ctgaagagct tggcggcgaa tgggctgacc gcttcctcgt gctttacggt 3780
atcgccgctc ccgattcgca gcgcatcgcc ttctatcgcc ttcttgacga gttcttctga 3840
ttgacggcta gctcagtcct aggtacagtg ctagctttaa gaaggagata tacatatggt 3900
tcagaccaaa tctgctgggt ttaatgccgg tgtacaggac taccgcctga cttactacac 3960
ccccgattac accccgaaag ataccgactt actcgcttgt ttccggatga ctccccaacc 4020
tggagtcccc cccgaagaat gtgctgcggc tgttgcggct gaatcttcta ccggtacttg 4080
gaccactgta tggaccgatg gtttaactga cctcgaccgc tacaagggtc gttgctacaa 4140
tgttgaaccc gttcccggtg aagacaacca atatttctgt ttcgttgctt accccctcga 4200
tctgtttgaa gaaggttctg taaccaacgt tttgacttcc ttggttggta acgtattcgg 4260
ttttaaagcg ctgcgtgccc tgcgcctcga agatatccgc ttccccgttg cgttaatcaa 4320
aacttaccaa gggcctcccc acgggatcac tgtagagcgt gacctcctca acaagtatgg 4380
tcgtcctctc ctcggttgta cgattaagcc gaagctcggt ctgtctgcga agaactacgg 4440
tcgtgcggtt tatgaatgtc tccgtggtgg tcttgacttc accaaagatg acgaaaacat 4500
caactctcag cctttcatgc gttggcgcga tcgcttcctg ttcgttcaag aagctatcga 4560
aaaatcccaa gctgaaacca acgaagttaa gggtcactac cttaacgtca ccgctggcac 4620
ttgcgaagaa atgctcaagc gggctgaatt cgctaaggaa atcggcactc ccatcatcat 4680
gcacgacttc ttaactggtg gtttcactgc gaatactacc cttgcgaagt ggtgtcgtga 4740
taacggcgtt ctgctccaca tccaccgggc aatgcacgcg gtaatcgacc gtcagaagaa 4800
ccacggtatt cacttccgcg ttctcgctaa gtgtctccgc ctctctggtg gtgaccacct 4860
ccactccggt acggttgttg gtaagctcga aggcgatcgc gccgccaccc tcggtttcgt 4920
agacctgatg cgtgaagact acgttgaaga agatcgttct cgcggtgtat tcttcaccca 4980
agactacgct tctctccccg gcaccatgcc tgtggcttcc ggtggtatcc acgtatggca 5040
catgcctgcc ctcgttgaaa tcttcggcga cgattcctgc ctccagtttg gtggtggtac 5100
cctcggtcac ccctggggta acgcacctgg tgcaactgca aaccgtgttg ctctggaagc 5160
ttgtgttcaa gctcgtaacg aaggtcgcag cctggcccgt gaaggtaatg atgtcctccg 5220
tgaagcaggt aagtggtcgc ctgaattggc agccgccctc gacctgtgga aggaaatcaa 5280
gttcgaattc gataccgttg acactctcta atttaagaag gagatataca tatggagttt 5340
aaaaaagttg cgaaggaaac ggccatcact ttgcaaagct atttgaccta ccaagcggtg 5400
cgtctaatta gtcagcagct tagtgaaacc aatcctggac aggcgatttg gctaggagag 5460
ttctctaaac gtcatccaat tcaggaaagt gatctttacc tcgaagcgat gatgctagaa 5520
aacaaagagc tcgtcctcag aatcctgacg gtgcgagaaa accttgcgga aggagttctg 5580
gagtttttgc cagaaatggt cctcagccaa atcaagcagt ccaatggaaa ccatcgccgt 5640
tctttattag agcgtttaac tcaagttgat tcttcatcaa ctgatcagac tgaacctaac 5700
cctggtgagt ctgatacttc agaagattct gaataaactt tgatccgata aagaggacat 5760
aaatcaatga aaactttacc taaagaaaag cgttacgaaa ctctttctta cttgcccccc 5820
ctcagcgacc agcaaatcgc tcgccaagtc cagtacatga tggatcaagg ctatattcct 5880
ggtatcgagt tcgaaaaaga tccgactcct gaactccacc actggacact gtggaagctg 5940
ccccttttca acgcaagctc tgctcaagaa gtactcaacg aagtgcgtga gtgccgtagt 6000
gaatattctg actgctacat ccgtgttgtt ggtttcgaca acatcaagca gtgccaaacc 6060
gttagcttca tcgtttacaa gcccaaccaa acccgttact aacttaagga tccaaactcg 6120
agttgacggc tagctcagtc ctaggtacag tgctagcttt aagaaggaga tatacatatg 6180
gcgagaactc actttgtatc taggagtccg tttcatcgcc gaccgactgc ccttattgca 6240
tcaacgcgga tccaaactcg agtaaggatc tccaggcatc aaataaaacg aaaggctcag 6300
tcgaaagact gggc 6314
<210> 12
<211> 8295
<212> DNA
<213> Artificial Sequence
<220>
<223> 重组质粒序列
<400> 12
ctttcgtttt atctgttgtt tgtcggtgaa cgctctctac tagagtcaca ctggctcacc 60
ttcgggtggg cctttctgcg tttataccta gggcgttcgg ctgcggctgg cgctgggcct 120
gtttctggcg ctggacttcc cgctgttccg tcagcagctt ttcgcccacg gccttgatga 180
tcgcggcggc cttggcctgc atatcccgat tcaacggccc cagggcgtcc agaacgggct 240
tcaggcgctc ccgaagatct cgggccgtct cttgggcttg atcggccttc ttgcgcatct 300
cacgcgctcc tgcggcggcc tgtagggcag gctcataccc ctgccgaacc gcttttgtca 360
gccggtcggc cacggcttcc ggcgtctcaa cgcgctttga gattcccagc ttttcggcca 420
atccctgcgg tgcataggcg cgtggctcga ccgcttgcgg gctgatggtg acgtggccca 480
ctggtggccg ctccagggcc tcgtagaacg cctgaatgcg cgtgtgacgt gccttgctgc 540
cctcgatgcc ccgttgcagc cctagatcgg ccacagcggc cgcaaacgtg gtctggtcgc 600
gggtcatctg cgctttgttg ccgatgaact ccttggccga cagcctgccg tcctgcgtca 660
gcggcaccac gaacgcggtc atgtgcgggc tggtttcgtc acggtggatg ctggccgtca 720
cgatgcgatc cgccccgtac ttgtccgcca gccacttgtg cgccttctcg aagaacgccg 780
cctgctgttc ttggctggcc gacttccacc attccgggct ggccgtcatg acgtactcga 840
ccgccaacac agcgtccttg cgccgcttct ctggcagcaa ctcgcgcagt cggcccatcg 900
cttcatcggt gctgctggcc gcccagtgct cgttctctgg cgtcctgctg gcgtcagcgt 960
tgggcgtctc gcgctcgcgg taggcgtgct tgagactggc cgccacgttg cccattttcg 1020
ccagcttctt gcatcgcatg atcgcgtatg ccgccatgcc tgcccctccc ttttggtgtc 1080
caaccggctc gacgggggca gcgcaaggcg gtgcctccgg cgggccactc aatgcttgag 1140
tatactcact agactttgct tcgcaaagtc gtgaccgcct acggcggctg cggcgcccta 1200
cgggcttgct ctccgggctt cgccctgcgc ggtcgctgcg ctcccttgcc agcccgtgga 1260
tatgtggacg atggccgcga gcggccaccg gctggctcgc ttcgctcggc ccgtggacaa 1320
ccctgctgga caagctgatg gacaggctgc gcctgcccac gagcttgacc acagggattg 1380
cccaccggct acccagcctt cgaccacata cccaccggct ccaactgcgc ggcctgcggc 1440
cttgccccat caattttttt aattttctct ggggaaaagc ctccggcctg cggcctgcgc 1500
gcttcgcttg ccggttggac accaagtgga aggcgggtca aggctcgcgc agcgaccgcg 1560
cagcggcttg gccttgacgc gcctggaacg acccaagcct atgcgagtgg gggcagtcga 1620
aggcgaagcc cgcccgcctg ccccccgagc ctcacggcgg cgagtgcggg ggttccaagg 1680
gggcagcgcc accttgggca aggccgaagg ccgcgcagtc gatcaacaag ccccggaggg 1740
gccacttttt gccggagggg gagccgcgcc gaaggcgtgg gggaaccccg caggggtgcc 1800
cttctttggg caccaaagaa ctagatatag ggcgaaatgc gaaagactta aaaatcaaca 1860
acttaaaaaa ggggggtacg caacagctca ttgcggcacc ccccgcaata gctcattgcg 1920
taggttaaag aaaatctgta attgactgcc acttttacgc aacgcataat tgttgtcgcg 1980
ctgccgaaaa gttgcagctg attgcgcatg gtgccgcaac cgtgcggcac cctaccgcat 2040
ggagataagc atggccacgc agtccagaga aatcggcatt caagccaaga acaagcccgg 2100
tcactgggtg caaacggaac gcaaagcgca tgaggcgtgg gccgggctta ttgcgaggaa 2160
acccacggcg gcaatgctgc tgcatcacct cgtggcgcag atgggccacc agaacgccgt 2220
ggtggtcagc cagaagacac tttccaagct catcggacgt tctttgcgga cggtccaata 2280
cgcagtcaag gacttggtgg ccgagcgctg gatctccgtc gtgaagctca acggccccgg 2340
caccgtgtcg gcctacgtgg tcaatgaccg cgtggcgtgg ggccagcccc gcgaccagtt 2400
gcgcctgtcg gtgttcagtg ccgccgtggt ggttgatcac gacgaccagg acgaatcgct 2460
gttggggcat ggcgacctgc gccgcatccc gaccctgtat ccgggcgagc agcaactacc 2520
gaccggcccc ggcgaggagc cgcccagcca gcccggcatt ccgggcatgg aaccagacct 2580
gccagccttg accgaaacgg aggaatggga acggcgcggg cagcagcgcc tgccgatgcc 2640
cgatgagccg tgttttctgg acgatggcga gccgttggag ccgccgacac gggtcacgct 2700
gccgcgccgg tagcacttgg gttgcgcagc aacccgtaag tgcgctgttc cagactatcg 2760
gctgtagccg cctcgccgcc ctataccttg tctgcctccc cgcgttgcgt cgcggtgcat 2820
ggagccgggc cacctcgacc tgaatggaag cttggattct caccaataaa aaacgcccgg 2880
cggcaaccga gcgttctgaa caaatccaga tggagttctg aggtcattac tggatctatc 2940
aacaggagtc caagcgagct ctcgaacccc agagtcccgc cattattgca attaataaac 3000
aactaacgga caattctacc taacacagga tgaggatcgt ttcgcatgat tgaacaagat 3060
ggattgcacg caggttctcc ggccgcttgg gtggagaggc tattcggcta tgactgggca 3120
caacagacaa tcggctgctc tgatgccgcc gtgttccggc tgtcagcgca ggggcgcccg 3180
gttctttttg tcaagaccga cctgtccggt gccctgaatg aactgcagga cgaggcagcg 3240
cggctatcgt ggctggccac gacgggcgtt ccttgcgcag ctgtgctcga cgttgtcact 3300
gaagcgggaa gggactggct gctattgggc gaagtgccgg ggcaggatct cctgtcatct 3360
caccttgctc ctgccgagaa agtatccatc atggctgatg caatgcggcg gctgcatacg 3420
cttgatccgg ctacctgccc attcgaccac caagcgaaac atcgcatcga gcgagcacgt 3480
actcggatgg aagccggtct tgtcgatcag gatgatctgg acgaagagca tcaggggctc 3540
gcgccagccg aactgttcgc caggctcaag gcgcgcatgc ccgacggcga ggatctcgtc 3600
gtgacccatg gcgatgcctg cttgccgaat atcatggtgg aaaatggccg cttttctgga 3660
ttcatcgact gtggccggct gggtgtggcg gaccgctatc aggacatagc gttggctacc 3720
cgtgatattg ctgaagagct tggcggcgaa tgggctgacc gcttcctcgt gctttacggt 3780
atcgccgctc ccgattcgca gcgcatcgcc ttctatcgcc ttcttgacga gttcttctga 3840
ttgacggcta gctcagtcct aggtacagtg ctagctttaa gaaggagata tacatatggt 3900
tcagaccaaa tctgctgggt ttaatgccgg tgtacaggac taccgcctga cttactacac 3960
ccccgattac accccgaaag ataccgactt actcgcttgt ttccggatga ctccccaacc 4020
tggagtcccc cccgaagaat gtgctgcggc tgttgcggct gaatcttcta ccggtacttg 4080
gaccactgta tggaccgatg gtttaactga cctcgaccgc tacaagggtc gttgctacaa 4140
tgttgaaccc gttcccggtg aagacaacca atatttctgt ttcgttgctt accccctcga 4200
tctgtttgaa gaaggttctg taaccaacgt tttgacttcc ttggttggta acgtattcgg 4260
ttttaaagcg ctgcgtgccc tgcgcctcga agatatccgc ttccccgttg cgttaatcaa 4320
aacttaccaa gggcctcccc acgggatcac tgtagagcgt gacctcctca acaagtatgg 4380
tcgtcctctc ctcggttgta cgattaagcc gaagctcggt ctgtctgcga agaactacgg 4440
tcgtgcggtt tatgaatgtc tccgtggtgg tcttgacttc accaaagatg acgaaaacat 4500
caactctcag cctttcatgc gttggcgcga tcgcttcctg ttcgttcaag aagctatcga 4560
aaaatcccaa gctgaaacca acgaagttaa gggtcactac cttaacgtca ccgctggcac 4620
ttgcgaagaa atgctcaagc gggctgaatt cgctaaggaa atcggcactc ccatcatcat 4680
gcacgacttc ttaactggtg gtttcactgc gaatactacc cttgcgaagt ggtgtcgtga 4740
taacggcgtt ctgctccaca tccaccgggc aatgcacgcg gtaatcgacc gtcagaagaa 4800
ccacggtatt cacttccgcg ttctcgctaa gtgtctccgc ctctctggtg gtgaccacct 4860
ccactccggt acggttgttg gtaagctcga aggcgatcgc gccgccaccc tcggtttcgt 4920
agacctgatg cgtgaagact acgttgaaga agatcgttct cgcggtgtat tcttcaccca 4980
agactacgct tctctccccg gcaccatgcc tgtggcttcc ggtggtatcc acgtatggca 5040
catgcctgcc ctcgttgaaa tcttcggcga cgattcctgc ctccagtttg gtggtggtac 5100
cctcggtcac ccctggggta acgcacctgg tgcaactgca aaccgtgttg ctctggaagc 5160
ttgtgttcaa gctcgtaacg aaggtcgcag cctggcccgt gaaggtaatg atgtcctccg 5220
tgaagcaggt aagtggtcgc ctgaattggc agccgccctc gacctgtgga aggaaatcaa 5280
gttcgaattc gataccgttg acactctcta atttaagaag gagatataca tatggagttt 5340
aaaaaagttg cgaaggaaac ggccatcact ttgcaaagct atttgaccta ccaagcggtg 5400
cgtctaatta gtcagcagct tagtgaaacc aatcctggac aggcgatttg gctaggagag 5460
ttctctaaac gtcatccaat tcaggaaagt gatctttacc tcgaagcgat gatgctagaa 5520
aacaaagagc tcgtcctcag aatcctgacg gtgcgagaaa accttgcgga aggagttctg 5580
gagtttttgc cagaaatggt cctcagccaa atcaagcagt ccaatggaaa ccatcgccgt 5640
tctttattag agcgtttaac tcaagttgat tcttcatcaa ctgatcagac tgaacctaac 5700
cctggtgagt ctgatacttc agaagattct gaataaactt tgatccgata aagaggacat 5760
aaatcaatga aaactttacc taaagaaaag cgttacgaaa ctctttctta cttgcccccc 5820
ctcagcgacc agcaaatcgc tcgccaagtc cagtacatga tggatcaagg ctatattcct 5880
ggtatcgagt tcgaaaaaga tccgactcct gaactccacc actggacact gtggaagctg 5940
ccccttttca acgcaagctc tgctcaagaa gtactcaacg aagtgcgtga gtgccgtagt 6000
gaatattctg actgctacat ccgtgttgtt ggtttcgaca acatcaagca gtgccaaacc 6060
gttagcttca tcgtttacaa gcccaaccaa acccgttact aacttaagga tccaaactcg 6120
agttgacggc tagctcagtc ctaggtacag tgctagcttt aagaaggaga tatacatatg 6180
gcgagaactc actttgtatc taggagtccg tatgaatctg cgtcctttgc acgaccgcgt 6240
gatcgtgaag cgtctggaca acgaaaccaa gaccgcgtcc ggtatcgtga ttcccgacaa 6300
cgctgccgag aagcccgatc aaggcgaagt gctggcaatc ggtcctggca agaaggatga 6360
caagggcaac aacatcgccc tcgacgtcaa ggtcggtgac cgcgtgctgt tcggcaagta 6420
cgccggccag gccgtgaagg tggaaggcca ggaactgctg gtcatgcgcg aagaagacat 6480
catggccgtg gtgaacaagt aattcaccaa ctgaccgcca ccccgtacag atttcaggag 6540
attcaagaat ggcagctaaa gacgtagtgt tcggcgacgc cgcacgtgcc aagatggtcg 6600
aaggcgtgaa catcctcgcc aacgcagtca aggtgaccct gggcccgaag ggccgcaacg 6660
tggtgctgga gcgcagcttc ggcggcccga ccgtgaccaa ggacggcgtg tccgtggcca 6720
aggaaatcga gctgaaggac aagctgcaga acatgggcgc ccagatggtc aaggaagtgg 6780
cttccaagac cagcgacaac gccggtgacg gtaccaccac cgctaccgtg ctggcccagt 6840
cgatcgtgcg cgaaggcatg aagttcgttg ccgccggcat gaacccgatg gacctgaagc 6900
gcggcatcga caaggctgtt gccgccgccg tggaagagct gaagaaggtc agcaagccca 6960
ccaccaccag caaggaaatc gcccaggttg gcgcgatctc ggccaacagc gacacctcca 7020
tcggtgagcg catcgccgaa gccatggaca aggtcggcaa ggaaggcgtg atcacggttg 7080
aagacggcaa gtcgctggcc gacgagctgg aagtcgtgga aggcatgcag ttcgaccgcg 7140
gctatctgtc gccgtacttc atcaacaacc cggaaaagca ggttgtccag ctggacaacc 7200
cgttcgtgct gctgttcgac aagaagatca gcaacatccg cgacctgctg ccggtgctgg 7260
agcaagtggc caaggccggc cgcccgctgc tgatcgtcgc tgaagacgtc gagggcgaag 7320
ccctggcgac cctagtggtc aacaacatcc gtggcatcct gaagaccgcc gccgtcaagg 7380
ccccgggctt cggcgaccgc cgcaaggcca tgctggaaga catcgccatc ctgaccggcg 7440
gcaccgtcat cgctgaagaa atcggcctga cgctggaaaa ggctggcctg aacgacctgg 7500
gccaggccaa gcgcatcgag atcggcaagg aaaacaccat catcatcgac ggcgccggcg 7560
acgcagctgc gatcgaaggc cgcgtcaagc aaatccgcgc ccagatcgaa gaagcgacct 7620
cggactacga ccgtgagaag ctgcaagagc gcgtggccaa gctggccggc ggtgttgccg 7680
tgatcaaggt tggcgctgcc accgaagtcg aaatgaagga aaagaaggcc cgcgtggaag 7740
acgccctgca cgccacccgc gctgcggtgg aagaaggcat cgtccccggc ggtggtgtgg 7800
ccctgctgcg tgcccgcgct gcgatctcgg cactgaccgg cgaaaacgcc gaccagaacg 7860
ccggtatcaa gatcgtgctg cgcgccatgg aagagccgct gcgccagatc gtgctgaacg 7920
ccggtgaaga agcttcggtg gtcgttgcca aggttatcga aggcaagggc aactacggct 7980
acaacgccgc ttcgggcgag tacggcgacc tggtggaaat gggcgtgctg gacccgacca 8040
aggtcacccg caccgcactg cagaacgccg cttcggtggc ttcgctgatg ctgaccaccg 8100
actgcgcagt tgccgaatcg ccgaaggaag aatcggctcc ggcaatgccg ggcggcatgg 8160
gcggcatggg cggcatggaa ggcatgatgt aattcatcgc cgaccgactg cccttattgc 8220
atcaacgcgg atccaaactc gagtaaggat ctccaggcat caaataaaac gaaaggctca 8280
gtcgaaagac tgggc 8295
- 一种以乙醇为过渡碳源的双菌分步发酵产单细胞蛋白的方法
- 一种PC固定模台生产线构件养护控制系统及控制方法
- 微生物发酵生产单细胞蛋白和单细胞油脂的方法
- 从玉米发酵醪中同时生产单细胞蛋白和高蛋白饲料的方法