基于卷积神经网络的盾构机故障类型构建及故障诊断方法
文献发布时间:2023-06-19 18:58:26
技术领域
本发明涉及故障类型构建及故障诊断,更特别地说,是指一种基于卷积神经网络的盾构机故障类型构建及故障诊断方法。
背景技术
盾构隧道掘进机,简称盾构机(Shield Machine)。它是一种软土隧道掘进的专用工程机械。随着我国城市化建设的需要,各大城市陆续开展地铁建设工程。盾构法因有对周围环境影响小、掘进速度快、工程质量高、作业安全环保、适用范围广等优势,在地铁隧道建设中得到了广泛应用。由于盾构机系统(如图1所示)复杂,工作环境恶劣,在工程作业中积累了很多盾构机故障数据。盾构机故障数据一般以半结构化的盾构机故障记录文本的形式保存,然而以文本(text)为载体的盾构故障记录数据难以有效进行语料库(corpus)中存储和分析,这就迫切需要通过统计自然语言处理技术(Natural Language Processing,NLP)和文本数据分析技术实现盾构故障文本记录数据的结构化存储和智能分类。
目前针对盾构机故障记录文本的存储和分类主要依靠人工进行,人工在处理盾构机故障记录文本数据时存在以下三点不足:
(A)速度缓慢,人工操作进行盾构机故障记录文本数据的存储和分类远低于计算机处理速度,会耗费大量时间。
(B)准确度较低,盾构机故障记录文本数据按不同的标准可以分为多种类别,且受限于工作人员的知识水平,正确分类每一条故障文本数据是十分困难的,且长时间重复性工作会降低人的判断能力,进一步增加错误分类的风险。
(C)一致性较差,不同工作人员的认知与知识上的差异会使得盾构机故障记录数据存储与分类呈现多样性的结果,不利于后续的文本数据分析工作。
综上所述,目前人工处理盾构机故障记录文本数据尚无法完成高效率的结构化统一存储和分类。
发明内容
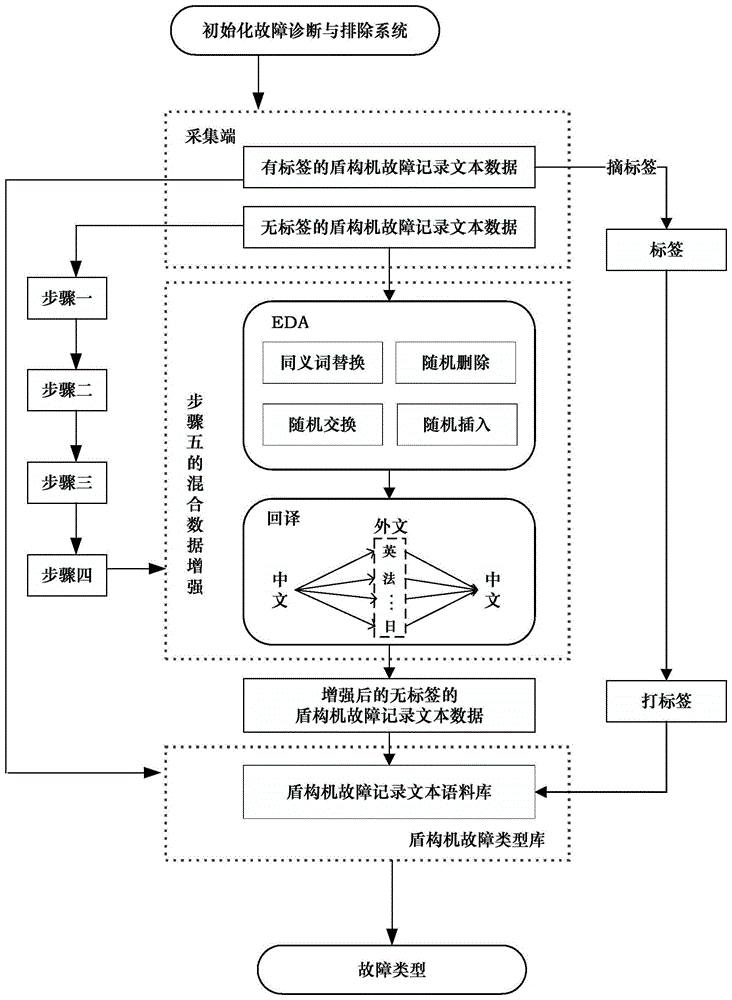
为了解决人工处理盾构机故障记录文本数据效率低,效果差的问题,另外人工处理的盾构机故障数据无法实现在语料库中进行自动学习的问题。本发明提出一种基于卷积神经网络的盾构机故障类型构建及故障诊断方法。本发明构建盾构机故障类型方法首先通过正则表达式(Regular Expression,RE)将故障文本按内容分割为固定条目,进行结构化故障类存储;其次,采用谱聚类(Spectral Clustering)算法对盾构机故障记录文本数据进行聚类,获得不同分类的故障数据簇;其三,对聚类产生的各类故障数据簇进行打标签;其四,针对各故障数据簇数据量不平衡的问题,采用简易数据增强(Easy DataAugmentation,EDA)与回译串行混合增强方法将各类标签数据增强到同一数量,得到训练数据集;其五,将故障训练数据集喂入卷积神经网络(Convolutional Neural Networks,CNN)进行故障文本分类模型的训练,得到盾构机故障分类模型FSM;最后利用盾构机故障分类模型FSM对盾构机故障记录文本数据进行智能分类并按类存储。
本发明的一种基于卷积神经网络的盾构机故障类型的构建方法,其包括的步骤有:
步骤一,形式化盾构机故障记录文本;
任意一个盾构机故障记录文本TEXT
故障内容,记为CONTENT;任意一个故障记录文本TEXT
步骤二,基于正则表达式的盾构机故障记录文本结构化存储;
将所述
所述
将故障-字段内容
步骤三,谱聚类分析盾构机故障记录文本数据;
通过调用scikit-learn的类库中的sklearn.cluster.SpectralClustering实现了基于Ncut的谱聚类;
输入层为盾构机故障记录文本数据集FTS={TEXT
基于Ncut的谱聚类需要调整的参数有:
谱聚类的维数为x;
全连接法的聚类为affinity;
核函数参数为gm;
谱聚类的输出结果中,采用集合的形式表达被划分为同一故障簇的盾构机故障记录文本数据集标记为{C},同一故障簇的划分集合,记为CTS
步骤四,打标盾构机故障;
盾构机故障记录文本数据包含多种标签,采用集合形式表达标签集为T_LABEL,且T_LABEL={LABEL
对聚类结果CTS
步骤五,基于EDA与回译的盾构机故障记录文本数据混合增强;
步骤501,将一个有标签的盾构机故障记录文本
步骤502,将TEXT
步骤503,将原标签LABEL
任意
任意
对CTS_LABEL
本发明构建盾构机故障类型的方法的优点在于:
①本发明方法通过正则表达式RE将盾构机故障记录文本分割为诸如项目名称、问题(故障)描述、原因分析等内容,便于结构化存储。
②本发明方法采用聚类算法对盾构机故障记录文本数据进行聚类,谱聚类算法在处理高维数据上比传统的K-means算法有更好的适应性,同时计算量也更小。
③本发明方法采用探索性数据分析EDA与回译混合数据增强方法可取得丰富度更高的数据,提高模型的准确度和鲁棒性。
④本发明方法生成的盾构机故障分类模型FSM可用于盾构机故障分类。
⑤本发明方法可扩展用于故障文本检索、盾构机故障诊断等用途。
附图说明
图1是盾构机系统的结构框图。
图2是本发明的基于卷积神经网络的盾构机故障类型构建的流程图。
图3是盾构机故障记录文本数据样本截图。
图3A是本发明经过正则表达式处理后的结构化盾构机故障记录文本数据。
图4A是本发明谱聚类DBI效果指标。
图4B是本发明谱聚类CH效果指标。
图4C是本发明谱聚类SC效果指标。
图5是本发明对盾构机故障记录文本数据经谱聚类后的可视化结果。
图6是本发明采用卷积神经网络进行智能分类故障簇的结构框架。
具体实施方式
下面将结合附图和实施例对本发明做进一步的详细说明。
盾构机故障记录文本,记为TEXT,多个故障记录文本TEXT采用集合形式表示为故障-记录文本数据集FTS,且FTS={TEXT
TEXT
TEXT
TEXT
TEXT
为了方便说明本发明,下角标i表示故障记录文本的标识号,下角标m表示故障记录文本的总数。所述TEXT
参见图3、图3A所示,本发明方法处理的对象是任意一个盾构机故障记录文本TEXT
参见图1、图2所示,本发明的一种基于卷积神经网络的盾构机故障类型的构建方法,包括有下列步骤:
步骤一,形式化盾构机故障记录文本;
在本发明中,参见图3、图3A所示,任意一个盾构机故障记录文本TEXT
在本发明中,故障内容,记为CONTENT;任意一个故障记录文本TEXT
步骤二,基于正则表达式的盾构机故障记录文本结构化存储;
参见图3、图3A所示的盾构故障记录文本样本数据,通过观察盾构机故障记录文本,发现每个文本都包含固定的字段内容。
在本发明中,将所述
所述
project表示项目名称,即故障记录所属的项目名称。
shield_num表示盾构机编号,即故障记录中的盾构机编号。
problem表示问题(故障)名称,即故障记录中的问题(故障)名称。
description表示简要描述,即故障记录中对故障的简要描述。
analysis表示原因分析,即故障记录中对故障的原因分析。
solution表示解决过程及措施,即对故障的解决过程及措施。
partner表示主要参与人员,即故障处理的主要参与人员。
summary表示小结,即故障记录的小结。
recorder表示记录人,即故障记录文本的记录人。
在本发明中,将故障-字段内容
在本发明中,结合故障内容集
通过制定的正则表达式C_regex处理故障记录文本TEXT
结构化表达后的盾构机故障记录文本数据如图3A所示。
在本发明中,对FTS={TEXT
步骤三,谱聚类分析盾构机故障记录文本数据;
在本发明中,通过调用scikit-learn的类库中的sklearn.cluster.SpectralClustering实现了基于Ncut的谱聚类。输入层为盾构机故障记录文本数据集FTS={TEXT
谱聚类的维数为x。
全连接法的聚类为affinity。
核函数参数为gm。
在本发明中,谱聚类的输出结果中,采用集合的形式表达被划分为同一故障簇的盾构机故障记录文本数据集标记为{C},同一故障簇的划分集合,记为CTS
{C
{C
{C
在本发明中,例如谱聚类采用全连接法建立故障聚类网络,affinity默认为高斯核函数rbf;由于FTS的维数未知,故设置x的取值范围为2~50,即x=[2,50];核函数参数的取值设为gm=[0.01,0.1,0.2,0.3,0.4,0.5];根据以上参数设置画出谱聚类的效果评价指标曲线,如图4A、图4B、图4C所示。
在本发明中,谱聚类效果评价指标有:
轮廓系数(Silhouette Coefficient),记为SC。SC结合了聚类的凝聚度和分离度,SC值越大,聚类效果越好。
Calinski Harabasz Score,记为CH。类内距离越小,类间距离越大,CH值越大,聚类效果越好。
戴维森堡丁指数,记为DBI。DBI越小意味着类内距离越小,同时类间距离越大。
根据图4A、图4B、图4C可知,当x=8,gm=0.5时,聚类效果最好,聚类结果如图5所示,每一个圆点代表一个盾构机故障记录文本,不同的颜色表示不同的故障类别。
在本发明中,谱聚类的输入数据为FTS={TEXT
{C
{C
{C
{C
{C
{C
{C
{C
步骤四,打标盾构机故障;
在本发明中,标签,记为LABEL。
盾构机故障记录文本数据包含多种标签,采用集合形式表达标签集为T_LABEL,且T_LABEL={LABEL
LABEL
LABEL
LABEL
LABEL
为了方便说明本发明,下角标k表示盾构机故障标签的标识号,下角标z表示盾构机故障标签的总数。所述LABEL
对聚类结果CTS
在本发明中,给盾构机故障记录文本数据打标的方式为,在每个TEXT
在本发明中,例如在聚类结果CTS
步骤五,基于EDA与回译的盾构机故障记录文本数据混合增强;
在本发明中,当盾构机故障记录文本数据的数量较少,且CTS_LABEL
本发明中的EDA是字词级的数据增强,通过改变文本中一些词语的方式来生成新的数据,包含四个子方法,即同义词替换(Synonym Replacement,SR)、随机删除(RandomDeletion,RD)、随机交换(Random Swap,RS)和随机插入(Random Insertion,RI)。
在本发明中,一条数据经EDA中的四个子方法分别处理后得到四条数据,以此实现数据增强。
EDA虽然可以保留大部分的文本信息,但存在新旧数据相似度过高的缺点,所以对经EDA增强后的数据用回译法再次增强,从而得到丰富度更高的数据。
回译是先将一种原语言的文本翻译成另一种目标语言,然后再将其翻译成原语言的数据增强方法。由于不同语言之间语法和表述习惯的不同,回译法可以保证文本语义不变,且具有足够的差异。在本发明中,利用百度翻译引擎,实现了从中文到外文(如英语、法语、日语、俄语、韩语等语种)的中外互译。
在本发明中,一条盾构机故障记录文本数据经EDA与回译混合增强后,可以获得20条增强数据。
在本发明中,盾构机故障记录文本数据增强流程如图2所示,具体步骤为:
步骤501,将一个有标签的盾构机故障记录文本
步骤502,将TEXT
TEXT
TEXT
TEXT
步骤503,将原标签LABEL
在本发明中,任意
在本发明中,任意
在本发明中,对CTS_LABEL
比如,对CTS_LABEL
基于CNN的盾构机故障模型进行的故障类型诊断
在本发明中,基于CNN的盾构机故障模型记为FSM模型。
在本发明中,基于CNN的盾构机故障文本智能分类的整体架构如图6所示,盾构机故障模型FSM的整个架构分为数据处理层、模型优化层和智能分类层。
在本发明中,框架的最上层是数据处理层。数据处理层通过Jieba分词工具实现故障文本数据分词,并通过word2vec转换为计算机可识别和计算的故障文本向量,实现故障文本数据结构化处理。
框架的中间层为模型优化层。在本发明中,针对数据处理层所得到的故障样本数据,模型优化层利用卷积神经网络CNN进行故障分类,并根据CNN参数特点进行调优。调优的参数主要有卷积核的大小、卷积核的数量、激活函数的选择、dropout参数选择,正则化的强度。
框架的最底层为智能分类层。在本发明中,智能分类层主要是根据模型优化层得到的智能分类模型,对待分类的盾构机故障记录文本进行自动分类。
诊断步骤一,输入盾构机故障记录文本,并进行形式化盾构机故障记录文本;
输入故障记录文本TEXT
诊断步骤二,基于正则表达式的盾构机故障记录文本结构化存储;
依据
诊断步骤三,谱聚类分析盾构机故障记录文本数据;
依据故障簇的划分集合CTS
为了详细说明,列举表1所示的盾构机故障文本内容。
表1CTS_LABEL
在本发明中,将AUG_LABEL
在本发明中,卷积神经网络的卷积核大小为3,4,5;卷积核数量为128;激活函数为relu,dropout参数为0.5;正则化强度为0.0。
测试结果表明,本发明方法应用改进的基于word2vec的CNN盾构机故障记录文本数据分类模型可以准确的对盾构机故障记录文本进行分类:精确率99.9%,F1值99.8%,召回率99.7%。并且本发明提出的EDA与回译串行混合增强方法解决了盾构机故障记录文本数据量小且各类数据不平衡的问题,提高了分类模型的鲁棒性和泛化能力。
另外,本发明提出的盾构机故障记录文本数据结构化表达方法,可将半结构化文本按照故障内容条目进行结构化存储,方便故障存储与查询。
- 基于卷积神经网络的故障诊断模型及跨部件故障诊断方法
- 基于卷积神经网络的故障诊断模型及跨部件故障诊断方法