基于改进SSD网络的针对小目标的目标检测方法
文献发布时间:2023-06-19 18:58:26
技术领域
本发明涉及目标检测的技术领域,尤其是指一种基于改进SSD网络的针对小目标的目标检测方法。
背景技术
小目标检测长期以来是计算机视觉中的一个难点和研究热点。小目标物体是在图片中所占据的像素点极少的物体,如在以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于32×32个像素点(中物体是指32*32-96*96,大物体是指大于96*96)。
小目标物体识别的困难之处在于原始图片中提供的语义信息太少,导致网络很难学习到小目标物体的特征信息。现在的目标检测算法大多采用特征融合的方法来提高小目标的检测精度。其主要原因是低层特征图语义信息相对稀缺但能准确地呈现目标位置,而高层特征图语义信息丰富但不准确,将两者结合可以很好地提高小目标物体的识别准确率。
尽管采取了很多措施,但是目前小目标物体的识别准确率还是较低。且目前大部分基于SSD的目标识别网络并未考虑到加入Attention模块,亦或者其结构还有可以改进的地方。如和超分辨率等其它图像处理方面领域结合不够等。
超分辨率复原是图像处理中的一个热门领域,其可以有效地从低分辨率图像中还原出高分辨率图像,这一特性可以很好地与小目标物体检测领域结合起来,有效解决小目标物体检测领域中的重点问题,即小目标物体在特征图中所占的分辨率过小,包含的语义信息过少的问题。
因此,提出一种结合超分辨率领域和Attention机制的目标检测方法具有现实意义。
发明内容
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于改进SSD网络的针对小目标的目标检测方法,引入了FTT模块、Attention模块、特征融合模块,有效地利用了多尺度的特征融合,有助于提高针对小目标物体的识别准确率。除此之外还将最后一个特征层conv11_2抛弃,更好地针对小目标物体识别。该方法创新地改进了SSD网络,使得改进后的SSD网络对小目标物体的识别精度更高。
为实现上述目的,本发明所提供的技术方案为:基于改进SSD网络的针对小目标的目标检测方法,该改进SSD网络是对原SSD网络进行了四部分改进,第一部分是构建了用于超分辨率还原的FTT模块并融合进SSD网络中,以提高特征层的分辨率大小;第二部分是构建了Attention模块来增加网络的特征提取能力;第三部分是使用了特征融合模块来增加网络多尺度信息融合能力,将经过Attention模块和FTT模块处理后的输出进行特征融合;第四部分是对原SSD网络结构的改进,具体是将SSD网络所用的backbone网络更改为ResNet-101,以更好地提取小目标特征,除此之外还将SSD网络所提取的最后一个特征层抛弃,这是因为最后一个特征层分辨率很小,不包含小目标物体信息,还会提供错误位置信息;
该目标检测方法的具体实施步骤如下:
1)收集图像进行物体标注,建立数据集,将数据集分为训练集、测试集、验证集,最后将数据集转换为XML格式;
2)构建SSD网络及其所需的Attetion模块、FTT模块和特征融合模块,修改SSD网络结构,将其backbone网络更改为ResNet-101,再将构建的Attetion模块、FTT模块和特征融合模块融入修改结构后的SSD网络,同时将SSD网络的最后一个特征层conv11_2抛弃,得到最终的SSD网络,即改进SSD网络;
3)使用训练集和验证集对改进SSD网络进行训练和验证,迭代进行至验证集的总损失达到最小的状态,得到经训练和验证后的最优网络;
4)将测试集中的图像送入步骤3)得到的最优网络中进行测试,并设置相应的分数阈值,得到高于分数阈值的检测目标,而低于分数阈值的目标将不显示。
进一步,在步骤1)中,使用工业摄像头采集数据,将采集到的数据分为训练集、测试集、验证集;然后通过在线工具或者离线工具进行标注,主要是设置预选框,将要检测的物体通过预选框包围起来,标注完成后将数据集输出为XML格式数据集。
进一步,在步骤2)中,将SSD网络的backbone网络更改为ResNet-101,ResNet-101由六个layer组成,分别为layer1、layer2、layer3、layer4、layer5、layer6;其中layer1为一个7×7、卷积核个数为64、stride=2的卷积层,layer1的输出经过一个3×3的maxpooling层后的输出,再经过剩下五个layer,得到最终的输出特征图;layer2、layer3、layer4、layer5、layer6都是由多个卷积层和残差结构组成,得到ResNer-101的输出后,与原SSD网络一样,添加额外的特征提取层Conv6、Conv7、Conv8、Conv9用于提取出不同尺度的特征。
进一步,在步骤2)中,需要构建用于对小特征层超分辨率复原的FTT模块和基于注意力机制的Attention模块,并将两个模块融合到SSD网络中,FTT模块和Attention模块的具体结构如下:
FTT模块的作用是对输入的特征进行超分辨率复原操作,得到更高分辨率的特征图,其有两个输入,第一个输入是帮助恢复细节部分的参考特征图P
在经过上述步骤,得到与P
得到Texture Extrator模块的输出后,将其与之前亚像素卷积后的另一个分支输出进行一个矩阵相加操作,形成一个残差结构,FTT模块总体公式如下:
Out
式中,Out
Attention模块的作用是利用注意力机制使得网络对物体的特征提取能力更有针对性,增强网络学习能力,其输入为需要进行Attention操作的特征图,conv4_3和fc7特征层的Attention结构与其它特征层不同,这是因为conv4_3和fc7特征层的分辨率高,所以注意力机制所需要的Attention系数矩阵通过这两个特征层形成,具体来说,conv4_3和fc7特征层的Attention模块结构如下:
conv4_3和fc7特征层的Attention模块接收了输入之后,首先经过一个残差块,然后分为两个分支,第一个分支由两个残差块组成,另一个分支则是先经过一个Hourglass结构,生成一个特征图的heatmap,然后经过多个BN层、Conv层以及Relu层,再通过一个sigmoid操作得到所需要的Attention系数矩阵,接着将得到的Attention系数矩阵与第一个分支的输出进行矩阵相乘操作,得到的输出再与第一个分支进行相加,形成一个残差结构,最后再经过一个残差块、一个L2 norm层以及一个Relu层得到最终输出,具体公式如下:
P
ATTmap=sig(2×δ(Hourglass(res(x)))) (3)
Out
式中,P
其余特征层的Attention模块相比于conv4_3和fc7特征层的Attention模块,少了生成Attention系数矩阵的步骤,具体结构如下:首先接收输入特征图,连续经过三个残差块处理,将得到的输出与Attention系数矩阵相乘,具体是与conv4_3特征层形成的Attention系数矩阵相乘,还是与fc7特征层形成的Attention系数矩阵相乘,取决于最终特征融合模块的输出维度和分辨率,相乘之后的操作与conv4_3和fc7特征层的Attention模块相同。
进一步,在步骤2)中,需要构建所用的特征融合模块,将上述步骤中构建的多个Attention模块的输出进行特征融合,加强模型的表达能力,特征融合模块的具体结构如下:
特征融合模块的输入是三个需要进行融合的特征图,由于之前步骤中构建的FTT模块包含了上采样的过程,所以特征融合模块接收到的三个特征图都具有相同的分辨率,将原始分辨率即上采样之前分辨率最大的特征图视为主特征图,其余两个特征图为次特征图,分别设计两个1×1卷积核,将次特征图的通道数转换为主特征图的一半,分辨率保持不变,这样能够使得主特征图所占的权重比次特征图高,最后将三个处理后的特征图进行拼接,得到最终输出。
进一步,在步骤2)中,需要将上述步骤中构建的模块添加进SSD网络中,同时将最后一个特征层conv11_2抛弃,得到最后的网络结构,具体步骤如下:
除了conv4_3、conv10_2之外的特征层都需要添加FTT模块,每个FTT模块的输入参考特征图P
进一步,在步骤3)中,将所制作数据集的训练集和验证集分批送进改进SSD网络中,训练集中的图像经过网络特征提取后,通过对应卷积层得到检测图像分类的概率值以及位置值,将二元交叉熵与SSD网络中初始的multibox_loss结合起来,计算loss值,根据训练过程中迭代的次数进行优化器调整网络参数,更新学习率,且每当特定次数的网络训练后用验证集对网络的训练效果进行验证,迭代进行至验证集的总损失达到最小的状态,最终得到经训练和验证后的最优网络。
本发明与现有技术相比,具有如下优点与有益效果:
1、设计并构建了基于超分辨率复原原理的FTT模块,有助于将低分辨率的特征图扩张成更高分辨率的特征图,有利于小目标物体检测。
2、设计并构建了基于注意力机制的Attention模块,有助于提高网络的特征提取能力。
3、设计并构建了特征融合模块,可以融合多尺度的特征信息,提高网络的检测性能。
4、修改了SSD网络的整体结构,包括更改了backbone网络和去除了最后一个特征层conv11_2,提高了网络检测速度以及检测精度。
5、本发明创新地改造了SSD网络,使得改进后的SSD网络对小目标物体的识别精度更高,具有实际推广价值与应用价值。
附图说明
图1为FTT模块的结构示意图。
图2为Attention模块的结构示意图。
图3为特征融合模块的结构示意图。
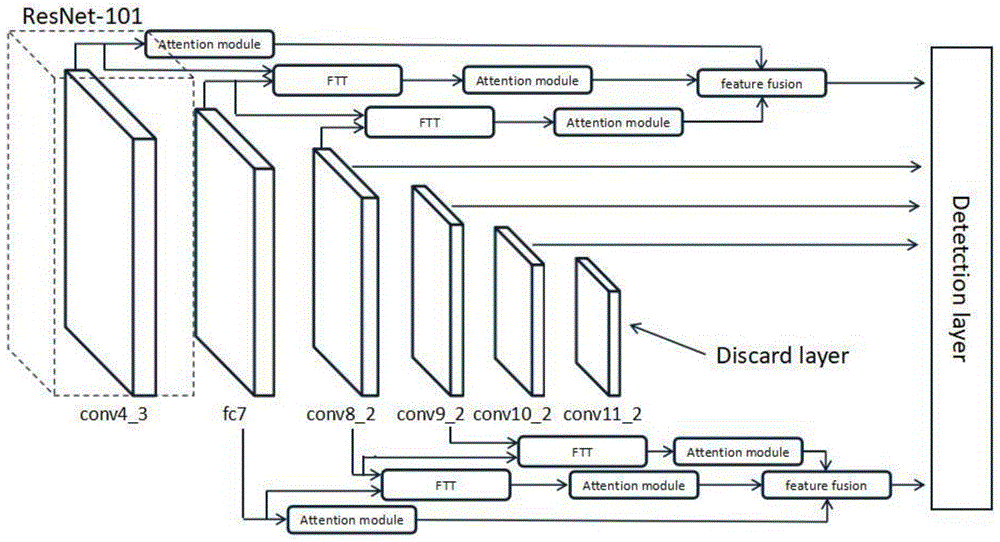
图4为改进SSD网络的结构示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
本实施例公开了一种基于改进SSD网络的针对小目标的目标检测方法,该改进SSD网络是对原SSD网络进行了四部分改进,第一部分是构建了用于超分辨率还原的FTT模块并融合进SSD网络中,以提高特征层的分辨率大小;第二部分是构建了Attention模块来增加网络的特征提取能力;第三部分是使用了特征融合模块来增加网络多尺度信息融合能力,将经过Attention模块和FTT模块处理后的输出进行特征融合;第四部分是对原SSD网络结构的改进,具体是将SSD网络所用的backbone网络更改为ResNet-101,以更好地提取小目标特征,除此之外还将SSD网络所提取的最后一个特征层抛弃,这是因为最后一个特征层分辨率过小,基本不包含小目标物体信息,还会提供错误位置信息。该方法的具体情况如下:
1)采集自己的数据集或是采用网络上的公开数据集,采集图像使用正常的工业摄像头,摄像头分辨率要求大于300×300,将数据集分为训练集、测试集、验证集,对数据集进行目标标注,即利用在线或离线工具将包含目标的区域用预选框框起来,导出数据集为XML格式。
2)构建原始SSD网络,原始SSD网络所用的backbone网络为VGG,经实验证明,VGG网络的特征提取能力不如ResNet,故将其backbone网络更改为ResNet-101,ResNet-101主要由六个layer组成,分别为layer1、layer2、layer3、layer4、layer5、layer6;其中layer1为一个7×7、卷积核个数为64、stride=2的卷积层,layer1的输出经过一个3×3的maxpooling层后的输出,再经过剩下五个layer,得到最终的输出特征图,layer2、layer3、layer4、layer5、layer6都是由多个卷积层和残差结构组成;
SSD网络还添加了几个额外的特征提取卷积层Conv6、Conv7、Conv8、Conv9,其结构都由两个卷积层组成,第一个卷积层为卷积核大小为1×1,第二个卷积层卷积核大小为3×3;
每个尺度特征图上预设的预选框数目为(4,6,6,6,4),预选框大小按照公式
如图1所示,FTT模块有两个输入,第一个输入是帮助恢复细节部分的参考特征图,其分辨率和目标特征图的分辨率相同,其作用是帮助恢复特征图中的细节纹理部分;
另一个输入是需要增大分辨率的低分辨率特征图,在输入后,先经过一个ContentExtrator模块进行粗略信息提取,Content Extrator模块是由多个Conv层、BN层以及Relu层堆叠而成,其可以提取超分辨率复原中所需的物体大概轮廓等信息,在经过ContentExtrator模块处理后,还需要进行一个亚像素卷积操作,将分辨率提高至和参考特征图相同;
在经过上述步骤,得到与参考特征图相同分辨率的输出后,将得到的输出分为两个分支,其中一个分支与参考特征图进行拼接,将拼接后的特征图输入进TextureExtrator模块中,进行特征图中细节纹理部分的特征提取,Texture Extrator模块也是由多个Conv层、BN层以及Relu层堆叠而成,其作用是提取超分辨率复原中所需的细节纹理等信息;
得到Texture Extrator模块的输出后,将其与之前亚像素卷积后的另一个分支输出进行一个矩阵相加操作,形成一个残差结构,FTT模块总体公式如下:
Out
式中,Out
Attention模块有两种结构,第一种是conv4_3和fc7特征层需要经过的Attention模块,第二种是其余特征层经过的Attention模块,第一种Attention模块需要构建生成自己特征层的Attention系数矩阵,即Attentionmap,其余特征层不需要生成自己的Attentionmap,而是在上采样后,直接采用之前conv4_3和fc7特征层生成的Attentionmap来进行Attention操作,这是因为除conv4_3和fc7特征层外的其余特征层分辨率都过小,导致其生成的Attentionmap上包含小目标物体的信息过少,并没有什么价值;
conv4_3和fc7特征层的Attention模块结构见图2所示,其输入为需要进行Attention处理的特征图,接收了输入之后,首先经过一个残差块,然后分为两个分支,第一个分支由两个残差块组成,另一个分支则是先经过一个Hourglass结构,生成一个特征图的heatmap,然后经过多个BN层、Conv层以及Relu层,再通过一个sigmoid操作得到所需要的Attention系数矩阵,接着将得到的Attention系数矩阵与第一个分支的输出进行矩阵相乘操作,得到的输出再与第一个分支进行相加,形成一个残差结构,最后再经过一个残差块、一个L2 norm层以及一个Relu层得到最终输出,具体公式如下:
P
ATTmap=sig(2×δ(Hourglass(res(x)))) (3)
Out
式中,P
其余特征层的Attention模块相比于conv4_3和fc7特征层的Attention模块,少了生成Attention系数矩阵的步骤,具体结构如下:首先接收输入特征图,连续经过三个残差块处理,将得到的输出与Attention系数矩阵相乘,具体是与conv4_3特征层形成的Attention系数矩阵相乘,还是与fc7特征层形成的Attention系数矩阵相乘,取决于最终输入哪个特征融合模块,相乘之后的操作与conv4_3和fc7特征层的Attention模块相同。
如图3所示,特征融合模块的输入是三个需要进行融合的特征图,由于之前步骤中构建的FTT模块包含了上采样的过程,所以特征融合模块接收到的三个特征图都具有相同的分辨率,将原始分辨率即上采样之前分辨率最大的特征图视为主特征图,其余两个特征图为次特征图,分别设计两个1×1卷积核,将次特征图的通道数转换为主特征图的一般,分辨率保持不变,这样可以使得主特征图所占的权重比次特征图高,最后将三个处理后的特征图进行拼接,得到最终输出。
如图4所示,构建特征融合模块后,需要将之前步骤中构建的所有模块添加进SSD网络中,在除了conv4_3以及conv10_2之外的所有特征层之后添加FTT模块,除了conv10_2之外的所有特征层都进行Attention处理,并将conv4_3、fc7以及conv8_2三个特征层的输出输入到第一个特征融合模块中,将fc7、conv8_2以及conv9_2三个特征层输入到第二个特征融合模块中,生成需要检测的两个输出,除此之外,将最后一个特征层con11_2抛弃,得到完整的网络结构。
3)将所制作数据集的训练集和验证集分批送进改进SSD网络中,训练集中的图像经过网络特征提取后,通过对应卷积层得到检测图像分类的概率值以及位置值,分别计算所有正标签框预测结果的回归loss、所有正标签预测结果的交叉熵loss、一定负标签的种类的预测结果的交叉熵loss,按照一定的比例进行相加,得到最终loss值,根据训练过程中迭代的次数进行优化器调整网络参数,更新学习率,且每当特定次数的网络训练后用验证集对网络的训练效果进行验证,迭代进行至验证集的总损失达到最小的状态,最终得到经训练和验证后的最优网络。
4)将测试集中的图像送入步骤3)得到的最优网络中进行测试,并设置相应的分数阈值,得到高于分数阈值的检测目标,而低于分数阈值的目标将不显示。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 基于多尺度特征自增强的改进SSD小目标检测方法
- 一种基于稠密特征金字塔的改进型SSD小目标检测方法