计算机渲染生成三维场景画面的混叠失真无参考评估方法
文献发布时间:2023-06-19 19:14:59
技术领域
本发明涉及一种计算机渲染生成三维场景画面的混叠失真无参考评估方法,属于图像质量评估技术领域。
背景技术
在虚拟现实(VR)应用中,需要用计算机实时地渲染生成三维场景画面,以便提供给人眼观看。三维场景画面的像素值可以看作是对三维场景视觉信号的采样值。对于连续信号采样,如果采样频率不足够高,会产生混叠失真,降低图像视觉质量。三维场景画面渲染生成速度对VR体验质量有重要影响。三维场景画面的分辨率越低(对应采样频率也越低),画面的渲染生成速度会越高。对VR应用而言,单从提高画面渲染生成速度的角度看,画面分辨率应该尽量低。然而,降低画面分辨率又可能会导致画面产生混叠失真,使得画面视觉质量降低。设计计算机渲染生成三维场景画面的混叠失真客观评估方法(即客观地评估不同混叠失真水平下的画面视觉质量),有助于客观地评估人眼视觉系统感知到的给定分辨率条件下的三维场景画面混叠失真严重程度,指导VR应用系统优化选取三维场景画面分辨率参数。
参见《Signal Processing:Image Communication》2018年61卷论文“Perceptualquality evaluation of synthetic pictures distorted by compression andtransmission”,图像质量评估分为全参考(FR)图像质量评估、部分参考(RR)图像质量评估和无参考(NR)图像质量评估等三类方法。全参考图像质量评估和部分参考图像质量评估都需要提前获得不同程度的无失真参考图像信息。无参考图像质量评估则无需参考图像信息,仅根据失真图像的自身特征来估计图像质量。论文“Perceptual quality evaluationof synthetic pictures distorted by compression and transmission”描述了根据无失真图像生成失真图像的方法;使用该论文介绍的“Interpolation”失真模拟技术(本发明称之为混叠失真模拟技术),可以根据无失真图像生成特定降采样因子(DownsamplingFactor)F对应的混叠失真图像。
《Proceedings of the ACM on Computer Graphics and InteractiveTechniques》2020年3卷2期的论文“FLIP:A Difference Evaluator for AlternatingImages”描述了一种针对计算机渲染生成三维场景画面图像的全参考差异评估方法,在此称之为FLIP评估模型,其可以预测出待评图像与无失真参考图像的视觉感知差异;FLIP评估模型用0~1之间的数描述像素感知差异的大小,1表示最大差异,0表示无差异。论文“FLIP:A Difference Evaluator for Alternating Images”叙述了基于加权中值(Weighted Median)的视觉感知差异图池化(Pooling)方法,可以获得用单个0~1之间的数表示的待评图像与无失真参考图像的视觉感知差异(本发明称之为单值视觉感知差异)的大小。值得注意的是,FLIP评估模型把人眼观察视场内像素角密度参数p(单位:每度的像素数目,Number of Pixel per Degree)作为一个控制参数。根据论文“FLIP:A DifferenceEvaluator for Alternating Images”的式(1)可计算像素角密度参数p的值。在论文“FLIP:A Difference Evaluator for Alternating Images”中,使用空间滤波来滤除在给定像素角密度参数p条件下人眼不能感知到的图像细节(参见该论文图1的“SpatialFiltering”),本发明称之为对图像的感知滤波处理。
在显示器屏幕上观看图像时,人眼观察视场内像素角密度参数p对图像视觉质量有重要影响。尽管现在已有不少无参考图像质量评估技术,但是都没有考虑像素角密度参数p的影响。本发明利用深度学习技术,从待评计算机渲染生成三维场景画面图像中提取特征,并把特征转换成质量分数。为了构建深度学习所需的训练集,本发明首先收集N
在深度学习中经常使用池化操作。广义均值池化是一种特殊池化操作。对于3D特征图E∈R
发明内容
本发明的目的在于,提供一种计算机渲染生成三维场景画面的混叠失真无参考评估方法,以便为评估不同像素角密度参数p条件下的混叠失真图像的视觉质量分数提供支持。
本方法的技术方案是这样实现的:
1)本方法第一部分构建训练集IMGS-T,具体步骤如下:
步骤Step101:收集N
步骤Step102:对于每张图像IMG-R,做如下操作:
步骤Step102-1:对于降采样因子F=3,4,…,f
步骤Step102-1-1:使用混叠失真模拟技术,根据图像IMG-R模拟生成降采样因子F对应的混叠失真图像IMG-A;
步骤Step102-1-2:对于i=1,2,…,p
步骤Step102-1-2-1:令像素角密度参数p等于P
步骤Step102-1-2-2:把混叠失真图像IMG-A与像素角密度参数p的组合作为一个训练样本IMGSAMPLE,添加到训练集IMGS-T中,同时把训练样本IMGSAMPLE对应的视觉质量分数标记为1-D
步骤Step102-1-2-3:针对正整数i的操作结束;
步骤Step102-1-3:针对降采样因子F的操作结束;
步骤Step102-2:针对图像IMG-R的操作结束。
2)本方法第二部分提供一种深度学习网络ANET,具体内容如下:
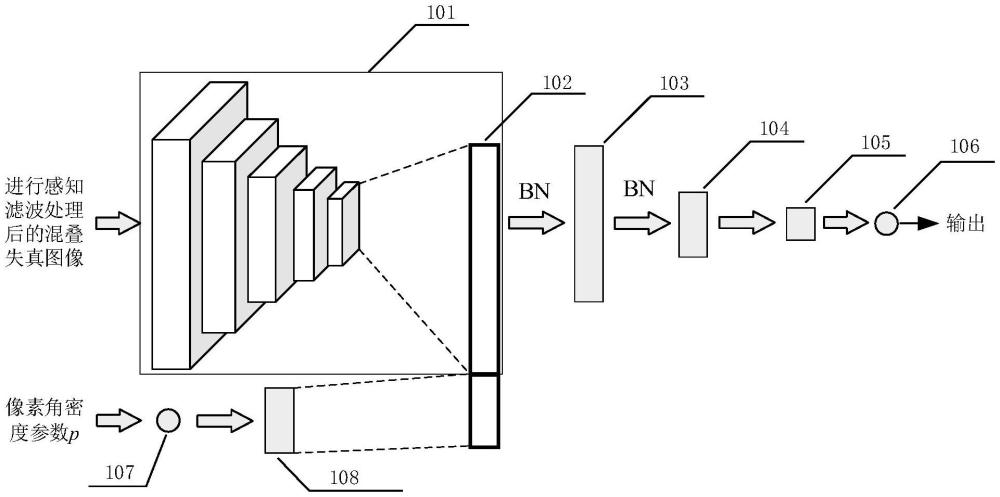
如图1所示,深度学习网络ANET包括一个特征提取模块(101),特征提取模块(101)把进行感知滤波处理后的混叠失真图像作为输入,并提取3D特征图,然后使用广义均值池化运算对3D特征图进行池化操作,得到一维特征矢量DF;单神经元结点输入层(107)把像素角密度参数p作为输入并不作任何处理直接输出给全连接层A(108),全连接层A(108)的输出为一维矢量;把一维特征矢量DF和全连接层A(108)的输出相拼接,得到一维特征矢量DFP(102);对一维特征矢量DFP(102)执行批量规范化运算处理后作为全连接层1(103)的输入,对全连接层1(103)的输出执行批量规范化运算处理后作为全连接层2(104)的输入,全连接层2(104)的输出作为全连接层3(105)的输入,全连接层3(105)的输出作为全连接层4(106)的输入,全连接层4(106)的输出经转换后就是质量分数;全连接层4(106)只有一个神经元结点,使用Tanh激活函数。
3)本方法第三部分利用本方法第一部分构建的训练集IMGS-T来训练本方法第二部分提供的深度学习网络ANET,使深度学习网络ANET具备输出能转换得到给定混叠失真图像在给定像素角密度参数p条件下的视觉质量分数的结果的能力,具体步骤如下:
步骤Step301:将深度学习网络ANET的权值优化算法设置为随机梯度下降法;
步骤Step302:利用训练集IMGS-T中的所有训练样本IMGSAMPLE,对深度学习网络ANET进行训练;对于每个训练样本IMGSAMPLE,在输入到深度学习网络ANET前,首先根据训练样本IMGSAMPLE对应的像素角密度参数p对训练样本IMGSAMPLE对应的混叠失真图像IMG-A进行感知滤波处理,然后再把训练样本IMGSAMPLE对应的进行感知滤波处理后的混叠失真图像IMG-AF和训练样本IMGSAMPLE对应的像素角密度参数p作为深度学习网络ANET的输入,把2S-1作为深度学习网络ANET的期望输出,利用深度学习算法来训练深度学习网络ANET,其中S表示训练样本IMGSAMPLE对应的视觉质量分数标记值。
4)本方法第四部分利用训练好的深度学习网络ANET来预测给定混叠失真图像在给定像素角密度参数p条件下的视觉质量分数,具体步骤如下:
根据给定的像素角密度参数p对给定的混叠失真图像进行感知滤波处理,得到进行感知滤波处理后的混叠失真图像IMG-AF,把进行感知滤波处理后的混叠失真图像IMG-AF和给定的像素角密度参数p作为深度学习网络ANET的输入,计算深度学习网络ANET的输出y
本发明的积极效果是:本发明的方法能够预测不同像素角密度参数p条件下的混叠失真图像的视觉质量分数。因此本发明的方法在针对不同观看条件的适应性方面相比于现有方法具有优越性。例如,同一张混叠失真图像显示在同一台显示器上,当人眼离显示器的距离发生变化时,人眼感知到的混叠失真程度就不一样。由于本发明的方法使用了像素角密度参数p,人眼离显示器的距离发生变化时,像素角密度参数p的值也会变化,因此本发明的方法可预测出不同人眼-显示器距离条件下的混叠失真图像视觉质量分数。
附图说明
图1为深度学习网络ANET的示意图。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本发明申请提供进一步的说明。除非另有指明,本发明申请使用的所有技术和科学术语具有与本发明申请所属技术领域的普通技术人员通常理解的相同含义。
本方法的技术方案是这样实现的:
1)本方法第一部分构建训练集IMGS-T,具体步骤如下:
步骤Step101:收集N
步骤Step102:对于每张图像IMG-R,做如下操作:
步骤Step102-1:对于降采样因子F=3,4,…,f
步骤Step102-1-1:使用混叠失真模拟技术,根据图像IMG-R模拟生成降采样因子F对应的混叠失真图像IMG-A;
步骤Step102-1-2:对于i=1,2,…,p
步骤Step102-1-2-1:令像素角密度参数p等于P
步骤Step102-1-2-2:把混叠失真图像IMG-A与像素角密度参数p的组合作为一个训练样本IMGSAMPLE,添加到训练集IMGS-T中,同时把训练样本IMGSAMPLE对应的视觉质量分数标记为1-D
步骤Step102-1-2-3:针对正整数i的操作结束;
步骤Step102-1-3:针对降采样因子F的操作结束;
步骤Step102-2:针对图像IMG-R的操作结束。
2)本方法第二部分提供一种深度学习网络ANET,具体内容如下:
如图1所示,深度学习网络ANET包括一个特征提取模块(101),特征提取模块(101)把进行感知滤波处理后的混叠失真图像作为输入,并提取3D特征图,然后使用广义均值池化运算对3D特征图进行池化操作,得到一维特征矢量DF;单神经元结点输入层(107)把像素角密度参数p作为输入并不作任何处理直接输出给全连接层A(108),全连接层A(108)的输出为一维矢量;把一维特征矢量DF和全连接层A(108)的输出相拼接,得到一维特征矢量DFP(102);对一维特征矢量DFP(102)执行批量规范化运算处理后作为全连接层1(103)的输入,对全连接层1(103)的输出执行批量规范化运算处理后作为全连接层2(104)的输入,全连接层2(104)的输出作为全连接层3(105)的输入,全连接层3(105)的输出作为全连接层4(106)的输入,全连接层4(106)的输出经转换后就是质量分数;全连接层4(106)只有一个神经元结点,使用Tanh激活函数。
3)本方法第三部分利用本方法第一部分构建的训练集IMGS-T来训练本方法第二部分提供的深度学习网络ANET,使深度学习网络ANET具备输出能转换得到给定混叠失真图像在给定像素角密度参数p条件下的视觉质量分数的结果的能力,具体步骤如下:
步骤Step301:将深度学习网络ANET的权值优化算法设置为随机梯度下降法;
步骤Step302:利用训练集IMGS-T中的所有训练样本IMGSAMPLE,对深度学习网络ANET进行训练;对于每个训练样本IMGSAMPLE,在输入到深度学习网络ANET前,首先根据训练样本IMGSAMPLE对应的像素角密度参数p对训练样本IMGSAMPLE对应的混叠失真图像IMG-A进行感知滤波处理,然后再把训练样本IMGSAMPLE对应的进行感知滤波处理后的混叠失真图像IMG-AF和训练样本IMGSAMPLE对应的像素角密度参数p作为深度学习网络ANET的输入,把2S-1作为深度学习网络ANET的期望输出,利用深度学习算法来训练深度学习网络ANET,其中S表示训练样本IMGSAMPLE对应的视觉质量分数标记值。
4)本方法第四部分利用训练好的深度学习网络ANET来预测给定混叠失真图像在给定像素角密度参数p条件下的视觉质量分数,具体步骤如下:
根据给定的像素角密度参数p对给定的混叠失真图像进行感知滤波处理,得到进行感知滤波处理后的混叠失真图像IMG-AF,把进行感知滤波处理后的混叠失真图像IMG-AF和给定的像素角密度参数p作为深度学习网络ANET的输入,计算深度学习网络ANET的输出y
在本实施例中,N
特征提取模块(101)用于从进行感知滤波处理后的混叠失真图像中提取3D特征图,并转化得到一维特征矢量DF。特征提取模块(101)用ResNet50卷积神经网络来提取3D特征图,但是删除了ResNet50卷积神经网络最后的全连接层,提取的3D特征图E∈R
全连接层1(103)有1024个神经元结点,使用Leaky ReLU激活函数。全连接层2(104)有64个神经元结点,使用Leaky ReLU激活函数。全连接层3(105)有4个神经元结点,使用Leaky ReLU激活函数。全连接层4(106)只有1个神经元结点,使用Tanh激活函数。全连接层A(108)有100个神经元结点,使用Leaky ReLU激活函数。电子工业出版社2018年出版的《深度学习核心技术与实践》对Leaky ReLU激活函数、Tanh激活函数、批量规范化运算进行过介绍。单神经元结点输入层(107)只有1个神经元结点,但该神经元结点仅接受输入,不进行激活函数处理,直接把输入作为输出。
基于均方误差损失函数来训练深度学习网络ANET,按照误差逆传播思想使用随机梯度下降法来实现深度学习网络ANET的权值优化。
当训练好深度学习网络ANET后,给深度学习网络ANET输入指定的像素角密度参数p和使用该像素角密度参数p进行感知滤波处理后的混叠失真图像,深度学习网络ANET就能输出可以转换得到混叠失真图像视觉质量分数的结果。
- 结合云端全局光照渲染的VR三维场景立体画面生成方法
- 结合云端全局光照渲染的VR三维场景立体画面生成方法