一种应用于编程教育的数据分析方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及数据分析领域,尤其涉及一种应用于编程教育的数据分析方法。
背景技术
教师一般通过作业,考试等成绩反馈来明确学生对于知识的掌控,然而这样的方法在编程课上则略有差异。作为一项更偏向实践与经验的技术,仅凭课上所学所练,学生会有很高的不及格率。在课后,学生会通过线上编程做题来巩固、学习新的知识与算法。在线编程则离不开在线判题系统(Online Judging System,以下简称OJ系统),当一段代码提交之后,会自然生成诸如学生id,题目id,是否通过,失败类型,程序运行时间,内存占用等多项文本数据。此类数据再结合学生表现(如考试成绩,作业成绩)等,可以更加精确地提供一个或者一群学生的特征,此类特征可以提供给教师用以改进教学方案等。
发明内容
为了解决以上技术问题,本发明提供了一种应用于编程教育的数据分析方法。
本发明的技术方案是:
一种应用于编程教育的数据分析方法,工作流程如下:
1)整合OJ系统提供的数据与该学生的数据构造一个数据库;
2)将所有数据划分为不同的集合簇;
3)对每个集合簇内进行数据挖掘,提取出相似特征;
4)将结果返回,基于此类结果做出改进。
进一步的,
构造数据库
对于原始数据库,用ID标明每项数据的归类依据以及数据库处理;
在原始数据表中,用户在一次提交之后的准确度转变为截止记录,开始转换的准确度。
准确度是该用户提交至OJ系统内所有正确答案与该用户所有提交至OJ的次数的比值。
采用k-means的方式对数据库内的数据进行分簇。
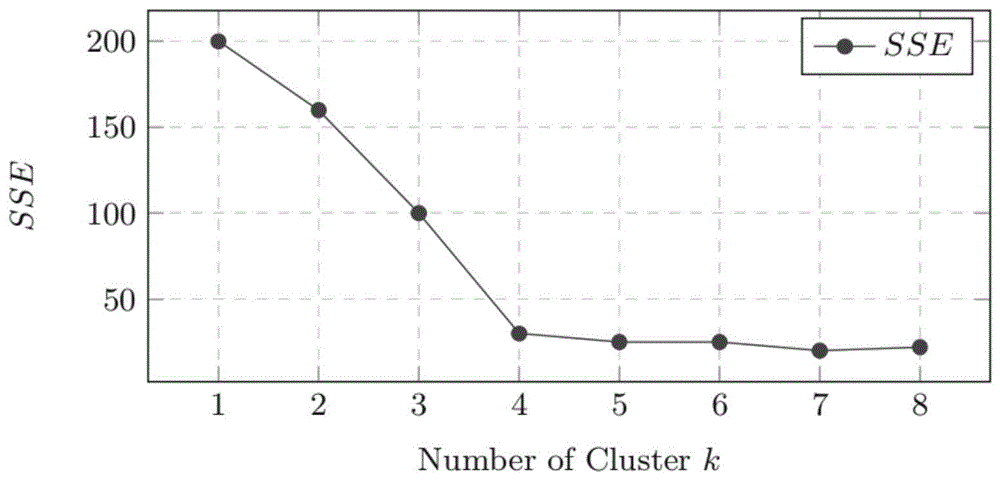
k-means有两个限制:1,如何决定分多少簇的K以及簇的中心选择;选择用Elbowmethod加以优化,ElbowMethod通过计算簇内每个点到簇中心的距离差的平方和(sunsquareerrorSSE)来确定分簇数量。
当SSE越小时,说明每个集合簇结合得越紧密;随着K值增大,当SSE的下降不明显的时候既可以选择为最优分簇数字。
进一步的,
使用FP-growth算法来对每个簇内的所有数据进行关联性获取;其输出的规则格式可以表述为:R=A->B,其中A,B都是上图转化规则内可能出现的指标;A表示既定事实(if),B表示如果发生A,则有大概率发生B的事件。
将输出的结果返回给,可辅助判断学生属于某一集合簇,或者是什么表现可能会带来什么结果。
附图说明
图1是本发明的划分集合簇示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种应用于编程教育的数据分析方法,包括:
1:整合OJ系统提供的数据与该学生的其他数据构造一个数据库。
2:将所有数据划分为不同的集合簇。
3:对每个集合簇内进行数据挖掘,提取出相似特征。
4:将结果返回给教师,教师可基于此类结果做出改进。
下面将依次介绍具体实现步骤
1:构造数据库
数据库表格分为原始数据与整理后数据
原始数据表结构如下:
SID表明某一用户针对某一道程序题所提交的一次程序,UID表示该用户,PID表示该问题id,
verdict标明该用户的提交程序后的结果,包括正确输出或者失败输出并记录其失败原因。
其内容可枚举如下
1:AC:accepted,通过
2:RTE:run time error运行时出错,
3:TLE:time limit error超时
4:WA:wronganswer答案错误
5:CE:compileerror编译错误
6:PrE:presentationerror,输出表述错误
7:MLE:memorylimiterror,内存超出错误
8:OLE:outputlimiterror,输出太多内容
accuracy表明截止此提交时,该用户整体的准确度(定义如下解释)。
准确度定义:准确度是该用户提交至OJ系统内所有正确答案与该用户所有提交至OJ的次数的比值。比如某用户提交了54次正确答案,而提交至OJ的总次数是100次,则此时该用户的准确度为54%。
Pogramming_assignment标明该学生的平时变成作业成绩
Coding_exam标明该学生代码考试成绩
Paper_exam标明该学生笔试成绩
其示例数据如下表显示:
ID抽象转换表,上面的原始数据库的数据有很多无用数据,有些数据由于差距很小也可以归为一类。也难以用于后续计算,因此特建立以下转换规则,用ID标明
每项数据的归类依据以及数据库处理。以下转换规则基于一共只有57道编程题的前提,可根据实际情况灵活安排。此外,在原始数据表中,某用户在某次提交之后的准确度没有参考意义,所有该用户的准确度将在此转变为截止记录,开始转换的准确度。
而转换后的数据表示例则如下显示:
至此,数据库构建完成。
2:划分集合簇
此处采用k-means的方式对数据库内的数据进行分簇。但k-means有两个限制:如何决定分多少簇的K以及簇的中心选择。此处选择用Elbow method加以优化。ElbowMethod通过计算簇内每个点到簇中心的距离差的平方和(sunsquareerrorSSE)来确定分簇数量。当SSE越小时,说明每个集合簇结合得越紧密。为了控制簇内样本数量足够支撑接下来的关联性挖掘,因此随着K值增大,当SSE的下降不明显的时候既可以选择为最优分簇数字,从而减少不必要分簇,如图所示,当k>4之后SSE的值没有多少变化,则取K=4为最优分簇数。
3:关联性规则挖掘
常见的关联性挖掘算法有FP-growth与Apriori算法。此处使用更快速的FP-growth算法来对每个簇内的所有数据进行关联性获取。
其输出的规则格式可以表述为:R=A->B,其中A,B都是上图转化规则内可能出现的指标。A表示既定事实(if),B表示如果发生A,则有大概率发生B的事件。其输出样例如下:
此类结果可返回给教师,可辅助教师判断某些学生属于某一集合簇,或者是什么表现可能会带来什么结果,从而调整教学方式与目标。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 一种基于编程教育系统获取编程语言的方法以及电子设备
- 一种应用于机器人教育的简易编程方法及装置
- 一种基于大数据分析的在线教育方法及在线教育平台