一种基于运行时的连接优化方法
文献发布时间:2023-06-19 19:33:46
技术领域
本发明涉及I T应用领域,特别是涉及一种基于运行时的连接优化方法。
背景技术
在I T应用领域,运行时的连接包括以下缺点:
1.运行时过滤
Joi n是CPU密集型的计算,输入数据的多少会直接影响到Joi n所占用的资源,在Joi n执行之前先进行数据的过滤,则可以避免资源的过度占用和浪费;
2.执行阶段无法自动过滤
执行阶段会严格按照执行计划进行执行,并且一旦执行,则不能进行动态调整,这就导致执行计划的选取格外重要,但由于执行计划的生成是依赖于统计信息生成的,统计信息和实际数据之间存在误差,生成的执行计划往往不是最优的,就会导致在连接过程中先连接,后过滤;
3.冗余数据传输
数据无法预先过滤,因为运行时的数据的分布,数据的真实情况在生成执行计划期间是未知的,无法构建过滤器对数据进行过滤,会导致冗余的数据在各个算子之间传输,一方面会影响查询的性能,另外一方面会给网络带来非常大的负载。
鉴于此,我们提供一种基于运行时的连接优化方法。
发明内容
为了克服现有技术的不足,本发明提供一种基于运行时的连接优化方法,以解决上述背景技术中提出的问题。
为解决上述技术问题,本发明提供如下技术方案:一种基于运行时的连接优化方法,包括:
运行时过滤器,所述运行时过滤器可以根据需要在查询计划中注入和下推Filter,以便在早期过滤数据,减少计算的中间数据大小;
Joi n,所述Joi n包括StreamIter端和Joi n Keys,同时Joi n是耗费资源、耗费时间的操作,Joi n中会产生大量的临时数据,需要大量的IO操作,是在靠近源头上减少参与计算的数据,一方面可以提高查询性能,另一方面也可以减少资源的消耗(网络/IO/CPU等);
B l oomFi lter过滤器,所述B l oomFi lter过滤器包括输入端和连接端,输入端和连接端在Joi n的左子节点或右子节点,在运行时输入端会根据输入数据进行生成B loomFi lter过滤器,连接端会根据输入端构建的B l ooFi lter对数据进行过滤;
在一些关联场景中,可以充分利用过滤之后的维度表,大幅削减事实表的数据扫描量,从整体上提升Joi n计算的执行性能;
通过在Joi n的StreamIter端提前过滤掉不会命中Joi n的输入数据来大幅减少Joi n中的数据传输和计算,减少整体的执行时间;通过使用B l oom Fi lter过滤器和Join另一侧的Joi n Keys的值来生成I N谓词,然后对Joi n的一侧进行预过滤来提高Joi n的性能。
作为本发明的一种优选技术方案,所述Joi n的过滤称之为SortMerjoi n,所述SortMerjoi n运行时过滤的步骤如下:
注入优化规则检查,所述注入优化规则检查名为Runt imeFi lter,Runt imeFilter在优化阶段会组织为Ru l e的方式,通过优化器将其注入到物理计划中,其Ru l e名为I njectRunt imeFi lter,在调用I njectRunt imeFi lter规则时会运行其I nject的逻辑,在I nject逻辑内会判断B l oomFi l ter.Enab l ed是否打开,如果都没有打开则不会进行Runt imeFi lter的优化;
B l oomFi lter的收益性检查,所述B l oomFi lter过滤器会在Joi n两端进行注入,如果B l oom过滤器输入端的输入来自单个叶子节点,则B l oomFi lter过滤器的连接端可以带来收益;
构造B l oomFi lter,所述构造B l oomFi lter过程,会在执行计划中筛选出Join所需的joi n keys,然后在执行期间通过聚合将其更新到B l oomFi lter中,在另外一侧的连接进行数据扫描时候,将B l oomFi lter过滤器加载,并根据Joi n Kyes在B l oomFilter过滤器中进行条件判断,若满足则将满足条件的数据输出,若不满足,则过滤该数据。
作为本发明的一种优选技术方案,如果B l oomFi l ter.Enab l ed为打开状态,则按照如下步骤运行:
确定B l oomFi lter的数量,B l oomFi lter用于对数据集进行过滤,B l oomFilter的数量会影响到过滤的效果,但是过多的B l oomFi lter对内存的占用也会较多,所以B l oomFi lter的选择,会权衡过滤效果和内存占用;
B l oomFi lter过滤器上不存在已有的B l oomFi lter在对应的Joi n Keys上,对应Joi n Keys上的B l oomFi lter只能存在一个B l oomFi lter过滤器;
Joi n Keys是简单表达式,复杂表达式计算如:UDF、JSON_TO_STRUCT、REGEXP_REPLACE等则不能支持B l oomFi lter过滤器;
Joi n类型判断,只有Joi n类型为I nner、LeftSemi、RightOuter时,才可以进行Bl oomFi lter的注入;
检查完毕且条件满足后,则可以进行I njectB l oomFi lter的操作。
作为本发明的一种优选技术方案,所述B l oomFi l ter过滤器输入端的过滤表达式有一个选择性谓词,如下过滤表达式能够带来收益:Not、And、Or、=、>=、<=、<、>、In、Contai ns、StartsWith、EndsWith、Li keAl l、NotLi keAl l、Li keAny、NotLi keAny,非列表表达式,不能构建B l oomFi lter过滤器。
作为本发明的一种优选技术方案,当前的Jo i n是SortMereJoi n或者HashJoin,过滤器应用端的大小大于b l oomFi l ter.app l i cat i onSi deScanSi zeThreshol d(默认为10GB),因为传递B l oomFi l ter本身会带来一定的成本,如果应用端的数据过小,造成的传输成本的代价会大于不应用B l oomF i l ter;
当注入规则检查通过,同时应用B l oomFi l ter预计会产生收益,则会执行injectFi l ter,构造B l oomFi l ter。
作为本发明的一种优选技术方案,构造B l oomFi l ter过程主要有以下几个步骤:
选择Hash函数;
将B l oomFi l ter过滤器输入端的Joi n Keys进行Hash后封装B l oomFi lter过滤器的聚合函数,并封装为聚合表达式,过滤器的大小设置为表的行数;
直接将应用端的逻辑计划应用B l oomFi l ter过滤器,同时进行列剪裁和常量合并;
将Joi n另一侧(大表侧)的Joi n Keys进行Hash,并在B l oomFi l ter过滤器查询匹配,若能匹配,则将匹配数据输出,若不匹配,则将不匹配数据过滤。
与现有技术相比,本发明能达到的有益效果是:
在执行引擎运行时,连接算子可以自动根据过滤条件过滤连接节点的子节点数据,通过对输入数据的过滤,从而减少输入数据的大小,提高性能和减少资源浪费;
在执行引擎运行时,对连接一侧连续不断输入的数据构建B l oomFi l ter过滤器,构造完成后在另一侧执行过滤操作,B l oomFi l ter过滤器的可应用性检查、收益性检查、构建过程、应用过程能够保证过滤有效性和高效性,从而提升连接的性能。
附图说明
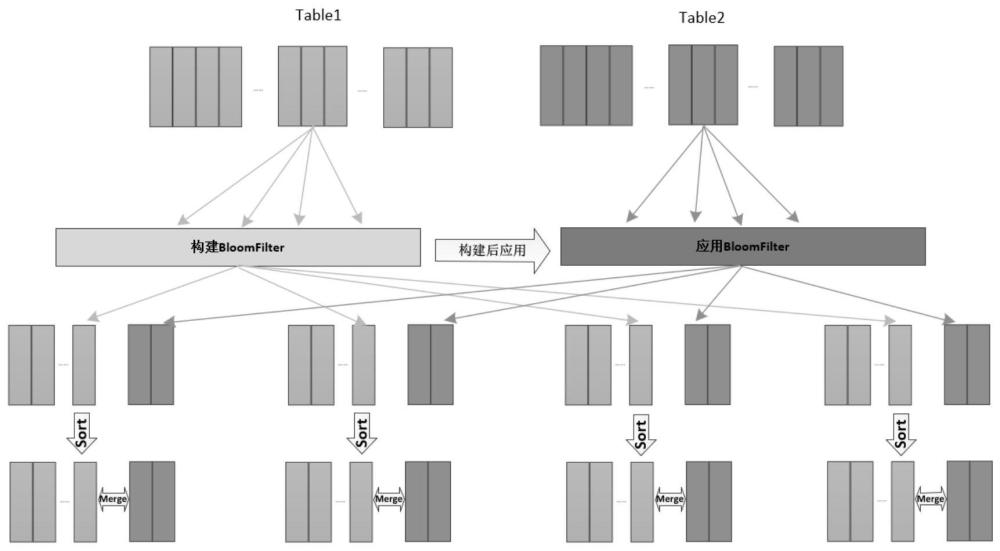
图1为本发明SortMergeJoi n运行时过滤的流程图;
图2为本发明HashJoi n运行时的过滤流程图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施例,进一步阐述本发明,但下述实施例仅仅为本发明的优选实施例,并非全部。基于实施方式中的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得其它实施例,都属于本发明的保护范围。下述实施例中的实验方法,如无特殊说明,均为常规方法,下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
实施例:
如图1和图2所示,本发明提供一种基于运行时的连接优化方法,包括:
运行时过滤器,运行时过滤器可以根据需要在查询计划中注入和下推Fi lter,以便在早期过滤数据,减少计算的中间数据大小;
Joi n,Joi n包括StreamIter端和Joi n Keys,同时Joi n是耗费资源、耗费时间的操作,Joi n中会产生大量的临时数据,需要大量的IO操作,是在靠近源头上减少参与计算的数据,一方面可以提高查询性能,另一方面也可以减少资源的消耗(网络/IO/CPU等);
B l oomFi lter过滤器,B l oomFi lter过滤器包括输入端和连接端,输入端和连接端在Joi n的左子节点或右子节点,在运行时输入端会根据输入数据进行生成B loomFi lter过滤器,连接端会根据输入端构建的B l ooFi lter对数据进行过滤;
在一些关联场景中,可以充分利用过滤之后的维度表,大幅削减事实表的数据扫描量,从整体上提升Joi n计算的执行性能;
通过在Joi n的StreamIter端提前过滤掉不会命中Joi n的输入数据来大幅减少Joi n中的数据传输和计算,减少整体的执行时间;通过使用B l oom Fi lter过滤器和Join另一侧的Joi n Keys的值来生成I N谓词,然后对Joi n的一侧进行预过滤来提高Joi n的性能。
如图1所示,本实施例公开了,Joi n的过滤称之为SortMerjoi n,SortMerjoi n运行时过滤的步骤如下:
注入优化规则检查,注入优化规则检查名为Runt imeFi lter,Runt imeFi lter在优化阶段会组织为Ru l e的方式,通过优化器将其注入到物理计划中,其Ru l e名为InjectRunt imeFi lter,在调用I njectRunt imeFi lter规则时会运行其I nject的逻辑,在I nject逻辑内会判断B l oomFi lter.Enab l ed是否打开,如果都没有打开则不会进行Runt imeFi lter的优化;
B l oomFi lter的收益性检查,B l oomFi lter过滤器会在Joi n两端进行注入,如果B l oom过滤器输入端的输入来自单个叶子节点,则B l oomFi lter过滤器的连接端可以带来收益;
构造B l oomFi lter,构造B l oomFi lter过程,会在执行计划中筛选出Joi n所需的joi n keys,然后在执行期间通过聚合将其更新到B l oomFi lter中,在另外一侧的连接进行数据扫描时候,将B l oomFi lter过滤器加载,并根据Joi n Kyes在B l oomFilter过滤器中进行条件判断,若满足则将满足条件的数据输出,若不满足,则过滤该数据。
如图1和图2所示,本实施例公开了,如果B l oomFi lter.Enab l ed为打开状态,则按照如下步骤运行:
确定B l oomFi lter的数量,B l oomFi lter用于对数据集进行过滤,B l oomFilter的数量会影响到过滤的效果,但是过多的B l oomFi lter对内存的占用也会较多,所以B l oomFi lter的选择,会权衡过滤效果和内存占用;
B l oomFi lter过滤器上不存在已有的B l oomFi lter在对应的Joi n Keys上,对应Joi n Keys上的B l oomFi lter只能存在一个B l oomFi lter过滤器;
Joi n Keys是简单表达式,复杂表达式计算如:UDF、JSON_TO_STRUCT、REGEXP_REPLACE等则不能支持B l oomFi l ter过滤器;
Joi n类型判断,只有Joi n类型为I nner、LeftSemi、Ri ghtOuter时,才可以进行B l oomFi l ter的注入;
检查完毕且条件满足后,则可以进行I njectB l oomFi l ter的操作。
如图1和图2所示,本实施例公开了,B l oomFi l ter过滤器输入端的过滤表达式有一个选择性谓词,如下过滤表达式能够带来收益:Not、And、Or、=、>=、<=、<、>、I n、Contai ns、StartsWith、EndsWith、Li keA l l、NotLi keA l l、Li keAny、NotLi keAny,非列表表达式,不能构建B l oomFi l ter过滤器。
如图1和图2所示,本实施例公开了,当前的Joi n是SortMereJoi n或者HashJoin,过滤器应用端的大小大于b l oomFi l ter.app l i cat i onSi deScanSi zeThreshol d(默认为10GB),因为传递B l oomFi l ter本身会带来一定的成本,如果应用端的数据过小,造成的传输成本的代价会大于不应用B l oomF i l ter;
当注入规则检查通过,同时应用B l oomFi l ter预计会产生收益,则会执行injectFi l ter,构造B l oomFi l ter。
如图2所示,本实施例公开了,构造B l oomFi l ter过程主要有以下几个步骤:
选择Hash函数;
将B l oomFi l ter过滤器输入端的Joi n Keys进行Hash后封装B l oomFi lter过滤器的聚合函数,并封装为聚合表达式,过滤器的大小设置为表的行数;
直接将应用端的逻辑计划应用B l oomFi l ter过滤器,同时进行列剪裁和常量合并;
将Joi n另一侧(大表侧)的Joi n Keys进行Hash,并在B l oomFi l ter过滤器查询匹配,若能匹配,则将匹配数据输出,若不匹配,则将不匹配数据过滤。
本发明一种基于运行时的连接优化方法的有益效果:
1.动态进行数据过滤
现有技术中,执行计划一旦确定,就会按照执行计划执行,过滤会发生在连接操作之后,不能够动态的根据数据情况过滤;而本发明中的方法,在连接运行时,可以根据过滤表达式和数据输入的真实情况,自动构造过滤器,过滤器均衡了性能和构造的代价,对连接优化提供了有力的支撑。
2.大幅提高JO I N效率
现有技术中,JO I N的执行顺序是先执行连接,再进行过滤,输入数据没有经过过滤,数据量会很大,增加计算的成本,Joi n操作低效;而本发明中的方法,Joi n的执行会在过滤之后,数据大幅度过滤,能有效减小计算成本,提高效率。
3.资源占用小
现有技术中,静态执行计划的执行,会导致大量的冗余计算占用CPU、网络、内存资源,导致资源不能有效利用,造成资源浪费;而本发明中的方法,能大幅减少冗余计算,对资源占用更加合理,对于CPU、网络、内存等资源,可以更加有效的利用。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于强化学习的动态并行应用程序能耗运行时优化方法及系统
- 一种基于强化学习的动态并行应用程序能耗运行时优化方法及系统