一种基于yolov5的可变长车牌识别方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及车牌号码检测领域,尤其涉及一种基于yolov5的可变长车牌识别方法。
背景技术
随在城市交通管理、视频监控、车辆识别和停车场管理中车牌识别是一项富有挑战而重要的任务,图像的清晰度、光照条件、天气因素、图像形变和车牌字符的多变性使车牌识别问题变的比较复杂。车牌识别技术作为交通管理自动化的重要手段和车辆检测系统的一个重要环节。在交通监视和控制中占有很重要的地位。
车牌识别技术的关键在于后面的三部分:车牌定位、车牌字符分割和车牌字符识别。
国内外的技术方案绝大多数都是利用文字纹理在车辆图像中的共性进行定位与识别,如国外的YuntaoCui提出了一种车牌识别系统,在车牌定位以后,利用马尔科夫场对车牌特征进行提取和二值化,其重点工作是放在二值化上,最后对其样本的识别达到了较高的识别率;国内都华南理工大学的骆雪超,刘桂雄等提出了一种基于车牌特征信息的二值化的方法,该系统对拍照效果较好的车牌的识别率达到96%。
然而现有技术中仍有一些难点需要解决,如:(1)拍摄车牌图像受环境因素干扰,如逆光、晚上光、光学成像发生衍射等,图片的质量很难保证;(2)其它字符区域的干扰,如车牌旁挂其它牌子,则车牌难以准确定位;(3)车牌出现污点变脏,字迹模糊和退色或者车牌磨损厉害,噪声污损严重;(4)车牌部分被遮挡和车牌变形;(5)图像背景复杂和一幅图像多车牌;(6)拍摄到的车牌是运动图像车牌,则车牌照片模糊失真,形成锯齿;(7)新型车牌识别模型迭代重新训练成本大。
发明内容
为克服现有技术的不足,本发明提出一种基于yolov5的可变长车牌识别方法。
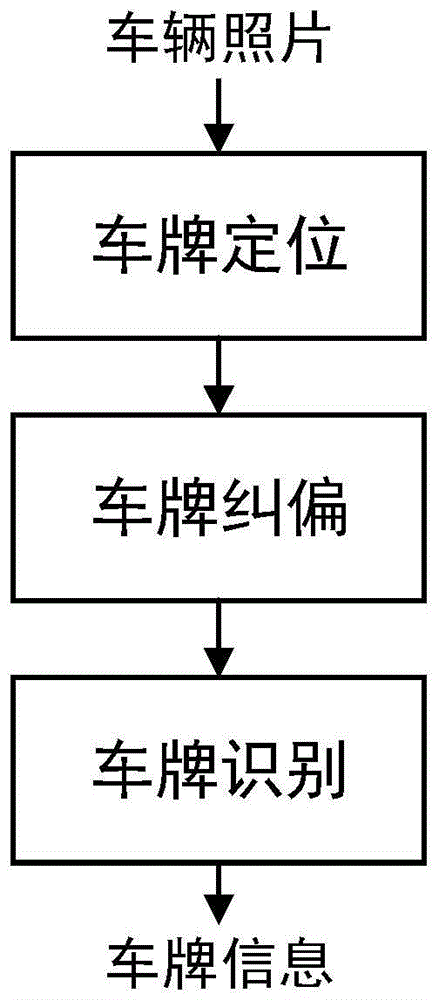
本发明的技术方案是这样实现的:一种基于yolov5的可变长车牌识别方法,包括步骤:
S1:车牌定位;
所述S1包括步骤:
S11:数据准备,采集环境复杂多变情况下的车辆照片,制作成图片数据集;通过人工筛选方式,去除图片数据集中不含完整车牌的图片和损坏的图片,剔除相似度较高的图片,并对不同类型的车牌进行人工分类;对图片数据集中的每辆车图片样本,使用labelimg工具进行标签信息的标注,生成标注txt文件,所述txt文件中的数据集格式为yolo格式,txt文件中每行表示一个车牌的信息,包含车牌类别、车牌中心点横坐标、车牌中心点纵坐标、车牌宽度和车牌高度;将图片数据集中的图像分为训练数据集、验证数据集和测试数据集;
S12:训练YOLOV5S模型,所述YOLOV5S模型包括:ConvBNSiLU模块、BottleNeck1模块、BottleNeck2模块、C3模块和SPPF模块,其中所述ConvBNSiLU模块网络结构是由conv卷积层+bn层+silu激活层组成,所述BottleNeck1模块网络结构包括依次连接1*1的ConvBNSiLU模块,然后再连接3*3的ConvBNSiLU模块,再通过残差结构与初始输入相加,所述BottleNeck2模块网络结构包括依次连接1*1的ConvBNSiLU模块,然后再连接3*3的ConvBNSiLU模块,所述C3模块网络结构结构分为两支,一支经过ConvBNSiLU模块再经过多个Bottleneck堆叠,另一支仅经过一个基本卷积模块,然后将两支进行concat操作,最后再经过ConvBNSiLU模块;所述SPPF模块包括3个串行的最大池化层,最大池化层的池化核大小均为5*5;
S2:车牌纠偏;
所述S2包括步骤:构建基于STN的网络模型结构,所述基于STN的网络输入为U,输出为V,所述基于STN的网络结构包括输入端、Localisation net、Grid generator和Sampler输出端,其中所述Localisation net输入U,输出变化参数Θ,参数Θ用来映射U和V的坐标关系;所述Grid generator根据V中的坐标点和变化参数Θ,计算出V相对于U中的坐标点;所述Sampler输出端根据Grid generator得到的一系列坐标和原图U来填充V;
S3:车牌识别;
所述S3包括步骤:使用LPRNet对车牌进行识别,所述LPRNet包括输入端、Backbone端、Neck端和Head,其中,所述输入端为94*24的RGB图片,所述Backbone端包括Small BasicBlock模块、Convolution、MaxPooling、avg pool、Dropout,所述Neck端通过avg pool层对四个尺度进行融合,所述Head是一个1*1的卷积,输入通道数为448加上预测字母数字的类别数,输出通道数则是预测字母数字的类别数。
进一步地,所述S11中采集环境复杂多变情况下的车辆照片,包括步骤:采集雨天、阴天、倾斜、模糊环境下的车牌照片。
进一步地,所述S11中剔除相似度较高的图片数据,其相似度的计算是通过直方图计算图片的相似度。
进一步地,所述S11中对不同类型的车牌进行人工分类包括步骤:将车牌按照新能源车牌、黄牌、两地牌和普通蓝牌进行人工分类。
进一步地,所述S11中将图片数据集中的图像分为训练数据集、验证数据集和测试数据集,其比例为8∶1∶1。
进一步地,所述S12中YOLOV5S模型的损失函数为:Loss=λ
进一步地,所述S12还包括步骤:在训练YOLOV5S模型过程中,通过数据增强方法扩充训练数据集,所述数据增强方法包括图片旋转、图片平移、图片翻折以及图片随机裁剪。
进一步地,所述S12在训练YOLOV5S模型过程中,训练周期为100,learning_rate为0.01,每隔20个epoch调整一次学习率,momentum为0.9,并生成权值文件,挑选出最佳的模型权重参数作为最优yolov5模型的权值,得到最优yolov5模型。
进一步地,本发明一种基于yolov5的可变长车牌识别方法,还包括步骤:后处理解码,使用argmax找到序列中每个位置的最大概率对应的类别,得到一个长度为18的序列,再对这个序列进行去除空白和去重重复,得到一个最终的预测序列。
本发明的有益效果在于,与现有技术相比,本发明通过人工筛选获取合格的训练集,训练YOLOV5S神经网络以准确获得车牌定位的结果,再通过训练STN网络对变形扭曲的车牌进行纠正以获得更好的车牌特征,最终通过训练LPRNet网络对车牌进行识别以得到准确的车牌信息。
附图说明
图1是本发明一种基于yolov5的可变长车牌识别方法流程示意图;
图2是本发明中车牌定位流程示意图;
图3是本发明中数据准备流程示意图;
图4是本发明中YOLOV5S网络结构中BottleNeck1模块结构示意图;
图5是本发明中YOLOV5S网络结构中BottleNeck2模块结构示意图;
图6是本发明中YOLOV5S网络结构中C3模块结构示意图;
图7是本发明中YOLOV5S网络结构中SPPF模块结构示意图;
图8是本发明中STN网络结构图;
图9是本发明中LPRNet网络结构图;
图10是本发明中small basic block网络结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参见图1、图2和图3,本发明将通过从华南农业大学停车场采集得来视频图像,进行等比例抽帧数,其中每张图像的分辨率为720(宽度)×1160(高)×3(通道),车辆照片的环境复杂多变(雨天、阴天、倾斜、模糊)情况的照片制作成数据集。然后通过人工筛选的方式,把不含完整车牌,已损坏图片均去除,因通过视频抽帧得到的图片数据,连续图片相似度会很高,故需要剔除相似度较高的图片数据(通过直方图计算图片的相似度的方法),并对不同类型的车牌进行人工分类(如新能源汽车车牌,黄牌,两地牌,普通蓝牌)。
对每张数据集图片中的每辆车样本,使用labelimg工具进行标签信息的标注,将生成标注txt文件,txt文件中数据集格式为yolo格式,txt文件中每行表示一个车牌的信息,包含车牌类别、车牌中心点横坐标、车牌中心点纵坐标、车牌宽度和车牌高度。将标注好标签的数据集按照一定比例进行随机抽取,将图像分为训练数据集、验证数据集和测试数据集,该比例为8:1:1。
本发明中,YOLOV5S网络结构包括:
ConvBNSiLU模块,其网络结构是由conv卷积层+bn层+silu激活层组成,其中conv卷积层中参数k指的是卷积核,随后的数字是指卷积核大小,s是指stride,随后的数字是指stride大小,p是指padding,随后的数字是指padding大小,c是指输出channal,随后的数字是指channal大小;
BottleNeck1模块,如图4所示,其网络结构包括依次连接1*1的ConvBNSiLU模块,然后再连接3*3的ConvBNSiLU模块,再通过残差结构与初始输入相加;
BottleNeck2模块,如图5所示,其网络结构包括依次连接1*1的ConvBNSiLU模块,然后再连接3*3的ConvBNSiLU模块;
C3模块,如图6所示,其网络结构是由是对残差特征进行学习的主要模块,其结构分为两支,一支经过ConvBNSiLU模块再经过上述指定多个Bottleneck堆叠,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。最后再经过ConvBNSiLU模块;
SPPF模块,如图7所示,其包括3个串行的最大池化层,最大池化层的池化核大小均为5*5。SPPF模块结构共为四支,第一支为经过1*1的ConvBNSiLU模块,第二支为第一支输出再经过一次最大池化层,第三支为第二支输出再经过一次最大池化层,第四支为第三支输出再经过一次最大池化层。最后将四支进行concat操作并再通过1*1的ConvBNSiLU模块。
图4-图7中,k指的是kernel,s指的是stride,p指的是padding,c指的是channel。输入640*640*3jpg图像到ConvBNSiLU(k6,s2,p2,c64)模块,输出得到320*320*64的特征图;再把该输出特征图输入到ConvBNSiLU(k6,s2,p1,c128)模块,输出得到160*160*128的特征图;把该输出特征图输入C3模块(其中BottleNeck选择1结构,重复三次)模块输出得到160*160*128的特征图;把该输出特征图输入ConvBNSiLU(k3,s2,p1,c256)模块输出得到80*80*256的特征图;再把该输出特征图输入C3模块(其中BottleNeck选择1结构,重复六次)模块输出得到80*80*256的特征图。该特征图分作两支,其中一只记作P1,另一支继续输入到ConvBNSiLU(k3,s2,p1,c256)模块输出得到40*40*512的特征图;把该输出特征图输入C3模块(其中BottleNeck选择1结构,重复九次)模块输出得到40*40*512的特征图。该特征图分作两支,其中一只记作P2,另一支继续输入到ConvBNSiLU(k3,s2,p1,c1024)模块输出得到20*20*1024的特征图;再把该输出特征图输入C3模块(其中BottleNeck选择1结构,重复三次)模块输出得到20*20*1024的特征图;再把该输出特征图输入SPPF模块输出得到20*20*1024的特征图;再把该输出特征图输入ConvBNSiLU(k1,s1,p0,c512)模块输出得到20*20*512的特征图。该特征图分作两支,其中一只记作F1,另一支继续输入到Upsample模块进行上采样输出得到40*40*512的特征图;再把该输出特征图输入Concat模块与P2进行特征融合输出得到40*40*512的特征图;再把该输出特征图输入C3模块(其中BottleNeck选择2结构,重复三次)模块输出得到40*40*512的特征图。
YOLOV5S模型损失函数分别由以下组成:分类损失(Classes loss),采用的是BCEloss,只计算正样本的分类损失;置信度损失(Objectness loss),采用的依然是BCE loss,指的是网络预测的目标边界框与GT Box的CIoU,这里计算的是所有样本的损失,定位损失(Location loss),采用的是CIoU loss,只计算正样本的定位损失,
Loss=λ
其中,lambda为平衡系数,分别为0.5,1和0.05。
在对YOLOV5S模型训练时,把yolov5s预训练权重作为整个网络的训练权重进行训练,在训练过程中,通过数据增强方法扩充训练数据集,所述数据增强方法包括图片旋转、图片平移、图片翻折以及图片随机裁剪。图片旋转是指将图片进行任意角度的旋转;图片平移是指水平或垂直移动图片,使目标位于图片中心位置;图片翻折是指在水平或垂直方向进行翻折;图片随机裁剪是指随机裁剪图片中一部分区域,并将裁剪的区域调整为原始图片的比例大小。通过数据增强方法扩充训练数据集可以减少过拟合,提升模型泛化能力。
YOLOV5S模型训练周期为100,同时生成所需的权值文件。将得到的权值文件中,挑选出训练好后的最佳的模型权重参数作为最优yolov5模型的权值,即可得出最优yolov5模型。
请参见图8,为了解决车牌倾斜变形、拍摄角度不固定对于车牌识别的影响,提高车牌识别应用的鲁棒性和精度,使得网络具备平移、旋转、缩放、剪切不变性。构建基于STN的网络模型结构。STN网络结构主要由输入端,Localisation net,Grid generator,Sampler输出端构成。
Localisation net:是一个自己定义的网络,它输入U,输出变化参数Θ,这个参数用来映射U和V的坐标关系。本发明通过CNN提取图像的特征来预测变换矩阵θ。
Grid generator:根据V中的坐标点和变化参数Θ,计算出V相对于U中的坐标点(理解:比如V中的坐标(1,1),与变化参数Θ相乘后,得到坐标(1.2,1.6),即V中坐标(1,1)的像素值等于U中坐标(1.2,1.6)的像素值)。这里是因为V的大小是自己先定义好的,当然可以得到V的所有坐标点,而填充V中每个坐标点的像素值的时候,要从U中去取,所以根据V中每个坐标点和变化参数Θ进行运算,得到一个相对于U的坐标。
Sampler:要做的是填充V,根据Grid generator得到的一系列坐标和原图U(因为像素值要从U中取)来填充,因为计算出来的坐标可能为小数,故本模块要用双线性插值的方法来填充。
STN是可导的网络,所以插入后续的LPRNet网络后它可以实现端对端的训练。新的重组网络具备了空间不变性,这让STN之后的网络的训练变得更加容易并提升了网络整体的表现力。
请参见图9,为了解决车牌号码长度不同,多行车牌,新型车牌等这些限制当前车牌识别技术精度的影响,车牌识别模块采用LPRNet(算法,该算法可以做到实时的高质量的,支持可变长车牌车牌识别网络结构。该算法不需要预先进行车牌字符分割,完全可以端到端的训练。因其没有使用rnn网络结构,故足够的轻量化。
LPRNet中的骨干网络如图10所示,其中输入端为94*24的RGB图片,Backbone端主要由Small Basic Block模块,Convolution,MaxPooling,avg pool,Dropout组成。
Neck端为了更好的利用backbone提取的特征,没有采取LPRNet论文中使用一个全连接层提取上下文信息,而是通过用avg pool层对四个尺度进行融合。
Head则是一个1*1的卷积,输入通道数为448加上预测字母数字的类别数(本方法中则是68),输出通道数则是预测字母数字的类别数。故最后网络最后输出[68,18],其中68代表序列中每个位置字符为相应类别的概率,车牌字符共有68类,18代表字符序列长度。其中Small Basic Block的结构如图7所示。
基于STN的网络模型在训练时,把CCPD数据集训练完的权重作为整个网络的开始训练权重进行训练,在训练过程中,通过数据增强方法扩充训练数据集,所述数据增强方法包括图片旋转、图片平移、图片翻折以及图片随机裁剪。图片旋转是指将图片进行任意角度的旋转;图片平移是指水平或垂直移动图片,使目标位于图片中心位置;图片翻折是指在水平或垂直方向进行翻折;图片随机裁剪是指随机裁剪图片中一部分区域,并将裁剪的区域调整为原始图片的比例大小。通过数据增强方法扩充训练数据集可以减少过拟合,提升模型泛化能力。
Max_epoch为100,learning_rate为0.01,每隔20个epoch调整一次学习率,momentum为0.9,同时生成所需的权值文件。将得到的权值文件中,挑选出训练好后的最佳的模型权重参数作为最优LPRNet模型的权值,即可得出最优yolov5模型。
为了处理不定长序列对齐问题,即得到的预测序列长度和真实gt的序列是不一样长的,导致无法使用交叉熵等一些经典的loss函数。本发明采用CTC Loss。最后为了得到一个最终的预测序列,先用argmax找到序列中每个位置的最大概率对应的类别(贪婪搜索),得到一个长度为18的序列,再对这个序列进行去除空白(’-‘字符,表示序列的当前位置没有字符),去重重复(序列的相邻两个位置字符不能重复),得到一个最终的预测序列。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 基于简化的yolov5与halcon相结合的车牌识别方法
- 一种基于改进yolov5算法的车牌识别系统