建立预测增殖或非增殖狼疮肾炎模型的方法及预测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及医疗技术领域,特别涉及建立预测增殖或非增殖狼疮肾炎模型的方法及预测方法。
背景技术
系统性红斑狼疮(SLE)是由内源性核抗原耐受性丧失引起的自身免疫性疾病的原型,引发针对各种组织的异常自身免疫反应。狼疮肾炎(LN)是SLE患者最常见且严重的靶器官损害,也是SLE患者发病和死亡的主要原因,影响多达60%的患者。
目前,肾活检组织学分类被认为是LN诊断和病理分型的“金标准”,根据2003年国际肾脏病学会/肾脏病理学会(ISN/RPS)的定义,LN在组织学上被分为六种不同的类型,代表SLE中不同的表现和肾脏受累的严重程度。狼疮肾炎分为:I型为轻微病变性LN;II型为系膜增生性LN;III型为局灶性LN;IV型为弥漫性LN;V型为膜性LN;VI型为晚期硬化型病变。其中,非增殖LN(I、II、V)通常采用保守治疗,免疫抑制只用于治疗肾外症状。而增殖LN (III、IV或III/IV+V)均采用全身免疫抑制和维持治疗,以抑制炎症和控制自身免疫。大量的研究发现,I /II型LN表现最为温和,具有较好的肾脏预后。相对于非增殖LN患者来说、增殖LN患者病情更严重,需要肾脏移植的风险最高、预后不良的风险明显增高。LN的病理类型可随着病程进展及治疗的干预发生转变。有研究表明,约15-30%的非增殖LN可转化为增殖LN。由于增殖和非增殖LN的分型不同,治疗方案、预后转归不同,所以,尽早区分增殖和非增殖LN对临床诊疗是非常重要的。
但目前诊断分型的金标准肾活检有很多的弊端。首先,它是一种有创侵入性操作,可能会出现一些并发症,如血尿、肾周血肿和感染。因此有些病人不适合接受这种手术。其次,组织病理学会随着时间的推移而改变,治疗需要适当调整。由于重复肾活检不容易重复进行,也存在争议,因此不利于监测分型的转变和调整治疗方案。此外,LN临床诊断与组织学评估之间的时间间隔可能会延迟治疗,错过最佳治疗时机,甚至导致LN患者肾功能不全的发展。而且,该技术受医疗技术的限制,很多基层单位由于该技术缺陷,可能延误患者的病情。该技术价格相对昂贵,因此还受患者经济条件的限制。
目前,多种因素导致狼疮肾损害,包括补体、自身抗体、环境和遗传。许多临床和实验室参数,如尿蛋白和自身抗体等,已被探索作为评估狼疮肾炎的指标,但它们缺乏预测和区分增殖LN和非增殖LN的能力。由于LN的异质性和复杂的表型,单一指标不能有效预测狼疮肾炎病理分型。狼疮肾炎病理分层(增殖LN和非增殖LN)的正确评估需要综合分析多个参数,而不是单一的参数。但临床医生对哪些参数重要并不总是一致,也没有有效的方法来评估一些有争议的参数。
因此本发明的目的就是寻找替代肾活检,能够早期预测增殖和非增殖LN的临床和实验室指标,并开发预测模型,有助于临床及时判断疾病进展和调整治疗方案,改善SLE患者的预后。
发明内容
基于以上问题,本发明的第一目的在于提供一种建立预测增殖或非增殖狼疮肾炎模型的方法,该方法能准确地建立起一种预测增殖或非增殖狼疮肾炎的模型。
本发明实现其第一发明目的所采用的技术方案是,建立预测增殖或非增殖狼疮肾炎模型的方法,其步骤包括:
S1、将预定数量狼疮肾炎患者的临床和实验室指标作为训练队列,用最小绝对收缩和选择算子LASSO回归算法筛选出特征指标变量;
S2、设发生增殖狼疮肾炎的概率为P,则非增殖狼疮肾炎的概率为1-P,则优势比OR= P/(1-P),定义Logit P为OR的对数,即Logit P = ln P/(1-P),利用步骤S1中筛选出来的所述特征指标变量进行逻辑回归模型拟合,得到拟合后的Logit P逻辑回归模型;
S3、根据拟合后的Logit P逻辑回归模型绘制ROC曲线,其横坐标为假阳性率,即1-特异度,纵坐标为真阳性率,即灵敏度,约登指数等于灵敏度+特异度-1,在ROC曲线上约登指数最大值即为最佳阈值。
进一步,步骤S1中,所述最小绝对收缩和选择算子LASSO回归算法内部采用十折交叉验证。
进一步,步骤S1中,所述特征指标变量包括性别、血压收缩压(单位,mmHg)、血压舒张压(单位,mmHg)、红细胞压积(单位,L/L)、中性分叶核粒细胞百分率(单位,%)、血红蛋白(单位,g/L)、二氧化碳结合力(单位,mmol/L)、血清钾(单位,mmol/L)、血清氯(单位,mmol/L)、红细胞计数(单位,10
其中:
性别为两分类变量,取值为1、2,其中1代表女性、2代表男性;
尿沉渣红细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,当尿沉渣红细胞>11cell/μL时为高,当尿沉渣红细胞≤11cell/μL时为正常;
尿沉渣白细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,当尿沉渣白细胞>11cell/μL时为高,当尿沉渣白细胞≤11cell/μL时为正常;
其中,红细胞压积、中性分叶核粒细胞百分率、血红蛋白、红细胞计数为血细胞分析指标。
更进一步,所述Logit P逻辑回归模型为:
Logit P=-5.2485+1.0393*性别+0.0125*血压收缩压+0.0298*血压舒张压-8.6097*红细胞压积+0.0257*中性分叶核粒细胞百分率-0.0080*血红蛋白-0.0566*二氧化碳结合力+0.6664*血清钾+0.0582*血清氯-0.1588*红细胞计数-0.5981*尿酸碱度+0.9399*尿沉渣红细胞+0.9783*尿沉渣白细胞;
模型中各变量单位或取值如前所述。
进一步,步骤S2中,得到拟合后的Logit P逻辑回归模型后,还根据所述Logit P逻辑回归模型,将各个特征指标变量对结局变量的贡献度绘制成列线图。
本发明的第二目的在于提供一种预测增殖或非增殖狼疮肾炎的方法,该方法无创安全、无禁忌症、成本低且能及时快速预测狼疮肾炎分型。
本发明实现其第二发明目的所采用的第一种技术方案是,预测增殖狼疮肾炎和非增殖狼疮肾炎的方法,其步骤包括:
S1、将待预测患者的实际特征指标值代入上述建立预测增殖或非增殖狼疮肾炎模型的方法得到的所述Logit P逻辑回归模型,计算得到Logit P值,再转换计算得到该患者发生增殖狼疮肾炎的概率P=1/(1+exp(-Logit P));
S2、若计算得到的概率P大于等于所述的最佳阈值,则预测结果为增殖狼疮肾炎;若概率P小于所述的最佳阈值,则预测结果为非增殖狼疮肾炎。
本发明实现其第二发明目的所采用的第二种技术方案是,预测增殖狼疮肾炎和非增殖狼疮肾炎的方法,其步骤包括:
S1、将待预测患者的实际特征指标值代入上述建立预测增殖或非增殖狼疮肾炎模型的方法得到的所述列线图,根据其每个特征指标变量的值对应列线图最上方的得分Points,得到该特征指标变量得分,将该患者的所有特征指标变量得分加总,得到总得分Total Points,再根据总得分Total Points对应列线图最下方的风险risk,得出该患者发生增殖狼疮肾炎的概率P;
S2、若得到的概率P大于等于所述的最佳阈值,则预测结果为增殖狼疮肾炎;若概率P小于所述的最佳阈值,则预测结果为非增殖狼疮肾炎。
本发明的有益效果为:
一、本发明属于无创技术,无并发症,普遍性强;
二、本发明无禁忌症,条件范围宽;
三、本发明在LN的进展过程中,有利于动态监测患者的病理进展情况,及时掌握患者的分型转变,从而调整患者的治疗方案,改善患者的预后;
四、本发明预测LN患者病理分型所需要的时间间隔短,有利于患者病情及时治疗和改善;
五、本发明筛选出来的指标普及性强,不受医疗技术的限制,基层单位也可以适用;
六、本发明应用中价格相对较低,可以减轻患者的经济负担。
附图说明
图1为本发明实施例1方法步骤流程图;
图2为本发明实施例2方法步骤流程图;
图3为本发明实施例3方法步骤流程图;
图4为本发明实施例基于十折交叉验证的LASSO筛选变量图;
图5为LASSO调优参数λ与偏回归系数图;
图6为LASSO解释偏差百分比与偏回归系数图;
图7为本发明实施例训练队列ROC曲线最佳阈值图;
图8为本发明实施例根据所述Logit P逻辑回归模型得到的列线图;
图9为本发明实施例训练队列ROC曲线图;
图10为本发明实施例验证队列ROC曲线图;
图11为本发明实施例训练队列校准曲线图;
图12为本发明实施例验证队列校准曲线图;
图13为本发明实施例训练队列临床决策曲线图;
图14为本发明实施例验证队列临床决策曲线图。
实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。
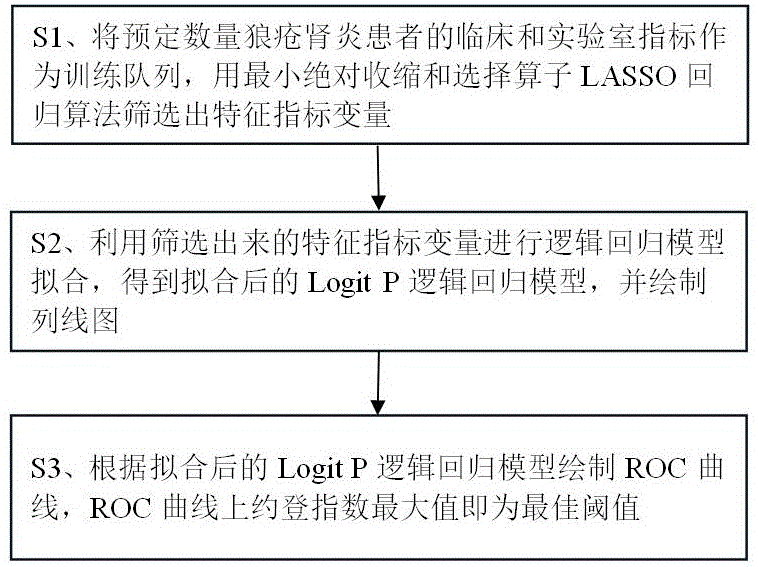
实施例1 建立预测增殖或非增殖狼疮肾炎模型的方法
图1示出本发明的一种具体实施方式,建立预测增殖或非增殖狼疮肾炎模型的方法,其步骤包括:
S1、将预定数量狼疮肾炎患者的临床和实验室指标作为训练队列,用最小绝对收缩和选择算子LASSO回归算法筛选出特征指标变量;
LASSO回归算法内部采用十折交叉验证。本实施例中,总共基于2011年至2021年四川大学华西医院的狼疮肾炎患者777例,收集所有患者的临床和实验室指标,选取其中70%患者共545例(415例增殖LN,130例非增殖LN)作为训练队列,使用LASSO回归算法筛选特征指标变量,剩余30%患者共232例(177例增殖LN,55例非增殖LN)作为验证队列。
图4~图6示出LASSO回归算法筛选特征指标变量的过程:通过正则化技术,在残差平方和(RSS)最小化的过程中,加入一个正则化项,此正则化项被称为收缩惩罚,这个收缩惩罚项包含λ及对偏回归系数βi和权重的规范化,最终的目标是使残差平方和与收缩惩罚之和最小化(即RSS+λ(sum|βi|最小化)。通过正则化技术对于高维数据,可以对偏回归系数βi进行限制甚至缩减为0,达到筛选变量的目的,从而避免变量间多重共线性问题的出现,同时,由于增加了正则化项,可以有效避免过拟合的发生。
其中,图4横坐标是λ的对数值,纵坐标是不同λ下的模型偏差,图形上方的横坐标是自变量的数目。两条竖虚线分别表示偏差最小时对应的λ对数值,以及距离最小偏差一个标准误差时对应λ的对数值。选择距离最小偏差一个标准误差所对应λ为0.04020。
图5横坐标是λ的对数值,纵坐标是各个变量的偏回归系数βi。随着λ的增大,偏回归系数βi绝对值不断减小甚至为0,以达到筛选变量的目的。
图6横坐标是解释偏差百分比,纵坐标是各个变量的偏回归系数βi。随着解释偏差百分比的增大,偏回归系数βi绝对值不断增大。
本实施例中,筛选出来的Logit P逻辑回归模型使用到的特征指标变量包括性别、血压收缩压(单位,mmHg)、血压舒张压(单位,mmHg)、红细胞压积(单位,L/L)、中性分叶核粒细胞百分率(单位,%)、血红蛋白(单位,g/L)、二氧化碳结合力(单位,mmol/L)、血清钾(单位,mmol/L)、血清氯(单位,mmol/L)、红细胞计数(单位,10
其中:
性别为两分类变量,取值为1、2,其中1代表女性、2代表男性;
尿沉渣红细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣红细胞>11cell/μL时为高,当尿沉渣红细胞≤11cell/μL时为正常;
尿沉渣白细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣白细胞>11cell/μL时为高,当尿沉渣白细胞≤11cell/μL时为正常;
其中,红细胞压积、中性分叶核粒细胞百分率、血红蛋白、红细胞计数为血细胞分析指标。
S2、设发生增殖狼疮肾炎的概率为P,则非增殖狼疮肾炎的概率为1-P,则优势比OR= P/(1-P),定义Logit P为OR的对数,即Logit P = ln P/(1-P),利用步骤S1中筛选出来的所述特征指标变量进行逻辑回归模型拟合,得到拟合后的Logit P逻辑回归模型;
本实施例中,所述Logit P逻辑回归模型为:
Logit P=-5.2485+1.0393*性别+0.0125*血压收缩压+0.0298*血压舒张压-8.6097*红细胞压积+0.0257*中性分叶核粒细胞百分率-0.0080*血红蛋白-0.0566*二氧化碳结合力+0.6664*血清钾+0.0582*血清氯-0.1588*红细胞计数-0.5981*尿酸碱度+0.9399*尿沉渣红细胞+0.9783*尿沉渣白细胞;
模型中各变量单位或取值如前所述。
由逻辑回归结果可得,男性、血压收缩压、血压舒张压、中性分叶核粒细胞百分率、血清钾、血清氯、尿沉渣红细胞、尿沉渣白细胞是增殖LN的危险因素;而红细胞压积、血红蛋白、二氧化碳结合力、红细胞计数、尿酸碱度是增殖LN的保护因素。以P<0.05为有显著性差异,在模型中,性别、红细胞压积、中性分叶核粒细胞百分率、血清钾、血清氯、尿酸碱度、尿沉渣红细胞、尿沉渣白细胞的系数显著的不为0。
S3、根据拟合后的Logit P逻辑回归模型绘制ROC曲线,其横坐标为假阳性率,即1-特异度,纵坐标为真阳性率,即灵敏度,约登指数等于灵敏度+特异度-1,在ROC曲线上约登指数最大值即为最佳阈值。
图7为训练队列ROC曲线及最佳阈值图。在该ROC曲线上可利用约登指数找最佳阈值,对本实施例的最佳阈值为0.772,对应此阈值点模型的灵敏度为0.757,特异度为0.808。
本实施例中,步骤S2中,得到拟合后的Logit P逻辑回归模型后,还根据所述LogitP逻辑回归模型,将各个特征指标变量对结局变量的贡献度绘制成列线图,预测发生增殖狼疮肾炎的风险概率P。
列线图是按照模型拟合的函数关系用图绘制在同一平面上,把复杂的数学关系转为可视化的图形,更加直观简便。
图8表示出本实施例根据所述Logit P逻辑回归模型得到的列线图。
列线图分为四个部分:
一、用于预测模型的自变量:每一个自变量的线段上都有相应的标尺,表示该自变量的取值范围,而线段的长度则反映了该自变量对因变量的贡献大小。
二、自变量相应的得分:根据自变量的取值对应列线图最上方的Points,可得出每个自变量取不同值时所对应的得分,所有自变量得分加总,即总得分Total Points。
三、总得分Total Points:所有自变量相应得分的总和,用于推算因变量的概率大小,即预测事件的发生风险。
四、事件的发生风险,即列线图最下方的risk:根据Total Points对应risk,即可得到事件的发生风险。
实施例2 预测增殖狼疮肾炎和非增殖狼疮肾炎的方法
图2示出本发明的第二种具体实施方式,预测增殖狼疮肾炎和非增殖狼疮肾炎的方法,其步骤包括:
S1、将待预测患者的实际特征指标值代入上述建立预测增殖或非增殖狼疮肾炎模型的方法得到的所述Logit P逻辑回归模型,计算得到Logit P值,再转换计算得到该患者发生增殖狼疮肾炎的概率P=1/(1+exp(-Logit P));
本实施例中,特征指标变量包括性别、血压收缩压(单位,mmHg)、血压舒张压(单位,mmHg)、红细胞压积(单位,L/L)、中性分叶核粒细胞百分率(单位,%)、血红蛋白(单位,g/L)、二氧化碳结合力(单位,mmol/L)、血清钾(单位,mmol/L)、血清氯(单位,mmol/L)、红细胞计数(单位,10
其中:
性别为两分类变量,取值为1、2,其中1代表女性、2代表男性;
尿沉渣红细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣红细胞>11cell/μL时为高,当尿沉渣红细胞≤11cell/μL时为正常;
尿沉渣白细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣白细胞>11cell/μL时为高,当尿沉渣白细胞≤11cell/μL时为正常;
其中,红细胞压积、中性分叶核粒细胞百分率、血红蛋白、红细胞计数为血细胞分析指标。
本实施例中,所述Logit P逻辑回归模型为:
Logit P=-5.2485+1.0393*性别+0.0125*血压收缩压+0.0298*血压舒张压-8.6097*红细胞压积+0.0257*中性分叶核粒细胞百分率-0.0080*血红蛋白-0.0566*二氧化碳结合力+0.6664*血清钾+0.0582*血清氯-0.1588*红细胞计数-0.5981*尿酸碱度+0.9399*尿沉渣红细胞+0.9783*尿沉渣白细胞。
S2、若计算得到的概率P大于等于所述的最佳阈值,则预测结果为增殖狼疮肾炎;若概率P小于所述的最佳阈值,则预测结果为非增殖狼疮肾炎。
本实施例的最佳阈值为0.772。
实施例3 预测增殖狼疮肾炎和非增殖狼疮肾炎的方法
图3示出本发明的第三种具体实施方式,预测增殖狼疮肾炎和非增殖狼疮肾炎的方法,其步骤包括:
S1、将待预测患者的实际特征指标值代入上述建立预测增殖或非增殖狼疮肾炎模型的方法得到的所述列线图,根据其每个特征指标变量的值对应列线图最上方的得分Points,得到该特征指标变量得分,将该患者的所有特征指标变量得分加总,得到总得分Total Points,再根据总得分Total Points对应列线图最下方的风险risk,得出该患者发生增殖狼疮肾炎的概率P;
本实施例中,特征指标变量包括性别、血压收缩压(单位,mmHg)、血压舒张压(单位,mmHg)、红细胞压积(单位,L/L)、中性分叶核粒细胞百分率(单位,%)、血红蛋白(单位,g/L)、二氧化碳结合力(单位,mmol/L)、血清钾(单位,mmol/L)、血清氯(单位,mmol/L)、红细胞计数(单位,10
其中:
性别为两分类变量,取值为1、2,其中1代表女性、2代表男性;
尿沉渣红细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣红细胞>11cell/μL时为高,当尿沉渣红细胞≤11cell/μL时为正常;
尿沉渣白细胞为两分类变量,取值为1、2,其中1代表正常、2代表高,标准参考值为0-11cell/μL,当尿沉渣白细胞>11cell/μL时为高,当尿沉渣白细胞≤11cell/μL时为正常;
其中,红细胞压积、中性分叶核粒细胞百分率、血红蛋白、红细胞计数为血细胞分析指标。
图8表示出本实施例根据所述Logit P逻辑回归模型得到的列线图。
列线图分为四个部分:
(一)用于预测模型的自变量:每一个自变量的线段上都有相应的标尺,表示该自变量的取值范围,而线段的长度则反映了该自变量对因变量的贡献大小。
(二)自变量相应的得分:根据自变量的取值对应列线图最上方的得分Points,可得出每个自变量取不同值时所对应的得分,所有自变量得分加总,即总得分Total Points。
本实施例的列线图中,例如,性别等于2代表男性,其对应得分为34分;血压收缩压等于100mmHg时,其对应得分为8分;血清钾等于4mmol/L时,其对应得分为33分;以此类推,可以对应出所有自变量相应的得分。
(三)总得分Total Points:所有自变量相应得分的总和,用于推算因变量的概率大小,即预测事件的发生风险。
(四)事件的发生风险,即列线图最下方的risk:根据Total Points对应risk,即可得到事件的发生风险也即概率。
本实施例的列线图中,例如,当总得分Total Points为347时,对应的预测风险risk也即概率P为0.5;当总得分Total Points为375时,对应的预测风险risk也即概率P为0.7;以此类推。
S2、若得到的概率P大于等于所述的最佳阈值,则预测结果为增殖狼疮肾炎;若概率P小于所述的最佳阈值,则预测结果为非增殖狼疮肾炎。
本实施例的最佳阈值为0.772。
模型验证:
为了对本发明的Logit P逻辑回归模型性能进行验证,对训练队列和验证队列分别进行验证,验证方法包括ROC曲线、校准曲线和临床决策曲线(DCA)分析。
一、ROC曲线分析
ROC曲线的横坐标为假阳性率,即1-特异度,纵坐标为真阳性率,也称灵敏度。它能反映模型在选取不同阈值时其灵敏度和特异度的趋势走向。ROC曲线的优势:当正负样本的分布发生变化时,其形状稳健性较高;能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。通常计算ROC曲线下面积(area under roc curve,AUC)表示预测模型的好坏。AUC为0.5时,即完全随机,说明该模型没有预测作用;AUC为1时,完全一致,说明模型的预测结果与实际结果完全一致。AUC在0.5~1之间,值越大,模型的准确性越高。
图9为本发明实施例训练队列ROC曲线图,其AUC=0.873;
图10为本发明实施例验证队列ROC曲线图,其AUC=0.861;
训练队列和验证队列的AUC均大于0.85,说明模型有较高的准确性。
二、校准曲线分析
Calibration校准曲线就是关于实际发生率和预测发生率的散点图。实质上,Calibration校准曲线是把Hosmer-Lemeshow拟合优度检验的结果可视化,它用来评价模型的一致性,即预测值与实际值之间的差异。基本原理:首先利用模型预测每位研究对象的预测值,并将其按从低到高的顺序排列,根据四分位数将队列分为4组(或者根据其他分位数分组),然后分别计算每组研究对象预测值和相应实际值的均值,并将两者结合起来作图得到4个校准点,最后将这4个校准点连接起来得到预测校准曲线。
图11为本发明实施例训练队列校准曲线图;
图12为本发明实施例验证队列校准曲线图;
图中未校正曲线表示预测值与实际值的拟合情况,校正曲线表示校正之后的预测值和实际值的拟合情况。若校正曲线或未校正曲线越接近参考线,说明预测值和实际值的一致性越高,若校正曲线或未校正曲线越偏离参考线,说明预测值和实际值的一致性越差。
从图11、图12可以看出,训练队列和验证队列预测值和实际值的一致性较好。
三、临床决策曲线分析
在临床决策(DCA)曲线中,横坐标为阈概率,纵坐标是净获益率。在DCA曲线中,有两条极端的曲线。横的那条表示所有样本都是阴性(None),所有人都没干预,净获益为0;斜的曲线表示所有样本都是阳性(All),所有人都接受了干预,净获益是一条斜率为负的斜线。若DCA曲线和两条极端曲线很接近,则说明DCA曲线没什么应用价值。若在一个很大的横坐标区间范围内,DCA曲线的净获益率都比极端曲线高,则说明DCA曲线其有一定的应用价值。
图13为本发明实施例训练队列临床决策曲线图;
图14为本发明实施例验证队列临床决策曲线图;
从图13看出,训练队列的临床决策曲线,阈概率在0.03-0.98都是有临床价值的;
从图14看出,验证队列的临床决策曲线,阈概率在0.05-0.95、0.99都是有临床价值的;
本模型的最佳阈值为0.772,可以看到在训练和验证队列净获益率都是明显大于极端曲线的,本模型在训练和验证队列的DCA曲线都有应用价值。
模型验证结论:通过对训练队列和验证队列的ROC曲线、校准曲线和临床决策曲线分析,本模型综合评价比较好,可以作为肾活检的补充或者替代应用于临床预测增殖LN的发生风险。
本发明的上述实施例仅仅是为说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化和变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 一种单井可采变化规律动态模型的建立方法及勘探项目储量指标预测方法
- 基于钢坯称重系统三冲量双模型回归预测模型建立方法
- 一组用于预测非增殖性DR发生风险的血浆代谢标志物及其应用和评分模型的构建方法
- 一种用于预测增殖型肝细胞癌的模型和诺模图的构建方法