一种电动轮椅用户需求提取方法、系统及电子设备
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及电子数字数据处理技术领域,特别是涉及一种电动轮椅用户需求提取方法、系统及电子设备。
背景技术
电动轮椅作为下肢残障者的重要代步工具,与用户连接最为紧密,其设计需要最大程度满足用户需求。对于轮椅制造商来说,如何全面地考量残障人士的用户需求,设计满足残障人士需求的电动轮椅尤其重要。
在线数据挖掘是指通过互联网进行数据采集并分析的方法,在数据驱动和用户导向的行业背景之下,以用户为中心的产品设计能够为用户提供积极健康的情感价值与实用价值,并有效的整合设计资源,提高产品适用性。对消费者进行细致入微的用户调研是获取用户需求的常用方法之一,传统的调研模式通过桌面调研、实地访谈等方式展开,成本较高,需要耗费大量人力和物力。随着电子商务的普及,越来越多的购买者选择通过在线购物平台(例如淘宝、京东、亚马逊等)购买产品,并在评论平台抒发自己体验后的感受和针对产品的建议。通过这些在线产品评论,制造商和设计师可以从海量带有需求导向的用户在线评论数据中挖掘消费者对于产品和服务的偏好需求,从中获取用户针对产品的情感、态度、需求等有用信息,指导产品设计与服务改进,提升用户体验与设计质量,解决传统需求获取方式成本高、范围小、实用性较差等问题。对线上评论数据进行文本分析,从中提取残障人士对电动轮椅的需求信息,具有重要意义。
当前基于数据挖掘和文本分析的用户体验情感分析在数据的提取和应用上存在适用性不强,有效性不足等问题。最初针对用户评论数据分析的研究主要集中在评论文本情感分析、文本重要度分析等方面,是对于用户评论整句话情感语义的判别与分析,属于粗粒度的文本分析。然而,用户针对产品发表的在线评论通常具有复杂性和随意性,针对产品的每个部件发表不同的情感体验与功能评价。因此,需要细粒度的分析来获取用户面向产品不同特征之间的需求观点。
细粒度的文本情感分析方法通常需要大量的标注数据以标注其中有效信息,进而训练合适的神经网络模型进行用户观点抽取,而对于大量样本进行人工标注,存在成本较高、时效性不足等问题。
发明内容
为解决现有技术存在的上述问题,本发明提供了一种电动轮椅用户需求提取方法、系统及电子设备。
为实现上述目的,本发明提供了如下方案。
一种电动轮椅用户需求提取方法,包括:收集线上用户评论并进行小样本标注,构建电动轮椅用户需求数据集;所述电动轮椅用户需求数据集包括文本数据集和模型数据集;所述小样本为样本条数不超过500条的样本。
基于情感预训练深度学习模型,构建用于抽取电动轮椅线上用户评论需求的神经网络模型;所述情感预训练深度学习模型为SKEP、BERT、Word2Vec中的任意一种。
采用所述模型数据集训练所述用于抽取电动轮椅线上用户评论需求的神经网络模型,得到训练好的神经网络模型。
将所述文本数据集输入至所述训练好的神经网络模型,抽取所述文本数据集中的电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征。
整合电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征,得到电动轮椅创新设计策略。
可选地,收集线上用户评论并进行小样本标注,构建电动轮椅用户需求数据集,具体包括:
从电商网站爬取评论文本数据。
对所述评论文本数据进行预处理。
结合专家知识,对预处理后的所述评论文本数据进行小样本标注,得到标注数据。
基于情感分析评估维度和观点抽取Demo数据,结合所述标注数据生成所述电动轮椅用户需求数据集。
可选地,所述预处理包括数据删除处理、数据去重处理和数据清洗处理。
可选地,基于情感分析评估维度和观点抽取Demo数据构建所述模型数据集,在小样本标注下实现用户评论情感分析,得到电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征。
可选地,基于电动轮椅专家知识,整合电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征,得到电动轮椅创新设计策略。
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明基于深度学习和文本分析进行用户需求的智能挖掘与筛选,实现了从电商平台上生成的电动轮椅用户评论中有效抽取用户需求信息,为大数据背景下快速、精准、智能地提取电动轮椅的用户需求提供了方法,解决了传统用户需求挖掘方法广度与深度不足、成本较高、时效性不足等问题。同时,本发明基于情感预训练深度学习模型(如SKEP、BERT、Word2Vec等),构建用于评论需求抽取的神经网络模型,能够实现细粒度的文本情感分析,在小样本数据的情况下迅速完成情感分析模型的训练,实现细粒度的、精准、快速的用户需求识别与分类,从而正确抽取电动轮椅特征及与之相应的用户需求,输出产品创新设计策略,能够为企业和设计师开发新产品提供快速、准确的技术支持。
进一步,本发明还提供了一种电动轮椅用户需求提取系统,应用于上述的电动轮椅用户需求提取方法;所述系统包括:数据集构建模块、网络模型构建模块、网络模型训练模块、用户需求提取模块和设计策略输出模块。
数据集构建模块,用于收集线上用户评论并进行小样本标注,构建电动轮椅用户需求数据集;所述电动轮椅用户需求数据集包括文本数据集和模型数据集;所述小样本为样本条数不超过500条的样本。
网络模型构建模块,基于情感预训练深度学习模型,构建用于抽取电动轮椅线上用户评论需求的神经网络模型;所述情感预训练深度学习模型为SKEP、BERT、Word2Vec中的任意一种。
网络模型训练模块,用于采用所述模型数据集训练所述用于抽取电动轮椅线上用户评论需求的神经网络模型,得到训练好的神经网络模型。
用户需求提取模块,用于将所述文本数据集输入至所述训练好的神经网络模型,抽取所述文本数据集中的电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征。
设计策略输出模块,用于整合电动轮椅部件特征及与所述电动轮椅部件特征对应的用户需求情感特征,得到电动轮椅创新设计策略。
一种电子设备,包括:存储器和处理器。
存储器,用于存储计算机程序。
处理器,与所述存储器连接,用于调取并执行所述计算机程序,以实施上述的电动轮椅用户需求提取方法。
可选地,所述存储器为计算机可读存储介质。
因本发明上述提供的两种实施结构实现的技术效果与本发明提供的电动轮椅用户需求提取方法实现的技术效果相同,故在此不再进行赘述。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
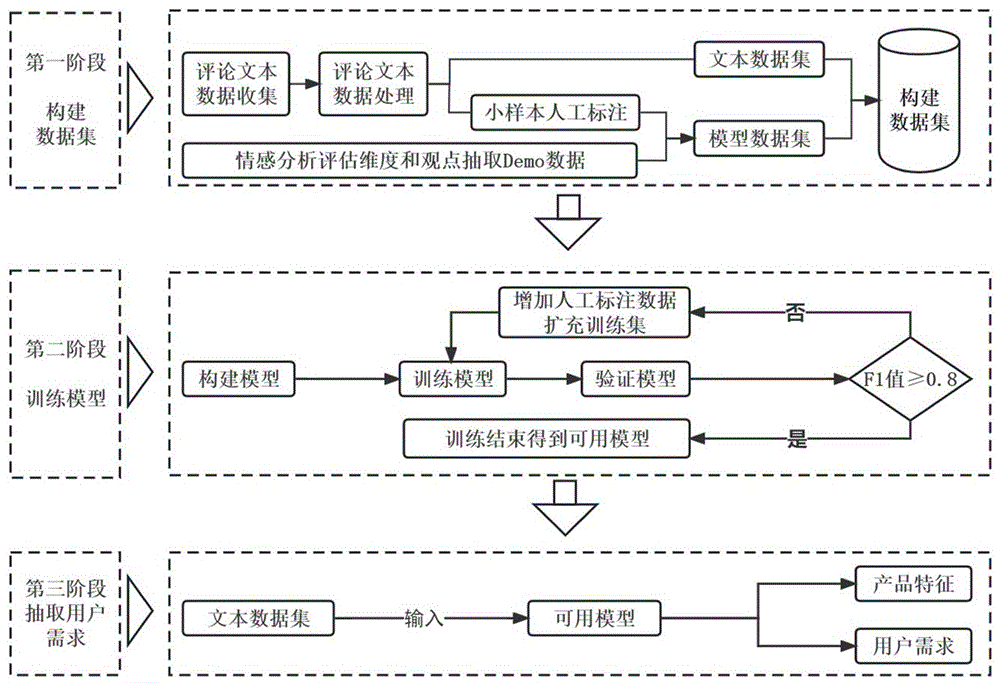
图1为本发明提供的电动轮椅用户需求提取方法的实施步骤图。
图2为本发明提供的模型数据集构成示意图。
图3为本发明提供的SKEP模型结构示意图。
图4为本发明提供的情感预训练模型SKEP计算过程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
基于深度模型的大型语料库预训练模型能够学习通用的语言规则,可以迁移至下游自然语言处理任务,并在少量标注的情况下迅速完成情感分析模型的训练。因此,本发明的目的是提供一种电动轮椅用户需求提取方法、系统及电子设备,着眼于大数据背景下的用户在线需求挖掘,从细粒度角度构建神经网络观点抽取模型,使用无监督学习方法自主挖掘情感知识,然后利用情感知识构建预训练模型,从而使计算机能够理解情感语义,获取线上用户需求,进而能够解决现有技术在用户观点抽取过程中存在的成本较高、时效性不足等问题。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明提供的电动轮椅用户需求提取方法,包括以下三个阶段。
第一阶段:收集线上用户评论并进行小样本标注,构建电动轮椅用户需求数据集;电动轮椅用户需求数据集包括文本数据集和模型数据集;小样本为样本条数不超过500条的样本。这一阶段的具体实现过程为:
步骤1、评论文本数据收集。
例如,使用后羿采集器从京东、天猫、淘宝等电商网站爬取产品用户评论,采集到市面上品牌(例如,Ainsnbot、互邦、凤凰、好哥、护卫神、佳康顺、九园、凯莱宝、联想、迈德斯特、欧航、仁和、斯维驰、小飞哥、英洛华、鱼跃、振邦)的用户评论数据。
步骤2、评论文本数据处理。
该步骤主要是为了对评论数据进行预处理。其中,预处理主要包含无效评论删除、评论去重、特殊字符处理等。例如,采用的数据处理具体操作如下:
1)删除字数较短评论(即无效评论删除)。例如,将字符数小于4的文本评论如“不错”、“可以”、“好”等删除。
2)删除重复评论(即评论去重)。例如,删除评论内容相同、用户ID相同的疑似“刷评论”数据。
3)特殊字符处理。例如,删除用户评论中的表情、特殊字符、网站信息等与用户需求识别无关的信息。
步骤3、小样本人工标注。
在该步骤实际应用过程中,随机抽取小样本评论文本数据,可以使用BIO序列标注方法对评论文本中的评论主题与用户观点进行标注,从而帮助神经网络模型能够准确识别产品特有的主题及用户需求,为训练模型提供基础。具体地,标注过程包括:采用BIO序列标注方法对文本批量数据进行人工标注,人工抽取评论中的产品属性与用户需求点,并对BIO序列标注方法进行了标签拓展(B-Aspect,I-Aspect,B-Opinion,I-Opinion,O),其中,前两者(即B-Aspect和I-Aspect)用于标注电动轮椅功能属性,后两者(即B-Opinion和I-Opinion)用于标注电动轮椅属性相应的情感需求观点,O用于标注无效词。具体标注示例如下所示:
示例1。
文本评论数据为:这全自动轮椅真不错。车架漂亮、结实。手把方向使用自如。开起来就是一辆超级舒适豪华电动车。对老年人来说真是人性化设计。比较半天,这个坐椅尺寸是比较窄的、入户门方便些。椅垫柔软。折叠简单方便、承重150公斤。一句话实用。不错的购物体验。
对应采用BIO序列标注方法标注后的数据为:O B-Aspect I-Aspect I-Aspect OO O B-Opinion I-Opinion O B-Aspect I-Aspect B-Opinion I-Opinion O B-OpinionI-Opinion O B-Aspect I-Aspect B-Aspect I-Aspect B-Aspect I-Aspect B-OpinionI-Opinion O B-Aspect I-Aspect I-Aspect O O O O O O B-Opinion I-Opinion B-Opinion I-Opinion O O O O O O O O O O O O B-Opinion I-Opinion I-Opinion B-Aspect I-Aspect O O O O O O O O B-Aspect I-Aspect B-Aspect I-Aspect O B-Opinion I-Opinion I-Opinion O O O O O B-Opinion I-Opinion O O B-Aspect I-Aspect B-Opinion I-Opinion O B-Aspect I-Aspect B-Opinion I-Opinion B-OpinionI-Opinion O B-Aspect I-Aspect O O O O O O O O O B-Opinion I-Opinion O B-Opinion I-Opinion O O O B-Opinion I-Opinion O。
示例2。
文本评论数据为:双电机的轮椅就是不一样,我买回家爸爸第一时间就坐着双电动轮椅去体验了,上坡有力,下坡不费力,刚开始以为自己不会使用,开两圈充分的爱上了这个车,充电快捷使用便捷一键折叠非常方便!
对应采用BIO序列标注方法标注后的数据为:O B-Aspect I-Aspect O O O O O OO O O O O O O O O O O O O O O O O O O O O O B-Opinion I-Opinion O O B-AspectI-Aspect B-Opinion I-Opinion O B-Aspect I-Aspect B-Opinion I-Opinion I-Opinion O O O O O O O O O O O O O O O O O O O O O O O O O O B-Aspect I-AspectB-Opinion I-Opinion B-Aspect I-Aspect B-Opinion I-Opinion B-Aspect I-AspectI-Aspect I-Aspect O O B-Opinion I-Opinion O。
通过数据标注自制电动轮椅评论数据300条。基于此,本发明结合飞桨(PaddlePaddle)发布的情感分析评估维度和观点抽取Demo数据1000条,制作用于产品属性与用户需求观点提取的模型数据集。
具体的,将标注好的自制电动轮椅评论数据与Demo数据结合构建模型数据集。按照8:2的比例,分别从其中选240条电动轮椅评论数据与800条目标级粒度情感分类Demo数据作为训练集,其余数据作为测试集。模型数据集的构成框架如图2所示。
步骤4、收集到的评论文本数据,在经步骤2的数据处理后,生成文本数据集,至此完成数据集的构建。
第二阶段:训练模型,具体实现过程如下所示。
步骤1、构建模型。该步骤的实现过程可以是:基于情感预训练深度学习模型,构建用于抽取电动轮椅线上用户评论需求的神经网络模型;情感预训练深度学习模型为SKEP、BERT、Word2Vec中的任意一种。
例如,基于情感预训练模型(Sentiment Knowledge Enhanced Pre-training forSentiment Analysis,SKEP),使用双向Transformer编码器模块构建用于评论需求抽取的神经网络模型。构建得到的神经网络模型的输入端设置为输入数据集中的评论文本,输出端设置为输出电动轮椅的功能需求属性与用户情感需求观点。SKEP的结构和计算过程如图3所示。其中,图3中CLS表示序列的开始,[CLS]
步骤2、训练模型。其中,基于得到的BIO标注训练集进行模型训练。具体的:采用模型数据集训练用于抽取电动轮椅线上用户评论需求的神经网络模型,得到训练好的神经网络模型。
例如,将训练集输入SKEP模型中对文本进行编码,输出对应的token格式向量,基于数据标签预测向量每个部分的输出标签。模型训练阶段的参数配置如下表1所示。
表1 SKEP参数设计表
步骤3、验证模型。其中,基于得到的测试集进行模型测试。使用精确率(Precision)、召回率(Recall)、F1值作为评价指标,这三者的计算公式如式(1)至式(3)所示。
(1)。
(2)。
(3)。
式中,TP(True Positive)是模型提取的用户需求中真正属于用户需求的评论数量,FP(False Positive)是模型提取的用户需求中不属于真正用户需求的评论数量,FN(False Negative)是模型标记为非用户需求中但实际为用户需求的评论数量。
当F1大于等于0.8,则认定为合格,训练结束得到可用模型(即训练好的神经网络模型)。当F1小于0.8时,则认为训练不合格,此时增加人工标注数据扩充训练集。例如,继续增加100条自制人工标注模型数据集,以重新训练模型。每次增加100条标注模型数据集,反复迭代,至达到目标指标数据为止。
第三阶段:抽取用户需求。具体实现过程为:将文本数据集输入训练好的神经网络模型(即可用模型),提取用户需求关联的电动轮椅特征(即产品特征)及与特征对应的用户需求。这一过程中,需要整理得到产品部件特征及与之相对应的用户功能与情感需求。这一模型计算过程如图4所示。
其中,语义识别主要是为了进行需求提取,需求提取的结果中,功能需求包括:外观、折叠、座椅等等。与外观对应的情感需求特征包括:时尚、灵巧、漂亮、不错、轻巧、不便、很重、喜欢、开心、好用、美观、轻盈、喜欢、满意、靓丽、改进、小巧、牢固、可靠、贴心、靓眼、笨拙、大气、美、舒服、亮丽、美丽、特别好、很好、玲珑、灵活、简约、大气、精美、新、时尚、稳固、坚实、一般、小巧、优质、拉风、真好、简单、高、还可以、不错、干净、好、精致、稳、简洁、结实、实用、方便、容易、新颖、瘦、好看、非常好、还行、没有、便捷、可以、扎实、高大、流畅、大、耐用、顺、轻、顺畅、挺好、精巧等等。与折叠对应的情感需求特征包括:卡顿、便携、便宜、容易、不错、漂亮、轻巧、响、不便、舒服、带劲、开心、紧、好用、没、美观、满意、节约、小、费力、随地、省力、皮实、省、顺手、占地方、舒服、顺利、轻松、不能、紧凑、很好、玲珑、灵活、麻烦、方便、不好、简易、小巧、吃力、舒适、简单、赞、不占地、简单、快捷、不太容易、快速、好、精致、顺畅、稳、简洁、实用、结实、方、还、方便、进、容易、舒适、稳当、优化、合适、愉快、简便、好看、普、体验、非常好、还行、没有、便捷、费劲、可以、重、省事、快速、轻便、便利、划算、顺、耐用、挺轻、可爱、挺好、精巧等等。与座椅对应的情感需求特征包括:不多、宽裕、有、舒服、敦实、不错、体验、非常好、还好、开心、可以、喜欢、满意、窄、非、好、宽敞、结实、时尚、透气、方便、没问、耐用、舒适、柔软、顺畅等等。将功能需求与情感需求结合,整合得到用户情感偏好需求与功能需求(即需求归类)。其中,情感偏好需求包括:时尚、灵巧、漂亮、轻巧、好用、美观、轻盈、靓丽、可靠、贴心、靓眼、笨拙、舒服、亮丽、美丽、简约、大气、精美、稳固、坚实、小巧、拉风、精致、简洁、新颖、好看、流畅、精巧、带劲、皮实、玲珑、稳当、顺畅、可爱、灵活、柔软、敦实、方便、稳固、扎实、高大、安全、耐用、亲切、高效、协调、舒适、高档、智能、现代、先进、圆润、移动、组合、方便、易用、整齐、创新、个性化、干净的、独特、精密、趣味、厚重、明亮、功能等等。功能需求包括:扶手方便、性能优越、折叠便携、座椅舒服、续航持久、重量轻盈、底盘扎实、功能卓越、设计贴心、电池耐用、踏板稳定、操作方便、品牌好、车架牢固、车座柔软、坐着舒适、行动静音、蓝牙播放、语音交互、收音机、仪表显示、影音播放、便于安装与拆卸、控制简单、操作简单、便于调速、参数调整功能、踏板宽大、新手指导功能、常用快捷键、手机充电、环境警示、安全保护、刹车灵敏、防止倾翻、行驶保护、入座轻松、座椅舒适性、环保材质、座椅靠背可调节、减重功能、折叠收纳功能、免弯腰充电、越障功能、长时续航、座椅调节、爬楼功能、转向灵活、储物功能、遥控功能、安全带舒适、手机支架等等。
第四阶段:整合输出电动轮椅创新设计优化策略。具体实现过程为:结合设计开发方向和专家知识,从情感偏好需求表中选取3-6个维度的关键感性词汇,如外观维度:时尚、高端、简洁等;操作维度:流畅、方便、智能等;结构:稳固、精密、安全等;体验维度:舒适、灵活、轻盈等。
结合设计开发方向和专家知识,从功能需求表中选取对应各轮椅特征的关键且新颖的功能需求作为优化方向,如折叠便携、免弯腰充电、手机支架、影音播放、手机充电、环境警示、安全保护等。
整合关键感性词汇和功能需求,得到电动轮椅创新设计策略。如关键造型意象:时尚、智能、精密、舒适;关键功能需求:性能优越、折叠便携、座椅舒服可调节、续航持久、重量轻盈、底盘扎实、免弯腰充电、手机支架、影音播放、手机充电、环境警示、安全保护等。
基于上述描述,本发明通过爬虫技术实现网上电商平台上用户评论文本的数据爬取与清洗。从文本数据中随机选取少量文本条,采用BIO标注方法,通过人工标注对其进行产品功能特征和用户需求特征的标注。将标注后的文本条与飞桨(PaddlePaddle)发布的情感分析评估维度和观点抽取Demo数据结合构建模型数据集。构建SKEP,输入模型数据集进行训练和测试,从而得到了电动轮椅用户评论文本的神经网络情感分析模型。基于该模型,输入从网络电商平台用户评论中获取的海量文本数据,从而实现精准、快速地对用户需求特征进行识别与分类,抽取用户需求关联的电动轮椅特征及与之相应的用户需求观点。
可见,本发明基于深度学习和文本分析进行用户需求的智能挖掘与筛选,实现了从电商平台上生成的电动轮椅用户评论中有效抽取用户需求信息,为大数据背景下快速、精准、智能地提取电动轮椅的用户需求提供了方法,解决了传统用户需求挖掘方法广度与深度不足、成本较高、时效性不足等问题。同时,基于情感预训练模型,通过结合飞桨(PaddlePaddle)发布的情感分析评估维度和观点抽取Demo数据,通过少样本标注实现细粒度的文本情感分析,在少量标注的情况下迅速完成情感分析模型的训练,实现精准、快速的用户需求特征识别与分类,从而正确抽取电动轮椅特征及与之相应的用户观点,为企业和设计师开发新产品提供了快速、准确地获取和聚焦用户需求的技术支持。
进一步,本发明还提供了以下实施结构。
一种电动轮椅用户需求提取系统,应用于上述的电动轮椅用户需求提取方法。该系统包括:数据集构建模块、网络模型构建模块、网络模型训练模块、用户需求提取模块和设计策略输出模块。
数据集构建模块,用于收集线上用户评论并进行小样本标注,构建电动轮椅用户需求数据集;电动轮椅用户需求数据集包括文本数据集和模型数据集;小样本为样本条数不超过500条的样本。
网络模型构建模块,基于情感预训练深度学习模型,构建用于抽取电动轮椅线上用户评论需求的神经网络模型;情感预训练深度学习模型为SKEP、BERT、Word2Vec中的任意一种。
网络模型训练模块,用于采用模型数据集训练用于抽取电动轮椅线上用户评论需求的神经网络模型,得到训练好的神经网络模型。
用户需求提取模块,用于将文本数据集输入至训练好的神经网络模型,抽取文本数据集中的电动轮椅部件特征及与电动轮椅部件特征对应的用户需求情感特征。
设计策略输出模块,用于整合电动轮椅部件特征及与电动轮椅部件特征对应的用户需求情感特征,得到电动轮椅创新设计策略。
一种电子设备,该电子设备包括:存储器和处理器。
存储器,用于存储计算机程序。
处理器,与存储器连接,用于调取并执行计算机程序,以实施上述的电动轮椅用户需求提取方法。
此外,上述的存储器中的计算机程序通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器、随机存取存储器、磁碟或者光盘等各种可以存储程序代码的介质。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种数据特征提取方法、系统及电子设备和存储介质
- 一种三维立体环绕式仿真电动轮椅及其工作方法
- 一种三维空间投影具有机械手的仿真电动轮椅及其工作方法
- 集成化电动轮椅控制系统及电动轮椅开机自检方法和童锁方法
- 一种基于特征空间的用户需求精准提取系统及方法