一种基于代码变更和测试历史的测试用例优先级排序方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于软件工程中的软件测试领域,尤其涉及一种基于代码变更和测试历史的测试用例优先级排序方法。
背景技术
测试用例优先级排序是指对软件测试中的测试用例按照一定的规则或标准进行排列,以便测试团队在有限的资源下更有效地执行测试,减少测试时间和资源的浪费。测试用例排序包括基于覆盖率排序、基于变更信息排序、基于深度学习方法排序等研究。
现有研究大多使用深度学习方法构建模型预测测试用例的是否能发现缺陷,其中最常见的策略是基于历史执行信息训练缺陷预测模型。然而已有的基于历史执行信息的方案使用的信息较为简单,忽略了代码变更信息,并且需要测试用例具有足够的历史执行长度,也没有考虑测试用例之间的区别。
发明内容
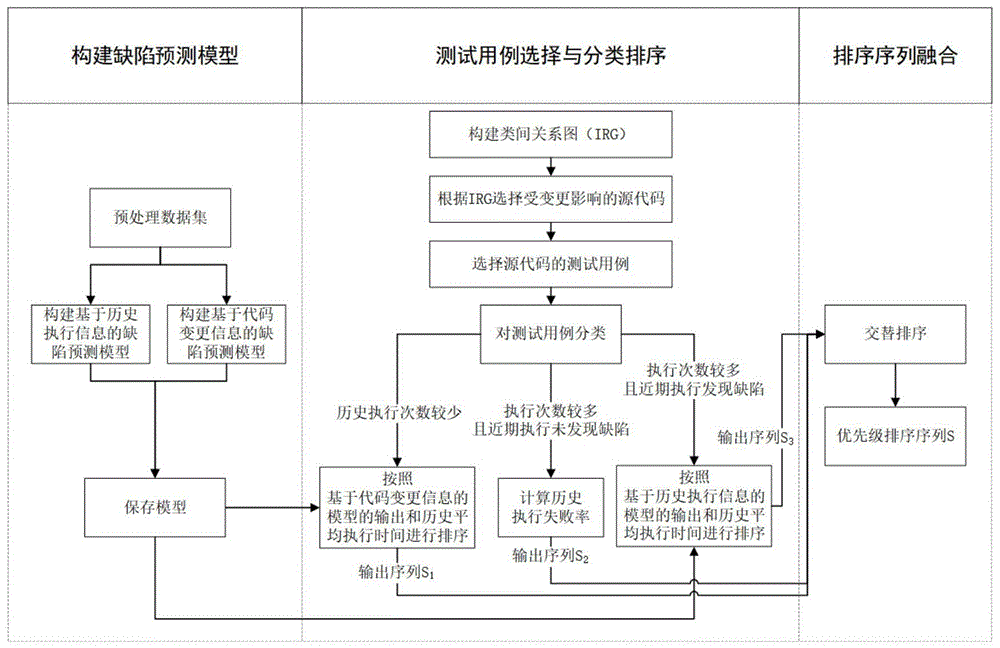
本发明提出了一种基于代码变更和测试历史的测试用例优先级排序方法,首先收集基于代码变更信息和历史执行信息的测试用例数据集,针对两类测试用例特点,采用深度学习方法,分别为两类测试用例构建缺陷预测模型;然后基于类间关系图确定受代码变更影响的源代码,选择其测试用例,结合近期发现过缺陷的测试用例根据执行次数和缺陷发现情况分类,对历史执行次数较少和执行次数较多且近期执行发现缺陷的测试用例根据相应的预测模型的输出和历史平均执行时间排序,对执行次数较多且近期执行发现缺陷的测试用例根据其失败率排序;最后,对分类排序得到的三个序列采用交替排序方法,融合为一个测试用例序列。实验证明,该方法具有更好的排序效果。
为了实现上述目的,本发明采用一种基于代码变更和测试历史的测试用例优先级排序方法,包括以下三大步骤:
步骤1,针对两类测试用例分别构建缺陷预测模型;
所述步骤1,针对两类测试用例分别构建缺陷预测模型,包含以下步骤:
步骤1.1,针对执行次数较少的测试用例,构建基于代码变更信息的缺陷预测模型,模型根据代码变更信息预测测试用例能否发现缺陷;
对于执行次数较少的测试用例,因为其历史执行次数较少,仅仅通过有限的历史执行信息可能无法准确预测能否发现缺陷,所以可以基于CodeBERT模型训练基于代码变更信息的缺陷预测模型,通过学习测试用例和代码变更之间的语义联系预测测试用例能否发现缺陷;
步骤1.2,针对执行次数较多且近期执行发现缺陷的测试用例,构建基于历史执行信息的缺陷预测模型;
对于这类测试用例,可以在持续集成环境的历史执行信息中获取到测试用例的历史执行结果、平均执行时长、所含方法数等信息,通过这些特征预测测试用例能否发现缺陷;
步骤2,基于类间关系图选择受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T,对T中测试用例分类进行排序,得到三个序列S
在持续集成环境中提交一次更改后,在测试时需要选择出受到变更影响的测试用例,并确定测试用例间的的优先级,因此通过静态分析的方法,利用类间关系图选择受变更影响的所有源代码,再选择出这些代码的测试用例以及近期执行发现缺陷的测试用例,针对测试用例的特点分类进行排序。
所述步骤2,基于类间关系图选择受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T,对T中测试用例分类进行排序,得到三个序列S
步骤2.1,通过静态分析源代码构建出类间关系图,根据类间关系图选择受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T;
步骤2.2,对于T中历史执行次数较少的测试用例,按照基于代码变更信息的缺陷预测模型的输出作为第一关键字降序排列,历史平均执行时间作为第二关键字升序排列得到序列S
步骤2.3,对于T中执行次数较多且近期执行未发现缺陷的测试用例采用启发式方法,计算其历史执行失败率,并根据失败率降序排列得到序列S
步骤2.4,对于T中执行次数较多且近期执行发现缺陷的测试用例,按照基于历史执行信息的缺陷预测模型的输出作为第一关键字降序排列,历史平均执行时间作为第二关键字升序排列得到序列S
步骤3,采用交替排序方法将步骤2得到的三个序列S
所述步骤3,采用交替排序方法将步骤2得到的三个序列S
步骤3.1,首先将序列S
大部分情况下基于历史执行信息的优先级缺陷预测模型准确率更高,因此要保证其中的测试用例比其他两个序列中的测试用例优先级更高。
步骤3.2,将序列S
步骤3.3,依次将S
步骤3.4,针对S
对于执行次数较多且近期执行未发现缺陷的测试用例,其最近若干次的执行结果都为通过,那么下一次同样为通过的概率较高,检测到缺陷的概率就较低,因此在序列S中优先级最低,需要插入到序列S的尾部;
最终得到优先级排序序列S。
附图说明
图1为本发明方法的总体流程示意图。
具体实施方式
为了更清楚地展示本发明的目的和技术方案,下面将结合附图更加详细地说明本发明的具体实施方式。
为了实现上述目的,本发明采用一种基于代码变更和测试历史的测试用例优先级排序方法,包括以下三大步骤:
步骤1,针对两类测试用例分别构建缺陷预测模型;
该步骤通过深度学习方法对执行次数较少和执行次数较多且近期执行发现缺陷的两类测试用例分别训练缺陷预测模型,预测这两类测试用例能否发现缺陷。
所述步骤1,针对两类测试用例分别构建缺陷预测模型,包含以下步骤:
步骤1.1,针对执行次数较少的测试用例,构建基于代码变更信息的缺陷预测模型,模型根据代码变更信息预测测试用例能否发现缺陷;
所述训练缺陷预测模型是指,在预处理后的RTPTorrent数据集上,通过代码变更信息特征,训练一个监督学习模型,预测测试用例能否发现缺陷;
所述代码变更信息是指,持续集成环境下,一次提交中所修改的文件数量、最近变更类名字和全部变更文件名字;
步骤1.2,针对执行次数较多且近期执行发现缺陷的测试用例,构建基于历史执行信息的缺陷预测模型;
所述训练缺陷预测模型是指,在预处理后的RTPTorrent数据集上,通过基于历史执行信息特征,训练一个监督学习模型,预测测试用例能否发现缺陷;
所述历史执行信息是指,回归测试方法中测试用例的历史执行结果、测试用例的方法数和平均执行时长;
步骤2,基于类间关系图选择受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T,对T中测试用例分类进行排序,得到三个序列S
该步骤通过静态分析源代码来构建类间关系图,再基于类问关系图选择所有受代码变更影响的源代码,选择这些代码的测试用例,根据测试用例的执行次数和近期缺陷发现情况将这些测试用例分为三个类别,针对每个类别的特点分别设计排序方法。
所述步骤2,基于类间关系图选择受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T,对T中测试用例分类进行排序,得到三个序列S
步骤2.1,通过静态分析源代码构建出类间关系图,根据类间关系图选择所有受代码变更影响的源代码,选择这些代码的测试用例以及最近发现缺陷的测试用例集合T;
步骤2.2,对于T中历史执行次数较少的测试用例,按照基于代码变更信息的缺陷预测模型的输出作为第一关键字降序排列,历史平均执行时间作为第二关键字升序排列得到序列S
步骤2.3,对于T中执行次数较多且近期执行未发现缺陷的测试用例采用启发式方法,计算其历史执行失败率,并根据失败率降序排列得到序列S
所述历史执行失败率是指测试用例的HFR(公式1),其中
步骤2.4,对于T中执行次数较多且近期执行发现缺陷的测试用例,按照基于历史执行信息的缺陷预测模型的输出作为第一关键字降序排列,历史平均执行时间作为第二关键字升序排列得到序列S
步骤3,采用交替排序方法将步骤2得到的三个序列S
该步骤将步骤2中的三个序列,通过交替排序方法融合为一个序列。
所述步骤3,采用交替排序方法将步骤2得到的三个序列S
步骤3.1,将序列S
如S
步骤3.2,将序列S
如S
步骤3.3,依次将S
将S
步骤3.4,针对S
如S
最终得到优先级排序序列S。
- 一种上位多目标测试用例优先级排序方法
- 一种基于代码和组合覆盖的测试用例优先级排序方法及测试系统
- 一种基于改进粒子群算法的测试用例优先级排序方法