基于LSTM模型的语音特征单元提取的改进型智慧工单系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及工单组合技术领域,具体地说,涉及基于LSTM模型的语音特征单元提取的改进型智慧工单系统。
背景技术
在运维领域中,存在着一系列困难和挑战,包括历史遗留问题、复杂的系统架构、不断的业务需、人员的不足以及安全方面的难点,运维人员需要不断学习新技术、更新知识,同时加强沟通和合作,保障系统的高可用和安全,为了克服这些问题,运维人员需要有高水平的技术能力和专业素养,同时需要具备灵活性和创新能力。
运维工单系统在使用的过程中存在以下问题:运维工单系统存在多个子系统,多个子系统中存在的数据样式不同,如文本数据、音频数据等,文本数据便于处理,但音频数据在处理的时,无法和文本数据进行整合,进而导致信息和数据传递困难,造成沟通和处理问题的困扰,而为了使多个子系统的之间的信息整合在一起,需要工作人员对每个子系统中的数据进行提取,然后再将多个子系统的数据整合起来,如此来回增加工作人员的工作量,同时也会延长每个子系统之间数据沟通的时间,故需要一种系统来将多个子系统中的数据进行整合,降低工作人员的工作量。
发明内容
本发明的目的在于提供基于LSTM模型的语音特征单元提取的改进型智慧工单系统,以解决上述背景技术中提出的问题。
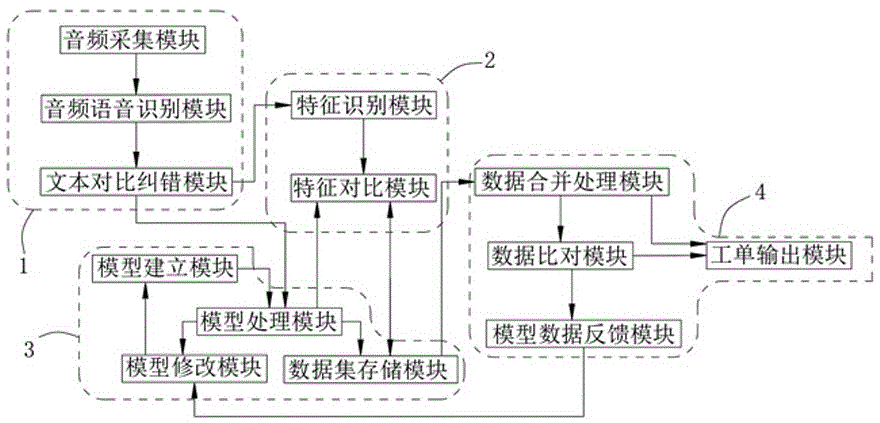
为实现上述目的,本发明提供基于LSTM模型的语音特征单元提取的改进型智慧工单系统,包括音频处理单元、特征提取单元、模型运行单元和工单输出单元;
所述音频处理单元接收音频数据,并根据音频数据的内容进行文本内容识别;
所述模型运行单元接收音频处理单元识别出的文本数据,并根据建立的模型对本文数据进行处理,并在数据处理后,将数据传输到特征提取单元中;
所述特征提取单元分别接收音频处理单元传输的文本数据以及模型运行单元传输的数据,并分别对音频处理单元和模型运行单元传输来的数据进行特征的提取,并将提取的数据传输到模型运行单元中进行存储;
所述工单输出单元接收模型运行单元中存储的数据,并对特征提取单元对音频处理单元、模型运行单元提取的数据进行数据对比,并在对比完成后,向模型运行单元中进行模型修改反馈,并在工单输出单元的对比一致后,进行工单的输出。
作为本技术方案的进一步改进,所述音频处理单元包括音频采集模块、音频语音识别模块和文本对比纠错模块;
所述音频采集模块对不同端的音频数据进行采集,获取音频数据内容;
所述音频语音识别模块对音频采集模块采集到的音频数据中的内容进行识别,获取音频数据对应的文本信息数据;
所述文本对比纠错模块接收音频语音识别模块中获取的文本信息数据以及音频采集模块中获取的音频数据,并将音频数据和文本信息数据进行对比,并在对比出现错误时,对文本信息数据进行修改。
作为本技术方案的进一步改进,所述模型运行单元包括模型建立模块和模型处理模块;
所述模型建立模块通过LSTM算法建立特征提取模型,并将建立的特征提取模型传输到模型处理模块中;
所述模型处理模块接收文本对比纠错模块核对后的文本信息数据,并通过特征提取模型对文本数据中的特征进行提取,获取文本信息数据中的特征数据。
作为本技术方案的进一步改进,所述特征提取模型对文本数据中的特征进行提取的步骤为:
①、首先进行第一次对文本信息数据进行特征提取,提取的信息标记为第一次数据;
②、将第一次数据进行选择性的遗忘,并在将第一次的数据遗忘后,进行第二次对文本信息数据的特征提取,并在提取时将对本次的信息提取中没有意义的数据进行剔除,获取第二次数据;
③、将第一次数据与第二次数据的信息进行叠加,并将叠加后的数据中的特征数据整合在一起,即第一次数据与第二次数据中相同的特征数据进行合并,不同的特征数据进行整合,整合在一起的数据定义为第二次完整数据;
④、对③叠加后的数据进行选择性的遗忘,并在遗忘后,对文本信息数据的特征进行第三次提取,并将第三次提取的数据和第二次完整数据进行叠加,获取第三次完整数据;
⑤、重复③、④的步骤,将前面获取的数据和新形成的数据进行叠加,直到新形成的数据中的特征数据都在前面叠加的数据中,此时停止对特征进行提取,并将叠加后的数据进行输出。
作为本技术方案的进一步改进,所述模型运行单元还包括数据集存储模块;
所述数据集存储模块存储往期的工单数据,并同时接收模型处理模块处理后的数据,并对模型处理模块处理数据的步骤进行记录,并接收特征提取单元传输来的数据,并将特征提取单元传输来的数据信息存储。
作为本技术方案的进一步改进,所述特征提取单元包括特征识别模块和特征对比模块;
所述特征识别模块接收文本对比纠错模块传输出来的文本数据,并对文本数据中的关键词汇进行识别,获取最大范围的特征数据;
所述特征对比模块接收模型处理模块和特征识别模块中的数据,并将模型处理模块、特征识别模块中的数据和数据集存储模块中存储的数据进行对比,确定数据集存储模块中是否存储有相同或相似的数据,并当存在相同或相似的数据时,对特征识别模块和模型处理模块中与数据集存储模块中相同或相似的数据进行标记,并在数据标记后,特征对比模块将模型处理模块和特征识别模块传输的数据传输到数据集存储模块中进行存储。
作为本技术方案的进一步改进,所述工单输出单元包括数据合并处理模块、数据比对模块和工单输出模块;
所述数据合并处理模块接收数据集存储模块传输的数据,并将数据集存储模块传输来的数据中特征识别模块和模型处理模块传输的数据中相同的特征进行合并,并在合并后将合并的数据传输到工单输出模块中,同时将未合并的数据传输到数据比对模块中;
所述数据比对模块接收数据合并处理模块传输来的未进行合并的数据,并将未进行合并的数据进行相互的对比,并在对比的过程中,确定未合并的数据之间的差异;
所述工单输出模块接收数据合并处理模块中合并的数据以及数据比对模块中差异较小的数据,并根据接收的数据进行工单的制作,并将制作的工单数据进行传输。
作为本技术方案的进一步改进,所述模型运行单元包括模型修改模块,所述工单输出单元包括模型数据反馈模块;
所述模型数据反馈模块接收数据比对模块中差异较大的特征数据,并将差异较大的数据进行识别,确定差异较大的特征数据对应文本数据中的内容数据,并将该部分内容数据传输到模型修改模块中;
所述模型修改模块接收模型数据反馈模块传输来的数据,并根据模型数据反馈模块中的传输内容,从本文信息数据中提取出此段内容,并将此段内容传输到模型建立模块中,使模型建立模块根据此段内容以及差异较大的特征数据进行模型的修改。
与现有技术相比,本发明的有益效果:
1、该基于LSTM模型的语音特征单元提取的改进型智慧工单系统中,通过音频处理单元将音频数据转化为文本数据,并通过模型运行单元对音频处理单元获取并处理,获取文本数据中的特征,再通过工单输出单元根据提取的特征数据进行工单的制作,如此来使多个子系统中的音频数据整合在一起,做到特征的准确提取,如此来方便后续工作人员对每个子系统数据的整合,加快工作人员整合每个系统的速度。
2、该基于LSTM模型的语音特征单元提取的改进型智慧工单系统中,通过特征提取单元接收音频处理单元中的文本数据,并根据文本数据进行特征提取,同时接收模型处理模块处理的数据,将模型处理模块处理的数据以及特征提取单元提取出的特征数据存储到数据集存储模块中,并通过工单输出单元进行判断,将差异较大的数据通过模型数据反馈模块进行反馈,使模型修改模块根据反馈的内容控制模型建立模块对模型进行调整,如此来提高模型对文本数据中的特征数据提取的准确性,做到模型的不断优化,如此来帮助工作人员对子系统中的数据的处理,也便于后续工作人员对每个子系统中的数据进行整合。
附图说明
图1为本发明实施例1的整体框图;
图2为本发明实施例1的音频处理单元框图;
图3为本发明实施例1的特征提取单元框图;
图4为本发明实施例1的模型运行单元框图;
图5为本发明实施例1的工单输出单元框图;
图6为本发明实施例1的整体组合框图。
图中各个标号意义为:
1、音频处理单元;11、音频采集模块;12、音频语音识别模块;13、文本对比纠错模块;
2、特征提取单元;21、特征识别模块;22、特征对比模块;
3、模型运行单元;31、模型建立模块;32、模型处理模块;33、数据集存储模块;34、模型修改模块;
4、工单输出单元;41、数据合并处理模块;42、数据比对模块;43、工单输出模块;44、模型数据反馈模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
运维工单系统在使用的过程中存在以下问题:运维工单系统存在多个子系统,多个子系统中存在的数据样式不同,如文本数据、音频数据等,文本数据便于处理,但音频数据在处理的时,无法和文本数据进行整合,进而导致信息和数据传递困难,造成沟通和处理问题的困扰,而为了使多个子系统的之间的信息整合在一起,需要工作人员对每个子系统中的数据进行提取,然后再将多个子系统的数据整合起来,如此来回增加工作人员的工作量,同时也会延长每个子系统之间数据沟通的时间,故需要一种系统来将多个子系统中的数据进行整合,降低工作人员的工作量。
本发明提供基于LSTM模型的语音特征单元提取的改进型智慧工单系统,请参阅图1-图6所示,包括音频处理单元1、特征提取单元2、模型运行单元3和工单输出单元4;
音频处理单元1接收音频数据,并根据音频数据的内容进行文本内容识别,通过将音频数据内的内容进行识别并转换为文本的形式,以便于根据文本数据进行特征数据的提取,使工单输出单元4便于进行工单数据的整合处理,同时将音频数据转化为文本的形式,使多个子系统之间的数据便于相互传输和识别,加快每个子系统之间的数据传输;
音频处理单元1包括音频采集模块11、音频语音识别模块12和文本对比纠错模块13;
音频采集模块11对不同端的音频数据进行采集,获取音频数据内容,同时在音频采集模块11采集音频数据的过程中,对获取的音频数据进行去噪和降噪操作,去除音频数据中影响文本识别的内容,以提高后续处理的准确性;
音频语音识别模块12对音频采集模块11采集到的音频数据中的内容进行识别,获取音频数据对应的文本信息数据;
文本对比纠错模块13接收音频语音识别模块12中获取的文本信息数据以及音频采集模块11中获取的音频数据,并将音频数据和文本信息数据进行对比,提高音频语音识别模块12获取的音频数据对应的文本信息数据的准确性,并在对比出现错误时,对文本信息数据进行修改,如此来提高音频数据转换文本信息数据的准确性,以便于后续对音频语音识别模块12获取的文本信息数据进行处理。
模型运行单元3接收音频处理单元1识别出的文本数据,并根据建立的模型对本文数据进行处理,并在数据处理后,将数据传输到特征提取单元2中;
模型运行单元3包括模型建立模块31和模型处理模块32;
模型建立模块31通过LSTM算法建立特征提取模型,并将建立的特征提取模型传输到模型处理模块32中,模型建立模块31建立的模型为不固定的模型,在对数据处理的过程中,当模型处理的数据出现问题时,以便于对模型进行修改;
模型处理模块32接收文本对比纠错模块13核对后的文本信息数据,并通过特征提取模型对文本数据中的特征进行提取,获取文本信息数据中的特征数据;
特征提取模型对文本数据中的特征进行提取的步骤为:
①、首先进行第一次对文本信息数据进行特征提取,提取的信息标记为第一次数据;
②、将第一次数据进行选择性的遗忘,并在将第一次的数据遗忘后,进行第二次对文本信息数据的特征提取,并在提取时将对本次的信息提取中没有意义的数据进行剔除,获取第二次数据;
③、将第一次数据与第二次数据的信息进行叠加,并将叠加后的数据中的特征数据整合在一起,即第一次数据与第二次数据中相同的特征数据进行合并,不同的特征数据进行整合,整合在一起的数据定义为第二次完整数据;
④、对③叠加后的数据进行选择性的遗忘,并在遗忘后,对文本信息数据的特征进行第三次提取,并将第三次提取的数据和第二次完整数据进行叠加,获取第三次完整数据;
⑤、重复③、④的步骤,将前面获取的数据和新形成的数据进行叠加,直到新形成的数据中的特征数据都在前面叠加的数据中,此时停止对特征进行提取,并将叠加后的数据进行输出。
通过采用LSTM算法建立的特征提取模型能够处理用户的多次输入后的特征提取,将提取出来的特征进行组合,同时也可以对一组数据进行多次的特征提取,并在输出的过程中逐步修正结果,提高对数据特征提取的准确度。
模型运行单元3还包括数据集存储模块33;
数据集存储模块33存储往期的工单数据,并同时接收模型处理模块32处理后的数据,并对模型处理模块32处理数据的步骤进行记录,并接收特征提取单元2传输来的数据,并将特征提取单元2传输来的数据信息存储,通过记录每次模型处理模块32处理数据的步骤,来判断模型建立模块31建立的模型对文本数据进行特征提取的情况,当模型处理模块32处理数据的步骤少,则代表模型建立模块31建立的模型提取文本数据中的特征效果好,反之,则建立的模型提取特征的效果不好。
特征提取单元2分别接收音频处理单元1传输的文本数据以及模型运行单元3传输的数据,并分别对音频处理单元1和模型运行单元3传输来的数据进行特征的提取,并将提取的数据传输到模型运行单元3中进行存储;
特征提取单元2包括特征识别模块21和特征对比模块22;
特征识别模块21接收文本对比纠错模块13传输出来的文本数据,并对文本数据中的关键词汇进行识别,获取最大范围的特征数据;
特征对比模块22接收模型处理模块32和特征识别模块21中的数据,并将模型处理模块32、特征识别模块21中的数据和数据集存储模块33中存储的数据进行对比,确定数据集存储模块33中是否存储有相同或相似的数据,并当存在相同或相似的数据时,对特征识别模块21和模型处理模块32中与数据集存储模块33中相同或相似的数据进行标记,并在数据标记后,特征对比模块22将模型处理模块32和特征识别模块21传输的数据传输到数据集存储模块33中进行存储。
工单输出单元4接收模型运行单元3中存储的数据,并对特征提取单元2对音频处理单元1、模型运行单元3提取的数据进行数据对比,并在对比完成后,向模型运行单元3中进行模型修改反馈,并在工单输出单元4的对比一致后,进行工单的输出;
工单输出单元4包括数据合并处理模块41、数据比对模块42和工单输出模块43;
数据合并处理模块41接收数据集存储模块33传输的数据,并将数据集存储模块33传输来的数据中特征识别模块21和模型处理模块32传输的数据中相同的特征进行合并,并在合并后将合并的数据传输到工单输出模块43中,同时将未合并的数据传输到数据比对模块42中;
数据比对模块42接收数据合并处理模块41传输来的未进行合并的数据,并将未进行合并的数据进行相互的对比,并在对比的过程中,确定未合并的数据之间的差异,当数据之间的差异较小,如仅属于不同词汇描述相同的名词时,则将该类数据进行整合并传输到工单输出模块43中;
工单输出模块43接收数据合并处理模块41中合并的数据以及数据比对模块42中差异较小的数据,并根据接收的数据进行工单的制作,并将制作的工单数据进行传输;
通过数据比对模块42对比数据后,将特征提取单元2处理的数据和模型运行单元3处理的数据的相同内容进行工单的制作,以确保制作出来的工单内容的准确性,以便于工作人员对多个子系统的工单内容进行处理,方便工作人员对数据的整合。
通过音频处理单元1将音频数据转化为文本数据,并通过模型运行单元3对音频处理单元1获取并处理,获取文本数据中的特征,再通过工单输出单元4根据提取的特征数据进行工单的制作,如此来使多个子系统中的音频数据整合在一起,做到特征的准确提取,如此来方便后续工作人员对每个子系统数据的整合,加快工作人员整合每个系统的速度。
模型运行单元3包括模型修改模块34,工单输出单元4包括模型数据反馈模块44;
模型数据反馈模块44接收数据比对模块42中差异较大的特征数据,并将差异较大的数据进行识别,确定差异较大的特征数据对应文本数据中的内容数据,并将该部分内容数据传输到模型修改模块34中;
模型修改模块34接收模型数据反馈模块44传输来的数据,并根据模型数据反馈模块44中的传输内容,从本文信息数据中提取出此段内容,并将此段内容传输到模型建立模块31中,使模型建立模块31根据此段内容以及差异较大的特征数据进行模型的修改。
通过特征提取单元2接收音频处理单元1中的文本数据,并根据文本数据进行特征提取,同时接收模型处理模块32处理的数据,将模型处理模块32处理的数据以及特征提取单元2提取出的特征数据存储到数据集存储模块33中,并通过工单输出单元4进行判断,将差异较大的数据通过模型数据反馈模块44进行反馈,使模型修改模块34根据反馈的内容控制模型建立模块31对模型进行调整,如此来提高模型对文本数据中的特征数据提取的准确性,做到模型的不断优化,如此来帮助工作人员对子系统中的数据的处理,也便于后续工作人员对每个子系统中的数据进行整合。
通过特征提取单元2对音频处理单元1以及模型运行单元3中的数据分别进行特征的提取,再由工单输出单元4对分别提取的数据进行对比,如此来判断模型运行单元3建立的模型是否正确,并在模型出现错误时对模型进行修复,使模型得到更新,以便于模型的后续使用,同时在工单输出单元4对比后,将不同工单中的数据组合在一起,使音频处理单元1采集的不同位置的数据整合起来,做到数据的统一处理,如此来方便运维人员对数据的处理,提高运维人员的工作效率和工作质量。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 基于LSTM和手工特征实现动作分类的方法、系统
- 基于LSTM和手工特征实现动作分类的方法、系统