农业灌区蒸散量和水位预测方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于农业预测技术领域,具体涉及一种农业灌区蒸散量预测方法和一种农业灌区水位预测方法。
背景技术
智慧农业将现代信息科学技术与传统农业相结合,旨在实现农业生产的智能化、信息化和精准化。目前智慧农业领域取得了较好的发展,例如,Attila等人在2022年设计了一种低成本、低功耗、多传感器的温室大棚物联网监测方案,为小农提供农业自动化监测。Alves于2023年提出了智能灌溉系统的数字孪生应用场景,通过物联网平台收集、处理土壤、天气和作物数据,计算每日灌溉需求,并评估不同的灌溉策略。Loversum和Prince在同年对智慧农业中使用的机器学习算法进行了实验分析。但是智慧农业领域还有诸多方面需要改善。
参考作物蒸散量(ET0)是指在一定条件下,某种参考作物单位面积的蒸散量。ET0是农业、水文学和环境科学中的重要指标,对农业水循环和决策具有重要意义。机器学习等算法在ET0的估算中得到了应用。但是目前的蒸散量估算方法还存在准确率较低的问题。
水位预测是水文、水利和农业等领域研究的热点问题之一。近年来,我国的水利相关学者在水位预测方面展开了许多研究,并取得了一定成果。例如,李燕飞等人提出了一种基于奇异谱分析(SSA)方法、数据处理的群组方法(GMDH)神经网络、基于准确性和多样性的加权积分(WIAD)和核极限学习机(KELM)算法的混合模型,用于预测河水位。王海麟在2022年提出了一种利用卷积径向网络进行多变量水位预测的模型,证明了蒸散量数据在水位预测中的有效性。
当前,水位预测研究主要基于深度学习和神经网络等方法,构建针对单一水位数据的单变量水位预测模型,或者考虑涵盖其他相关因素的多变量水位预测模型。气象参数如温湿度、降雨量、水流量和蒸散量等在提高水位预测精度方面发挥了重要作用。但是目前的水位预测方法的预测准确率低,仍有待于提高。
发明内容
本发明为了解决现有的农业灌区蒸散量预测和水位预测方法存在预测准确率低的问题。
一种农业灌区蒸散量预测方法,利用ET
S101、获取一段时间内监测区域各气象站点的每日气象参数,每日气象参数包括年份Year和日期day,以及对应的气象参数,所述气象参数包括最高气温Tmax和最低气温Tmin,平均相对湿度RH、风速Wind、日照时数SH、太阳辐射通量RAD、光照强度LI;
S102、特征重要性排序及数据划分:
将每个气象站的气象数据分别记为站点数据集;同时基于每个气象站的气象数据,使用FAO-56PM方程分别计算各自对应的蒸散量ET
将所有站点的气象数据集合并组成广义气象数据集;
使用CatBoost算法对每个气象站的气象数据进行气象参数重要度排序,取排序前3的气象参数,将排序相同的气象站归为一类地区,得到多个区域记为区域j,并将同一类地区的数据集合并组成具有特征相关性的区域数据集;
同时取气象参数重要度排序中排序前4的气象参数作为机器学习模型的输入特征;将排序前4的气象参数记为特征气象参数;
S103、训练局部模型、区域模型和广义模型,确定其中最优模型:
选择多个机器学习模型Mi作为预测模型,i为机器学习模型的序号;
基于区域j,提取区域j中每个站点对应的站点数据集,以每个站点为对象,在气象参数中提取特征气象参数作为预测模型的输入特征,输出为预测的ET
同时针对所有区域中每个站点各自对应的局部模型的评价指标确定所有区域构成的全范围下最优的机器学习模型,记为MIJ,将其作为广义模型;
针对区域j,基于对应的区域数据集,在气象参数中提取特征气象参数作为预测模型的输入特征,训练区域模型MIj,同时记录对应的区域模型的测试集评价指标MAE、RMSE、R
同时,基于广义气象数据集,基于对应的区域数据集,在气象参数中提取特征气象参数作为预测模型的输入特征,训练广义模型MIJ;同时记录广义模型的测试集评价指标MAE、RMSE、R
然后对比区域模型的评价指标和每个站点各自对应的局部模型的评价指标选择区域模型或局部模型作为拟确定预测模型;再对比拟确定预测模型的评价指标和广义模型的评价指标作为最终确定的预测模型,得到ET
利用ET
进一步地,所述特征气象参数包括Tmax、RH、Wind和LI。
进一步地,S103中的机器学习模型包括XGboost、随机森林RF和Catboost。
一种农业灌区蒸散量预测方法,利用ET
A101、获取一段时间内监测区域各气象站点的每日气象参数,每日气象参数包括年份Year和日期day,以及对应的气象参数,所述气象参数包括每最高气温Tmax和最低气温Tmin,平均相对湿度RH、风速Wind、日照时数SH、太阳辐射通量RAD、光照强度LI;
A102、特征重要性排序及数据划分:
将每个气象站的气象数据分别记为站点数据集;同时基于每个气象站的气象数据,使用FAO-56PM方程分别计算各自对应的蒸散量ET
使用CatBoost算法对每个气象站的气象数据进行气象参数重要度排序,取排序前3的气象参数,将排序相同的气象站归为一类地区,得到多个区域记为区域j,并将同一类地区的数据集合并组成具有特征相关性的区域数据集;
同时取气象参数重要度排序中排序前4的气象参数作为机器学习模型的输入特征;将排序前4的气象参数记为特征气象参数;
A103、基于区域j,在对应的区域数据集中提取特征气象参数作为预测模型的输入特征,输出为预测的ET
利用ET
进一步地,所述特征气象参数包括Tmax、RH、Wind和LI。
进一步地,S103中的机器学习模型包括XGboost、随机森林RF和Catboost。
一种农业灌区水位预测方法,包括以下步骤:
S201、获取历史的水位数据和蒸散气象数据,所述蒸散气象数据包括最高温度Tmax、最低温度Tmin、相对湿度RH和蒸散量ET0;
S202、使用快速傅里叶变换分析水位数据,得到水位数据主峰的频率结果,然后基于水位数据主峰的频率结果确定时序模型的时序滑动窗口长度N;
S203、采用VMD变分模态分解算法对水位数据进行VMD分解,得到8个分解信号IMF1~IMF8;
基于IMF1~IMF8与蒸散气象数据,使用皮尔逊相关系数法确定与水位数据的相关系数高的IMF1~IMF8中的三个IMF,将三个IMF与蒸散气象数据以及水位数据共计8个特征构成多变量水位预测数据;
S204、训练水位预测模型:
基于历史的8个特征构成多变量水位预测数据和时序滑动窗口长度N,构建(N,8)的特征矩阵作为水位预测模型的输入,以未来水位的预测值为水位预测模型的输出,训练水位预测模型,得到训练好的水位预测模型;所述的水位预测模型的神经网络包括一维卷积神经网络CNN层和一维卷积神经网络CNN层之后设置的GRU网络;
S204、利训练好的水位预测模型对未来水位进行预测;对未来水位进行预测时,输入数据中未来蒸散量数据为利用所述的一种农业灌区蒸散量预测方法预测得到的蒸散量数据。
进一步地,确定时序模型的时序滑动窗口长度N为基于使用快速傅里叶变换分析的主峰3的周期确定的。
进一步地,所述的时序滑动窗口长度N取35天。
进一步地,与水位数据的相关系数高的IMF1~IMF8中的三个IMF为IMF1、IMF6和IMF7。
有益效果:
1、与彭曼方程计算的参考ET0值对比,本发明采用区域模型的农业灌区蒸散量预测方案的预测稳定性更强、精度更高,且只需要四个气象参数就能实现蒸散量ET0的准确估算,降低了蒸散量计算的成本。
2、本发明提出的融合蒸散气象数据的多变量VMD-CNN-GRU模型在水位的多步长预测中预测准确率高,且整体误差偏移更加平稳。
附图说明
图1为黑龙江省气象站分布图。
图2为蒸散量估算模型设计流程图。
图3为特征重要性排序图。
图4为各气象站点区域划分分布图。
图5为区域一模型ET0计算值对比图。
图6为区域二模型ET0计算值对比图。
图7为区域三模型ET0计算值对比图。
图8为VMD模态分解图(哈尔滨数据集)。
图9为VMD模态分解图(七台河数据集)。
图10为CNN-GRU模型结构图。
图11为模型构建整体流程图。
图12为多变量与单变量模型对比图(哈尔滨)。
图13为多变量与单变量模型对比图(七台河)。
图14为各模型预测步长RMSE变化趋势(哈尔滨数据集)。
图15为各模型预测步长RMSE变化趋势(七台河数据集)。
图16为3个局部模型在各区域上的性能对比图。
具体实施方式
本发明旨在分析各气象参数对某省蒸散量估算的贡献度,并帮助选取物联网监测终端的传感器类型,设计一种蒸散量估算模型,然后结合水位数据内部信息和气象参数等多个变量的多变量水位预测模型,分析各气象参数对黑龙江省蒸散量估算的贡献度,并设计物联网监测终端的传感器类型,以进一步提高水位预测精度。下面结合具体实施方式对本发明进行详细说明。
具体实施方式一:
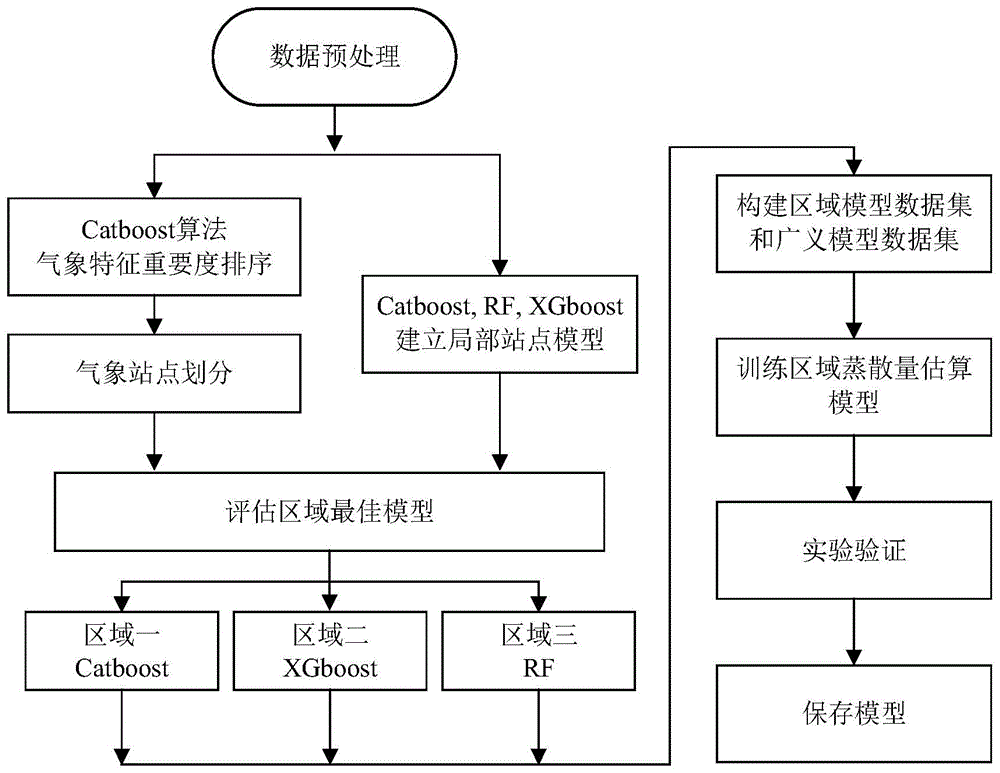
本实施方式为一种农业灌区蒸散量预测方法,通过分析蒸散量与气象参数之间的特征关系,筛选出重要度高的气象参数,为农业灌区水位预测系统提供基础。本实施方式设计了一种基于机器学习区域划分特征划分区域的蒸散量估算模型,仅需要少量气象数据即可完成对蒸散量的估算,大大提高了时间效率;同时,在构建模型前,使用CatBoost对气象数据进行重要性排序,以筛选有效特征,进一步提高模型效率;而且,还通过划分为3个区域构建区域数据集,建立区域蒸散量估算模型,以解决现有广义模型和区域模型方法存在的不足。
本实施方式所述的一种农业灌区蒸散量预测方法,包括以下步骤:
S101、获取数据并进行预处理:
本发明的气象数据包括黑龙江省25个气象站从1960年到2015年的每日气象参数,包括每最高气温(Tmax)和最低气温(Tmin),平均相对湿度(RH)、2米高度的风速(Wind)、日照时数(SH)、太阳辐射通量(RAD)、光照强度(LI)、年和日(Year、day);
黑龙江省地图及25个气象站分布如图1所示。这些数据用于计算标准参考蒸散量值(ET0),是后续机器学习算法的预测目标,计算公式采用联合国粮农组织(FAO)认证的Penman-Monteith方程(FAO-56PM)。部分数据如表1和表2所示。
表1 25个气象站点的数据统计表
表2每日气象数据(以哈尔滨数据集为例)
在蒸散量估算方面,本发明进行了大量的机器学习方法研究,主要有广义模型和局部模型。广义模型将多个气象站的数据合并为一个大的数据集进行分析和训练,选择效果最佳的模型作为整个地域的模型;局部模型针对每个气象站的数据集进行独立训练,通过比较各个模型的表现,选择最适合该气象站点的模型。
这两种方法各有优劣。广义模型的优点是数据集较大,能提高模型对未知数据的适应性和鲁棒性,增强模型稳定性。然而,广义模型的训练时间长,特征选择困难,无法考虑不同地区之间的差异,可能导致蒸散量估算出现偏差。局部模型的优点是训练数据量小,训练时间短,对本地区具有针对性。但局部模型容易过拟合,泛化性能差,特征选择不准确,影响模型性能。
为了解决上述问题,本发明提出了一种按照特征区域划分气象站的方法。即:将多个气象站的数据集划分成不同组合,对每个气象站的气象数据(时间、风速、湿度、最高温、最低温、光照强度和日照时长)进行特征重要度排序,取排序前3的气象参数并记录。将排序相同的气象站归为一类地区,将数据集合并,组成具有特征相关性的区域数据集来训练模型,即区域模型。同时,参考各个气象站点的地理分布情况来判断划分结果的合理性。
本发明提出的ET
预处理后的数据要分成训练数据和测试数据,训练数据用于训练各自对应的机器学习模型,测试数据用于测试机器学习模型的泛化性能。
S102、特征重要性排序及数据划分:
使用FAO-56PM方程计算ET
本发明分别对25个气象站点的气象数据使用CatBoost算法进行特征重要度排序。其特征重要性结果值(保留小数点后两位)如表3所示,特征排序堆叠如图3所示。
表3Catboost特征重要性排序结果表
根据特征排序的结果,可以发现在所有的气象站点上,最高温度(Tmax)都具有十分高的特征重要度,这说明Tmax这个气象参数对整个黑龙江区域蒸散量的计算具有十分重要的影响,在绝大多数蒸散量相关研究的文献描述中,Tmax也是对蒸散量影响力最大的气象参数。同时在大多数站点上,Tmax、RH、Wind和LI都具有较高的特征重要度,因此本发明采用这四种气象参数作为蒸散量估计模型的输入特征。
然后,对每个站点选出重要度排序前三的特征,表2中加粗的字体为特征重要度最高的前三名,将前三名特征排序相同的站点归为同一个区域,这样我们将25个气象站被划分为3类区域,划分结果如表4和图4所示。
表4各气象站区域划分分布表
按照特征划分的结果,分别将3个区域内所包含气象站点的气象数据合并,从而构建出3个区域气象数据集,分别用来训练各自对应的区域模型。同时,将所有25个气象站数据合并,组成一个广义气象数据集,用来训练广义模型。
本发明在建立模型时,根据所排序出的特征重要度结果,选择特征重要度较高的前四个气象参数,即:最高温度、相对湿度、风速、光照强度作为区域模型和广义模型训练的输入特征,其他参数因为重要度较低,对模型贡献度较差则舍弃,这样也能提高模型训练的速度。
同时根据上面实验数据的结果也可以发现,区域一和区域三划分出的气象站之间在地理位置上都是相邻的,这符合在地理位置相近的地方,气候环境相似,其气象数据在机器学习特征排序结果也相同;在区域二划分的各气象站之间分布离散,并没有地理上的相邻关系,这里将它们划分为一类区域是因为这些气象站点的数据集在机器学习排序算法上的表现结果相似,在后文的机器学习模型训练上,区域二的模型整体的表现效果也要优于广义模型和局部模型,这也表明机器学习方法能找到更深层次的相关性关系。
S103、构建、训练局部模型、区域模型和广义模型并进行对比实验:
将3个区域包含气象站点的气象数据采用XGboost、随机森林RF和Catboost等3种算法进行模型训练,使用各区域每个气象站点的气象数据分别建立机器学习模型。具体来说,我们使用区域一中包含的12个气象站点建立12个局部模型,为便于后续说明,将这12个局部模型简称为区域一局部模型,区域二局部模型和区域三局部模型的建立过程与区域一局部模型一致,将这些模型统称为区域局部模型。区域局部模型的输入为气象站点的气象数据,输出为估算的蒸散量ET
表5区域一局部模型训练结果
表6区域二局部模型训练结果
表7区域三局部模型训练结果
区域局部模型的性能对比如图16所示,其中(a)、(b)、(c)分别为区域一、区域二、区域三的R
已经确定好各个区域的最佳算法,接下来进行区域的站点数据融合训练,步骤如下:
(1)区域一所有站点数据集合并,采用Catboost算法训练区域一模型;
(2)区域二所有站点数据合并,采用XGboost算法训练区域二模型;
(3)区域三所有站点数据合并,采用RF算法训练区域三模型;
(4)所有25个站点数据合并,组成广义数据集,采用Catboost算法训练广义模型。
4个模型的训练结果及其指标如表8和图5、图6、图7所示。
表8各模型训练结果表
从区域模型和广义模型的对比分析中可以发现,区域模型上蒸散量估算的效果要优于广义模型。对比表8和表5、表6、表7中区域一局部模型、区域二局部模型和区域三局部模型评估指标的均值也可以发现,三个区域模型的表现效果也要优于区域内每个站点对应的局部模型的效果,也验证了区域划分的机器学习模型方法的有效性。同时也可以发现,在区域二各数据集表现上,本发明建立的区域二模型的R
实测数据验证:
上面已经完成了对黑龙江省25个气象站的区域划分,并建立对应的最佳机器学习模型,采用实测数据进行验证,对比验证模型的效果。实测数据是硬件监测终端采集并上传至阿里云物联网平台的哈尔滨市2022年7月1日至2023年10月1日数据。同时为了验证对比,需要计算参考ET0值,计算参考蒸散量的数据来源于小麦芽—农业大数据系统软件,获取了哈尔滨市同期气象数据,作为FAO-56PM方程计算参考ET0的参数,其中区域模型选择的是哈尔滨所在区域二模型。
上述内容表明区域模型的性能优于区域局部模型,这进一步验证了按照机器学习特征排序划分区域的有效性。为进一步验证本发明提出的蒸散量估算模型的估算准确性,在上述实验的基础之上,我们使用实测数据进行进一步验证,实测数据是硬件监测终端采集并上传至阿里云物联网平台的哈尔滨市2022年7月1日至2023年10月1日数据。
经实验对比,区域二模型计算的ET0值更加接近参考ET0值,ET0值变化起伏较大,广义模型所计算的ET0值误差较大,区域模型计算的ET0值更加接近标准参考值,模型表现也更加稳定。验证了区域模型对所在区域蒸散量预测更加精准,针对性更强。
上述过程是针对区域二中的站点数据输入站点所在区域二对应的模型进行预测。针对其他区域的站点,要将站点的气象数据输入到站点所在区域对应的区域模型进行预测。
上述实验表明,与彭曼方程计算的参考ET0值对比,本发明构建的区域模型的预测稳定性更强、精度更高,且只需要四个气象参数就能实现蒸散量ET0的准确估算,降低了蒸散量计算的成本。在模型部署上,只需根据硬件监测终端采集回的GPS经纬度信息,匹配最近的气象站点,从而判断所属区域,然后调用对应的区域模型进行ET0值估算。
具体实施方式二:
本实施方式为一种农业灌区水位预测方法,基于具体实施方式一的蒸散量估算方法,实现农业灌区水位预测。本实施方式所述的一种农业灌区水位预测方法具有以下特点:
1、针对传统水位预测方法严重依赖人工经验的问题。本发明使用深度时序神经网络来解决这个问题;具体而言,本发明使用LSTM、BiLSTM和GRU 3种时序模型作为单变量水位预测模型的主干网络,并且通过SSA超参数优化获得最佳超参数,后续多变量水位预测模型也使用相同的超参数;然后通过实验对比筛选出最佳时序模型作为多变量水位预测模型的主干网络。
2、时序滑动窗口是深度时序神经网络的一个重要超参数,现有研究仅使用人工经验和超参数搜索等方式,这不但会使得时序滑动窗口的选取不具备科学性和可解释性,而且会导致资源消耗严重,且可解释性较差的问题。因此,本发明提出使用快速傅里叶变换选取最佳时序滑动窗口大小的方法。
3、在原始水位数据预处理方面,现有的研究仅关注缺失值带来的影响,而忽略异常值的重要性。因此,受其他领域异常值处理方法的启发,本发明提出使用离群点检测算法检测水位数据中存在的异常值数据,然后使用插值法进行后续处理。
4、现有研究对单一水位数据的潜在信息挖掘较弱,且水位数据存在非线性和不平稳的特点,这会影响模型最终的预测性能,鉴于此,本发明VMD变分模态分解算法进一步挖掘单一水位数据包含的信息并且消除水位数据存在的非线性和不平稳性特性,进一步提高模型预测性能,经过处理获得IMF1~IMF8等8组模态分解特征,是本发明多变量水位预测数据的组成部分。
5、VMD变分模态算法需要人工确定两个参数,现有研究使用人工确定这两个参数,这会因为人的经验造成误差。因此,本发明提出使用人工大猩猩部队(Artificial gorillatroops optimizer,AGTA),对VMD算法的参数进行优化。
6、现有研究表明,影响水位的因素是多元化的,受此启发,本发明进一步将蒸散量、气象数据、使用VMD算法分解之后的模态分解特征和水位数据进行结合形成初步多变量水位预测数据;有其他研究者表明,并不是所有输入特征都对模型具有促进作用,受此启发,本发明使用随机森林重要性排序算法和皮尔逊相关系数法对初步多变量水位预测数据进行进一步分析,经过筛选和剔除,最终构建多变量水位数据。
7、现有研究直接将多变量输入模型中,并未考虑变量增多引起的模型复杂度升高的问题,因此,本发明在时序模型前引入了一维卷积层,通过引入一维卷积层,能够对输入数据进行局部感知,捕捉时间序列中的局部特征模式,实现更加高效的预测模型,最终构建VMD-CNN-GRU多变量水位预测模型。
更具体地,本实施方式所述的一种农业灌区水位预测方法,包括以下步骤:
S201、结合水位数据内部信息、气象数据和蒸散量确定用于水位预测模型的多变量水位数据:
水位数据来自哈尔滨市红星水库和七台河市桃山水库,涵盖了2010年至2015年的水位数据。数据收集自水利部信息中心的全国水情信息网站和哈尔滨公共数据集开放平台。数据包含每日水库水位的变化情况。
气象数据包含哈尔滨市和七台河市气象站从2010-2015年间每日的气象参数,每日的气象参数包括每最高气温(Tmax)和最低气温(Tmin),平均相对湿度(RH)、2米高度的风速(Wind)、日照时数(SH)、太阳辐射通量(RAD)、光照强度(LI)、年和日(Year、day)。
本发明基于现有技术水位预测进一步将水位数据内部信息、蒸散量、气象数据和水位数据进行结合,进一步将蒸散量、气象数据和水位数据进行结合形成多变量水位预测数据;
根据气象数据和具体实施方式一所述的蒸散量估算方法估算哈尔滨市和七台河市的蒸散量,这里计算蒸散量仅使用最高温度、相对湿度、风速、光照强度四个气象特征。然后将蒸散量与气象数据合并形成蒸散气象数据,进行数据异常值、缺失值和归一化等预处理;然后对蒸散气象数据使用随机森林重要性排序筛选出最有效的变量,重要性排序前5的特征分别是Tmax、Tmin、ET0、RH和LI;然后使用皮尔逊相关系数对这五个特征与水位数据的相关性进行分析,得出水位数据和蒸散数据具有一定程度的相关度,其中最高温度、最低温度、相对湿度和蒸散值与水位相关程度较高,因此选用这4个气象参数结合水位为水位预测模型的新特征;
S202、由于时序滑动窗口是深度时序神经网络的一个重要超参数,而现有研究仅使用人工经验和超参数搜索等方式,这不但会使得时序滑动窗口的选取不具备科学性和可解释性,而且会导致资源消耗严重,且可解释性较差的问题。与超参数搜索相比,快速傅里叶变换所需的资源要少得多,同时,快速傅里叶变换分析了水位数据的周期性,考虑了实际情况,与人工经验相比更具备科学性。综上所述,本发明通过使用快速傅里叶变换分析水位数据,更科学和高效的确定最佳时序滑动窗口。具体来说,我们首先通过快速傅里叶变换得到水位数据前8个主峰的频率结果,具体见表9。
通过表9中的主频结果,可以发现主峰1的周期大于100天,反映了水位数据整体的变换周期,即水位季节新变化的趋势。主峰2到主峰8反映了数据在小范围内的波动周期,其中主峰3的幅度最大,因此本发明选择主峰3作为后续分析的重点。在哈尔滨数据集上,主峰3的周期为34.7天,在七台河数据集上为33.1天,本发明最终选择35天作为时序模型的时序滑动窗口,具体原因如下:考虑到周期一致性原则,选择一个与这两个周期较为接近的时序滑动窗口大小可以更好地捕获这些周期性特征。通过选择35天作为时序窗口大小,在一定程度上同时保留了这两个数据集包含的时序信息。另一方面,较大的时序窗口会提供更稳定的输入特征信息。本发明的方法综合考虑了实际情况,更具科学性,同时对于资源消耗较小。因此本发明采用时序滑动窗口大小为35天,即输入前35天的数据来预测未来的水位。
表9周期寻找结果表
/>
S203、由于现有研究对单一水位数据的潜在信息挖掘较弱,且水位数据存在非线性和不平稳的特点,这会影响模型最终的预测性能,鉴于此,本发明采用VMD变分模态分解算法进一步挖掘单一水位数据包含的信息并且消除水位数据存在的非线性和不平稳性,进一步提高模型预测性能。在进行VMD分解时,需要手动设置惩罚因子和模态分解数,传统方法依靠人工经验确定,但是这种方法也不具备科学性。本发明使用人工大猩猩部队优化算法(Artificial gorilla troops optimizer,AGTA)对VMD参数进行优化,优化得到的参数为分解模态数为8,惩罚因子为695。根据优化参数进行VMD分解,得到的分解信号波形如图8和图9所示。经过VMD分解后,得到了8个模态分解特征(IMF1~IMF8),作为水位预测的辅助特征。
接下来,对水位数据使用VMD模态分解算法得到IMF1~IMF8等8个模态分解特征,将其与上述筛选出的4个蒸散气象数据(最高温度、最低温度、相对湿度和蒸散量)进行合并,并进一步使用皮尔逊相关系数法进行分析,发现蒸散气象数据与水位数据的相关系数整体上比IMF模态分解特征的高,这也验证了蒸散数据与数位数据结合来预测水位的可行性和有效性,同时在8个VMD模态分解特征中,相关度较高的为IMF1、IMF6和IMF7,因此选用IMF1、IMF6和IMF7与蒸散气象数据以及水位数据共计8个特征构成多变量水位预测数据。
S204、搭建基于VMD-CNN-GRU的多变量水位预测模型:
本发明从两个方面入手对水位预测进行研究:一种是将水位数据直接作为特征输入时序模型,模型输出为未来的水位预测值,即单变量水位预测模型;另一种是对水位数据使用VMD算法进行深入分析,将最终得到的3个模态分解特征结合蒸散气象数据进一步构成多变量水位预测数据,形成多变量水位预测模型,模型输入为(35,8)的矩阵,其中第一维度的35表示时间滑动窗口大小为35天,第二维度的8表示8个多变量水位预测数据的特征,模型输出同样为未来水位的预测值。(35,8)的矩阵实际就是35*8的矩阵,每一行表示一天对应的8个特征。
首先对单变量水位预测模型进行分析,采用LSTM、BiLSTM和GRU三种时序预测模型,并且使用SSA超参数优化,最终建立单变量水位预测模型。结果表明在单变量预测上,GRU模型的性能优于其他两种时序模型,因此在多变量水位预测模型的建立上也采用GRU模型。
为了应对特征数量增多带来的复杂度增加,考虑到多变量水位预测数据有8个特征,与仅使用水位数据相比,多变量水位预测数据具有高维度和复杂的时空间结构,因此,本发明在多变量GRU模型前引入了一维卷积神经网络(CNN)层。引入一维卷积层的优点有两方面:一方面,通过设计卷积层的通道数(滤波器数量),在不增加感受野的情况下,提高特征维度,更好地捕捉特征气象数据的高维特性,同时使网络结构更深;另一方面,一维卷积层更好地捕捉蒸散气象数据和水位时序数据的周期性规律和趋势。图10展示了本发明设计的多变量水位预测模型的结构,图11展示了模型构建的整体流程。
在单变量GRU模型的基础上,构建了多变量GRU水位预测模型,并使用相同的SSA优化算法进行超参数优化。最终建立了融合蒸散气象数据的VMD-CNN-GRU多变量水位预测模型,并与单变量GRU模型进行对比。实验结果表10展示了预测效果对比,图12和图13展示了单变量和多变量水位预测效果的对比。
表10多变量GRU模型和单变量GRU模型评估表
从表10和图12、图13的实验结果可以发现,采用结合蒸散量相关气象数据以及VMD分解模态数据的多变量水位预测模型VMD-CNN-GRU,在单步水位预测的表现效果上要优于单变量水位预测模型SSA-GRU。GRU模型由于在单变量预测上已经被证明比LSTM和BiLSTM模型效果更佳,所以本发明在构建多变量模型时,只选用了GRU模型,这里验证了由GRU模型构建的多变量水位预测模型效果要比GRU的单变量预测效果更好,从机器学习、深度学习的角度来说,多变量模型相比于单变量模型,引入了更多的数据,为模型预测提供了更多的参考依据,有效的输入特征增多,模型的预测效果相应提升。但从表10也可以发现,多变量的模型相比于单变量模型,R
在对未来水位进行预测时,输入数据中未来的蒸散量数据为利用具体实施方式一所述的一种农业灌区蒸散量预测方法预测得到的蒸散量数据。
以上实验均为单步水位预测,即利用历史水位数据预测未来一步或一天的水位预测值。相比之下,多步水位预测是指根据历史水位数据预测未来多个时间步长内的水位变化趋势,具有更好的指导意义。然而,预测步长过长也会使模型的预测结果变得不准确。本节单变量水位预测模型的基础上,进行了多步水位预测实验。比较了三个单变量水位预测模型和本发明提出的多变量水位预测模型在10步长下的预测结果,并以均方根误差(RMSE)作为参考指标进行了评估。实验结果见表11-表12和图14-图15。
表11不同步长预测RMSE比较(哈尔滨数据集)
表12不同步长预测RMSE比较(七台河数据集)
根据表11、表12和图14、图15的实验结果,可以发现本发明提出的融合蒸散气象数据的多变量VMD-CNN-GRU模型在水位的多步长预测中表现比三种单变量预测模型方法的整体预测效果都要好,整体误差偏移更加平稳。该实验也反应出在单步长预测上,单变量模型和多变量模型的区别不大,但在多步长预测上,多变量模型的效果明显要优于单变量模型。因此,可以得出结论:本发明提出的融合气象数据的VMD-CNN-GRU模型在水位预测中比单变量模型具有更好的预测精度,且在多步长预测中表现更为平稳。同时也可以发现,在单变量的三个模型中,GRU也有着最佳的多步长预测表现。
本发明的上述算例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 一种农田蒸散量短期预测方法
- 基于集成极限学习机的参考作物蒸散量预测方法