基于大数据的胶原蛋白肽抗衰老评估系统
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及医疗保健信息处理技术领域,具体涉及基于大数据的胶原蛋白肽抗衰老评估系统。
背景技术
胶原蛋白肽是一种蛋白质分子,是胶原蛋白的一种水解产物。通常作为保健品或化妆品中的成分使用,具有美容、抗衰老、促进伤口愈合等功能。胶原蛋白肽具有一定的抗衰老功能。随着年龄的增长,人体内胶原蛋白的含量会逐渐减少,导致皮肤失去弹性和水分,并出现皱纹和干燥等现象。胶原蛋白肽的补充可以促进皮肤的胶原蛋白合成,改善皮肤弹性,增加皮肤水分含量,从而减缓皮肤老化的速度。
而在使用大数据对胶原蛋白肽抗衰老效果进行评估时,其中的异常数据会直接影响评估精度,故需要对其中的异常数据进行检测。LOF局部离群因子(Local OutlierFactor)是常用的一种异常数据检测方法。而LOF算法中K值的设定直接影响了异常检测的精度。K值过大,异常数据可能会被误判为正常数据。K值过小,数据点只考虑了非常有限的邻域信息,容易受到局部噪声和随机波动的影响,将正常数据误判为异常数据。
发明内容
为了解决算法本身容易受到影响的技术问题,本发明提供了基于大数据的胶原蛋白肽抗衰老评估系统,所采用的技术方案具体如下:
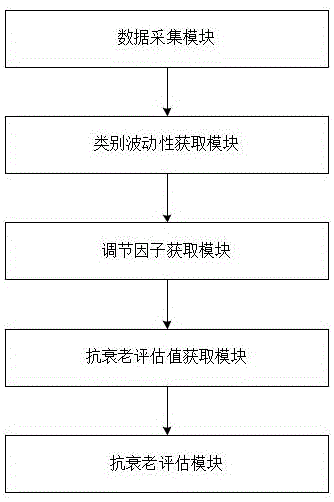
本发明提出了基于大数据的胶原蛋白肽抗衰老评估系统,该系统包括以下模块:
数据采集模块,用于获取用户的特征数据、皮肤相关数据、使用胶原蛋白肽的时间以及胶原蛋白肽的使用量,所述特征数据包括但不限于用户的年龄、性别、工作时间;
类别波动性获取模块,用于构建多维空间,获取每个用户的数据点和特征序列;将每一类特征数据对应的所有用户的特征值构成一条波动序列,根据波动序列中的特征值获取特征数据的类别波动性;
调节因子获取模块,用于根据数据点之间的类别波动性和特征序列特征值的差异获取数据点之间的特征差异值;任意一个数据点记为目标数据点,以目标数据点获取圆形区域,根据圆形区域内数据点到目标数据点的距离获取数据点的距离差异特征值;根据圆形区域内数据点的距离差异特征值、特征差异值以及数据点到目标数据点的欧氏距离获取目标数据点对应的圆形区域的分布规律性;根据目标数据点对应的圆形区域的分布规律性以及圆形区域内的最大特征差异值获取目标数据点的调节因子;
抗衰老评估值获取模块,用于根据调节因子对已知K值进行调节获取最优K值,根据最优K值获取最优局部离群因子,将用户使用胶原蛋白肽的时间和最优局部离群因子的比值作为用户置信度;根据用户置信度、胶原蛋白肽的使用量以及用户的皮肤相关数据获取胶原蛋白肽的抗衰老评估值;
抗衰老评估模块,用于根据抗衰老评估值判断胶原蛋白肽的抗衰老效果。
优选的,所述构建多维空间,获取每个用户的数据点和特征序列的方法为:
将用户的每个特征数据作为一个维度构建多维空间,每个用户在多维空间中表示一个数据点,用户的所有特征数据的值记为特征值,所有特征值构成一条特征序列。
优选的,所述根据波动序列中的特征值获取特征数据的类别波动性的方法为:
所述波动序列中的特征值是从小到大排序的,获取波动序列中的最大特征值和最小特征值,计算每个特征值在波动序列中出现的频率,根据波动序列中相邻特征值的差异和频率差异以及最大特征值和最小特征值获取特征数据的类别波动性。
优选的,所述根据波动序列中相邻特征值的差异和频率差异以及最大特征值和最小特征值获取特征数据的类别波动性的方法为:
将波动序列中相邻特征值的差值记为第一特征差异,将相邻特征值对应的频率差值记为第一频率差异,将任意一个特征值记为第一特征值,将第一特征值与其相邻靠后的特征值的第一特征差异和第一频率差异的乘积记为第一乘积,将最大特征值和最小特征值的差值的绝对值记为第一绝对值,将第一绝对值与所有特征值的第一乘积的累计和的乘积作为特征数据的类别波动性。
优选的,所述根据数据点之间的类别波动性和特征序列特征值的差异获取数据点之间的特征差异值的方法为:
;
式中,
优选的,所述以目标数据点获取圆形区域,根据圆形区域内数据点到目标数据点的距离获取数据点的距离差异特征值的方法为:
以目标数据点为圆心,选取距离目标数据点最近的预设数量个数据点,以选取的数据点中距离目标数据点最远的欧氏距离为半径构建圆形区域;
将圆形区域内所有数据点到圆心的距离从小到大排序获取距离序列,将距离序列中任意一个数据点记为选择数据点,将选择数据点到圆心的欧氏距离与距离序列中选择数据点后一位数据点到圆心的欧氏距离的差值的绝对值记为选择数据点的距离差异特征值。
优选的,所述根据圆形区域内数据点的距离差异特征值、特征差异值以及数据点到目标数据点的欧氏距离获取目标数据点对应的圆形区域的分布规律性的方法为:
;
式中,
优选的,所述根据目标数据点对应的圆形区域的分布规律性以及圆形区域内的最大特征差异值获取目标数据点的调节因子的方法为:
预设初始K值,根据初始K值获取初始LOF值;
在同时满足条件
在同时满足条件
其中,
优选的,所述根据调节因子对已知K值进行调节获取最优K值的方法为:
当调节因子为
优选的,所述根据用户置信度、胶原蛋白肽的使用量以及用户的皮肤相关数据获取胶原蛋白肽的抗衰老评估值的方法为:
皮肤相关数据包括皮肤的种类以及使用胶原蛋白前后每个皮肤相关数据对应的相关值;
;
式中,
本发明具有如下有益效果:本发明中获取胶原蛋白肽抗衰老评估的相关数据,通过对采集到的数据进行分析构建数据种类的类别波动性,进而基于类别波动性与数据点邻域内数据点的差异与分布规律性构建LOF算法中K值的调节因子,进而基于调节因子对K值进行自适应调节,获取最优K值进行完成数据的异常检测,基于数据所对应的LOF值构建用户置信度,基于用户置信度完成胶原蛋白肽的抗衰老评估。通过对K值的自适应调节,提高了胶原蛋白肽抗衰老评估的精度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明一个实施例所提供的基于大数据的胶原蛋白肽抗衰老评估系统流程图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的基于大数据的胶原蛋白肽抗衰老评估系统,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
基于大数据的胶原蛋白肽抗衰老评估系统实施例:
下面结合附图具体的说明本发明所提供的基于大数据的胶原蛋白肽抗衰老评估系统的具体方案。
请参阅图1,其示出了本发明一个实施例提供的基于大数据的胶原蛋白肽抗衰老评估系统流程图,该系统包括:数据采集模块、类别波动性获取模块、调节因子获取模块、抗衰老评估值获取模块、抗衰老评估模块。
数据采集模块,对于使用胶原蛋白肽的用户数据进行调查采样,获取用户的特征数据,所述特征数据包括但不限于性别、年龄、睡眠时长、每天工作时长等,在本实施例中以上述进行叙述,同时用调查问卷及VISIA检测等方式获取用户在使用胶原蛋白肽前后的皮肤相关数据,所述皮肤相关数据包括皮肤光泽度、皮肤皱纹数量、皮肤皱纹体积、皮肤含水量等;以上仅为本实施例的说明,实施者可自行调节皮肤相关数据和特征数据,并且皮肤相关数据的评分也由实施者决定,除此之外,通过调查问卷等方式获取用户使用胶原蛋白肽的时间以及使用量。
至此,获取了每个用户的特征数据和皮肤相关数据。
类别波动性获取模块,对于用户,其所有的特征数据构成一个特征序列,每个特征数据对应一个特征值,其中特征值由实施者自行设置,在此举例,例如:性别为男时,特征值为0,性别为女时,特征值为1;用户年龄为其特征值,睡眠时长和工作时长也用数字表示。
通过对系统内用户的特征数据使用LOF算法获取用户的异常因子,异常因子越大,则用户置信度越小。而LOF算法中K值的设定直接影响了异常检测的精度。K值过大,异常数据可能会被误判为正常数据。K值过小,数据点只考虑了非常有限的邻域信息,容易受到局部噪声和随机波动的影响,将正常数据误判为异常数据。
将每个用户作为一个数据点,其对应一条特征序列,根据特征序列中特征值的数量构建多维空间,每个数据点就是多维空间的数据点,数据点的每一维数据即为用户的一类特征数据。因此先对每类特征数据进行分析,构建特征数据的类别波动性,对于任意一类特征数据,将该类特征数据下的所有用户的特征值从小到大进行排序构成波动序列,获取其中的最大值和最小值,并且计算每个特征值出现的频率,根据波动序列中相邻两个特征值的差异、相邻特征值对应频率的差异以及特征值的最大值和最小值获取此类特征数据的类别波动性,公式如下:
;
式中,
其中,
至此,获取了每类特征数据的类别波动性。
调节因子获取模块,对于每个用户对应的数据点,格努数据点局部邻域内其余数据点的特征自适应点对LOF算法中的K值进行调节,以此获取用户所对应的最优K值,进而基于最优K值获取用户所对应的异常因子。
对于任意一个数据点,将其记为目标数据点,在本实施例中设定LOF算法的初始K值为5,计算目标数据点与其余所有数据点的欧氏距离,选取距离目标数据点最近的5个数据点,以距离第五近的距离为半径,目标数据点为中心获取一个圆形区域,区域内除了目标数据点必然存在5个或5个以上的数据点,若为5个以上时说明其中距离目标数据点第五近的数据点有多个,将圆形区域内每个数据点距离目标数据点的距离从小到大排序得到目标数据点的距离序列。
对于目标数据点以初始K值进行LOF检测获取此时的LOF值,记为初始LOF值。
根据数据点之间同类特征数据的特征值差异以及特征数据的类别波动性获取数据点之间的特征差异,公式如下:
;
式中,
对于每个目标数据点的距离序列,令距离序列中相邻距离作差获取目标数据点对应的圆形区域中数据点的距离差异特征值,公式如下:
;
式中,
根据目标数据点的圆形区域内相邻数据点的距离差异特征值的差异以及圆形区域内数据点的特征差异值和距离差异特征值获取目标数据点对应的圆形区域的分布规律性,公式如下:
;
式中,
根据所得到的目标数据点对应的圆形区域的分布规律性以及圆形区域内数据点与目标数据点的特征差异值最大值获取目标数据点的调节因子,公式如下:
;
式中,
至此,获取了每个数据点的调节因子。
抗衰老评估值获取模块,对于获取的每个数据点的调节因子进行归一化,由于K值越大,越可能将异常数据误判为正常数据,K值越小,越有可能将正常数据判断为异常数据,因此对于正常数据需要增大K值,对于异常数据需要减少K值,由此根据数据点的调节因子获取调节后的K值,公式如下:
;
式中,
根据上述步骤对每个数据点的半径进行调节,直到不满足调节因子的结果或调节50次后为止。
由于每个数据点对应一个用户,因此上述步骤可得到用户所对应的最优K值,通过LOF算法获取其所对应的局部离群因子LOF值,获取方法为公知技术,此处不再赘述。则本发明中通过用户的局部离群因子以及用户在系统内的活跃度构建用户置信度Z。用户置信度作为系统内用户的胶原蛋白肽抗衰老评估数据的权重,局部离群因子越大,用户为异常用户的可能性越大,其所对应的相关数据的置信度越小,进而提高胶原蛋白肽抗衰老的评估精度。根据最优局部离群因子和用户使用胶原蛋白肽的时长T构建用户置信度,公式如下:
;
式中,
每个用户的每个皮肤相关数据对应一个相关值,例如:皱纹含水量和皱纹数量都以自身数字表示,将每个用户的所有相关值进行归一化。
获取每个用户的用户置信度后,根据使用胶原蛋白肽前后的归一化后的每个相关值以及用户置信度构建抗衰老评估值,公式如下:
;
式中,
至此,获取了胶原蛋白肽的抗衰老评估值。
抗衰老评估模块,获取胶原蛋白肽的抗衰老评估值后,抗衰老评估值越大,说明胶原蛋白肽的抗衰老效果越好,在本实施例中设定阈值,若抗衰老评估值大于0.5,则说明衰老效果好,若抗衰老评估值小于等于0.5,则说明衰老效果差。
需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
- 一种提高免疫力、抗衰老的胶原蛋白肽组合物
- 钢筋桁架楼承板施工装置及方法