基于深度学习的自然语言理解方法及AI助教系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于人工智能助教系统领域,具体涉及一种基于深度学习的自然语言理解方法及AI助教系统。
背景技术
目前许多智能助教系统都只支持预编程的问题回答,不支持使用者自由对话。也有一些智能助教使用了自然语言处理算法如长短时记忆网络和卷积网络为基础开发的。但是这些算法在使用时需要大量新的数据。训练时间和对计算资源的占用会限制这类系统的表现力和潜力。
发明内容
本发明所要解决的技术问题是:提供一种基于深度学习的自然语言理解方法,解决了现有技术中训练算法需要大量数据量和效率不足的问题。
本发明为解决上述技术问题采用以下技术方案:
基于深度学习的自然语言理解方法,包括如下步骤:
步骤1、构建知识数据库,首先,获取预先存储或用户上传的多种形式的学习资料,并对这些学习资料进行清洗和预处理,然后,将经过清洗和预处理的学习资料通过归纳和整理,形成文档并保存进知识数据库;
步骤2、构建问题数据库,对用户输入的多种形式的自然语言信息进行预处理,然后将经过预处理的自然语言信息保存进问题数据库;
步骤3、对问题数据库里的自然语言信息进行学习和理解,根据理解的内容,在知识数据库中查找与之相关的知识点,然后根据一种或多种评分或匹配算法,选择最佳匹配的知识点所对应的学习资料作为样本对自然语言信息进行回复;
步骤4、生成一条包括问题、回复及评价的记录,并保存至知识数据库中;
步骤5、生成多种形式的回复,并按照相应的需求输出。
所述学习资料、用户输入的自然语言信息及回复均包括但不限于文字、语音、视频、图像中的至少一种形式;所述步骤1中对学习资料进行清洗和预处理包括但不限于以下部分:
筛选有效信息:通过识别和剔除学习资料中的无效、冗余或不相关的信息,仅保留对于理解文本内容有贡献的信息;
记录和理解知识点:记录和理解学习资料中的若干知识点及其内在关系;
标记知识类别:对于学习资料进行内容分析,识别和标记其涵盖的知识类别;
对视频和语音类的学习资料进行预处理:针对视频和语音类的学习资料,首先生成字幕,并对字幕内容进行包括但不限于基于语义的分段、时间戳的标记、讲话者的标记的预处理;
对图像类的学习资料进行预处理:对于图像类的学习资料,识别并提取图像中包括但不限于图像中的文字、图像中物体的特征、图像中的视觉元素、图像的各类参数信息,并将这些信息转变为文字描述,并对文字描述进行理解和处理;
标准化处理:对学习资料进行标准化处理,减少数据的噪声;
去除噪音信息:识别并去除学习资料中包括但不限于语法错误、错别字、无关词汇的噪音信息。
所述步骤2中对自然语言信息进行预处理包括但不限于以下部分:
标记自然语言信息的类别:对用户输入的自然语言信息进行内容分析,识别和标记其涵盖的知识类别;
对视频和语音类的自然语言信息进行预处理:对视频和语音类的自然语言信息,首先生成字幕,并对字幕内容进行包括但不限于基于语义的分段、时间戳的标记、讲话者的标记的预处理;
对图像类的自然语言信息进行预处理:对图像类的自然语言信息,识别并提取图像中包括但不限于图像中的文字、图像中物体的特征、图像中的视觉元素、图像的各类参数信息,并将这些信息转变为文字描述,并对文字描述进行理解和处理;
标准化处理:对基于自然语言信息生成的文字信息进行标准化处理,减少数据的噪声;
去除噪音信息:识别并去除自然语言信息中包括但不限于语法错误、错别字、无关词汇的噪音信息。
所述步骤3中对问题数据库里的自然语言信息进行学习和理解包括但不限于以下部分:
提取关键点:采用AI大语言模型,学习并提取自然语言信息中若干的关键点;
理解关键点:采用自然语言处理模型,理解并记录各个关键点。
所述步骤3中选择最佳匹配的知识点所对应的学习资料作为样本对自然语言信息进行回复包括但不限于以下部分:
查询搜索相关学习资料:将自然语言信息中的关键点和知识数据库中的各知识点进行比较,找出数个在向量空间中与关键点最为接近的知识点;
选择最佳匹配的学习资料:对找出的学习资料和自然语言信息中的关键点进行比对,选择出最佳匹配的学习资料;
采用学习资料进行回复:根据选定的最匹配学习资料,配合训练好的AI大语言模型,对自然语言信息进行回复。
所述步骤4中还包括自学习评分过程,具体如下:
首先,收集并记录用户对于回复的反馈,包括正面反馈和负面反馈;
然后,根据收集到的反馈,采用一定的评分规则,来给回复进行打分;
最后,将评分结果反馈用于回复的优化,包括但不限于调整参数权重、重新理解指令问题重点、重新生成更加详细和准确的回复。
所述步骤5中的回复包括但不限于以下形式:
如果是文字,则直接输出至终端;
如果是语音,则通过文字转语音功能进行转换,并以音频的方式同步输出;
如果是学习资料,包括但不限于知识图谱、幻灯片,则通过内嵌的图像生成器,根据需求生成相关的资料输出;
如果是视频,则输出视频链接或采用小窗口播放视频。
为了进一步解决现有智能助教系统缺少与智能助教互动感和沉浸感、回复形式单一的问题,本发明还提供一种AI助教系统,具体的技术方案如下:
AI助教系统,包括云上后端和用户终端;其中,用户终端采集用户输入的各种指令问题及对回复的评价信息,并传输至云上后端;云上后端应用所述基于深度学习的自然语言理解方法对指令问题进行处理,并将回复信息反馈至用户终端;所述用户根据收到的回复信息,选择是否通过终端对回复做出评价及评价内容。
所述云上后端包括知识库储存模块、问题输入模块、后端学习模块、自学习评分模块、知识输出模块;其中,
知识库储存模块:用于储存知识数据库;
问题输入模块:用于接收用户终端发送的包括但不限于文字、语音、视频、图像的自然语言信息,对接收到的自然语言信息进行预处理;
后端学习模块:用于学习和理解用户输入的自然语言信息,并生成多种形式的回复;
自学习评分模块:用于对后端学习模块赋予权重,对后端学习模块及其回复进行优化;
知识输出模块:用于将后端学习模块所生成的回复,输出至用户终端。
所述用户终端为具有用户交互界面的任意硬件载体,所述硬件载体具备多种形式的回复输出模块。
所述用户终端支持用户上传包括但不限于文字、语音、视频、图像多种形式的学习资料,等云上后端通过知识库储存模块将用户上传的学习资料储存进知识数据库中。
计算机存储介质,其特征在于:该计算机存储介质存储有若干计算机指令,所述计算机指令被调用时用于执行所述基于深度学习的自然语言理解方法的全部或部分步骤。
与现有技术相比,本发明具有以下有益效果:
1、通过采用多个深度学习自然语言处理算法,解决了训练算法需要大量数据量和效率不足的问题,达到了更加节约计算资源和提升效率的效果。
2、通过将算法学习和计算置于云端,解决了多进程导致服务器负荷过大、响应不及时的问题,达到了多用户实时使用并互不干扰的效果。
3、通过允许接受多种媒介的问题、能够生成自然语言处理的回复、以多种媒介为载体的回复,解决了人工助教成本高、人手不足、效率不高;传统智能助教回复形式单一、只理解预编程的问题、只能通过文字交流等问题,达到了用户自由选择提问方式(文字、语音提问、截图问题)都能得到便于理解和形式丰富的答案的效果。
4、通过添加了Web3.0技术,允许人工智能助教系统接入VR元宇宙中,解决了缺少与智能助教互动感和沉浸感的问题,达到了提升用户交互的实用性以及信息传达效率的效果。
附图说明
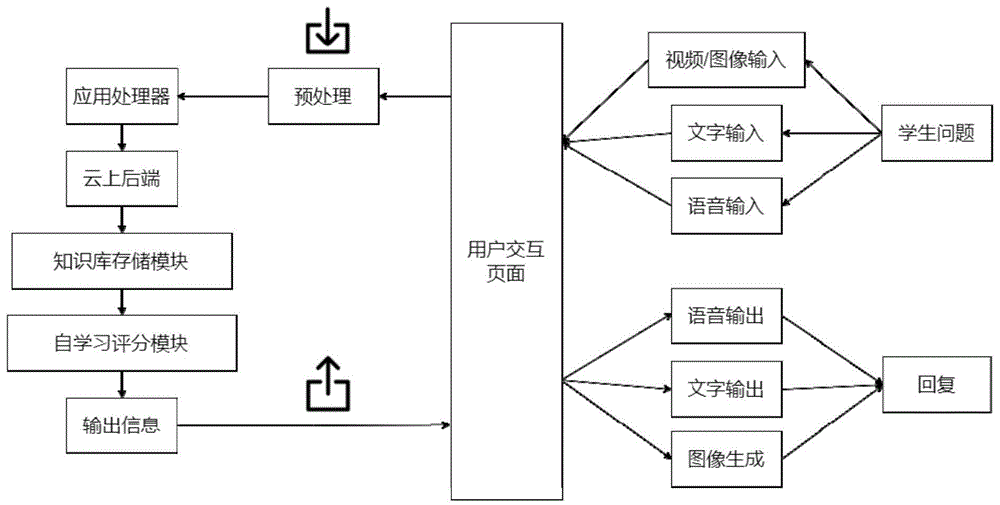
图1为本发明助教系统功能模块组成示意图。
图2为本发明方法样本获取流程图。
图3为本发明方法自我学习模块流程图。
具体实施方式
下面结合附图对本发明的结构及工作过程作进一步说明。
基于深度学习的自然语言理解方法,包括如下步骤:
步骤1、构建知识数据库,首先,获取预先存储或用户上传的多种形式的学习资料,并对这些学习资料进行清洗和预处理,然后,将经过清洗和预处理的学习资料通过归纳和整理,形成文档并保存进知识数据库;
步骤2、构建问题数据库,对用户输入的多种形式的自然语言信息进行预处理,然后将经过预处理的自然语言信息保存进问题数据库;
步骤3、对问题数据库里的自然语言信息进行学习和理解,根据理解的内容,在知识数据库中查找与之相关的知识点,然后根据一种或多种评分或匹配算法,选择最佳匹配的知识点所对应的学习资料作为样本对自然语言信息进行回复;
步骤4、生成一条包括问题、回复及评价的记录,并保存至知识数据库中;
步骤5、生成多种形式的回复,并按照相应的需求输出。
查询搜索相关学习资料采用文本嵌入技术,即将文本内容映射到向量空间,并计算文本向量间的相似度。
具体实施例,如图1至图3所示,
基于深度学习的自然语言理解方法,包括如下步骤:
步骤1、构建知识数据库,获取预先存储或用户上传的多种形式的学习资料,包括但不限于文字、语音、视频、图像等。对这些学习资料进行清洗和预处理,具体实现包括但不限于以下几个环节:
一、筛选有效信息:通过识别和剔除学习资料中的无效、冗余或不相关的信息,包括但不限于语气词、重复的内容、对于理解文本内容贡献较小的词句等,以确保仅保留对于理解文本内容有贡献的信息;
具体的,所述有贡献的信息即为有意义的信息,采用信息贡献度来进行判定,具体判定方法包括但不限于采用词嵌入技术,将文本内容映射到向量空间,并确定与文本整体内容在向量空间中距离更近,即更为相关的信息,也就是筛选有效信息中的仅保留对于理解文本内容有贡献的信息。
二、记录和理解知识点:采用一种或多种自然语言处理技术,包括但不限于词嵌入(Word Embedding)技术,记录和理解学习资料中的若干知识点及其内在关系。在此,词嵌入技术是一种将词或短语从词汇表中映射到向量空间的技术,通过捕捉词语的语义和语法关系,使得语义上相似的词在向量空间中的距离更近。
三、标记知识类别:对于学习资料进行内容分析,识别和标记其涵盖的知识类别;
四、对视频和语音类的学习资料进行预处理:针对视频和语音类的学习资料,通过一种或多种语音识别技术生成字幕,并对字幕内容进行预处理。预处理包括但不限于基于语义的分段、时间戳的标记、讲话者的标记等;
五、对图像类的学习资料进行预处理:对于图像类的学习资料,采用一种或多种图像识别技术,识别并提取图像中的重要信息,包括但不限于图像中的文字信息、图像中物体的特征、图像中的视觉元素、图像的各类参数等,并将这些信息转变为文字描述,并对文字描述进行进一步的理解和处理;
六、标准化处理:对学习资料进行标准化处理,包括但不限于将英文字符统一改为小写、将中文字符统一改为简体、消除特殊符号等,以减少数据的噪声和复杂性;
七、去除噪音信息:识别并去除学习资料中的其他噪音信息,包括但不限于语法错误、错别字、无关词汇等。
然后将这些经过清洗和预处理的学习资料通过进一步的归纳和整理,形成文档,并将这些文档保存进知识数据库。
步骤2、对用户输入的多种形式的自然语言信息,包括但不限于文字、语音、视频、图像等,进行预处理,具体实现包括但不限于以下环节:
一、标记自然语言信息的类别:对于用户输入的自然语言信息进行内容分析,识别和标记其涵盖的知识类别;
二、对视频和语音类的自然语言信息进行预处理:针对视频和语音类的自然语言信息,通过一种或多种语音识别技术生成字幕,并对字幕内容进行预处理。预处理包括但不限于基于语义的分段、时间戳的标记、讲话者的标记等;
三、对图像类的自然语言信息进行预处理:对于图像类的自然语言信息,采用一种或种图像识别技术,识别并提取图像中的重要信息,包括但不限于图像中的文字信息、图像中物体的特征、图像中的视觉元素、图像的各类参数等,并将这些信息转变为文字描述,并对文字描述进行进一步的理解和处理;
四、标准化处理:对基于自然语言信息生成的文字信息进行标准化处理,包括但不限于将英文字符统一改为小写、将中文字符统一改为简体、消除特殊符号等,以减少数据的噪声和复杂性;
五、去除噪音信息:识别并去除自然语言信息中的其他噪音信息,包括但不限于语法错误、错别字、无关词汇等。
然后将经过预处理的自然语言信息保存进问题数据库。
步骤3、对问题数据库里的自然语言信息进行学习和理解。具体实现包括但不限于以下环节:
一、提取关键点:采用一种或多种AI大语言模型,包括但不限于GPT,学习并提取自然语言信息中若干的关键点;
二、理解关键点:采用一种或多种自然语言处理技术,包括但不限于词嵌入技术,理解并记录各个关键点。
根据理解的内容,在知识数据库中查找与之相关的知识点,然后根据一种或多种评分或匹配算法,选择最佳匹配的知识点所对应的学习资料作为样本对自然语言信息进行回复。选择最佳匹配的知识点所对应的学习资料作为样本对自然语言信息进行回复的具体实现包括但不限于以下环节:
一、查询搜索相关学习资料:采用一种或多种算法,包括但不限于余弦相似度(Cosine Similarity)算法,将自然语言信息中的关键点和知识数据库中的各知识点进行比较,找出数个在向量空间中与关键点最为接近的知识点。余弦相似度算法是一种用于计算两个向量间角度的余弦值的度量方法,通常用于评估两个向量间的相似度。其数学公式的常见形式为:cos(θ)=(A·B)/(||A||||B||)。其中,θ是两个向量的夹角,A·B是向量A和向量B的点积,||A||和||B||是向量A和向量B的模长;
二、选择最佳匹配的学习资料:采用一种或多种算法,包括但不限于采用AI大语言模型,对找出的学习资料和自然语言信息中的关键点进行比对,选择出最佳匹配的学习资料;
三、采用学习资料进行回复:采用一种或多种算法,包括但不限于小样本学习法(Few-Shot Learning),根据选定的最匹配学习资料,配合训练好的AI大语言模型,对自然语言信息进行回复。这里的小样本学习法是指在只有少量训练样本的情况下,依靠与预训练的AI大预言模型的结合,仍能做出准确预测的机器学习技术。
步骤4、生成一条包括问题、回复及评价的记录,并保存至知识数据库中;该步骤中还包括自学习评分过程,具体如下:
一、收集反馈:收集并记录用户对于回复的反馈,包括正面反馈和负面反馈;
二、评分计算:根据收集到的反馈,采用一定的评分算法,来给回复进行打分;
三、反馈采用:将评分结果反馈用于回复的优化,包括但不限于调整参数权重、重新理解指令问题重点、重新生成更加详细和准确的回复等。
步骤5、生成多种形式的回复,包括但不限于文字、语音、视频、图像等,并按照相应的需求输出。具体的,
一、如果是文字,则直接输出至终端;
二、如果是语音,则通过文字转语音功能进行转换,并以音频的方式同步输出;
三、如果是学习资料,包括但不限于知识图谱、幻灯片等,则通过内嵌的图像生成器,根据需求生成相关的资料输出;
四、如果是视频,则输出视频链接或采用小窗口播放视频。
AI助教系统,包括云上后端和用户终端;其中,用户终端采集用户输入的各种指令问题及对回复的评价信息,并传输至云上后端;云上后端应用所述基于深度学习的自然语言理解方法对指令问题进行处理,并将回复信息反馈至用户终端;所述用户根据收到的回复信息,选择是否通过终端对回复做出评价及评价内容。
所述云上后端包括知识库储存模块、问题输入模块、后端学习模块、自学习评分模块、知识输出模块;其中,
知识库储存模块:用于储存在线学习平台的学习资料或者学校课程内容。这些学习资料可以是文本、图像、视频等形式,尤其是线上学习平台的资料以录播视频为主。这些资料将通过一系列清洗和预处理的步骤。包括但不限于筛选有效信息、记录知识点关键词、标记图像和视频涵盖的知识类别、视频生成字幕并标记时间戳、图像提取文字等等。下一步将所有数据归纳整理成文档并保存进数据库。数据可以根据知识类别来储存,但是更加实用的方法是根据上传机构和学校来储存。这样确保使用者获得的答复一定是和其从属机构或学校相关的。
问题输入模块:用于接收用户终端发送的包括但不限于文字、语音、视频、图像的自然语言信息,对接收到的自然语言信息进行预处理;例如:用于收集和记录学生使用者向助教提出的问题或者教师使用者向助教下达的指令。指令的形式并不固定,可以有以下的形式:文字、语音、视频和图像等。文字指令将直接进入预处理步骤,而语音指令将通过语音识别功能来转换成文字。助教会识别使用者上传的图像,提取其中的文字信息之后送入预处理环节。视频将会拆分成声音和图像两种信息之后分别处理。在预处理环节中,助教会识别有效指令和其他噪音信息。有效指令将传回后端学习模块。
后端学习模块:用于学习和理解用户输入的自然语言信息,并生成多种形式的回复;例如,用于学习和理解上述字串序列,并根据理解的意思去知识数据库中查找相关的知识点。后端学习模块包括两个已经成熟的深度学习自然语言理解算法:GPT-3和BERT。BERT算法可以双向学习指令并抓取其中的关键词。其也可以同时处理多行指令,学习和理解每一行的重点和作用,并选择最合适的回复。GPT-3则使用小样本学习法,可以消耗更少的资源来学习用户的指令。同时GPT-3也会为每一个可能的回复赋予权重并传回自学习评分模块。
自学习评分模块:用于对后端学习模块赋予权重,对后端学习模块及其回复进行优化;给后端学习模块输出的回复赋予权重。模块使用集成学习将两种语言处理算法的结果放入数个分类器中。每个分类器使用线性模型拟合指令和回复,然后返回平均方差最小的结果。集成学习将归纳所有分类器的结果,之后选择可能性最大的结果传给文字和语音输出模块的。同时前端赋予了评分系统,使用者可以给助教发送的每一个回复评价。无论是正面还是负面评价,都会将结果送回自学习评分模块进行自我优化。优化包括调整参数权重、重新理解用户问题重点、重新生成更加详细的回复等。一条记录,包含了使用者问题、助教生成的回复和用户的评价的,会生成并且保存到储存模块中。
知识输出模块:用于将后端学习模块所生成的回复,输出至用户终端。例如,用于将助教生成的内容传达给用户。助教可以生成的回复也有多种形式,包括文字、音频、图像和视频等。文字部分将直传回交互界面。语音部分将通过文字转语音服务,以声音的方式同步输出。有些情况比如使用者要求生成知识树或者知识图谱的情况,就可以通过内嵌的图像生成器,根据用户的需求来生成相关的图像。助教也可以根据情况返回超链接或者小窗口播放来展示一个视频的片段。这个视频片段的内容可以解决使用者提出的问题,并且比单纯文字更加好理解。这个视频可以是课程录播视频或者在线学习平台的课程视频。
所述用户终端为具有用户交互界面的任意硬件载体,所述硬件载体具备多种形式的回复输出模块。
所述用户终端支持用户上传包括但不限于文字、语音、视频、图像多种形式的学习资料,等云上后端通过知识库储存模块将用户上传的学习资料储存进知识数据库中。
为了进一步说明该方案,下面以具体的例子对具体的实施过程进行详细的说明:
步骤1、将预先收集好的学习资料进行清洗和预处理,其具体包括(以视频学习资料为例):
步骤1.1、使用一种或多种语音识别技术,将视频学习资料生成字幕,并记录每个文字的起始和结束时间戳,以及对声音源进行标记;
步骤1.2、使用预训练AI大语言模型,将字幕按照断句进行划分,并同时去除噪音信息(如语法错误、错别字、语气词等无关词汇等);
步骤1.3、使用自然语言处理技术,为每个完整的断句进行标准化处理(包括但不限于将英文字符统一改为小写、将中文字符统一改为简体、消除特殊符号等)并筛选有效的信息(包括但不限于去除语气词、去除重复多次的句子、去除有过多重复词的句子等);
步骤1.4、基于步骤1.1的记录,为每个清理过后的完整的断句加入起始和结束时间戳,以及声音源的标记;并加入包括但不限于视频名称、作者、创作日期、视频地址、视频封面、视频对应课程等全部知识类别相关的信息;将该视频学习资料的全部字幕合并为一个完整的文本,并使用AI大语言模型对其内容进行概括和总结;
步骤1.5、使用一种或多种词嵌入模型,将每一个完整的断句映射到不同的向量空间,并记录每一个完整的断句的全部向量信息;
步骤1.6、将经过清理和预处理的学习资料根据知识类别相关的信息,通过进一步的归纳和整理,形成文档,并将这些文档保存进知识数据库;
步骤2、用户选择课程信息(实施例:用户选择某一知识数据库中所包含的知识类别如英语教学);
步骤3、用户输入自然语言信息(实施例:Expression和Majority的考点分别是什么?请概括一下视频“Day 3”的内容。用列表的形式回复。);
步骤4、使用问题输入模块对“用户输入的自然语言信息”进行预处理,其具体步骤包括:
步骤4.1、使用自然语言处理技术,对“用户输入的自然语言信息”进行标准化处理(包括但不限于将英文字符统一改为小写、将中文字符统一改为简体、消除特殊符号)并去除噪音信息(包括但不限于语法错误、错别字、无关词汇等)
步骤4.2、根据用户于步骤2中所选择的课程信息,来匹配识别和标记“用户输入的自然语言信息”所对应的知识类别。
步骤5、使用后端学习模块对“用户输入的自然语言信息”进行学习、理解、分析,并最终生成多种形式的回复,其具体步骤包括:
步骤5.1、使用预训练的AI大语言模型,将“用户输入的自然语言信息”中的“问题”和“对于回复的要求”进行判定、分离、和储存;(实施例:“问题”:Expression和Majority的考点分别是什么?请概括一下视频“Day 3”的内容。“对于回复的要求”:用列表的形式回复。)
步骤5.2、使用预训练的AI大语言模型,对“问题”部分进行学习、理解、分析,进而将其拆分成数个“独立的问题”;(实施例:“独立的问题”:1.Expression的考点是什么?2.Majority的考点是什么?3.视频“Day 3”讲了什么?)
骤5.3、使用预训练的AI大语言模型,对于每个“独立的问题”进行学习、理解、分析,进而判断其属于何种问题,包括但不限于“对于某个具体知识点的问题”或者“对于某一个学习资料的概括总结类问题”,并根据此判断来选择最佳匹配的学习资料种类;(实施例:“对于某个具体知识点的问题”:1.Expression的考点是什么?2.Majority的考点是什么?;“对于某一个学习资料的概括总结类问题”:1.视频“Day 3”讲了什么?)
步骤5.4、对于每个“独立的问题”,如该“独立的问题”为“对于某个具体知识点的问题”,则使用以下步骤生成对该“独立的问题”的回复:
步骤5.4.1、使用一个或多个词嵌入模型将该“独立的问题”映射到相应向量空间;(实施例:使用Sentence Transformers的Python框架中的数个词嵌入模型)
步骤5.4.2、使用余弦相似度算法,将该“独立的问题”和知识数据库中的各知识点进行比较。使用一种或多种评判标准,选出每种评判标准中和该“独立的问题”最为接近的数个知识点,并记录;(实施例:通过余弦相似度算法,计算出学习资料中的每句话和该“独立的问题”之间的距离,选取每个模型中距离该“独立的问题”最近的前数个句子,并记录它们在学习资料中的位置。通过余弦相似度算法,计算出学习资料中的每句话和该“独立的问题”之间的距离,选取每个模型中某一句话及其后N句连续的话和该“独立的问题”之间的距离的平均值最近的前数个句子,并记录它们在学习资料中的位置。)
步骤5.4.3、使用预训练的AI大语言模型,将步骤3.3.2中所记录的全部知识点及其所在学习资料的部分内容与该“独立的问题”进行比较,选择一个或多个最佳匹配的学习资料;(实施例:根据步骤5.4.2中所记录的全部知识点的位置,合并其所在位置附近的数句学习资料作为一个样本段落,并使用AI大语言模型将全部的样本段落和该“独立的问题”进行比较,选择出一个或多个最佳的最佳匹配的样本段落。)
步骤5.4.4、使用小样本学习法和预训练的AI大预言模型,利用最佳匹配的学习资料结合步骤5.1中“对于回复的要求”来生成对该“独立的问题”的回复;(实施例:将步骤5.4.3中所选择的最佳匹配的样本段落作为样本训练AI大预言模型,并基于此样本段落对该“独立的问题”的回复。)
步骤5.5、如该“独立的问题”为“对于某一个学习资料的概括总结类问题”,则使用以下步骤生成对该“独立的问题”的回复:
步骤5.5.1、使用一个或多个词嵌入模型将该“独立的问题”映射到相应向量空间;(实施例:使用Sentence Transformers的Python框架中的数个词嵌入模型)
步骤5.5.2、使用余弦相似度算法,将该“独立的问题”和知识数据库中的各学习资料进行比较。使用一种或多种评判标准,选出每种评判标准中和该“独立的问题”最为接近的数个学习资料,并记录;(实施例:通过余弦相似度算法,计算出学习资料中的知识类别相关的信息,包括但不限于视频名称、作者、创作日期、视频地址、视频封面、视频对应课程等,和该“独立的问题”之间的距离,选取每个模型中距离该“独立的问题”最近的前数个学习资料,并记录。)
步骤5.5.3、使用预训练的AI大语言模型,将步骤3.4.2中所记录的全部学习资料及其知识类别相关的信息与该“独立的问题”进行比较,选择一个或多个最佳匹配的学习资料;(实施例:根据步骤5.5.2中所记录的知识类别相关的信息,并使用AI大语言模型将知识类别相关的信息和该“独立的问题”进行比较,选择出一个或多个最佳的学习资料。“对于某一个学习资料的概括总结类问题”:1.视频“Day 3”讲了什么?则最后选择视频名称为“Day3”的学习资料作为最佳匹配的学习资料。)
步骤5.5.4、使用小样本学习法和预训练的AI大预言模型,利用最佳匹配的学习资料及其预先概括和总结的内容结合步骤2.1中“对于回复的要求”来生成对该“独立的问题”的回复;(实施例:将步骤5.5.3中所选择的最佳匹配的学习资料的预先概括和总结的内容作为样本训练AI大预言模型,并基于此样本段落对该“独立的问题”的回复。)
步骤5.6、将生成的全部回复整合并生成完整的回复,其具体步骤包括:
步骤5.6.1、将每个“独立的问题”所对应的最佳匹配的学习资料知识及其段落的相关的信息,包括但不限于视频时间戳、视频链接、视频作者、创作日期等,结合步骤5.5中所生产的回复合并成完整的回复;(实施例:Expression的考点:
1.表达的意思;
2.表情的意思;
3.价值观中关键要素的具体体现;
4.具体的表现,翻译成of;
5.形容词为expressive,表示表达丰富的;
6.形容词为expressible,表示能够清楚表达的;
7.否定形容词为inexpressible,表示无法用语言表达出来的。
这个回答是基于视频"Day 3"。
Majority的考点如下:
1.majority:大多数,常用于描述数量或人数的占比。
2.minority:少数派,与majority相对应。
3.a majority of:大多数的,常用于修饰名词。
4.take something seriously:严肃对待某件事,常用于表达态度或行为。
5.it is obvious that:显然,常用于引出一个明显的观点或结论。
6.System/Systematic:系统/系统化的,常用于描述某种体系或方法。
7.Warning System:预警系统,常用于描述某种预警机制。
8.Red Alert:红色预警,常用于表示最高级别的危险。
9.Endangered Species:濒危物种,常用于描述生物多样性的保护。
10.Systematic Survey Methods:系统的调查方法,常用于描述科学研究方法。
11.Systematic drug abuse:系统的药物滥用,常用于描述药物滥用的规模和影响。
这个回答是基于视频"Day 2"。
-介绍了与价值相关的词汇,如value、evaluate、valuable等。
-探讨了最好的教育方式和学区房的概念。
-讲述了英语中常见的前缀和一些涉及价值、工作、生产等方面的词汇。
-解释了贬值和低估的概念及其区别,以及价值的主观性和量化方式。
-谈到了科研职业的奉献精神和个人选择的体现,以及一些相关的词汇,如overvalue、toxic assets等-介绍了与head相关的词汇和搭配,以及与标题相关的词汇,强调了动词修饰名词的简单规则。
-讲解了几个与经济、财务相关的词汇,如clickbait、headlong、overhead、finance和financial。
-介绍了一些与财政和技术相关的词汇,如financial、fiscal、technology、hightechnology和technological。
-讲述了英语中关于消费和购物的词汇和表达方式,如“consumed sparingly”、“consuming”、“style conscious consumers”和“consumerism”。
-提到了与网购相关的词汇,如“e-commerce platform”、“shop around”等,并提到了现代社会的隐私问题。-解释了“assume”这个单词的含义和用法,以及相关词汇和表达方式。
-介绍了与快递服务行业相关的英语词汇。
-讲述了诗歌表达情感的特点以及一些词汇的含义和用法,包括expressible、inexpressible、explicable、inexplicable、call、call out、issue、recall等。-介绍了与保险和投资相关的词汇及其含义。
-选择自己生活方式的考点。
-保险的英文是insurance,assurance的意思是自我确认,投资的英文是invest,基金的英文是fund。
-选择的英文是choose,选择自己的生活方式可以用choose their own way oflife来表达。
-交友很重要,Policy是政策方针,Address是解决问题的意思,thorny questions指的是真正棘手的问题。
-讲座还强调了独立思考和不随大流的重要性,提醒年轻人不要受到同辈压力的影响,要选择适合自己的道路。
-介绍了一些英文单词和短语的含义和用法,包括headhunter、explore、fine、search、seek、find、job seeker、official、gain、benefit、formation flight、eraser、eradicate、ready、radiate等。
-引用了“No pain,no gain”这句谚语,正确的用法是“No pain,no gain”,不是“No pains,no gains”。视频“Day 3”的内容概括如下:
-使用英语时应注意使用常用的表达方式,而不是使用偏门的表达方式。
-介绍电影《当幸福来敲门》中的幸福概念,即幸福是一个获取的过程,叫ThePursuit of Happiness。
-电影中的Happiness单词中的字母I也表达了幸福的含义,即幸福的答案在自己身上,需要自己去寻找,而不是去寻找原因。
-片段以电影中的一句话作为收尾,即答案在你自己身上,It is an eye inhappiness。
这个回答是基于视频"Day 3"。
步骤6、使用知识输出模块,将后端学习模块所生成的回复,输出至用户终端;
步骤7、用户可以对所生成的回复进行打分。自学习评分模块将记录打分情况,并对后端学习模块进行反馈,对于相似的问题的回复进行优化;
步骤8、用户可以基于回复,请求相关的学习资料,其具体步骤为:
步骤8.1、选择所需要的学习资料类别,如知识图谱、幻灯片等;
步骤8.2、将回复中所用到的一个或多个最佳的学习资料的字幕整合成完整的文本。使用AI大语言模型,生成对应学习资料类别的内容;
步骤8.3、将AI大预言模型所生成的内容导入到对应学习资料类别的生成器中。并导出对应的学习资料;
步骤8.4、将学习资料发送至用户。
本方案还提供了一种集成了多个深度学习自然语言理解算法和Web3.0技术的人工智能助教系统,所述人工智能助教设有下述组成部件:问题输入模块、后端学习模块、知识库储存模块、自学习评分模块、知识输出模块。其中:
问题输入模块,用于收集和记录学生使用者向助教提出的问题或者教师使用者向助教下达的指令。指令的形式并不固定,可以有以下的形式:文字、语音、视频和图像等。文字指令将直接进入预处理步骤,而语音指令将通过语音识别功能来转换成文字。助教会识别使用者上传的图像,提取其中的文字信息之后送入预处理环节。视频将会拆分成声音和图像两种信息之后分别处理。在预处理环节中,助教会识别有效指令和其他噪音信息。有效指令将传回后端学习模块。
后端学习模块,用于学习和理解上述字串序列,并根据理解的意思去知识数据库中查找相关的知识点。后端学习模块包括两个改进的深度学习自然语言理解算法:改进的基于自注意力的GPT模型和改进的BERT模型。BERT算法可以双向学习指令并抓取其中的关键词。其也可以同时处理多行指令,学习和理解每一行的重点和作用,并选择最合适的回复。GPT-3则使用小样本学习法,可以消耗更少的资源来学习用户的指令。同时GPT-3也会为每一个可能的回复赋予权重并传回自学习评分模块。
知识库储存模块,用于储存在线学习平台的学习资料或者学校课程内容。这些学习资料可以是文本、图像、视频等形式,尤其是线上学习平台的资料以录播视频为主。这些资料将通过一系列清洗和预处理的步骤。包括但不限于筛选有效信息、记录知识点关键词、标记图像和视频涵盖的知识类别、视频生成字幕并标记时间戳、图像提取文字等等。下一步将所有数据归纳整理成文档并保存进数据库。数据可以根据知识类别来储存,但是更加实用的方法是根据上传机构和学校来储存。这样确保使用者获得的答复一定是和其从属机构或学校相关的。
自学习评分模块,给后端学习模块输出的回复赋予权重。模块使用集成学习将两种语言处理算法的结果放入数个分类器中。每个分类器使用线性模型拟合指令和回复,然后返回平均方差最小的结果。集成学习将归纳所有分类器的结果,之后选择可能性最大的结果传给文字和语音输出模块的。同时前端赋予了评分系统,使用者可以给助教发送的每一个回复评价。无论是正面还是负面评价,都会将结果送回自学习评分模块进行自我优化。优化包括调整参数权重、重新理解用户问题重点、重新生成更加详细的回复等。一条记录,包含了使用者问题、助教生成的回复和用户的评价的,会生成并且保存到储存模块中。
知识输出模块,用于将助教生成的内容传达给用户。助教可以生成的回复也有多种形式,包括文字、音频、图像和视频等。文字部分将直传回交互界面。语音部分将通过文字转语音服务,以声音的方式同步输出。有些情况比如使用者要求生成知识树或者知识图谱的情况,就可以通过内嵌的图像生成器,根据用户的需求来生成相关的图像。助教也可以根据情况返回超链接或者小窗口播放来展示一个视频的片段。这个视频片段的内容可以解决使用者提出的问题,并且比单纯文字更加好理解。这个视频可以是课程录播视频或者在线学习平台的课程视频。
该实施例中,
可以接受语音、文字、图像和影像作为指令输入。这些信息经过预处理之后送到云上后端。云端链接的多个深度学习自然语言理解算法会将信息处理成字符串序列并开始学习。算法会使用注意力机制来抓取指令中的关键词,为储存模块中的多个可能的回复计算可能性。这些回复也会一一与指令并列学习,并采用反馈机制让算法意识那个回复更加适合。
除了常规的文字和语音回复外,本发明还生成知识图谱,帮助使用者系统性地理解知识概念。
原始数据可以是课程网站或者是录播视频,通过爬虫抓取之后进行初步整理。文字类数据加上识别标签,视频类数据进行字幕识别,并且保存字幕数据为文档,为每一句话标记时间戳。这些数据都将保存为CSV文件,之后送去清洗。清洗数据可以使用信息熵或者余弦距离等方式,将无意义的文字从文档中去除,只保留核心知识和相关信息。这些整理好的文档将会送入后端的深度学习模型。
当使用者收到智能助教的反馈之后,可以根据满意程度评分。这个评价将会和用户的问题、机器的反馈一起整合成一个JSON文件送到后端。学习模块会根据这个问题和评分,调整生成出的回复中各个参数的权重,并且重新学习理解用户的问题。之后会根据调整好的参数来生成新的答复呈现给用户。
本发明集成了多个深度学习语言理解模型,可以使用小样本学习方法来减少资源消耗、提高运行效率并生成更加自然的语句。用户完全可以自由与本发明的助教对话,自由地使用任何语气和方式来提出一个问题。智能助教会通过自然语言模型理解信息中哪一部分是问题、哪一部分是自由对话,并且针对做出回复。
本发明还扩展了可以处理的信息载体,不仅可以接受文字和语音,还可以接受图像和影像,提升了智能助教系统的实用性、处理任务的多样性和用户使用的便携性。
除此之外,本发明的智能助教也能用这些信息载体作为回复。
相比较传统的智能助教普遍只能用文本来回复,部分支持播放声音回复,本发明可以用图像和视频给予更加丰富的用户体验。
本发明还允许嵌入到更多使用场景中。不仅可以嵌入在线学习平台作为小助手或者单独用网页来使用,还可以应用到元宇宙的虚拟环境中,以建模形象与使用者互动,提供沉浸式体验。
下面以在元宇宙的教室里使用为例,对该方案进行详细的说明。
首先,学生能够在元宇宙使用交互性网页,访问智能对话机器人,并通过多种途径发送指令。在这个虚拟沉浸式的环境中,学生可以选择输入文字、说话、画图、传送图片等等方式与机器人交互,而这些指令会传送至云上后端,并开始处理。最后机器人会以与语音和文字同步回复学生,解答他们的问题或者提供他们想要的资料。
比如说,学生想要了解一节课程的内容,他可以先文字输入课程代号,然后说“想了解这节课的详细信息。”机器人会根据这两个信息构成的指令去学习和理解。当机器人了解指令之后就会去数据储存模块查找课程相关的数据。这些数据可以是学校提供的,也有上过课的学生的反馈等等。机器人将会选择更加可能的回复输出给同学。最后机器人会在交互屏幕上展示回复,并且念给学生听。最后学生可以给这个回复打分,将自己的满意程度反馈给机器人。
计算机存储介质,该计算机存储介质存储有若干计算机指令,所述计算机指令被调用时用于执行所述基于深度学习的自然语言理解方法的全部或部分步骤。
本发明集成了多个深度学习语言理解模型,可以使用小样本学习方法来减少资源消耗、提高运行效率并生成更加自然的语句。用户完全可以自由与本发明的助教对话,自由地使用任何语气和方式来提出一个问题。智能助教会通过自然语言模型理解信息中哪一部分是问题、哪一部分是自由对话,并且针对做出回复。本发明还扩展了可以处理的信息载体,不仅可以接受文字和语音,还可以接受图像和影像,提升了智能助教系统的实用性、处理任务的多样性和用户使用的便携性。除此之外,本发明的智能助教也能用这些信息载体作为回复。相比较传统的智能助教普遍只能用文本来回复,部分支持播放声音回复,本发明可以用图像和视频给予更加丰富的用户体验。本发明还允许嵌入到更多使用场景中。不仅可以嵌入在线学习平台作为小助手或者单独用网页来使用,还可以应用到元宇宙的虚拟环境中,以建模形象与使用者互动,提供沉浸式体验。
- 基于自然语言理解和图像图形的智能图像识别系统及方法
- 一种基于AI深度学习的AI辅助自动化测试方法及系统
- 一种基于AI视觉下的英语课文辅助教学方法及系统