多存储列存储器控制器中的高效存储列切换
文献发布时间:2024-04-18 19:59:31
背景技术
计算机系统通常使用廉价且高密度的动态随机存取存储器(DRAM)芯片作为主存储器。现今销售的大多数DRAM芯片与由联合电子设备工程委员会(JEDEC)发布的各种双倍数据速率(DDR)DRAM标准兼容。DDR DRAM提供高性能和低功率操作这两者,并且DRAM制造商已提供以越来越快的时钟速度操作的DDR DRAM。
现代DDR存储器控制器维持队列以存储未决的存储器访问请求,从而允许这些存储器控制器乱序地选取未决的存储器访问请求,以提高效率。例如,存储器控制器可以从队列无序地检索对存储器的给定存储列(rank)中的同一行的多个存储器访问请求,并且将该多个存储器访问请求连续地发出到存储器系统以避免预充电当前行和激活另一行的开销。
较高性能的DDR存储器系统提供连接到单个存储器通道并且共享大多数地址、数据及控制信号的存储器的多个存储列。这些存储器系统产生复杂的定时约束,并且如果存储器控制器频繁地在存储列之间切换,则可降低存储器总线效率。然而,高性能计算系统中的存储列数量继续增长。例如,组织成一个或多个负载减少的双列直插式存储器模块(LRDIMM)的DDR存储器可具有四个物理芯片选择/物理存储列,并且每个芯片选择/物理存储列可在三维堆叠(3DS)封装中具有八个逻辑存储列。此外,随着时间的推移,DDR存储器已被指定为使用越来越快的存储器时钟信号来运行。然而,在这些更快的存储器时钟信号的情况下,某些定时参数(例如,最小写入到读取定时)已成比例地增加,这降低了使用已知存储器控制器的存储器控制器效率。
附图说明
图1以框图形式示出了现有技术中已知的加速处理单元(APU)和存储器系统;
图2以框图形式示出了现有技术中已知的存储器控制器;
图3以框图形式示出了根据一些实施方案的可以用于图1的APU中的存储器控制器;
图4示出了例示写入到读取周转时间的部件的时序图;并且
图5示出了可由现有技术中已知的存储器控制器选择的存储器访问的一组时间线;
图6示出了根据一些实施方案的图3的存储器控制器的一部分的框图;
图7示出了根据一些实施方案的由图6的仲裁器选择的存储器访问的时间线;并且
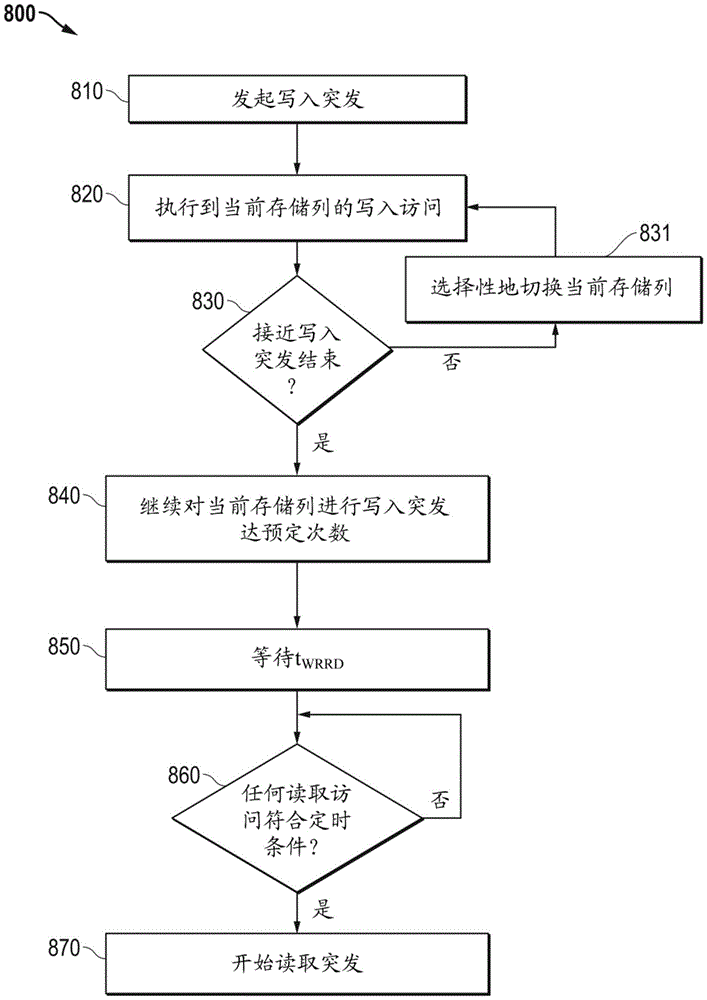
图8是根据一些实施方案的用于从多存储列系统选择访问的技术的流程图。
在以下描述中,在不同的附图中使用相同的附图标号指示类似或相同的项。除非另有说明,否则字词“耦接”及其相关联的动词形式包括直接连接和通过本领域已知的方式的间接电连接两者,并且除非另有说明,否则对直接连接的任何描述也意味着使用合适形式的间接电连接的另选实施方案。
具体实施方式
一种数据处理器包括分级缓冲器、命令队列、挑选器和仲裁器。分级缓冲器接收并存储第一存储器访问请求。命令队列存储第二存储器访问请求,每个第二存储器访问请求指示存储器系统的多个存储列中的一个存储列。挑选器在分级缓冲器中的第一存储器访问请求中进行挑选,并且将第一存储器访问请求中选定的第一存储器访问请求提供给命令队列。仲裁器至少基于对存储器系统的当前存储列的访问的偏好而在来自命令队列的第二存储器访问请求中进行选择。挑选器挑选对分级缓冲器的第一存储器访问请求中的当前存储列的访问,并且将第一存储器访问请求中选定的第一存储器访问请求提供给命令队列。
数据处理器包括命令队列和仲裁器。命令队列接收和存储解码的存储器命令,其中,每个解码的存储器命令包括指示类型和存储列的信息,其中,类型指示读取和写入中的一者。仲裁器耦合到命令队列,用于基于多个标准在来自命令队列的解码的存储器命令中进行选择,以提供给存储器通道。仲裁器可操作以确定仲裁器是否接近写入访问突发的结束,并且如果接近,则在开始读取突发之前继续对当前存储列的写入访问突发达预定次数。
一种用于存储器控制器选择要提供给具有多个存储列的存储器通道的存储器访问请求的方法包括发起写入访问突发。执行对当前存储列的写入访问。确定存储器控制器是否接近写入访问突发的结束。如果存储器控制器不接近写入访问突发的结束,则选择性地切换当前存储列,并且重复执行对当前存储列的写入访问以及确定存储器控制器是否接近写入访问突发的结束。如果存储器控制器接近写入访问突发的结束,则继续对当前存储列的写入访问突发达预定次数,等待写入到读取周转时间,并且当任何读取访问符合定时条件时开始读取突发。
图1以框图形式示出了现有技术中已知的加速处理单元(APU)100和存储器系统130。APU 100是适合于用作数据处理系统中的主机处理器的集成电路数据处理器,并且通常包括中央处理单元(CPU)核心复合体110、图形核心120、一组显示引擎122、存储器管理集线器140、数据结构125、一组外围控制器160、一组外围总线控制器170和系统管理单元(SMU)180。
CPU核心复合体110包括CPU核心112和CPU核心114。在该示例中,CPU核心复合体110包括两个CPU核心,但是在其他实施方案中,CPU核心复合体110可包括任意数量的CPU核心。CPU核心112和114中的每个核心双向连接至系统管理网络(SMN)(该SMN形成控制结构)和数据结构125,并且能够将存储器访问请求提供到数据结构125。CPU核心112和114中的每个核心可以是一体式核心,或者还可以是具有共享某些资源诸如高速缓存的两个或更多个一体式核心的核心复合体。
图形核心120是高性能图形处理单元(GPU),该GPU能够以高度集成和并行方式执行图形操作诸如顶点处理、片段处理、着色、纹理混合等。图形核心120双向连接至SMN和数据结构125,并且能够将存储器访问请求提供到数据结构125。就此而言,APU 100可支持其中CPU核心复合体110和图形核心120共享相同存储空间的统一存储器架构,或其中CPU核心复合体110和图形核心120共享存储空间的一部分、同时图形核心120还使用CPU核心复合体110不能访问的私有图形存储器的存储器架构。
显示引擎122渲染并光栅化由图形核心120生成的对象以用于在监测器上显示。图形核心120和显示引擎122双向连接到公共存储器管理集线器140以用于统一转换为存储器系统130中的适当地址,并且存储器管理集线器140双向连接到数据结构125以用于生成此类存储器访问并且接收从存储器系统返回的读取数据。
数据结构125包括用于在任何存储器访问代理和存储器管理集线器140之间路由存储器访问请求和存储器响应的纵横开关。数据结构还包括由基本输入/输出系统(BIOS)定义的、用于基于系统配置确定存储器访问的目的地的系统存储器映射,以及用于每个虚拟连接的缓冲器。
外围控制器160包括通用串行总线(USB)控制器162和串行高级技术附件(SATA)接口控制器164,它们中的每一者双向连接至系统集线器166和SMN总线。这两个控制器仅仅是可用于APU 100的外围控制器的示例。
外围总线控制器170包括系统控制器或“南桥”(SB)172以及外围部件互连高速(PCIe)控制器174,它们中的每一者双向连接至输入/输出(I/O)集线器176和SMN总线。I/O集线器176也双向连接至系统集线器166和数据结构125。因此,例如,CPU核心可通过数据结构125通过I/O集线器176路由的访问对USB控制器162、SATA接口控制器164、SB 172或PCIe控制器174中的寄存器进行编程。APU 100的软件和固件存储在系统数据驱动器或系统BIOS存储器(未示出)中,系统数据驱动器或系统BIOS存储器可以是多种非易失性存储器类型中的任一种,诸如只读存储器(ROM)、闪存电可擦除可编程ROM(EEPROM)等。通常,BIOS存储器通过PCIe总线访问,并且系统数据驱动器通过SATA接口。
SMU 180是控制APU 100上的资源的操作并使这些资源之间的通信同步的本地控制器。SMU 180管理APU 100上的各种处理器的上电定序,并且经由复位、启用和其他信号控制多个芯片外设备。SMU 180包括一个或多个时钟源(未示出),诸如锁相环路(PLL),以为APU 100的每个部件提供时钟信号。SMU 180还管理各种处理器和其它功能块的功率,并且可从CPU核心112和114以及图形核心120接收测量功率消耗值以确定适当的功率状态。
在该实施方案中,存储器管理集线器140及其相关联的物理接口(PHY)151和152与APU 100集成。存储器管理集线器140包括存储器通道141和142以及功率引擎149。存储器通道141包括主机接口145、存储器通道控制器143和物理接口147。主机接口145通过串行存在检测链路(SDP)将存储器通道控制器143双向连接至数据结构125。物理接口147将存储器通道控制器143双向连接至PHY 151,并且符合DDR PHY接口(DFI)规范。存储器通道142包括主机接口146、存储器通道控制器144和物理接口148。主机接口146通过另一SDP将存储器通道控制器144双向连接至数据结构125。物理接口148将存储器通道控制器144双向连接至PHY152,并且符合DFI规范。功率引擎149通过SMN总线双向连接到SMU 180,通过APB连接到PHY151和PHY 152,并且还双向连接到存储器通道控制器143和144。PHY 151具有到存储器通道131的双向连接。PHY 152具有双向连接存储器通道133。
存储器管理集线器140是具有两个存储器通道控制器的存储器控制器的实例化,并且使用共享功率引擎149以将在下面进一步描述的方式控制存储器通道控制器143和存储器通道控制器144两者的操作。存储器通道141和142中的每一者都可以连接至现有技术DDR存储器,诸如第五代DDR(DDR5)、第四代DDR(DDR4)、低功率DDR4(LPDDR4)、第五代图形DDR(GDDR5)和高带宽存储器(HBM),并且可以适于未来存储器技术。这些存储器提供高总线带宽和高速操作。同时,它们还提供低功率模式以节省用于电池供电应用诸如膝上型计算机的功率,并且还提供内置热监控。
存储器系统130包括存储器通道131和存储器通道133。存储器通道131包括连接至DDRx总线132的一组双列直插存储器模块(DIMM),包括代表性的DIMM 134、136和138,它们在该示例中对应于单独的存储列。同样,存储器通道133包括连接至DDRx总线129的一组DIMM,包括代表性的DIMM 135、137和139。
APU 100作为主机数据处理系统的中央处理单元(CPU)操作并且提供在现代计算机系统可用的各种总线和接口。这些接口包括两个双数据速率(DDRx)存储器通道、用于连接至PCIe链路的PCIe根复合体、用于连接至USB网络的USB控制器以及到SATA大容量存储设备的接口。
APU 100还实现各种系统监控和功率节省功能。具体地,一个系统监测功能是热监测。例如,如果APU 100变热,则SMU 180可降低CPU核心112和114和/或图形核心120的频率和电压。如果APU 100变得过热,则可将其完全关断。SMU 180还可经由SMN总线从外部传感器接收热事件,并且作为响应,SMU 180可降低时钟频率和/或电源电压。
图2以框图形式示出了现有技术中已知的存储器控制器200。存储器控制器200包括存储器通道控制器210和功率控制器250。存储器通道控制器210包括接口212、存储器接口队列214、命令队列220、地址生成器222、内容可寻址存储器(CAM)224、重放队列230、刷新逻辑部件块232、定时块234、页表236、仲裁器238、纠错码(ECC)检查块242、ECC生成块244和数据缓冲器(DB)246。
接口212具有通过外部总线到数据结构125的第一双向连接,并且具有输出端。在存储器控制器200中,该外部总线与由ARM Holdings,PLC of Cambridge,England规定的高级可扩展接口版本四(称为AXI4)兼容,但在其他实施方案中可以是其他类型的接口。接口212将存储器访问请求从称为FCLK(或MEMCLK)域的第一时钟域转换到存储器控制器200内部的称为UCLK域的第二时钟域。类似地,存储器接口队列214提供从UCLK域到与DFI接口相关联的DFICLK域的存储器访问。
地址生成器222解码通过AXI4总线从数据结构125接收的存储器访问请求的地址。存储器访问请求包括物理地址空间中以归一化地址表示的访问地址。地址生成器222将归一化地址转换成可用于对存储器系统130中的实际存储器设备进行寻址以及高效地调度相关访问的格式。该格式包括将存储器访问请求与特定存储列、行地址、列地址、存储体地址和存储体组相关联的区域标识。在启动时,系统BIOS查询存储器系统130中的存储器设备以确定它们的大小和配置,并且对与地址生成器222相关联的一组配置寄存器进行编程。地址生成器222使用存储在配置寄存器中的配置来将归一化地址转换成适当格式。命令队列220是从APU 100中的存储器访问代理诸如CPU核心112和114以及图形核心120接收的存储器访问请求的队列。命令队列220存储由地址生成器222解码的地址字段以及允许仲裁器238高效地选择存储器访问的其他地址信息,包括访问类型和服务质量(QoS)标识。CAM 224包括实施排序规则诸如写后写(WAW)以及写后读(RAW)排序规则的信息。
重放队列230是用于存储由仲裁器238选取的存储器访问的临时队列,这些存储器访问正在等待响应,诸如地址和命令奇偶校验响应、针对DDR4 DRAM的写入循环冗余校验(CRC)响应或针对GDDR5 DRAM的写入和读取CRC响应。重放队列230访问ECC检查块242以确定所返回的ECC是正确的还是指示错误。重放队列230允许在这些循环中的一个循环的奇偶校验或CRC错误的情况下重放访问。
刷新逻辑部件232包括用于各种下电、刷新和终端电阻(ZQ)校准循环的状态机,这些校准循环与从存储器访问代理接收的正常读取和写入存储器访问请求分开生成。例如,如果存储器存储列处于预充电下电,则必须周期性地唤醒该存储器存储列以运行刷新循环。刷新逻辑部件232周期性地生成自动刷新命令,以防止由于电荷从DRAM芯片中的存储器单元的存储电容器泄漏而引起的数据错误。此外,刷新逻辑部件232周期性地校准ZQ以防止由于系统的热变化而导致的管芯上终端电阻的失配。刷新逻辑部件232还决定何时将DRAM设备置于不同的掉电模式。
仲裁器238双向连接到命令队列220并且是存储器通道控制器210的核心。该仲裁器通过智能调度访问来提高效率以提高存储器总线的使用率。仲裁器238使用定时块234通过基于DRAM定时参数确定命令队列220中的某些访问是否有资格发布来实施正确的定时关系。例如,每个DRAM在对同一存储体的激活命令之间具有最小规定时间,称为“t
响应于从接口212接收到写入存储器访问请求,ECC生成块244根据写入数据计算ECC。DB 246存储所接收的存储器访问请求的写入数据和ECC。当仲裁器238选取对应写入访问以用于调度到存储器通道时,数据缓冲器将组合写入数据/ECC输出到存储器接口队列214。
功率控制器250包括到高级可扩展接口版本一(AXI)的接口252、APB接口254和功率引擎260。接口252具有到SMN的第一双向连接,该第一双向连接包括用于接收图2中单独示出的标记为“EVENT_n”的事件信号的输入端,以及输出端。APB接口254具有连接到接口252的输出端的输入端,以及用于通过APB连接到PHY的输出端。功率引擎260具有连接到接口252的输出端的输入端,以及连接到存储器接口队列214的输入端的输出端。功率引擎260包括一组配置寄存器262、微控制器(μC)264、自刷新控制器(SLFREF/PE)266和可靠读取/写入训练引擎(RRW/TE)268。配置寄存器262通过AXI总线编程,并且存储配置信息以控制存储器控制器200中各种块的操作。因此,配置寄存器262具有连接到这些块的输出端,这些块在图2中未详细示出。自刷新控制器266是除了由刷新逻辑部件232自动生成刷新之外还允许手动生成刷新的引擎。可靠读取/写入训练引擎268向存储器或I/O设备提供连续存储器访问流,用于诸如DDR接口读取时延训练和回送测试等目的。
存储器通道控制器210包括允许其选取存储器访问以用于调度到相关联的存储器通道的电路系统。为了做出期望的仲裁决定,地址生成器222将地址信息解码成预解码信息,预解码信息包括存储器系统中的存储列、行地址、列地址、存储体地址和存储体组,并且命令队列220存储预解码信息。配置寄存器262存储配置信息以确定地址生成器222解码所接收的地址信息的方式。仲裁器238使用所解码的地址信息、由定时块234指示的符合定时条件信息以及由页表236指示的活动页面信息来高效地调度存储器访问,同时遵守诸如QoS要求等其他标准。例如,仲裁器238实现对访问打开页面的优先,以避免改变存储器页面所需的预充电和激活命令的开销,并且通过将对一个存储体的开销访问与对另一个存储体的读取和写入访问交错来隐藏对一个存储体的开销访问。特别是在正常操作期间,仲裁器238可决定保持页面在不同存储体中打开,直到需要对这些页面进行预充电,然后选择不同的页面。
图3以框图形式示出了根据一些实施方案的可以用于图1的APU 100中的存储器控制器300。存储器控制器300包括具有与图2中的标号对应的标号的许多元件。由于这些元件以相同或相似的方式起作用,因此将不再描述这些元件。
然而,存储器控制器300在多存储列系统中比图2的存储器控制器200更有效地操作,并且现在将描述存储器控制器300与存储器控制器200之间的差异。除了与图2的命令队列220类似地操作的命令队列320之外,存储器控制器300还包括分级缓冲器326和挑选器328。分级缓冲器326具有连接到地址生成器322的输出端的输入端以及输出端。挑选器328具有连接到分级缓冲器326的输入端、连接到页表336的第二输出端的控制输入端以及连接到命令队列320的输入端的输出端。页表336类似于图2的页表236,但已被修改,以提供关于当前选择的存储列的附加信息以及在一些实施方案中的附加存储列信息,如现在将描述的。
在操作中,存储器控制器300在多存储列存储器系统中比图2的存储器控制器200更有效地操作。相反地,存储器控制器300需要比图2的存储器控制器200更小的电路面积,以在多存储列系统中以特定存储列切换效率操作。
存储器控制器300添加分级缓冲器326和挑选器328,以针对给定大小的命令队列320提供较高存储列命中率。此外,如下文将进一步描述,存储器控制器300还促进在多存储列存储器系统中的有效写入到读取切换。地址生成器322将存储器访问解码成至少一个存储列。在一个特定实施方案中,地址生成器322将访问解码成存储列、存储体、行和列。分级缓冲器326接收并存储已由地址生成器322解码的存储器访问请求。分级缓冲器326仅用于基于存储列而不是基于其他仲裁标准在访问中挑选,并且在每个条目中需要更少的字段。因此,分级缓冲器326中的每个条目需要比命令队列320中的对应条目少的电路面积。
挑选器328从存储在分级缓冲器326中的存储器访问请求中挑选,并且将选定的访问提供给命令队列320的输入端。在一个实施方案中,挑选器328挑选对当前存储列和对第二存储列的访问,而不是对任何其他存储列的访问。在这种情况下,页表336存储当前存储列和第二存储列(或其指示),并将当前存储列和第二存储列提供给挑选器328。在这种情况下,页表336从仲裁器338接收当前存储列和第二存储列,并且除了每个存储体和存储列的当前页之外还存储当前存储列和第二存储列,并且将当前存储列提供给挑选器328的输入端。挑选器328从当前存储列和第二存储列中挑选来自分级缓冲器326的访问,而不是对任何其它存储列的访问。挑选器328尝试以循环方式从两个存储列挑选大约相同数量的访问,以隐藏单存储列四访问窗口(t
在另一实施方案中,挑选器328挑选对由仲裁器338选择的当前存储列的访问,而不是对任何其它存储列的访问。在这种情况下,页表336从仲裁器338接收当前存储列(或当前存储列的指示),并且除了每个存储体和存储列的当前页之外还存储当前存储列,并且将当前存储列提供给挑选器328的输入端。如果没有对分级缓冲器326中的当前存储列的剩余访问,则挑选器328按照所接收的顺序从分级缓冲器326挑选访问。
由于包括分级缓冲器326和挑选器328,存储器控制器300增加在需要存储列切换之前可以从命令队列320挑选的相同存储列访问的平均数量。通过根据命令队列320的深度和分级缓冲器326的深度这两者增加存储器访问命令窗口大小来实现这一点。这种机制减少了在访问序列期间存储列切换的数量。此外,分级缓冲器326中的每个条目显著小于命令队列320中的对应条目,并且因此存储器控制器300在附加电路面积与提高的存储列切换效率之间做出更好的权衡。
在具有大量存储列的多存储列系统中,与图2的存储器控制器200相比,分级缓冲器326提供存储列切换效率的显著增加。例如,命令队列320可以在32存储列存储器系统中具有总共64个条目。如果访问均匀地分布在多个存储列上,则平均起来,命令队列320将存储来自每个存储列的两个访问。与具有数量少得多的存储列的系统相比,每两个存储器访问请求执行一次存储列周转将产生显著更低的效率。存储器控制器300添加分级缓冲器326以增加对仲裁器338可见的访问窗口,使得可将对当前存储列和第二存储列的更多访问放置于命令队列320中。同时,这不增加命令队列320的大小或仲裁器338的复杂性。
命令队列320中的条目包括比分级缓冲器326中的条目更多的字段。挑选器328仅基于存储列挑选分级缓冲器326的条目,以提供给命令队列320。因此,挑选器328可以被实现为相对简单的电路。此外,由于其每个条目的较小尺寸,分级缓冲器326可以包括比命令队列320更多的条目。该特征在具有大量预期存储器存储列的多存储列系统中是重要的。
由于相同存储体写入到读取周转,在多存储列系统中出现附加的效率问题。现在将描述该机制以及用于处理该问题的改进的仲裁系统。
图4示出了例示写入到读取周转时间的部件的时序图400。在图4中,水平轴表示以皮秒(ps)为单位的时间,垂直轴表示以伏特为单位的各种感兴趣信号的振幅。时序图400包括标记为“CK”的存储器命令时钟信号及其标记为“CK#”的补足物的波形410、标记为“COMMAND”的命令信号的波形420、标记为“ADDRESS”的地址信号的波形430、标记为“DQS”的真实数据选通信号及其标记为“DQS#”的补足物的波形440、以及表示复合数量(例如,八位)的数据信号的标记为“DQ”的数据信号的波形450。
CK和CK#信号形成差分时钟信号,DDR存储器芯片使用该差分时钟信号来记录命令并对数据的输入和输出进行定时。时序图400示出了标记为“T0”到“T9”的特定转变以及在由存储器和时钟速度确定的T7之后的时间量发生的标记为“Tn”的转变。
COMMAND被记录在CK信号的低到高转变和CK#信号的高到低转变上。时序图400中所示的是在T0处发生的写入命令,随后是在Tn处发生的读取命令,这些命令由对COMMAND信号的无操作(NOP)编码分开。COMMAND信号包括存储器控制器300用来对特定类型的命令进行编码的一组单独的信号。这些信号及其编码由对应的DDR标准规定,并且因为这些信号及其编码是公知的,所以将不再进一步描述。
如时序图400中所示,时间T0处的WRITE周期针对标记为“存储体,列n”的给定存储列中的特定存储体和列,并且READ周期针对标记为“存储体,列b”的Tn处的相同存储列的不同存储体和列。T0和Tn之间的最小时间量被称为周转时间,并且在这种情况下是相同存储列写入到读取周转时间。相同存储列写入到读取周转时间由三个单独的定时组件确定,现将参考时序图400中所示的特定WRITE命令来描述这三个单独定时组件。
从发出WRITE命令直到将写入数据提供给存储器芯片的时间量被称为列写入时延或t
由对T0的WRITE命令发起的写入周期使在时间T5开始写入数据。在T5之前,存储器控制器在DQS和DQS#信号中提供前同步码时段。时序图400是DDR4 SDRAM的时序图,并且前同步码包括在T4处在半个时钟周期变为高、然后在半个时钟周期变为低、并且然后在T5处再次变为高以使第一数据元素被写入到存储器的DQS。如时序图400所示,写入周期是4个突发,其中,数据在由DQS和DQS#信号的四个连续转变定义的四个半周期上传送。对于写入周期,存储器控制器驱动数据选通信号DQS和DQS#以及数据信号DQ两者。DQS和DQS#信号中的转变发生在存储器芯片处的每个数据值的有效时间的中间,在时序图400中显示为值“D
从DQS后同步码的末端直到可以接受随后的READ命令的时间量对于写入到读取时间或t
总的相同存储列写入到读取周转时间由等式1给出:
相同存储列周转时间=t
其中,t
图5示出了可由现有技术中已知的存储器控制器选择的存储器访问的一组时间线500。在时间线500中,时间从左向右前进。时间线500包括第一时间线510和第二时间线520。第一时间线510示出了由开销时段513分开的写入访问突发511和随后的读取访问突发512。如图5及其它地方所使用的,写入或读取访问的“突发”意指一连串或者一系列单独存储器访问命令,每个存储器访问命令包含多个数据传送。虽然一组单独数据传送通常也被称为“突发”,但本公开涉及存储器访问命令的突发而非单独数据传送。然而,根据其上下文,“突发”的适当含义将是显而易见的。
在写入访问突发511中,标记为“W
在读取访问突发512中,标记为“R
开销时段513表示存储器控制器不能挑选任何存储器访问的时间段,因为存储器访问有相同存储列写入到读取周转时间而尚未变为符合定时条件。该时间段相对较长,并且显著降低了系统的效率。
第二时间线520示出了由开销时段523分开的写入访问突发521和随后的读取访问突发522。第二时间线520类似于第一时间线510,除了在对存储体1的最后访问之后的相同存储体写入到读取周转时间期满时不存在可用的读取访问。因此,存储器控制器在对存储体0的最后访问之后等待整个相同存储体写入到读取周转时间。随后,在第一读取访问之前,对存储列1的读取访问变为可用,并且存储器控制器在对存储列0的访问之后在读取突发中挑选该读取访问。
发明人已发现,接近写入突发(例如,写入访问突发511或521)结束的存储列切换由于长的相同存储体写入到读取周转时间而增加了低效率。然而,根据本文中所公开的各种实施方案,数据处理器和方法避免接近写入突发结束的存储列切换,并且将泡沫减少到小得多的量,借此增加存储器控制器效率。
为了解决该效率问题,发明人已经发现,在多存储列系统中存在降低通常由写入到读取周转引起的低效率的机会,并且已经开发了具有仲裁器338的数据处理器和存储器控制器,仲裁器利用该机会来提高效率和存储器总线利用率。
图6示出了根据一些实施方案的图3的存储器控制器300的部分600的框图。部分600包括仲裁器238和与仲裁器238的操作相关联的一组控制电路660。
仲裁器238包括一组子仲裁器605和最终仲裁器650。子仲裁器605包括子仲裁器610、子仲裁器620和子仲裁器630。子仲裁器610包括标记为“PH ARB”的页命中仲裁器612以及输出寄存器614。页命中仲裁器612具有连接到命令队列220的第一输入端、第二输入端和输出端。寄存器614具有连接到页命中仲裁器612的输出端的数据输入端、用于接收UCLK信号的时钟输入端以及输出端。子仲裁器620包括标记为“PC ARB”的页冲突仲裁器622以及输出寄存器624。页冲突仲裁器622具有连接到命令队列220的第一输入端、第二输入端和输出端。寄存器624具有连接到页冲突仲裁器622的输出端的数据输入端、用于接收UCLK信号的时钟输入端以及输出端。子仲裁器630包括标记为“PM ARB”的页未命中仲裁器632以及输出寄存器634。页未命中仲裁器632具有连接到命令队列220的第一输入端、第二输入端和输出端。寄存器634具有连接到页未命中仲裁器632的输出端的数据输入端、用于接收UCLK信号的时钟输入端以及输出端。最终仲裁器650具有连接到刷新逻辑部件232的输出端的第一输入端、来自页关闭预测器662的第二输入端、连接到输出寄存器614的输出端的第三输入端、连接到输出寄存器624的输出端的第四输入端、连接到输出寄存器634的输出端的第五输入端、以及用于向存储器接口队列214提供标记为“CMD”的仲裁获胜者的输出端。在一些实施方案中,最终仲裁器650能够在每个存储器控制器时钟周期挑选两个子仲裁获胜者。
控制电路660包括如先前关于图2所描述的定时块234和页表236,以及页关闭预测器662、当前模式寄存器602和交叉模式启用逻辑部件604。定时块234具有连接到交叉模式启用逻辑部件604的输出端、连接到页命中仲裁器612、页冲突仲裁器622和页未命中仲裁器632的输入端和输出端。页表234具有连接到重放队列230的输出端的输入端、连接到重放队列230的输入端的输出端、连接到命令队列220的输入端的输出端、连接到定时块234的输入端的输出端和连接到页关闭预测器662的输入端的输出端。页关闭预测器662具有连接到页表236的一个输出端的输入端、连接到输出寄存器614的输出端的输入端以及连接到最终仲裁器650的第二输入端的输出端。交叉模式启用逻辑部件604具有连接到当前模式寄存器602的输入端和连接到命令队列220的输入端、连接到最终仲裁器650的输入端和输出端、以及连接到子仲裁器610、子仲裁器620和子仲裁器630的输入端和输出端。
在操作中,仲裁器338通过考虑当前模式(指示读取拖尾还是写入拖尾在进行中)、每个条目的页状态、每个存储器访问请求的优先级和这些请求之间的相关性而从命令队列220和刷新逻辑部件232选择存储器访问命令。优先级与从AXI4总线接收并存储在命令队列220中的请求的服务质量或QoS相关,但是可以基于存储器访问的类型和仲裁器238的动态操作来更改。仲裁器238包括三个子仲裁器,这三个子仲裁器并行操作以用于解决现有集成电路技术的处理和传输限制之间的失配。相应子仲裁的获胜者被呈现给最终仲裁器650。最终仲裁器650在这三个子仲裁获胜者之间进行选择以及选择来自刷新逻辑部件232的刷新操作,并且可以进一步将读取或写入命令修改为具有如由页关闭预测器662确定的自动预充电命令的读取或写入。
交叉模式启用逻辑部件604操作以引起和管理存储器通道上读取命令的拖尾和写入命令的拖尾。在任一类型的命令的当前拖尾期间,交叉模式启用逻辑部件604监视存储器通道的数据总线效率的指示。响应于数据总线效率的指示指示数据总线效率低于指定阈值,交叉模式启用逻辑部件304停止当前拖尾,开始另一类型的拖尾,并且改变当前模式寄存器602中的当前模式。
页命中仲裁器612、页冲突仲裁器622和页未命中仲裁器632中的每一者都具有连接到定时块234的输出端以确定命令队列220中落入这些相应类别中的命令的符合定时条件的输入端。定时块234包括二进制计数器的阵列,该阵列对与针对每个存储列中的每个存储体的特定操作相关的持续时间进行计数。确定状态所需的定时器的数目取决于定时参数、给定存储器类型的存储体的数量以及系统在给定存储器通道上支持的存储列的数量。所实现的定时参数的数目进而取决于系统中所实现的存储器的类型。例如,与其它DDRx存储器类型相比,GDDR5存储器需要更多的定时器来遵守更多的定时参数。通过包括被实现为二进制计数器的通用定时器的阵列,定时块234可以被缩放并且重新用于不同的存储器类型。来自交叉模式启用逻辑部件604的输入端向子仲裁器发信号通知提供哪种类型的命令(读取或写入)作为最终仲裁器650的候选。
页命中是对打开页的读取或写入周期。页命中仲裁器612在命令队列220中的访问之间仲裁以打开页。由定时块234中的定时器跟踪并且由页命中仲裁器612检查的符合定时条件参数包括例如行地址选通(RAS)到列地址选通(CAS)延迟时间(t
页冲突是当存储体中的一行当前被激活时对该存储体中的另一行的访问。页冲突仲裁器622在命令队列220中对与当前在对应的存储体和存储列中打开的页冲突的页的访问之间进行仲裁。页冲突仲裁器622选择导致发出预充电命令的子仲裁获胜者。由定时块234中的定时器跟踪并由页冲突仲裁器622检查的符合定时条件参数包括例如活动到预充电命令时段(t
页未命中是对处于预充电状态的存储体的访问。页未命中仲裁器632在命令队列220中对预充电的存储体的访问之间进行仲裁。由定时块234中的定时器跟踪并由页未命中仲裁器632检查的符合定时条件参数包括例如预充电命令时段(t
每个子仲裁器为它们各自的子仲裁获胜者输出优先级值。最终仲裁器650比较来自页命中仲裁器612、页冲突仲裁器622和页未命中仲裁器632中的每一者的子仲裁获胜者的优先级值。最终仲裁器650通过执行一次考虑两个子仲裁获胜者的一组相对优先级比较来确定子仲裁获胜者之间的相对优先级。子仲裁器可以包括一组逻辑,该组逻辑用于仲裁针对每个模式读取和写入的命令,使得当当前模式改变时,一组可用的候选命令作为子仲裁获胜者是可快速获得的。
在确定这三个子仲裁获胜者之间的相对优先级之后,最终仲裁器650然后确定这些子仲裁获胜者是否冲突(即,它们是否指向相同存储体和存储列)。当不存在此类冲突时,则最终仲裁器650选择最多两个具有最高优先级的子仲裁获胜者。当存在冲突时,则最终仲裁器650遵循以下规则。当页命中仲裁器612的子仲裁获胜者的优先级值高于页冲突仲裁器622的子仲裁获胜者的优先级值并且两者均指向相同存储体和存储列时,则最终仲裁器650选择由页命中仲裁器612指示的访问。当页冲突仲裁器622的子仲裁获胜者的优先级值高于页命中仲裁器612的子仲裁获胜者的优先级值时并且两者均指向相同存储体和存储列时,则最终仲裁器650基于若干附加因素选择获胜者。在一些情况下,页关闭预测器662通过设定自动预充电属性而使页在由页命中仲裁器612指示的访问结束时关闭。
在页命中仲裁器612内,优先级最初由来自存储器访问代理的请求优先级设定,但基于访问类型(读取或写入)和访问序列而动态地调整。一般来讲,页命中仲裁器612将较高隐式优先级分配给读取,但实现优先级提升机制以确保写入在完成方面取得进展。
每当页命中仲裁器612选择读取或写入命令时,页关闭预测器662就确定是否发送具有自动预充电(AP)属性的命令。在读取或写入周期期间,自动预充电属性用预定义地址位来设定,并且自动预充电属性致使DDR设备在读取或写入周期完成之后关闭页,这避免了存储器控制器稍后发送用于该存储体的单独预充电命令的需要。页关闭预测器662考虑命令队列220中已经存在的访问与所选择命令访问的存储体相同的存储体的其他请求。如果页关闭预测器662将存储器访问转换成AP命令,则对该页的下一次访问将是页未命中。
交叉模式启用逻辑部件604通过控制子仲裁器605以避免接近写入突发结束的存储列切换,来减少由相同存储列写入到读取周转时间引起的低效率。为了完全隐藏相同存储列的写入到读取开销,将需要在写入突发结束处可用的相同存储列的写入请求的数量L:
L=(t
其中,t
在一个示例中,交叉模式启用逻辑部件604可通过确定命令队列320中的写入的总数量小于固定阈值来确定交叉模式启用逻辑部件接近写入突发“结束”。在另一示例中,交叉模式启用逻辑部件604可通过确定命令队列320中对与当前存储列不同的存储列的写入的数量小于L而确定交叉模式启用逻辑部件接近写入突发“结束”。在任一情况下,当交叉模式启用逻辑部件604检测到“接近结束”条件时,交叉模式启用逻辑部件不允许写入突发切换到另一存储列。当切换到读取突发时,这些约束可能使一些写入不在突发之中。
图7示出了根据一些实施方案的由图6的仲裁器338选择的存储器访问的时间线700。在时间线700中,时间从左向右前进。时间线700示出了由开销时段730分开的写入访问突发710和随后的读取访问突发720。写入访问突发710包括对存储列1的写入访问,随后是对存储列0的四个写入访问。读取访问突发720包括对存储列1的四个读取访问,随后是对存储列0的读取访问。如时间线700中所示,符合定时条件包括从对存储列1的写入访问结束到在读取访问突发720的开始处满足的对存储列1的第一读取访问的相同存储体写入到读取周转时间。类似地,存在从对存储列0的最后写入访问结束到在读取访问突发720中对存储列0的读取访问开始时满足的对存储列0的读取访问的相同存储体写入到读取周转时间。
另外,存在标记为“t
t
分级缓冲器326可增强避免相同存储列写入到读取周转时间损失的能力,这可通过使用分级缓冲器326来辅助。如果命令队列320可以看到来自许多存储列的请求,则命令队列自然将更频繁地进行存储列切换。为了避免命令队列320看到来自太多存储列的请求,挑选器328可以在分级缓冲器326中临时留下不想要的请求。以这种方式,分级缓冲器326和挑选器328可以通过仅从两个活动存储列挑选请求来将多存储列业务重新整形为两存储列业务。
例如,可以从分级缓冲器326中挑选在五个存储列上均匀分布并且在读取和写入之间均等划分的请求序列,使得命令队列320一次仅聚焦于两个存储列。该技术确保大多数命令请求仅来自两个存储列而不是来自多个存储列,并且防止CAS命令之间的太多存储列切换时间。挑选器328将从两个优选存储列挑选请求,直到来自分级缓冲器的请求耗尽为止,并且然后将移动到另一存储列(如果第一存储列在第二存储列之前耗尽)或者移动到两个其他存储列(如果第一存储列和第二存储列同时耗尽)。
图8是根据一些实施方案的用于从多存储列系统选择访问的技术的流程图800。在动作框810中,存储器控制器300发起写入突发。在动作框820中,存储器控制器300执行对当前存储列的写入访问。然后,在判定框830中,存储器控制器300通过例如交叉模式启用逻辑部件604确定其是否接近写入突发的结束。例如,交叉模式启用逻辑部件604可以确定命令队列320中的写入访问的总数是否小于预定数量。在另一示例中,交叉模式启用逻辑部件604可以确定命令队列320中对当前存储列的写入访问的数量是否足以隐藏相同存储体写入到读取周转时间的开销。如果存储器控制器300不接近写入突发的结束,则在动作框831中,存储器控制器300确定是否选择性地将当前存储列切换到另一存储列。该切换可以基于其它常规存储器控制器选择标准。在选择性地切换当前存储列之后,流程返回到动作框820。然而,如果存储器控制器300接近写入突发的结束,则在动作框840中,存储器控制器继续对当前存储列进行写入突发达预定次数。选择该预定数量,以隐藏相同存储列写入到读取周转时间。在动作框850中,等待短得多的存储列写入到读取周转时间t
所公开的技术通过避免相同存储体写入到读取周转时间,而是仅等待不同存储体写入到读取周转时间的开销来提高存储器访问的效率,假定对不相同存储列的某种读取访问是可用的。此外,这依赖于现有符合定时条件的检验,以允许仲裁器基于正常符合定时条件标准在写入突发结束之后自然地选择任何符合定时条件的读取访问。
数据处理器100或其任何部分(例如,存储器控制器300)可由呈数据库形式的计算机可访问数据结构或可由程序读取并且直接或间接用于制造集成电路的其他数据结构来描述或表示。例如,该数据结构可以是高级设计语言(HDL)诸如Verilog或VHDL中的硬件功能性的行为级描述或寄存器传送级(RTL)描述。描述可由合成工具读取,合成工具可合成描述以产生包括来自合成库的门列表的网表。网表包括门集,门集也表示包括集成电路的硬件的功能性。然后可以放置和路由网表以产生描述待应用于掩码的几何形状的数据集。然后可以在各种半导体制造步骤中使用掩模以产生集成电路。另选地,计算机可访问存储介质上的数据库可以是网表(具有或不具有合成库)或数据集(根据需要)或图形数据系统(GDS)II数据。
虽然已描述了特定实施方案,但是对这些实施方案的各种修改对于本领域技术人员将是显而易见的。例如,确定存储器控制器何时接近写入突发结束的各种技术都是可能的。此外,写入到读取周转技术可独立于分级缓冲器和挑选器或与分级缓冲器和挑选器结合使用,其中,分级缓冲器和挑选器非常适合于扩展用于选择期望访问以放置于多存储列系统中的命令队列中的窗口。虽然描述了从分级缓冲器挑选当前存储列和第二存储列以提供给命令队列的示例,但可选择不同数量的附加存储列。此外,在其它实施方案中,仲裁器的电路结构可以是不同的。
因此,所附权利要求书旨在覆盖所公开实施方案的落入所公开实施方案的范围内的所有修改。
- 一种适用于硬质合金硬面加工的硬质合金条/块及其粘结方法
- 一种高性能YC50硬质合金及其加工方法
- 一种适用于不锈钢加工的硬质合金及其制备方法
- 一种硬质合金加工作业数据的信息管理系统
- 一种银行数据加工作业调度系统及其方法