一种基于大数据的半导体厂良率预测与提升的方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及集成电路技术领域,特别涉及一种基于大数据的半导体厂良率预测与提升的方法。
背景技术
在集成电路制造过程中,良率与生产单位的利益直接相关。而在生在过程中,会出现大量的测试数据,包括在线Inline数据(主要是错误检测与分类(Fault Detection andClassification,FDC)数据)、缺陷(defect)数据、晶圆验收测试(Wafer Acceptance Test,WAT)数据和晶圆探针测试(Chip Probing,CP)数据。其中WAT数据主要是对晶圆进行电学性能的测试来监控生产过重中出现的工艺波动的稳定性,通过WAT测试后再进行CP测试。然而WAT数据通常含有几十到几百个测试变量包括晶体管的电压、电阻、电容等各项参数,并且数据量非常庞大。传统的分析方法采用T检验值、方差分析和平均值比较的方法来确定这些测试变量是否存在问题,然而这些方法存在一定的局限性,首先这些方法并不能与晶圆良率相关联,第二这些数据的维度非常的高,上述分析方法需要工程师进行手动分析费时费力,第三如果工艺参数发生变化这些分析方法也需要发生变化,如果还基于上述分析,可能会导致生产资源的浪费,同时传统的WAT测试数据分析方法与晶圆良率很难产生关联,数据维度过高导致分析费时费力,分析结果甚至可能出现出错。
发明内容
针对现有技术存在的问题及技术要求,本发明的目的是提供了一种基于大数据的半导体厂良率预测与提升的方法,对收集半导体厂中的WAT数据和CP数据的不平衡性做出预处理,同时对高维数据进行了降维处理,增强了模型的鲁棒性和可解释性,最后采用了机器学习模型将大数据同晶圆良率进行关联,分析出导致良率的下降的测试因素。
为了达到上述目的,本发明采用以下技术方案实现:
一种基于大数据的半导体厂良率预测与提升的方法,包括以下步骤:
步骤1:收集半导体厂中晶圆可接受性测试数据和晶圆探针测试(Chip Probing,CP)数据,形成数据集作为原始数据并存储于存储系统;
步骤2:对收集到的晶圆可接受性测试数据和晶圆探针测试数据进行数据预处理,包括异常值处理、缺失值处理和数据归一化;
步骤3:将晶圆验收测试(Wafer Acceptance Test,WAT)数据和晶圆探针测试数据进行合并,再进行数据集划分,划分为训练集、测试集和验证集;
步骤4:对晶圆验收测试数据中的训练集进行样本增强,生成平衡样本集;
步骤5:对生成的平衡样本集进行降维处理,通过特征变量筛选的方式筛选出预测性能效果最好的参数集;
步骤6:对处理后的晶圆验收测试数据和晶圆探针测试数据进行晶圆良率预测建模;
步骤7:计算晶圆良率预测模型当中各个特征的特征重要性,输出各个特征的模型重要性,并从大到小排序;
步骤8:计算各个特征的SHAP值,输出每个特征的SHAP值和分析图。
步骤9:根据特征的模型重要性的大小排序和SHAP值及分析图进行良率损失的根因分析。
所述的步骤1中收集的晶圆可接受性测试数据,包括晶体管的电阻、电容、电感的数据、阈值电压、饱和电流、亚阈值电流以及金属互联层的电容、电阻和电感。
所述的步骤1中收集的探针测试数据,包括晶圆中每个裸片的电性测试数据、晶圆的良率数据。
所述的步骤2中的预处理,包括以下步骤:
步骤21:对晶圆可接受性测试数据和晶圆探针测试数据进行异常值处理,去除测试过程中存在的异常情况;
步骤22:对异常值处理后的晶圆可接受性测试数据和晶圆探针测试数据进行缺失值处理,去除测试过程中未保存错误的情况;
步骤23:对缺失值处理后的晶圆可接受性测试数据和晶圆探针测试数据进行数据归一化,去除测试过程中测试参量的量纲不一致情况。
所述的异常值处理,采用的方法为箱线图法、Z-score法、均方差分析法。
所述的缺失值处理,采用的方法为去除缺失值、插值法、均值填充法。
所述的数据归一化,采用的方法为Min-Max归一化、均值方差归一化和批归一化。
所述的步骤4中的样本增强,采用的方法为抗生成网络(Generative AdversarialNetwork,GAN)。
所述的步骤5中特征筛选的方法,采用的方法为Boruta算法与遗传算法结合的算法。
所述的步骤6中晶圆良率预测建模,采用的方法为Catboost模型、随机森林模型、决策树模型、XGboost模型、支持向量机模型。
与现有技术相比,本发明的有益效果是:
本发明一种基于大数据的半导体厂良率预测与提升的方法,通过对收集到的半导体厂中WAT数据和CP数据进行有效的数据增强手段和数据降维方法提升了数据的质量,增强了模型的鲁棒性和可解释性,同时降低了分析的难度,加快了分析的时间,为后续的分析提供了可靠的保障,与此同时,处理后的WAT数据和CP数据进行模型建立和分析,根据模型的结果进行良率的根因分析,可以大大提升根因分析的效率,提高制造厂的经济效益,并且对WAT数据和CP数据的处理过程具有全面性,预测准确性,分析快速性和可靠性。
上述说明仅是本发明技术方案的概述,为了能够更清楚地了解本发明的技术手段,从而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下列举本发明的具体实施方法。
根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述及其他目的、特征和优点,但不作为对本发明的限定。
附图说明
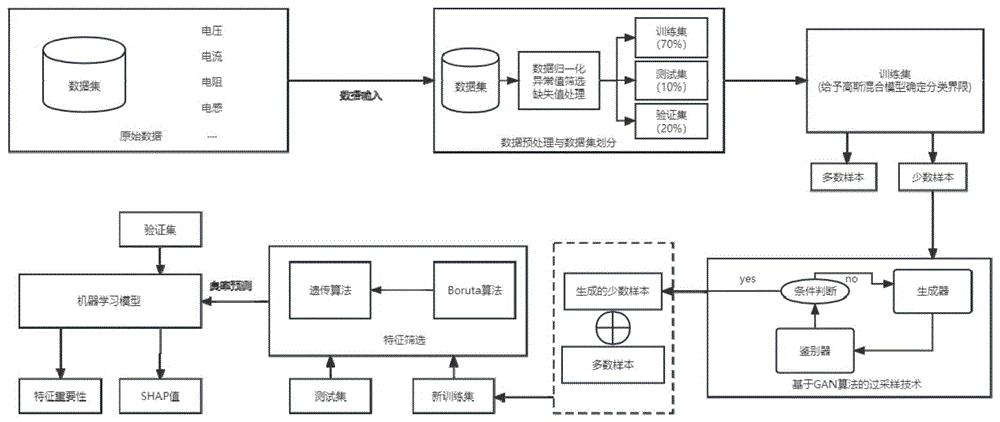
图1是本发明的框架图
图2是本发明的样本增强框架图
具体实施方式
为了便于理解本发明,下面将对本发明进行更全面的描述。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
以下对本发明提供的具体实施方式进行详细说明。
如图1所示,一种基于大数据的半导体厂良率预测与提升的方法,包括以下步骤:
步骤1:收集半导体厂中晶圆可接受性测试数据和晶圆探针测试(Chip Probing,CP)数据,形成数据集作为原始数据并存储于存储系统;
步骤2:对收集到的晶圆可接受性测试数据和晶圆探针测试数据进行数据预处理,包括异常值处理、缺失值处理和数据归一化;
步骤3:将晶圆验收测试(Wafer Acceptance Test,WAT)数据和晶圆探针测试数据进行合并,再进行数据集划分,划分为训练集、测试集和验证集;
步骤4:对晶圆验收测试数据中的训练集进行样本增强,生成平衡样本集;
步骤5:对生成的平衡样本集进行降维处理,通过特征变量筛选的方式筛选出预测性能效果最好的参数集;
步骤6:对处理后的晶圆验收测试数据和晶圆探针测试数据进行晶圆良率预测建模;
步骤7:计算晶圆良率预测模型当中各个特征的特征重要性,输出各个特征的模型重要性,并从大到小排序;
步骤8:计算各个特征的SHAP值,输出每个特征的SHAP值和分析图。
步骤9:根据特征的模型重要性的大小排序和SHAP值及分析图进行良率损失的根因分析。
在步骤1中收集的晶圆可接受性测试数据,包括晶体管的电阻、电容、电感的数据、阈值电压、饱和电流、亚阈值电流以及金属互联层的电容、电阻和电感。
在步骤1中收集的探针测试数据,包括晶圆中每个裸片的电性测试数据、晶圆的良率数据。
其中,晶圆可接受性测试通常包含几十测试到几百项测试不等,探针测试数据通常包括几十类测试类别,每个测试类别包含不同的电性功能测试。
在步骤2中的预处理,包括以下步骤:
步骤21:对晶圆可接受性测试数据和晶圆探针测试数据进行异常值处理,去除测试过程中存在的异常情况,例如测试时探针与晶圆接触存在的接触不良或者测试值保存错误等情况;
步骤22:对异常值处理后的晶圆可接受性测试数据和晶圆探针测试数据进行缺失值处理,去除测试过程中未保存错误的情况;
步骤23:对缺失值处理后的晶圆可接受性测试数据和晶圆探针测试数据进行数据归一化,去除测试过程中测试参量的量纲不一致情况。
其中,异常值处理,采用的方法为箱线图法、Z-score法、均方差分析法等方法。
缺失值处理,采用的方法为去除缺失值、插值法、均值填充法等方法。
数据归一化,采用的方法为Min-Max归一化、均值方差归一化和批归一化等方法。
在步骤3中的数据合并,将训练集、测试集和验证集的比例设置为7:2:1。
在步骤4中的样本增强,采用的方法为抗生成网络(Generative AdversarialNetwork,GAN)。
在步骤4中,根据半导体厂对产品不同的研发时期,晶圆良率的分布情况通常有所差异,在研发阶段,通常是高良率晶圆的数量远远少于低良率晶圆的数量,在成熟的量产阶段,高良率晶圆的数量远远多于低良率晶圆的数量,对这些不同的良率分布,都需要进行数据增强的技术来增强后续机器学习或深度学习模型的可靠性。
如图2所示,样本增强方法是将样本中的少数类样本输入进模型中进行学习,并生成少数类样本,使其跟多数类样本数量一致。通常,抗生成网络包括一个生成器和一个鉴别器,其中生成器用于生成少数类样本,鉴别器用于鉴别生成的少数类样本和原始样本。通过一个对抗式的训练从而达到平衡数据集。
抗生成网络的步骤为:首先对少数类样本施加一个噪声并输入进入生成器中,然后训练鉴别器区分生成少数类样本和原始样本,设置适当的损失函数直到鉴别器其无法区分生成的少数类样本和原始样本,最终生成平衡数据集。
在步骤5中特征筛选的方法,采用的方法为Boruta算法与遗传算法结合的算法,首先通过Boruta算法筛选出特征变量中与因变量最相关的一组特征变量,然后采用遗传算法筛选出对模型效果最好的一组特征变量,其中特征变量包括晶体管的电阻、电容、电感等各项参数。
在步骤6中晶圆良率预测建模,采用的方法为Catboost模型、随机森林模型、决策树模型、XGboost模型、支持向量机模型。
晶圆良率预测建模以预测晶圆良率、失效测试项、失效类别等。
以上所述实例的各技术特征可以进行任意组合,为使描述简洁,未对上述实例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和非实质性的改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。
- 一种曲面微透镜阵列面形检测装置
- 微透镜阵列检测系统及微透镜阵列的检测方法
- 一种微透镜阵列的制备方法
- 一种具有环带分布微环曲面透镜阵列眼镜片及其设计方法
- 一种具有微透镜阵列的离焦眼镜片、设计方法及眼镜