基于公有与私有特征分解的混合可读性评估方法与系统
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于人工智能技术领域,具体涉及基于公有与私有特征分解的混合可读性评估方法与系统。
背景技术
文本可读性(Text Readability)指文本对于阅读者而言易于理解的程度和性质,若阅读文本的可读性相对于读者水平不相匹配,例如太困难或不易理解,对读者的阅读效率和文本理解效果会产生负面影响,因此对于文本可读性的评估对向读者进行阅读材料的选择、推荐等方面具有重要意义。
早期的方法主要依赖于可读性公式,包括Flesch-Kincaid可读性公式、Dale-Chal可读性指标计算公式和SMOG可读性公式。这些方法通过分析文本的浅层特征,如句子长度、单词长度和词汇复杂性,以此来计算文本的可读性分数。然而,这些方法忽略了文本的语义和上下文信息,限制了可读性评估的准确性。
为了克服基于可读性公式的方法的局限性,基于语言特征和机器学习的方法逐渐出现。这些方法提取了文本的结构、句法和语义特征,如词频、句法树结构和情感信息,使用机器学习算法来建立可读性预测的模型。这些方法在一定程度上提高了可读性评估的有效性。然而,手工特征工程仍然是提取重要语言特征来构建可读性分类模型的关键步骤,这使得该方法耗时且劳动密集。
最近深度学习技术的快速发展为文本可读性评估带来了新的可能性。利用深度学习方法使文本特征和上下文见解的自动获取成为可能,从而显著提高了可读性预测的精度。学习方法包括递归神经网络(RNNs)、双向长短期记忆网络(Bi-LSTM)和Transformer模型。最初的神经方法是基于预先训练的词嵌入构建的,如:HAN采用多层次的注意机制来捕获重要的单词和句子,利用Bi-GRU来生成句子和单个单词的表示,最终形成一个全面的文本表示;Vec2Read通过合并语法和形态学等单词级信息来增强HAN。然而,嵌入的静态特性往往限制了它们在特定上下文中表达细微的语义细微差别的能力。因此,出现了基于Transformer的新技术。如DTRA模型,其是一个受HAN启发改进的模型,利用BERT和软标签进行有序回归,显示出比HAN优越的性能。
虽然现有的ARA(Automatic Readability Assessment,自动可读性评估)模型在一些可读性评估任务中取得了令人印象深刻的表现,但它们仍然难以对语言学特征实现有效的利用,再如何提取高质量的深度特征方面也存在缺陷,尤其是利用深度特征和语言学特征这两种特征的有效融合提高可读性评估效果方面缺乏效果较好的相关技术。
发明内容
本发明的目的是提供基于公有与私有特征分解的混合可读性评估方法,用于解决现有技术中无法同时有效利用深度特征和语言学特征,难以将两种特征有效融合从而达到较高的可读性评估效果的技术问题。
所述的基于公有与私有特征分解的混合可读性评估方法,包括下列步骤:
步骤一、构建ARA模型;
步骤二、采集一定量文本作为训练集和测试集并对构建的ARA模型进行训练;
步骤三、完成训练后利用训练好的ARA模型对文本进行可读性评估,生成相应的可读性水平标签;
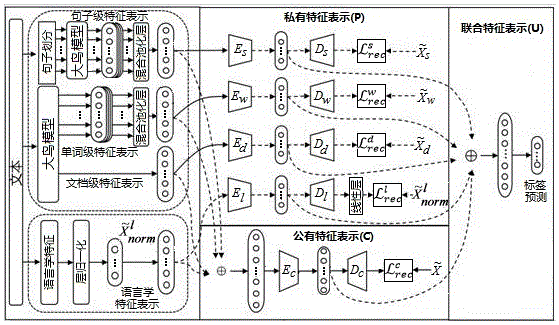
所述ARA模型为CP-ARA模型,所述CP-ARA模型包括深度特征模块、语言特征模块、私有特征模块、公有特征模块和联合特征模块;
所述步骤二具体包括:
S1、通过深度特征模块对文本进行不同深度的深度特征提取生成相应深度特征表示,深度特征表示包括文档级表示、句子级表示和单词级表示;
S2、通过语言特征模块对文本进行语言特征的提取获得语言学特征表示;
S3、对不同深度的深度特征表示和语言学特征表示进行相应私有特征表示和这些特征的公有特征表示的学习,深度特征表示和语言学特征表示输入私有特征模块分别生成相应的私有特征表示,深度特征表示和语言学特征表示连接在一起后输入公有特征模块生成这些特征表示的公有特征表示,私有特征表示和公有特征表示均通过引入自监督学习进行训练;
S4、所得的各个私有特征表示和公有特征表示通过联合特征模块融合后进行可读性标签的标签预测,标签预测通过联合损失进行训练。
优选的,所述步骤S1中,不同深度的深度特征表示的生成方法如下:通过预训练的长序列变换器BigBird直接提取文档级信息中的深度特征从而得到文档级表示
优选的,所述步骤S2中,通过语言特征模块中的语言特征提取器从文本中提取多个语言特征,然后对这些语言特征进行层归一化获得归一化特征
优选的,所述公有特征模块设有公有编码器
优选的,所述步骤S3中,将公有特征表示
优选的,公有特征表示的重构损失
其中,
对于语言学特征表示
对应文档级表示
其中,
对应语言学特征表示
其中,
优选的,所述步骤S4中,各个私有特征表示
优选的,所述CP-ARA模型的累计训练损失的表达式如下:
其中,
本发明还提供了基于公有与私有特征分解的混合可读性评估系统,包括ARA模型,所述ARA模型为CP-ARA模型,所述CP-ARA模型包括深度特征模块、语言特征模块、私有特征模块、公有特征模块和联合特征模块;所述混合可读性评估系统能够通过如前所述的混合可读性评估方法实现所述CP-ARA模型的构建和训练,并利用训练好的所述CP-ARA模型对文本进行可读性评估。
本发明具有以下优点:本发明捕获文档级、句子级和单词级三种不同深度的文本信息,由此产生了三个层次的深度特征表示,同时通过学习公有特征和私有特征,以实现深层特征和语言学特征有效的融合。通过提取上述特征表示间的公有特征,并分离它们的私有特征,这样能有效地发现他们地一致性,并消除不同层次地表示之间的信息冗余。
本方案通过提取私有特征表示和公有特征表示将语言学特征与多个深度特征的融合,同时利用自监督损失来分别监督公有特征和私有特征的学习,所得模型用于可读性评估时在若干重要的评价指标上实现了更优的性能。
本方案对于语言学特征表示利用层归一化以消除不同特征之间显著的差异变化而造成的影响,并在自监督学习时通过线性层进一步解码,以与实现与归一化特征间的自监督关系。
附图说明
图1为本发明基于公有与私有特征分解的混合可读性评估方法的模型流程图。
具体实施方式
下面对照附图,通过对实施例的描述,对本发明具体实施方式作进一步详细的说明,以帮助本领域的技术人员对本发明的发明构思、技术方案有更完整、准确和伸入的理解。
如图1所示,本发明提供了基于公有与私有特征分解的混合可读性评估方法,包括下列步骤。
步骤一、构建CP-ARA模型(基于公有特征和私有特征的自动阅读能力评估模型)。
CP-ARA模型包括深度特征模块、语言特征模块、私有特征模块、公有特征模块和联合特征模块。
深度特征模块基于文本中的文档级、句子级和单词级的文本信息来分别提取不同深度的深度特征,从而得到对应的深度特征表示,即文档级表示、句子级表示和单词级表示。
语言特征模块用于在不同级别从文本中提取多个语言特征并通过处理得到的与深度特征表示的维度一致的语言学特征表示。
私有特征模块用于对不同深度的深度特征表示以及语言学特征表示分别用对应的编码器进行编码从而得到相应的私有特征表示。
公有特征模块用于将不同深度的深度特征表示以及语言学特征连接在一起,再通过编码器处理获得公有特征表示。
联合特征模块用于将之前获取的各个私有特征表示和公有特征表示均连接在一起后用于预测可读性水平,生成相应可读性水平的标签。
步骤二、采集一定量文本作为训练集和测试集并对构建的CP-ARA模型进行训练。
采集一定量文本,人工分析并对文本进行可读性水平的标签设置,将设置标签后的文本作为样本集并划分为训练集和测试集。将训练集中的文本样本输入对构建的CP-ARA模型进行训练。具体训练方法如下。
S1、对文本进行不同深度的深度特征提取生成相应深度特征表示。
为了充分发掘深度模型的潜力,特征提取时需要提取高质量且丰富的深度特征。为实现这一目标,该步骤从文本多个层次的信息中提取不同深度的深度特征,包括文档级、句子级和单词级,由此得到不同级别的深度特征表示能捕捉不同类型的文本信息。具体方法如下。
对于给定的文本,通过预训练的长序列变换器BigBird(大鸟模型)直接提取文档级信息中的深度特征(基于长序列变换器BigBird输出的[
f
其中
S2、对文本进行语言特征的提取。
文本中的语言学特征刻画了文本的一些重要属性,并能够为ARA模型提供许多额外的见解和上下文信息。因此,在ARA模型中,应特别关注语言学特征。具体方法如下。
该步骤中为了充分利用语言学特征,使用已有的语言特征提取器从文本中提取多个语言特征,然后对这些语言特征进行层归一化以消除由于不同特征之间的显著差异变化而造成的影响,这样能获得归一化特征
进行层归一化时,要注意层归一化是对一个中间层的所有神经元进行归一化。令第
其中,
其中,γ表示缩放参数向量,β表示平移参数向量,σ
线性层的表达式为:F=fW+b,其中W为可训练参数,b为标量偏差,f为输入数据,F为输出结果,由线性层处理输出的是语言学特征表示
S3、对不同深度的深度特征表示和语言学特征表示进行相应私有特征表示和这些特征的公有特征表示的学习。
注意到语言学特征表示和三个不同层次的深度特征表示在其所在不同层次表示中,它们之间应该存在潜在的一致性。因此,提取它们的公有特征,并分离它们的私有特征是非常有用的。通过这样做,可以有效地发现他们地一致性,并消除不同层次地表示之间的信息冗余。具体方法如下。
为了获取所述的公有特征,所述公有特征模块设有公有编码器
其中,
为了获取所述的私有特征,所述私有特征模块设有私有编码器,特征表示
上述模块中所使用的编码器(包括公有编码器和相应私有编码器)和解码器(包括公有解码器和相应私有解码器)所使用的激活函数分别为Sigmiod和LeakyReLU,以下将Sigmiod函数简写为Act1( ),将LeakyReLU函数简写为Act2( ),激活函数Act1( )和Act2( )的表达式依次如下:
其中
对编码器我们首先将信息向量输入到一个可训练的神经层中,再通过激活函数Act1( )引入非线性性质,再输入到一个新的神经层中,得到一个压缩后信息向量。解码器则是用于帮助编码器进行信息压缩提取以形成内部的自监督。解码器的具体操作是将前述的压缩后信息向量输入到第一层可训练地神经元层和一个激活函数Act2()处理,再通过第二个可训练的神经元层和激活函数Act2( )处理,然后最终输入到第三层可训练的神经元层中处理,得到解码向量。编码器和解码器相应的处理方式依次通过下列表达式表示:
其中,
对应文档级表示
其中,
而对应语言学特征表示
其中,
S4、基于所得的各个私有特征表示和公有特征表示,进行可读性标签的标签预测。
经过上一步骤S3生成的各个私有特征表示
z
基于以上训练过程,所述CP-ARA模型的累计训练损失的表达式如下:
其中,
步骤三、完成训练后利用训练好的CP-ARA模型对文本进行可读性评估,生成相应的可读性水平标签。
本方法通过公有特征表示和私有特征表示进行自监督学习,学习所用的特征表示都是领域内的,并且这些信息的产生依赖于样本中的单个文本,同时自监督学习中引入了文本的语言学特征,实现对文本中多种类型多种尺度的特征表示进行联合学习的效果,从而能将两种特征有效融合获得较高的可读性评估效果。
本发明还提供了基于公有与私有特征分解的混合可读性评估系统,包括ARA模型,所述ARA模型为CP-ARA模型,所述CP-ARA模型包括深度特征模块、语言特征模块、私有特征模块、公有特征模块和联合特征模块;所述混合可读性评估系统能够前述的混合可读性评估方法实现所述CP-ARA模型的构建和训练,并利用训练好的所述CP-ARA模型对文本进行可读性评估。
上面结合附图对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的发明构思和技术方案进行的各种非实质性的改进,或未经改进将本发明构思和技术方案直接应用于其它场合的,均在本发明保护范围之内。
- 一种Src酪氨酸激酶抑制剂晶型、其制备方法及药物组合物
- 一种酪氨酸激酶抑制剂的二马来酸盐的晶型及其制备方法
- 一种酪氨酸激酶抑制剂的二马来酸盐的晶型及其制备方法
- 一种WEE1酪氨酸蛋白激酶抑制剂的制备方法
- 一种酪氨酸蛋白激酶抑制剂及其制备方法