一种基于信息检索和源代码结构的需求跟踪方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及需求工程技术领域,具体涉及一种基于信息检索和源代码结构的需求跟踪方法。
背景技术
软件系统由存储信息的各种工件组成,如需求文档、规范文档、交互图、用户文档、源代码、用例、测试用例、bug报告等。从需求工程阶段,到项目部署阶段,需求的更新和扩展指导着软件系统开发的整个过程。但是到了软件开发过程的后期阶段,由于应用程序的大小增加、参与该过程的人数增加、系统的快速演化、原始需求文档的变化等各种因素,软件工程师们往往难以对需求进行可靠的跟踪,这就很可能会导致最终的软件产品出现错误,因为很难去对所有需求实现的正确性和完整性进行合理的验证。
建立需求的可追溯性是帮助开发人员和利益相关者们在软件开发的过程中了解需求的实现程度的主要方法。需求可追溯性定义为“在正向和反向上对需求的生命周期进行描述和跟踪的能力”。通过建立需求到源码的可追溯性链接,开发人员和利益相关者们可以了解到每段源码的来源,跟踪他们对其做出的每一个变化,了解每条需求的实现情况,从而确保最终能够正确地交付系统。
研究需求的可追溯性既可以是从高等级需求到低等级需求的可追溯性,也可以是从需求文档到设计文档的可追溯性,也可以是从需求文档到源码、测试用例等工件的可追溯性,他们的主要区别体现在对文本中关键信息的提取方式。其中从需求到源码的可追溯性生成技术是目前被研究最多的问题,针对该问题,目前基于信息检索(IR)的方法已经成为需求可追溯生成技术领域最流行的技术。IR是按照一定的方式对源信息进行加工、整理、组织和存储,然后从目标信息集合中准确查找出对应目标的技术。
图1是基于IR的源码到需求的信息检索过程图。
如图1所示,对于从需求到源码的可追溯性生成技术而言,通常需要对需求和源代码进行预处理,提取出其中的关键词,然后以源代码作为查询条件,从需求集合中找到相似度最高的需求作为查询结果。
但是传统的基于IR的方法准确性较低,这是因为传统的IR方法如VSM(向量空间模型)往往只基于词语自身的匹配来计算相似度,而忽略了词语的语义以及词语相互间的上下文关系。比如Kafka在计算机领域指的是一种高性能的分布式消息队列中间件,而在文学领域则指的是奥地利的小说家,这是一词多义的问题;比如requirement和need都有需求的意思,这是同义词的问题;而VSM是Vector Space Model的缩写,这是缩略词的问题。这些问题都会导致传统的IR方法出现匹配错误或者缺失。针对以上诸多问题,本发明提出了对应的改进。
发明内容
本发明是为了解决上述问题而进行的,目的在于提供一种基于信息检索和源代码结构的需求跟踪方法。
本发明提供了一种基于信息检索和源代码结构的需求跟踪方法,具有这样的特征,包括以下步骤:步骤1,引入数据集,数据集包括需求文档和源代码;步骤2,构造一个数据处理引擎,对数据集进行解析,分别对需求文档和源代码进行不同方式的预处理,输出需求文档到源代码之间的追踪链接相似度,得到结果集;步骤3,基于解析完成的数据集,用户对结果集进行标记,展示结果的准确率、召回率以及F
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤1中,需求文档是正向设计的起点,是在项目中以自然语言编写而成的多条英文需求文档,是功能性需求或非功能性需求,源代码是计算机语言指令的集合,用面向对象语言编写而成,源代码的对象主要是源代码中的每个类。
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤2具体包括以下步骤:步骤2-1,对数据集进行预处理,生成对应的术语-文档矩阵,步骤2-2,利用FNN深度学习网络进行共指消解,包括术语对排名模型的训练和簇集对排名模型的训练;步骤2-3,更新术语-文档矩阵,获取源代码类结构图;步骤2-4,对源代码类结构图进行图嵌入,获取源代码类的向量表示;步骤2-5,利用向量改进需求和源代码类之间相似度的计算,获取跟踪链接相似度,其中,步骤2-1中,对需求文档的处理方式包括:分词、删除冗余以及形态学分析,对源代码的代码部分的处理方式包括:提取标识符、分割标识符、删除冗余以及形态学分析,对源代码的注释部分的处理方式与对需求文档的处理方式相同,步骤2-5中,计算需求文档到源代码之间的追踪链接相似度时,采取设定阈值的方式,将超过阈值的链接设定为有效链接。
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤2-2具体包括以下步骤:步骤2-2-1,针对文档i的每个术语t,将t在文档i中的每一次出现称为m,然后将m和文档i中的每一个其他术语a作为一个术语对,输入到术语对排名模型中进行训练,其中a是术语t的候选共指;步骤2-2-2,术语对排名模型基于FNN实现,包括输入层、隐藏层以及输出层,术语对排名模型经过输入层的处理,得到m和a的术语对的向量表示;步骤2-2-3,向量经过三层隐藏层,三层隐藏层为三个线性整流单元神经元,每个神经元都与前一层相连接;步骤2-2-4,经过隐藏层处理后,最后经过输出层,输出层由一个和隐藏层第三层全连接的神经元构成;步骤2-2-5,对于文档d
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤2-2-2中,输入层有一层,输入的特征包括:t的词嵌入、POS标记、位置、与候选词的距离以及与候选词的字符串匹配程度,步骤2-2-3中,术语对排名模型中隐藏层的计算公式如(1)所示:
h
式中h
s
式中,W
R
步骤2-2-7中,如公式(4)所示,池化操作连接了平均池化和最大池化的结果:
式中,d=M
s
要判断c
s
式中,s
π(c
如果π(c
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤2-3具体包括以下步骤:步骤2-3-1,更新术语-文档矩阵;步骤2-3-2,引入源代码的结构信息后,首先将源代码中的类进一步划分为方法,然后对于具有不止一个方法的源代码类,计算出每个需求和每个类之间的文本相似度和每一个方法与每一条需求之间的文本相似度,将超出阈值的结果视为这个类与对应需求的可追溯性链接,最终找到一部分需求和源代码类之间潜在的可追溯性链接,其中,类的结构图为一种无向有权图,其中每个图结点代表着源代码中的每个类,而结点之间用一条带有权值的无向边相连接,每条边上的权值为两个类之间的关系数量,通过建立无向有权图,获取任意两个源代码类之间的紧密程度,紧密程度与两者之间的权值成正比,与两者之间的距离成反比。
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤2-4中,采用图嵌入技术将类结构图转化为对应的向量表示,然后类之间的紧密程度通过计算两个类向量之间的距离来表示,具体过程为:步骤2-4-1,采用LINE算法进行图嵌入,图嵌入包括无向图、有向图、无加权图或加权图中的任意一种或多种;步骤2-4-2,将图嵌入之后,采用欧拉距离公式来确定两个类的紧密程度,对于两个类c
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,骤2-5中,相似度的计算的具体过程为:对于已经超过阈值的链接为设定为有效链接,则将相应的链接和文本相似度记录下来,文本相似度没有达到阈值的链接,则利用已有的可追溯性链接和源代码中类之间的关系来优化相似性的计算,每个类c
式中,sim
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤3中,用户标记的具体过程为:选择对应的源代码类之后,在需求列表中对与之具有跟踪关系的需求进行多项选择,然后进行标记,作为结果集来验证结果的有效性。
在本发明提供的基于信息检索和源代码结构的需求跟踪方法中,还可以具有这样的特征:其中,步骤4中,结果查询功能的具体过程为:用户选择某个源代码类,查看与之具有跟踪关系的需求列表和每个需求的相似度结果,或者选择某条需求,查看与之具有跟踪关系的源代码类列表和每个源代码类的相似度结果。
发明的作用与效果
根据本发明所涉及的基于信息检索和源代码结构的需求跟踪方法,因为具体过程为:步骤1,引入数据集,数据集包括需求文档和源代码;步骤2,构造一个数据处理引擎,对数据集进行解析,分别对需求文档和源代码进行不同方式的预处理,输出需求文档到源代码之间的追踪链接相似度,得到结果集;步骤3,基于解析完成的数据集,用户对结果集进行标记,展示结果的准确率、召回率以及F
因此,本发明提出的一种基于信息检索和源代码结构的需求跟踪方法,可以应用于很多软件工程项目中,对提高系统开发的效率,降低系统开发的风险,提高系统的质量,提高项目进度的可控性等各个方面都有十分显著的作用:
(1)引入深度学习方法来消除在计算需求和源代码类之间的跟踪关系时语义不一致的问题。
(2)利用源代码类的内部信息优化了获取跟踪链接的方式。
(3)引入源代码类之间的结构信息,通过构建类关系图,并利用图嵌入技术将每个节点表示为对应的向量,再利用向量之间的距离来改善需求和源代码类之间相似度的计算,从而找到潜在跟踪链接。
附图说明
图1是基于IR的源码到需求的信息检索过程图;
图2是本发明的实施例中的算法总体流程图;
图3是本发明的实施例中利用类中的方法找到潜在链接的示例图;
图4是本发明的实施例中在两种数据集上的实验结果图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明一种基于信息检索和源代码结构的需求跟踪方法作具体阐述。
在本实施例中,提供了一种基于信息检索和源代码结构的需求跟踪方法。
本实施例所涉及的基于信息检索和源代码结构的需求跟踪方法包括以下步骤:
步骤S1,引入数据集,数据集包括需求文档和源代码。
需求是正向设计的起点,在1999年的IEEE大会上需求被定义为:标识产品或过程的功能、操作、约束或设计特征的说明。本实施例研究的需求即是在项目中以自然语言编写而成的多条英文需求,这些需求既可以是功能性需求也可以是非功能性需求。
对于需求而言,首先需要对需求进行分词,由于本实施例研究对象都是由英文编写而成的,所以本实施例采用Java中常用的英文分词器StanfordCoreNLP对需求进行分词。然后再利用相应的语料库删除冗余,包括停止词和大部分非文本标记。接下来是形态学分析,包括单词大小写的转换,名词单数和复数的转换,缩写的恢复等。最终生成了需求文档和术语的索引列表。
源代码是计算机语言指令的集合,在源代码的开发方式中,使用面向对象的编程语言,例如Java、Python、C++等,已经成为了主流。在项目中,大部分源代码是为了实现需求而编写的,而实现需求的源代码可以由某一种编程语言编写而成,也可以是多种语言编写而成的源代码的组合。本实施例研究的源代码是用面向对象语言编写而成的,具体而言,本实施例研究的源代码对象主要是源代码中的每个类。
对于源代码而言,它跟需求的主要区别在于分词的方式不一样,不能通过NLP的方式进行处理。而在良好的项目代码中的标识符应该具有其本身的意义,此外,应该包含相应的注释。因此,本实施例对源码的分词方式包含两步,第一步是提取出类中包含的标识符,再对标识符进行合理的分离,第二步是提取出类中的注释,再利用与需求相同的预处理方式进行处理。对于标识符的处理,首先利用Java词法分析器解析源代码,生成一个标识符列表,然后利用驼峰法或者下划线分割法对标识符进行分割,将由多个单词形成的标识符分割为单独的单词。例如,TriangleSize和Triangle_Size都将被分成Triangle和Size。对源代码进行分词之后,再对这些单词进行和需求一样的删除冗余和形态学分析处理。最终生成了源代码和术语的索引列表。
对于需求到源码的可追溯性关系而言,一个需求可能对应着多个源代码类,而一个源代码类也可能对应着多个需求,即需求和源码之间应该具有多对多的关系。例如,在某个实际项目中的某条需求为“该系统可以对用户上传的图片进行美化”,这个需求实际上对应着“ImageObtain”和“ImageBeautify”这两个类,而其中“ImageObtain”这个类还对应着“该系统可以对用户上传的图片进行分类”等其他需求。所以本实施例在计算需求到源码的跟踪链接相似度的时候,采取的是设定阈值的方式,将超过阈值的链接都设定为有效链接,其中相似度阈值被设定为0.8。
步骤S2,构造一个数据处理引擎,对数据集进行解析,分别对需求文档和源代码进行不同方式的预处理,输出需求文档到源代码之间的追踪链接相似度,得到结果集。
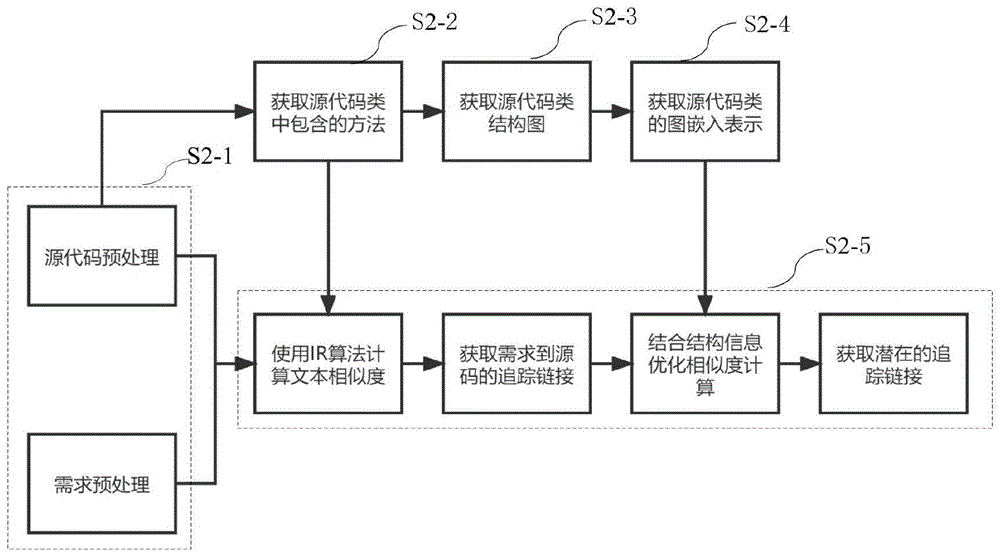
图2是本发明的实施例中的算法总体流程图。
如图2所示,步骤S2具体包括以下步骤:
步骤S2-1,对数据集进行预处理,生成对应的术语-文档矩阵。由于需求文档是自然语言编写而成,而源代码则不同,因此对于需求和源码需要不同的预处理方式。对需求的处理方式有分词,删除冗余,形态学分析。对源代码的代码部分,处理方式包括提取标识符,分割标识符,删除冗余和形态学分析,对源代码的注释部分则与需求的处理方式相同。该步骤完成后就可以生成术语-文档矩阵。
步骤S2-2,利用FNN深度学习网络进行共指消解,包括术语对排名模型的训练和簇集对排名模型的训练。
FNN是人工神经网络的一种基本类型,其全称是feedforward neural network,即前馈神经网络。在FNN中,信息只向一个方向移动,即从输入层移动到输出层,而在输入层和输出层之间可能还有一到多个隐藏层。由于FNN可以用来学习任何非线性关系,因此,它被认为是一种强大的方法,可以被应用于许多深度学习的任务上。既往研究表明,FNN可以在共指和问答等NLP任务上提供令人满意的结果。
步骤2-2具体包括以下步骤:
步骤S2-2-1,针对文档i的每个术语t,由于t可能在文档i中出现不止一次,将t在文档i中的每一次出现称为m,然后将m和文档i中的每一个其他术语a作为一个术语对,输入到术语对排名模型中进行训练,其中a是术语t的候选共指,共指的含义就是在文本中指代同一对象或实体的不同表达方式。
步骤S2-2-2,术语对排名模型基于FNN实现,包括输入层、隐藏层以及输出层,其中输入层有一层,输入的特征有t的词嵌入、POS标记、位置、与候选词的距离、与候选词的字符串匹配程度,术语对排名模型经过输入层的处理,得到m和a的术语对的向量表示。
步骤S2-2-3,向量经过三层隐藏层,这三层隐藏层实际上就是三个ReLU神经元,每个神经元都与前一层相连接。其中ReLU是RectifiedLinearUnit的简称,即线性整流单元,它是一种激活函数,可以对大型和复杂的数据进行高效的训练。术语对排名模型中隐藏层的计算公式如(1)所示:
h
式中h
步骤S2-2-4,经过隐藏层处理后,最后经过输出层,输出层由一个和隐藏层第三层全连接的神经元构成,通过公式(2)计算m和a之间的匹配度:
s
式中,W
通过术语对训练模型,就可以得到每个术语在每个文档中得分最高的候选共指。而为了提高结果的准确度,本实施例还提出了另一个模型,叫做簇集对排序模型,该模型的主要作用是为了验证通过术语对排序模型得到的术语在不同文档中的共指是否相同。
步骤S2-2-5,对于文档d
步骤S2-2-6,为了判断a
输入层将c
R
步骤S2-2-7中,然后,池化层通过保存任务的相关信息,同时去除不相关的细节来实现更紧凑的表示,以及更好的鲁棒性。如公式(4)所示,池化操作连接了平均池化和最大池化的结果:
式中,d=M
步骤S2-2-8,决定层的计算方式与术语对训练模型的输出层类似,如公式(5)所示:
s
要判断c
s
式中,s
然后训练一个策略网络π,π(c
π(c
如果π(c
步骤S2-3,更新术语-文档矩阵,获取源代码类结构图。
其中,步骤S2-3具体包括以下步骤:
步骤2-3-1,更新术语-文档矩阵。
例如在文档d
步骤S2-3-2,本实施例研究的需求和源代码之间存在着多对多的关系,这就表示一个需求很可能对应的是源代码类中的一部分,而在计算需求和源代码类之间的相似度时,类中不相关的另外一部分就会对结果进行干扰。因此,如果将源代码类进行更细粒度的划分,也就是划分为方法的集合,再用这些方法分别与每条需求计算相似度,就有可能找到潜在的可追溯性链接。
图3是本发明的实施例中利用类中的方法找到潜在链接的示例图。
如图3所示,可以利用类中的方法来寻找潜在的可追溯性链接。对于需求Req.1和类A,他们之间的相似度没有达到阈值,但是由于A中的method_1与Req.1具有可追溯性关系,就可以找到Req.1和类A之间的一条跟踪链接,在图中用虚线表示。而类A的method_2与Req.2也具有可追溯性关系,这样,又找到了Req.2和类A之间的潜在链接。同理,对于类B而言,也可以找到一条新的跟踪链接,即从Req.1到类B的链接。而对于类C而言,则不能通过方法来找到潜在的可追溯性链接,这表明类C与Req.3的可追溯性关系可能由类C中多种方法的组合来决定,也表明不仅需要计算每个方法与需求之间的相似度,也需要计算每个源代码类与需求之间的相似度。
但是,一个源代码类中不仅包含了方法,还有参数,注释等其他信息。对于参数而言,在规范的代码中大部分参数都会在方法中得到调用,所以对结果不会有很大的影响,而对于注释而言,本实施例的处理方法是将方法内以及与该方法相邻的注释当做该方法的一部分,对于类中的其他注释则将其忽略。
最终将源代码中的类进一步划分后,首先需要计算出每个需求和每个类之间的文本相似度。对于那些具有不止一个方法的源代码类,还需要将这些类中的每一个方法与每一条需求计算文本相似度,将超出阈值的结果视为这个类与对应需求的可追溯性链接,通过这种方法就可以找到一部分需求和源代码类之间潜在的可追溯性链接。
本实施例研究的源代码是使用面向对象的编程语言编写而成的,所以可以很方便地获取源代码中类与类之间的关系。在使用面向对象思想编写而成的源代码中,类与类之间往往存在着六种可以通过分析得到的关系,这些关系的具体含义如表1所示。
表1
图结构是源代码结构关系的一种自然有效的表示,代码关系结构图可以充分反映源代码之间的关系。在软件项目中,不同源代码类之间的关系密切程度是不同的,源代码类之间的关系类型和关系数越多,则它们之间的相关关系越密切。所以,需要对类之间的关系进行加权处理,其中权值表示源代码类之间关系的紧密程度,对于两个源代码类,它们之间每存在一个关系,它们之间的边的权重会增加1。例如,如果代码结点node
因此,本实施例将类的结构图定义为一种无向有权图,其中每个图结点代表着源代码中的每个类,而结点之间用一条带有权值的无向边相连接,每条边上的权值为两个类之间的关系数量。通过建立这样的一种无向有权图,就可以从理论上获取任意两个源代码类之间的紧密程度,它们的紧密程度与两者之间的权值成正比,与两者之间的距离成反比。
步骤S2-4,在获取类关系图之后,就需要计算类之间的关系。可以看出,两个类之间的紧密程度与类之间的距离成反比,与类之间的权值成正比,其中,类之间的距离表示类之间结点的数量,结点数量越少,则距离越近。通常在计算两个类之间的紧密程度时,可以通过图的遍历来获取两个类之间的距离和每条边上的权值,但是对于几百个结点来说,每次计算都需要对图进行一次遍历,通过这种方式在计算文档间相似度的时候会产生巨大的计算量。为了降低计算的复杂度,本实施例还采用了图嵌入技术来将类结构图转化为对应的向量表示,然后类之间的紧密程度就可以直接通过计算两个类向量之间的距离来表示。具体过程为:
步骤S2-4-1,图嵌入技术主要是为了将图的结构进行压缩,从而简化计算量。通过图嵌入的方式,可以将图中的结点映射到低维向量上,其低阶的结构信息可以保持相邻结点在嵌入空间中的距离依然非常接近,而对于不相邻的结点而言,也可以利用高阶的结构信息即它们上下文结点的信息来获取这些结点之间的紧密程度。一般的图嵌入是采用deepwalk和word2vec相结合的方式,但是该方法只适用于无权图,无法应用于本发明获取到的类结构有权图,因此,本实施例采用LINE算法来进行图嵌入,它可以适用于任何类型的信息网络,包括无向图、有向图、无加权图或加权图等。
步骤S2-4-2,将图嵌入之后,采用欧拉距离公式来确定两个类的紧密程度,对于两个类c
步骤S2-5,利用向量改进需求和源代码类之间相似度的计算,获取跟踪链接相似度。
通过前面的步骤,已经可以通过计算类的向量之间的距离来表示类之间的紧密程度,然后可以利用这些关系来优化相似度的计算。本发明对于已经大于阈值的链接不进行优化,优化的对象是那些没有达到阈值的链接,其目的是为了找出潜在可追溯性链接。对于已经超过阈值的链接,本实施例将直接确定这些链接为有效链接,将相应的链接和文本相似度记录下来。而对于文本相似度没有达到阈值的链接,则利用已有的可追溯性链接和源代码中类之间的关系来优化相似性的计算,对于每个类c
其中sim
可以看出,优化后的相似度随着c
本实施例中,系统实现所用的编程环境是Eclipse和Visual Studio Code,后端使用Java和Python,前端使用Vue,数据库使用MySQL。其中,本实施例使用python的pytorch来对Polysemy算法中的FNN进行实现。此外,由于Polysemy还利用了池化层来验证共指结果,因此文本也基于pytorch实现了池化层。一些训练细节如表2所示。
表2
本实施例使用SpanBERT来获取词嵌入,SpanBERT模型是Facebook在开源社区Github上提供的英文预训练模型,其中主要的微调(fine-tuning)参数如表3所示。
表3
基于源代码结构的算法首先需要对源代码进行解析,从而获取源代码的结构信息。为了获取源代码的结构化表示,常用的办法是在对源代码进行词法分析、语法分析等处理之后构建出对应的抽象语法树(AST)。针对不同的面向对象的编程语言,有不同的工具来对源代码进行解析,由于本实施例研究的数据集都是用Java语言编写而成的,因此本实施例使用了Eclipse提供的JDT工具来对源码进行解析。通过使用JDT可以快速地构建出Java源代码对应的AST,构建出的AST的每一个结点都表示Java源代码中的某一个元素,其中Java源代码中的类一般对应着AST中的顶点。
通过类结构图已经可以获取任意两个类之间的关系,两个类之间的紧密程度应该与两个类之间的距离成反比,而与两个类之间的关系数量成正比,但是为了计算两个类之间的紧密程度,每次都需要对整个类结构图进行遍历,这样毫无疑问将增加计算量,为此,本实施例还采用了图嵌入的方法对将类结构信息转化为相应的向量表示,从而简化计算。
本实施例基于开源的LINE代码进行图嵌入训练,其中一些训练细节如表4所示。
表4
/>
步骤S3,基于解析完成的数据集,用户对结果集进行标记,展示结果的准确率、召回率以及F
选择对应的源代码类之后,在需求列表中对与之具有跟踪关系的需求进行多项选择,然后进行标记,作为结果集来验证结果的有效性。
步骤S4,用户对结果进行查询,具体过程为:
用户选择某个源代码类,查看与之具有跟踪关系的需求列表和每个需求的相似度结果,或者选择某条需求,查看与之具有跟踪关系的源代码类列表和每个源代码类的相似度结果。
为了证明本实施例的效果,实现了相应的原型系统,进行了一系列实验。本实施例所用硬件环境为一台CPU为AMD锐龙7 3700x,显卡为RTX 2070super,内存为32GB的台式电脑,操作系统为windows 10 Pro 64位。系统实现所用的编程环境是Eclipse和VisualStudio Code,后端使用Java和Python,前端使用Vue,数据库使用MySQL。
本实施例使用的数据集来自CoEST这个开放社区,该社区里面了可追溯性研究的进展和相关数据集。本实施例选择的数据集为EBT和eTour,他们的具体内容如表5所示。
表5
本实验使用准确率P、召回率R、和F
而召回率R的意思是正确的链接数量除以真正的正确数量,其计算公式由(11)给出,
TP表示真正例数,FP表示假正例数,FN表示假负例数。
由于在实际情况中,P和R往往是矛盾的,在提高P的同时很可能会降低R,因此为了综合考虑P和R,本发明还选用了F
其中当β=1的时候,P和R在F
图4是本发明的实施例中在两种数据集上的实验结果图。
如图4所示,可以看出,在两种数据集上本发明的准确率都达到了90%以上,而召回率也分别有60%以上和40%以上,这说明本发明在某些对召回率要求不高的场景下已经具有了很高的实用性。
实施例的作用与效果
根据本实施例所涉及的基于信息检索和源代码结构的需求跟踪方法,因为具体过程为:步骤1,引入数据集,数据集包括需求文档和源代码;步骤2,构造一个数据处理引擎,对数据集进行解析,分别对需求文档和源代码进行不同方式的预处理,输出需求文档到源代码之间的追踪链接相似度,得到结果集;步骤3,基于解析完成的数据集,用户对结果集进行标记,展示结果的准确率、召回率以及F
因此,本实施例提出的一种基于信息检索和源代码结构的需求跟踪方法,可以应用于很多软件工程项目中,对提高系统开发的效率,降低系统开发的风险,提高系统的质量,提高项目进度的可控性等各个方面都有十分显著的作用:
(4)引入深度学习方法来消除在计算需求和源代码类之间的跟踪关系时语义不一致的问题。
(5)利用源代码类的内部信息优化了获取跟踪链接的方式。
(6)引入源代码类之间的结构信息,通过构建类关系图,并利用图嵌入技术将每个节点表示为对应的向量,再利用向量之间的距离来改善需求和源代码类之间相似度的计算,从而找到潜在跟踪链接。
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
- 一种基于非牛顿流体的防碰撞型道路路障
- 一种轨道和道路障碍物检测方法
- 一种高速道路隔断用移动式路障
- 一种用于单向车道防逆行的路障装置
- 一种道路工程防挪移路障
- 一种公路工程用道路警示路障