一种基于卷积注意力和特征解耦的单目三维目标检测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及一种单目三维目标检测方法。
背景技术
单目三维目标检测是自动驾驶领域的一项具有挑战性的任务。最初,一些单目方法仅使用一张图像作为输入[1],通过利用二维和三维之间的几何约束,取得了令人印象深刻的进展。尽管单目三维目标检测具有低成本的优势,但从单幅图像估计深度是很困难的,导致单目三维目标检测性能仍远不能令人满意。
在单目三维目标检测领域中,仅使用图像的方法最初依赖于单个图像来预测目标。然而,图像中深度信息的缺失构成了一个挑战。一些方法依靠几何一致性来进行预测以解决这一限制。文献[2]结合了二维和三维投影的几何关系,构建了一个三维目标区域建议网络。文献[3]基于成对空间关系的探索,进一步提高了三维检测性能。文献[4]先将物体的三维边界框的底面作为地平面引入,以减轻物体无关属性的干扰。文献[5]将单目目标深度估计作为一个渐近细化问题,并提出了一个联合的语义和几何代价体积来建模深度误差。为了解决由于缺乏深度线索而导致的单眼三维目标检测的局限性,研究人员提出了在训练过程中利用深度信息的额外方法[6]。文献[7]侧重于融合图像,并通过使用专门设计的卷积网络来估计深度。文献[8]利用图形模型有效地从相邻的点云中提取上下文信息。文献[9]通过投影三维坐标,重建图像的二维坐标,并以自监督学习的方式学习目标几何信息。
受视觉自注意力模型(Visual Transformers,ViTs)具有强大的自注意机制和全局特征提取能力的启发[10],一些工作已经成功地将视觉自注意力模型应用于自动驾驶场景中的单目目标检测任务,从而进一步提高了检测精度。文献[11]提出了第一个基于自注意力模型的单目3D目标检测网络,有效地集成了视觉和深度特征,提高了单目三维目标检测的精度。此外,文献[12]提出通过编码器-解码器范式来检测对象,并使用匈牙利匹配算法进行输出预测。文献[13]在[12]的视觉编码器和解码器的基础上,提出了深度编码器和深度引导解码器,用于自适应场景级深度理解,显著提高了单目三维目标检测的精度。
虽然基于视觉自注意力模型的单目三维目标检测方法取得了一定的效果,但目前有一个关于如何进一步改进基于视觉自注意力模型的趋势,一种可能的解决方案是在视觉自注意力中引入卷积局部特征,使其具有一定程度的偏移不变性、尺度不变性和失真不变性。另外,所有现有基于视觉自注意力的模型都将视觉特征和深度特征输入到同一个解码器中进行解码处理,由于单目任务的本质,不准确的深度信息会干扰模型对其他信息的学习。
参考文献:
[1]Ku J,Pon A D,Waslander S L.Monocular 3d object detectionleveraging accurate proposals and shape reconstruction[C]//Proceedings of theIEEE/CVF conference on computer vision and pattern recognition.2019:11867-11876.
[2]Brazil G,Liu X.M3d-rpn:Monocular 3d region proposal network forobject detection[C]//Proceedings of the IEEE/CVF International Conference onComputer Vision.2019:9287-9296.
[3]Chen Y,Tai L,Sun K,et al.Monopair:Monocular 3d object detectionusing pairwise spatial relationships[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2020:12093-12102.
[4]Qin Z,Li X.Monoground:Detecting monocular 3d objects from theground[C]//Proceedings of the IEEE/CVF Conference on Computer Vision andPattern Recognition.2022:3793-3802.
[5]Lian Q,Li P,Chen X.Monojsg:Joint semantic and geometric costvolume for monocular 3d object detection[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2022:1070-1079.
[6]WangY,Chao W L,Garg D,et al.Pseudo-lidar from visual depthestimation:Bridging the gap in 3d object detection for autonomous driving[C]//Proceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition.2019:8445-8453.
[7]Ding M,Huo Y,Yi H,et al.Learning depth-guided convolutions formonocular 3d object detection[C]//Proceedings of the IEEE/CVF Conference oncomputer vision and pattern recognition workshops.2020:1000-1001.
[8]Wang L,Du L,Ye X,et al.Depth-conditioned dynamic messagepropagation for monocular 3d object detection[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2021:454-463.
[9]Chen H,Huang Y,Tian W,et al.Monorun:Monocular 3d object detectionby reconstruction and uncertainty propagation[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2021:10379-10388.
[10]Han K,Wang Y,Chen H,et al.A survey on vision transformer[J].IEEEtransactions on pattern analysis and machine intelligence,2022,45(1):87-110.
[11]Huang K C,Wu T H,Su H T,et al.Monodtr:Monocular 3d objectdetection with depth-aware transformer[C]//Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2022:4012-4021.
[12]Carion N,Massa F,Synnaeve G,et al.End-to-end object detectionwith transformers[C]//European conference on computer vision.Cham:SpringerInternational Publishing,2020:213-229.
[13]Zhang R,Qiu H,Wang T,et al.MonoDETR:depth-guided transformer formonocular 3D object detection[J].arXiv preprint arXiv:2203.13310,2022.
[14]Huang K C,Wu T H,Su H T,et al.Monodtr:Monocular 3d objectdetection with depth-aware transformer[C]//Proceedings ofthe IEEE/CVFConference on ComputerVision and Pattern Recognition.2022:4012-4021.
发明内容
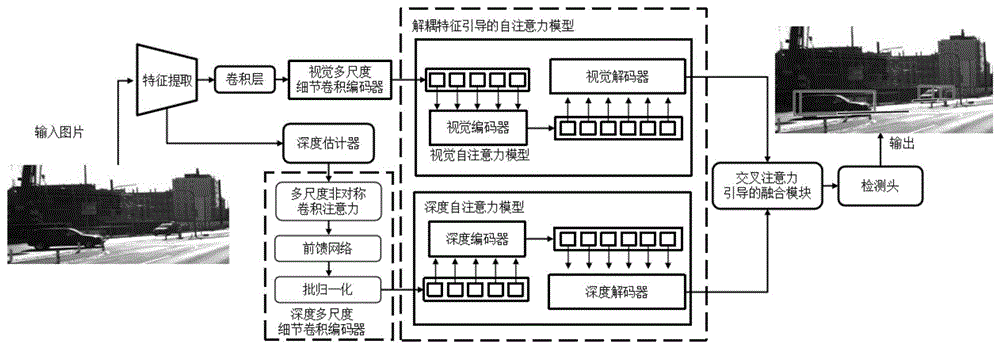
本专利针对现有技术的上述问题,一种基于多尺度非对称卷积注意力和特征解耦的单目三维目标检测方法。该方法对具有解耦的深度特征和视觉特征的自注意力模型引入了非对称卷积。多尺度细节卷积编码器对输入图像的局部特征进行聚合,利用多个不同形状的卷积核进行深度卷积对特征进行编码,以获得图像中更多的细节。解耦的结构允许视觉和深度特征独立学习,而不相互干扰。此外,卷积和自注意力模型的结合使该方法能够同时具备局部特性和全局特性。在KITTI数据集上的实验结果表明,与其他先进的方法相比,该方法具有良好的性能。技术方案如下:
一种基于卷积注意力和特征解耦的单目三维目标检测方法,包括下列步骤:
步骤一:给定一张分辨率为H×W的输入图像,通过主干网络输出特征图F,以F为原始特征,利用一系列卷积层生成视觉特征f
对于原始特征F,采用两个卷积层来预测离散深度区间D的概率,该概率表示每个像素的深度值属于某一深度区间的置信度,采用线性递增离散化将深度真值从连续空间离散到离散空间d
用中间特征图X=Conv(F)表示初始深度感知特征,每个深度区间的特征中心,即深度原型,通过聚合属于指定区间的每个像素的深度感知特征来计算,使用组卷积生成预测的深度区间D,用设定尺度r将区间数从N减少到N’=N/r,深度原型F
步骤二,将视觉特征和深度特征分别输入到视觉多尺度细节卷积编码器和深度多尺度细节卷积编码器处理,多尺度细节卷积编码器集成多尺度非对称卷积注意力模块,以聚合输入图像的局部特征,并对聚合得到的局部特征进行编码,方法如下:
输入的视觉特征和深度特征各经过一个多尺度非对称卷积注意力模块,得到多尺度非对称卷积注意力模块的注意力图Attention和输出和f
在多尺度非对称卷积注意力模块中,输入特征首先非对称卷积来聚合局部信息;然后使用多分支的非对称卷积捕获多尺度上下文信息,再通过1×1卷积进行通道维度的相关建模;
多尺度非对称卷积注意力模块的输出f
步骤三,利用解耦特征引导的自注意力模型的双编码器-双解码器结构对输入图像的空间和外观信息分别进行编码和解码处理,解耦特征引导的自注意力模型具有深度和视觉两个分支,两个分支采用相同的结构,而这两个分支的参数分别进行训练;解耦特征引导的自注意力模型的两个分支分别以深度多尺度细节卷积编码器的输出
步骤四,利用交叉注意力引导的融合模块将深度分支的输出F
步骤五,采用预定义的二维-三维锚点的单阶段检测器来回归边界框,每个预定义的锚点由二维边界框[x
步骤六,预测每个锚点的二维边界框[t
进一步的,步骤一中,采用线性递增离散化将深度真值从连续空间离散到离散空间d
其中,N是深度区间的数量,[d
进一步的,步骤一中,深度区间数N设置为96,深度范围[d
进一步的,步骤二中,所述非对称卷积表示为:
其中,BN表示批归一化操作,γ
进一步的,步骤二所述的一个多尺度非对称卷积注意力模块为:
f
其中,f表示输入特征f
进一步的,步骤三中,对于深度分支,方法如下:
1)将深度多尺度细节卷积编码器的输出
2)在深度分支的编码器中,
其中,Linear表示线性变换,softmax是一种激活函数,C表示输入特征的维度,LN表示层归一化操作;A表示注意力分数,
3)在深度分支的解码器中,
其中,A
对于视觉分支,按照相同的方法进行处理,得到视觉分支的输出F
进一步的,步骤六中,输出边界框恢复如下:
其中(^)表示三维对象的恢复参数;对二维边界中心[x
附图说明
图1所提方法整体结构图
图2在KITTI数据集可视化汽车类别的三维边界框
具体实施方式
本发明方法属于监督学习,首先需要对模型进行有监督训练,训练得到最佳模型后,再使用新的数据进行检测。本发明的整体结构如图1所示。为使本发明的技术方案更加清楚,下面对本发明具体实施方式做进一步地描述。本发明按以下步骤具体实现。
步骤一:给定一张分辨率为H×W的输入图像,通过主干网络DLA-102输出特征图F。以F为原始特征,利用一系列卷积层生成视觉特征f
深度特征f
其中,i是深度区间索引,d
其中X’
进一步地,基于深度原型表示来重建新的深度特征f
步骤二,将视觉特征和深度特征分别输入到视觉多尺度细节卷积编码器和深度多尺度细节卷积编码器处理。多尺度细节卷积编码器集成了多尺度非对称卷积注意力模块,以聚合输入图像的局部特征,并对这些特征进行编码,方法如下:
输入特征经过一个多尺度非对称卷积注意力模块:
f
其中,f表示输入特征f
在多尺度非对称卷积注意力模块中,输入特征首先通过5×5的非对称卷积来聚合局部信息;然后使用多分支的非对称卷积捕获多尺度上下文信息,其中每个分支的卷积内核大小分别设置为7、11和21;进一步地,通过1×1卷积进行通道维度的相关建模。其中,非对称卷积表示为:
其中,BN表示批归一化操作,γ和β是BN操作中的可学习参数;
多尺度非对称卷积注意力模块的输出f
步骤三,利用解耦特征引导的自注意力模型的双编码器-双解码器结构对输入图像的空间和外观信息分别进行编码和解码处理。解耦特征引导的自注意力模型具有深度和视觉两个分支,两个分支采用相同的结构,而这两个分支的参数分别进行训练。解耦特征引导的自注意力模型的两个分支分别以深度多尺度细节卷积编码器的输出
1)将深度多尺度细节卷积编码器的输出
2)在深度分支的编码器中,
其中,Linear表示线性变换,softmax是一种激活函数,C表示输入特征的维度,LN表示层归一化操作。A表示注意力分数,
4)在深度分支的解码器中,
其中,A
步骤四,利用交叉注意力引导的融合模块将深度分支的输出F
步骤五,采用预定义的二维-三维锚点的单阶段检测器来回归边界框。每个预定义的锚点由二维边界框[x
步骤六,预测每个锚点的[t
其中(^)表示三维对象的恢复参数。对二维边界中心[x
本发明在自动驾驶数据集KITTI上进行了实验,KITTI数据集是由德国卡尔斯鲁厄理工学院和丰田工业大学芝加哥分校联合赞助的用于自动驾驶领域研究的数据集。作者收集了长达6个小时的真实交通环境,数据集由经过校正和同步的图像、雷达扫描、高精度的GPS信息和IMU加速信息等多种模态的信息组成。KITTI数据集包含7481张用于训练的图像和7518张用于测试的图像。由于测试集的地真值尚未被正式公开,因此通过向KITTI的官方网站提交本发明提出的方法,得到了测试集上的实验结果。本发明遵循其他文献将训练样本划分为训练集(3712张)和验证集(3769张)。
在上述数据集上进行模型训练、验证和测试,根据输入的单张图像对场景中的汽车、行人以及骑自行车的人进行检测,并输出三维边界框。结果表明,在验证集中,检测汽车类别且IoU=0.7时,简单、中等和困难三种设置下的三维平均精度分别为29.70%、20.64%和17.05%。在测试集中,检测汽车类别且IoU=0.7时,简单、中等和困难三种设置下的三维平均精度分别为24.27%、17.06%和14.76%;检测行人类别且IoU=0.5时,简单、中等和困难三种设置下的三维平均精度分别为13.30%、8.25%和7.38%;检测骑自行车的人类别且IoU=0.5时,简单、中等和困难三种设置下的三维平均精度分别为10.67%、6.47%和5.62%。该结果与其他检测模型相比精度更高,表明该模型能够学习并准确检测不同类别的目标。将所提方法在KITTI数据集上对汽车类别的目标的检测结果进行可视化,结果如图2所示。结果表明,本发明的模型能够准确地检测到目标物体,且检测结果接近实际值,具有优异的性能。
- 基于图片识别的库存管理方法及相关产品
- 基于屏下摄像头显示屏的伽马校正方法及相关产品
- 应用于屏下摄像头的显示屏的制作方法、AMOLED显示屏