图像编码/解码方法和装置
文献发布时间:2024-04-18 20:01:30
本申请是申请日为2017年7月10日、申请号为201780043698.7、标题为“图像编码/解码方法和装置”的专利申请的分案申请。
技术领域
本发明涉及一种用于对图像进行编码和解码的方法和设备。更具体地,本发明涉及一种使用扫描来对图像进行编码和解码的方法和设备。
背景技术
最近,对于高分辨率和高质量图像(诸如,高清晰度(HD)图像和超高清晰度(UHD)图像)的需求已在各种应用领域中增加。然而,更高分辨率和质量的图像数据与传统图像数据相比增加了数据量。因此,当通过使用诸如传统有线和无线宽带网络的介质传输图像数据时,或者当通过使用传统存储介质存储图像数据时,传输和存储的成本增加。为了解决随着图像数据的分辨率和质量提高而发生的这些问题,需要一种高效图像编码/解码技术用于更高分辨率和更高质量的图像。
图像压缩技术包括各种技术,包括:从当前画面的先前画面或随后画面对包括在当前画面中的像素值进行预测的帧间预测技术;通过使用当前画面中的像素信息对包括在当前画面中的像素值进行预测的帧内预测技术;用于对残差信号的能量进行压缩的变换和量化技术;将短码分配给具有高出现频率的值并将长码分配给具有低出现频率的值的熵编码技术;等等。图像数据可通过使用这样的图像压缩技术而被有效地压缩,并可被传输或存储。
发明内容
技术问题
本发明的目的在于提供一种用于有效地对图像进行编码和解码的方法和设备。
技术方案
根据本发明的一种图像编码方法可包括:通过执行变换和量化中的至少一个来产生变换块;将包括在变换块中的至少一个系数分组到至少一个系数组(CG)中;对包括在系数组中的至少一个系数进行扫描;以及对包括在系数组中的所述至少一个系数进行编码。
在本发明的图像编码方法中,所述扫描可以是基于变换块的对角方向扫描、基于变换块的Z字形方向扫描和边界扫描中的至少一个扫描。
在本发明的图像编码方法中,当所述扫描是基于变换块的对角方向扫描时,所述扫描可以以从变换块的右下AC系数的位置到DC系数的位置的顺序或者以从变换块的DC系数的位置到右下AC系数的位置的顺序被执行,对角方向可以是左下对角方向或右上对角方向,所述至少一个CG中的每个CG可包括按照扫描顺序连续的预定数量的系数。
在本发明的图像编码方法中,当所述扫描是基于变换块的Z字形方向扫描时,所述扫描可以以从变换块的右下AC系数的位置到DC系数的位置的顺序或者以从变换块的DC系数的位置到右下AC系数的位置的顺序,按照Z字形方向被执行,所述至少一个CG中的每个CG可包括按照扫描顺序连续的预定数量的系数。
在本发明的图像编码方法中,当所述扫描是边界扫描时,第一扫描可被应用于所述至少一个CG中的包括DC系数的第一CG,第二扫描可被应用于其余CG,所述至少一个CG中的每个CG可具有不同于其它CG的尺寸或形状。
在本发明的图像编码方法中,第一扫描可以是Z字形扫描,第二扫描可以是水平扫描和垂直扫描中的至少一个扫描。
在本发明的图像编码方法中,所述方法还可包括:指定变换块的预定区域,其中,可不对包括在所述预定区域中的系数执行所述扫描、所述分组和所述编码中的至少一个。
在本发明的图像编码方法中,所述预定区域可基于变换块内的系数的坐标被指定。
在本发明的图像编码方法中,当变换块是矩形时,所述扫描可以是Z字形扫描,并且所述Z字形扫描可以是向变换块的宽度和长度中的较长边倾斜的Z字形扫描。
根据本发明的一种图像解码方法可包括:识别关于对包括在变换块中的至少一个系数进行扫描的扫描信息或关于基于所述扫描将所述至少一个系数分组到至少一个系数组(CG)中的分组信息;从比特流对包括在变换块中的至少一个系数进行解码;以及基于解码的所述至少一个系数来重建变换块,其中,对所述至少一个系数进行解码的步骤可基于扫描信息和分组信息中的至少一个信息而被执行。
在本发明的图像解码方法中,所述扫描可以是基于变换块的对角方向扫描、基于变换块的Z字形方向扫描和边界扫描中的至少一个扫描。
在本发明的图像解码方法中,当所述扫描是基于变换块的对角方向扫描时,所述扫描可以以从变换块的右下AC系数的位置到DC系数的位置的顺序或者以从变换块的DC系数的位置到右下AC系数的位置的顺序被执行,对角方向可以是左下对角方向或右上对角方向,所述至少一个CG中的每个CG可包括按照扫描顺序连续的预定数量的系数。
在本发明的图像解码方法中,当所述扫描是基于变换块的Z字形方向扫描时,所述扫描可以以从变换块的右下AC系数的位置到DC系数的位置的顺序或者以从变换块的DC系数的位置到右下AC系数的位置的顺序,按照Z字形方向被执行,所述至少一个CG中的每个CG可包括按照扫描顺序连续的预定数量的系数。
在本发明的图像解码方法中,当所述扫描是边界扫描时,第一扫描可被应用于所述至少一个CG中的包括DC系数的第一CG,第二扫描可被应用于其余CG,所述至少一个CG中的每个CG可具有不同于其它CG的尺寸或形状。
在本发明的图像解码方法中,第一扫描可以是Z字形扫描,第二扫描可以是水平扫描和垂直扫描中的至少一个扫描。
在本发明的图像解码方法中,所述方法还可包括:指定变换块的预定区域,其中,包括在所述预定区域中的系数可被设置为0。
在本发明的图像解码方法中,所述预定区域可基于变换块内的系数的坐标被指定。
在本发明的图像解码方法中,当变换块是矩形时,所述扫描可以是Z字形扫描,并且所述Z字形扫描可以是向变换块的宽度和长度中的较长边倾斜的Z字形扫描。
根据本发明的一种图像编码设备可包括编码部,其中,所述编码部可通过执行变换和量化中的至少一个来产生变换块,将包括在变换块中的至少一个系数分组到至少一个系数组(CG)中,对包括在系数组中的至少一个系数进行扫描,并对包括在系数组中的所述至少一个系数进行编码。
根据本发明的一种记录介质可存储通过图像编码方法产生的比特流,其中,所述图像编码方法可包括:通过执行变换和量化中的至少一个来产生变换块;将包括在变换块中的至少一个系数分组到至少一个系数组(CG)中;对包括在系数组中的至少一个系数进行扫描;以及对包括在系数组中的所述至少一个系数进行编码。
技术效果
根据本发明,可提高图像的编码/解码效率。
根据本发明,可减少对TU中的系数进行编码所需比特的数量。
附图说明
图1是示出根据本发明的实施例的编码设备的配置的框图。
图2是示出根据本发明的实施例的解码设备的配置的框图。
图3是示意性地示出当对图像进行编码和解码时图像的分区结构的示图。
图4是示出可包括在编码单元(CU)中的预测单元(PU)的形式的示图。
图5是示出可包括在编码单元(CU)中的变换单元(TU)的形式的示图。
图6是用于解释帧内预测的处理的实施例的示图。
图7是用于解释帧间预测的处理的实施例的示图。
图8是用于解释根据帧内预测模式的变换集的示图。
图9是用于解释变换的处理的示图。
图10是用于解释对经过量化的变换系数的扫描的示图。
图11是用于解释块分区的示图。
图12是示出根据本发明的DCT-2频域中的基本矢量的示图。
图13是示出根据本发明的DST-7频域中的基本矢量的示图。
图14是示出根据本发明的在8×8编码单元(CU)的2N×2N预测单元(PU)中的根据位置的平均残差值的分布的示图,其中,8×8编码单元(CU)按照Cactus序列的帧间模式被预测。
图15是示出根据本发明的在8×8编码单元(CU)的2N×2N预测单元(PU)中的残差值的分布特性的三维图表,其中,8×8编码单元(CU)按照帧间预测模式(帧间模式)被预测。
图16是示出根据本发明的按照编码单元(CU)的2N×2N预测单元(PU)模式的残差信号的分布特性的示图。
图17是示出根据本发明的在2N×2N预测单元(PU)的洗牌(shuffling)之前和之后的残差信号的分布特性的示图。
图18是示出根据本发明的子块的4×4残差数据的重布置的示例的示图。
图19是示出根据本发明的根据编码单元(CU)的预测单元(PU)模式和变换单元(TU)的洗牌方法的变换单元(TU)的分区结构的示图。
图20是示出根据本发明的基于2N×2N预测单元(PU)的残差信号分布执行DCT-2和SDST的结果的示图。
图21是示出根据本发明的SDST处理的示图。
图22是示出根据本发明的基于帧间预测的编码单元(CU)的预测单元(PU)分区模式的变换单元(TU)分区的分布特性和残差绝对值的示图。
图23是示出根据本发明的预测单元(PU)中的具有深度0的变换单元(TU)的残差信号的扫描顺序和重布置顺序的示图。
图24是示出根据本发明的通过率失真优化(RDO)选择DCT-2或SDST的编码处理的流程图。
图25是示出根据本发明的选择DCT-2或SDST的解码处理的流程图。
图26是示出根据本发明的使用SDST的解码处理的流程图。
图27和图28是示出根据本发明的在编码器和解码器中执行残差信号重布置(残差重布置)的位置的示图。
图29是示出根据本发明的使用SDST方法的解码方法的流程图。
图30是示出根据本发明的使用SDST方法的编码方法的流程图。
图31是示出按照CG单元对具有16×16尺寸的TU内的经过变换和/或量化的系数进行分组的示例的示图。
图32是示出具有16×16尺寸的TU内的所有系数的扫描顺序的示例的示图。
图33是示出TU内的系数的分布特性、有效扫描、以及对CG配置的需求的示图。
图34是示出根据本发明的实施例的左下对角扫描和/或分组的示图。
图35是示出32×32TU的编码/解码区域的示例的示图。
图36是示出根据本发明的实施例的Z字形扫描和/或分组的示图。
图37是示出根据本发明的实施例的边界扫描和/或分组的示图。
图38是示出32×32TU的编码/解码区域的示例的示图。
图39是示出针对水平长矩形TU的扫描和/或分组的示例的示图。
图40是示出针对垂直长矩形TU的扫描和/或分组的示例的示图。
图41是示出当对应用了根据本发明的扫描和/或分组方法的8×8TU中的当前CG的CSBF进行编码/解码时的参考CG的示例。
图42是示出当应用了根据本发明的扫描和/或分组方法时根据TU内的系数的位置参考用于对sig_coeff_flag进行编码/解码的上下文模型的方法的示图。
具体实施方式
发明模式
可对本发明做出多种修改,并且存在本发明的多种实施例,其中,现在将参照附图提供所述实施例的示例并且将详细描述所述实施例的示例。然而,本发明不限于此,尽管示例性实施例可被解释为包括本发明的技术构思和技术范围内的所有修改、等同形式或替换形式。相似的参考标号指在各方面相同或相似的功能。在附图中,为了清楚起见,元件的形状和尺寸可被夸大。在本发明的以下详细描述中,对通过图示的方式示出可对本发明进行实施的具体实施例的附图进行参照。这些实施例被足够详细地描述以使本领域技术人员能够实施本公开。应该理解,本公开的各种实施例尽管不同,但不必是相互排他的。例如,在不脱离本公开的精神和范围的情况下,这里描述的与一个实施例关联的特定特征、结构和特性可在其它实施例中被实施。此外,应该理解,在不脱离本公开的精神和范围的情况下,每个公开的实施例内的各个元件的位置或布置可被修改。因此,以下详细描述将不以限制的含义进行,本公开的范围仅由所附权利要求(在合适的解释的情况下,还连同权利要求所要求保护的等同物的全部范围)来限定。
在说明书中使用的术语“第一”、“第二”等可被用于描述各种组件,但这些组件并不被解释为限制所述术语。所述术语仅被用于将一个组件与另一组件区分开。例如,在不脱离本发明的范围的情况下,“第一”组件可被称为“第二”组件,并且“第二”组件也可被类似地称为“第一”组件。术语“和/或”包括多个项的组合或者多个项中的任意一项。
将理解的是,在本说明书中,当元件被简单称为“连接到”或“结合到”另一元件而不是“直接连接到”或“直接结合到”另一元件时,它可以“直接连接到”或“直接结合到”另一元件,或者是在其间插入其它元件的情况下连接到或结合到另一元件。相反,应该理解,当元件被称为“直接结合”或“直接连接”到另一元件时,不存在中间元件。
此外,在本发明的实施例中示出的组成部件被独立示出,以便呈现彼此不同的特性功能。因此,这并不意味着每个组成部件以单独的硬件或软件的组成单元被构成。换句话说,为了方便,每个组成部件包括枚举的组成部件中的每一个。因此,每个组成部件中的至少两个组成部件可被组合形成一个组成部件,或者一个组成部件可被划分为多个组成部件以执行每个功能。在没有脱离本发明的本质的情况下,每个组成部件被组合的实施例以及一个组成部件被划分的实施例也被包括在本发明的范围中。
在本说明书中使用的术语仅用于描述具体实施例,而不旨在限制本发明。以单数使用的表达包括复数表达,除非它在上下文中具有明显不同的含义。在本说明书中,将理解,诸如“包括...的”、“具有...的”等的术语旨在指明说明书中所公开的特征、数量、步骤、行为、元件、部件、或其组合的存在,而并不旨在排除一个或更多个其它特征、数量、步骤、行为、元件、部件、或其组合可能存在或者可能被添加的可能性。换句话说,当特定元件被称为“被包括”时,除相应元件以外的元件并不被排除,而是,另外的元件可被包括在本发明的实施例或者本发明的范围中。
此外,一些组成元件可能不是执行本发明的必要功能的不可缺的组成元件,而是仅提升其性能的可选组成元件。可通过仅包括用于实施本发明的实质的不可缺的组成部件而排除在提升性能时使用的组成部件来实施本发明。仅包括所述不可缺的组成部件而排除在仅提升性能时使用的可选组成部件的结构也被包括在本发明的范围中。
在下文中,将参照附图详细描述本发明的实施例。在描述本发明的示例性实施例时,将不详细描述公知功能或结构,这是因为它们会不必要地模糊对本发明的理解。附图中的相同的组成元件通过相同的参考标号来表示,并且对相同元件的重复描述将被省略。
此外,在下文中,图像可意为构成视频的画面,或者可意为视频本身。例如,“对图像进行编码或解码或者进行两者”可意为“对视频进行编码或解码或者进行两者”,并且可意为“对视频的多个图像之中的一个图像进行编码或解码或者进行两者”。这里,画面和图像可具有相同的含义。
术语描述
编码器:可意为执行编码的设备。
解码器:可意为执行解码的设备。
解析:可意为通过执行熵解码来确定语法元素的值,或者可意为熵解码本身。
块:可意为M×N矩阵的样点。这里,M和N是正整数,并且块可意为二维形式的样点矩阵。
样点:是块的基本单元,并且可指示依据比特深度(Bd)而范围为0至2Bd–1的值。样点在本发明中可意为像素。
单元:可意为对图像进行编码和解码的单元。在对图像进行编码和解码时,单元可以是通过对一个图像进行分区而产生的区域。此外,单元可意为在编码或解码期间当一个图像被分区为多个子划分单元时的子划分单元。在对图像进行编码和解码时,可执行针对每个单元的预定处理。一个单元可被分区为尺寸比该单元的尺寸更小的子单元。依据功能,单元可意为块、宏块、编码树单元、编码树块、编码单元、编码块、预测单元、预测块、变换单元、变换块等。此外,为了将单元与块区分开,单元可包括亮度分量块、亮度分量块的色度分量块、以及每个颜色分量块的语法元素。单元可具有各种尺寸和形状,具体而言,单元的形状可以是二维几何图形,诸如矩形、正方形、梯形、三角形、五边形等。此外,单元信息可包括单元类型(指示编码单元、预测单元、变换单元等)、单元尺寸、单元深度、对单元进行编码和解码的顺序等中的至少一个。
重建邻近单元:可意为在空间上/时间上被在先编码或解码的重建单元,并且重建单元与编码/解码目标单元相邻。这里,重建邻近单元可意为重建邻近块。
邻近块:可意为与编码/解码目标块相邻的块。与编码/解码目标块相邻的块可意为具有与编码/解码目标块接触的边界的块。邻近块可意为位于编码/解码目标块的相邻顶点的块。邻近块可意为重建邻近块。
单元深度:可意为单元的被分区程度。在树结构中,根节点可以是最高节点,叶节点可以是最低节点。
符号:可意为编码/解码目标单元的语法元素、编码参数、变换系数的值等。
参数集:可意为比特流的结构中的头信息。参数集可包括视频参数集、序列参数集、画面参数集或自适应参数集中的至少一个参数集。此外,参数集可意为条带头信息和并行块(tile)头信息等。
比特流:可意为包括编码图像信息的比特串。
预测单元:可意为当执行帧间预测或帧内预测以及针对预测的补偿时的基本单元。一个预测单元可被分区为多个分区。在这种情况下,多个分区中的每个分区可以是在执行预测和补偿时的基本单元,并且从预测单元分区出的每个分区可以是预测单元。此外,一个预测单元可以被分区为多个小预测单元。预测单元可具有各种尺寸和形状,并且具体来说,预测单元的形状可以是二维几何图形,诸如矩形、正方形、梯形、三角形、五边形等。
预测单元分区:可意为分区出的预测单元的形状。
参考画面列表:可意为包括至少一个参考画面的列表,其中,所述至少一个参考画面被用于帧间预测或运动补偿。参考画面列表的类型可以是List Combined(LC)、List 0(L0)、List 1(L1)、List 2(L2)、List 3(L3)等。至少一个参考画面列表可被用于帧间预测。
帧间预测指示符:可意为以下之一:帧间预测情况下的编码/解码目标块的帧间预测方向(单向预测、双向预测等)、用于通过所述编码/解码目标块产生预测块的参考画面的数量、以及用于通过所述编码/解码目标块执行帧间预测或运动补偿的参考块的数量。
参考画面索引:可意为参考画面列表中的特定参考画面的索引。
参考画面:可意为特定单元为了帧间预测或运动补偿所参考的画面。参考图像可被称为参考画面。
运动矢量:是用于帧间预测或运动补偿的二维矢量,并且可意为编码/解码目标画面与参考画面之间的偏移。例如,(mvX,mvY)可指示运动矢量,mvX可指示水平分量,mvY可指示垂直分量。
运动矢量候选:可意为当预测运动矢量时成为预测候选的单元,或者可意为该单元的运动矢量。
运动矢量候选列表:可意为通过使用运动矢量候选配置的列表。
运动矢量候选索引:可意为指示运动矢量候选列表中的运动矢量候选的指示符。运动矢量候选索引可被称为运动矢量预测因子的索引。
运动信息:可意为运动矢量、参考画面索引和帧间预测指示符、以及包括参考画面列表信息、参考画面、运动矢量候选、运动矢量候选索引等中的至少一个的信息。
合并候选列表:可意为通过使用合并候选配置的列表。
合并候选:可包括空间合并候选、时间合并候选、组合合并候选、组合双向预测合并候选、零合并候选等。合并候选可包括诸如预测类型信息的运动信息、用于每个列表的参考画面索引、运动矢量等。
合并索引:可意为指示合并候选列表中的合并候选的信息。此外,合并索引可指示与当前块在空间/时间上相邻的重建块之中的推导合并候选的块。此外,合并索引可指示合并候选的多条运动信息中的至少一条运动信息。
变换单元:可意为当对残差信号执行与变换、逆变换、量化、反量化以及变换系数编码/解码类似的编码/解码时的基本单元。一个变换单元可被分区为多个小变换单元。变换单元可具有各种尺寸和形状。具体而言,变换单元的形状可以是二维几何图形,诸如矩形、正方形、梯形、三角形、五边形等。
缩放:可意为将一因子与变换系数等级相乘的处理,其结果是,变换系数可被产生。缩放还可被称为反量化。
量化参数:可意为在量化和反量化期间在对变换系数等级进行缩放时使用的值。这里,量化参数可以是被映射到量化的步长大小的值。
增量(Delta)量化参数:可意为编码/解码目标单元的量化参数与预测出的量化参数之间的差值。
扫描:可意为对块或矩阵内的系数顺序进行排序的方法。例如,将二维矩阵排序为一维矩阵的操作可被称为扫描,并且将一维矩阵排序为二维矩阵的操作可被称为扫描或逆扫描。
变换系数:可意为在执行变换之后产生的系数值。在本发明中,经过量化的变换系数等级(即被应用了量化的变换系数)可被称为变换系数。
非零变换系数:可意为值不为0的变换系数,或者可意为值不为0的变换系数等级。
量化矩阵:可意为在量化和反量化中使用以便提高图像的主体质量(subjectquality)或对象质量(object quality)的矩阵。量化矩阵可被称为缩放列表。
量化矩阵系数:可意为量化矩阵的每个元素。量化矩阵系数可被称为矩阵系数。
默认矩阵:可意为在编码器和解码器中被预先定义的预定量化矩阵。
非默认矩阵:可意为在编码器和解码器中未被预先定义的情况下由用户发送/接收的量化矩阵。
编码树单元:可由一个亮度分量(Y)编码树单元以及相关的两个色度分量(Cb,Cr)编码树单元构成。每个编码树单元可通过使用至少一种分区方法(诸如四叉树、二叉树等)被分区,以构成诸如编码单元、预测单元、变换单元等的子单元。编码树单元可被用作用于指示像素块(其中,像素块是在图像的解码/编码处理中的处理单元,如输入图像的分区)的术语。
编码树块:可用作用于指示Y编码树单元、Cb编码树单元和Cr编码树单元之一的术语。
图1是示出根据本发明的实施例的编码设备的配置的框图。
编码设备100可以是视频编码设备或图像编码设备。视频可包括一个或更多个图像。编码设备100可按照时间顺序对视频的一个或更多个图像进行编码。
参照图1,编码设备100可包括运动预测单元111、运动补偿单元112、帧内预测单元120、切换器115、减法器125、变换单元130、量化单元140、熵编码单元150、反量化单元160、逆变换单元170、加法器175、滤波器单元180以及参考画面缓冲器190。
编码设备100可按照帧内模式或帧间模式或者帧内模式和帧间模式两者来对输入画面进行编码。此外,编码设备100可通过对输入画面进行编码来产生比特流,并可输出产生的比特流。当帧内模式被用作预测模式时,切换器115可切换到帧内。当帧间模式被用作预测模式时,切换器115可切换到帧间。这里,帧内模式可被称为帧内预测模式,帧间模式可被称为帧间预测模式。编码设备100可产生输入画面的输入块的预测块。此外,在产生预测块之后,编码设备100可对输入块和预测块之间的残差进行编码。输入画面可被称为作为当前编码的目标的当前图像。输入块可被称为当前块或者可被称为作为当前编码的目标的编码目标块。
当预测模式是帧内模式时,帧内预测单元120可使用与当前块相邻的先前编码块的像素值作为参考像素。帧内预测单元120可通过使用参考像素来执行空间预测,并可通过使用空间预测来产生输入块的预测样点。这里,帧内预测可意为帧内帧预测。
当预测模式是帧间模式时,运动预测单元111可在运动预测处理中从参考画面搜索与输入块最优匹配的区域,并可通过使用搜索到的区域推导运动矢量。参考画面可被存储在参考画面缓冲器190中。
运动补偿单元112可通过使用运动矢量执行运动补偿来产生预测块。这里,运动矢量可以是用于帧间预测的二维矢量。此外,运动矢量可指示当前画面和参考画面之间的偏移。这里,帧间预测可意为帧间帧预测。
当运动矢量的值不为整数时,运动预测单元111和运动补偿单元112可通过对参考画面中的部分区域应用插值滤波器来产生预测块。为了基于编码单元执行帧间预测或运动补偿,可在跳过模式、合并模式、AMVP模式和当前画面参考模式之中确定编码单元中的预测单元的运动预测和补偿方法使用哪种方法。可根据每种模式执行帧间预测或运动补偿。这里,当前画面参考模式可意为使用具有编码目标块的当前画面的预先重建的区域的预测模式。为了指明所述预先重建的区域,可定义针对当前画面参考模式的运动矢量。是否按照当前画面参考模式对编码目标块进行编码可通过使用编码目标块的参考画面索引而被编码。
减法器125可通过使用输入块和预测块之间的残差来产生残差块。残差块可被称为残差信号。
变换单元130可通过对残差块进行变换来产生变换系数,并可输出变换系数。这里,变换系数可以是通过对残差块进行变换而产生的系数值。在变换跳过模式下,变换单元130可跳过对残差块的变换。
可通过对变换系数应用量化来产生经过量化的变换系数等级。在下文中,在本发明的实施例中,经过量化的变换系数等级可被称为变换系数。
量化单元140可通过依据量化参数对变换系数进行量化来产生经过量化的变换系数等级,并可输出经过量化的变换系数等级。这里,量化单元140可通过使用量化矩阵来对变换系数进行量化。
熵编码单元150可通过根据概率分布对由量化单元140计算出的值或对在编码处理中计算出的编码参数值等执行熵编码来产生比特流,并可输出产生的比特流。熵编码单元150可对用于对图像进行解码的信息执行熵编码,并对图像的像素的信息执行熵编码。例如,用于对图像进行解码的信息可包括语法元素等。
当熵编码被应用时,通过向具有高出现概率的符号分配少量比特并向具有低出现概率的符号分配大量比特来表示符号,从而减小对目标符号进行编码的比特流的大小。因此,通过熵编码,图像编码的压缩性能可提高。对于熵编码,熵编码单元150可使用诸如指数golomb、上下文自适应变长编码(CAVLC)以及上下文自适应二进制算术编码(CABAC)的编码方法。例如,熵编码单元150可通过使用变长编码/码(VLC)表来执行熵编码。此外,熵编码单元150可推导目标符号的二值化方法以及目标符号/二进制位的概率模型,并且随后可通过使用推导出的二值化方法或推导出的概率模型来执行算术编码。
为了对变换系数等级进行编码,熵编码单元150可通过使用变换系数扫描方法将二维块形式的系数改变为一维矢量形式。例如,通过用右上扫描来扫描块的系数,二维形式的系数可被改变为一维矢量。根据变换单元的尺寸以及帧内预测模式,可使用用于沿列方向扫描二维块形式的系数的垂直方向扫描以及用于沿行方向扫描二维块形式的系数的水平方向扫描,而不是使用右上扫描。也就是说,依据变换单元的尺寸以及帧内预测模式,可确定右上扫描、垂直方向扫描和水平方向扫描之中的哪种扫描方法将被使用。
编码参数可包括由编码器编码并被发送到解码器的诸如语法元素的信息,并可包括可在编码或解码处理中推导出的信息。编码参数可意为对图像进行编码或解码所必要的信息。例如,编码参数可包括以下项中的至少一个值或组合形式:块尺寸、块深度、块分区信息、单元尺寸、单元深度、单元分区信息、四叉树形式的分区标志、二叉树形式的分区标志、二叉树形式的分区方向、帧内预测模式、帧内预测方向、参考样点滤波方法、预测块边界滤波方法、滤波器抽头、滤波器系数、帧间预测模式、运动信息、运动矢量、参考画面索引、帧间预测方向、帧间预测指示符、参考画面列表、运动矢量预测因子、运动矢量候选列表、关于运动合并模式是否被使用的信息、运动合并候选、运动合并候选列表、关于跳过模式是否被使用的信息、插值滤波器类型、运动矢量大小、运动矢量表示的精确度、变换类型、变换大小、关于附加(二次)变换是否被使用的信息、关于残差信号是否存在的信息、编码块样式、编码块标志、量化参数、量化矩阵、环路内的滤波器信息、关于滤波器是否在环路内被应用的信息、环路内的滤波器系数、二值化/反二值化方法、上下文模型、上下文二进制位、旁通二进制位、变换系数、变换系数等级、变换系数等级扫描方法、图像显示/输出顺序、条带识别信息、条带类型、条带分区信息、并行块识别信息、并行块类型、并行块分区信息、画面类型、比特深度、以及亮度信号或色度信号的信息。
残差信号可意为原始信号与预测信号之间的差。可选择地,残差信号可以是通过对原始信号和预测信号之间的差进行变换而产生的信号。可选择地,残差信号可以是通过对原始信号和预测信号之间的差进行变换和量化而产生的信号。残差块可以是块单元的残差信号。
当编码设备100通过使用帧间预测执行编码时。编码的当前画面可被用作针对将被随后处理的另一图像的参考画面。因此,编码设备100可对编码的当前画面进行解码,并可将解码的图像存储为参考画面。为了执行解码,可对编码的当前画面执行反量化和逆变换。
量化的系数可通过反量化单元160被反量化,并可通过逆变换单元170被逆变换。可由加法器175将经过反量化和逆变换的系数与预测块相加,由此可产生重建块。
重建块可通过滤波器单元180。滤波器单元180可向重建块或重建画面应用去块滤波器、样点自适应偏移(SAO)以及自适应环路滤波器(ALF)中的至少一个。滤波器单元180可被称为环路滤波器。
去块滤波器可去除在块之间的边界处出现的块失真。为了确定去块滤波器是否被运行,可基于包括在块中的若干行或列中的像素来确定去块滤波器是否被应用于当前块。当去块滤波器被应用于块时,可依据所需的去块滤波强度来应用强滤波器或弱滤波器。此外,在应用去块滤波器时,可并行处理水平方向滤波和垂直方向滤波。
样点自适应偏移可将最优偏移值添加到像素值以便对编码误差进行补偿。样点自适应偏移可针对每个像素对经过去块滤波的图像和原始画面之间的偏移进行校正。为了对特定画面执行偏移校正,可使用考虑每个像素的边缘信息来应用偏移的方法,或使用以下方法:将图像的像素分区为预定数量的区域,确定将被执行偏移校正的区域,并对所确定的区域应用偏移校正。
自适应环路滤波器可基于通过将重建画面与原始画面进行比较而获得的值来执行滤波。图像的像素可被分区为预定组,被应用于每个组的一个滤波器被确定,并且不同的滤波可在每个组被执行。关于自适应环路滤波器是否被应用于亮度信号的信息可针对每个编码单元(CU)被发送。被应用于每个块的自适应环路滤波器的形状和滤波器系数可变化。此外,具有相同形式(固定形式)的自适应环路滤波器可在不考虑目标块的特性的情况下被应用。
经过滤波器单元180的重建块可被存储在参考画面缓冲器190中。
图2是示出根据本发明的实施例的解码设备的配置的框图。
解码设备200可以是视频解码设备或图像解码设备。
参照图2,解码设备200可包括熵解码单元210、反量化单元220、逆变换单元230、帧内预测单元240、运动补偿单元250、加法器255、滤波器单元260以及参考画面缓冲器270。
解码设备200可接收从编码设备100输出的比特流。解码设备200可按照帧内模式或帧间模式对比特流进行解码。此外,解码设备100可通过执行解码来产生重建画面,并可输出重建画面。
当在解码中使用的预测模式是帧内模式时,切换器可被切换到帧内。当在解码中使用的预测模式是帧间模式时,切换器可被切换到帧间。
解码设备200可从输入的比特流获得重建残差块,并可产生预测块。当重建残差块和预测块被获得时,解码设备200可通过将重建残差块与预测块相加来产生作为解码目标块的重建块。解码目标块可被称为当前块。
熵解码单元210可通过根据概率分布对比特流执行熵解码来产生符号。产生的符号可包括具有量化的变换系数等级的符号。这里,熵解码的方法可与上述熵编码的方法类似。例如,熵解码的方法可以是上述熵编码的方法的逆处理。
为了对变换系数等级进行解码,熵解码单元210可执行变换系数扫描,由此,一维矢量形式的系数可被改变为二维块形式。例如,通过用右上扫描来扫描块的系数,一维矢量形式的系数可被改变为二维块形式。根据变换单元的尺寸以及帧内预测模式,可使用垂直方向扫描以及水平方向扫描,而不是使用右上扫描。也就是说,依据变换单元的尺寸以及帧内预测模式,可确定在右上扫描、垂直方向扫描和水平方向扫描之中的哪种扫描方法被使用。
经过量化的变换系数等级可通过反量化单元220被反量化,并可通过逆变换单元230被逆变换。经过量化的变换系数等级被反量化并被逆变换以便产生重建残差块。这里,反量化单元220可对经过量化的变换系数等级应用量化矩阵。
当帧内模式被使用时,帧内预测单元240可通过执行空间预测来产生预测块,其中,空间预测使用与解码目标块相邻的先前解码块的像素值。
当帧间模式被使用时,运动补偿单元250可通过执行运动补偿来产生预测块,其中,运动补偿使用存储在参考画面缓冲器270中的参考画面以及运动矢量两者。当运动矢量的值不是整数时,运动补偿单元250可通过对参考画面中的部分区域应用插值滤波器来产生预测块。为了执行运动补偿,基于编码单元,可在跳过模式、合并模式、AMVP模式和当前画面参考模式之中确定编码单元中的预测单元的运动补偿方法使用哪种方法。此外,可依据所述模式执行运动补偿。这里,当前画面参考模式可意为使用具有解码目标块的当前画面内的先前重建区域的预测模式。先前重建区域可不与解码目标块相邻。为了指明先前重建区域,可针对当前画面参考模式使用固定矢量。此外,指示解码目标块是否是按照当前画面参考模式被解码的块的标志或索引可被用信号发送,并可通过使用解码目标块的参考画面索引而被推导出。针对当前画面参考模式的当前画面可存在于针对解码目标块的参考画面列表内的固定位置(例如,参考画面索引为0的位置或最后的位置)。此外,当前画面可以可变地位于参考画面列表内,为此,可用信号发送指示当前画面的位置的参考画面索引。这里,用信号发送标志或索引可表示编码器对相应标志或索引进行熵编码并将其包括到比特流中,并且解码器从比特流对相应标志或索引进行熵解码。
可通过加法器255将重建残差块与预测块相加。通过将重建残差块和预测块相加而产生的块可经过滤波器单元260。滤波器单元260可对重建块或重建画面应用去块滤波器、样点自适应偏移和自适应环路滤波器中的至少一个。滤波器单元260可输出重建画面。重建画面可被存储在参考画面缓冲器270中,并可被用于帧间预测。
图3是示意性地示出当对图像进行编码和解码时的图像的分区结构的示图。图3示意性地示出将一个单元分区为多个子单元的实施例。
为了对图像进行有效分区,编码单元(CU)可在编码和解码中被使用。这里,编码单元可意为进行编码的单元。单元可以是1)语法元素和2)包括图像样点的块的组合。例如,“单元的分区”可意为“与单元相关的块的分区”。块分区信息可包括关于单元深度的信息。深度信息可指示单元被分区的次数或单元被分区的程度或两者。
参照图3,图像300针对每个最大编码单元(LCU)被顺序分区,并且分区结构针对每个LCU被确定。这里,LCU和编码树单元(CTU)具有相同的含义。一个单元可具有基于树结构的深度信息,并可被分层分区。每个分区出的子单元可具有深度信息。深度信息指示单元被分区的次数或单元被分区的程度或两者,因此,深度信息可包括关于子单元的尺寸的信息。
分区结构可意为LCU 310中的编码单元(CU)的分布。CU可以是用于对图像进行有效编码/解码的单元。所述分布可基于一个CU是否将被多次(等于或大于2的正整数,包括2、4、8、16等)分区而被确定。分区出的CU的宽度尺寸和高度尺寸可分别为原始CU的一半宽度尺寸和一半高度尺寸。可选择地,根据分区的次数,分区出的CU的宽度尺寸和高度尺寸可分别小于原始CU的宽度尺寸和高度尺寸。分区出的CU可被递归地分区为多个进一步分区出的CU,其中,按照相同的分区方法,所述进一步分区出的CU具有比所述分区出的CU的宽度尺寸和高度尺寸更小的宽度尺寸和高度尺寸。
这里,CU的分区可被递归地执行直到预定深度。深度信息可以是指示CU的尺寸的信息,并且可被存储在每个CU中。例如,LCU的深度可以是0,并且最小编码单元(SCU)的深度可以是预定最大深度。这里,LCU可以是具有上述最大尺寸的编码单元,并且SCU可以是具有最小尺寸的编码单元。
每当LCU 310开始被分区,并且CU的宽度尺寸和高度尺寸通过分区操作而减小时,CU的深度增加1。在不能被分区的CU的情况下,CU针对每个深度可具有2N×2N尺寸。在能够被分区的CU的情况下,具有2N×2N尺寸的CU可被分区为多个N×N尺寸的CU。每当深度增加1时,N的大小减半。
例如,当一个编码单元被分区为四个子编码单元时,所述四个子编码单元之一的宽度尺寸和高度尺寸可分别为原始编码单元的一半宽度尺寸和一半高度尺寸。例如,当32×32尺寸的编码单元被分区为四个子编码单元时,所述四个子编码单元中的每一个可具有16×16尺寸。当一个编码单元被分区为四个子编码单元时,编码单元可按照四叉树形式被分区。
例如,当一个编码单元被分区为两个子编码单元时,所述两个子编码单元之一的宽度尺寸或高度尺寸可分别为原始编码单元的一半宽度尺寸或一半高度尺寸。例如,当32×32尺寸的编码单元被垂直分区为两个子编码单元时,所述两个子编码单元中的每一个可具有16×32尺寸。例如,当32×32尺寸的编码单元被水平分区为两个子编码单元时,所述两个子编码单元中的每一个可具有32×16尺寸。当一个编码单元被分区为两个子编码单元时,编码单元可按照二叉树形式被分区。
参照图3,具有最小深度0的LCU的尺寸可以是64×64像素,并且具有最大深度3的SCU的尺寸可以是8×8像素。这里,可由深度0来表示具有64×64像素的CU(即,LCU),可由深度1来表示具有32×32像素的CU,可由深度2来表示具有16×16像素的CU,并且可由深度3来表示具有8×8像素的CU(即,SCU)。
此外,可通过CU的分区信息来表示关于CU是否将被分区的信息。分区信息可以是1比特信息。分区信息可被包括在除SCU之外的所有CU中。例如,当分区信息的值为0时,CU可不被分区,当分区信息的值为1时,CU可被分区。
图4是示出可被包括在编码单元(CU)中的预测单元(PU)的形式的示图。
从LCU分区出的多个CU之中的不再被分区的CU可被分区为至少一个预测单元(PU)。该处理也可被称为分区。
PU可以是用于预测的基本单元。PU可按照跳过模式、帧间模式和帧内模式中的任一模式而被编码和解码。PU可依据所述模式按照各种形式被分区。
此外,编码单元可不被分区为多个预测单元,并且编码单元和预测单元具有相同的尺寸。
如图4所示,在跳过模式中,CU可不被分区。在跳过模式中,可支持与不经分区的CU具有相同尺寸的2N×2N模式410。
在帧间模式中,在CU中可支持8个分区模式。例如,在帧间模式中,可支持2N×2N模式410、2N×N模式415、N×2N模式420、N×N模式425、2N×nU模式430、2N×nD模式435、nL×2N模式440以及nR×2N模式445。在帧内模式中,可支持2N×2N模式410和N×N模式425。
一个编码单元可被分区为一个或更多个预测单元。一个预测单元可被分区为一个或更多个子预测单元。
例如,当一个预测单元被分区为四个子预测单元时,所述四个子预测单元之一的宽度尺寸和高度尺寸可为原始预测单元的一半宽度尺寸和一半高度尺寸。例如,当32×32尺寸的预测单元被分区为四个子预测单元时,所述四个子预测单元中的每一个可具有16×16尺寸。当一个预测单元被分区为四个子预测单元时,预测单元可按照四叉树形式被分区。
例如,当一个预测单元被分区为两个子预测单元时,所述两个子预测单元之一的宽度尺寸或高度尺寸可为原始预测单元的一半宽度尺寸或一半高度尺寸。例如,当32×32尺寸的预测单元被垂直分区为两个子预测单元时,所述两个子预测单元中的每一个可具有16×32尺寸。例如,当32×32尺寸的预测单元被水平分区为两个子预测单元时,所述两个子预测单元中的每一个可具有32×16尺寸。当一个预测单元被分区为两个子预测单元时,预测单元可按照二叉树形式被分区。
图5是示出可被包括在编码单元(CU)中的变换单元(TU)的形式的示图。
变换单元(TU)可以是CU内的用于变换、量化、逆变换和反量化的基本单元。TU可具有正方形状或矩形形状等。TU可按照CU的尺寸或CU的形式或者以上两者而被独立确定。
从LCU分区出的CU之中的不再被分区的CU可被分区为至少一个TU。这里,TU的分区结构可以是四叉树结构。例如,如图5所示,一个CU 510可依据四叉树结构而被分区一次或更多次。一个CU被分区至少一次的情况可被称为递归分区。通过进行分区,一个CU 510可由具有各种尺寸的TU形成。可选择地,CU可依据对CU进行分区的垂直线的数量或对CU进行分区的水平线的数量或两者而被分区为至少一个TU。CU可被分区为彼此对称的TU,或者可被分区为彼此不对称的TU。为了将CU分区为彼此对称的TU,TU的尺寸/形状的信息可被用信号发送,并可从CU的尺寸/形状的信息被推导出。
此外,编码单元可不被分区为变换单元,并且编码单元和变换单元可具有相同的尺寸。
一个编码单元可被分区为至少一个变换单元,并且一个变换单元可被分区为至少一个子变换单元。
例如,当一个变换单元被分区为四个子变换单元时,所述四个子变换单元之一的宽度尺寸和高度尺寸可分别为原始变换单元的一半宽度尺寸和一半高度尺寸。例如,当32×32尺寸的变换单元被分区为四个子变换单元时,所述四个子变换单元中的每一个可具有16×16尺寸。当一个变换单元被分区为四个子变换单元时,变换单元可按照四叉树形式被分区。
例如,当一个变换单元被分区为两个子变换单元时,所述两个子变换单元之一的宽度尺寸或高度尺寸可分别为原始变换单元的一半宽度尺寸或一半高度尺寸。例如,当32×32尺寸的变换单元被垂直分区为两个子变换单元时,所述两个子变换单元中的每一个可具有16×32尺寸。例如,当32×32尺寸的变换单元被水平分区为两个子变换单元时,所述两个子变换单元中的每一个可具有32×16尺寸。当一个变换单元被分区为两个子变换单元时,变换单元可按照二叉树形式被分区。
当执行变换时,可通过使用预定变换方法中的至少一种变换方法对残差块进行变换。例如,所述预定变换方法可包括离散余弦变换(DCT)、离散正弦变换(DST)、KLT等。可通过使用以下项中的至少一个来确定哪种变换方法被应用于对残差块进行变换:预测单元的帧间预测模式信息、预测单元的帧内预测模式信息以及变换块的尺寸/形状。指示变换方法的信息可被用信号发送。
图6是用于解释帧内预测的处理的实施例的示图。
帧内预测模式可以是非方向模式或方向模式。非方向模式可以是DC模式或平面模式。方向模式可以是具有特定方向或角度的预测模式,并且方向模式的数量可以是等于或大于1的M。方向模式可被指示为模式编号、模式值和模式角度中的至少一个。
帧内预测模式的数量可以是等于或大于1的N,包括非方向模式和方向模式。
帧内预测模式的数量可依据块的尺寸而变化。例如,当块的尺寸为4×4或8×8时,帧内预测模式的数量可以是67,当块的尺寸是16×16时,帧内预测模式的数量可以是35,当块的尺寸是32×32时,帧内预测模式的数量可以是19,当块的尺寸是64×64时,帧内预测模式的数量可以是7。
帧内预测模式的数量可被固定为N,而不管块的尺寸如何。例如,帧内预测模式的数量可被固定为35或67中的至少一个,而不管块的尺寸如何。
帧内预测模式的数量可依据颜色分量的类型而变化。例如,预测模式的数量可依据颜色分量是亮度信号还是色度信号而变化。
可通过使用重建邻近块中所包括的样点值或编码参数来执行帧内编码和/或解码。
为了按照帧内预测对当前块进行编码/解码,可识别包括在重建邻近块中的样点是否可用作编码/解码目标块的参考样点。当存在不能用作编码/解码目标块的参考样点的样点时,通过使用包括在重建邻近块中的样点中的至少一个样点,样点值被复制和/或插值到不能用作参考样点的样点,由此,不能用作参考样点的样点可被用作编码/解码目标块的参考样点。
在帧内预测中,基于帧内预测模式以及编码/解码目标块的尺寸中的至少一个,滤波器可被应用于参考样点或预测样点中的至少一个。这里,编码/解码目标块可意为当前块,并且可意为编码块、预测块和变换块中的至少一个。被应用于参考样点或预测样点的滤波器的类型可依据帧内预测模式或当前块的尺寸/形状中的至少一个而变化。滤波器的类型可依据滤波器抽头的数量、滤波器系数值或滤波器强度中的至少一个而变化。
在帧内预测模式之中的非方向平面模式中,当产生编码/解码目标块的预测块时,可根据样点位置通过使用当前样点的上参考样点、当前样点的左参考样点、当前块的右上参考样点、以及当前块的左下参考样点的加权和来产生预测块中的样点值。
在帧内预测模式之中的非方向DC模式中,当产生编码/解码目标块的预测块时,可通过当前块的上参考样点和当前块的左参考样点的均值来产生预测块。此外,可通过使用参考样点值对编码/解码块中与参考样点相邻的一个或更多个上方行以及一个或更多个左侧列执行滤波。
在帧内预测模式之中的多个方向模式(角度模式)的情况下,可通过使用右上参考样点和/或左下参考样点来产生预测块,并且所述多个方向模式可具有不同的方向。为了产生预测样点值,可执行实数单位的插值。
为了执行帧内预测方法,可从与当前预测块相邻的邻近预测块的帧内预测模式预测当前预测块的帧内预测模式。在通过使用从邻近帧内预测模式预测出的模式信息来预测当前预测块的帧内预测模式的情况下,在当前预测块和邻近预测块具有相同的帧内预测模式时,当前预测块和邻近预测块具有相同的帧内预测模式的信息可通过使用预定标志信息被发送。在当前预测块的帧内预测模式不同于邻近预测块的帧内预测模式时,可通过执行熵编码来对编码/解码目标块的帧内预测模式信息进行编码。
图7是用于解释帧间预测的处理的实施例的示图。
图7中示出的四边形可指示图像(或画面)。此外,图7的箭头可指示预测方向。也就是说,图像可根据预测方向被编码或解码、或者被编码和解码。根据编码类型,每个图像可被分类为I画面(帧内画面)、P画面(单向预测画面)、B画面(双向预测画面)等。每个画面可依据每个画面的编码类型而被编码和解码。
当作为编码目标的图像是I画面时,画面本身可在无需帧间预测的情况下被帧内编码。当作为编码目标的图像是P画面时,可通过使用仅在前向上的参考画面进行帧间预测或运动补偿来对图像进行编码。当作为编码目标的图像是B画面时,可通过使用在前向和逆向两者上的参考画面进行帧间预测或运动补偿来对图像进行编码。可选择地,可通过使用在前向和逆向之一上的参考画面进行帧间预测或运动补偿来对图像进行编码。这里,当帧间预测模式被使用时,编码器可执行帧间预测或运动补偿,并且解码器可响应于编码器执行运动补偿。通过使用参考画面被编码或解码或者被编码和解码的P画面和B画面的图像可被视为用于帧间预测的图像。
在下文中,将详细描述根据实施例的帧间预测。
可通过使用参考画面和运动信息两者来执行帧间预测或运动补偿。此外,帧间预测可使用上述跳过模式。
参考画面可以是当前画面的先前画面和后续画面中的至少一个。这里,帧间预测可依据参考画面来预测当前画面的块。这里,参考画面可意为在对块进行预测时使用的图像。这里,参考画面内的区域可通过使用指示参考画面的参考画面索引(refIdx)、运动矢量等来指明。
帧间预测可选择参考画面和参考画面内与当前块相关的参考块。可通过使用选择的参考块来产生当前块的预测块。当前块可以是当前画面的块之中的作为当前编码目标或当前解码目标的块。
可由编码设备100和解码设备200从帧间预测的处理推导运动信息。此外,推导出的运动信息可在执行帧间预测时被使用。这里,编码设备100和解码设备200可通过使用重建邻近块的运动信息或同位块(col块)的运动信息或以上两者来提高编码效率或解码效率或两者。col块可以是先前被重建的同位画面(col画面)内的与编码/解码目标块的空间位置相关的块。重建邻近块可以是当前画面内的块、以及通过编码或解码或者编码和解码两者先前被重建的块。此外,重建块可以是与编码/解码目标块相邻的块,或者是位于编码/解码目标块的外部拐角处的块,或者是以上两者。这里,位于编码/解码目标块的外部拐角处的块可以是与水平相邻于编码/解码目标块的邻近块垂直相邻的块。可选择地,位于编码/解码目标块的外部拐角处的块可以是与垂直相邻于编码/解码目标块的邻近块水平相邻的块。
编码设备100和解码设备200可分别确定存在于col画面内的与编码/解码目标块空间相关的位置处的块,并可基于确定的块来确定预定义的相对位置。所述预定义的相对位置可以是存在于与编码/解码目标块空间相关的位置处的块的内部位置或外部位置或者内部位置和外部位置两者。此外,编码设备100和解码设备200可基于所确定的所述预定义的相对位置来分别推导出col块。这里,col画面可以是在参考画面列表中包括的至少一个参考画面中的一个画面。
推导运动信息的方法可根据编码/解码目标块的预测模式而变化。例如,应用于帧间预测的预测模式可包括高级运动矢量预测(AMVP)、合并模式等。这里,合并模式可被称为运动合并模式。
例如,当AMVP作为预测模式被应用时,编码设备100和解码设备200可通过使用重建邻近块的运动矢量或col块的运动矢量或者以上两者来分别产生运动矢量候选列表。重建邻近块的运动矢量或col块的运动矢量或者以上两者可被用作运动矢量候选。这里,col块的运动矢量可被称为时间运动矢量候选,重建邻近块的运动矢量可被称为空间运动矢量候选。
编码设备100可产生比特流,比特流可包括运动矢量候选索引。也就是说,编码设备100可通过对运动矢量候选索引进行熵编码来产生比特流。运动矢量候选索引可指示从包括在运动矢量候选列表中的运动矢量候选中选择出的最优运动矢量候选。运动矢量候选索引可通过比特流从编码设备100被发送到解码设备200。
解码设备200可从比特流对运动矢量候选索引进行熵解码,并可通过使用经过熵解码的运动矢量候选索引在运动矢量候选列表中所包括的运动矢量候选之中选择解码目标块的运动矢量候选。
编码设备100可计算解码目标块的运动矢量和运动矢量候选之间的运动矢量差(MVD),并可对MVD进行熵编码。比特流可包括经过熵编码的MVD。MVD可通过比特流从编码设备100被发送到解码设备200。这里,解码设备200可对从比特流接收到的MVD进行熵解码。解码设备200可通过解码的MVD与运动矢量候选之和来推导出解码目标块的运动矢量。
比特流可包括指示参考画面的参考画面索引等,并且参考画面索引可被熵编码并通过比特流从编码设备100被发送到解码设备200。解码设备200可通过使用邻近块的运动信息来预测解码目标块的运动矢量,并可通过使用预测出的运动矢量以及运动矢量差来推导解码目标块的运动矢量。解码设备200可基于推导出的运动矢量和参考画面索引信息来产生解码目标块的预测块。
作为推导运动信息的另一方法,合并模式被使用。合并模式可意为多个块的运动的合并。合并模式可意为一个块的运动信息被应用于另一个块。当合并模式被应用时,编码设备100和解码设备200可通过使用重建邻近块的运动信息或col块的运动信息或者以上两者来分别产生合并候选列表。运动信息可包括以下项中的至少一个:1)运动矢量、2)参考画面索引、以及3)帧间预测指示符。预测指示符可指示单向(L0预测、L1预测)或双向。
这里,合并模式可被应用于每个CU或每个PU。当合并模式在每个CU或每个PU被执行时,编码设备100可通过对预定义的信息进行熵解码来产生比特流,并可将比特流发送到解码设备200。比特流可包括所述预定义的信息。所述预定义的信息可包括:1)作为指示合并模式是否针对每个块分区被执行的信息的合并标志、2)作为指示与编码目标块相邻的邻近块之中的哪个块被合并的信息的合并索引。例如,与编码目标块相邻的邻近块可包括编码目标块的左邻近块、编码目标块的上邻近块、编码目标块的时间邻近块等。
合并候选列表可指示存储运动信息的列表。此外,合并候选列表可在执行合并模式之前被产生。存储在合并候选列表中的运动信息可以是以下运动信息中的至少一个:与编码/解码目标块相邻的邻近块的运动信息、参考画面中与编码/解码目标块相关的同位块的运动信息、通过对合并运动候选列表中存在的运动信息的预先组合而新产生的运动信息、以及零合并候选。这里,与编码/解码目标块相邻的邻近块的运动信息可被称为空间合并候选。参考画面中与编码/解码目标块相关的同位块的运动信息可被称为时间合并候选。
跳过模式可以是将邻近块本身的模式信息应用于编码/解码目标块的模式。跳过模式可以是用于帧间预测的模式之一。当跳过模式被使用时,编码设备100可对关于哪个块的运动信息被用作编码目标块的运动信息的信息进行熵编码,并可通过比特流将该信息发送到解码设备200。编码设备100可不将其它信息(例如,语法元素信息)发送到解码设备200。语法元素信息可包括运动矢量差信息、编码块标志以及变换系数等级中的至少一个。
在帧内预测或帧间预测之后产生的残差信号可通过作为量化处理的一部分的变换处理被变换到频域。这里,首次变换可使用DCT类型2(DCT-II)以及各种DCT、DST核。这些变换核可对残差信号执行沿水平和/或垂直方向执行1D变换的可分离变换,或者可对残差信号执行2D不可分离变换。
例如,在1D变换的情况下,在变换中使用的DCT和DST类型可使用如下表中所示的DCT-II、DCT-V、DCT-VIII、DST-I以及DST-VII。例如,如表1和表2中所示,可推导出通过组成变换集而在变换中使用的DCT或DST类型。
[表1]
[表2]
例如,如图8所示,根据帧内预测模式,不同的变换集针对水平方向和垂直方向被定义。接下来,编码器/解码器可通过使用当前编码/解码目标块的帧内预测模式和相关变换集的变换来执行变换和/或逆变换。在这种情况下,不对变换集执行熵编码/解码,并且编码器/解码器可根据相同的规则来定义变换集。在这种情况下,指示变换集的变换之中的哪种变换被使用的熵编码/解码可被执行。例如,当块的尺寸等于或小于64×64时,根据帧内预测模式,如表2中所示三个变换集被组成,并且三个变换被用于每个水平方向变换和垂直方向变换以组合并执行总共九个多变换方法。接下来,通过使用最优变换方法来对残差信号进行编码/解码,由此,编码效率可被提高。这里,为了对关于一个变换集的三个变换之中哪个变换方法被使用的信息进行熵编码/解码,可使用截断一元二值化。这里,为了进行垂直变换和水平变换中的至少一个,可对指示变换集的变换中的哪个变换被使用的信息执行熵编码/解码。
在完成上述首次变换之后,如图9中所示,编码器可针对经过变换的系数执行二次变换以提高能量集中度。二次变换可执行沿水平和/或垂直方向执行1D变换的可分离变换,或者可执行2D不可分离变换。所使用的变换信息可被发送,或者可由编码器/解码器根据当前编码信息和邻近编码信息推导出。例如,如1D变换,用于二次变换的变换集可被定义。不对该变换集执行熵编码/解码,并且编码器/解码器可根据相同的规则定义变换集。在这种情况下,指示变换集的变换之中的哪个变换被使用的信息可被发送,并且该信息可通过帧内预测或帧间预测被应用于至少一个残差信号。
变换候选的数量或类型中的至少一个针对每个变换集而不同。变换候选的数量或类型中的至少一个可基于以下至少一个而被不同地确定:块(CU、PU、TU等)的位置、尺寸、分区形式、以及预测模式(帧内/帧间模式)或帧内预测模式的方向/非方向。
解码器可依据二次逆变换是否被执行来执行二次逆变换,并可从二次逆变换的结果依据首次逆变换是否被执行来执行首次逆变换。
上述首次变换和二次变换可被应用于亮度/色度分量中的至少一个信号分量,或者可根据任意编码块的尺寸/形状被应用。可对指示首次变换/二次变换是否被使用以及任意编码块中的所使用的首次变换/二次变换两者的索引执行熵编码/解码。可选择地,所述索引可由编码器/解码器根据至少一条当前/邻近编码信息而默认推导出。
在帧内预测或帧间预测之后获得的残差信号在经过首次变换和/或二次变换之后经过量化处理,并且经过量化的变换系数经过熵编码处理。这里,如图10中所示,经过量化的变换系数可基于帧内预测模式或最小块的尺寸/形状中的至少一个,按照对角方向、垂直方向和水平方向被扫描。
此外,执行了熵解码的经过量化的变换系数可通过被逆扫描而按照块形式被布置,并且可对相关块执行反量化或逆变换中的至少一个。这里,作为逆扫描的方法,对角方向扫描、水平方向扫描和垂直方向扫描中的至少一个可被执行。
例如,在当前编码块的尺寸为8×8时,可对针对8×8的块的残差信号执行首次变换、二次变换以及量化,接下来,可根据图10中示出的三种扫描顺序方法中的至少一种针对四个4×4的子块中的每一个对经过量化的变换系数执行扫描和熵编码。此外,可通过执行熵解码来对经过量化的变换系数执行逆扫描。执行了逆扫描的经过量化的变换系数在经过反量化之后成为变换系数,并且二次逆变换或首次逆变换中的至少一个被执行,由此,重建残差信号可被产生。
在视频编码处理中,一个块可如图11所示被分区,并且与分区信息相应的指示符可被用信号发送。这里,分区信息可以是以下项中的至少一个:分区标志(split_flag)、四叉/二叉树标志(QB_flag)、四叉树分区标志(quadtree_flag)、二叉树分区标志(binarytree_flag)以及二叉树分区类型标志(Btype_flag)。这里,split_flag是指示块是否被分区的标志,QB_flag是指示块是按照四叉树形式还是按照二叉树形式被分区的标志,quadtree_flag是指示块是否按照四叉树形式被分区的标志,binarytree_flag是指示块是否按照二叉树形式被分区的标志,Btype_flag是指示在二叉树形式的分区的情况下块是被垂直分区还是被水平分区的标志。
当分区标志为1时,它可指示分区被执行,当分区标志为0时,它可指示分区不被执行。在四叉/二叉树标志的情况下,0可指示四叉树分区,并且1可指示二叉树分区。可选择地,0可指示二叉树分区,1可指示四叉树分区。在二叉树分区类型标志的情况下,0可指示水平方向分区,1可指示垂直方向分区。可选择地,0可指示垂直方向分区,1可指示水平方向分区。
例如,可通过将如表3中示出的quadtree_flag、binarytree_flag和Btype_flag中的至少一个用信号发送来推导出图11的分区信息。
[表3]
例如,可通过将如表4中示出的split_flag、QB_flag和Btype_flag中的至少一个用信号发送来推导出图11的分区信息。
[表4]
可根据块的尺寸/形状仅按照四叉树形式或仅按照二叉树形式来执行分区方法。在这种情况下,split_flag可意为指示是按照四叉树形式还是按照二叉树形式执行分区的标志。块的尺寸/形状可根据块的深度信息被推导,并且深度信息可被用信号发送。
当块的尺寸在预定范围中时,可仅按照四叉树形式执行分区。这里,所述预定范围可被定义为仅能够按照四叉树形式被分区的最大块的尺寸或最小块的尺寸中的至少一个。可通过比特流用信号发送指示允许四叉树形式的分区的最大块/最小块的尺寸的信息,并且可以以序列、画面参数或条带(分段)中的至少一个为单位用信号发送该信息。可选择地,最大块/最小块的尺寸可以是在编码器/解码器中预设的固定尺寸。例如,当块的尺寸的范围是256×256至64×64时,可仅按照四叉树形式执行分区。在这种情况下,split_flag可以是指示是否按照四叉树形式执行分区的标志。
当块的尺寸在预定范围中时,可仅按照二叉树形式执行分区。这里,所述预定范围可被定义为仅能够按照二叉树形式被分区的最大块的尺寸或最小块的尺寸中的至少一个。可通过比特流用信号发送指示允许二叉树形式的分区的最大块/最小块的尺寸的信息,并且可以以序列、画面参数或条带(段)中的至少一个为单位用信号发送该信息。可选择地,最大块/最小块的尺寸可以是在编码器/解码器中预设的固定尺寸。例如,当块的尺寸的范围是16×16至8×8时,可仅按照二叉树形式执行分区。在这种情况下,split_flag可以是指示是否按照二叉树形式执行分区的标志。
在按照二叉树形式对一个块进行分区之后,当分区出的块被进一步分区时,可仅按照二叉树形式执行分区。
当分区出的块的宽度尺寸或长度尺寸不能被进一步分区时,至少一个指示符可不被用信号发送。
除了基于四叉树的二叉树分区以外,基于四叉树的分区可在二叉树分区之后被执行。
以下,将描述通过作为视频编码处理的一部分的变换方法来提高视频压缩效率的方法。更具体地,传统视频编码的编码包括:帧内/帧间预测步骤,对作为当前原始图像的一部分的原始块进行预测;作为预测的预测块与原始块之间的差的残差块的变换和量化步骤;熵编码,其为针对经过变换和量化的块的系数和从先前阶段获得的压缩信息的基于概率的无损压缩方法。通过编码,作为原始图像的压缩形式的比特流被形成,并且比特流被发送到解码器或被存储在记录介质中。这里描述的洗牌和离散正弦变换(以下称为SDST)被用于提高变换方法的效率,从而可提高压缩效率。
根据本发明的SDST方法使用离散正弦变换类型-7或DST-VII(以下称为DST-7)而不是作为视频编码中广泛使用的变换核的离散余弦变换类型-2或DCT-II(以下称为DCT-2),从而可更好地应用图像的共同频率特性。
通过根据本发明的变换方法,可以以相比于传统视频编码方法相对更低的比特率获得客观的高清晰度视频。
DST-7可被应用于残差块的数据。可基于与残差块相应的预测模式来执行对残差块应用DST-7。例如,DST-7可应用于按照帧间模式编码的残差块。根据本发明的实施例,DST-7可在重布置或洗牌之后被应用于残差块的数据。这里,洗牌表示图像数据的重布置,并可被称为残差信号重布置。这里,残差块可具有与残差、残差信号和残差数据相同的含义。另外,残差块可具有与重建残差、重建残差块、重建残差信号和重建残差数据相同的含义,其中,重建残差、重建残差块、重建残差信号和重建残差数据是通过编码器和解码器的重建形式的残差块。
根据本发明的实施例,SDST可使用DST-7作为变换核。这里,SDST的变换核不限于DST-7,并可以是各种类型的DST(诸如,离散正弦变换类型-1(DST-1)、离散正弦变换类型-2(DST-2)、离散正弦变换类型-3(DST-3)、…、离散正弦变换类型-n(DST-n)等(这里,n是等于或大于1的正整数))中的至少一种类型。
根据本发明实施例的执行一维DCT-2的方法可被表示为如下的方程式1。这里,块尺寸被指定为N,频率分量位置被指定为k,空间域中的第n系数的值被指定为x
【方程式1】
通过方程式1对残差块执行水平变换和垂直变换,能够进行二维域的DCT-2。
DCT-2变换核可被定义为如下方程式2。这里,频域中的根据位置的基本矢量可被指定为X
【方程式2】
同时,图12是示出根据本发明的DCT-2频域中的基本矢量的示图。图12示出频域中的DCT-2的频率特性。这里,通过DCT-2的基本矢量X
DCT-2可用于针对4×4、8×8、16×16、32×32等尺寸的残差块的变换处理。
同时,DCT-2可基于残差块尺寸、残差块的颜色分量(例如,亮度分量和色度分量)或与残差块相应的预测模式中的至少一个被选择性地使用。例如,当按照帧内模式编码的4×4尺寸的残差块的分量是亮度分量时,可不使用DCT-2。这里,预测模式可意为帧间预测或帧内预测。另外,在帧内预测的情况下,预测模式可意为帧内预测模式或帧内预测方向。
通过DCT-2变换核的变换在具有邻近像素之间的变化小的特性的块(诸如,图像中的背景)中可具有高压缩效率。然而,它可能并不适合作为具有复杂样式的区域(诸如,图像中的纹理)的变换核。当在邻近像素之间具有低相关性的块通过DCT-2被变换时,实质的变换系数可能出现在频域的高频分量中。在视频压缩中,高频区域中的变换系数的频繁出现可能降低压缩效率。为了提高压缩效率,期望系数在低频分量附近为大值,并且期望系数在高频分量中靠近0。
根据本发明实施例的执行一维DST-7的方法可被表示为如下的方程式3。这里,块尺寸被指定为N,频率分量位置被指定为k,空间域中的第n系数的值被指定为x
【方程式3】
通过经由方程式3对残差块执行水平变换和垂直变换,能够进行二维域中的DST-7。
DST-7变换核可被定义为如下方程式4。这里,DST-7的第k基本矢量被指定为X
【方程式4】
DST-7可用于针对2×2、4×4、8×8、16×16、32×32、64×64、128×128等中的至少一个尺寸的残差块的变换处理。
同时,除了正方形块之外,DST-7还可应用于矩形块。例如,DST-7可应用于具有不同宽度尺寸和高度尺寸(例如,8×4、16×8、32×4、64×16等)的矩形块的垂直变换和水平变换中的至少一个变换。
另外,DST-7可基于残差块尺寸、残差块的颜色分量(例如,亮度分量和色度分量)或与残差块相应的预测模式中的至少一个被选择性地使用。例如,当按照帧内模式编码的4×4尺寸的残差块的分量是亮度分量时,可使用DST-7。这里,预测模式可意为帧间预测或帧内预测。另外,在帧内预测的情况下,预测模式可意为帧内预测模式或帧内预测方向。
同时,图13是示出根据本发明的DST-7频域中的基本矢量的示图。参照图13,DST-7的第一基本矢量(x
当按照帧内预测的编码单元(CU)对4×4变换单元(TU)执行变换时,可使用DST-7。由于帧内预测特性,错误率随着远离参考样点而增加,这被应用于DST-7,从而DST-7可提供更高的变换效率。也就是说,在空间域中,当块具有随着远离块中的(0,0)位置而增加的残差信号时,该块可通过使用DST-7而被有效压缩。
如上所述,为了提高变换效率,使用适合于图像的频率特性的变换核是重要的。特别地,对原始块的残差块执行变换,从而可通过按照CU或PU或TU识别残差信号的分布特性来识别DST-7和DCT-2的变换效率。
图14是示出在8×8编码单元(CU)的2N×2N预测单元(PU)中的根据位置的平均残差值的分布的示图,其中,8×8编码单元(CU)按照通过在低延迟P简档环境下实验“Cactus”序列获得的帧间模式被预测。
参照图14,图14的左侧示出块中的平均残差信号值中的相对大的前30%的值,右侧示出与左侧相同的块中的平均残差信号值中的相对大的前70%的值。
在图14中,按照帧间模式预测的8×8CU的2N×2N PU中的残差信号分布示出了小的残差信号值主要集中在块的中心附近并且残差信号值随着远离块的中心而更大的特性。也就是说,残差信号值在块边界更大。残差信号的这样的分布特性是PU中的残差信号的共同特征,而与CU尺寸和使CU能够按照帧间模式被预测的PU分区模式(2N×2N、2N×N、N×2N、N×N、nR×2N、nL×2N、2N×nU、2N×nD)无关。
图15是示出根据本发明的在8×8编码单元(CU)的2N×2N预测单元(PU)中的残差信号的分布特性的三维图表,其中,8×8编码单元(CU)按照帧间预测模式(帧间模式)被预测。
参照图15,小的残差信号值集中在块的中心附近,并且残差信号值随着靠近块边界而相对更大。
基于图14和图15中的残差信号的分布特性,按照帧间模式预测的CU的PU中的残差信号的变换通过使用DST-7而非DCT-2会更有效。
以下,将描述作为将DST-7用作变换核的变换方法之一的SDST。
根据本发明的SDST可按照两个步骤执行。第一个步骤是对按照帧间模式或帧内模式预测的CU的PU中的残差信号进行洗牌。第二个步骤是将DST-7应用于块中的洗牌后的残差信号。
布置在当前块(例如,CU、PU或TU)中的残差信号可按照第一方向被扫描,并可按照第二方向被重布置。也就是说,在当前块中布置的残差信号可按照第一方向被扫描,并可照第二方向被重布置,从而洗牌可被执行。这里,残差信号可意为指示原始信号与预测信号之间的残差信号的信号。也就是说,残差信号可意为执行变换和量化中的至少一个操作之前的信号。可选择地,残差信号可意为执行了变换和量化中的至少一个操作的信号。
另外,残差信号可意为重建残差信号。也就是说,残差信号可意为执行了逆变换和反量化中的至少一个操作的信号。另外,残差信号可意为执行逆变换和反量化中的至少一个操作之前的信号。
同时,第一方向(或扫描方向)可以是光栅扫描顺序、右上对角扫描顺序、水平扫描顺序和垂直扫描顺序中的一个扫描顺序。另外,第一方向可被如下定义。
(1)从顶部行到底部行进行扫描,而在一个行中从左侧到右侧进行扫描
(2)从顶部行到底部行进行扫描,而在一个行中从右侧到左侧进行扫描
(3)从底部行到顶部行进行扫描,而在一个行中从左侧到右侧进行扫描
(4)从底部行到顶部行进行扫描,而在一个行中从右侧到左侧进行扫描
(5)从左侧列到右侧列进行扫描,而在一个列中从顶部到底部进行扫描
(6)从左侧列到右侧列进行扫描,而在一个列中从底部到顶部进行扫描
(7)从右侧列到左侧列进行扫描,而在一个列中从顶部到底部进行扫描
(8)从右侧列到左侧列进行扫描,而在一个列中从底部到顶部进行扫描
(9)按照螺旋形进行扫描:从块的内部(或外部)到块的外部(或内部)并按照顺时针/逆时针方向进行扫描
(10)对角扫描:从块中的一个角到左上侧、右上侧、左下侧或右下侧对角地进行扫描
同时,上述扫描方向中的一个扫描方向可被选择性地用作第二方向(或重布置方向)。第一方向和第二方向可相同,或者可彼此不同。
可对每个当前块执行针对残差信号的扫描和重布置处理。
这里,重布置可意为将按照第一方向在块中扫描的残差信号按照第二方向布置在相同尺寸的块中。另外,按照第一方向扫描的块的尺寸可不同于按照第二方向重布置的块的尺寸。
另外,这里,扫描和重布置分别根据第一方向和第二方向被单独执行,但是扫描和重布置可作为关于第一方向的一个处理被执行。例如,块中的残差信号从顶部行到底部行被扫描,而在一个行中,残差信号从右侧到左侧被扫描,并且可被存储(重布置)在块中。
同时,可对当前块中的每个预定子块执行针对残差信号的扫描和重布置处理。这里,子块可以是在尺寸上等于或小于当前块的块。
子块可具有固定尺寸/形状(例如,4×4、4×8、8×8、…、N×M,这里,N和M是正整数)。另外,子块的尺寸和/或形状可被不同地推导出。例如,子块的尺寸和/或形状可根据当前块的尺寸、形状和/或预测模式(帧间、帧内)而被确定。
扫描方向和/或重布置方向可根据子块的位置而被自适应地确定。在这种情况下,每个子块可使用不同扫描方向和/或不同重布置方向。可选择地,当前块中的所有或部分子块可使用相同扫描方向和/或相同重布置方向。
图16是示出根据本发明的按照编码单元(CU)的2N×2N预测单元(PU)模式的残差信号的分布特性的示图。
参照图16,PU按照四叉树结构被分区为四个子块,并且每个子块的箭头方向指示残差信号的分布特性。具体地,每个子块的箭头方向指示残差信号增加的方向。与PU分区模式无关,PU中的残差信号具有共同的分布特性。因此,为了具有适合于DST-7变换的分布特性,可执行用于重布置每个子块的残差信号的洗牌。
图17是示出根据本发明的在2N×2N预测单元(PU)的洗牌之前和之后的残差信号的分布特性的示图。
参照图17,左侧块示出按照帧间模式预测的8×8CU的2N×2N PU中的残差信号的洗牌之前的分布。以下方程式5表示根据图17的左侧块中的每个残差信号的位置的值。
【方程式5】
由于按照帧间模式预测的CU的PU中的残差信号的分布特性,具有相对小的值的残差信号实质分布在图17的左侧块的中心区域。具有大的值的残差信号实质分布在左侧块的边界。
在图17中,右侧块示出洗牌之后的2N×2N PU中的残差信号的分布。这示出针对执行了洗牌的PU的每个子块的残差信号分布是适合于DST-7的第一基本矢量的残差信号分布。也就是说,每个子块中的残差信号当位于远离(0,0)位置时具有大的值。因此,当执行变换时,通过DST-7被频率变换的变换系数值可同轴地出现在低频区域中。
以下方程式6表示根据按照四叉树结构被分区为四个子块的PU中的每个子块的位置的洗牌方法。
【方程式6】
S0
a′(x,y)=a(W
S1
b′(x,y)=b(x,H
S2
c′(x,y)=c(W
S3
d′(x,y)=d(x,y)
0≤x≤W
这里,PU中的第k子块(k∈{blk0,blk1,blk2,blk3})的宽度和高度被指定为W
图18是示出根据本发明的子块的4×4残差数据的重布置的示例的示图。
参照图18,子块可意为8×8预测块中的几个子块中的一个子块。图18(a)示出重布置之前的原始残差数据的位置,图18(b)示出残差数据的重布置的位置。
参照图18(c),残差数据的值从(0,0)位置到(3,3)位置逐渐增加。这里,每个子块中的水平和/或垂直一维残差数据可具有按照图13中所示的基本矢量的类型的数据分布。
也就是说,根据本发明的洗牌可重布置每个子块的残差数据,使得残差数据分布适合于DST-7基本矢量的类型。
在每个子块的洗牌之后,DST-7变换可被应用于针对每个子块重布置的数据。
同时,基于TU的深度,子块可按照四叉树结构被分区,或者重布置处理可被选择性地执行。例如,当TU的深度是2时,2N×2N PU中的N×N子块可被分区为N/2×N/2块,并且重布置处理可被应用于每个N/2×N/2块。这里,基于四叉树的TU分区可被连续执行直到最小TU尺寸为止。
另外,当TU的深度是0时,DCT-2变换可被应用于2N×2N块。这里,残差信号的重布置可不被执行。
同时,根据本发明的SDST方法使用PU块中的残差信号的分布特性,使得执行SDST的TU的分区结构可被定义为基于PU按照四叉树进行分区。
图19(a)和图19(b)是示出根据本发明的根据编码单元(CU)的预测单元(PU)模式和变换单元(TU)的洗牌方法的变换单元(TU)的分区结构的示图。图19(a)和图19(b)示出针对帧间预测的PU的非对称分区模式(2N×nU、2N×nD、nR×2N、nL×2N)中的每一个的根据TU的深度的TU的四叉树分区结构。
参照图19(a)和图19(b),每个块的粗线指示CU中的PU,细线指示TU。另外,TU中的S0、S1、S2和S3指示按照方程式定义的TU中的残差信号的洗牌方法。
同时,在图19(a)和图19(b)中,每个PU中的具有深度0的TU具有与PU相同的块尺寸(例如,在2N×2N PU中,具有深度0的TU的尺寸与PU的尺寸相同)。这里,将参照图23公开针对具有深度0的TU中的残差信号的洗牌。
另外,当CU、PU和TU中的至少一个具有矩形形状(例如,2N×nU、2N×nD、nR×2N和nL×2N)时,CU、PU和TU中的至少一个在残差信号的重布置之前被分区为N个子块(诸如,2、4、6、8、16个子块等),并且残差信号的重布置可被应用于分区后的子块。
另外,当CU、PU和TU中的至少一个具有正方形状(例如,2N×2N和N×N)时,CU、PU和TU中的至少一个在残差信号的重布置之前被分区为N个子块(诸如,4、8、16个子块等),并且残差信号的重布置可被应用于分区后的子块。
另外,当TU从CU或PU被分区并且TU具有最高深度(不能被分区)时,TU可被分区为N个子块(诸如,2、4、6、8、16个子块等),并且残差信号的重布置可被应用于分区后的子块。
以上示例示出了当CU、PU和TU具有不同形状或尺寸时执行残差信号的重布置。然而,即使在CU、PU和TU中的至少两个具有相同的形状或尺寸时,残差信号的重布置也可被应用。
同时,图19示出了帧间预测的PU的非对称分区模式,但是非对称分区模式不限于此。TU的分区和洗牌可被应用于PU的对称分区模式(2N×N和N×2N)。
可对PU中的执行了洗牌的每个TU执行DST-7变换。这里,当CU、PU和TU具有相同尺寸和形状时,可对一个块执行DST-7变换。
考虑帧间预测的PU块的残差信号的分布特性,在洗牌之后执行DST-7变换是更有效的变换方法,而不是执行不管CU的尺寸和PU分区模式如何的DCT-2变换。
在变换之后,与残差信号的分布中的相反情况相比,变换系数实质分布在低频分量(具体地,DC分量)附近的事实意为i)使量化之后的能量损失最小,以及ii)在熵编码处理中就比特使用减少方面来说具有更高的压缩效率。
图20是示出根据本发明的基于2N×2N预测单元(PU)的残差信号分布执行DCT-2变换和SDST变换的结果的示图。
图20的左侧示出当CU的PU分区模式是2N×2N时残差信号从中心到边界增加的分布。另外,图20的中间示出对PU中具有深度1的TU执行了DCT-2变换的残差信号的分布。图20的右侧示出在洗牌之后对PU中具有深度1的TU执行了DST-7变换(SDST)的残差信号的分布。
参照图20,与执行DCT-2相比,当对具有残差信号的分布特性的PU的TU执行SDST时,更多的实质系数集中在低频分量附近。较小的系数值出现在高频分量侧。当基于这样的变换特性对帧间预测的PU的残差信号进行变换时,可通过执行SDST而非DCT-2来获得更高的压缩效率。
对执行了DST-7变换的块(其为在PU中定义的TU)执行SDST。如图19所示,TU的分区结构是从PU尺寸直到最大深度的四叉树结构或二叉树结构。这意为DST-7变换可在洗牌之后对正方形块和矩形块执行。
图21是示出根据本发明的SDST处理的示图。在步骤S2110对TU中的残差信号进行变换的步骤中,首先,在步骤S2120可对预测模式是帧间模式的PU中的分区后的TU执行洗牌。接下来,在步骤S2130对洗牌后的TU执行DST-7变换,在步骤S2140可执行量化,并且可执行一系列随后的步骤。
同时,可对预测模式是帧内模式的块执行洗牌和DST-7变换。
以下,作为用于在编码器中实现SDST的实施例,将公开i)对帧间预测的PU中的所有TU执行SDST的方法,以及ii)通过率失真优化选择性地执行SDST或DCT-2的方法。以下方法被描述用于帧间预测的块,但不限于此,以下方法可应用于帧内预测的块。
图22是示出根据本发明的基于帧间预测的编码单元(CU)的预测单元(PU)分区模式的变换单元(TU)分区的分布特性和残差绝对值的示图。
参照图22,在帧间预测模式下,CU可按照四叉树结构或二叉树结构被分区为TU直到最大深度,PU的分区模式的数量可以是K。这里,K是正整数,并且图22中的K是8。
根据本发明的SDST使用图15中所述的帧间预测的CU中的PU的残差信号的分布特性。另外,PU可按照四叉树结构或二叉树结构被分区为TU。具有深度0的TU可与PU相应,具有深度1的TU可与按照四叉树结构或二叉树结构从PU分区的每个子块相应。
图22的每个块根据帧间预测的CU的每个PU分区模式被分区为具有深度2的TU。这里,粗线指示PU,细线指示TU。每个TU的箭头方向指示TU中的残差信号的值增加的方向。可根据PU中的每个TU的位置对每个TU执行洗牌。
具体地,当TU具有深度0时,除了上述用于洗牌的方法之外,还可按照多种方法执行洗牌。
一种方法是从在PU的中心处的残差信号开始进行扫描,按照螺旋方向扫描邻近残差信号,并重新布置按照Z字形扫描顺序从PU的(0,0)位置开始扫描的残差信号。
图23是示出预测单元(PU)中的具有深度0的变换单元(TU)的残差信号的扫描顺序和重布置顺序的示图。
图23(a)和图23(b)示出用于洗牌的扫描顺序,图23(c)示出用于SDST的重布置顺序。
对每个TU中的洗牌后的残差信号执行DST-7变换,并可对其执行量化和熵编码等。这样的洗牌方法使用根据PU分区模式的TU中的残差信号的分布特性。洗牌方法可对残差信号的分布进行优化以提高作为随后的步骤的DST-7变换的效率。
在编码器中,对帧间预测的PU中的所有TU的SDST可根据图21中的SDST处理被执行。根据如图22所述的帧间预测的CU的PU分区模式,PU可被分区为直到最大深度2的TU。可通过使用图22中的TU中的残差信号的分布特性对每个TU中的残差信号执行洗牌。接下来,可在使用DST-7变换核进行变换之后执行量化和熵编码等。
在编码器中,当重建帧间预测的PU中的TU的残差信号时,对帧间预测的PU的每个TU执行DST-7逆变换。重建的残差信号可通过对重建的残差信号进行逆洗牌而被获得。根据这个SDST方法,SDST被应用于帧间预测的PU中的所有TU的变换方法,使得没有标志或信息将被发送到解码器。也就是说,SDST方法可在无需针对SDST方法进行信号发送的情况下被执行。
同时,即使当对帧间预测的PU中的所有TU执行SDST时,编码器也将针对洗牌的残差信号的上述重布置方法中的一部分确定为最优重布置方法。关于确定的重布置方法的信息可被发送到解码器。
作为用于实现SDST的另一实施例,将公开通过RDO使用DCT-2和SDST中的一个而应用的PU的变换方法。与对帧间预测的PU中的所有TU执行SDST的先前实施例相比,编码器的计算可根据此方法而增加。然而,从DCT-2和SDST中选择了更有效的变换方法,使得相比于先前实施例可获得更高的压缩效率。
图24是示出根据本发明的通过率失真优化(RDO)选择DCT-2或SDST的编码处理的流程图。
参照图24,在步骤S2410的TU的残差信号的变换中,将在步骤S2420通过对按照帧间模式执行预测的PU中的每个TU执行DCT-2获得的TU的代价与在步骤S2430和S2440通过执行SDST获得的TU的代价进行比较,并在步骤S2450可根据率失真确定TU的最优变换模式(DCT-2或SDST)。接下来,在步骤S2460可根据确定的变换模式对变换后的TU执行量化和熵编码等。
同时,仅当应用SDST或DCT-2的TU满足以下条件中的一个时,可通过RDO选择最优变换模式。
i)执行DCT-2和SDST的TU按照四叉树结构或二叉树结构或按照与PU分区模式无关的基于CU的CU尺寸被分区。
ii)执行DCT-2和SDST的TU按照四叉树结构或二叉树结构或按照根据PU分区模式的PU尺寸从PU被分区。
iii)不管PU分区模式如何,执行DCT-2和SDST的TU不基于CU而被分区。
条件i)是将SDST或DCT-2选为TU的变换模式的方法,其中,该TU按照四叉树结构或二叉树结构或按照与PU分区模式无关的根据率失真优化的来自CU的CU尺寸被分区。
条件ii)是对TU执行DCT-2和SDST,并且通过使用代价来确定TU的变换模式,其中,该TU按照四叉树结构或二叉树结构或按照根据PU分区模式的PU尺寸被分区,该PU分区模式在用于对帧间预测的PU中的所有TU执行SDST的实施例中被描述。
条件iii)是不管PU分区模式如何,在不对CU或具有与CU相同尺寸的TU进行分区的情况下,执行DCT-2和SDST并确定TU的变换模式。
当按照具体的PU分区模式对针对具有深度0的TU的RD代价进行比较时,将针对对具有深度0的TU执行SDST的结果的代价与针对对具有深度0的TU执行DCT-2的结果的代价进行比较,从而具有深度0的TU的变换模式可被选择。
图25是示出根据本发明的选择DCT-2或SDST的解码处理的流程图。
参照图25,在步骤S2510,可针对每个TU参考发送的SDST标志。这里,SDST标志可以是指示SDST是否被用作变换模式的标志。
当在步骤S2520-是处SDST标志为真时,将SDST模式确定为TU的变换模式并在步骤S2530对TU中的残差信号执行DST-7逆变换。在步骤S2540对执行了DST-7逆变换的TU中的残差信号执行使用上述根据PU中的TU的位置的方程式6的逆洗牌,从而在步骤S2560可获得重建残差信号。
同时,当在步骤S2520-否处SDST标志不为真时,将DCT-2模式确定为TU的变换模式并在步骤S2550对TU中的残差信号执行DCT-2逆变换,从而在步骤S2560可获得重建残差信号。
当使用SDST方法时,可对残差数据进行重布置。这里,残差数据可意为与帧间预测的PU相应的残差数据。可将通过使用可分离属性的从DST-7引入的整数变换用作SDST方法。
同时,可用信号发送sdst_flag用于DCT-2或DST-7的选择性使用。可针对每个TU用信号发送sdst_flag。sdst_flag用于标识是否执行SDST。
图26是示出根据本发明的使用SDST的解码处理的流程图。
参照图26,在步骤S2610,sdst_flag可针对每个TU被用信号发送并可被熵解码。
首先,当在步骤S2620-是处TU的深度是0时,可在步骤S2670和S2680通过使用DCT-2而不是使用SDST来重建TU。可对具有从1直到最大的深度的TU执行SDST。
另外,即使在步骤S2620-否处TU的深度不是0,在步骤S2630-是处当TU的变换模式是变换跳过模式时和/或当TU的编码块标志(cbf)的值是0时,在步骤S2680也可重建TU而不执行逆变换。
同时,当在步骤S2620-否处TU的深度不是0,在步骤S2630-否处TU的变换模式不是变换跳过模式并且TU的cbf的值不是0时,在步骤S2640可识别sdst_flag的值。
这里,当在步骤S2640-是处sdst_flag的值是1时,在步骤S2650可执行基于DST-7的逆变换,在步骤S2660对TU的残差数据执行逆洗牌,并在步骤S2680可重建TU。相反,当在步骤S2640-否处sdst_flag的值不是0时,在步骤S2670可执行基于DCT-2的逆变换,并在步骤S2680可重建TU。
这里,洗牌或重布置的目标信号可以是以下信号中的至少一个信号:逆变换之前的残差信号、反量化之前的残差信号、逆变换之后的残差信号、反量化之后的残差信号、重建残差数据和重建块信号。
同时,在图26中针对每个TU用信号发送sdst_flag,但是可基于TU的变换模式或TU的cbf的值中的至少一个选择性地用信号发送sdst_flag。例如,当TU的变换模式是变换跳过模式时和/或当TU的cbf的值是0时,可不用信号发送sdst_flag。另外,当TU的深度是0时,可不用信号发送sdst_flag。
同时,针对每个TU用信号发送sdst_flag,但也可针对预定单元用信号发送sdst_flag。例如,可针对视频、序列、画面、条带、并行块、编码树单元、编码单元、预测单元和变换单元中的至少一个用信号发送sdst_flag。
在图25的SDST标志和图26的sdst_flag的实施例中,可通过n比特标志(n是等于或大于1的正整数)针对每个TU对选择的变换模式信息进行熵编码/解码。变换模式信息可指示以下至少一个:通过DCT-2、通过SDST还是通过DST-7等对TU执行变换。
仅在帧间预测的PU中的TU的情况下,可按照旁路模式对变换模式信息进行熵编码/解码。另外,当变换模式是变换跳过模式、RDPCM(残差差分PCM)模式或无损模式中的至少一个时,变换模式信息可不被熵编码/解码并可不被用信号发送。
另外,当块的编码块标志的值是0时,变换模式信息可不被熵编码/解码并可不被用信号发送。当编码块标志的值是0时,逆变换处理可在解码器中省略。因此,即使变换模式信息在解码器中不存在,也可重建块。
然而,变换模式信息不限于将变换模式指示为标志,并可被实现为预定义的表和索引。这里,可用于每个索引的变换模式可被定义为预定义的表。
另外,DCT或SDST可按照水平方向和垂直方向被单独执行。相同的变换模式可按照水平方向和垂直方向被使用,或者不同的变换模式可被使用。
另外,关于DCT-2、SDST、和DST-7是否按水平方向和垂直方向被使用的变换模式信息可被分别熵编码/解码。
另外,变换模式信息可按照CU、PU和TU中的至少一个被熵编码/解码。
另外,变换模式信息可根据亮度分量或色度分量被发送。也就是说,变换模式信息可根据Y分量或Cb分量或Cr分量被发送。例如,当用信号发送关于对Y分量执行DCT-2还是SDST的变换模式信息时,在Y分量中用信号发送的变换模式信息(而不用信号发送Cb分量和Cr分量中的至少一个分量中的变换模式信息)可被用作块的变换模式。
这里,可通过使用上下文模型的算术编码方法对变换模式信息进行熵编码/解码。当变换模式信息被实现为预定义的表和索引时,可通过使用上下文模型的算术编码方法对一些二进制位中的全部或部分进行熵编码/解码。
另外,变换模式信息可根据块尺寸被选择性地熵编码/解码。例如,在当前块的尺寸等于或大于64×64时,变换模式信息可不被熵编码/解码。在当前块的尺寸等于或小于32×32时,变换模式信息可被熵编码/解码。
另外,当不是0的一个变换系数或一个量化等级存在于当前块中时,变换模式信息可不被熵编码/解码,并且可对变换模式信息执行DCT-2或DST-7或SDST中的至少一个方法。这里,不管针对变换系数或量化等级不是0的块中的位置如何,变换模式信息可不被熵编码/解码。另外,仅当不是0的变换系数或量化等级存在于块中的左上部时,变换模式信息可不被熵编码/解码。
另外,当不是0的J个或者更多个变换系数或量化等级存在于当前块中时,变换模式信息可被熵编码/解码。这里,J是正整数。
另外,变换模式信息可由于根据同位块的变换模式的一些变换模式的受限使用或由于几个比特的用于指示同位块的变换模式的变换信息的二值化方法而改变。
SDST可基于当前块的预测模式、TU的深度、尺寸和形状中的至少一个而被受限地使用。
例如,在当前块按照帧间模式被编码时,SDST可被使用。
准许SDST的最小/最大深度可被定义。在这种情况下,在当前块的深度等于或大于最小深度时,SDST可被使用。可选择地,在当前块的深度等于或小于最大深度时,SDST可被使用。这里,最小/最大深度可以是固定值,或者可以基于指示最小/最大深度的信息被不同地确定。指示最小/最大深度的信息可从编码器被用信号发送,并可由解码器基于当前/邻近块的属性(例如,尺寸、深度和/或形状)推导出。
准许SDST的最小/最大尺寸可被定义。类似地,在当前块的尺寸等于或大于最小尺寸时,SDST可被使用。可选择地,在当前块的尺寸等于或大于最大尺寸时,SDST可被使用。这里,最小/最大尺寸可以是固定值,或者可以基于指示最小/最大尺寸的信息被不同地确定。指示最小/最大尺寸的信息可从编码器被用信号发送,并可由解码器基于当前/邻近块的属性(例如,尺寸、深度和/或形状)推导出。例如,在当前块的尺寸是4×4时,DCT-2可被用作变换方法,关于DCT-2还是SDST被使用的变换模式信息可不被熵编码/解码。
准许SDST的块的形状可被定义。在这种情况下,在当前块的形状是所定义的块的形状时,SDST可被使用。可选择地,不准许SDST的块的形状可被定义。在这种情况下,在当前块的形状是所定义的块的形状时,SDST可不被使用。准许或不准许SDST的块的形状可被固定,并且块的形状的信息可从编码器被用信号发送。可选择地,块的形状的信息可由解码器基于当前/邻近块的属性(例如,尺寸、深度和/或形状)推导出。准许或不准许SDST的块的形状可意为例如M×N块中的M、N和/或M与N的比率。
另外,当TU的深度是0时,DCT-2或DST-7可被用作变换方法,并且关于哪个变换方法被使用的变换模式信息可被熵编码/解码。当使用DST-7作为变换方法时,残差信号的重布置可被执行。另外,当TU的深度等于或大于1时,DCT-2或SDST可被用作变换方法,并且关于哪个变换方法被使用的变换模式信息可被熵编码/解码。
另外,变换方法可根据CU和PU的分区形状或当前块的形状被选择性地使用。
根据实施例,当CU和PU的分区形状或当前块的形状是2N×2N时,DCT-2可被使用并且DCT-2或SDST可被选择性地用于其余分区和块形状。
另外,当CU和PU的分区形状或当前块的形状是2N×N或N×2N时,DCT-2可被使用并且DCT-2或SDST可被选择性地用于其余分区和块形状。
另外,当CU和PU的分区形状或当前块的形状是nR×2N或nL×2N或者2N×nU或2N×nD时,DCT-2可被使用并且DCT-2或SDST可被选择性地用于其余分区和块形状。
同时,对从当前块分区的每个块执行SDST或DST-7,可对每个分区后的块执行针对变换系数(量化等级)的扫描和逆扫描。另外,对从当前块分区的每个块执行SDST或DST-7,可对每个未分区的当前块执行针对变换系数(量化等级)的扫描和逆扫描。
另外,使用SDST或DST-7的变换/逆变换可根据当前块的帧内预测模式(方向)、当前块的尺寸和当前块的分量(亮度分量或色度分量)中的至少一个被执行。
另外,当执行使用SDST或DST-7的变换/逆变换时,可使用DST-1而取代DST-7。另外,当执行使用SDST或DST-7的变换/逆变换时,可使用DCT-4而取代DST-7。
另外,当执行使用DCT-2的变换/逆变换时,在SDST或DST-7的残差信号的布置中使用的布置方法可被应用。也就是说,即使当使用DCT-2时,也可执行残差信号的重布置或使用预定角度的残差信号的旋转。
以下,将公开针对洗牌方法和信号发送方法的各种修改和实施例。
本发明的SDST被用于通过变换方法的改变来提高图像压缩效率。PU中的残差信号的分布特性通过残差信号的洗牌被有效应用于执行DST-7,从而可获得高压缩效率。
在洗牌的上述描述中,已公开了残差信号的重布置方法。以下,除了洗牌之外,还将公开针对残差信号的重布置方法的其它实施方式。
为了最小化用于残差信号的重布置的硬件复杂度,可通过水平翻转和垂直翻转方法来实现残差信号的重布置方法。可如下通过翻转来实现残差信号的重布置方法(1)至(4)。
(1):r'(x,y)=r(x,y);不执行翻转(不翻转)
(2):r'(x,y)=r(w-1-x,y);水平方向翻转
(3):r'(x,y)=r(x,h-1-y);垂直方向翻转
(4):r'(x,y)=r(w-1-x,h-1-y);水平方向和垂直方向翻转
r'(x,y)是重布置之后的残差信号,r(x,y)是重布置之前的残差信号。块的宽度和高度被分别指定为w和h。块中的残差信号的位置被指定为x,y。使用翻转的重布置方法的逆重布置方法可按照重布置方法的相同处理而被执行。也就是说,通过使用水平方向翻转的重布置的残差信号被进一步水平方向翻转,从而可重建残差信号的原始布置。在编码器中执行的重布置方法和在解码器中执行的逆重布置方法可使用相同的翻转方法。
使用翻转的残差信号洗牌/重布置方法可使用当前块而不进行分区。也就是说,在SDST方法中,当前块(TU等)被分区为子块并且DST-7被用于每个子块。然而,在使用翻转的残差信号洗牌/重布置方法中,在不将当前块分区为子块的情况下,可对当前块的全部或部分执行翻转并随后可使用DST-7。
关于使用翻转的残差信号洗牌/重布置方法是否被使用的信息可通过使用变换模式信息被熵编码/解码。例如,当指示变换模式信息的标志比特具有第一值时,使用翻转的残差信号洗牌/重布置方法和DST-7可被用作变换/逆变换方法。当标志比特具有第二值时,可使用另一变换/逆变换方法而不是使用翻转的残差信号洗牌/重布置方法。这里,可针对每个块对变换模式信息进行熵编码/解码。
另外,四个翻转方法(不翻转、水平方向翻转、垂直方向翻转、水平方向和垂直方向翻转)中的至少一个方法可通过使用翻转方法信息被熵编码/解码为标志或索引。也就是说,通过用信号发送翻转方法信息的在编码器中执行的翻转方法可在解码器中执行。变换模式信息可包括翻转方法信息。
另外,残差信号的重布置方法不限于先前描述的残差信号的重布置,并可通过以预定角度旋转块中的残差信号来实现洗牌。这里,预定角度可意为0度、90度、180度、-90度、-180度、270度、-270度、45度、-45度、135度、-135度等。这里,关于角度的信息可被熵编码/解码为标志或索引,并可与针对变换模式信息(变换模式)的信号发送方法相似地被执行。
另外,当熵编码/解码时,角度信息可从邻近当前块的重建块的角度信息被预测编码/解码。当通过使用角度信息执行重布置时,SDST或DST-7可在对当前块进行分区之后被执行。可选择地,可对每个当前块执行SDST或DST-7而无需对当前块进行分区。
预定角度可根据子块的位置被不同地确定。旋转子块中仅特定位置的子块(例如,第一子块)的重布置方法可被受限地使用。另外,使用预定角度的重布置可被应用于整个当前块。这里,重布置的目标当前块可以是逆变换之前的残差块、反量化之前的残差块、逆变换之后的残差块、反量化之后的残差块、重建残差块和重建块中的至少一个。
同时,为了获得与残差信号重布置或旋转相同的效果,用于变换的变换矩阵的系数可被重布置或旋转,并且该系数被应用于预布置的残差信号,从而变换被执行。也就是说,取代残差信号的重布置,通过使用变换矩阵的重布置来执行变换,从而可获得与执行残差信号重布置和变换的方法相同的效果。这里,变换矩阵的系数的重布置可按照与残差信号重布置方法相同的方式被执行。其信息的信号发送方法可按照与用于残差信号重布置方法的信息的信号发送方法相同的方式被执行。
同时,编码器可将在洗牌的上述描述中所述的残差信号重布置方法的一部分确定为最优重布置方法,并可将关于确定的重布置方法的信息发送到解码器。例如,当使用四个重布置方法时,编码器可通过2比特将关于残差信号重布置方法的信息发送到解码器。
另外,当重布置方法具有不同出现概率时,可通过使用较少比特对具有高出现概率的重布置方法进行编码,并可通过使用相对多的比特对具有低出现概率的重布置方法进行编码。例如,四个重布置方法可按照更高出现概率的顺序被编码为截断一元码(0,10,110,111)。
另外,根据诸如当前CU的预测模式、PU的帧内预测模式(方向)、邻近块的运动矢量等的编码参数,重布置方法的出现概率可改变。因此,关于重布置方法的编码方法可根据编码参数被不同地使用。例如,重布置方法的出现概率可根据帧内预测的预测模式而改变。因此,对于每个帧内模式,较少比特被分配给具有高出现概率的重布置方法,多的比特被分配给具有低出现概率的重布置方法。在一些情况下,具有极低出现概率的重布置方法可不被使用,并且可不对其分配比特。
以下表5示出了根据CU的预测模式和PU的帧内预测模式(方向)对残差信号重布置方法进行编码的示例。
【表5】
表5中的残差信号重布置方法(1)至(4)可指定残差信号重布置方法,诸如,针对用于对残差信号进行重布置的扫描/重布置顺序的索引、针对预定角度值的索引、针对预定翻转方法的索引等。
如表5中所示,在当前块与预测模式和帧内预测模式(方向)中的至少一个相关时,至少一个重布置方法可在编码器和解码器中被使用。
例如,在当前块按照帧内模式并且帧内预测方向是偶数时,不翻转、水平方向翻转和垂直方向翻转中的至少一个可被用作残差信号重布置方法。另外,在当前块按照帧内模式并且帧内预测方向是奇数时,不翻转、垂直方向翻转以及水平方向和垂直方向翻转中的至少一个可被用作残差信号重布置方法。
在帧内预测的平面/DC预测的情况下,关于四个重布置方法的信息可基于四个重布置方法的出现频率被熵编码/解码为截断一元码。
当帧内预测方向是水平方向或近水平方向模式时,重布置方法(1)和(3)的概率会高。在这种情况下,1比特被用于所述两个重布置方法中的每个方法并且关于重布置方法的信息可被熵编码/解码。
当帧内预测方向是垂直方向或近垂直方向模式时,重布置方法(1)和(2)的概率会高。在这种情况下,1比特被用于所述两个重布置方法中的每个方法并且关于重布置方法的信息可被熵编码/解码。
当帧内预测方向是偶数时,关于重布置方法(1)、(2)和(3)的信息可被熵编码/解码为截断一元码。
当帧内预测方向是奇数时,关于重布置方法(1)、(3)和(4)的信息可被熵编码/解码为截断一元码。
在其它帧内预测方向中,重布置方法(4)的出现概率会低。因此,关于重布置方法(1)、(2)和(3)的信息可被熵编码/解码为截断一元码。
在帧间预测的情况下,重布置方法(1)至(4)具有相同的出现概率,关于重布置方法的信息可被熵编码/解码为2比特固定长度码。
这里,编码二进制位值中的每个可使用算术编码/解码。另外,编码二进制位值中的每个可按照旁路被熵编码/解码,而不使用算术编码。
图27和图28是示出根据本发明的在编码器和解码器中执行残差信号重布置(残差重布置)的位置的示图。
参照图27,在编码器中,残差信号重布置可在DST-7变换之前被执行。未在图27中示出,在编码器中,残差信号重布置可在变换和量化之间被执行,并且残差信号重布置可在量化之后被执行。
参照图28,在解码器中,残差信号重布置可在DST-7逆变换之后被执行。未在图28中示出,在解码器中,残差信号重布置可在反量化和逆变换之间被执行,并且残差信号重布置可在反量化之前被执行。
上面已经参照图12至图28描述了根据本发明的SDST方法。以下,将参照图29和图30详细描述根据本发明的应用了SDST方法的解码方法、编码方法、解码器、编码器和比特流。
图29是示出根据本发明的使用SDST方法的解码方法的示图。
参照图29,首先,在步骤S2910,可确定当前块的变换模式。在步骤S2920,可根据当前块的变换模式对当前块的残差数据进行逆变换。
另外,在步骤S2930,可对根据当前块的变换模式的当前块的经过逆变换的残差数据进行重布置。
这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
在SDST模式下,逆变换可按照DST-7变换模式被执行,并且用于对经过逆变换的残差数据执行重布置的模式可被命令。
在SDCT模式下,逆变换可按照DCT-2变换模式被执行,并且用于对经过逆变换的残差数据执行重布置的模式可被命令。
在DST模式下,逆变换可按照DST-7变换模式被执行,并且用于不对经过逆变换的残差数据执行重布置的模式可被命令。
在DCT模式下,逆变换可按照DCT-2变换模式被执行,并且用于不对经过逆变换的残差数据执行重布置的模式可被命令。
因此,仅在当前块的变换模式是SDST和SDCT中的一个时,残差数据的重布置可被执行。
对于SDST和DST模式,逆变换可按照DST-7变换模式被执行,但基于另一DST(诸如,DST-1、DST-2等)的变换模式可被使用。
同时,在步骤S2910的当前块的变换模式的确定操作可包括:从比特流获得当前块的变换模式信息;基于变换模式信息确定当前块的变换模式。
另外,在步骤S2910的当前块的变换模式的确定操作可基于当前块的预测模式、当前块的深度信息、当前块的尺寸和当前块的形状中的至少一个被执行。
具体地,在当前块的预测模式是帧间预测模式时,当前块的变换模式可被确定为SDST和SDCT中的一个。
同时,在步骤S2930的当前块的经过逆变换的残差数据的重布置操作可包括:按照第一方向顺序对当前块中布置的经过逆变换的残差数据进行扫描;按照第二方向顺序重布置当前块中按照第一方向扫描的残差数据。这里,第一方向顺序可以是光栅扫描顺序、右上对角扫描顺序、水平扫描顺序和垂直扫描顺序中的一个扫描顺序。另外,第一方向顺序可被如下定义。
(1)从顶部行到底部行进行扫描,而在一行中从左侧到右侧进行扫描
(2)从顶部行到底部行进行扫描,而在一行中从右侧到左侧进行扫描
(3)从底部行到顶部行进行扫描,而在一行中从左侧到右侧进行扫描
(4)从底部行到顶部行进行扫描,而在一行中从右侧到左侧进行扫描
(5)从左侧列到右侧列进行扫描,而在一列中从顶部到底部进行扫描
(6)从左侧列到右侧列进行扫描,而在一列中从底部到顶部进行扫描
(7)从右侧列到左侧列进行扫描,而在一列中从顶部到底部进行扫描
(8)从右侧列到左侧列进行扫描,而在一列中从底部到顶部进行扫描
(9)按照螺旋形状进行扫描:按照顺时针/逆时针方向从块的内部(或外部)到块的外部(或内部)进行扫描
同时,上述方向中的一个方向可被选择性地用作第二方向。第一方向和第二方向可以相同,或者可以彼此不同。
另外,在步骤S2930的当前块的经过逆变换的残差数据的重布置操作可对当前块中的每个子块执行。在这种情况下,残差数据可基于当前块中的子块的位置被重布置。已在方程式6中描述了基于子块的位置的残差数据的重布置,从而将省略其重复的描述。
另外,在步骤S2930的当前块的经过逆变换的残差数据的重布置操作可通过按照预定义角度旋转在当前块中布置的经过逆变换的残差数据而被执行。
另外,在步骤S2930的当前块的经过逆变换的残差数据的重布置操作可通过根据翻转方法翻转当前块中布置的经过逆变换的残差数据而被执行。在这种情况下,在步骤S2910的当前块的变换模式的确定操作可包括:从比特流获得翻转方法信息;基于翻转方法信息确定当前块的翻转方法。
图30是示出根据本发明的使用SDST方法的编码方法的示图。
参照图30,在步骤S3010,可确定当前块的变换模式。
另外,在步骤S3020,可根据当前块的变换模式来重布置当前块的残差数据。
另外,在步骤S3030,可根据当前块的变换模式对当前块的经过重布置的残差数据进行变换。
这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。已经参照图29描述了SDST、SDCT、DST和DCT模式,从而将省略其重复的描述。
同时,仅在当前块的变换模式是SDST和SDCT中的一个时,残差数据的重布置可被执行。
另外,在步骤S3010的当前块的变换模式的确定操作可基于当前块的预测模式、当前块的深度信息、当前块的尺寸和当前块的形状中的至少一个被执行。
这里,在当前块的预测模式是帧间预测模式时,当前块的变换模式可被确定为SDST和SDCT中的一个。
同时,在步骤S3020的当前块的残差数据的重布置操作可包括:按照第一方向顺序对当前块中布置的残差数据进行扫描;按照第二方向顺序重布置当前块中按照第一方向扫描的残差数据。
另外,在步骤S3020的当前块的残差数据的重布置操作可对当前块中的每个子块执行。
在这种情况下,在步骤S3020的当前块的残差数据的重布置操作可基于当前块中的子块的位置而被执行。
同时,在步骤S3020的当前块的残差数据的重布置操作可通过按照预定义角度旋转在当前块中布置的残差数据而被执行。
同时,在步骤S3020的当前块的残差数据的重布置操作可通过根据翻转方法翻转当前块中布置的残差数据而被执行。
根据本发明的通过使用SDST方法对视频进行解码的设备可包括:逆变换单元,确定当前块的变换模式,根据当前块的变换模式对当前块的残差数据进行逆变换,并根据当前块的变换模式重布置当前块的经过逆变换的残差数据。这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
根据本发明的通过使用SDST方法对视频进行解码的设备可包括:逆变换单元,确定当前块的变换模式,根据当前块的变换模式重布置当前块的残差数据,并根据当前块的变换模式对当前块的重布置的残差数据进行逆变换。这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
根据本发明的通过使用SDST方法对视频进行编码的设备可包括:变换单元,确定当前块的变换模式,根据当前块的变换模式重布置当前块的残差数据,并根据当前块的变换模式对当前块的重布置的残差数据进行变换。这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
根据本发明的通过使用SDST方法对视频进行编码的设备可包括:变换单元,确定当前块的变换模式,根据当前块的变换模式对当前块的残差数据进行变换,并根据当前块的变换模式重布置当前块的经过变换的残差数据。这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
通过根据本发明的通过使用SDST方法对视频进行编码的方法形成比特流。所述方法可包括:确定当前块的变换模式;根据当前块的变换模式重布置当前块的残差数据;并根据当前块的变换模式对当前块的重布置的残差数据进行变换。这里,变换模式可包括SDST(洗牌离散正弦变换)、SDCT(洗牌离散余弦变换)、DST(离散正弦变换)或DCT(离散余弦变换)中的至少一种。
根绝本发明的实施例,通过改变经过变换和/或量化的系数的扫描和/或分组方法,提高了编码效率。
详细地,视频编码处理可通过以下处理产生作为原始图像的压缩形式的比特流:通过帧内预测或帧间预测对原始块进行预测,将变换和量化中的至少一个应用于作为预测块与原始块之间的差的残差块内的残差像素,并对应用了变换和量化中的至少一个的块内的系数以及编码信息进行熵编码,其中,熵编码是基于概率的无损压缩方法。产生的比特流可被发送到解码器或被存储在记录介质中。
根据本发明的实施例,具体地,当通过使用预定预测模式对TU进行预测时,为了对应用了变换和/或量化的TU内的系数进行熵编码/解码,根据本发明的扫描和/或分组方法可被应用。后面将描述的编码/解码可表示熵编码/解码。此外,后面将描述的TU可表示存在至少一个样点的样点阵列(诸如,CU、PU、块、子块等)。换句话说,TU可表示CU、PU、块和子块中的至少一个。此外,后面将描述的系数可表示经过变换和/或量化的系数。这里,变换可包括第一变换和第二变换中的至少一个。这里,第二变换可表示另外地再次对通过第一变换获得的系数的一部分或全部进行变换的方法。
预定预测模式可以是帧间预测模式或帧内预测模式。帧内预测模式可以是预定义的方向模式或预定义的非方向模式中的至少一个。通过考虑使用预定预测模式预测的TU的经过变换和/或量化的系数的分布特性,可通过应用根据本发明的扫描方法对TU内的系数进行编码/解码。此外,可通过使用预定分组方法将TU划分为至少一个子块。可通过应用扫描方法对包括在每个子块中的系数进行编码/解码。
根据本发明的扫描和/或分组方法可考虑TU内的经过变换和/或量化的系数的分布特性。因此,根据本发明,有很高的可能性系数不为0或者为0的系数可被分类到相同的组。根据本发明,对TU内的系数进行编码/解码所需的比特的数量可减少,从而与相同的图像质量相比可减少更多的比特。
为了对TU内的经过变换和/或量化的系数进行编码/解码,将TU内的N个系数分组到单个组中的系数组(CG)可被定义。这里,N可以是大于0的正整数。例如,N可以是16。分组方法可表示TU内应用了变换和/或量化的系数可被分配到系数组的单元的方法。后面将描述的组可表示系数组。
图31是示出按照CG单元对具有16×16尺寸的TU内的经过变换和/或量化的系数进行分组的示例的示图。
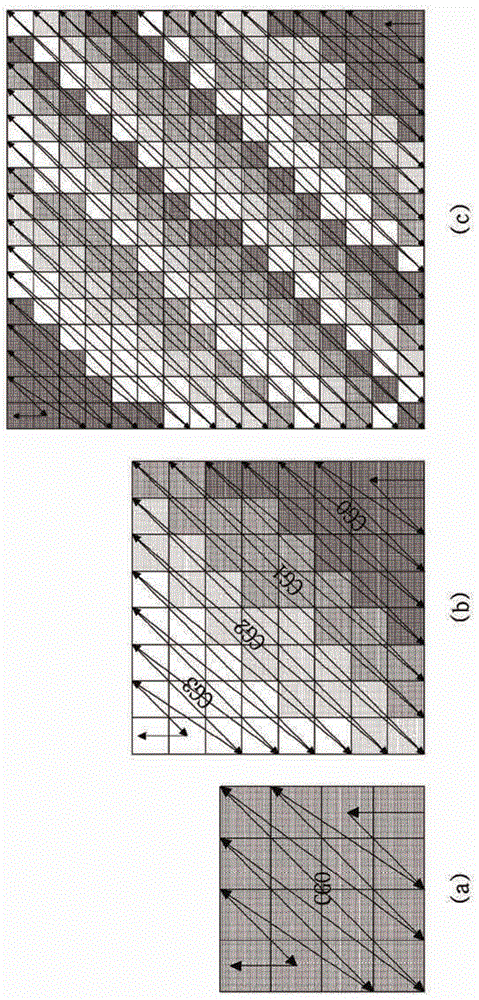
包括在固定在TU内的4×4正方形子块中的系数可被分组到单个CG中。可针对每个CG确定标志和/或语法元素以对经过变换和/或量化的系数进行编码/解码。例如,标志和/或语法元素可包括coded_sub_block_flag(以下,CSBF)、sig_coeff_flag、coeff_abs_level_greater1_flag、coeff_abs_level_greater2_flag、coeff_sign_flag和coeff_abs_level_remaining_value中的至少一个。这里,coded_sub_block_flag可以是指示在每个CG中是否存在不为0的经过变换和/或量化的系数的语法元素。此外,sig_coeff_flag可以是指示经过变换和/或量化的系数是否为0的语法元素。此外,coeff_abs_level_greater1_flag可以是指示经过变换和/或量化的系数的绝对值是否大于1的语法元素。此外,coeff_abs_level_greater2_flag可以是指示经过变换和/或量化的系数的绝对值是否大于2的语法元素。此外,coeff_sign_flag可以是指示经过变换和/或量化的系数的符号值的语法元素。此外,coeff_abs_level_remaining_value可以是指示当经过变换和/或量化的系数的绝对值大于3时从经过变换和/或量化的系数的绝对值减去3获得的值的语法元素。换句话说,用于经过变换和/或量化的系数的语法元素中的至少一个语法元素可按照CG单元被编码/解码。
可基于指示帧内预测被执行还是帧间模式被执行的预测模式和/或帧内模式的预测方向来选择特定的扫描方法。可通过使用选择的扫描方法对TU内的每个CG的经过变换和/或量化的系数进行扫描来确定标志和语法元素中的至少一个。此外,可通过使用选择的扫描方法对TU内的每个CG的经过变换和/或量化的系数进行扫描来对标志和语法元素中的至少一个进行编码/解码。
表6示出了TU内的每个CG的系数的扫描方法的示例。如表6所示,扫描方法可根据预测模式、帧内预测方向和/或块尺寸而被确定。然而,扫描方法及其决定条件不限于表6所示的示例。例如,扫描方法可基于TU的预测模式、帧内预测方向和TU尺寸中的至少一种被确定。可选择地,与表6所示的扫描方法不同的其它扫描方法可被执行。此外,变为扫描目标的经过变换和/或量化的系数可表示经过量化变换的系数等级、变换系数、量化的等级和残差信号系数中的至少一个。
【表6】
表6示出的扫描方法(对角、水平或垂直)中的每一个方法可与图10示出的扫描方法中的每一个方法相应。
图32是示出具有16×16尺寸的TU内的所有系数的扫描顺序的示例的示图。
可通过对由预测块(其中,预测块通过帧间预测或帧内预测产生)与原始块之间的差产生的残差块执行变换和量化中的至少一个来获得TU的系数。在图32中,粗线表示每个CG的边界,具有箭头的线表示每个CG内的系数的扫描顺序,具有箭头的虚线表示在对每个CG的最后系数进行扫描之后将被扫描的CG。换句话说,虚线示出了CG之间的扫描顺序。
在帧内预测的TU的全部TU中或在每个CG中,可至少基于预测方向和TU尺寸来选择性地使用多个预定义的扫描方法中的任意一个扫描方法。帧间预测的TU的每个CG内的系数可使用左下对角方向的扫描顺序。这里,位于图32中箭头通过的位置的系数可被扫描。可选择地,可应用按照右上对角方向的扫描而不是按照左下对角方向的扫描。
可期望根据本发明的扫描方法即使应用按照左下对角方向的扫描或按照右上对角方向的扫描中的任意一个扫描也具有相同结果。这里,对角扫描可表示根据扫描方向的左下对角扫描或右上对角扫描。
如上所述,按照左下对角方向的扫描可被应用于通过帧间预测模式预测的TU内的每个CG的系数。CG可以是TU内的具有N×N尺寸的正方形,或者可以是具有N×M尺寸的矩形。CG尺寸可以是在编码器/解码器中预设的固定尺寸,或可以根据TU尺寸/形状被不同地确定。可选择地,关于CG尺寸的信息可被用信号发送,并且CG尺寸可基于相应的信息被不同地确定。关于CG尺寸的信息可被不同地编码/解码为指示高度/宽度、深度、是否进行划分、以及构成TU的CG的数量等的标志。
图33是示出TU内的系数的分布特性、有效扫描和对CG配置的需求的示图。
图33(a)是示出具有16×16尺寸的TU内的经过变换和/或量化的系数的出现频率的示例的示图。此外,图33(b)是示出具有8×8尺寸的TU内的经过变换和/或量化的系数的出现频率的示例的示图。
在图33中,较暗的颜色表示系数具有高出现频率的地方。根据图33所示的TU内的系数的分布特性,系数的出现频率随着系数变得远离DC系数的位置而变得更低。上述特征可以是通过帧间预测模式预测的所有TU中示出的共同特性,而与TU尺寸无关。这是由于当视频压缩时通过在低频带宽中产生经过变换和/或量化的系数能够获得高压缩性能。
根据本发明的实施例,可通过考虑TU内的经过变换和/或量化的系数的分布特性来提供用于对经过变换和/或量化的系数进行编码/解码的有效扫描和/或分组方法。
以下,将描述TU内的系数分布特性被有效反映的扫描和/或分组方法。根据本发明的扫描目标在于优化TU内的系数的布置以提高熵编码效率。
扫描可被执行以将二维块内的系数表示为一维阵列。可选择地,扫描可被执行以将一维阵列内的系数表示为二维块。熵编码效率可根据扫描的系数在阵列内如何分布而改变。例如,在编码效率方面可优选的是阵列内的系数集中在低频区域。由于根据本发明的扫描反映了TU内的系数的分布特性,故系数可按照使得系数的数据逐渐增加的方向被布置。因此,提高了熵编码效率。
此外,为了增加所有经过变换和/或量化的系数均为0的CG的数量,根据本发明的分组被执行,使得TU内有高可能性为0的经过变换和/或量化的系数被分组到单个CG中。
本发明可执行具有可分离特性的垂直变换和/或水平变换以提高视频编码/解码的压缩率。例如,垂直变换和水平变换中的至少一个变换可使用DST-7,或者垂直变换和水平变换中的至少一个变换可使用DCT-2。可选择地,与垂直变换不同类型的变换可被用于水平变换。水平变换可使用DST-7(或DST-4),垂直变换可使用DCT-2。可选择地,水平变换可使用DCT-2,垂直变换可使用DST-7(或DST-4)。如上所述,通过使用针对垂直变换和水平变换的相同变换方法或通过使用针对垂直变换和水平变换的彼此不同的变换方法,块内的系数的分布可更集中于靠近低频分量(靠近DC分量)。
根据本发明的分组方法反映了上述的系数分布特性,从而分别包括在组内的所有系数均为0的所述组的数量可增加。当包括在特定组中的所有系数均为0时,用于对相应的组内的系数进行编码所需的语法元素(例如,标志)可被节省。在本发明中,编码可表示熵编码。例如,当4×4CG内的所有系数均为0时,编码器可将CSBF设置为0。当CSBF为0时,解码器可不参考用于重建相应的CG内的系数的另外的语法元素(例如,标志)或不对其进行解码。在本发明中,解码可表示熵解码。
当非0的系数存在于4×4CG内时,编码器可通过对表示关于CSBF和系数的信息的另外的标志和语法元素(sig_coeff_flag、coeff_abs_level_greater1_flag、coeff_abs_level_greater2_flag、coeff_sign_flag、coeff_abs_level_remaining_value)中的至少一个进行编码来对相应的CG内的系数进行编码。解码器可通过对所述标志和语法元素中的至少一个进行解码来对相应的CG内的系数的值进行解码。因此,可通过将位于TU内的具有高可能性为0的系数分组到单个组中来节省对组内的系数进行编码/解码所需的语法元素和/或标志。
根据本发明的扫描和/或分组方法可被应用于M×N TU。M和N可分别是大于0的正整数。例如,M和N可分别具有诸如2、4、8、16、32、48、64或更大的值。M和N可相同或彼此不同。
当变换和/或量化被执行时,在TU的高频区域中出现的系数可按照值的大小和/或其出现频率而被减小。此外,考虑人类视觉系统(HVS),通过丢弃高频区域的系数获得的压缩效率的提高大于根据主观和客观图像质量恶化的损失。因此,根据本发明的扫描和/或分组可被应用于仅TU内的左侧区域的一部分。此外,对于TU内的除了左上区域部分之外的区域,根据本发明的关于经过量化的系数的分组信息和/或等级信息可不被编码/解码。例如,在图35中,对于具有黑颜色的区域,编码/解码可不被执行。
后面将详细描述根据本发明的扫描和/或分组方法的各种实施例。在以下描述中,当扫描和/或分组的基础是TU时,TU可表示变换单元或变换块。
根据本发明的实施例的扫描和/或分组可以是基于TU的对角扫描和/或分组。根据基于TU的对角扫描和/或分组,按照左下对角方向连续的从右下AC位置的系数到左上DC位置的系数的N个系数可构成单个组CG。N可以是大于0的正整数。多个CG中的每一个CG可被配置有相同数量的系数(N个系数)。可选择地,多个CG中的所有或一部分CG可被配置有彼此不同数量的系数。每个组内的系数可从具有最高频率的区域到DC位置按照左下对角方向被扫描。
图34是示出根据本发明的实施例的基于TU的对角扫描和/或分组的示图。
图34(a)是示出4×4TU的扫描和分组的示图。
图34(b)是示出8×8TU的扫描和分组的示图。
图34(c)是示出16×16TU的扫描和分组的示图。
在图34中,箭头示出每个CG内的系数的扫描顺序。此外,具有相同阴影的连续区域表示单个CG。单个CG包括从右上AC位置的系数开始按照左下对角方向的16个连续系数。换句话说,在图34示出的示例中,多个CG中的每个CG包括相同数量的系数(16个系数)。
如图34所示,每个CG内的系数可按照箭头所示的方向和顺序被扫描。此外,当每个CG内的最后系数被扫描时,可按照左下对角方向针对包括按照扫描顺序在该最后系数之后的系数的CG执行扫描。可通过使用上述方法对TU内的所有系数进行扫描。
虽然在图34中未示出,但是右上对角扫描(而非左下对角扫描)也可被用作对角扫描方法。
图35是示出32×32TU的编码/解码区域的示例的示图。
在图35中,关于经过变换和/或量化的系数的组信息和等级信息中的至少一个信息不被编码/解码的频率区域的系数被以黑颜色表示。位于高频区域的系数的出现频率低,或者其值小。此外,虽然高频区域的系数被移除,但是根据HVS系统,人感觉到的图像质量并无区别。因此,可通过移除并不对高频区域的系数进行编码来获得高编码效率。
因此,对于具有预定尺寸或更大尺寸的TU,一部分高频区域的系数可不被编码/解码。这里,所述预定尺寸可以是N×M。N和M可分别是正整数。此外,N和M可相同或彼此不同。例如,如图35所示,N×M可以是32×32。所述预定尺寸(N和/或M)可以是在编码器/解码器中预定义的固定值,或者明确地可被用信号发送。所述一部分高频区域可基于TU内的位置而被确定。例如,所述一部分高频区域可基于TU内的水平坐标和/或垂直坐标而被确定。例如,所述一部分高频区域可以是水平坐标和/或垂直坐标等于或大于预定第一阈值的区域,或可以是水平坐标和垂直坐标的和等于或大于预定第二阈值的区域。
第一阈值和/或第二阈值可以是在编码器/解码器中预定义的固定值,或者明确地可被用信号发送。可选择地,第一阈值和/或第二阈值可根据TU的特性(例如,块尺寸、块形状、深度、预测模式(帧间或帧内)、帧内预测模式、变换类型、分量(亮度或色度))而被确定。例如,第一阈值和/或第二阈值可被确定为TU的水平长度或垂直长度的3/4。可选择地,第一阈值和/或第二阈值可从由至少一个邻近TU使用的阈值被推导出。不被编码/解码的所述一部分高频区域或者排除不被编码/解码的所述一部分高频区域之外的将被编码和解码的区域可具有诸如正方形、矩形、三角形和/或五角形的块形状。所述一部分高频区域可基于TU的特性(例如,块尺寸、块形状、深度、预测模式(帧间或帧内)、帧内预测模式、变换类型、分量(亮度或色度))而被确定。
如上所述,TU内的系数可按照左下对角方向从右下AC位置的系数到左上DC位置的系数被扫描,并且N个连续系数可被分组到单个组中。可选择地,TU内的系数可按照右上对角方向从左上DC位置的系数到右下AC位置的系数被扫描,并且N个连续系数可被分组到单个组中。可选择地,可按照扫描方向从右下AC位置的系数到左上DC位置的系数执行分组。
根据本发明实施例的扫描和/或分组可以是基于TU的Z字形扫描和/或分组。
图36是示出根据本发明的实施例的Z字形扫描和/或分组的示图。
图36(a)是示出4×4TU的扫描和分组的示图。
图36(b)是示出8×8TU的扫描和分组的示图。
图36(c)是示出16×16TU的扫描和分组的示图。
在图36中,箭头表示每个CG内的系数的扫描顺序。此外,具有相同阴影的连续区域表示单个CG。TU的按照Z字形方向的从右下AC位置的系数到左上DC位置的系数的N个连续系数可构成单个CG。N可以是大于0的正整数。多个CG中的每个CG可被配置有相同数量的系数(N个系数)。可选择地,多个CG中的所有或一部分CG可被配置有彼此不同数量的系数。每个CG的系数可按照Z字形方向从右下AC位置的系数到左上DC位置的系数被顺序地扫描。此外,每个CG可按照Z字形方向被扫描。
当每个CG的最后系数被扫描时,可针对包括按照基于TU的Z字形扫描顺序在该最后系数之后的系数的CG执行扫描。可如上所述对TU内的所有系数进行扫描。
当根据本发明实施例的基于TU的Z字形扫描和/或分组被执行时,如上述的对角扫描和/或分组,对于具有预定尺寸或更大尺寸的TU,一部分高频区域的系数可不被编码/解码。参照图35描述的方法可被应用以确定所述预定尺寸并指定所述一部分高频区域。
如上所述,TU内的系数按照Z字形扫描方向从右下AC位置的系数到左上DC位置的系数被扫描,并且N个连续系数可被分组到单个组中。可选择地,TU内的系数按照Z字形扫描方向从左上DC位置的系数到右下AC位置的系数被扫描,并且N个连续系数可被分组到单个组中。可选择地,可根据扫描方向从右下AC位置的系数到左上DC位置的系数执行分组。
根据本发明实施例的扫描和/或分组可以是边界扫描和/或分组。
图37是示出根据本发明的实施例的边界扫描和/或分组的示图。
图37(a)是示出4×4TU的扫描和分组的示图。
图37(b)是示出8×8TU的扫描和分组的示图。
图37(c)是示出16×16TU的扫描和分组的示图。
参照图34至图36描述的扫描和/或分组的方法在单个组中按照扫描顺序配置固定数量的连续系数。根据参照图37描述的边界扫描和/或分组,TU内的组中的至少一个组可具有不同的尺寸或形状。例如,当组包括位于高频分量的更多系数时,组尺寸可变得更大。如上所述,位于高频分量的系数可具有高可能性为0。因此,在包括大量高频分量的组的所有系数为0的可能性与4×4CG的所有系数为0的可能性之间没有太多不同。此外,当CG被配置为如图37中所示时,组的总数量减少,从而对TU内的系数进行编码所需的比特数量减少,并且可实现有效分组。
表7示出图37中示出的分组和根据按照4×4单元对CG进行分组的组的数量。
【表7】
从表7中,当TU尺寸变大时,确认使用图37中示出的方法的分组在组的总数量方面优于按照4×4单元对CG进行分组。换句话说,TU尺寸越大,图37中示出的分组效率提高得越多。
如上所述,多个CG中的每一个CG可包括固定数量的系数,多个CG中的全部或一部分CG可包括彼此不同数量的系数。根据图37中示出的边界扫描和/或分组,可针对具有固定尺寸(例如,4×4正方形尺寸)并包括DC系数的组执行Z字形扫描。此外,对于其余的组,可执行按照水平方向和/或垂直方向来回重复地对组内的系数进行扫描。这里,可使用左下对角扫描、右上对角扫描、水平扫描和垂直扫描中的至少一个扫描而不是Z字形扫描。
对于具有预定尺寸或更大尺寸的TU,可不对一部分高频区域的系数执行扫描、分组和/或编码/解码。参照图35描述的方法可被相似地应用以确定所述预定尺寸并指定所述一部分高频区域。例如,所述一部分高频区域可以是位于在水平方向上大于TU宽度的一半的坐标处和/或在垂直方向上大于TU高度的一半的坐标处的区域。
图38是示出32×32TU的编码/解码区域的示例的示图。
在图38中,扫描、分组和/或编码/解码不被执行的区域的系数以黑颜色表示。当TU内的特定系数的水平位置和/或垂直位置等于或大于第三阈值时,相应的系数可被排除进行扫描和/或分组。对于被排除进行扫描和/或分组的系数,可省略编码/解码,并且其值可被设置为0。
第三阈值可以是在编码器/解码器中预定义的固定值,或者明确地可被用信号发送。可选择地,第三阈值可根据TU的特性(例如,块尺寸、块形状、深度、预测模式(帧间或帧内)、帧内预测模式、变换类型、分量(亮度或色度))而被确定。例如,第三阈值可被确定为TU的水平长度和/或垂直长度的1/2。可选择地,第三阈值可从由至少一个邻近TU使用的阈值被推导出。可选择地,针对系数的水平位置的阈值可被设置为与针对系数的垂直位置的阈值不同。不执行编码/解码的所述一部分高频区域或者排除不执行编码/解码的所述一部分高频区域之外的执行编码和解码的区域可具有正方形、矩形、三角形和/或五角形的形状。所述一部分高频区域可基于TU的特性(例如,块尺寸、块形状、深度、预测模式(帧间或帧内)、帧内预测模式、变换类型、分量(亮度或色度))而被确定。
如图38中所示,根据TU尺寸的边界扫描和/或分组可按照从AC位置的系数到DC位置的系数的方向对TU内的系数进行扫描,并可将按照扫描顺序的可变数量的连续系数分组到单个组中。可选择地,TU内的系数可按照从DC位置的系数到AC位置的系数的方向被扫描,并且可变数量的连续系数可按照扫描序列被分组到单个组中。可选择地,可按照扫描方向从AC位置的系数到DC位置的系数执行分组。
根据本发明实施例的扫描和/或分组可以是基于矩形(非正方形)TU的扫描和/或分组。
当M×N的TU不是正方形时,基于矩形TU的扫描和/或分组可被执行。例如,基于矩形TU的扫描和/或分组可被应用于诸如2N×N、N×2N、4N×N、N×4N、8N×N、N×8N等的矩形TU。
图39是示出水平长矩形TU的扫描和/或分组的示例的示图。图39从顶部开始顺序地示出4N×N配置的8×2TU、4N×N配置的16×4TU、8N×N配置的16×2TU、8N×N配置的32×4TU、2N×N配置的8×4TU和2N×N配置的16×8TU的扫描和/或分组。
图40是示出垂直长矩形TU的扫描和/或分组的示例的示图。图40从左侧开始顺序地示出N×4N配置的2×8TU、N×4N配置的4×16TU、N×8N配置的2×16TU、N×8N配置的4×32TU、N×2N配置的4×8TU和N×2N配置的8×16TU的扫描和/或分组。
在图39和图40中,箭头表示每个CG内的系数的扫描顺序。此外,具有相同阴影的连续区域表示单个CG。
具有矩形配置的TU内的系数也集中于频率靠近DC分量的位置。因此,可通过考虑上述特征对TU内的系数进行扫描和分组。此外,具有长于垂直长度的水平长度的矩形TU内的系数可靠近DC分量并在DC分量的右侧区域频繁地出现。此外,具有长于水平长度的垂直长度的矩形TU内的系数可靠近DC分量并在DC分量的下部区域频繁地出现。
因此,例如,对于诸如图39的16×8TU的水平长TU,可执行向水平轴倾斜的Z字形扫描。此外,例如,对于诸如图40的8×16TU的垂直长TU,可执行向垂直轴倾斜的Z字形扫描。此外,按照扫描顺序的16个连续系数可被分组到单个组中。
此外,虽然在图39和图40中未示出,但是可针对水平长TU执行向垂直轴倾斜的Z字形扫描,并可针对垂直长TU执行向水平轴倾斜的Z字形扫描。
这里,可使用左下对角扫描、右上对角扫描、水平扫描和垂直扫描中的至少一个扫描而不是Z字形扫描。
此外,例如,对于具有垂直长度或水平长度是对方长度的四倍或更长(诸如,N×4N、N×8N、N×16N、4N×N、8N×N或16N×N)(或者,等于或大于K倍,K是大于2的整数)的矩形配置的TU,可通过将TU划分为与TU具有相同比率的子块,从AC位置的系数到DC位置的系数执行扫描和/或分组。
根据本发明,当TU内的系数分布并集中于DC位置时,可提供TU内的系数的扫描和/或分组方法,该扫描和/或分组方法比按照固定4×4尺寸对CG进行分组并按照CG单元进行扫描的方法具有更高的压缩效率。
例如,根据本发明的扫描和/或分组方法中的每个方法可替换从AC位置到DC位置按照左下对角方向的TU内的系数的扫描和分组方法(第一方法)。
可选择地,TU内的系数可按照固定4×4尺寸的CG被分组,并且根据本发明的扫描可按照CG单元或在CG内被执行(第二方法)。
可选择地,第一方法和第二方法中的至少一个方法可被选择性地执行(第三方法)。
当第三方法被执行时,编码器可选择多个扫描和/或分组方法中的至少一个方法。关于由编码器选择的扫描和/或分组方法的信息可被编码到比特流。解码器可从比特流对关于选择的扫描和/或分组方法的信息进行解码。随后,解码器可通过使用选择的扫描和/或分组方法对TU内的系数进行解码。可选择地,为了对关于选择的扫描和/或分组方法的信息进行解码,标志可被使用。可通过可选择的扫描/分组方法的数量确定标志的比特的数量。例如,当可选择的扫描/分组方法的数量是2时,标志可以是1比特标志。例如,两个可选择的方法可以是使用固定4×4尺寸的CG的对角扫描和/或分组、基于TU的对角扫描和/或分组、基于TU的Z字形扫描和/或分组、以及边界扫描和/或分组中的至少两个。可选择的扫描/分组方法可在编码器和解码器中被预定义。
当变换和/或量化被执行时,经过变换和/或量化的系数可集中于靠近DC分量。这里,考虑TU内的系数的分布特性,优选的是应用固定扫描和/或分组方法(第一方法),而非应用发送关于选择扫描和/或分组方法的信息的方法(第三方法)。这里,1比特或更多比特的索引可被用于关于扫描和分组中的至少一个的信息。此外,可基于帧内预测模式、帧间预测模式、帧内预测方向、TU尺寸、变换类型、变换尺寸、使用亮度信号还是使用色度信号等来确定或应用扫描方法。
考虑根据本发明的扫描和/或分组方法,可改变确定与系数的编码/解码有关的上下文模型的方法。
当根据本发明的扫描和/或分组方法被应用时,为了选择用于对CSBF进行编码/解码的上下文模型,可参考紧接在当前编码/解码目标CG之前执行了编码/解码的CG的CSBF。可选择地,为了对CSBF进行编码/解码,当前TU内的CG中的至少一个CG可被参考。这里,参考的CG可与该CG在TU内的位置无关地被选择。
图41是示出当对应用了根据本发明的扫描和/或分组方法的8×8TU中的当前CG的CSBF进行编码/解码时的参考CG的示例。
按照扫描顺序,可基于紧接在当前编码/解码目标CG之前被编码/解码的CG的CSBF值来选择CSBF的上下文增量。可基于选择的上下文增量来获得用于对当前CG的CSBF进行编码/解码的上下文信息。不为0的系数是否存在于紧接的先前CG中的概率可影响不为0的系数是否存在于当前CG中的概率。因此,紧接的先前CG的CSBF值的概率可影响当前CG的CSBF值的概率。在当前CG是扫描顺序中的第一CG(包括AC位置的系数的CG)时或当紧接的先前被编码/解码的CG的CSBF是0时,用于对当前CG的CSBF进行编码/解码的上下文增量可被设置为0,在其它情况下,所述上下文增量可被设置为1。
此外,可改变确定sig_coeff_flag的上下文模型的方法。
图42是示出当应用了根据本发明的扫描和/或分组方法时根据TU内的系数的位置参考用于对sig_coeff_flag进行编码/解码的上下文模型的方法的示图。
例如,当根据本发明的扫描和/或分组方法被应用时,当选择用于对当前CG内的每个系数的sig_coeff_flag进行编码/解码的上下文模型时,可基于TU内的每个系数的位置来选择上下文,而不使用邻近CG的CSBF。
例如,由于TU可被划分为多个区域,故相同上下文增量可被用于单个区域。可基于TU的水平长度的N分之一和/或垂直长度的M分之一来确定所述多个区域。N和M可以是大于0的正整数,并且N和M可以相同或彼此不同。
如图42中所示,每个TU可被划分为至少两个区域。例如,在图42中,每个TU被划分为三个区域(区域A、区域B和区域C)。
例如,区域A可以是包括水平坐标小于TU的水平长度的四分之一并且垂直坐标小于TU的垂直长度的四分之一的位置的区域。可选择地,区域A可以是包括水平坐标和垂直坐标的和小于TU的水平长度或垂直长度的四分之一的位置的区域。相同上下文增量可被用于包括在区域A中的系数。
区域B可以在排除了区域A之外的TU中被定义。例如,区域B可以是包括水平坐标小于TU的水平长度的二分之一并且垂直坐标小于TU的垂直长度的二分之一的位置的区域。可选择地,区域B可以是包括水平坐标和垂直坐标的和小于TU的水平长度或垂直长度的二分之一的位置的区域。相同上下文增量可被用于包括在区域B中的系数。
区域C可被定义为排除了区域A和区域B之外的TU中其余部分。相同上下文增量可被用于包括在区域C中的系数。
当上下文增量变大时,可表示sig_coeff_flag出现的概率变高。这里,区域可具有正方形、矩形、三角形和五角形中的至少一个的形状。区域可基于TU的特性(例如,块尺寸、块形状、深度、预测模式(帧间或帧内)、帧内预测模式、变换类型、分量(亮度或色度))而被确定。
此外,sig_coeff_flag可在不使用上下文模型的情况下被编码/解码。例如,上下文模型可不被用于减小编码器/解码器的复杂度。
如上所述,根据本发明,可提供编码/解码目标TU内的系数的有效扫描和/或分组方法。相比于通过帧内预测产生的经过变换和/或量化的系数,通过帧间预测产生的经过变换和/或量化的系数被分布并更集中于靠近DC分量。此外,可通过执行有效预测(帧内预测或帧间预测)减少产生的残差信号的量。这可对更集中于靠近DC分量的经过变换和/或量化的系数具有效果。
然而,根据传统的扫描和/或分组方法,当TU内的系数集中于靠近DC分量时会降低效率。根据本发明,TU内的系数可基于TU按照对角或Z字形顺序被扫描和/或分组。当根据本发明的扫描方法被应用时,按照一维布置的系数值稳定地降低,从而在熵编码方面的效率可被增加。此外,当根据本发明的分组方法被应用时,位于高频处并具有高可能性为0的系数根据TU内的系数的分布特性被分组为单个组,从而可产生每个组内的所有系数为0的许多组。因此,可节省对组内的系数进行编码所需的语法元素和/或标记,并且比特数量也被减少。
可针对亮度信号和色度信号中的每一个执行帧内编码/解码处理。例如,在帧内编码/解码处理中,推导帧内预测模式、对块进行划分、构建参考样点和执行帧内预测中的至少一个方法可不同地应用于亮度信号和色度信号。
可针对亮度信号和色度信号同等地执行帧内编码/解码处理。例如,在帧内编码/解码处理被应用于亮度信号时,推导帧内预测模式、对块进行划分、构建参考样点和执行帧内预测中的至少一个可被同等地应用于色度信号。
可按照相同方式在编码器和解码器中执行所述方法。例如,在帧内编码/解码处理中,可在编码器和解码器中同等地应用推导帧内预测模式、对块进行划分、构建参考样点和执行帧内预测中的至少一个方法。此外,应用所述方法的顺序可以在编码器和解码器中不同。例如,在针对当前块执行帧内编码/解码的处理中,编码器可在构建参考样点之后对通过执行至少一个帧内预测而确定的帧内预测模式进行编码。
本发明的实施例可根据编码块、预测块、块和单元中的至少一个的尺寸而被应用。这里,所述尺寸可被定义为最小尺寸和/或最大尺寸以便应用实施例,并且可被定义为实施例被应用于的固定尺寸。此外,第一实施例可按照第一尺寸被应用,第二实施例可按照第二尺寸被应用。也就是说,实施例可根据所述尺寸而被多次应用。此外,本发明的实施例可仅在尺寸等于或大于最小尺寸并且等于或小于最大尺寸时被应用。也就是说,实施例可仅在块尺寸在预定范围中时被应用。
例如,仅当编码/解码目标块的尺寸等于或大于8×8时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于16×16时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于32×32时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于64×64时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于128×128时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸为4×4时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或小于8×8时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于16×16时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于8×8且等于或小于16×16时,实施例才可被应用。例如,仅当编码/解码目标块的尺寸等于或大于16×16且等于或小于64×64时,实施例才可被应用。
本发明的实施例可根据时间层而被应用。用于标识实施例可被应用于的时间层的标识符可用信号发送,并且可针对由所述标识符指明的时间层应用实施例。这里,所述标识符可被定义为指示实施例可被应用于的最小层和/或最大层,并且可被定义为指示实施例可被应用于的特定层。
例如,仅在当前画面的时间层为最低层时,实施例才可被应用。例如,仅在当前画面的时间层标识符为0时,实施例才可被应用。例如,仅在当前画面的时间层标识符等于或大于1时,实施例才可被应用。例如,仅在当前画面的时间层为最高层时,实施例才可被应用。
如在本发明的实施例中所描述的,在参考画面列表构建和参考画面列表修改的处理中使用的参考画面集可使用参考画面列表L0、L1、L2和L3中的至少一个。
根据本发明的实施例,当去块滤波器计算边界强度时,可使用编码/解码目标块的至少一个至最多N个运动矢量。这里,N指示等于或大于1的正整数,诸如2、3、4等。
在运动矢量预测中,当运动矢量具有以下单位中的至少一个时,可应用本发明的实施例:16-像素(16-pel)单位、8-像素(8-pel)单位、4-像素(4-pel)单位、整数-像素(整数-pel)单位、1/2-像素(1/2-pel)单位、1/4-像素(1/4-pel)单位、1/8-像素(1/8-pel)单位、1/16-像素(1/16-pel)单位、1/32-像素(1/32-pel)单位以及1/64-像素(1/64-pel)单位。此外,在执行运动矢量预测时,可针对每个像素单元可选地使用运动矢量。
可定义应用本发明的实施例的条带类型并且可根据条带类型应用本发明的实施例。
例如,当条带类型是T(三向预测)-条带时,预测块可通过使用至少三个运动矢量来产生,并且可通过计算至少三个预测块的加权和而被用作编码/解码目标块的最终预测块。例如,当条带类型是Q(四向预测)-条带时,预测块可通过使用至少四个运动矢量来产生,并且可通过计算至少四个预测块的加权和而被用作编码/解码目标块的最终预测块。
本发明的实施例可被应用于使用运动矢量预测的帧间预测和运动补偿方法以及使用跳过模式、合并模式等的帧间预测和运动补偿方法。
应用了本发明的实施例的块的形状可具有正方形状或非正方形状。
在上述实施例中,基于具有一系列步骤或单元的流程图描述了所述方法,但本发明不限于所述步骤的顺序,而是,一些步骤可与其它步骤被同时执行,或者可与其它步骤按照不同顺序被执行。此外,本领域普通技术人员应该理解,流程图中的步骤不彼此相斥,并且在不影响本发明的范围的情况下,其它步骤可被添加到流程图中,或者一些步骤可从流程图被删除。
实施例包括示例的各种方面。针对各种方面的所有可能组合可不被描述,但本领域技术人员将能够认识到不同组合。因此,本发明可包括权利要求范围内的所有替换形式、修改形式和改变。
本发明的实施例可按照程序指令的形式来实施,其中,所述程序指令可由各种计算机组件来执行,并被记录在计算机可读记录介质上。计算机可读记录介质可包括单独的程序指令、数据文件、数据结构等,或者是程序指令、数据文件、数据结构等的组合。记录在计算机可读记录介质中的程序指令可被特别设计和构造用于本发明,或者对于计算机软件技术领域的普通技术人员而言是公知的。计算机可读记录介质的示例包括:磁记录介质(诸如硬盘、软盘和磁带);光学数据存储介质(诸如CD-ROM或DVD-ROM);磁光介质(诸如软光盘);以及被特别构造用于存储和实施程序指令的硬件装置(诸如只读存储器(ROM)、随机存取存储器(RAM)、闪存等)。程序指令的示例不仅包括由编译器格式化出的机器语言代码,还包括可由计算机使用解释器实施的高级语言代码。硬件装置可被配置为由一个或更多个软件模块操作以进行根据本发明的处理,反之亦可。
虽然已根据特定术语(诸如详细元件)以及有限实施例和附图描述了本发明,但它们仅被提供用于帮助更通俗地理解本发明,本发明不限于上述实施例。本发明所属领域的技术人员将理解,可从上述描述做出各种修改和改变。
因此,本发明的精神不应受限于上述实施例,所附权利要求及其等同物的全部范围将落入本发明的范围和精神之内。
工业可用性
本发明可用于对图像进行编码/解码。
- 电子地图标注及显示方法、装置、终端设备及存储介质
- 基表显示方法、装置、计算机设备以及存储介质
- 显示客户地址的方法、装置、计算机设备和存储介质
- 楼层信息的显示方法、装置、计算机设备及存储介质
- 风险数据显示方法、装置、计算机设备及存储介质
- 电子地图中的楼块显示方法、装置、计算机设备和介质
- 电子地图的斑马线显示方法、设备和计算机可读存储介质