一种机器视角下的多目标动态调度优化方法
文献发布时间:2024-05-31 01:29:11
技术领域
本发明属于生产调度技术领域,尤其涉及一种机器视角下的多目标动态调度优化方法。
背景技术
调度是通过对生产资源进行合理的安排和优化,以缩短生产周期、提高资源利用率、降低生产成本的一项关键活动,它在生产系统中发挥着重要作用。由此可见,基于人工智能的、数据驱动的、在复杂环境下的动态调度方法已成为智能制造的重要一环。
与机器种类、工件数量、工件工序加工所需时间是固定的静态生产调度不同,动态生产调度中可能出现各种突发情况,影响制造周期、成本等关键指标。例如,机器故障、订单调整、人工作业等情形都会导致生产过程充满不确定性。在处理动态生产调度问题时,包括群智能、进化算法在内的离线调度算法在难以根据因生产过程不确定导致的生产流程常来实时调整调度方案的同时,无法有效评估不确定性下调度方案的优劣。
在一个电商企业的仓库中,存在多个机器人和物流小车,它们负责执行订单处理的任务。若在这企业中推行多目标动态调度,改善生产效率,提高企业竞争力,则必然需要面对每个订单都有独特的属性,如紧急程度、包裹大小和重量,其次,仓库中的机器人和物流小车的数量有限,在执行不同任务中的执行效率各不相同,且存在能源限制。因此,这一现实场景要求多目标动态调度优化方法能够在不断变化的环境中保持高普适性。但强化学习的主要问题却包括:训练成本高和知识迁移难,这制约基于强化学习的调度方法在复杂环境中的应用。
发明内容
本发明主要针对基于强化学习的动态调度方法尚未解决在生产环境发生变化后的调度策略迁移困难的问题,提出了一种机器视角下的多目标动态调度优化方法,通过多类智能体组合来有效提高系统的普适性;快速响应新的生产环境,辅助管理人员根据不同目标的权重配比来制定相应的调度方案。
为实现上述目的,本发明提供了一种机器视角下的多目标动态调度优化方法,包括:
基于多层神经网络模型,采用多任务学习,获取当前订单加工情况的元状态表征;
基于所述元状态表征,对生产设备进行训练,获取值函数;
采用多目标优化方法,对所述值函数进行求解,基于求解结果,完成生产调度的多目标动态调度优化。
可选地,所述多层神经网络模型包括:输入层、隐藏层和输出层;
所述输入层为:
out
其中,s
所述隐藏层为:
其中,Relu表示的是激活函数,
所述的输出层为:
其中,out
可选地,对智能体进行训练,获取值函数包括:
构建生产设备环境的数学模型;
设计环境奖励;
基于所环境奖励述,根据预设损失函数对所述数学模型求解,获取所述值函数。
可选地,设计所述环境奖励包括:
在执行任务t
可选地,所述预设损失函数为:
其中,
可选地,采用多目标优化方法,对所述值函数进行求解包括:
采用多目标优化生成帕累托前沿,将多目标优化问题定义为预设表达式;
将所述值函数,带入所述预设表达式后进行求解。
可选地,所述预设表达式为:
其中,
可选地,带入所述值函数后的所述预设表达式为:
其中,P′表示的是需要优化的问题。
本发明具有以下有益效果:
本发明提出了一种机器视角下的多目标动态调度优化方法,通过多类智能体组合来有效提高系统的普适性;快速响应新的生产环境,辅助管理人员根据不同目标的权重配比来制定相应的调度方案。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
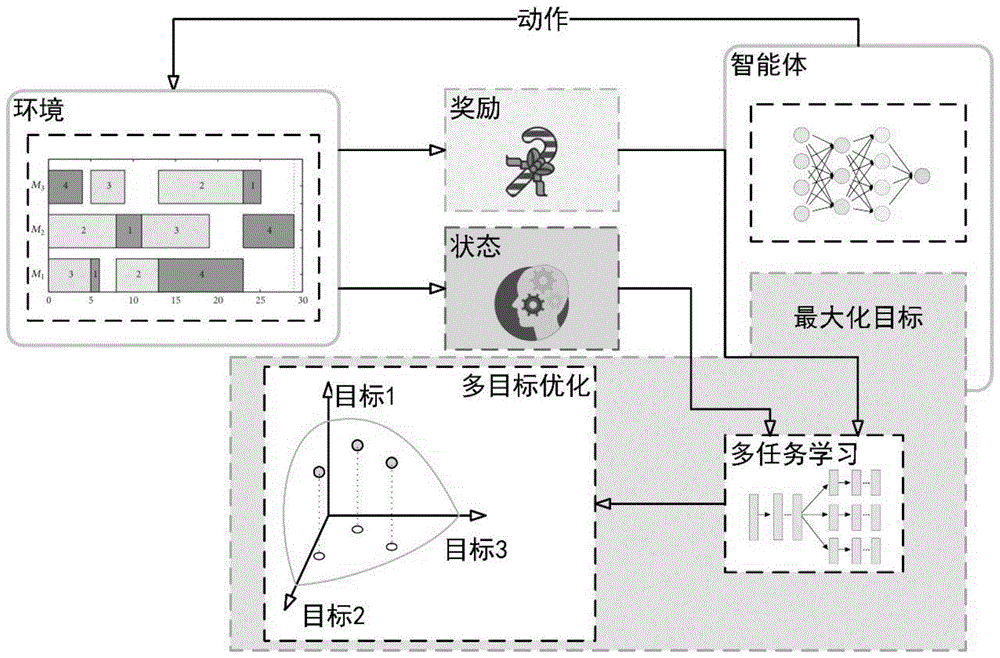
图1为本发明实施例中的一种机器视角下的多目标动态调度优化方法的技术路线。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
当目标因管理理念调整而发生改变时,根据原目标训练的智能体将失去可用性。目前,基于强化学习的动态调度研究中多为固定目标,即以平均延误或平均成本最小化为目标;当目标转变时,例如,从效率优先转为能效优先,已有的策略调整困难。
在动态生产调度领域中,使用强化学习方法的训练成本高、知识迁移难,这制约基于强化学习的调度方法在复杂环境中的应用。针对这些问题,本实施例提出了一种机器视角下的多目标动态调度优化方法,通过多类智能体组合来有效提高系统的普适性;快速响应新的生产环境,辅助管理人员根据不同目标的权重配比来制定相应的调度方案。
本实施例在多任务学习的基础上,构造元状态表征。面向多维度的评价指标,提出潜在目标池,结合多目标优化技术,研究不同理念下的最优调度策略。提出基于多优化目标的动态多智能体调度方法。其技术路线图如图1所示。
通过人工专家设计不同维度下调度策略的评价指标,以此作为智能体目标。根据多任务学习进一步提取不同目标下的元状态表征。随后通过训练获得值函数。最终采用多目标优化方法求解值函数,输出当前状态下的帕累托前沿,即不同目标下的最优动作集合。具体内容如下:
1.拟采用多任务学习抽取状态元表征:本发明通过对多层神经网络模型采用多任务学习获得当前订单加工情况的元表征,从而加速实现在多目标条件下的调度策略学习与迁移过程。每个任务均为单目标优化,且任务间权重相等。此时,通过加权损失最小化即可获得当前状态的元表征。
2.通过多层神经网络模型来抽取当前订单加工情况的元表征,所述的多层神经网络模型包括:输入层、隐藏层和输出层;
所述的输入层为:
out
其中,s
所述的隐藏层为:
其中,Relu表示的是激活函数,
所述的输出层为:
其中,out
3.生产设备进行训练获得值函数,在生产线上,生产设备在t时刻所处的状态为
3.1构建环境的数学模型:在当前环境中,任务集合为
3.2设计环境奖励:在执行任务t
3.3根据公式计算损失:
其中,
4.采用多目标优化方法值函数进行求解
拟采用多目标优化生成帕累托前沿:当值函数
其中,
通过强化学习的在线调度来解决以生产设备结构调整、企业需求改变为代表的复杂环境下的动态调度问题,改善跨厂区、跨企业的调度策略迁移,降低调度策略的训练开销,实现企业自身需求调整后的调度策略复用。
一个智能工厂,涉及多个生产环节和生产设备,以生产不同种类的产品,原以效率为导向,采用单一目标的生产调度优化方法,即追求最小化生产成本和最大化生产效率。但由于社会观念的变化和企业社会责任的日益凸显,公司决定调整策略以更全面地考虑环境、员工关怀和社会责任;决定多方面调整,包括最小化生产周期、最大化设备利用率、最小化能源消耗等。而使用传统的强化学的方法,训练成本高、知识迁移难,已有的策略调整困难。使用本方法,使用多层神经网络模型来提取不同目标下的元状态表征,通过训练获得值函数,加速实现在多目标条件下的策略学习和迁移过程,最后通过采用多目标优化方法求解值函数,输出不同目标下的最优动作集。
在生产线上,机器视角下将每个生产设备都视为一个智能体,从车间内的各个智能体中提取元状态表征。这些表征包括设备的工作状态、生产进度、当前订单的加工要求等信息。智能体通过观察当前订单的加工情况、设备状态和生产进度等信息,学习多个任务,包括生产时间、设备的利用率、能源消耗等,对相应的智能体进行调整生产计划、设备的运行模式等,以满足不同目标下的最优动作集。
当经营理念发生改变时,每一个目标对应一个任务,且任务间权重相等,通过添加、删除或更改任务模块,避免了重新训练整个系统,这样可以快速适应新的优化目标,减轻了经营理念变化带来的重新训练的压力。
本实施例以多目标优化为方法,使用新的方法来实现多个导向下的均衡调度,本实施例对比多目标优化和多任务学习来权衡不同评价指标对调度策略的影响,改善多目标下下调度策略的迁移困难的问题。
以上所述,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 一种手术机器人导航定位系统及测量视角多目标优化方法
- 一种手术机器人导航定位系统及测量视角多目标优化方法