使用结合白细胞介素-17A(IL-17A)的抗体的自身免疫紊乱和炎性紊乱的治疗
文献发布时间:2023-06-19 09:29:07
相关的专利申请
本申请要求于2018年3月29日提交的美国临时申请第62/649,854号的权益,该美国临时申请通过引用以其整体并入本文。
技术领域
白细胞介素-17A(IL-17A,也被称为细胞毒性T淋巴细胞相关抗原8(CTLA8))是一种CD4+ T细胞来源的同二聚体细胞因子,由记忆T细胞在抗原识别后产生。这样的T细胞的发育通过白细胞介素-23促进(McKenzie等人,Trends Immunol.27(1):17-23,2006;Langrish等人,J.Exp.Med.201(2):233-40,2005)。IL-17A通过两种受体,IL-17RA和IL-17RC起作用,以诱导中性粒细胞生物学、炎症和器官破坏中涉及的许多分子的产生。IL-17A上调靶细胞诸如角质形成细胞和成纤维细胞中许多炎症相关基因的表达,导致趋化因子、细胞因子、抗微生物肽和对临床疾病特征有贡献的其他介导物的产生增加。IL-17A与组织坏死因子(TNF)和/或白细胞介素1β(IL-1β)协同作用,以促进更大的促炎性环境。
IL-17A的不适当或过量产生与多种疾病和紊乱的病理学相关,所述多种疾病和紊乱包括类风湿性关节炎(Lubberts,Cytokine 41:84-91,2008),气道超敏反应,包括过敏性气道疾病,诸如哮喘(在Linden,Curr.Opin.Investig.Drugs.4:1304-12,2003;Ivanov,Trends Pharmacol.Sci.30:95-103,2009中综述),银屑病(Johansen等人,Br.J.Dermatol.160:319-24,2009),皮肤超敏反应,包括特应性皮炎(Toda等人,J.AllergyClin.Immunol.111:875-81,2003),系统性硬化(Fujimoto等人,J.Dermatolog.Sci.50:240-42,2008),炎性肠病,包括溃疡性结肠炎和克罗恩氏病(Holtta等人,Inflamm.BowelDis.14:1175-84,2008;Zhang等人,Inflamm.Bowel Dis.12:382-88,2006)和肺病,包括慢性阻塞性肺病(Curtis等人,Proc.Am.Thorac.Soc.4:512-21,2007)。
针对IL-17A(例如,苏金单抗(Secukinumab))或IL-17RA(例如,Brodalumab)的治疗性抗体对受银屑病和类风湿性关节炎影响的患者显示出相当大的临床益处,并且目前正在试验用于其他炎性状况。在2015年,美国食品和药品管理局(US Food and DrugAdministration,FDA)和欧洲药品管理局(European Medicines Agency,EMA)批准了用于治疗银屑病的苏金单抗(
使用结肠癌模型,其中腺瘤在结肠上皮中在杂合Apc消融的工程化背景下由肿瘤阻抑物Apc的自发杂合性丧失引起(Wang等人,Immunity,41:1052-1063,2014),Wang等人观察到肿瘤来源的IL-17A、IL-17C和IL-17F的同时增加,并且发现缺乏上皮IL-17RA表达或用中和IL-17A抗体治疗的小鼠中肿瘤启动(tumor initiation)减少。这种抗体的长期施用减少了已建立的腺瘤的生长,并且使得能够响应于5-氟尿嘧啶凋亡和肿瘤缩小,5-氟尿嘧啶是目前用于治疗结肠癌的化学疗法混合物中的一种组分。在人类中,快速增殖的肠干细胞中APC的双等位基因突变解释了多于80%的散发性结肠癌的启动事件,并且单等位基因突变是家族性腺瘤性息肉病综合征的基础。与IL-17A的促肿瘤发生作用一致,Wang等人报道了在这些小鼠中的全身性IL-17RA消融损伤了肿瘤细胞增殖,降低了STAT3和NF-κB活化,并且增加了肿瘤细胞凋亡(Wang 2014)。
仍然存在对IL-17A的拮抗剂,诸如抗IL-17A单克隆抗体的需要,其在人类受试者中表现出低免疫原性,并且允许重复施用而没有不良的免疫应答,用于治疗人类紊乱,诸如炎性紊乱、自身免疫紊乱、癌症和其他增殖性紊乱。
援引并入
本文公开的所有参考文献在此出于所有目的通过引用以其整体并入。
本发明的公开内容
根据本发明,提供了与白细胞介素-17A(IL-17A)特异性地结合的分离的抗体及其抗原结合片段。这些IL-17A抗体或其抗原结合片段具有对IL-17A的高亲和力,发挥抑制IL-17A的功能,与它们的未修饰的亲本抗体相比在给定的物种(例如,人类)中的免疫原性较低,并且可以用于治疗可通过抑制IL-17A介导的活性治疗的人类紊乱,诸如炎性紊乱、自身免疫紊乱、癌症和其他增殖性紊乱。
在多种实施方案中,抗体或抗原结合片段选自完全人类抗体、人源化抗体、嵌合抗体、单克隆抗体、多克隆抗体、重组抗体、单链抗体、双抗体(diabody)、三抗体(triabody)、四抗体(tetrabody)、Fab片段、Fab’片段、Fab
在多种实施方案中,抗体或抗原结合片段以至少约1×10
在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含以下任一项:(a)轻链CDR3序列,所述轻链CDR3序列与选自SEQ ID NO:25-29的CDR3序列相同、基本上相同或基本上相似;(b)重链CDR3序列,所述重链CDR3序列与选自SEQ IDNO:13-17的CDR3序列相同、基本上相同或基本上相似;或(c)(a)的轻链CDR3序列和(b)的重链CDR3序列。
在多种实施方案中,分离的抗体或抗原结合片段还包含选自以下的氨基酸序列:(d)轻链CDR1序列,所述轻链CDR1序列与选自SEQ ID NO:18-21的CDR1序列相同、基本上相同或基本上相似;(e)轻链CDR2序列,所述轻链CDR2序列与选自SEQ ID NO:22-24的CDR2序列相同、基本上相同或基本上相似;(f)重链CDR1序列,所述重链CDR1序列与选自SEQ IDNO:2-6的CDR1序列相同、基本上相同或基本上相似;(g)重链CDR2序列,所述重链CDR2序列与选自SEQ ID NO:7-12的CDR2序列相同、基本上相同或基本上相似;(h)(d)的轻链CDR1序列和(f)的重链CDR1序列;或(i)(e)的轻链CDR2序列和(g)的重链CDR2序列。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与选自SEQ ID NO:18-21的CDR1序列相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与选自SEQID NO:22-24的CDR2序列相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与选自SEQ ID NO:25-29的CDR3序列相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与选自SEQ ID NO:2-6的CDR1序列相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与选自SEQ ID NO:7-12的CDR2序列相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与选自SEQ ID NO:13-17的CDR3序列相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:18相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:22相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:25相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:2相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:7相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:13相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:19相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:23相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:26相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:3相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:8相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:14相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:20相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:22相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:27相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:4相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:9相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:15相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:21相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:24相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:28相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:5相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:10相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:16相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:20相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:22相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:27相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:6相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:11相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:17相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的人类单克隆抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)轻链CDR1序列,所述轻链CDR1序列与SEQ ID NO:19相同、基本上相同或基本上相似;(b)轻链CDR2序列,所述轻链CDR2序列与SEQ ID NO:22相同、基本上相同或基本上相似;(c)轻链CDR3序列,所述轻链CDR3序列与SEQ ID NO:29相同、基本上相同或基本上相似;(d)重链CDR1序列,所述重链CDR1序列与SEQ ID NO:4相同、基本上相同或基本上相似;(e)重链CDR2序列,所述重链CDR2序列与SEQ ID NO:12相同、基本上相同或基本上相似;以及(f)重链CDR3序列,所述重链CDR3序列与SEQ ID NO:17相同、基本上相同或基本上相似。
在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含:(a)一种或更多种重链可变结构域和/或一种或更多种轻链可变结构域,所述一种或更多种可变结构域具有三个轻链CDR1、CDR2和CDR3的组,和/或三个重链CDR1、CDR2和CDR3的组,所述三个轻链CDR1、CDR2和CDR3与SEQ ID NO:18-21、22-24和25-29相同、基本上相同或基本上相似,所述三个重链CDR1、CDR2和CDR3与SEQ ID NO:2-6、7-12和13-17相同、基本上相同或基本上相似;以及(b)来自人类免疫球蛋白(IgG)的四个框架区的组。在多种实施方案中,抗体可以任选地包含铰链区。在多种实施方案中,框架区选自人类种系外显子X
在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:30中列出的氨基酸序列的重链可变区和具有SEQ ID NO:42中列出的氨基酸序列的轻链可变区。在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:32中列出的氨基酸序列的重链可变区和具有SEQ ID NO:44中列出的氨基酸序列的轻链可变区。在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:34中列出的氨基酸序列的重链可变区和具有SEQ ID NO:46中列出的氨基酸序列的轻链可变区。在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:36中列出的氨基酸序列的重链可变区和具有SEQ ID NO:48中列出的氨基酸序列的轻链可变区。在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:38中列出的氨基酸序列的重链可变区和具有SEQ ID NO:50中列出的氨基酸序列的轻链可变区。在多种实施方案中,本发明的分离的抗体或其抗原结合片段与人类IL-17A结合并且包含具有SEQ ID NO:40中列出的氨基酸序列的重链可变区和具有SEQID NO:52中列出的氨基酸序列的轻链可变区。
在多种实施方案中,当与人类IL-17A结合时,分离的抗体或抗原结合片段:(a)以与参考抗体基本上相同或更大的Kd与人类IL-17A结合;(b)与所述参考抗体竞争结合人类IL-17A;或(c)在人类受试者中的免疫原性低于所述参考抗体,其中所述参考抗体包含选自SEQ ID NO:30/42、32/44、34/46、36/48、38/50和40/52的重链可变结构域序列和轻链可变结构域序列的组合。
在多种实施方案中,本发明的分离的嵌合抗体或其抗原结合片段与人类IL-17A结合,并且包含重链和轻链,所述重链具有与SEQ ID NO:54相同、基本上相同或基本上相似的序列,并且所述轻链具有与SEQ ID NO:56相同、基本上相同或基本上相似的序列。
在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含重链可变区和轻链可变区,所述重链可变区具有与SEQ ID NO:58、60、62和64相同、基本上相同或基本上相似的序列,并且所述轻链可变区具有与SEQ ID NO:59、61、63和65相同、基本上相同或基本上相似的序列。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:58中列出的氨基酸序列的重链可变区和具有SEQ ID NO:59中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:58中列出的氨基酸序列的重链可变区和具有SEQ ID NO:61中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:58中列出的氨基酸序列的重链可变区和具有SEQID NO:63中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:58中列出的氨基酸序列的重链可变区和具有SEQ ID NO:65中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:60中列出的氨基酸序列的重链可变区和具有SEQ ID NO:59中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:60中列出的氨基酸序列的重链可变区和具有SEQID NO:61中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:60中列出的氨基酸序列的重链可变区和具有SEQ ID NO:63中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:60中列出的氨基酸序列的重链可变区和具有SEQ ID NO:65中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:62中列出的氨基酸序列的重链可变区和具有SEQID NO:59中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:62中列出的氨基酸序列的重链可变区和具有SEQ ID NO:61中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:62中列出的氨基酸序列的重链可变区和具有SEQ ID NO:63中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:62中列出的氨基酸序列的重链可变区和具有SEQID NO:65中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:64中列出的氨基酸序列的重链可变区和具有SEQ ID NO:59中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:64中列出的氨基酸序列的重链可变区和具有SEQ ID NO:61中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:64中列出的氨基酸序列的重链可变区和具有SEQID NO:63中列出的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:64中列出的氨基酸序列的重链可变区和具有SEQ ID NO:65中列出的氨基酸序列的轻链可变区。
在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含重链和轻链,所述重链具有与SEQ ID NO:66、70、74和78相同、基本上相同或基本上相似的序列,并且所述轻链具有与SEQ ID NO:68、72、76和80相同、基本上相同或基本上相似的序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:66中列出的重链序列和SEQ ID NO:68中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:66中列出的重链序列和SEQ ID NO:72中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQID NO:66中列出的重链序列和SEQ ID NO:76中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:66中列出的重链序列和SEQ ID NO:80中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:70中列出的重链序列和SEQ ID NO:68中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:70中列出的重链序列和SEQ ID NO:72中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:70中列出的重链序列和SEQ ID NO:76中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:70中列出的重链序列和SEQ ID NO:80中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:74中列出的重链序列和SEQ ID NO:68中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ IDNO:74中列出的重链序列和SEQ ID NO:72中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:74中列出的重链序列和SEQ ID NO:76中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:74中列出的重链序列和SEQ ID NO:80中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:78中列出的重链序列和SEQ ID NO:68中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:78中列出的重链序列和SEQ ID NO:72中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:78中列出的重链序列和SEQ ID NO:76中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:78中列出的重链序列和SEQ ID NO:80中列出的轻链序列。
在多种实施方案中,当与人类IL-17A结合时,分离的抗体或抗原结合片段:(a)以与参考抗体基本上相同或更大的Kd与人类IL-17A结合;(b)与所述参考抗体竞争结合人类IL-17A;或(c)在人类受试者中的免疫原性低于所述参考抗体,其中所述参考抗体包含SEQID NO:58的重链可变结构域序列和SEQ ID NO:59的轻链可变结构域序列。
在另一方面,本发明涉及药物组合物,所述药物组合物包含与药学上可接受的载体混合的本发明的分离的抗体或抗原结合片段。在多种实施方案中,药物组合物包含与药学上可接受的载体混合的分离的人类抗体。在多种实施方案中,药物组合物被配制成用于经由选自由以下组成的组的途径施用:皮下注射、腹膜内注射、肌肉内注射、胸骨内注射、静脉内注射、动脉内注射、鞘内注射、脑室内注射/心室内注射(intraventricularinjection)、尿道内注射、颅内注射、滑膜内注射或经由输注。
在另一方面,本发明涉及治疗患有IL-17A相关的紊乱的受试者的方法,所述方法包括向受试者施用治疗有效量(作为单一疗法或在组合疗法方案中)的本发明的分离的抗体或抗原结合片段,其中IL-17A相关的紊乱选自由炎性紊乱、自身免疫紊乱和癌症组成的组。
在多种实施方案中,IL-17A相关的紊乱是选自由以下组成的组的免疫相关和炎性疾病:系统性红斑狼疮、关节炎、银屑病性关节炎、类风湿性关节炎、骨关节炎、幼年型慢性关节炎、脊椎关节病(spondyloarthropathy)、系统性硬化、特发性炎性肌病、干燥综合征、系统性血管炎、结节病、自身免疫性溶血性贫血、自身免疫性血小板减少症、甲状腺炎、糖尿病、免疫介导的肾病、中枢和外周神经系统的脱髓鞘疾病诸如多发性硬化、特发性脱髓鞘性多神经病或吉兰-巴雷综合征(Guillain-Barre syndrome)和慢性炎性脱髓鞘性多神经病、肝胆疾病诸如感染性自身免疫性慢性活动性肝炎、原发性胆汁性肝硬化、肉芽肿性肝炎和硬化性胆管炎、炎性肠病、结肠炎、克罗恩氏病、谷蛋白敏感性肠病和内毒素血症、自身免疫性或免疫介导的皮肤病包括大疱性皮肤病、多形性红斑和特应性皮炎和接触性皮炎、银屑病、嗜中性皮肤病、囊性纤维化、过敏性疾病诸如哮喘、过敏性鼻炎、食物超敏反应和荨麻疹、囊性纤维化、免疫性肺病诸如嗜酸性肺炎、特发性肺纤维化、成人呼吸道疾病(ARD)、急性呼吸窘迫综合征(ARDS)和炎性肺损伤诸如哮喘、慢性阻塞性肺病(COPD)、气道高反应性、慢性支气管炎、过敏性哮喘和过敏性肺炎、移植相关疾病包括移植物和器官排斥和移植物抗宿主病、感染性休克、多器官衰竭、癌症和血管生成。在多种实施方案中,IL-17A相关的紊乱是选自由以下组成的组的炎性紊乱:银屑病、炎性肠病、溃疡性结肠炎、克罗恩氏病、肠易激综合征、哮喘、关节炎、特应性皮炎、银屑病性关节炎、类风湿性关节炎、幼年型慢性关节炎、系统性硬化、干燥综合征、多发性硬化、系统性红斑狼疮和移植物抗宿主病。
在多种实施方案中,IL-17A相关的紊乱是选自由以下组成的组的自身免疫紊乱:系统性红斑狼疮、关节炎、银屑病性关节炎、类风湿性关节炎、骨关节炎、幼年型慢性关节炎、脊椎关节病、系统性硬化、特发性炎性肌病、干燥综合征、系统性血管炎、结节病、自身免疫性溶血性贫血、自身免疫性血小板减少症、甲状腺炎、糖尿病、免疫介导的肾病、中枢和外周神经系统的脱髓鞘疾病诸如多发性硬化、特发性脱髓鞘性多神经病或吉兰-巴雷综合征和慢性炎性脱髓鞘性多神经病、肝胆疾病诸如感染性自身免疫性慢性活动性肝炎、原发性胆汁性肝硬化、肉芽肿性肝炎和硬化性胆管炎、炎性肠病、结肠炎、克罗恩氏病、谷蛋白敏感性肠病和内毒素血症、自身免疫性或免疫介导的皮肤病包括大疱性皮肤病、多形性红斑和特应性皮炎和接触性皮炎、银屑病、嗜中性皮肤病、囊性纤维化、过敏性疾病诸如哮喘、过敏性鼻炎、食物超敏反应和荨麻疹、囊性纤维化、免疫性肺病诸如嗜酸性肺炎、特发性肺纤维化、成人呼吸道疾病(ARD)、急性呼吸窘迫综合征(ARDS)和炎性肺损伤诸如哮喘、慢性阻塞性肺病(COPD)、气道高反应性、慢性支气管炎、过敏性哮喘和过敏性肺炎、移植相关疾病,包括移植物和器官排斥和移植物抗宿主病、感染性休克、多器官衰竭、癌症和血管生成。
在多种实施方案中,IL-17A相关的紊乱是癌症。在多种实施方案中,癌症是与升高的1L-17A表达相关的癌症。在多种实施方案中,受试者先前响应于用抗癌疗法的治疗,但在疗法停止后,遭受复发(下文称为“复发性癌症”)。在多种实施方案中,受试者患有耐受性癌症或难治性癌症。在多种实施方案中,癌细胞是免疫原性肿瘤(例如,使用肿瘤本身进行疫苗接种可以引起对肿瘤攻击的免疫的那些肿瘤)。
在另一方面,本发明涉及被设计成治疗受试者中的癌症的组合疗法,所述组合疗法包括向受试者施用a)治疗有效量的本发明的分离的抗体或抗原结合片段,和b)一种或更多种另外的疗法,所述一种或更多种另外的疗法选自由免疫疗法、化学疗法、小分子激酶抑制剂靶向疗法、手术、放射疗法和干细胞移植组成的组,其中组合疗法提供了对肿瘤细胞的增加的细胞杀伤,即当被共施用时,分离的抗体或抗原结合片段和另外的疗法之间存在协同作用。在多种实施方案中,免疫疗法选自由以下组成的组:使用针对共刺激或共抑制分子(免疫检查点)诸如PD-1、PD-L1、OX-40、CD137、GITR、LAG3、TIM-3和VISTA的激动抗体、拮抗抗体或阻断抗体的治疗;使用双特异性T细胞接合抗体
在多种实施方案中,包括施用本发明的分离的抗体或抗原结合片段和疫苗或免疫调节剂的组合疗法控制与使用免疫调节剂(例如,(CAR)-T细胞)的单一疗法相关的自身免疫应答和/或细胞因子风暴。在多种实施方案中,与使用免疫调节剂诸如检查点抑制剂、(CAR)-T细胞和其他免疫干预的单一疗法相比,包括施用本发明的分离的抗体或抗原结合片段和疫苗或免疫调节剂的组合疗法提供了癌症免疫疗法的增强的功效。
在多种实施方案中,本发明涉及用于刺激受试者中对病原体、毒素和自身抗原的免疫应答的方法,所述方法包括向受试者施用治疗有效量(作为单一疗法或在组合疗法方案中)的本发明的分离的抗体或抗原结合片段。在多种实施方案中,受试者患有耐受使用常规疫苗的治疗或通过使用常规疫苗的治疗未被有效治疗的传染病。
在另一方面,提供了分离的免疫缀合物或融合蛋白,所述免疫缀合物或融合蛋白包含与效应物分子缀合、连接(或以其他方式稳定地缔合)的抗体或抗原结合片段。在多种实施方案中,效应物分子是免疫毒素、细胞因子、趋化因子、治疗剂或化学治疗剂。
在另一方面,本文公开的抗体或抗原结合片段可以与另外的功能部分共价地连接(或以其他方式稳定地缔合),所述另外的功能部分诸如标记物或赋予期望的药代动力学特性的部分。在多种实施方案中,标记物选自由以下组成的组:荧光标记物、放射性标记物和具有独特的核磁共振特征的标记物。
在另一方面,本发明提供了用于体外或体内检测样品中人类IL-17A抗原的存在的方法,例如,用于诊断人类IL-17A相关的疾病的方法。
在另一方面,提供了分离的核酸,所述分离的核酸包含编码本发明的抗体或抗原结合片段的轻链、重链或二者的多核苷酸序列。在多种实施方案中,多核苷酸包含SEQ IDNO:69、73、77和81的轻链多核苷酸序列;SEQ ID NO:67、71、75和79的重链多核苷酸序列;或二者。
还提供了载体,所述载体包含本发明的核酸。在一种实施方案中,载体是表达载体。还提供了分离的细胞,所述分离的细胞包含本发明的核酸。在一种实施方案中,细胞是包含本发明的表达载体的宿主细胞。在另一种实施方案中,细胞是杂交瘤,其中细胞的染色体包含本发明的核酸。还提供了制备本发明的抗体或抗原结合片段的方法,所述方法包括在允许细胞表达本发明的抗原结合蛋白的条件下培养或孵育细胞。
附图简述
图1描绘了描绘在人类IL-17A结合测定(ELISA)和IL-17AIL-17R阻断测定(ELISA)中评价17种鼠单克隆抗体的结果的线图。
图2描绘了描绘在食蟹猴(cyno primate)IL-17A结合测定(ELISA)中评价17种鼠单克隆抗体的结果的线图。
图3是描绘了在已经用0.5ng/ml TNFα引发的(primed)NIH3T3细胞中,IL-17A滴定对IL-6分泌的作用的线图。
图4描绘了描绘在NIH3T3体外功能测定中评价7种鼠单克隆抗体对IL-6产生的结果的线图。
图5描绘了描绘在NIH3T3体外功能测定中评价10种鼠单克隆抗体对IL-6产生的结果的线图。
用于实施本发明的方式
本发明涉及与人类IL-17A特异性地结合的抗原结合蛋白,诸如抗体或其抗原结合片段。在一方面,提供了分离的抗体及其抗原结合片段,所述分离的抗体及其抗原结合片段与IL-17A特异性地结合,具有对IL-17A的高亲和力,发挥抑制IL-17A的功能,与它们的未修饰的亲本抗体相比在给定的物种(例如,人类)中的免疫原性较低,并且可以用于治疗人类疾病(例如,癌症)、感染和由IL-17A介导的其他紊乱。还提供了核酸分子及其衍生物和片段,所述核酸分子及其衍生物和片段包含编码与IL-17A结合的整个多肽或多肽的一部分的多核苷酸的序列,诸如编码整个抗IL-17A抗体或抗IL-17A抗体的部分、抗体片段或抗体衍生物的核酸。还提供了包含这样的核酸的载体和质粒,和包含这样的核酸和/或载体和质粒的细胞或细胞系。还提供了制备、鉴定或分离与人类IL-17A结合的抗原结合蛋白(诸如抗IL-17A抗体)的方法、确定抗原结合蛋白是否与IL-17A结合的方法、制备包含与人类IL-17A结合的抗原结合蛋白的组合物(诸如药物组合物)的方法、以及用于向受试者施用与IL-17A结合的抗体或其抗原结合片段的方法,例如用于治疗由IL-17A介导的状况的方法。
除非本文中另外定义,否则与本发明关联使用的科学和技术术语应具有本领域普通技术人员通常理解的含义。此外,除非上下文另外要求,否则单数术语应包括复数,并且复数术语应包括单数。通常地,本文描述的与细胞和组织培养、分子生物学、免疫学、微生物学、遗传学以及蛋白和核酸化学和杂交关联使用的命名法和技术是本领域中通常地使用和熟知的那些命名法和技术。除非另外指示,否则本发明的方法和技术通常根据本领域熟知的常规方法和如在整个本说明书中引用和讨论的多个一般性和更具体的参考文献中描述地进行。参见例如Green和Sambrook,Molecular Cloning:A Laboratory Manual,第4版,Cold Spring Harbor Laboratory Press,Cold Spring Harbor,N.Y.(2012),该文献通过引用并入本文。酶促反应和纯化技术根据生产商的说明进行,如本领域中通常地完成或如本文描述的。本文描述的与分析化学、合成有机化学以及药学和药物化学关联使用的命名法和实验程序和技术是本领域中通常地使用和熟知的那些命名法和实验程序和技术。标准的技术被用于化学合成、化学分析、药物制备、配制和递送以及受试者的治疗。
使用标准单字母缩写或三字母缩写指示多核苷酸和多肽序列。除非另外指示,多肽序列在左侧具有它们的氨基末端并且在右侧具有它们的羧基末端,并且单链核酸序列和双链核酸序列的上方的链在左侧具有它们的5’末端并且在右侧具有它们的3’末端。多肽的特定部分可以通过氨基酸残基编号诸如氨基酸80至119,或通过在该位点处的实际的残基诸如Ser80至Ser119来命名。特定多肽或多核苷酸序列还可以基于其与参考序列如何不同来描述。特定轻链和重链的多核苷酸和多肽序列被命名为L1(“轻链1”)和H1(“重链1”)。包含轻链和重链的抗体通过将轻链的名称和重链的名称组合来指示。例如,“L4H4”指例如包含轻链“L4”和重链“H4”的抗体。
本文使用术语“抗体”指包含一个或更多个多肽并且具有对肿瘤抗原的特异性或具有对在病理学状态中过表达的分子的特异性的蛋白,所述多肽基本上或部分地由免疫球蛋白基因或免疫球蛋白基因的片段编码。公认的免疫球蛋白基因包括κ、λ、α、γ、δ、ε和μ恒定区基因,以及这些基因的亚型和大量免疫球蛋白可变区基因。轻链(LC)被分类为κ或λ。重链(HC)被分类为γ、μ、α、δ或ε,其继而分别地定义免疫球蛋白类别IgG、IgM、IgA、IgD和IgE。典型的免疫球蛋白(例如,抗体)结构单元包含四聚体。每个四聚体包含相同的两对多肽链,每一对具有一条“轻链”(约25kD)和一条“重链”(约50-70kD)。每条链的N-末端定义主要负责抗原识别的约100个至110个或更多个氨基酸的可变区。
在全长抗体中,每条重链包含重链可变区(在本文中被缩写为HCVR或VH)和重链恒定区。重链恒定区包含3个结构域,CH1、CH2和CH3(并且在一些实例中,CH4)。每条轻链包含轻链可变区(在本文中被缩写为LCVR或VL)和轻链恒定区。轻链恒定区包含一个结构域,C
CDR主要负责与抗原的表位结合。每条链的CDR通常地被称为CDR1、CDR2、CDR3,从N-末端开始顺序地编号,并且还通常通过特定CDR位于其中的链来鉴定。因此,VH CDR3位于在其中发现它的抗体重链的可变结构域,而VL CDR1是来自在其中发现它的抗体轻链的可变结构域的CDR1。具有不同的特异性的抗体(即针对不同的抗原的不同结合位点)具有不同的CDR。尽管CDR在抗体与抗体之间变化,但在CDR中只有有限数目的氨基酸位置直接地参与抗原结合。CDR中的这些位置被称为特异性决定残基(SDR)。
Kabat定义是用于对抗体中的残基进行编号的标准,并且通常用于鉴定CDR区。Kabat数据库现在保持在线,并且可以确定CDR序列,例如,参见在互联网上可得的IMGT/V-QUEST程序3.2.18版,2011年3月29日,和Brochet,X.等人,Nucl.Acids Res.36,W503-508,2008。Chothia定义与Kabat定义相似,但Chothia定义考虑了某些结构环区域的位置。参见例如Chothia等人,J.Mol.Biol.,196:901-17,1986;Chothia等人,Nature,342:877-83,1989。AbM定义使用由Oxford Molecular Group生产的将抗体结构建模的一套整合的计算机程序。参见例如Martin等人,Proc.Natl.Acad.Sci.USA,86:9268-9272,1989;"AbM
使用术语“Fc区”以定义免疫球蛋白重链的C-末端区域,其可以通过用木瓜蛋白酶消化完整抗体生成。Fc区可以是天然序列Fc区或变体Fc区。免疫球蛋白的Fc区通常包含两个恒定结构域,CH2结构域和CH3结构域,并且任选地包含CH4结构域。抗体的Fc部分介导几个重要的效应物功能,例如细胞因子诱导、ADCC、吞噬作用、补体依赖性细胞毒性(CDC)和抗体与抗原-抗体复合物的半衰期/清除率(例如,新生的FcR(FcRn)在内体(endosome)中的酸性pH与IgG的Fc区结合并且保护IgG免受降解,从而对IgG的长血清半衰期作出贡献)。替换Fc部分中的氨基酸残基以改变抗体效应物功能是本领域中已知的(参见例如Winter等人,美国专利第5,648,260号和第5,624,821号)。
抗体作为完整的免疫球蛋白或作为许多良好表征的片段存在。这样的片段包括与靶抗原结合的Fab片段、Fab’片段、Fab
木瓜蛋白酶消化抗体产生两个相同的被称为“Fab”片段的抗原结合片段,每个片段具有单个抗原结合位点。“Fab片段”包含一条轻链和一条重链的CH1和可变区。Fab分子的重链不能与另一条重链分子形成二硫键。“Fab’片段”包含一条轻链和一条重链的一部分,所述重链的一部分包含VH结构域和CH1结构域并且还包含CH1和CH2结构域之间的区域,使得链间二硫键可以在两个Fab’片段的两条重链之间形成,以形成F(ab’)
胃蛋白酶处理抗体产生具有两个抗原结合位点并且仍然能够交联抗原的F(ab’)
“Fv区”包含来自重链和轻链二者的可变区,但缺乏恒定区。
“单链抗体”是其中重链可变区和轻链可变区已经通过柔性接头连接以形成单个多肽链的Fv分子,所述多肽链形成抗原结合区。单链抗体在国际专利申请公布第WO 88/01649号、美国专利第4,946,778号和第5,260,203号中详细讨论,三篇文献的公开内容通过引用并入。
如本文使用的术语“抗原结合片段”和“抗原结合蛋白”意指与特定靶抗原结合的任何蛋白。“抗原结合片段”包括但不限于抗体及其结合部分,诸如免疫学上有功能的片段。抗体的示例性抗原结合片段是一个或更多个重链CDR和/或一个或更多个轻链CDR,或重链可变区和/或轻链可变区。
如本文使用的,术语抗体或免疫球蛋白链(重链或轻链)抗原结合蛋白的“免疫学上有功能的片段”(或简称“片段”)是一种抗原结合蛋白,其包含缺乏在全长链中存在的至少一些氨基酸但仍能够与抗原特异性地结合的抗体的一部分(无论该部分是如何获得或合成的)。这样的片段是生物学上有活性的,因为它们与靶抗原结合并且可以与其他抗原结合蛋白(包括完整抗体)竞争结合给定表位。在一些实施方案中,片段是中和片段。在一方面,这样的片段将保留在全长轻链或重链中存在的至少一个CDR,并且在一些实施方案中,将包含单条重链和/或轻链或其一部分。这些生物学上有活性的片段可以通过重组DNA技术产生,或可以通过抗原结合蛋白(包括完整抗体)的酶促裂解或化学裂解产生。免疫学上有功能的免疫球蛋白片段包括但不限于Fab、双抗体、Fab’、F(ab’)
双抗体是包含两条多肽链的二价抗体,其中每条多肽链包含通过接头连接的VH区和VL区,所述接头太短以至于不允许同一条链上的两个区之间配对,从而允许每个区与另一条多肽链上的互补区配对(参见例如Holliger等人,Proc.Natl.Acad.Sci.USA,90:6444-48,1993;和Poljak等人,Structure,2:1121-23,1994)。如果双抗体的两条多肽链是相同的,那么由它们的配对产生的双抗体将具有两个相同的抗原结合位点。具有不同序列的多肽链可以用于制备具有两个不同的抗原结合位点的双抗体。相似地,三抗体和四抗体分别是包含三条和四条多肽链并且分别形成可以是相同的或不同的三个和四个抗原结合位点的抗体。
双特异性抗体或片段可以具有几种构型。例如,双特异性抗体可以与单个抗体(或抗体片段)相似,但具有两个不同的抗原结合位点(可变区)。在多种实施方案中,双特异性抗体可以通过化学技术(Kranz等人,Proc.Natl.Acad.Sci.USA,78:5807,1981);通过“多瘤(polydoma)”技术(参见例如美国专利第4,474,893号);或者通过重组DNA技术来产生。在多种实施方案中,本公开内容的双特异性抗体可以具有对至少两种不同的表位(其中至少一种是肿瘤相关的抗原)的结合特异性。在多种实施方案中,抗体和片段还可以是异种抗体(heteroantibody)。异种抗体是连接在一起的两种或更多种抗体或抗原结合片段(例如,Fab),每种抗体或片段具有不同的特异性。
如本文使用的术语“单克隆抗体”是指从基本上同质的抗体的群中获得的抗体,即除了可能以少量存在的可能天然存在的突变之外构成该群的个体抗体是相同的。单克隆抗体是高度特异性的,针对单一抗原。此外,与通常包括针对不同的决定簇(表位)的不同的抗体的多克隆抗体制剂不同,每种单克隆抗体针对在抗原上的单个决定簇。修饰语“单克隆”不应被解释为需要通过任何特定方法产生抗体。
如本文使用的术语“嵌合抗体”是指具有来自一个物种(诸如人类)的框架残基和来自另一个物种的CDR(其通常地赋予抗原结合)的抗体,诸如与靶向的抗原特异性地结合的鼠抗体。
如本文使用的,术语“人类抗体”意图包括具有来源于人类种系免疫球蛋白序列的可变区和恒定区的抗体。本公开内容的人类抗体可以包括未被人类种系免疫球蛋白序列编码的氨基酸残基(例如,通过体外随机突变或位点特异性诱变或通过体内体细胞突变引入的突变),所述氨基酸残基例如在CDR中并且特别是在CDR3中。然而,如本文使用的术语“人类抗体”不意图包括其中来源于另一个哺乳动物物种(诸如小鼠)的种系的CDR序列已经被接枝到人类框架序列上的抗体。
如本文使用的术语“人源化抗体”是指包含人源化轻链和人源化重链免疫球蛋白的抗体。人源化抗体与提供CDR的供体抗体结合相同的抗原。人源化免疫球蛋白或抗体的受体框架可以具有通过取自供体框架的氨基酸的有限数目的取代。人源化抗体或其他单克隆抗体可以具有另外的保守氨基酸取代,这些另外的保守氨基酸取代对抗原结合或其他免疫球蛋白功能基本上没有影响。
如本文使用的,术语“重组人类抗体”意图包括通过重组手段制备、表达、产生或分离的所有人类抗体,诸如使用转染到宿主细胞中的重组表达载体表达的抗体;从重组、组合的人类抗体文库分离的抗体;从对于人类免疫球蛋白基因而言是转基因的动物(例如小鼠)分离的抗体;或通过包括将人类免疫球蛋白基因序列剪接至其他DNA序列的任何其他手段制备、表达、产生或分离的抗体。这样的重组人类抗体具有来源于人类种系免疫球蛋白序列的可变区和恒定区。然而,在多种实施方案中,这样的重组人类抗体经历体外诱变(或,当使用人类Ig序列的转基因动物时,则经历体内体细胞诱变),并且因此重组抗体的VH和VL区的氨基酸序列是这样的序列,所述序列尽管来源于人类种系VH和VL序列并且与人类种系VH和VL序列相关,但可以不天然地存在于体内人类抗体种系库(repertoire)中。所有这类重组手段是本领域普通技术人员熟知的。
如本文使用的术语“表位”包括能够与免疫球蛋白或T细胞受体特异性结合或以其他方式与分子相互作用的任何蛋白决定簇。表位决定簇通常由化学活性表面分组的分子(chemically active surface groupings of molecules)组成,诸如氨基酸或碳水化合物或糖侧链,并且通常地具有特定的三维结构特征以及特定的电荷特征。表位可以是“线性的”或“构象的”。在线性表位中,蛋白和相互作用分子(诸如抗体)之间的所有相互作用的点都沿着蛋白的一级氨基酸序列线性地存在。在构象表位中,相互作用的点跨越蛋白上彼此分离的氨基酸残基存在。一旦确定了抗原上的期望的表位,那么生成针对该表位的抗体则是可能的,例如,使用本公开内容中描述的技术。可选地,在发现过程期间,抗体的生成和表征可以阐明关于期望的表位的信息。然后根据该信息,竞争性地筛选结合相同表位的抗体则是可能的。实现这一点的方法是进行交叉竞争(cross-competition)研究,以找到彼此竞争性地结合的抗体,例如竞争结合抗原的抗体。
如果抗原结合蛋白(包括抗体)以如通过解离常数(K
如本文使用的术语“表面等离子共振(surface plasmon resonance)”是指一种光学现象,其允许通过检测在生物传感器基质中的蛋白浓度的改变来分析实时生物特异性相互作用,例如使用BIACORE
如本文使用的术语“免疫原性”是指当被施用至接受者时,抗体或抗原结合片段引发免疫应答(体液应答或细胞应答)的能力,并且包括例如人类抗小鼠抗体(HAMA)应答。当来自受试者的T细胞对施用的抗体产生免疫应答时,启动了HAMA应答。然后,T细胞招募B细胞以生成特异性“抗抗体(anti-antibody)”抗体。
如本文使用的术语“免疫细胞”意指参与调控针对抗原(例如,自身抗原)的免疫应答的造血谱系的任何细胞。在多种实施方案中,免疫细胞是例如T细胞、B细胞、树突细胞、单核细胞、自然杀伤细胞、巨噬细胞、朗氏细胞或Kuffer细胞。
术语“多肽”、“肽”和“蛋白”在本文中可互换使用,以指氨基酸残基的聚合物。在多种实施方案中,“肽”、“多肽”和“蛋白”是氨基酸的α碳通过肽键连接的氨基酸的链。因此在链的一个末端(氨基末端)处的末端氨基酸具有游离氨基基团,而在链的另一个末端(羧基末端)处的末端氨基酸具有游离羧基基团。如本文使用的,术语“氨基末端”(缩写为N-末端)是指在肽的氨基末端处的氨基酸上的游离α-氨基基团,或指在该肽中的任何其他位置处的氨基酸的α-氨基基团(当参与肽键时为亚氨基基团)。相似地,术语“羧基末端”是指在肽的羧基末端上的游离羧基基团,或在该肽中的任何其他位置处的氨基酸的羧基基团。肽还包括基本上任何多氨基酸,包括但不限于肽模拟物(peptide mimetic)诸如通过醚键而非酰胺键连接的氨基酸。
如本文使用的术语“重组多肽”意图包括所有多肽,包括通过重组手段制备、表达、产生、来源于重组手段或通过重组手段分离的融合分子,诸如使用转染到宿主细胞中的重组表达载体表达的多肽。
本公开内容的多肽包括以任何方式和出于任何原因已经被修饰的多肽,例如,以:(1)降低对蛋白水解的易感性、(2)降低对氧化的易感性、(3)改变用于形成蛋白复合物的结合亲和力、(4)改变结合亲和力,和(5)赋予或修饰其他物理化学或功能特性。例如,单个氨基酸取代或多于一个氨基酸取代(例如,保守氨基酸取代)可以在天然存在的序列中进行(例如,在形成分子间接触的一个或更多个结构域以外的一部分多肽中进行)。“保守氨基酸取代”是指在多肽中氨基酸被功能上相似的氨基酸取代。以下六组各自包含彼此为保守取代的氨基酸:
丙氨酸(A)、丝氨酸(S)和苏氨酸(T)
天冬氨酸(D)和谷氨酸(E)
天冬酰胺(N)和谷氨酰胺(Q)
精氨酸(R)和赖氨酸(K)
异亮氨酸(I)、亮氨酸(L)、甲硫氨酸(M)和缬氨酸(V)
苯丙氨酸(F)、酪氨酸(Y)和色氨酸(W)。
“非保守氨基酸取代”是指这些类别之一的成员取代为来自另一个类别的成员。在进行这样的改变中,根据多种实施方案,可以考虑氨基酸的亲水指数(hydropathicindex)。基于氨基酸的疏水性和电荷特征,每种氨基酸已经被指定了亲水指数。它们是:异亮氨酸(+4.5);缬氨酸(+4.2);亮氨酸(+3.8);苯丙氨酸(+2.8);半胱氨酸/胱氨酸(+2.5);甲硫氨酸(+1.9);丙氨酸(+1.8);甘氨酸(-0.4);苏氨酸(-0.7);丝氨酸(-0.8);色氨酸(-0.9);酪氨酸(-1.3);脯氨酸(-1.6);组氨酸(-3.2);谷氨酸(-3.5);谷氨酰胺(-3.5);天冬氨酸(-3.5);天冬酰胺(-3.5);赖氨酸(-3.9)和精氨酸(-4.5)。
本领域理解亲水氨基酸指数在赋予蛋白的相互作用的生物学功能中的重要性(参见例如Kyte等人,1982,J.Mol.Biol.157:105-131)。已知某些氨基酸可以被具有相似的亲水指数或评分的其他氨基酸取代,并且仍然保留相似的生物学活性。在基于亲水指数进行改变中,在多种实施方案中,包括了其亲水指数在±2内的氨基酸的取代。在多种实施方案中,包括在±1内的那些,并且在多种实施方案中,包括在±0.5内的那些。
本领域还理解,可以基于亲水性有效地进行相似的氨基酸的取代,特别是在从而产生的生物学上有功能的蛋白或肽被意图用于在如本文公开的免疫学实施方案中使用的情况中。在多种实施方案中,蛋白的最大局部平均亲水性(如由其相邻的氨基酸的亲水性决定的)与其免疫原性和抗原性,即,与蛋白的生物学特性相关。
以下亲水性值已经被指定至这些氨基酸残基:精氨酸(+3.0);赖氨酸(+3.0);天冬氨酸(+3.0.+-.1);谷氨酸(+3.0.+-.1);丝氨酸(+0.3);天冬酰胺(+0.2);谷氨酰胺(+0.2);甘氨酸(0);苏氨酸(-0.4);脯氨酸(-0.5.+-.1);丙氨酸(-0.5);组氨酸(-0.5);半胱氨酸(-1.0);甲硫氨酸(-1.3);缬氨酸(-1.5);亮氨酸(-1.8);异亮氨酸(-1.8);酪氨酸(-2.3);苯丙氨酸(-2.5)和色氨酸(-3.4)。在基于相似的亲水性值进行改变中,在多种实施方案中,包括其亲水性值在±2内的氨基酸的取代,在多种实施方案中,包括在±1内的那些,并且在多种实施方案中,包括在±0.5内的那些。示例性氨基酸取代在表1中列出。
如本文使用的术语“多肽片段”和“截短的多肽”是指如与对应的全长蛋白相比具有氨基末端缺失和/或羧基末端缺失的多肽。在多种实施方案中,片段的长度可以是例如至少5个、至少10个、至少25个、至少50个、至少100个、至少150个、至少200个、至少250个、至少300个、至少350个、至少400个、至少450个、至少500个、至少600个、至少700个、至少800个、至少900个或至少1000个氨基酸。在多种实施方案中,片段的长度还可以是例如至多1000个、至多900个、至多800个、至多700个、至多600个、至多500个、至多450个、至多400个、至多350个、至多300个、至多250个、至多200个、至多150个、至多100个、至多50个、至多25个、至多10个或至多5个氨基酸。片段还可以在其任一个或两个末端处包含一个或更多个另外的氨基酸,例如,来自不同的天然存在的蛋白的氨基酸的序列(例如,Fc或亮氨酸拉链结构域)或人工氨基酸序列(例如,人工接头序列)。
如本文使用的术语“多肽变体”和“多肽突变体”是指包含这样的氨基酸序列的多肽,在所述氨基酸序列中,相对于另一个多肽序列,一个或更多个氨基酸残基被插入到该氨基酸序列中、从该氨基酸序列缺失和/或被取代到该氨基酸序列中。在多种实施方案中,待插入、缺失或取代的氨基酸残基的数目可以是例如至少1个、至少2个、至少3个、至少4个、至少5个、至少10个、至少25个、至少50个、至少75个、至少100个、至少125个、至少150个、至少175个、至少200个、至少225个、至少250个、至少275个、至少300个、至少350个、至少400个、至少450个或至少500个氨基酸的长度。本公开内容的变体包括融合蛋白。
多肽的“衍生物”是已经被化学修饰的多肽,所述化学修饰例如缀合至另一个化学部分诸如例如聚乙二醇、白蛋白(例如,人血清白蛋白),磷酸化和糖基化。
术语“%序列同一性”与术语“%同一性”在本文中可互换使用并且是指当使用序列比对程序比对时,在两个或更多个肽序列之间的氨基酸序列同一性的水平或在两个或更多个核苷酸序列之间的核苷酸序列同一性的水平。例如,如本文使用的,80%同一性与通过定义的算法确定的80%序列同一性意指相同的事物,并且意指给定的序列与另一种长度的另一个序列至少80%相同。在多种实施方案中,%同一性选自,例如,与给定的序列至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少99%或更大的序列同一性。在多种实施方案中,%同一性在例如约60%至约70%、约70%至约80%、约80%至约85%、约85%至约90%、约90%至约95%、或约95%至约99%的范围内。
术语“%序列同源性”与术语“%同源性”在本文中可互换使用并且是指当使用序列比对程序比对时,在两个或更多个肽序列之间的氨基酸序列同源性的水平或在两个或更多个核苷酸序列之间的核苷酸序列同源性的水平。例如,如本文使用的,80%同源性与通过定义的算法确定的80%序列同源性意指相同的事物,并且因此给定的序列的同源物具有相对于给定的序列的长度大于80%的序列同源性。在多种实施方案中,%同源性选自例如与给定的序列至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少99%或更大的序列同源性。在多种实施方案中,%同源性在例如约60%至约70%、约70%至约80%、约80%至约85%、约85%至约90%、约90%至约95%、或约95%至约99%的范围内。
可以用于确定两个序列之间的同一性的示例性计算机程序包括但不限于在互联网在NCBI网站上公开地可得的一套BLAST程序,例如BLASTN、BLASTX和TBLASTX、BLASTP和TBLASTN。还参见Altschul等人,J.Mol.Biol.215:403-10,1990(特别参考公开的默认设置,即参数w=4、t=17)和Altschul等人,Nucleic Acids Res.,25:3389-3402,1997。当相对于GenBank蛋白序列和其他公开数据库中的氨基酸序列评价给定的氨基酸序列时,通常使用BLASTP程序进行序列搜索。BLASTX程序优选用于针对在GenBank蛋白序列和其他公开数据库中的氨基酸序列搜索在所有阅读框中已经被翻译的核酸序列。使用开放空位(gap)罚分为11.0和延伸空位罚分为1.0的默认参数并且使用BLOSUM-62矩阵运行BLASTP和BLASTX二者。参见同上。
除了计算序列同一性百分比以外,BLAST算法还进行两个序列之间的相似性的统计分析(参见例如Karlin&Altschul,Proc.Nat'l.Acad.Sci.USA,90:5873-5787,1993)。由BLAST算法提供的相似性的一个量度是最小总概率(P(N)),所述最小总概率提供在两个核苷酸序列或氨基酸序列之间的匹配将偶然发生的概率的指示。例如,如果在测试核酸与参考核酸的比较中,最小总概率为例如小于约0.1、小于约0.01或小于约0.001,则该核酸被认为与参考序列相似。
在多肽序列的上下文中,术语“基本相似性(substantial similarity)”或“基本上相似(substantially similar)”指示多肽区域具有与参考序列至少70%、通常至少80%、更通常至少85%、或至少90%或至少95%序列相似性的序列。例如,多肽与第二多肽基本上相似,例如,其中两个肽的差别在于一个或更多个保守取代。
“多核苷酸”是指包含核苷酸单元的聚合物。多核苷酸包括天然存在的核酸,诸如脱氧核糖核酸(“DNA”)和核糖核酸(“RNA”)以及核酸类似物。核酸类似物包括这样的类似物,所述类似物包含非天然地存在的碱基、以除天然存在的磷酸二酯键以外的连接与其他核苷酸衔接(engage)的核苷酸、或包含通过除了磷酸二酯键以外的连接附接的碱基的核苷酸。因此,核苷酸类似物包括例如并且不限于硫代磷酸酯、二硫代磷酸酯、磷酸三酯(phosphorotriester)、氨基磷酸酯(phosphoramidate)、硼烷磷酸酯(boranophosphate)、甲基膦酸酯、手性甲基膦酸酯、2-O-甲基核糖核苷酸、肽核酸(PNA)等。这类多核苷酸可以例如使用自动化的DNA合成仪来合成。术语“核酸”通常是指大的多核苷酸。术语“寡核苷酸”通常是指短的多核苷酸,通常不大于约50个核苷酸。将理解的是,当核苷酸序列由DNA序列(即,A、T、G、C)表示时,这还包括其中“U”代替“T”的RNA序列(即,A、U、G、C)。
本文使用常规符号描述多核苷酸序列:单链多核苷酸序列的左手末端为5’-末端;双链多核苷酸序列的左手方向被称作5’-方向。向新生RNA转录物添加核苷酸的5’至3’方向被称作转录方向。具有与mRNA相同的序列的DNA链被称作“编码链”;在具有与从该DNA转录的mRNA相同的序列的DNA链上并且位于RNA转录物的5’-末端的5’的序列被称作“上游序列”;在具有与RNA相同的序列的DNA链上并且在编码RNA转录物的3’-末端的3’的序列被称作“下游序列”。
“互补的”是指两个多核苷酸的相互作用表面的拓扑相容性或匹配在一起。因此,这两个分子可以被描述为互补的,并且更进一步地,接触表面特征是彼此互补的。如果第一多核苷酸的核苷酸序列与第二多核苷酸的多核苷酸结合配偶体的核苷酸序列基本上相同,或如果第一多核苷酸可以与第二多核苷酸在严格的杂交条件下杂交,则第一多核苷酸是与第二多核苷酸互补的。
“与...特异性杂交”或“特异性杂交”或“与...选择性杂交”是指当序列存在于复杂混合物(例如,总细胞)DNA或RNA中时,核酸分子优先与特定核苷酸序列在严格的条件下的结合、双链体化或杂交。术语“严格的条件”是指在该条件下探针将优先与其靶子序列杂交,并且在较小程度上与其他序列杂交或根本不与其他序列杂交的条件。在核酸杂交实验诸如DNA杂交和RNA杂交的背景中,“严格的杂交”和“严格的杂交洗涤条件”是序列依赖性的,并且在不同的环境参数下是不同的。核酸杂交的广泛指导见于Tijssen,1993,Laboratory Techniques in Biochemistry and Molecular Biology--Hybridizationwith Nucleic Acid Probes,第I部分,第2章“Overview of principles ofhybridization and the strategy of nucleic acid probe assays”,Elsevier,N.Y.;Sambrook等人,2001,Molecular Cloning:A Laboratory Manual,Cold Spring HarborLaboratory,3.sup.rd.ed,NY;以及Ausubel等人,编著,现行版,Current Protocols inMolecular Biology,Greene Publishing Associates and Wiley Interscience,NY。
通常,高度严格的杂交和洗涤条件被选择为比特定序列在定义的离子强度和pH的热解链点(Tm)低约5℃。Tm是50%的靶序列与完全匹配的探针杂交的温度(在定义的离子强度和pH下)。非常严格的条件被选择为等于特定探针的Tm。在DNA印迹或RNA印迹中的过滤器上,用于具有多于约100个互补残基的互补核酸的杂交的严格的杂交条件的实例是在42℃,50%福尔马林与1mg肝素,其中杂交被过夜进行。高度严格的洗涤条件的实例是在72℃,0.15M NaCl,持续约15分钟。严格的洗涤条件的实例是在65℃,0.2×SSC洗涤,持续15分钟。对于SSC缓冲液的描述,参见Sambrook等人。高严格度洗涤之前可以进行低严格度洗涤以去除背景探针信号。对于例如多于约100个核苷酸的双链体的示例性中等严格度洗涤是在45℃,1×SSC,持续15分钟。对于例如多于约100个核苷酸的双链体的示例性低严格度洗涤是在40℃,4-6×SSC,持续15分钟。一般而言,比起在特定杂交测定中对于不相关的探针观察到的2×(或更高)的信噪比指示出检测到特异性杂交。
“引物”是指能够与指定的多核苷酸模板特异性地杂交并且提供用于互补的多核苷酸的合成的起始点的多核苷酸。当多核苷酸引物被放置在其中合成被诱导的条件下,即在核苷酸、互补的多核苷酸模板和用于聚合的剂诸如DNA聚合酶的存在下,发生这样的合成。引物通常是单链的,但可以是双链的。引物通常是脱氧核糖核酸,但许多种合成的和天然存在的引物对于许多应用是有用的。引物与模板互补,其被设计成与模板杂交以用作合成起始的位点,但不需要反映模板的精确序列。在这样的情况中,引物与模板的特异性杂交取决于杂交条件的严格度。引物可以用例如,显色的、放射性的或荧光部分标记并且用作可检测的部分。
当在提及多核苷酸中使用时,“探针”是指能够与指定的另一个多核苷酸序列特异性地杂交的多核苷酸。探针与靶互补多核苷酸特异性地杂交,但不需要反映模板的精确互补序列。在这样的情况中,探针与靶的特异性杂交取决于杂交条件的严格度。探针可以用例如,显色的、放射性的或荧光部分标记并且用作可检测的部分。在其中探针提供互补多核苷酸的合成的起始点的实例中,探针也可以是引物。
“载体”是可以被用于将与其连接的另一个核酸引入到细胞中的多核苷酸。一种类型的载体是“质粒”,其是指可以将另外的核酸区段连接到其中的线性或环状双链DNA分子。另一种类型的载体是病毒载体(例如,复制缺陷型逆转录病毒、腺病毒和腺病毒相关病毒),其中另外的DNA区段可以被引入到病毒基因组中。某些载体能够在引入了它们的宿主细胞中自主复制(例如,包含细菌复制起点的细菌载体和附加型哺乳动物载体(episomalmammalian vector))。其他载体(例如,非附加型哺乳动物载体)在引入到宿主细胞中后被整合到宿主细胞的基因组中,并且从而与宿主基因组一起复制。“表达载体”是可以指导选择的多核苷酸的表达的一种类型的载体。
“调控序列”是影响与其可操作地连接的核酸的表达(例如,表达的水平、时机或位置)的核酸。调控序列可以例如直接对被调控的核酸发挥其作用,或通过一种或更多种其他分子(例如,与调控序列和/或核酸结合的多肽)的作用发挥其作用。调控序列的实例包括启动子、增强子及其他表达控制元件(例如多腺苷酸化信号)。调控序列的其他实例在例如Goeddel,1990,Gene Expression Technology:Methods in Enzymology 185,AcademicPress,San Diego,Calif.和Baron等人,1995,Nucleic Acids Res.23:3605-06中描述。如果调控序列影响核苷酸序列的表达(例如,表达的水平、时机或位置),则核苷酸序列与调控序列“可操作地连接”。
“宿主细胞”是可以被用于表达本公开内容的多核苷酸的细胞。宿主细胞可以是原核生物,例如大肠杆菌(E.coli),或者宿主细胞可以是真核生物,例如单细胞真核生物(例如,酵母或其他真菌)、植物细胞(例如,烟草或番茄植物细胞)、动物细胞(例如,人类细胞、猴细胞、仓鼠细胞、大鼠细胞、小鼠细胞或昆虫细胞)或杂交瘤。通常,宿主细胞是可以用编码多肽的核酸转化或转染的培养的细胞,所述核酸然后可以在宿主细胞中被表达。短语“重组宿主细胞”可以被用于表示已经用待表达的核酸转化或转染的宿主细胞。宿主细胞还可以是包含核酸但不以期望的水平表达该核酸的细胞,除非调控序列被引入到宿主细胞中,使得调控序列变成与该核酸可操作地连接。将理解,术语宿主细胞不仅是指特定的受试者细胞,而且指这样的细胞的子代或潜在子代。因为某些修饰可以由于,例如突变或环境影响而在随后世代中发生,这样的子代实际上可以与亲本细胞不相同,但仍然被包括在如本文使用的该术语的范围内。
术语“分离的分子”(其中分子是例如多肽或多核苷酸)是这样的分子:该分子凭借其起源或衍生的来源(1)不与在其天然状态中伴随其的、天然地缔合的组分缔合,(2)基本上不含来自相同物种的其他分子,(3)由来自不同物种的细胞表达,或(4)不存在于自然界中。因此,化学合成的、或在与其天然起源的细胞不同的细胞系统中表达的分子将是与其天然缔合的组分“分离”的。也可以通过使用本领域熟知的纯化技术分离使分子基本上不含天然缔合的组分。分子纯度或同质性可以通过本领域中熟知的许多手段来测定。例如,多肽样品的纯度可以使用本领域中熟知的技术使用聚丙烯酰胺凝胶电泳和对凝胶染色以使多肽可视化来测定。出于某些目的,可以通过使用HPLC或本领域中熟知的用于纯化的其他手段来提供更高的分辨率。
当样品的至少约60%至75%表现为单一种类的多肽时,蛋白或多肽是“基本上纯的”、“基本上同质的”或“基本上纯化的”。多肽或蛋白可以是单体的或多体的(multimeric)。基本上纯的多肽或蛋白将通常包含约50%、60%、70%、80%或90%W/W的蛋白样品,更通常约95%,并且优选地将超过99%纯。蛋白纯度或同质性可以通过本领域中熟知的许多手段来指示,所述手段诸如蛋白样品的聚丙烯酰胺凝胶电泳,随后是用本领域中熟知的染色剂对凝胶进行染色后使单个多肽条带可视化。出于某些目的,可以通过使用HPLC或本领域中熟知的用于纯化的其他手段来提供更高的分辨率。
“接头”是指共价地或通过离子、范德华力或氢键连接两个其他分子的分子,例如在5’末端处与一个互补的序列杂交并且在3’末端处与另一个互补的序列杂交,因此连接两个非互补的序列的核酸分子。“可裂解的接头”是指可以被降解或以其他方式切断以使通过该可裂解的接头连接的两个组分分离的接头。可裂解的接头通常被酶,通常是肽酶、蛋白酶、核酸酶、脂肪酶等裂解。可裂解的接头还可以通过环境因素,诸如例如温度、pH、盐浓度等的改变来裂解。
如本文使用的术语“标记物(label)”或“标记的(labeled)”是指在抗体中掺入另一种分子。在一种实施方案中,标记物是可检测的标志物,例如掺入放射性标记的氨基酸或附接至可以通过标记的亲和素检测的生物素基部分的多肽(例如,包含荧光标志物的链霉亲和素或可以通过光学方法或量热法检测的酶活性)。在另一种实施方案中,标记物或标志物可以是治疗性的,例如药物缀合物或毒素。标记多肽和糖蛋白的多种方法是本领域中已知的并且可以被使用。用于多肽的标记物的实例包括但不限于以下:放射性同位素或放射性核素(例如
如本文使用的,术语“免疫疗法”是指包括但不限于以下的癌症治疗:使用针对特定肿瘤抗原的消耗性抗体(depleting antibody)的治疗;使用抗体-药物缀合物的治疗;使用针对共刺激或共抑制分子(免疫检查点)的激动抗体、拮抗抗体或阻断抗体的治疗,所述共刺激或共抑制分子(免疫检查点)诸如IL-17A、PD-1、PD-L1、OX-40、CD137、GITR、LAG3、TIM-3和VISTA;使用双特异性T细胞接合抗体
如本文使用的术语“免疫缀合物”或“融合蛋白”是指包含直接地或间接地与效应物分子缀合(或连接)的抗体或其抗原结合片段的分子。效应物分子可以是可检测的标记物、免疫毒素、细胞因子、趋化因子、治疗剂或化学治疗剂。抗体或其抗原结合片段可以经由肽接头与效应物分子缀合。免疫缀合物和/或融合蛋白保留抗体或抗原结合片段的免疫反应性,例如抗体或抗原结合片段在缀合后具有与缀合前近似地相同的或仅略微降低的与抗原结合的能力。如本文使用的,免疫缀合物也可以被称作抗体药物缀合物(ADC)。因为免疫缀合物和/或融合蛋白最初从具有单独的功能的两种分子制备,诸如抗体和效应物分子,它们有时也被称作“嵌合分子”。
“药物组合物”是指适合于动物中的药学用途的组合物。药物组合物包含药理学有效量的活性剂和药学上可接受的载体。“药理学有效量”是指有效产生预期药理学结果的剂的量。“药学上可接受的载体”是指任何标准的药物载体、媒介物、缓冲剂和赋形剂,诸如磷酸盐缓冲盐水溶液、5%右旋糖的水性溶液,和乳液,诸如油/水乳液或水/油乳液,以及多种类型的润湿剂和/或佐剂。合适的药学载体和制剂在Remington的PharmaceuticalSciences,第21版2005,Mack Publishing Co,Easton中描述。“药学上可接受的盐”是可以被配制成用于药学用途的化合物的盐,包括例如金属盐(钠、钾、镁、钙等)和氨的盐或有机胺的盐。
术语“治疗(treat)”、“治疗(treating)”和“治疗(treatment)”是指减轻或消除生物学紊乱和/或其至少一个伴随症状的方法。如本文使用的,“减轻”疾病、紊乱或状况意指降低该疾病、紊乱或状况的症状的严重性和/或发生频率。如本文使用的,“治疗(treatment)”是用于获得有益的或期望的临床结果的方法。出于本发明的目的,有益的或期望的临床结果包括但不限于以下任何一个或更多个:减轻一种或更多种症状、减轻疾病的程度、预防或延迟疾病的扩散(例如转移,例如转移至肺或至淋巴结)、预防或延迟疾病的复发、延迟或减缓疾病进展、改善疾病状态和缓解(无论是部分的还是全部的)。“治疗(treatment)”还包括降低增生性疾病的病理学后果。本发明的方法考虑治疗的这些方面的任何一个或更多个。
如本文使用的术语“有效量”或“治疗有效量”是指足以治疗特定紊乱、状况或疾病诸如改善、缓和、减轻和/或延迟其一种或更多种症状的化合物或组合物的量。在提及癌症或其他不期望的细胞增殖中,有效量包含足以(i)减少癌细胞的数目;(ii)减小肿瘤尺寸;(iii)在一定程度上抑制、延缓、减缓并且优选地停止癌细胞浸润到周围器官中;(iv)抑制(即,在一定程度上减缓,并且优选地停止)肿瘤转移;(v)抑制肿瘤生长;(vi)预防或延迟肿瘤的发生和/或复发;和/或(vii)在一定程度上缓解一种或更多种与癌症相关的症状的量。有效量可以以一次或更多次施用来施用。
“耐受性或难治性癌症”是指不响应于先前的抗癌疗法的肿瘤细胞或癌症,所述先前的抗癌疗法包括例如化学疗法、手术、放射疗法、干细胞移植和免疫疗法。肿瘤细胞可以在治疗的开始时是耐受性或难治性的,或者它们可以在治疗期间变成耐受性或难治性的。难治性肿瘤细胞包括在治疗的开始时不响应的肿瘤,或最初持续短的时间段作出响应但不能响应于治疗的肿瘤。难治性肿瘤细胞还包括响应于使用抗癌疗法的治疗但不能响应于随后几轮疗法的肿瘤。出于本发明的目的,难治性肿瘤细胞还包括通过使用抗癌疗法的治疗表现出被抑制但在治疗停止后长达5年,有时长达10年或更长时间而复发的肿瘤。抗癌疗法可以使用单独的化学治疗剂、单独的放射、单独的靶向疗法、单独的手术或其组合。为了便于描述而非限制性,将理解,难治性肿瘤细胞与耐受性肿瘤是可互换的。
将理解,本文描述的本发明的方面和实施方案包括“由所述方面和实施方案组成”和/或“基本上由所述方面和实施方案组成”。
本文中,提及“约”值或参数包括(并且描述)针对该值或参数本身的变化。例如,提及“约X”的描述包括对“X”的描述。
除非上下文另外明确指出,如本文和所附的权利要求中使用的单数形式“一种/一个”、“或”和“该”包含复数指代物。将理解,本文描述的本发明的方面和变化包括“由所述方面和变化组成”和/或“基本上由所述方面和变化组成”。
白细胞介素-17(IL-17)细胞因子家族由于其调节炎性应答的能力而被广泛认可。在六个IL-17家族成员中,IL-17A和IL-17F在淋巴细胞群体中是被最佳地理解的。IL-17A和IL-17F具有相似的表达模式,并作为配体同二聚体或异二聚体与二聚体IL-17RA-IL-17RC受体复合物结合,以在皮肤、肺和结肠的上皮和粘膜屏障处诱导宿主对细菌病原体的防御反应。白细胞介素-17A(IL-17A,也被称为细胞毒性T淋巴细胞相关抗原8(CTLA8))是一种CD4+T细胞来源的同二聚体细胞因子,促进诸如类风湿性关节炎、哮喘、多发性硬化、银屑病和移植物排斥的疾病中的炎症(Gaffen,Nat.Rev.Immunol.,9:556-567,2009)。鼠NIH3T3细胞表达IL-17A受体异二聚体(IL-17RA、IL-17RC),并且用IL-17A活化该受体刺激了IL-6在细胞培养基中累积。这种作用通过与TNFα的共处理而增强,并且已经示出鼠IL-17R可以被人类和小鼠IL-17A以基本上相等的效力活化(Yao,Z.,等人,Immunity,1995.3(6):p.811-21,1995;Gaffen,S.L.,Nature reviews.Immunology,9(8):p.556,2009)。这种人类交叉反应性使得能够利用NIH3T3细胞来测定抗人类IL-17A抗体的抑制作用。
如本文使用的人类IL-17A可以包含NCBI参考序列NP_002181.1中列出的氨基酸序列(SEQ ID NO:1):
在多种实施方案中,IL-17A多肽包含与SEQ ID NO:1的人类IL-17A序列共有例如至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、或至少99%的观察到的同源性(observed homology)的氨基酸序列。在一些实施方案中,IL-17A多肽变体具有SEQ ID NO:1的人类IL-17A的至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少1×、至少1.5×、至少2×、至少2.5×、或至少3×的活性。在本文中,IL-17A的多肽变体可以通过参考SEQ IDNO:1的223个氨基酸序列中的给定位置处存在的氨基酸残基的添加、缺失或取代来描述。因此,例如,术语“P21W”指SEQ ID NO:1中的位置21处的“P”(脯氨酸,以标准单字母代码)残基已经被“W”(色氨酸,以标准单字母代码)取代。
生成与人类IL-17A多肽结合的新型抗体的方法是本领域技术人员已知的。例如,用于生成与IL-17A多肽特异性地结合的单克隆抗体的方法可以包括向小鼠施用一定量的免疫原性组合物,所述免疫原性组合物包含有效刺激可检测的免疫应答的IL-17A多肽,从小鼠获得产生抗体的细胞(例如,来自脾的细胞)并且使产生抗体的细胞与骨髓瘤细胞融合以获得产生抗体的杂交瘤,以及测试产生抗体的杂交瘤以鉴定产生与IL-17A多肽特异性地结合的单克隆抗体的杂交瘤。获得后,杂交瘤可以在细胞培养物中繁殖,任选地在其中来源于杂交瘤的细胞产生与IL-17A多肽特异性地结合的单克隆抗体的培养条件中繁殖。单克隆抗体可以从细胞培养物纯化。然后,用于测试抗体:抗原相互作用以鉴定特别期望的抗体的多种不同的技术是可得的。
可以使用产生或分离具有必需的特异性的抗体的其他合适的方法,包括例如从文库选择重组抗体的方法,或依赖于对能够产生人类抗体的完整贮库(full repertoire)的转基因动物(例如小鼠)进行免疫接种的方法。参见例如,Jakobovits等人,Proc.Natl.Acad.Sci.USA,90:2551-2555,1993;Jakobovits等人,Nature,362:255-258,1993;Lonberg等人,美国专利第5,545,806号;Surani等人,美国专利第5,545,807号。
抗体可以以多种方式被工程化。它们可以被制备为单链抗体(包括小模块免疫药物(small modular immunopharmaceutical)或SMIPs
嵌合抗体可以通过本领域已知的重组DNA技术产生。例如,用限制酶消化编码鼠(或其他物种)单克隆抗体分子的Fc恒定区的基因,以去除编码鼠Fc的区域,并且取代为编码人类Fc恒定区的基因的等效部分(参见Robinson等人,国际专利公布PCT/US86/02269;Akira,等人,欧洲专利申请184,187;Taniguchi,M.,欧洲专利申请171,496;Morrison等人,欧洲专利申请173,494;Neuberger等人,国际申请WO 86/01533;Cabilly等人.美国专利第4,816,567号;Cabilly等人,欧洲专利申请125,023;Better等人,Science,240:1041-1043,1988;Liu等人,PNAS USA,84:3439-3443,1987;Liu等人,J.Immunol.139:3521-3526,1987;Sun等人,PNAS USA,84:214-218,1987;Nishimura等人,Canc.Res.47:999-1005,1987;Wood等人,Nature 314:446-449,1985;以及Shaw等人,J.Natl Cancer Inst.,80:1553-1559,1988)。
本领域中已经描述了用于使抗体人源化的方法。在实践中,人源化抗体通常是其中一些高变区残基和可能地一些框架区残基被来自啮齿动物抗体中的类似位点的残基取代的人类抗体。因此,这样的“人源化”抗体是嵌合抗体,其中基本上少于一个完整的人类可变区已经被来自非人类物种的对应的序列取代。在某种程度上,这可以与人源化技术和使用适当的文库的展示技术关联来实现。将理解,鼠抗体或来自其他物种的抗体可以使用本领域熟知的技术进行人源化或灵长类化(primatized)(参见例如Winter等人,ImmunolToday,14:43-46,1993;和Wright等人,Crit.Reviews in Immunol.,12125-168,1992)。感兴趣的抗体可以通过重组DNA技术来工程化,以用对应的人类序列取代CH1、CH2、CH3、铰链结构域和/或框架结构域(参见WO 92/02190和美国专利第5,530,101号、第5,585,089号、第5,693,761号、第5,693,792号、第5,714,350号和第5,777,085号)。此外,使用Ig cDNA用于构建嵌合免疫球蛋白基因是本领域中已知的(Liu等人,P.N.A.S.84:3439,1987;J.Immunol.139:3521,1987)。mRNA从杂交瘤或产生抗体的其他细胞分离并用于产生cDNA。感兴趣的cDNA可以使用特定引物通过聚合酶链式反应扩增(美国专利第4,683,195号和第4,683,202号)。可选地,制备并筛选文库以分离感兴趣的序列。编码抗体的可变区的DNA序列然后与人类恒定区序列融合。人类的恒定区基因的序列可以在Kabat等人(1991)Sequences of Proteins of Immunological Interest,N.I.H.公开号91-3242中发现。人类C区基因是从已知的克隆容易地可得的。同种型的选择将通过期望的效应物功能诸如补体固定(complement fixation)或抗体依赖性细胞毒性的活性来指导。在多种实施方案中,同种型选自由IgG1、IgG2、IgG3和IgG4组成的组。可以使用人类轻链恒定区κ或λ的任一个。嵌合的、人源化抗体然后通过常规方法表达。
Queen等人的美国专利第5,693,761号公开了对Winter等人对于使抗体人源化的改进,并且基于这样的前提:将亲合力(avidity)损失归因于人源化框架的结构基序方面的问题,其由于空间不相容性或其他化学不相容性,干扰CDR折叠成在小鼠抗体中发现的能够结合的构象。为了解决该问题,Queen教导了使用线性肽序列与待人源化的小鼠抗体的框架序列密切同源的人类框架序列。因此,Queen的方法关注于比较物种之间的框架序列。通常,将所有可得的人类可变区序列与特定小鼠序列进行比较,并计算在对应的框架残基之间的百分比同一性。选择具有最高百分比的人类可变区以提供用于人源化项目的框架序列。Queen还教导了,在人源化框架中保留对于支持能够结合的构象中的CDR至关重要的来自小鼠框架的某些氨基酸残基是重要的。从分子模型评价潜在的重要性。用于保留的候选残基通常是在线性序列中与CDR相邻或物理地在任何CDR残基的
在其他方法中,一旦获得低亲合力人源化构建体,特定框架氨基酸残基的重要性通过将单个残基恢复(reversion)至小鼠序列并测定抗原结合由实验确定,如由Riechmann等人,1988所描述的。用于鉴定框架序列中的重要氨基酸的另一个示例方法由Carter等人,美国专利第5,821,337号和Adair等人,美国专利第5,859,205号公开。这些参考文献公开了框架中特定Kabat残基位置,其在人源化抗体中可能需要用对应的小鼠氨基酸取代以保持亲合力。
被称作“框架改组(framework shuffling)”的另一种使抗体人源化的方法依赖于生成组合文库,所述组合文库具有符合读框地(in frame)融合至单个人类种系框架的池中的非人类CDR可变区(Dall’Acqua等人,Methods,36:43,2005)。然后,筛选文库以鉴定编码保留良好结合的人源化抗体的克隆。
在制备期望的人源化抗体中待使用的人类可变区(轻链和重链二者)的选择对降低抗原性是非常重要的。根据被称为“最佳拟合”的方法,针对已知的人类可变结构域序列的整个文库筛选啮齿动物抗体的可变区的序列。然后,接受最接近啮齿动物的序列的人类序列作为用于人源化抗体的人类框架区(框架区)(Sims等人,J.Immunol.,151:2296,1993;Chothia等人,J.Mol.Biol.,196:901,1987)。另一种方法使用来源于特定亚组的轻链可变区或重链可变区的所有人类抗体的共有序列的特定框架区。相同的框架可以被用于几种不同的人源化抗体(Carter等人,Proc.Natl.Acad.Sci.USA,89:4285,1992;Presta等人,J.Immunol.,151:2623,1993)。
取代到人类可变区中的非人类残基的选择可以被多种因素影响。这些因素包括例如氨基酸在特定位置中的稀有性、与CDR或抗原相互作用的可能性和参与轻链可变结构域界面和重链可变结构域界面之间的界面的可能性。(参见例如美国专利第5,693,761号、第6,632,927号和第6,639,055号)。分析这些因素的一种方法是通过使用非人类序列和人源化序列的三维模型。三维免疫球蛋白模型是通常可得的,并且是本领域技术人员熟悉的。说明和显示选择的候选免疫球蛋白序列的可能三维构象结构的计算机程序是可得的。对这些显示的检查允许分析残基在候选免疫球蛋白序列的功能中可能的作用,例如,分析影响候选免疫球蛋白与其抗原结合的能力的残基。以该方式,非人类残基可以被选择并且取代为人类可变区残基,以便于实现期望的抗体特征,诸如对一个或更多个靶抗原的增加的亲和力。
本领域中已经描述了用于制备完全人类抗体的方法。以举例的方式,用于产生抗IL-17A抗体或其抗原结合片段的方法包括以下步骤:在噬菌体上合成人类抗体的文库、用IL-17A或其抗体结合部分筛选文库、分离与IL-17A结合的噬菌体和从噬菌体获得抗体。以另一个实例的方式,用于制备用于在噬菌体展示技术中使用的抗体的文库的一种方法包括以下步骤:用IL-17A或其抗原性部分对包括人类免疫球蛋白基因座的非人动物进行免疫接种以产生免疫应答、从经免疫接种的动物提取产生抗体的细胞、从提取的细胞分离编码本发明的抗体的重链和轻链的RNA、逆转录RNA以产生cDNA、使用引物扩增cDNA、并且将cDNA插入到噬菌体展示载体中,使得抗体在噬菌体上表达。本发明的重组抗IL-17A抗体可以以该方式获得。
本发明的重组人类抗IL-17A抗体还可以通过筛选重组组合抗体文库来分离。优选地,文库是使用从B细胞分离的mRNA制备的人类VL和VH cDNA生成的scFv噬菌体展示文库。用于制备和筛选这类文库的方法是本领域已知的。用于生成噬菌体展示文库的试剂盒是商购可得的(例如,Pharmacia重组噬菌体抗体系统,目录号27-9400-01;和StratageneSurfZAP
人类抗体还通过用人类IgE抗原对非人类转基因动物进行免疫接种来产生,所述非人类转基因动物在其基因组中包含一些或所有人类免疫球蛋白重链和轻链基因座,例如XenoMouse
可以通过例如标准ELISA来测试本发明的抗体与IL-17A的结合。作为实例,将微量滴定板用在PBS中的纯化的IL-17A包被,并且然后用在PBS中的5%牛血清白蛋白封闭。将抗体的稀释物(例如,来自IL-17A免疫接种的小鼠的血浆的稀释物)添加至每个孔,并且在37℃孵育持续1-2小时。将板用PBS/Tween洗涤,并且然后用与碱性磷酸酶缀合的第二试剂(例如,对于人类抗体,山羊抗人类IgG Fc特异性多克隆试剂)在37℃孵育持续1小时。在洗涤后,将板用pNPP底物(1mg/ml)显色,并且在OD为405-650分析。优选地,产生最高滴度的小鼠将被用于融合。ELISA测定也可以用于筛选显示出与IL-17A免疫原呈阳性反应性的杂交瘤。将以高亲合力与IL-17A结合的杂交瘤亚克隆并进一步表征。可以从每个杂交瘤选择保留亲本细胞的反应性(通过ELISA)的一个克隆,用于制备储存在-140℃的5-10小瓶细胞库,并且用于抗体纯化。
为了确定选择的抗IL-17A单克隆抗体是否与独特的表位结合,可以使用商购可得的试剂(Pierce,Rockford,Ill.)将每种抗体生物素化。使用未标记的单克隆抗体和生物素化的单克隆抗体的竞争研究可以使用如上文描述的IL-17A包被的ELISA板进行。生物素化的mAb结合可以用链霉亲和素-碱性磷酸酶(strep-avidin-alkaline phosphatase)探针来检测。为了确定纯化的抗体的同种型,可以使用对特定同种型的抗体特异性的试剂进行同种型ELISA。例如,为了确定人类单克隆抗体的同种型,微量滴定板的孔可以用1μg/ml的抗人类免疫球蛋白在4℃包被过夜。在用1%BSA封闭后,将板与1μg/ml或更少的测试单克隆抗体或纯化的同种型对照在环境温度反应持续1小时至2小时。然后可以将孔与人类IgG1或人类IgM特异性碱性磷酸酶缀合的探针反应。将板如以上描述地显色和分析。
抗IL-17A人类IgG可以通过蛋白印迹进一步测试与IL-17A抗原的反应性。简而言之,可以制备IL-17A并且使IL-17A经历十二烷基硫酸钠聚丙烯酰胺凝胶电泳。在电泳后,将分离的抗原转移至硝酸纤维素膜,用10%胎牛血清封闭,并用待测试的单克隆抗体探测。人类IgG结合可以使用抗人类IgG碱性磷酸酶检测,并用BCIP/NBT底物片剂(BCIP/NBTsubstrate tablets)(Sigma Chem.Co.,St.Louis,Mo.)显色。
本发明提供了与IL-17A抗原特异性地结合的单克隆抗体及其抗原结合片段。
在本发明中还包括与本发明的抗IL-17A抗体结合相同的表位的抗体。为了确定抗体是否可以竞争结合与由本发明的抗IL-17A抗体结合的表位相同的表位,可以进行交叉阻断测定,例如竞争性ELISA测定。在示例性竞争性ELISA测定中,包被在微量滴定板的孔上的IL-17A与或不与候选竞争性抗体预孵育,并且然后添加本发明的生物素标记的抗IL-17A抗体。在孔中与IL-17A抗原结合的标记的抗IL-17A抗体的量使用亲和素-过氧化物酶缀合物和适当的底物测量。抗体可以用放射性标记物或荧光标记物或一些其他可检测且可测量的标记物标记。与抗原结合的标记的抗IL-17A抗体的量将具有与候选竞争性抗体(测试抗体)竞争结合相同的表位的能力的间接相关性,即测试抗体对相同的表位的亲和力越大,标记的抗体将越少地与抗原包被的孔结合。如果与不存在候选竞争性抗体时平行进行的对照相比,候选抗体可以阻断IL-17A抗体的结合至少20%,优选地至少20%-50%,甚至更优选地至少50%,则认为候选竞争性抗体是与本发明的抗IL-17A抗体基本上结合相同的表位的抗体或竞争结合相同的表位的抗体。将理解,可以进行该测定的变化形式以达到相同的定量的值。
如本文描述生成的6种鼠抗体4H11C7(还在下文中被称为“A1”)、8A5G4(还在下文中被称为“A2”)、22E2G4(还在下文中被称为“A3”)、23A4D8(还在下文中被称为“A4”)、24F11E4(还在下文中被称为“A5”)和26G11B11(还在下文中被称为“A6”)的重链CDR和轻链CDR的氨基酸序列在下表2中示出。
重链CDR
轻链CDR
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体4H11C7(“A1”),包含SEQ ID NO:30的重链可变区序列和SEQ ID NO:42的轻链可变区序列,其中SEQ ID NO:30的氨基酸1-19是前导序列:
其中SEQ ID NO:42的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:30中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:31具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:31为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:42中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:43具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:43为:
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体8A5G4(“A2”),包含SEQ ID NO:32的重链可变区序列和SEQ ID NO:44的轻链可变区序列,其中SEQ ID NO:32的氨基酸1-19是前导序列:
其中SEQ ID NO:44的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:32中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:33具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:33为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:44中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:45具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:45为:
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体22E2G4(“A3”),包含SEQ ID NO:34的重链可变区序列和SEQ ID NO:46的轻链可变区序列,其中SEQ ID NO:34的氨基酸1-19是前导序列:
其中SEQ ID NO:46的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:34中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:35具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:35为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:46中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:47具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:47为:
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体23A4D8(“A4”),包含SEQ ID NO:36的重链可变区序列和SEQ ID NO:48的轻链可变区序列,其中SEQ ID NO:36的氨基酸1-19是前导序列:
其中SEQ ID NO:48的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:36中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:37具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:37为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:48中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:49具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:49为:
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体24F11E4(“A5”),包含SEQ ID NO:38的重链可变区序列和SEQ ID NO:50的轻链可变区序列,其中SEQ ID NO:38的氨基酸1-19是前导序列:
其中SEQ ID NO:50的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:38中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:39具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:39为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:50中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:51具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:51为:
在本发明的多种实施方案中,抗体或抗原结合片段是鼠抗体26G11B11(“A6”),包含SEQ ID NO:40的重链可变区序列和SEQ ID NO:52的轻链可变区序列,其中SEQ ID NO:40的氨基酸1-19是前导序列:
其中SEQ ID NO:52的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含重链可变区,并且其中重链可变区包含与如SEQ ID NO:40中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:41具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:41为:
并且其中轻链包含轻链可变区,并且其中轻链可变区包含与如SEQ ID NO:52中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:53具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:53为:
在多种实施方案中,本发明的抗体包括与鼠抗体A1结合相同的表位的抗体。在多种实施方案中,本发明的抗体包括与鼠抗体A2结合相同的表位的抗体。在多种实施方案中,本发明的抗体包括与鼠抗体A3结合相同的表位的抗体。在多种实施方案中,本发明的抗体包括与鼠抗体A4结合相同的表位的抗体。在多种实施方案中,本发明的抗体包括与鼠抗体A5结合相同的表位的抗体。在多种实施方案中,本发明的抗体包括与鼠抗体A6结合相同的表位的抗体。
在本发明的多种实施方案中,抗体或抗原结合片段是来源于鼠抗体A4和人类IgG4的鼠-人类嵌合抗体,所述鼠-人类嵌合抗体包含SEQ ID NO:54的重链序列和SEQ ID NO:56的轻链序列,并且其中SEQ ID NO:54的氨基酸1-19是前导序列:
并且其中SEQ ID NO:56的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的鼠-人类嵌合抗体,其中重链包含与如SEQ ID NO:54中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:55具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:55为:
并且其中轻链包含与如SEQ ID NO:56中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:57具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:57为:
在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含重链可变区和轻链可变区,所述重链可变区具有与SEQ ID NO:58、60、62和64相同、基本上相同或基本上相似的序列,并且所述轻链可变区具有与SEQ ID NO:59、61、63和65相同、基本上相同或基本上相似的序列。
在多种实施方案中,抗体或其抗原结合片段包含重链可变结构域,所述重链可变结构域包含与具有SEQ ID NO:58、60、62和64中列出的氨基酸序列的重链可变结构域的序列仅在15个、14个、13个、12个、11个、10个、9个、8个、7个、6个、5个、4个、3个、2个、1个或0个残基处不同的氨基酸的序列,其中每个这样的序列差异独立地是一个氨基酸残基的缺失、插入或取代。在多种实施方案中,抗体或其抗原结合片段包含重链可变结构域,所述重链可变结构域包含与如SEQ ID NO:58、60、62和64中列出的氨基酸序列具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列。
在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合并且包含轻链可变结构域,所述轻链可变结构域包含与具有SEQ ID NO:59、61、63和65中列出的氨基酸序列的轻链可变结构域的序列仅在15个、14个、13个、12个、11个、10个、9个、8个、7个、6个、5个、4个、3个、2个、1个或0个残基处不同的氨基酸的序列,其中每个这样的序列差异独立地是一个氨基酸残基的缺失、插入或取代。在多种实施方案中,抗体或其抗原结合片段包含轻链可变结构域,所述轻链可变结构域包含与如SEQ ID NO:59、61、63和65中列出的氨基酸序列具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列。
在本公开内容的多种实施方案中,抗体可以是具有与包含如SEQ ID NO:58、60、62和64的任一项中列出的重链可变区序列的抗体的抗原-结合亲和力相同或更高的抗原-结合亲和力的抗IL-17A抗体。在多种实施方案中,抗体可以是与包含如SEQ ID NO:58、60、62和64的任一项中列出的重链可变区序列的抗体结合相同的表位的抗IL-17A抗体。在多种实施方案中,抗体是与包含如SEQ ID NO:58、60、62和64的任一项中列出的重链可变区序列的抗体竞争的抗IL-17A抗体。在多种实施方案中,抗体可以是包含如SEQ ID NO:58、60、62和64的任一项中列出的重链可变区序列的至少一个(诸如2个或3个)CDR的抗IL-17A抗体。
在本公开内容的多种实施方案中,抗体可以是具有与包含如SEQ ID NO:59、61、63和65的任一项中列出的轻链可变区序列的抗体的抗原-结合亲和力相同或更高的抗原-结合亲和力的抗IL-17A抗体。在多种实施方案中,抗体可以是与包含如SEQ ID NO:59、61、63和65的任一项中列出的轻链可变区序列的抗体结合相同的表位的抗IL-17A抗体。在多种实施方案中,抗体是与包含如SEQ ID NO:59、61、63和65的任一项中列出的轻链可变区序列的抗体竞争的抗IL-17A抗体。在多种实施方案中,抗体可以是包含如SEQ ID NO:59、61、63和65的任一项中列出的轻链可变区序列的至少一个(诸如2个或3个)CDR的抗IL-17A抗体。
在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:58中列出的氨基酸序列的重链可变区和具有选自由SEQID NO:59、SEQ ID NO:61、SEQ ID NO:63和SEQ ID NO:65组成的组的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:60中列出的氨基酸序列的重链可变区和具有选自由SEQ IDNO:59、SEQ ID NO:61、SEQ ID NO:63和SEQ ID NO:65组成的组的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:62中列出的氨基酸序列的重链可变区和具有选自由SEQ IDNO:59、SEQ ID NO:61、SEQ ID NO:63和SEQ ID NO:65组成的组的氨基酸序列的轻链可变区。在多种实施方案中,抗体是人源化抗体或其抗原结合片段,所述人源化抗体或其抗原结合片段包含具有SEQ ID NO:64中列出的氨基酸序列的重链可变区和具有选自由SEQ IDNO:59、SEQ ID NO:61、SEQ ID NO:63和SEQ ID NO:65组成的组的氨基酸序列的轻链可变区。
在本发明的多种实施方案中,抗体是人源化IgG,所述人源化IgG包含SEQ ID NO:66的重链序列(“H1”)和SEQ ID NO:68的轻链序列(“L1”),并且其中SEQ ID NO:66的氨基酸1-19是前导序列:
并且其中SEQ ID NO:68的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含与如SEQID NO:66中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:67具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:67为:
并且其中轻链包含与如SEQ ID NO:68中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:69具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:69为:
在本发明的多种实施方案中,抗体是人源化IgG,所述人源化IgG包含SEQ ID NO:70的重链序列(“H2”)和SEQ ID NO:72的轻链序列(“L2”),并且其中SEQ ID NO:70的氨基酸1-19是前导序列:
并且其中SEQ ID NO:72的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含与如SEQID NO:70中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:71具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:71为:
并且其中轻链包含与如SEQ ID NO:72中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:73具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:73为:
在本发明的多种实施方案中,抗体是人源化IgG,所述人源化IgG包含SEQ ID NO:74的重链序列(“H3”)和SEQ ID NO:76的轻链序列(“L3”),并且其中SEQ ID NO:74的氨基酸1-19是前导序列:
并且其中SEQ ID NO:76的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含与如SEQID NO:74中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:75具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:75为:
并且其中轻链包含与如SEQ ID NO:76中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:77具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:77为:
在本发明的多种实施方案中,抗体是人源化IgG,所述人源化IgG包含SEQ ID NO:78的重链序列(“H4”)和SEQ ID NO:80的轻链序列(“L4”),并且其中SEQ ID NO:78的氨基酸1-19是前导序列:
并且其中SEQ ID NO:80的氨基酸1-19是前导序列:
在某些可选的实施方案中,抗体是包含重链和轻链的抗体,其中重链包含与如SEQID NO:78中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:79具有至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:79为:
并且其中轻链包含与如SEQ ID NO:80中列出的氨基酸序列或其对应的多核苷酸序列SEQ ID NO:81具有至少约75%、至少约80%、至少约85%、至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或至少约99%同一性的序列,SEQ ID NO:81为:
在多种实施方案中,抗体包含与SEQ ID NO:66、70、74和78的任一项共有例如,至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的观察到的同源性的重链氨基酸序列。在多种实施方案中,抗体包含与SEQID NO:67、71、75和79的任一项共有例如,至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的观察到的同源性的重链核酸序列。
在本公开内容的多种实施方案中,抗体可以是具有与包含如SEQ ID NO:66、70、74和78的任一项中列出的重链序列的抗体的抗原-结合亲和力相同或更高的抗原-结合亲和力的抗IL-17A抗体。在多种实施方案中,抗体可以是与包含如SEQ ID NO:66、70、74和78的任一项中列出的重链序列的抗体结合相同的表位的抗IL-17A抗体。在多种实施方案中,抗体是与包含如SEQ ID NO:66、70、74和78的任一项中列出的重链序列的抗体竞争的抗IL-17A抗体。在多种实施方案中,抗体可以是包含如SEQ ID NO:66、70、74和78的任一项中列出的重链序列的至少一个(诸如2个或3个)CDR的抗IL-17A抗体。
在多种实施方案中,抗体包含与SEQ ID NO:68、72、76和80的任一项共有例如,至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的观察到的同源性的轻链氨基酸序列。在多种实施方案中,抗体包含与SEQID NO:69、73、77和81的任一项共有例如,至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%的观察到的同源性的核酸序列。
在本公开内容的多种实施方案中,抗体可以是具有与包含如SEQ ID NO:68、72、76和80的任一项中列出的轻链序列的抗体的抗原-结合亲和力相同或更高的抗原-结合亲和力的抗IL-17A抗体。在多种实施方案中,抗体可以是与包含如SEQ ID NO:68、72、76和80的任一项中列出的轻链序列的抗体结合相同的表位的抗IL-17A抗体。在多种实施方案中,抗体是与包含如SEQ ID NO:68、72、76和80的任一项中列出的轻链序列的抗体竞争的抗IL-17A抗体。在多种实施方案中,抗体可以是包含如SEQ ID NO:68、72、76和80的任一项中列出的轻链序列的至少一个(诸如2个或3个)CDR的抗IL-17A抗体。
在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:66中列出的重链序列和SEQ ID NO:68中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ ID NO:66中列出的重链序列和SEQ ID NO:72中列出的轻链序列。在多种实施方案中,本发明的分离的人源化抗体或其抗原结合片段与人类IL-17A结合,并且包含SEQ IDNO:66中列出的重链序列和SEQ ID NO:80中列出的轻链序列。
本发明的抗体或其抗原结合片段可以包含本领域中已知的任何恒定区。轻链恒定区可以是,例如κ或λ型轻链恒定区,例如人类κ或λ型轻链恒定区。重链恒定区可以是,例如α、δ、ε、γ或μ型重链恒定区,例如IgA、IgD、IgE、IgG和IgM型重链恒定区。在多种实施方案中,轻链恒定区或重链恒定区是天然存在的恒定区的片段、衍生物、变体或突变蛋白(mutein)。
用于从感兴趣的抗体衍生不同的子类或同种型的抗体,即子类转换(subclassswitching)的技术是已知的。因此,IgG抗体可以来源于例如IgM抗体,反之亦然。这样的技术允许制备具有给定的抗体(亲本抗体)的抗原结合特性但还表现出与该亲本抗体不同的抗体同种型或子类相关的生物学特性的新的抗体。可以使用重组DNA技术。可以在这样的程序中使用编码特定抗体多肽的克隆的DNA,例如,编码期望的同种型的抗体的恒定结构域的DNA。还参见Lanitto等人,Methods Mol.Biol.178:303-16,2002。
在多种实施方案中,本发明的抗体还包含轻链κ或λ恒定结构域或其片段,并且还包含重链恒定结构域或其片段。在例举的抗体中使用的轻链恒定区和重链恒定区的序列以及编码它们的多核苷酸在以下提供。
轻链(κ)恒定区
轻链(λ)恒定区
重链恒定区
本发明的抗体也可以根据它们的交叉反应性来描述或指定。与IL-17A多肽结合的抗体也包括在本发明中,所述IL-17A多肽与人类IL-17A具有至少95%、至少90%、至少85%、至少80%、至少75%、至少70%、至少65%、至少60%、至少55%和至少50%同一性(如使用本领域中已知的和本文描述的方法计算的)。
本发明还包括与本发明的抗IL-17A抗体结合相同的表位的抗体。为了确定抗体是否可以竞争结合由本发明的抗IL-17A抗体结合的表位相同的表位,可以进行交叉阻断测定,例如竞争性ELISA测定。在示例性竞争性ELISA测定中,包被在微量滴定板的孔上的IL-17A与或不与候选竞争性抗体预孵育,并且然后添加本发明的生物素标记的抗IL-17A抗体。在孔中与IL-17A抗原结合的标记的抗IL-17A抗体的量使用亲和素-过氧化物酶缀合物和适当的底物测量。抗体可以用放射性标记物或荧光标记物或一些其他可检测且可测量的标记物标记。与抗原结合的标记的抗IL-17A抗体的量将具有与候选竞争性抗体(测试抗体)竞争结合相同的表位的能力的间接相关性,即测试抗体对相同的表位的亲和力越大,标记的抗体将越少地与抗原包被的孔结合。如果与不存在候选竞争性抗体时平行进行的对照相比,候选抗体可以阻断IL-17A抗体的结合至少20%、至少30%、至少40%或至少50%,则认为候选竞争性抗体是与本发明的抗IL-17A抗体基本上结合相同的表位的抗体或竞争结合相同的表位的抗体。将理解,可以进行该测定的变化形式以达到相同的定量的值。
在一方面,本发明提供了一种药物组合物,所述药物组合物包含如以上描述的抗体或其抗原结合片段。本发明的药物组合物、方法和用途因此还包括与其他活性剂组合(共施用)的实施方案,如以下详述的。
通常,本发明的抗体或其抗原结合片段适合于作为与一种或更多种药学上可接受的赋形剂联合的制剂被施用。本文使用术语“赋形剂”来描述除本发明的一种或更多种化合物以外的任何成分。一种或更多种赋形剂的选择将很大程度上取决于诸如特定的施用模式、赋形剂对溶解性和稳定性的影响和剂型的性质的因素。如本文使用的,“药学上可接受的赋形剂”包括生理学上相容的任何和所有溶剂、分散介质、包衣、抗细菌剂和抗真菌剂、等渗剂和吸收延迟剂等。药学上可接受的赋形剂的一些实例是水、盐水、磷酸盐缓冲的盐水、右旋糖、甘油、乙醇等,以及其组合。在许多情况中,在组合物中包含等渗剂,例如糖类、多元醇类诸如甘露醇、山梨醇、或氯化钠将是优选的。药学上可接受的物质的另外的实例是润湿剂或少量的辅助物质诸如润湿剂或乳化剂、防腐剂或缓冲液,其延长抗体的货架期或增强抗体的效力。本发明的药物组合物和用于其制备的方法对于本领域技术人员而言将是十分明显的。这类组合物和用于其制备的方法可以在例如Remington的PharmaceuticalSciences,第19版(Mack Publishing Company,1995)中发现。优选在GMP条件下制造药物组合物。
本发明的药物组合物可以以单一单位剂量或以多于一个单一单位剂量制备、包装或大量销售。如本文使用的,“单位剂量”是包含预先确定的量的活性成分的药物组合物的分散的量。活性成分的量通常等于将被施用至受试者的活性成分的剂量或这样的剂量的方便的部分,诸如例如这样的剂量的一半或三分之一。
本领域中公认的用于施用肽、蛋白、或抗体的任何方法可以合适地被用于本发明的抗体和部分。
本发明的药物组合物通常适合于肠胃外施用。如本文使用的,药物组合物的“肠胃外施用”包括以以下为特征的任何施用途径:物理穿破(physical breaching)受试者的组织并且通过组织中的缺口(breach)施用药物组合物,因此通常引起直接施用到血流中、到肌肉中或到内脏器官中。因此,肠胃外施用包括但不限于,通过注射组合物施用药物组合物、通过经手术切口应用组合物、通过经组织渗透性非手术伤口应用组合物等。特别是,预期肠胃外施用包括但不限于皮下、腹膜内、肌肉内、胸骨内、静脉内、动脉内、鞘内、脑室内/心室内、尿道内、颅内、滑膜内注射或输注;和肾透析输注技术。多种实施方案包括静脉内和皮下途径。
适合于肠胃外施用的药物组合物的制剂往往通常包含与药学上可接受的载体诸如无菌水或无菌等渗盐水组合的活性成分。这样的制剂可以以适合于团注施用(bolusadministration)或用于连续施用的形式被制备、包装或销售。可注射的制剂可以以单位剂型被制备、包装或销售,诸如在安瓿中或在包含防腐剂的多剂量容器中。用于肠胃外施用的制剂包括但不限于悬浮液、溶液、在油或水性媒介物中的乳液、糊剂等。这样的制剂还可以包含一种或更多种另外的成分,包括但不限于悬浮剂、稳定剂或分散剂(dispersingagents)。在用于肠胃外施用的制剂的一种实施方案中,活性成分以干燥(即粉末或颗粒)形式提供,用于与合适的媒介物(例如无菌的无热原水)重构,然后肠胃外施用所重构的组合物。肠胃外制剂还包括水性溶液,所述水性溶液可以包含赋形剂诸如盐、碳水化合物和缓冲剂(优选地至从3至9的pH),但对于一些应用,它们可能更适合于被配制为无菌非水溶液或与合适的媒介物诸如无菌的、无热原的水一起使用的干燥的形式。示例性肠胃外施用形式包括在无菌水性溶液,例如水性丙二醇或右旋糖溶液中的溶液或悬浮液。如果期望,这样的剂型可以被合适地缓冲。其他有用的可肠胃外施用的制剂包括包含呈微晶形式的活性成分的那些,或呈脂质体制备物的那些。用于肠胃外施用的制剂可以被配制为即时释放和/或改良释放(modified release)。改良释放制剂包括延迟的、持续的、脉冲的、受控的、靶向的和编程的释放。
例如,在一方面,无菌可注射溶液可以通过将需要的量的抗IL-17A抗体掺入具有以上列举的一种成分或成分的组合的适当溶剂中来制备,如果需要,随后过滤灭菌。通常,分散体(dispersions)通过将活性化合物掺入到包含基础分散介质和来自以上列举的那些的需要的其他成分的无菌媒介物中来制备。在用于制备无菌可注射溶液的无菌粉末的情况中,优选的制备方法是真空干燥和冷冻干燥,其产生活性成分加来自其先前无菌过滤的溶液的任何另外的期望的成分的粉末。适当的溶液流动性可以例如,通过使用包衣诸如卵磷脂、在分散体的情况中通过维持需要的颗粒尺寸和通过使用表面活性剂来维持。可注射组合物的延长的吸收可以由在组合物中包括延迟吸收的剂例如单硬脂酸盐和明胶引起。
本发明的抗体还可以鼻内施用或通过吸入施用,通常以干燥粉末的形式(单独的、作为混合物或作为混合的组分颗粒,例如与合适的药学上可接受的赋形剂混合)从干粉吸入器施用、作为气雾剂喷雾从压力容器、泵、喷雾器(spray)、雾化器(优选地使用电水动力学以产生细雾(fine mist)的雾化器)、或喷雾器(nebulizer)施用,使用或不使用合适的推进剂,或作为滴鼻液施用。
压力容器、泵、喷雾器(spray)、雾化器、或喷雾器(nebulizer)通常包含本发明的抗体的溶液或悬浮液,所述溶液或悬浮液包含例如用于分散、溶解或延长活性剂的释放的合适的剂、作为溶剂的一种或更多种推进剂。
在干燥粉末或悬浮液制剂中使用前,药物产品通常地被微粉化至适合于通过吸入递送的尺寸(通常小于5微米)。这可以通过任何适当的粉碎方法进行,诸如螺旋气流粉碎、流化床气流粉碎、超临界流体加工以形成纳米颗粒、高压均质或喷雾干燥。
用于在吸入器或吹药器(insufflator)中使用的胶囊、泡罩和药筒可以被配制为包含本发明的化合物、合适的粉末基质和性能修饰剂(performance modifier)的粉末混合物。
合适的调味剂(flavour)诸如薄荷脑和左薄荷脑,或甜味剂诸如糖精或糖精钠,可以被添加至意图用于吸入/鼻内施用的本发明的那些制剂。
用于吸入/鼻内施用的制剂可以被配制为即时释放和/或改良释放。改良释放制剂包括延迟的、持续的、脉冲的、受控的、靶向的和编程的释放。
在干粉吸入器和气雾剂的情况中,剂量单位借助递送计量的量的阀的手段来确定。根据本发明的单位通常被布置以施用本发明的抗体的计量的剂量或“喷出(puff)”本发明的抗体。总每日剂量将通常以单一剂量施用,或更通常地,作为分次剂量整天施用。
本发明的抗体和抗体部分还可以被配制为用于口服途径施用。口服施用可以涉及吞咽,使得化合物进入胃肠道和/或经颊、经舌或舌下施用,通过这些方式化合物从口直接进入血流。
适合于口服施用的制剂包括固体、半固体和液体系统,诸如片剂;包含多颗粒或纳米颗粒、液体或粉末的软胶囊或硬胶囊;锭剂(包括填充液体的);咀嚼剂(chews);凝胶;快速分散的剂型;膜;卵形剂(ovule);喷雾剂和颊/粘膜黏附贴剂(buccal/mucoadhesivepatch)。
意图用于口服使用的药物组合物可以根据本领域已知的用于制造药物组合物的任何方法制备,并且这样的组合物可以包含选自由甜味剂组成的组的一种或更多种剂以提供药学上巧妙(elegant)且可口的制剂。例如,为了制备可口服递送的片剂,将抗体或其抗原结合片段与至少一种药物赋形剂混合,并且根据已知方法压缩所述固体制剂以形成片剂,用于递送至胃肠道。片剂组合物通常与添加剂一起配制,所述添加剂例如糖类或纤维素载体、粘合剂诸如淀粉糊或甲基纤维素、填充剂、崩解剂或往往通常在医用制剂的制造中使用的其他添加剂。为了制备可口服递送的胶囊,将DHEA与至少一种药物赋形剂混合,并且将固体制剂放置在适合于递送至胃肠道的胶囊容器中。包含抗体或其抗原结合片段的组合物可以如Remington的Pharmaceutical Sciences,第18版.1990(Mack PublishingCo.Easton Pa.18042)的第89章中一般描述的来制备,该文献通过引用并入本文。
在多种实施方案中,药物组合物被配制为包含与适合于制造片剂的非毒性药学上可接受的赋形剂混合的抗体或其抗原结合片段的可口服递送的片剂。这些赋形剂可以是惰性稀释剂,诸如碳酸钙、碳酸钠、乳糖、磷酸钙或磷酸钠;成粒剂和崩解剂,例如,玉米淀粉、明胶或阿拉伯胶,以及润滑剂,例如硬脂酸镁、硬脂酸或滑石。片剂可以是未包衣的,或者它们可以用已知技术包衣以延迟在胃肠道中的崩解和吸收并且从而在更长的时间段内提供持续的作用。例如,可以使用时间延迟材料诸如单独的单硬脂酸甘油酯或二硬脂酸甘油酯或与蜡一起使用。
在多种实施方案中,药物组合物被配制为硬明胶胶囊,其中将抗体或其抗原结合片段与惰性固体稀释剂混合,所述惰性固体稀释剂例如碳酸钙、磷酸钙或高岭土,或被配制为软明胶胶囊,其中将抗体或其抗原结合片段与水性介质或油介质,例如花生油(arachisoil)、花生油(peanut oil)、液体石蜡或橄榄油混合。
液体制剂包括悬浮液、溶液、糖浆和酏剂。这样的制剂可以作为软胶囊或硬胶囊(从例如明胶或羟丙基甲基纤维素制成)中的填充剂使用,并且通常包含载体,例如水、乙醇、聚乙二醇、丙二醇、甲基纤维素或合适的油,以及一种或更多种乳化剂和/或悬浮剂。液体制剂还可以通过重构例如来自小袋的固体制备。
在另一方面,本发明涉及治疗患有IL-17A相关的紊乱的受试者的方法,所述方法包括向受试者施用治疗有效量(作为单一疗法或在组合疗法方案中)的本发明的分离的抗体或抗原结合片段。本发明的典型方法包括治疗哺乳动物中与IL-17A或IL-17F表达和/或活性增加或增强相关或由IL-17A或IL-17F表达和/或活性增加或增强导致的病理学状况或疾病的方法。在治疗方法中,可以施用IL-17A/F抗体,其优选地阻断或降低各自与其受体的结合或活化。任选地,在所述方法中使用的IL-17A/F抗体能够阻断或中和IL-17A和IL-17F二者的活性,例如阻断或中和IL-17A或IL-17F二者的活性的双重拮抗剂(即如本文描述的交叉反应性IL-17A/F抗体)。这些方法预期使用单一的交叉反应性抗体或者两种或更多种抗体的组合。
在多种实施方案中,IL-17A相关的紊乱是包括例如以下的免疫相关和炎性疾病:系统性红斑狼疮、关节炎、银屑病性关节炎、类风湿性关节炎、骨关节炎、幼年型慢性关节炎、脊椎关节病、系统性硬化、特发性炎性肌病、干燥综合征、系统性血管炎、结节病、自身免疫性溶血性贫血、自身免疫性血小板减少症、甲状腺炎、糖尿病、免疫介导的肾病、中枢和外周神经系统的脱髓鞘疾病诸如多发性硬化、特发性脱髓鞘性多神经病或吉兰-巴雷综合征和慢性炎性脱髓鞘性多神经病、肝胆疾病诸如感染性自身免疫性慢性活动性肝炎、原发性胆汁性肝硬化、肉芽肿性肝炎和硬化性胆管炎、炎性肠病、结肠炎、克罗恩氏病、谷蛋白敏感性肠病和内毒素血症、自身免疫性或免疫介导的皮肤病包括大疱性皮肤病、多形性红斑和特应性皮炎和接触性皮炎、银屑病、嗜中性皮肤病、囊性纤维化、过敏性疾病诸如哮喘、过敏性鼻炎、食物超敏反应和荨麻疹、囊性纤维化、免疫性肺病诸如嗜酸性肺炎、特发性肺纤维化、成人呼吸道疾病(ARD)、急性呼吸窘迫综合征(ARDS)和炎性肺损伤诸如哮喘、慢性阻塞性肺病(COPD)、气道高反应性、慢性支气管炎、过敏性哮喘和过敏性肺炎、移植相关疾病,包括移植物和器官排斥和移植物抗宿主病、感染性休克、多器官衰竭、癌症和血管生成。在多种实施方案中,IL-17A相关的紊乱是选自由以下组成的组的炎性紊乱:银屑病、炎性肠病、溃疡性结肠炎、克罗恩氏病、肠易激综合征、哮喘、关节炎、特应性皮炎、银屑病性关节炎、类风湿性关节炎、幼年型慢性关节炎、系统性硬化、干燥综合征、多发性硬化、系统性红斑狼疮和移植物抗宿主病。
在多种实施方案中,IL-17A相关的紊乱是选自由以下组成的组的免疫相关紊乱:系统性红斑狼疮、关节炎、银屑病性关节炎、类风湿性关节炎、骨关节炎、幼年型慢性关节炎、脊椎关节病、系统性硬化、特发性炎性肌病、干燥综合征、系统性血管炎、结节病、自身免疫性溶血性贫血、自身免疫性血小板减少症、甲状腺炎、糖尿病、免疫介导的肾病、中枢和外周神经系统的脱髓鞘疾病诸如多发性硬化、特发性脱髓鞘性多神经病或吉兰-巴雷综合征和慢性炎性脱髓鞘性多神经病、肝胆疾病诸如感染性自身免疫性慢性活动性肝炎、原发性胆汁性肝硬化、肉芽肿性肝炎和硬化性胆管炎、炎性肠病、结肠炎、克罗恩氏病、谷蛋白敏感性肠病和内毒素血症、自身免疫性或免疫介导的皮肤病包括大疱性皮肤病、多形性红斑和特应性皮炎和接触性皮炎、银屑病、嗜中性皮肤病、囊性纤维化、过敏性疾病诸如哮喘、过敏性鼻炎、食物超敏反应和荨麻疹、囊性纤维化、免疫性肺病诸如嗜酸性肺炎、特发性肺纤维化、成人呼吸道疾病(ARD)、急性呼吸窘迫综合征(ARDS)和炎性肺损伤诸如哮喘、慢性阻塞性肺病(COPD)、气道高反应性、慢性支气管炎、过敏性哮喘和过敏性肺炎、移植相关疾病,包括移植物和器官排斥和移植物抗宿主病、感染性休克、多器官衰竭、癌症和血管生成。
在多种实施方案中,IL-17A相关的紊乱是与升高的1L-17A表达相关的癌症。在多种实施方案中,受试者先前响应于用抗癌疗法的治疗,但在疗法停止后,遭受复发(下文称为“复发性癌症”)。在多种实施方案中,受试者患有耐受性癌症或难治性癌症。在多种实施方案中,癌细胞是免疫原性肿瘤(例如,使用肿瘤本身进行疫苗接种可以引起对肿瘤攻击的免疫的那些肿瘤)。根据本发明的可以被治疗的癌细胞包括肉瘤和癌,诸如但不限于:纤维肉瘤、黏液肉瘤、脂肪肉瘤、软骨肉瘤、骨原性肉瘤、脊索瘤、血管肉瘤、内皮肉瘤、淋巴管肉瘤、淋巴管内皮肉瘤、滑膜瘤、间皮瘤、淋巴瘤、黑素瘤、卡波西肉瘤(Kaposi's sarcoma)、尤因肿瘤(Ewing's tumor)、平滑肌肉瘤、横纹肌肉瘤、结肠-直肠癌、胃癌、胰腺癌、乳腺癌、卵巢癌、前列腺癌、鳞状细胞癌、基底细胞癌、腺癌、汗腺癌、皮脂腺癌、乳头状癌、乳头状腺癌、囊腺癌、髓样癌、支气管癌、肾细胞癌、肝癌、胆管癌、绒毛膜癌、精原细胞瘤、胚胎性癌、维尔姆斯瘤(Wilms'tumor)、宫颈癌、睾丸肿瘤、肺癌、小细胞肺癌、膀胱癌、上皮癌、神经胶质瘤、星形细胞瘤、髓母细胞瘤、颅咽管瘤、室管膜瘤、松果体瘤、血管母细胞瘤、听觉神经瘤、少突神经胶质瘤、脑膜瘤、黑素瘤、神经母细胞瘤和视网膜母细胞瘤。
在多种实施方案中,癌细胞选自由卵巢癌、肺癌、乳腺癌、胃癌、前列腺癌、结肠癌、肾细胞癌、胶质母细胞瘤和黑素瘤组成的组。在多种实施方案中,受试者先前响应于用抗癌疗法的治疗,但在疗法停止后,遭受复发(下文称为“复发性癌症”)。在多种实施方案中,受试者患有耐受性癌症或难治性癌症。在多种实施方案中,癌细胞是免疫原性肿瘤(例如,使用肿瘤本身进行疫苗接种可以引起对肿瘤攻击的免疫的那些肿瘤)。
在多种实施方案中,本发明的抗体及其抗原结合片段可以被用于促进癌性肿瘤细胞的生长和/或增殖的抑制。这些方法可以抑制或预防所述受试者的癌细胞的生长,诸如例如,至少10%、至少15%、至少20%、至少25%、至少30%、至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%或至少95%。因此,在癌症是实体肿瘤的情况中,调控可以将实体肿瘤的尺寸减少至少10%、至少15%、至少20%、至少25%、至少30%、至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、或至少95%。
在另一方面,本发明涉及被设计成治疗受试者中的癌症的组合疗法,所述组合疗法包括向受试者施用a)治疗有效量的本发明的分离的抗体或抗原结合片段,和b)一种或更多种另外的疗法,所述一种或更多种另外的疗法选自由免疫疗法、化学疗法、小分子激酶抑制剂靶向疗法、手术、放射疗法和干细胞移植组成的组,其中组合疗法提供了对肿瘤细胞的增加的细胞杀伤,即当被共施用时,分离的抗体或抗原结合片段和另外的疗法之间存在协同作用。在多种实施方案中,免疫疗法选自由以下组成的组:使用针对共刺激或共抑制分子(免疫检查点)诸如PD-1、PD-L1、OX-40、CD137、GITR、LAG3、TIM-3和VISTA的激动抗体、拮抗抗体或阻断抗体的治疗;使用双特异性T细胞接合抗体
在多种实施方案中,包括施用本发明的分离的抗体或抗原结合片段和疫苗或免疫调节剂的组合疗法控制与使用免疫调节剂(例如,(CAR)-T细胞)的单一疗法相关的自身免疫应答和/或细胞因子风暴。在多种实施方案中,与使用免疫调节剂诸如检查点抑制剂、(CAR)-T细胞和其他免疫干预的单一疗法相比,包括施用本发明的分离的抗体或抗原结合片段和疫苗或免疫调节剂的组合疗法提供了癌症免疫疗法的增强的功效。
在另一方面,本发明涉及用于减少炎性细胞从血管系统向哺乳动物的组织中浸润的方法,所述方法包括向所述哺乳动物施用拮抗剂IL-17A/F抗体,其中哺乳动物中炎性细胞从血管系统的浸润减少。在另一方面,本发明涉及降低哺乳动物中T淋巴细胞的活性的方法,所述方法包括向所述哺乳动物施用IL-17A/F拮抗剂抗体,其中哺乳动物中T淋巴细胞的活性降低。在另一方面,本发明涉及减少哺乳动物中T淋巴细胞的增殖的方法,所述方法包括向所述哺乳动物施用IL-17A/F拮抗剂抗体,其中哺乳动物中T淋巴细胞的增殖减少。
在多种实施方案中,本发明涉及用于在受试者中刺激对病原体、毒素和自身抗原的免疫应答的方法,所述方法包括向受试者施用治疗有效量(作为单一疗法或在组合疗法方案中)的本发明的分离的抗体或抗原结合片段。在多种实施方案中,受试者患有耐受使用常规疫苗的治疗或通过使用常规疫苗的治疗未被有效治疗的传染病。
“治疗有效量”或“治疗有效剂量”是指将使被治疗的紊乱的一种或更多种症状缓解至一定程度的被施用的治疗剂的量。
治疗有效剂量可以通过确定IC
可以调整剂量方案以提供最佳的期望的应答(例如,治疗应答或预防应答)。例如,可以施用单次团注,可以随时间施用几个分次剂量(多个或重复或维持)并且剂量可以根据治疗情境的迫切需要所指示的按比例减少或增加。为了便于施用和剂量的一致性,配制呈剂量单位形式的肠胃外组合物是特别有利的。如本文使用的剂量单位形式是指合适作为用于待治疗的哺乳动物受试者的单一剂量的物理分散的单位;每一个单位包含与需要的药物载体一起的被计算产生期望的治疗作用的预先确定的量的活性化合物。本公开内容的剂量单位形式的规格将主要由抗体的独特特征和待实现的特定治疗作用或预防作用决定。
因此,技术人员将理解,基于本文提供的公开内容,根据治疗领域中熟知的方法调整剂量和给药方案。即,最大可耐受剂量可以被容易地确定,并且向受试者提供可检测的治疗益处的有效量也可以被确定,向受试者提供可检测的治疗益处而施用每个剂的时间要求同样可以被确定。因此,尽管在本文中例举了某些剂量和施用方案,这些实例绝不限制在实践本公开内容时可以向受试者提供的剂量和施用方案。
应注意到,剂量值可以随着待减轻的状况的类型和严重性而变化,并且可以包括单个剂量或多于一个剂量。还应理解,对于任何特定受试者,应根据个体需要和施用组合物或监督组合物的施用的人士的专业判断随时间调整具体剂量方案,并且本文列出的剂量范围仅是示例性的并且不意图限制所要求保护的组合物的范围或实践。另外,本公开内容的组合物的剂量方案可以基于多个因素,包括疾病的类型、受试者的年龄、体重、性别、医学状况、状况的严重性、施用途径和使用的特定抗体。因此,剂量方案可以广泛变化,但可以使用标准方法常规地确定。例如,剂量可以基于药代动力学或药效动力学参数调整,所述参数可以包括临床作用诸如毒性作用和/或实验值。因此,本公开内容包括如由技术人员确定的受试者内的剂量递增(intra-subject dose-escalation)。确定适当的剂量和方案是相关技术领域中熟知的并且将被理解为一旦提供本文所公开的教导,则由技术人员掌握。
对于向人类受试者施用,当然取决于施用的模式,本公开内容的抗体或其抗原结合片段的总每月剂量可以在0.5-1200mg/受试者、0.5-1100mg/受试者、0.5-1000mg/受试者、0.5-900mg/受试者、0.5-800mg/受试者、0.5-700mg/受试者、0.5-600mg/受试者、0.5-500mg/受试者、0.5-400mg/受试者、0.5-300mg/受试者、0.5-200mg/受试者、0.5-100mg/受试者、0.5-50mg/受试者、1-1200mg/受试者、1-1100mg/受试者、1-1000mg/受试者、1-900mg/受试者、1-800mg/受试者、1-700mg/受试者、1-600mg/受试者、1-500mg/受试者、1-400mg/受试者、1-300mg/受试者、1-200mg/受试者、1-100mg/受试者或1-50mg/受试者的范围内。例如,每月静脉内剂量可以需要约1-1000mg/受试者。在多种实施方案中,本公开内容的抗体或其抗原结合片段可以以约1-200mg/受试者、1-150mg/受试者或1-100mg/受试者被施用。总每月剂量可以以单个剂量或分次剂量来施用,并且可以以医师的判断,落在本文给出的典型范围之外。
本公开内容的抗体或其抗原结合片段的治疗有效量或预防有效量的示例性、非限制性每日给药范围可以是0.001mg/kg体重至100mg/kg体重、0.001mg/kg体重至90mg/kg体重、0.001mg/kg体重至80mg/kg体重、0.001mg/kg体重至70mg/kg体重、0.001mg/kg体重至60mg/kg体重、0.001mg/kg体重至50mg/kg体重、0.001mg/kg体重至40mg/kg体重、0.001mg/kg体重至30mg/kg体重、0.001mg/kg体重至20mg/kg体重、0.001mg/kg体重至10mg/kg体重、0.001mg/kg体重至5mg/kg体重、0.001mg/kg体重至4mg/kg体重、0.001mg/kg体重至3mg/kg体重、0.001mg/kg体重至2mg/kg体重、0.001mg/kg体重至1mg/kg体重、0.010mg/kg体重至50mg/kg体重、0.010mg/kg体重至40mg/kg体重、0.010mg/kg体重至30mg/kg体重、0.010mg/kg体重至20mg/kg体重、0.010mg/kg体重至10mg/kg体重、0.010mg/kg体重至5mg/kg体重、0.010mg/kg体重至4mg/kg体重、0.010mg/kg体重至3mg/kg体重、0.010mg/kg体重至2mg/kg体重、0.010mg/kg体重至1mg/kg体重、0.1mg/kg体重至50mg/kg体重、0.1mg/kg体重至40mg/kg体重、0.1mg/kg体重至30mg/kg体重、0.1mg/kg体重至20mg/kg体重、0.1mg/kg体重至10mg/kg体重、0.1mg/kg体重至5mg/kg体重、0.1mg/kg体重至4mg/kg体重、0.1mg/kg体重至3mg/kg体重、0.1mg/kg体重至2mg/kg体重、0.1mg/kg体重至1mg/kg体重、1mg/kg体重至50mg/kg体重、1mg/kg体重至40mg/kg体重、1mg/kg体重至30mg/kg体重、1mg/kg体重至20mg/kg体重、1mg/kg体重至10mg/kg体重、1mg/kg体重至5mg/kg体重、1mg/kg体重至4mg/kg体重、1mg/kg体重至3mg/kg体重、1mg/kg体重至2mg/kg体重、或1mg/kg体重至1mg/kg体重。应注意到,剂量值可以随着待被减轻的状况的类型和严重性变化。还应理解,对于任何特定受试者,具体剂量方案应根据个体需要和施用组合物或监督组合物的施用的人士的专业判断随时间调整,并且本文列出的剂量范围仅是示例性的并且不意图限制所要求保护的组合物的范围或实践。
在多种实施方案中,施用的总剂量将实现在例如约1μg/ml至1000μg/ml、约1μg/ml至750μg/ml、约1μg/ml至500μg/ml、约1μg/ml至250μg/ml、约10μg/ml至1000μg/ml、约10μg/ml至750μg/ml、约10μg/ml至500μg/ml、约10μg/ml至250μg/ml、约20μg/ml至1000μg/ml、约20μg/ml至750μg/ml、约20μg/ml至500μg/ml、约20μg/ml至250μg/ml、约30μg/ml至1000μg/ml、约30μg/ml至750μg/ml、约30μg/ml至500μg/ml、约30μg/ml至250μg/ml的范围内的血浆抗体浓度。
本发明的药物组合物的毒性和治疗指数可以通过在细胞培养物或实验动物中的标准药学程序,例如用于确定LD
在多种实施方案中,药物组合物的单次施用或多于一次施用取决于受试者需求和耐受的剂量和频率来施用。无论如何,组合物应提供充分量的至少一种本文公开的抗体或其抗原结合片段以有效地治疗受试者。剂量可以被施用一次,但可以被周期性地应用直到实现治疗结果或直到副作用警告停止疗法。
施用抗体或其抗原结合片段药物组合物的给药频率取决于疗法的性质和被治疗的特定疾病。受试者可以以规律间隔治疗,诸如每周地或每月地,直到实现期望的治疗结果。示例性给药频率包括但不限于:无间断地每周一次;每隔一周地每周一次;每2周一次;每3周一次;无间断地每周一次,持续2周,然后每月一次;无间断地每周一次,持续3周,然后每月一次;每月一次;每两个月一次;每3个月一次;每4个月一次;每5个月一次;或每6个月一次,或每年一次。
如本文使用的,提及本公开内容的抗体或其抗原结合片段和一种或更多种其他治疗剂时,术语“共施用(co-administration)”、“共施用(co-administered)”和“与...组合(in combination with)”意图意指,并且的确是指并且包括以下:本公开内容的抗体或其抗原结合片段和一种或更多种治疗剂的这样的组合同时施用至需要治疗的受试者,当这样的组分被一起配制成单一剂型时,所述单一剂型在基本上相同的时间将所述组分释放至所述受试者;本公开内容的抗体或其抗原结合片段和一种或更多种治疗剂的这样的组合基本上同时施用至需要治疗的受试者,当这样的组分彼此分开配制成单独的剂型时,所述单独的剂型在基本上相同的时间被所述受试者服用,届时所述组分基本上在相同的时间释放至所述受试者;本公开内容的抗体或其抗原结合片段和一种或更多种治疗剂的这样的组合顺序施用至需要治疗的受试者,当这样的组分彼此分开配制成单独的剂型时,所述单独的剂型被所述受试者在连续的时间服用,每次施用之间具有显著的时间间隔,届时所述组分在基本上不同的时间释放至所述受试者;以及,本公开内容的抗体或其抗原结合片段和一种或更多种治疗剂的这样的组合顺序施用至需要治疗的受试者,当这样的组分一起配制成单一剂型时,所述单一剂型以受控方式释放所述组分,届时它们在相同和/或不同的时间同时、连续和/或重叠地释放至所述受试者,其中每个部分可以通过相同或不同的途径施用。
在另一方面,本发明涉及被设计成治疗受试者中的癌症的组合疗法,所述组合疗法包括向受试者施用a)治疗有效量的本发明的分离的抗体或抗原结合片段,和b)一种或更多种另外的疗法,所述一种或更多种另外的疗法选自由免疫疗法、化学疗法、小分子激酶抑制剂靶向疗法、手术、放射疗法和干细胞移植组成的组,其中组合疗法提供了对肿瘤细胞的增加的细胞杀伤,即当被共施用时,分离的抗体或抗原结合片段和另外的疗法之间存在协同作用。
在多种实施方案中,免疫疗法选自由以下组成的组:使用针对共刺激或共抑制分子(免疫检查点)诸如PD-1、PD-L1、OX-40、CD137、GITR、LAG3、TIM-3和VISTA的激动抗体、拮抗抗体或阻断抗体的治疗;使用双特异性T细胞接合抗体
在多种实施方案中,本发明的分离的抗体或抗原结合片段可以作为唯一的活性成分,或与例如佐剂组合,或者与其他药物(例如免疫抑制剂或免疫调节剂或其他抗炎剂或其他细胞毒性剂或抗癌剂)组合施用,例如用于治疗或预防上文提及的疾病。例如,本公开内容的抗体可以与以下进行组合使用:DMARD,例如金盐、柳氮磺胺吡啶(sulphasalazine)、抗疟药、氨甲蝶呤、D-青霉胺、硫唑嘌呤、霉酚酸、他克莫司、西罗莫司、米诺环素、来氟米特、糖皮质激素;钙调磷酸酶抑制剂,例如环孢菌素A或FK 506;淋巴细胞再循环的调节剂,例如FTY720和FTY720类似物;mTOR抑制剂,例如雷帕霉素、40-O-(2-羟乙基)-雷帕霉素、CC1779、ABT578、AP23573或TAFA-93;具有免疫抑制特性的子囊霉素,例如ABT-281、ASM981等;皮质类固醇;环磷酰胺;硫唑嘌呤;来氟米特,咪唑立宾;霉酚酸酯;15-脱氧精胍菌素或其免疫抑制同源物、类似物或衍生物;免疫抑制单克隆抗体,例如针对白细胞受体例如MHC、CD2、CD3、CD4、CD7、CD8、CD25、CD28、CD40、CD45、CD58、CD80、CD86或其配体的单克隆抗体,其他免疫调节化合物,例如具有CTLA4的细胞外结构域的至少一部分或其突变体的重组结合分子,例如与非CTLA4蛋白序列连接的CTLA4的至少细胞外部分或其突变体,例如CTLA4Ig(例如,被命名为ATCC 68629)或其突变体,例如LEA29Y;粘附分子抑制剂,例如LFA-1拮抗剂、ICAM-1或ICAM-3拮抗剂、VCAM-4拮抗剂或VLA-4拮抗剂;或化学治疗剂,例如紫杉醇、吉西他滨、顺铂、多柔比星或5-氟尿嘧啶;抗TNF剂,例如针对TNF的单克隆抗体,例如英夫利昔单抗、阿达木单抗、CDP870,或针对TNF-RI或TNF-RII的受体构建体,例如依那西普、PEG-TNF-RI、促炎性细胞因子的阻断剂、IL1阻断剂,例如阿那白滞素或IL1陷阱(IL1 trap)、卡那单抗(canakinumab)、IL13阻断剂、IL4阻断剂、IL6阻断剂、其他IL17阻断剂(诸如苏金单抗、broadalumab、ixekizumab);趋化因子阻断剂,例如蛋白酶的抑制剂或活化剂,例如金属蛋白酶、抗IL15抗体、抗IL6抗体、抗IL4抗体、抗IL13抗体、抗CD20抗体、NSAID,诸如阿司匹林或抗感染剂(清单不限于提及的剂)。
在多种实施方案中,组合疗法包括同时施用抗体或其抗原结合片段和一种或更多种另外的疗法。在多种实施方案中,抗体或其抗原结合片段组合物和一种或更多种另外的疗法被顺序施用,即,在施用一种或更多种另外的疗法之前或之后施用抗体或其抗原结合片段组合物。
在多种实施方案中,抗体或其抗原结合片段组合物和一种或更多种另外的疗法的施用是同时进行的,即,抗体或其抗原结合片段组合物和一种或更多种另外的疗法的施用时间段彼此重叠。
在多种实施方案中,抗体或其抗原结合片段组合物和一种或更多种另外的疗法的施用不是同时进行的。例如,在多种实施方案中,在施用一种或更多种另外的疗法之前,终止抗体或其抗原结合片段组合物的施用。在多种实施方案中,在施用抗体或其抗原结合片段组合物之前,终止一种或更多种另外的疗法的施用。
当本文公开的抗体或其抗原结合片段与一种或更多种另外的疗法同时地或顺序地组合施用时,这样的抗体或其抗原结合片段可以增强一种或更多种另外的疗法的治疗效果或克服细胞对一种或更多种另外的疗法的耐受性。这允许减少一种或更多种另外的疗法的剂量或缩短一种或更多种另外的疗法的持续时间,从而降低不期望的副作用,或恢复一种或更多种另外的疗法的效力。
本申请还提供了免疫缀合物,所述免疫缀合物包含直接或间接地与效应物分子缀合(或连接)的本发明的抗体或其抗原结合片段。在该方面中,术语“缀合的”或“连接的”是指使两个多肽形成一个连续的多肽分子。该连接可以通过化学手段或重组手段进行。在一种实施方案中,连接是化学的,其中抗体部分和效应物分子之间的反应已经产生了在两个分子之间形成的共价键以形成一个分子。肽接头(短肽序列)可以任选地包含在抗体和效应物分子之间。在多种实施方案中,抗体或抗原结合片段与效应物分子连接。在其他实施方案中,与效应物分子连接的抗体或抗原结合片段还与脂质、蛋白或肽连接,以增加其在体内的半衰期。因此,在多种实施方案中,本公开内容的抗体可以被用于递送多种效应物分子。
效应物分子可以是可检测的标记物、免疫毒素、细胞因子、趋化因子、治疗剂或化学治疗剂。
免疫毒素的具体的、非限制性的实例包括任何对细胞有害(例如,杀伤细胞)的剂。实例包括紫杉醇、细胞松弛素B、短杆菌肽D、溴化乙锭、吐根碱、丝裂霉素、依托泊苷、替诺泊苷、长春新碱、长春花碱、秋水仙碱、多柔比星、柔红霉素、二羟基蒽二酮、米托蒽醌、光神霉素、放线菌素D、1-去氢睾酮、糖皮质激素、普鲁卡因、丁卡因、利多卡因、普萘洛尔和嘌呤霉素及其类似物或同源物。治疗剂还包括,例如,抗代谢物(例如,氨甲蝶呤、6-巯基嘌呤、6-硫代鸟嘌呤、阿糖胞苷、5-氟尿嘧啶、氨烯咪胺)、消融剂(例如,氮芥、塞替派、苯丁酸氮芥、美法仑、卡莫司汀(BSNU)和洛莫司汀(CCNU)、环磷酰胺、白消安、二溴甘露醇、链脲佐菌素、丝裂霉素C和顺式二氯二胺铂(II)(DDP)、顺铂、蒽环类(例如,道诺霉素(daunorubicin)(先前称为道诺霉素(daunomycin))和多柔比星)、抗生素(例如,放线菌素(dactinomycin)(先前称为放线菌素(actinomycin))、博来霉素、光神霉素和安曲霉素(AMC)),以及抗有丝分裂剂(例如,长春新碱和长春花碱)。
“细胞因子”是由一个细胞群体释放的、作为细胞间介导物作用于另一个细胞的一类蛋白或肽。细胞因子可以作为免疫调节剂起作用。细胞因子的实例包括淋巴因子、单核因子、生长因子和传统多肽激素。因此,实施方案可以利用干扰素(例如,IFN-α、IFN-β和IFN-γ);肿瘤坏死因子超家族(TNFSF)成员;人类生长激素;甲状腺素;胰岛素;前胰岛素;松弛素;前松弛素;促卵泡激素(FSH);促甲状腺激素(TSH);促黄体生成激素(LH);肝生长因子;前列腺素、成纤维细胞生长因子;催乳素;胎盘泌乳激素、OB蛋白;TNF-α;TNF-β;整合素;血小板生成素(TPO);神经生长因子诸如NGF-β;血小板生长因子;TGF-α;TGF-β;胰岛素样生长因子-I和胰岛素样生长因子-II;促红细胞生成素(EPO);集落刺激因子(CSF)诸如巨噬细胞-CSF(M-CSF);粒细胞-巨噬细胞-CSF(GM-CSF);和粒细胞-CSF(G-CSF);白细胞介素(IL-1至IL-21)、kit-配体或FLT-3、血管抑制素、血小板反应蛋白或内皮生长抑素。这些细胞因子包括来自天然来源或来自重组细胞培养物的蛋白和天然序列细胞因子的生物学上有活性的等效物。
本发明的免疫缀合物可以用于修饰给定的生物应答,并且药物部分不应被解释为限于典型的化学治疗剂。例如,药物部分可以是具有期望的生物学活性的蛋白或多肽。这样的蛋白可以包括,例如,酶学上有活性的毒素或其活性片段,诸如相思豆毒蛋白(abrin)、蓖麻毒蛋白(ricin)A、假单胞菌外毒素(pseudomonas exotoxin)或白喉毒素(diphtheriatoxin);蛋白,诸如肿瘤坏死因子或干扰素-γ;或,生物应答修饰剂,诸如例如淋巴因子、白细胞介素-1(“IL-1”)、白细胞介素-2(“IL-2”)、白细胞介素-6(“IL-6”)、粒细胞巨噬细胞集落刺激因子(“GM-CSF”)、粒细胞集落刺激因子(“G-CSF”)或其他生长因子。
趋化因子也可以与本文公开的抗体缀合。趋化因子是一个小的(近似地约4kDa至约14kDa)、诱导型和分泌型促炎性细胞因子的超家族,主要作为特定白细胞亚型的化学引诱剂和活化剂起作用。趋化因子的产生由炎性细胞因子、生长因子和病原性刺激物诱导。趋化因子蛋白基于保守氨基酸序列基序分成子家族(α、β和δ),并且基于与氨基末端相邻的前两个半胱氨酸的位置分类成四个高度保守的组——CXC、CC、C和CX3C。迄今,已经发现多于50种趋化因子,并且至少存在18种人类七次跨膜结构域(7TM)趋化因子受体。使用的趋化因子包括但不限于RANTES、MCAF、MCP-1和fractalkine。
治疗剂可以是化学治疗剂。本领域技术人员可以容易地鉴定使用的化学治疗剂(例如参见Harrison的Principles of Internal Medicine,第14版的第86章,Slapak和Kufe,Principles of Cancer Therapy;Perry等人,Abeloff,Clinical Oncology2.sup.nd ed.中的第17章,Chemotherapy.COPYRIGHT.2000Churchill Livingstone,Inc;Baltzer L.,Berkery R.(编著):Oncology Pocket Guide to Chemotherapy,第2版.St.Louis,Mosby-Year Book,1995;Fischer D S,Knobf M F,Durivage H J(编著):TheCancer Chemotherapy Handbook,第4版.St.Louis,Mosby-Year Book,1993)。用于制备免疫缀合物的有用的化学治疗剂包括auristatin、海兔毒素(dolastatin)、MMAE、MMAF、AFP、DM1、AEB、多柔比星、柔红霉素、氨甲蝶呤、美法仑、苯丁酸氮芥、长春花生物碱类、5-氟尿苷、丝裂霉素-C、紫杉醇、L-天冬酰胺酶、巯基嘌呤、硫鸟嘌呤、羟基脲、阿糖胞苷、环磷酰胺、异环磷酰胺、亚硝基脲类、顺铂、卡铂、丝裂霉素、氮烯咪胺、丙卡巴肼、拓泊替康、氮芥类、环磷酰胺(cytoxan)、依托泊苷、BCNU、伊立替康、喜树碱、博来霉素、依达比星、更生霉素、普卡霉素、米托蒽醌、天冬酰胺酶、长春花碱、长春新碱、长春瑞滨、紫杉醇和多西他赛及其盐、溶剂化物或衍生物。在多种实施方案中,化学治疗剂是auristatin E(在本领域中也称作海兔毒素-10)或其衍生物以及其药学上的盐或溶剂化物。典型的auristatin衍生物包括DM1、AEB、AEVB、AFP、MMAF和MMAE。auristatin E及其衍生物,以及接头的合成和结构在例如美国专利申请公布第20030083263号;美国专利申请公布第20050238629号;和美国专利第6,884,869号(每篇文献通过引用以其整体并入本文)中描述。在多种实施方案中,治疗剂是auristatin或auristatin衍生物。在多种实施方案中,auristatin衍生物是dovaline-缬氨酸-dolaisoleunine-dolaproine-苯丙氨酸(MMAF)或monomethyauristatin E(MMAE)。在多种实施方案中,治疗剂是美登素(maytansinoid)或美登醇(maytansinol)类似物。在多种实施方案中,美登素是DM1。
效应物分子可以使用本领域技术人员已知的任何数目的手段连接至本发明的抗体或抗原结合片段。可以使用共价附接和非共价附接手段二者。将效应物分子附接至抗体的程序根据效应物分子的化学结构变化。多肽通常包含多种官能团;诸如羧酸(COOH)、游离胺(--NH
在一些情况中,期望当免疫缀合物已经到达其靶位点时,效应物分子从抗体中游离出来。因此,在这些情况中,免疫缀合物将包含在靶位点附近可裂解的连接。裂解接头以从抗体释放效应物分子可以由免疫缀合物在靶细胞中或在靶位点附近经历的酶促活性或条件来促进。
用于将抗体与效应物分子缀合的程序先前已经描述过,并且在本领域技术人员的范围内。例如,用于制备免疫毒素的酶学上有活性的多肽的程序在WO84/03508和WO85/03508中描述,该文献出于其具体教导的目的通过引用并入本文。其他技术在Shih等人,Int.J.Cancer 41:832-839(1988);Shih等人,Int.J.Cancer 46:1101-1106(1990);Shih等人,美国专利第5,057,313号;Shih Cancer Res.51:4192、国际公布WO 02/088172;美国专利第6,884,869号;国际专利公布WO2005/081711;美国公布的申请2003-0130189A;和美国专利申请第20080305044号中描述,出于教导这类技术的目的,每篇文献通过引用并入本文。
本发明的免疫缀合物保留抗体或抗原结合片段的免疫反应性,例如抗体或抗原结合片段在缀合后具有与缀合前近似相同、或仅略微降低的与抗原结合的能力。如本文使用的,免疫缀合物也被称作抗体药物缀合物(ADC)。
在另一方面,本发明提供了用于体外或体内检测样品中人类IL-17A抗原的存在的方法,例如,用于诊断人类IL-17A相关的疾病的方法。在一些方法中,这通过将待测试的样品连同对照样品与本发明的人类序列抗体或人类单克隆抗体或其抗原结合部分(或双特异性分子或多特异性分子)在允许抗体和人类IL-17A之间形成复合物的条件下接触来实现。然后在两个样品中检测(例如,使用ELISA)复合物形成,并且样品之间在复合物形成方面的任何统计上显著的差异都指示测试样品中人类IL-17A抗原的存在。
在多种实施方案中,提供了用于在受试者中检测癌症或确定癌症的诊断的方法。该方法包括将来自受试者的生物样品与本发明的分离的抗体或其抗原结合片段接触,并且检测分离的人类单克隆抗体或其抗原结合片段与样品的结合。与分离的人类单克隆抗体或其抗原结合片段与对照样品的结合相比,分离的人类单克隆抗体或其抗原结合片段与样品的结合的增加检测出受试者中的癌症或确定了受试者中的癌症的诊断。对照可以是来自已知不患有癌症的受试者的样品,或标准值。样品可以是任何样品,包括但不限于来自活组织检查、尸体解剖和病理标本的组织。生物样品还包括组织切片,例如,出于组织学目的采集的冷冻切片。生物样品还包括体液,诸如血液、血清、血浆、痰和脊髓液。
在一种实施方案中,提供了用于检测生物样品(诸如血液样品)中的IL-17A的试剂盒。用于检测多肽的试剂盒通常将包含与IL-17A特异性地结合的人类抗体,诸如本文公开的任何抗体。在一些实施方案中,抗体片段诸如Fv片段包括在试剂盒中。对于体内使用,抗体可以是scFv片段。在另外的实施方案中,抗体被标记(例如用荧光、放射性或酶标记物标记)。
在一种实施方案中,试剂盒包括公开了使用与IL-17A特异性地结合的抗体的手段的说明材料。说明材料可以以电子形式(诸如计算机软盘或光盘)编写,或可以是可视的(诸如视频文件)。试剂盒还可以包括促进试剂盒被设计用于其特定应用的另外的组分。因此,例如,试剂盒可以另外包含检测标记物的工具(means)(诸如用于酶标记物的酶底物、检测荧光标记物的过滤器组、适当的二级标记物诸如二级抗体等)。试剂盒可以另外地包含缓冲剂和常规用于实践特定方法的其他试剂。这样的试剂盒和适当的成分是本领域技术人员熟知的。
在一种实施方案中,诊断试剂盒包含免疫测定。尽管免疫测定的细节可以随使用的特定格式而变化,但检测生物样品中的IL-17A的方法通常包括将生物样品与抗体接触的步骤,所述抗体在免疫学反应条件下特异性地与IL-17A反应。允许抗体在免疫学反应条件下特异性地结合以形成免疫复合物,并且免疫复合物(结合的抗体)的存在被直接地或间接地检测。
在多种实施方案中,抗体或抗原结合片段可以被标记或可以不被标记以用于诊断目的。通常,诊断测定需要检测由抗体与IL-17A的结合得到的复合物的形成。抗体可以被直接地标记。可以使用多个标记物,包括但不限于放射性核素、荧光剂(fluorescer)、酶、酶底物、酶辅因子、酶抑制剂和配体(例如,生物素、半抗原)。许多适当的免疫测定是技术人员已知的(参见例如美国专利第3,817,827号;第3,850,752号;第3,901,654号;和第4,098,876号)。当未被标记时,抗体可以在测定,诸如凝集测定中使用。未标记的抗体还可以与另外的(一种或更多种)合适的试剂组合使用,所述试剂可以用于检测抗体,诸如与第一抗体(例如,抗独特型抗体或对未标记的免疫球蛋白特异性的其他抗体)反应的标记的抗体(例如第二抗体)或其他合适的试剂(例如,标记的蛋白A)。
本文提供的抗体或抗原结合片段还可以在检测哺乳动物对某些疾病的易感性的方法中使用。为了说明,该方法可以用于检测哺乳动物对疾病的易感性,所述疾病基于在细胞上存在的IL-17A的量和/或哺乳动物中的IL-17A阳性细胞的数目进展。在一种实施方案中,本申请提供了一种检测哺乳动物对肿瘤的易感性的方法。在该实施方案中,待测试的样品与结合IL-17A或其部分的抗体在适于所述抗体与其结合的条件下接触,其中样品包含正常个体中表达IL-17A的细胞。抗体的结合和/或结合的量被检测,指示个体对肿瘤的易感性,其中较高水平的受体与个体对肿瘤的增加的易感性相关。
在多种实施方案中,抗体或抗原结合片段被附接至能够被检测的标记物(例如,标记物可以是放射性同位素、荧光化合物、酶或酶辅因子)。活性部分可以是放射性剂,诸如:放射性重金属诸如铁螯合物、钆或锰的放射性螯合物、氧、氮、铁、碳或镓的正电子发射物、
使用针对IL-17A的抗体或抗原结合片段的免疫闪烁照相法可以用于检测和/或诊断癌症和血管系统。例如,针对用
在另一方面,本发明的特征在于包含本发明的抗IL-17A抗体或其抗原结合片段的双特异性分子。本发明的抗体或其抗原结合片段可以被衍生化或连接至另一种功能分子,例如另一种肽或蛋白(例如,另一种抗体或受体的配体),以生成与至少两种不同的结合位点或靶分子结合的双特异性分子。本发明的抗体可以事实上被衍生化或连接至多于一种其他功能分子,以生成与多于两种不同的结合位点和/或靶分子结合的多特异性分子;这样的多特异性分子还意图由如本文使用的术语“双特异性分子”所包括。为了产生本发明的双特异性分子,本发明的抗体可以功能性连接(例如通过化学偶联、遗传融合、非共价缔合或其他方式)至一种或更多种其他结合分子,诸如另一种抗体、抗体片段、肽或结合模拟物,使得双特异性分子产生。在多种实施方案中,本发明包括能够与表达FcγR或FcαR的效应细胞(例如单核细胞、巨噬细胞或多形核细胞(PMN))和与表达IL-17A的靶细胞二者结合的双特异性分子。在这样的实施方案中,双特异性分子将表达IL-17A的细胞靶向至效应细胞,并且触发Fc受体介导的效应细胞活性,例如,表达IL-17A的细胞的吞噬作用、抗体依赖性细胞介导的细胞毒性(ADCC)、细胞因子释放或超氧阴离子的生成。制备本发明的双特异性分子的方法是本领域中熟知的。
本申请还提供了包含编码抗IL-17A抗体或其抗原结合片段的核苷酸序列的多核苷酸。由于遗传密码的简并性,每种抗体氨基酸序列由许多核酸序列编码。本申请还提供了在例如,如本文定义的严格的杂交条件或较低严格的杂交条件下与编码与人类IL-17A结合的抗体的多核苷酸杂交的多核苷酸。
严格的杂交条件包括但不限于,在约45℃与在6×SSC中的过滤器结合的DNA杂交,随后是在约50-65℃在0.2×SSC/0.1%SDS中洗涤一次或更多次,高度严格的条件诸如在约45℃与在6×SSC中的过滤器结合的DNA杂交随后是在约60℃在0.1×SSC/0.2%SDS中洗涤一次或更多次,或本领域技术人员已知的任何其他严格的杂交条件(参见例如Ausubel,F.M.等人,编著1989Current Protocols in Molecular Biology,第1卷,GreenPublishing Associates,Inc.和John Wiley and Sons,Inc.,NY,在6.3.1页至6.3.6页和2.10.3页)。
可以通过本领域中已知的任何方法获得多核苷酸并确定多核苷酸的核苷酸序列。例如,如果抗体的核苷酸序列是已知的,则编码抗体的多核苷酸可以从化学合成的寡核苷酸组装(例如如Kutmeier等人,BioTechiques17:242(1994)中描述的),简而言之,其包括合成包含编码抗体的序列的部分的重叠寡核苷酸、退火和连接这些寡核苷酸、并且然后通过PCR扩增连接的寡核苷酸。在一种实施方案中,使用的密码子包括对于人类或小鼠而言是典型的那些密码子(参见例如Nakamura,Y.,Nucleic Acids Res.28:292(2000))。
编码抗体的多核苷酸还可以由来自合适的来源的核酸生成。如果包含编码特定抗体的核酸的克隆无法获得,但抗体分子的序列是已知的,那么编码免疫球蛋白的核酸可以化学地合成或从合适的来源(例如,抗体cDNA文库,或从表达抗体的任何组织或细胞生成的cDNA文库,或从表达抗体的任何组织或细胞分离的核酸,优选polyA+RNA,所述组织或细胞诸如被选择表达抗体的杂交瘤细胞)获得,所述获得通过使用与序列的3’末端和5’末端可杂交的合成引物的PCR扩增进行,或通过使用对特定基因序列特异性的寡核苷酸探针进行克隆以鉴定例如来自编码抗体的cDNA文库的cDNA克隆。然后,通过PCR生成的扩增的核酸可以用本领域熟知的任何方法克隆到可复制的克隆载体中。
本发明还涉及表达本发明的IL-17A多肽和/或抗IL-17A抗体的宿主细胞。本领域中已知的许多种宿主表达系统可以用于表达本发明的抗体,包括原核(细菌)表达系统和真核表达系统(诸如酵母、杆状病毒(baculovirus)、植物、哺乳动物和其他动物细胞、转基因动物和杂交瘤细胞),以及噬菌体展示表达系统。
本发明的抗体可以通过在宿主细胞中重组表达免疫球蛋白轻链和重链基因来制备。为了重组地表达抗体,用一种或更多种携带编码抗体的免疫球蛋白轻链和/或重链的DNA片段的重组表达载体将宿主细胞转化、转导、感染等,使得轻链和/或重链在宿主细胞中被表达。重链和轻链可以独立地从它们在一个载体中可操作地连接的不同的启动子表达,或可选地,重链和轻链可以独立地从在两个载体中可操作地连接的不同的启动子表达,一个载体表达重链并且一个载体表达轻链。任选地,重链和轻链可以在不同宿主细胞中表达。
另外地,重组表达载体可以编码促进抗体轻链和/或重链从宿主细胞分泌的信号肽。抗体轻链和/或重链基因可以被克隆到载体中,使得信号肽在框架内可操作地连接至抗体链基因的氨基末端。信号肽可以是免疫球蛋白信号肽或异源信号肽。优选地,重组抗体被分泌到培养宿主细胞的培养基中,从培养基中可以回收或纯化抗体。
编码HCVR的分离的DNA可以通过将编码HCVR的DNA可操作地连接至编码重链恒定区的另一种DNA分子而转化为全长重链基因。人类以及其他哺乳动物重链恒定区基因的序列在本领域中是已知的。包含这些区域的DNA片段可以通过例如标准PCR扩增来获得。重链恒定区可以是任何类型(例如,IgG、IgA、IgE、IgM或IgD)、类别(例如,IgG
编码LCVR区的分离的DNA可以通过将编码LCVR的DNA可操作地连接至编码轻链恒定区的另一种DNA分子而转化为全长轻链基因(以及转化为Fab轻链基因)。人类以及其他哺乳动物轻链恒定区基因的序列在本领域中是已知的。包含这些区域的DNA片段可以通过标准PCR扩增来获得。轻链恒定区可以是κ或λ恒定区。
除了一种或更多种抗体重链和/或轻链基因之外,本发明的重组表达载体携带控制一种或更多种抗体链基因在宿主细胞中表达的调控序列。术语“调控序列”意图如需要的包括启动子、增强子和控制一种或更多种抗体链基因的转录或翻译的其他表达控制元件(例如,多腺苷酸化信号)。表达载体的设计,包括调控序列的选择,可以取决于诸如待转化的宿主细胞的选择、期望的蛋白的表达的水平等因素。用于哺乳动物宿主细胞表达的优选的调控序列包括指导哺乳动物细胞中高水平的蛋白表达的病毒元件,诸如来源于巨细胞病毒(CMV)、猴病毒40(SV40)、腺病毒(例如,腺病毒主要晚期启动子(AdMLP))和/或多瘤病毒的启动子和/或增强子。
另外地,本发明的重组表达载体可以携带另外的序列,诸如调控载体在宿主细胞中的复制的序列(例如,复制起点)和一个或更多个可选择标志物基因。可选择标志物基因促进已经引入载体的宿主细胞的选择。例如,通常,可选择标志物基因赋予已经引入载体的宿主细胞对药物诸如G418、潮霉素或氨甲蝶呤的抗性。优选的可选择标志物基因包括二氢叶酸还原酶(dhfr)基因(用于在用氨甲蝶呤选择/扩增的dhfr阴性宿主细胞中使用)、neo基因(用于G418选择)和在用于选择/扩增的谷氨酰胺合成酶(GS)阴性细胞系(诸如NSO)中的GS。
为了表达轻链和/或重链,编码重链和/或轻链的一个或更多个表达载体通过标准技术,例如电穿孔、磷酸钙沉淀、DEAE-葡聚糖转染、转导、感染等引入宿主细胞中。尽管在原核宿主细胞或真核宿主细胞中表达本发明的抗体理论上是可能的,但真核细胞是优选的,并且最优选哺乳动物宿主细胞,因为这样的细胞更有可能组装和分泌恰当地折叠的和免疫学上有活性的抗体。用于表达本发明的重组抗体的优选的哺乳动物宿主细胞包括中国仓鼠卵巢(CHO细胞)[包括dhfr阴性CHO细胞,如Urlaub和Chasin,Proc.Natl.Acad.Sci.USA 77:4216-20,1980中描述的,与DHFR可选择标志物一起使用,例如,如Kaufman和Sharp,J.Mol.Biol.159:601-21,1982中描述的]、NSO骨髓瘤细胞、COS细胞和SP2/0细胞。当编码抗体基因的重组表达载体被引入哺乳动物宿主细胞中时,抗体通过将宿主细胞培养持续足以允许抗体在宿主细胞中表达的时间段来产生,或更优选地,将抗体分泌到其中宿主细胞在本领域中已知的适当条件下生长的培养基中。抗体可以使用标准纯化方法从宿主细胞和/或培养基回收。
本发明提供了包含根据本发明的核酸分子的宿主细胞。优选地,本发明的宿主细胞包含一种或更多种包含本发明的核酸分子的载体或构建体。例如,本发明的宿主细胞是已经引入本发明的载体的细胞,所述载体包含编码本发明的抗体的LCVR的多核苷酸和/或编码本发明的HCVR的多核苷酸。本发明还提供了一种已经引入本发明的两种载体的宿主细胞;一种载体包含编码本发明的抗体的LCVR的多核苷酸,并且一种载体包含编码在本发明的抗体中存在的HCVR的多核苷酸,并且每种多核苷酸可操作地连接至增强子/启动子调控元件(例如,来源于SV40、CMV、腺病毒等,诸如CMV增强子/AdMLP启动子调控元件或SV40增强子/AdMLP启动子调控元件),以驱动基因的高水平的转录。
表达之后,本发明的完整抗体、单个轻链和重链或其他免疫球蛋白形式可以根据本领域的标准程序纯化,包括硫酸铵沉淀、离子交换、亲和(例如蛋白A)、反相、疏水相互作用柱色谱、羟基磷灰石色谱、凝胶电泳等。治疗性抗体的纯化的标准程序例如由Feng L1,Joe X.Zhou,Xiaoming Yang,Tim Tressel和Brian Lee在题为“Current TherapeuticAntibody Production and Process Optimization”的文章(BioProcessing Journal,2005年9月/10月)(出于教导治疗性抗体的纯化的目的,通过引用以其整体并入)中描述。另外,用于从重组地表达的抗体制剂去除病毒的标准技术也是本领域已知的(参见例如GerdKern和Mani Krishnan,“Viral Removal by Filtration:Points to Consider”(BiopharmInternational,2006年10月))。已知从治疗性抗体的制剂去除病毒的过滤的有效性至少部分取决于待过滤的溶液的蛋白和/或抗体的浓度。用于本发明的抗体的纯化过程可以包括过滤以从一个或更多个色谱操作的主流中去除病毒的步骤。优选地,在过滤通过药物级纳米过滤器以去除病毒之前,稀释或浓缩包含本发明的抗体的色谱主流,以给予约1g/L至约3g/L的总蛋白浓度和/或总抗体浓度。甚至更优选地,纳米过滤器是DV20纳米过滤器(例如Pall Corporation;East Hills,N.Y.)。优选至少约90%、约92%、约94%或约96%同质性的,并且最优选约98%至约99%或更高同质性的基本纯的免疫球蛋白用于制药用途。一旦如期望的部分纯化或纯化至同质性,然后无菌抗体可以如本文指导的被治疗上使用。
鉴于上文提及的讨论,本发明还涉及通过包括培养宿主细胞使得核酸被表达并且任选地,从宿主细胞培养基回收抗体的步骤的方法可获得的抗体,所述宿主细胞包括但不限于已经被包含编码本发明的抗体的核酸分子的多核苷酸或载体转化的哺乳动物、植物、细菌、转基因动物或转基因植物细胞。
在某些方面,本申请提供了杂交瘤细胞系,以及由这些杂交瘤细胞系产生的单克隆抗体。所公开的细胞系具有除了用于产生单克隆抗体之外的其他用途。例如,细胞系可以与其他细胞(诸如合适地药物标记的人类骨髓瘤、小鼠骨髓瘤、人类-小鼠杂合骨髓瘤或人类类淋巴母细胞细胞)融合以产生另外的杂交瘤,并且因此提供编码单克隆抗体的基因的转移。此外,细胞系可以用作编码抗IL-17A免疫球蛋白链的核酸的来源,其可以被分离和表达(例如,在使用任何合适的技术转移至其他细胞时)(参见例如Cabilly等人,美国专利第4,816,567号;Winter,美国专利第5,225,539号))。例如,包含重排的抗IL-17A轻链或重链的克隆可以被分离(例如,通过PCR),或cDNA文库可以从由细胞系分离的mRNA制备,并且编码抗IL-17A免疫球蛋白链的cDNA克隆可以被分离。因此,编码抗体的重链和/或轻链或其部分的核酸可以根据用于在多种宿主T细胞中或体外翻译系统中产生特异性免疫球蛋白、免疫球蛋白链或其变体(例如,人源化免疫球蛋白)的重组DNA技术获得和使用。例如,编码变体诸如人源化免疫球蛋白或免疫球蛋白链的核酸,包括cDNA或其衍生物,可以被放置到合适的原核载体或真核载体(例如表达载体)中,并且通过适当的方法(例如转化、转染、电穿孔、感染)引入合适的宿主T细胞中,使得核酸可操作地连接至一个或更多个表达控制元件(例如在载体中或整合到宿主T细胞基因组中)。为了产生,宿主T细胞可以被维持在适于表达的条件下(例如在诱导剂的存在下、补充有适当的盐、生长因子、抗生素、营养补充剂等的合适的培养基),由此产生编码的多肽。如果期望,可以回收和/或分离编码的蛋白(例如从宿主T细胞或培养基)。将理解,生产的方法包括在转基因动物的宿主T细胞中的表达(参见例如1992年3月19日公布的GenPharm International的WO 92/03918)(通过引用以其整体并入)。
宿主细胞也可以用于通过常规的技术产生完整抗体的部分或片段,例如Fab片段或scFv分子。例如,可以期望用编码本发明的抗体的轻链或重链的DNA转染宿主细胞。重组DNA技术还可以用于去除编码对于与人类IL-17A结合而言不必需的轻链和重链之一或二者的一些或所有DNA。本发明的抗体还包括从这样的截短的DNA分子表达的分子。
已经描述了用于从细菌诸如大肠杆菌(E.coli)表达单链抗体和/或再折叠成适当的活性形式,包括单链抗体的方法,并且这些方法是熟知的,并且适用于本文公开的抗体(参见例如Buchner等人,Anal.Biochem.205:263-270,1992;Pluckthun,Biotechnology 9:545,1991;Huse等人,Science246:1275,1989和Ward等人,Nature 341:544,1989,全部通过引用并入本文)。
通常,来自大肠杆菌或其他细菌的有功能的异源蛋白从包涵体分离,并且需要使用强变性剂增溶,并且随后再折叠。在增溶步骤期间,如本领域中熟知的,还原剂必须存在以分离二硫键。具有还原剂的示例性缓冲液是:0.1M Tris pH 8、6M胍、2mM EDTA、0.3M DTE(二硫代赤藓糖醇)。二硫键的再氧化可以在呈还原的和氧化的形式的低分子量硫醇试剂的存在的情况中发生,如在Saxena等人,Biochemistry 9:5015-5021,1970中描述的(通过引用并入本文),并且特别地如由Buchner等人上文描述的。
复性通常通过将变性的且还原的蛋白稀释(例如,100倍)到再折叠缓冲液中来实现。示例性缓冲液是0.1M Tris,pH 8.0、0.5M L-精氨酸、8mM氧化的谷胱甘肽(GSSG)和2mMEDTA。
作为对双链抗体纯化方案的修改,重链区和轻链区被单独地增溶和还原,并且然后在再折叠溶液中组合。当这两种蛋白以使得一种蛋白相对于另一种蛋白不超过5倍摩尔过量的摩尔比混合时,获得了示例性产率。在氧化还原改组完成后,可以将过量的氧化的谷胱甘肽或其他氧化低分子量化合物添加至再折叠溶液。
除了重组方法之外,本文公开的抗体、标记的抗体及其抗原结合片段还可以全部或部分使用标准的肽合成来构建。长度小于约50个氨基酸的多肽的固相合成可以通过将序列的C-末端氨基酸附接至不可溶的支持物,随后顺序添加在序列中的剩余的氨基酸来完成。用于固相合成的技术由Barany&Merrifield,The Peptides:Analysis,Synthesis,Biology.第2卷:Special Methods in Peptide Synthesis,A部分3-284页;Merrifield等人,J.Am.Chem.Soc.85:2149-2156,1963,和Stewart等人,Solid Phase PeptideSynthesis,第2版,Pierce Chem.Co.,Rockford,Ill.,1984描述。较大长度的蛋白可以通过较短的片段的氨基末端和羧基末端的缩合来合成。通过羧基末端的活化来形成肽键的方法(诸如通过使用偶联剂N,N’-二环己基碳二亚胺)是本领域熟知的。
提供以下实施例以更充分地说明本发明,但以下实施例不应被理解为限制本发明的范围。
特异性地靶向人类IL-17A的单克隆抗体的生成
对Balb/c(22g,6-8周)、C57Bl/6(22g,6-8周)和SJL(18g-20g,6-8周)小鼠免疫接种三次(每隔一周)。对于第1次免疫接种,用每只小鼠50μg的IL-17A蛋白(R&D Systems,Cat#3012)对小鼠进行皮下免疫接种。抗原以与完全弗氏佐剂(Sigma,St.Louis,MO)的1:1的混合物注射。对于第2次和第3次免疫接种,用每只小鼠25μg的IL-17A蛋白对小鼠进行腹膜内免疫接种。在第2次和第3次给药时,抗原以与不完全弗氏佐剂(Sigma,St.Louis,MO)的1:1的混合物注射。用25μg的IL-17A腹膜内给予小鼠最终加强,并且在4天后收获脾细胞用于与来自ATCC(Allendale,NJ)的骨髓瘤细胞系NS0融合。使用电融合方法获得杂交瘤细胞,并且然后针对抗原结合、配体阻断、IgG分箱(binning)、参考抗体结合和FACS结合对杂交瘤上清液进行筛选。最终从初始筛选中选择20种鼠mAb用于亚克隆(有限稀释法)。使用BD细胞MAb培养基使杂交瘤在滚瓶中生长,以用于收集上清液用于抗体生产。mAb用蛋白A亲和色谱纯化。基于SDS-PAGE考马斯染色,mAb的估计纯度高于90%。选择17种纯化的mAb(7B9D6、9D8E4、13E6F10、25E4F11、23A4D8、22E2G4、4H11C7、28C8D3、26G11B11、8A5G4、11D1C8、24F11E4、27D1C4、3A8F7、13E4E2、25D7F7和24B2G11)进行二次筛选,二次筛选包括:人类IL-17A结合测定(ELISA)、IL-17a/IL-17R阻断测定(ELISA)、鼠IL-17A交叉反应性测定(ELISA)、灵长类动物IL-17交叉反应性测定(ELISA)、体外TNFα引发的NIH3T3细胞功能测定和表位分箱筛选。
17种鼠mAb的二次测定数据总结于图1和图2和表3中:
如图1、图2和表3中描绘的,抗IL-17A鼠单克隆抗体以高亲和力结合人类和灵长类动物IL-17A。
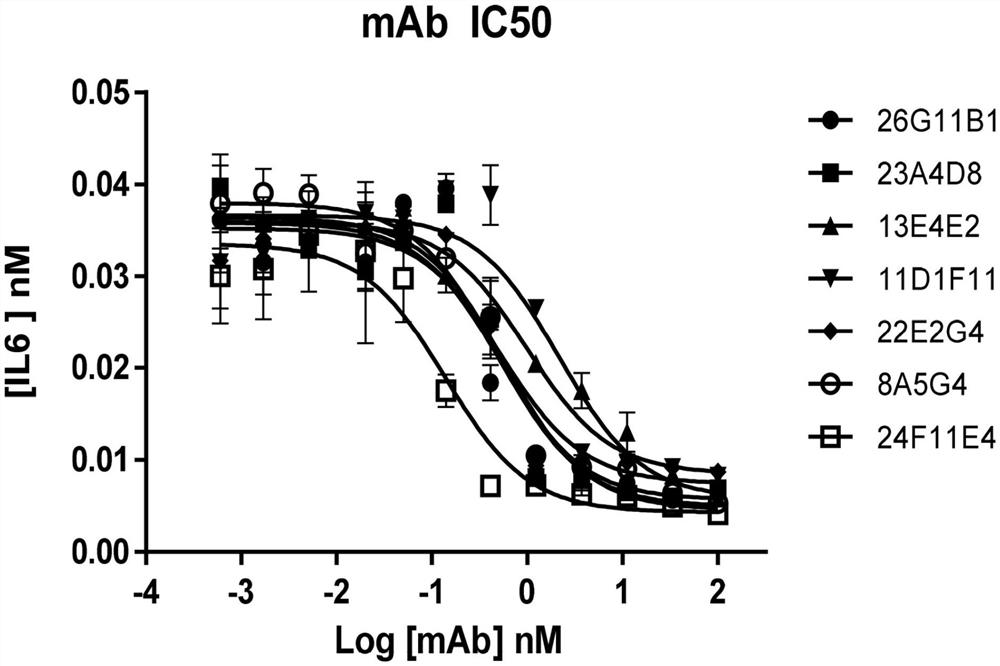
使用以TNFα引发的NIH3T3细胞的体外功能测定被用于评价17种抗IL-17A鼠单克隆抗体组的效力。在该系统中用人类IL17A的刺激诱导IL6炎性细胞因子的浓度依赖性表达和分泌(图3)。(Yao,Z.,等人,Immunity,1995.3(6):p.811-21,1995;Gaffen,S.L.,Naturereviews.Immunology,9(8):p.556,2009)。NIH3T3功能测定使用固定在3.1nM的IL17浓度和0.5ng/mL的TNFα,使用0.6pM至100nM的范围内的抗体进行。简而言之,在第1天,将DMEM+10%FBS中的NIH3T3细胞与参考抗体预孵育30分钟,并且然后向细胞中添加0.5ng/mL TNFα和20ng/mL IL-17A。在第2天,收获细胞上清液,并且进行ELISAIL-17A测定,以IL6产生作为读出。
体外NIH3T3功能测定评价的结果描绘在图4、图5和表4中:
如图4、图5和表4中描绘的,确定了所述mAb中的几个抑制了对IL17R的刺激,具有临床mAb治疗所需的亚纳摩尔IC50。
基于二次测定的累积结果,选择纯化的鼠mAb 4H11C7(“A1”)、8A5G4(“A2”)、22E2G4(“A3”)、23A4D8(“A4”)、24F11E4(“A5”)和26G11B11(“A6”)用于测序和进一步分析。遵循
靶向人类IL-17A的嵌合IgG4的生成
使用mAb 23A4D8(“A4”)的HCVR序列和LCVR序列,制备了鼠-人类IgG4嵌合Fab(下文称为“嵌合IgG4”),所述鼠-人类IgG4嵌合Fab包含SEQ ID NO:54中列出的重链序列和SEQID NO:56中列出的轻链序列。嵌合IgG4的重链和轻链分别由SEQ ID NO:55和57中列出的核酸编码。将由SEQ ID NO:55和SEQ ID NO:57编码的包含前导序列的核酸扩增并插入到pTT5中,以制备全长嵌合IgG4的表达质粒。将重链和轻链表达质粒用于共转染100mL HEK293-6E细胞。使用蛋白A亲和纯化分泌至培养基的重组IgG4。纯化的抗体使用PD-10脱盐柱缓冲液交换到PBS中。在非还原条件下的SDS-PAGE中,纯化的嵌合IgG4作为~170kDa条带迁移,在还原条件下的SDS-PAGE中,纯化的嵌合IgG4作为~55kDa条带和~30kDa条带迁移。嵌合IgG4的纯度为>85%,并且来自100mL培养物的产量为~2.4mg/L。
嵌合IgG4与抗原IL-17A之间的结合亲和力使用表面等离子共振(SPR)生物传感器Biacore T200(GE Healthcare)确定。嵌合IgG4通过胺偶联法固定于传感器芯片上。将抗原IL-17A蛋白用作分析物。解离(k
特异性靶向人类IL-17A的人源化Ab的生成
CDR接枝和回复突变方法用于制备来源于鼠mAb 23A4D8(“A4”)的人源化抗IL-17AmAb。简而言之,将亲本鼠抗体A4的CDR接枝到人类接受者中,以获得亲本抗体的人源化轻链和人源化重链。针对VH和VL选择的人类接受者分别是GenBank AAP97932.1和AKU38886.1。人类接受者的CDR和HV环被它们的小鼠对应物替代(CDR接枝),这给出了接枝的抗体的序列。接枝的抗体中的CDR中的典型残基、框架区和VH-VL界面上的残基被认为对结合活性是重要的,被选择为用亲本抗体对应物替代。进行IL-17A抗体Fv片段的同源性建模。针对PDB_Antibody数据库对IL-17A序列进行BLAST搜索,用于鉴定Fv片段的最佳模板,并且特别是用于构建结构域界面。选择结构模板1I3G(氨苄青霉素单链fv的晶体结构,形式1),同一性=75%。总共存在16种氨基酸被鉴定为用于替换。然后在HEK293细胞中表达回复突变的抗体并进行评估。基于评估,构建用于筛选主要人源化抗体的人源化重链被命名为H1、H2、H3和H4并且分别包含SEQ ID NO:66、70、74和78中列出的序列,而产生的人源化轻链被命名为L1、L2、L3和L4并且分别包含SEQ ID NO:68、72、76和80中列出的序列。
使用H1-H4和L1-L4的多种组合,在HEK 293-6E细胞中表达了16种人源化抗体。简而言之,将由SEQ ID NO:67(H1)、71(H2)、75(H3)或79(H4)中任一项和SEQ ID NO:69(L1)、73(L2)、77(L3)或81(L4)中任一项编码的核酸(各自包含前导序列)扩增,并插入到pTT5中以制备全长IgG的表达质粒。将重链和轻链表达质粒用于共转染100mL HEK293-6E细胞。使用蛋白A亲和纯化分泌至培养基的重组IgG。纯化的抗体使用PD-10脱盐柱缓冲液交换到PBS中。在非还原条件下的SDS-PAGE中,纯化的IgG以~170kDa条带迁移,并且来自100mL培养物的产量大于20mg/L。16种人源化IL-17A抗体的HC和LC氨基酸序列总结于表6中:
使用Biacore T200(GE Healthcare)对16种人源化IgG进行亲和力排序。使用胺偶联法将抗人类Fcγ特异性抗体固定于传感器芯片上。将分泌到培养基中的16种人源化抗体加上亲本抗体单独地注入并且经由Fc被抗人类Fc抗体捕获(捕获阶段)。在平衡后,注入AgIL-17A持续300秒(缔合阶段),随后是注入运行缓冲液持续900s(解离阶段)。从在每个循环期间人源化抗体流动池的那些响应减去参考流动池(流动池1)的响应。将表面再生,然后注入其他人源化抗体。重复该过程,直到所有抗体被分析。使用Biacore T200评价软件将实验数据局部地拟合到1∶1相互作用模型,获得人源化抗体的解离速率(off-rate)。抗体通过其解离速率常数(解离速率,k
基于亲和力排序,选择三种IgG:1)IgG 1(H1/L1)(在下文也被称为“REMD 155”);2)IgG 2(H1/L2)(在下文也被称为“REMD 155.1”);和3)IgG4(H1/L4)(在下文也被称为“REMD 155.2”)用于在HEK293细胞培养物中表达。重组IgG分泌到培养基中,并使用蛋白A亲和色谱纯化。根据SDS-PAGE评价,人源化IgG的纯度均超过90%。与IL-17A结合的纯化抗体的亲和力使用表面等离子共振(SPR)生物传感器Biacore 8k确定。通过胺偶联法将抗体固定于传感器芯片上。抗原IL-17A用作分析物。解离(k
如表7中描绘的,3种人源化抗体保持与嵌合抗体可比较的抗原结合亲和力。
然后在实施例1中描述的NIH3T3体外功能测定中评价3种人源化抗体。结果总结于表8中:
如表8中描绘的,3种人源化抗体抑制了IL-6的产生,具有临床mAb治疗所需的IC50。
本文公开和请求保护的所有的物品和方法鉴于本公开内容均可被制备和执行,无需过度实验。尽管已经根据优选的实施方案描述了本发明的物品和方法,但对本领域技术人员而言将是明显的是,变化形式可以被应用至所述物品和方法而不偏离本发明的精神和范围。对于本领域技术人员明显的所有这类变化形式和等效物,无论是现有的或以后开发的,都被认为是在本发明的精神和范围中,如由所附权利要求限定的。在说明书中提及的所有专利、专利申请和出版物指示本发明所属领域的普通技术人员的水平。出于所有目的,所有专利、专利申请和出版物通过引用以其整体并入本文,并且其程度如同每个单独的出版物具体地并且单独地被指示出于任何和所有目的通过引用以其整体并入。本文示例性地描述的本发明可以在本文未具体地公开的任何一个或更多个要素不存在的条件下被合适地实践。因此,应理解,尽管本发明已经通过优选的实施方案和任选的特征被具体地公开,但是本领域技术人员可以寻求本文所公开的概念的修改和变化形式,并且认为这类修改和变化形式在本发明的如由所附权利要求限定的范围中。
序列表
如在37C.F.R.1.822中规定的,在随附的序列表中使用核苷酸碱基的标准字母缩写和氨基酸的三字母编码示出了列出的核酸和氨基酸序列。
SEQ ID NO:1是人类IL-17A多肽的氨基酸序列。
SEQ ID NO:2-6是与IL-17A特异性地结合的单克隆抗体中的重链CDR1的氨基酸序列。
SEQ ID NO:7-12是与IL-17A特异性地结合的单克隆抗体中的重链CDR2的氨基酸序列。
SEQ ID NO:13-17是与IL-17A特异性地结合的单克隆抗体中的重链CDR3的氨基酸序列。
SEQ ID NO:18-21是与IL-17A特异性地结合的单克隆抗体中的轻链CDR1的氨基酸序列。
SEQ ID NO:22-24是与IL-17A特异性地结合的单克隆抗体中的轻链CDR2的氨基酸序列。
SEQ ID NO:25-29是与IL-17A特异性地结合的单克隆抗体中的轻链CDR3的氨基酸序列。
SEQ ID NO:30、32、34、36、39和40是与IL-17A特异性地结合的鼠单克隆抗体的重链可变区的氨基酸序列。
SEQ ID NO:31、33、35、37、39和41是编码与IL-17A特异性地结合的鼠单克隆抗体的重链可变区的核酸序列。
SEQ ID NO:42、44、46、48、50和52是与IL-17A特异性地结合的鼠单克隆抗体的轻链可变区的氨基酸序列。
SEQ ID NO:43、45、47、49、51和53是编码与IL-17A特异性地结合的鼠单克隆抗体的轻链可变区的核酸序列。
SEQ ID NO:54是与IL-17A特异性地结合的鼠-人类嵌合抗体的重链的氨基酸序列。
SEQ ID NO:55是与IL-17A特异性地结合的鼠-人类嵌合抗体的重链的核酸序列。
SEQ ID NO:56是与IL-17A特异性地结合的鼠-人类嵌合抗体的轻链的氨基酸序列。
SEQ ID NO:57是与IL-17A特异性地结合的鼠-人类嵌合抗体的轻链的核酸序列。
SEQ ID NO:58、60、62和64是与IL-17A特异性地结合的人源化单克隆抗体的重链可变区的氨基酸序列。
SEQ ID NO:59、61、63和65是与IL-17A特异性地结合的人源化单克隆抗体的轻链可变区的氨基酸序列。
SEQ ID NO:66、70、74和78是与IL-17A特异性地结合的人源化单克隆抗体的重链的氨基酸序列。
SEQ ID NO:67、71、75和79是与IL-17A特异性地结合的人源化单克隆抗体的重链的核酸序列。
SEQ ID NO:68、72、76和80是与IL-17A特异性地结合的人源化单克隆抗体的轻链的氨基酸序列。
SEQ ID NO:69、73、77和81是与IL-17A特异性地结合的人源化单克隆抗体的轻链的核酸序列。
SEQ ID NO:82和83是与IL-17A特异性地结合的单克隆抗体的轻链恒定区的氨基酸序列。
SEQ ID NO:84是与IL-17A特异性地结合的单克隆抗体的重链恒定区的氨基酸序列。
序列表
SEQ ID NO:1-IL-17A抗原氨基酸序列
SEQ ID NO:2-鼠单克隆抗体重链CDR1氨基酸序列
TFGMGVD
SEQ ID NO:3-鼠单克隆抗体重链CDR1氨基酸序列
SYGVY
SEQ ID NO:4-鼠单克隆抗体重链CDR1氨基酸序列
SYWMH
SEQ ID NO:5-鼠单克隆抗体重链CDR1氨基酸序列
DYYMN
SEQ ID NO:6-鼠单克隆抗体重链CDR1氨基酸序列
NYWIH
SEQ ID NO:7-鼠单克隆抗体重链CDR2氨基酸序列
HIWWDDDKYYNPALES
SEQ ID NO:8-鼠单克隆抗体重链CDR2氨基酸序列
VIWSDGTTTYNSALKS
SEQ ID NO:9-鼠单克隆抗体重链CDR2氨基酸序列
EIDPSDTYTNYNPKFKG
SEQ ID NO:10-鼠单克隆抗体重链CDR2氨基酸序列
DINPKNGGTIFNQNFRG
SEQ ID NO:11-鼠单克隆抗体重链CDR2氨基酸序列
EIDPSDTFTNYSPKFKG
SEQ ID NO:12-鼠单克隆抗体重链CDR2氨基酸序列
EIDPSDSYTNYNQKFKG
SEQ ID NO:13-鼠单克隆抗体重链CDR3氨基酸序列
RELGPYFFDY
SEQ ID NO:14-鼠单克隆抗体重链CDR3氨基酸序列
QGDNYSYAVDY
SEQ ID NO:15-鼠单克隆抗体重链CDR3氨基酸序列
SGIYYDYYEDY
SEQ ID NO:16-鼠单克隆抗体重链CDR3氨基酸序列
SILTGPFYFDY
SEQ ID NO:17-鼠单克隆抗体重链CDR3氨基酸序列
SGIYYDYYEDY
SEQ ID NO:18-鼠单克隆抗体轻链CDR1氨基酸序列
RSSQSIVHSNGNTYLE
SEQ ID NO:19-鼠单克隆抗体轻链CDR1氨基酸序列
RSSQSLVHSNGNTYLH
SEQ ID NO:20-鼠单克隆抗体轻链CDR1氨基酸序列
RSSQILLHSNGNTYLH
SEQ ID NO:21-鼠单克隆抗体轻链CDR1氨基酸序列
KASQSVSFAGTGLMH
SEQ ID NO:22-鼠单克隆抗体轻链CDR2氨基酸序列
KVSNRFS
SEQ ID NO:23-鼠单克隆抗体轻链CDR2氨基酸序列
KVFNRFS
SEQ ID NO:24-鼠单克隆抗体轻链CDR2氨基酸序列
RASNLEA
SEQ ID NO:25-鼠单克隆抗体轻链CDR3氨基酸序列
FQGSHFPYT
SEQ ID NO:26-鼠单克隆抗体轻链CDR3氨基酸序列
SQSTHAPLT
SEQ ID NO:27-鼠单克隆抗体轻链CDR3氨基酸序列
SQSVHVPT
SEQ ID NO:28-鼠单克隆抗体轻链CDR3氨基酸序列
QQTMEYPT
SEQ ID NO:29-鼠单克隆抗体轻链CDR3氨基酸序列
SQSIHVPT
SEQ ID NO:30-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:31-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:32-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:33-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:34-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:35-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:36-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:37-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:38-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:39-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:40-鼠单克隆抗体重链可变区氨基酸序列
SEQ ID NO:41-鼠单克隆抗体重链可变区核酸序列
SEQ ID NO:42-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:43-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:44-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:45-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:46-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:47-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:48-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:49-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:50-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:51-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:52-鼠单克隆抗体轻链可变区氨基酸序列
SEQ ID NO:53-鼠单克隆抗体轻链可变区核酸序列
SEQ ID NO:54-鼠-人类嵌合抗体的重链氨基酸序列
SEQ ID NO:55-鼠-人类嵌合抗体的重链核酸序列
SEQ ID NO:56-鼠-人类嵌合抗体的轻链氨基酸序列
SEQ ID NO:57-鼠-人类嵌合抗体的轻链核酸序列
SEQ ID NO:58-人源化重链可变区氨基酸序列
SEQ ID NO:59-人源化轻链可变区氨基酸序列
SEQ ID NO:60-人源化重链可变区氨基酸序列
SEQ ID NO:61-人源化轻链可变区氨基酸序列
SEQ ID NO:62-人源化重链可变区氨基酸序列
SEQ ID NO:63-人源化轻链可变区氨基酸序列
SEQ ID NO:64-人源化重链可变区氨基酸序列
SEQ ID NO:65-人源化轻链可变区氨基酸序列
SEQ ID NO:66-人源化重链氨基酸序列
SEQ ID NO:67-人源化重链核酸序列
SEQ ID NO:68-人源化轻链氨基酸序列
SEQ ID NO:69-人源化轻链核酸序列
SEQ ID NO:70-人源化重链氨基酸序列
SEQ ID NO:71-人源化重链核酸序列
SEQ ID NO:72-人源化轻链氨基酸序列
SEQ ID NO:73-人源化轻链核酸序列
SEQ ID NO:74-人源化重链氨基酸序列
SEQ ID NO:75-人源化重链核酸序列
SEQ ID NO:76-人源化轻链氨基酸序列
SEQ ID NO:77-人源化轻链核酸序列
SEQ ID NO:78-人源化重链氨基酸序列
SEQ ID NO:79-人源化重链核酸序列
SEQ ID NO:80-人源化轻链氨基酸序列
SEQ ID NO:81-人源化轻链核酸序列
SEQ ID NO:82-轻链恒定区氨基酸序列
SEQ ID NO:83-轻链恒定区氨基酸序列
SEQ ID NO:84-重链恒定区氨基酸序列
序列表
<110> 瑞美德生物医药科技有限公司
<120> 使用结合白细胞介素-17A (IL-17A)的抗体的自身免疫紊乱和炎性紊乱的治疗
<130> CACRE1.0015WO
<160> 84
<170> PatentIn version 3.5
<210> 1
<211> 155
<212> PRT
<213> 智人(Homo sapiens)
<400> 1
Met Thr Pro Gly Lys Thr Ser Leu Val Ser Leu Leu Leu Leu Leu Ser
1 5 10 15
Leu Glu Ala Ile Val Lys Ala Gly Ile Thr Ile Pro Arg Asn Pro Gly
20 25 30
Cys Pro Asn Ser Glu Asp Lys Asn Phe Pro Arg Thr Val Met Val Asn
35 40 45
Leu Asn Ile His Asn Arg Asn Thr Asn Thr Asn Pro Lys Arg Ser Ser
50 55 60
Asp Tyr Tyr Asn Arg Ser Thr Ser Pro Trp Asn Leu His Arg Asn Glu
65 70 75 80
Asp Pro Glu Arg Tyr Pro Ser Val Ile Trp Glu Ala Lys Cys Arg His
85 90 95
Leu Gly Cys Ile Asn Ala Asp Gly Asn Val Asp Tyr His Met Asn Ser
100 105 110
Val Pro Ile Gln Gln Glu Ile Leu Val Leu Arg Arg Glu Pro Pro His
115 120 125
Cys Pro Asn Ser Phe Arg Leu Glu Lys Ile Leu Val Ser Val Gly Cys
130 135 140
Thr Cys Val Thr Pro Ile Val His His Val Ala
145 150 155
<210> 2
<211> 7
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 2
Thr Phe Gly Met Gly Val Asp
1 5
<210> 3
<211> 5
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 3
Ser Tyr Gly Val Tyr
1 5
<210> 4
<211> 5
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 4
Ser Tyr Trp Met His
1 5
<210> 5
<211> 5
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 5
Asp Tyr Tyr Met Asn
1 5
<210> 6
<211> 5
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 6
Asn Tyr Trp Ile His
1 5
<210> 7
<211> 16
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 7
His Ile Trp Trp Asp Asp Asp Lys Tyr Tyr Asn Pro Ala Leu Glu Ser
1 5 10 15
<210> 8
<211> 16
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 8
Val Ile Trp Ser Asp Gly Thr Thr Thr Tyr Asn Ser Ala Leu Lys Ser
1 5 10 15
<210> 9
<211> 17
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 9
Glu Ile Asp Pro Ser Asp Thr Tyr Thr Asn Tyr Asn Pro Lys Phe Lys
1 5 10 15
Gly
<210> 10
<211> 17
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 10
Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn Gln Asn Phe Arg
1 5 10 15
Gly
<210> 11
<211> 17
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 11
Glu Ile Asp Pro Ser Asp Thr Phe Thr Asn Tyr Ser Pro Lys Phe Lys
1 5 10 15
Gly
<210> 12
<211> 17
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 12
Glu Ile Asp Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 13
<211> 10
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 13
Arg Glu Leu Gly Pro Tyr Phe Phe Asp Tyr
1 5 10
<210> 14
<211> 11
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 14
Gln Gly Asp Asn Tyr Ser Tyr Ala Val Asp Tyr
1 5 10
<210> 15
<211> 11
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 15
Ser Gly Ile Tyr Tyr Asp Tyr Tyr Glu Asp Tyr
1 5 10
<210> 16
<211> 11
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 16
Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
1 5 10
<210> 17
<211> 11
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 17
Ser Gly Ile Tyr Tyr Asp Tyr Tyr Glu Asp Tyr
1 5 10
<210> 18
<211> 16
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 18
Arg Ser Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu
1 5 10 15
<210> 19
<211> 16
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 19
Arg Ser Ser Gln Ser Leu Val His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 20
<211> 16
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 20
Arg Ser Ser Gln Ile Leu Leu His Ser Asn Gly Asn Thr Tyr Leu His
1 5 10 15
<210> 21
<211> 15
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 21
Lys Ala Ser Gln Ser Val Ser Phe Ala Gly Thr Gly Leu Met His
1 5 10 15
<210> 22
<211> 7
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 22
Lys Val Ser Asn Arg Phe Ser
1 5
<210> 23
<211> 7
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 23
Lys Val Phe Asn Arg Phe Ser
1 5
<210> 24
<211> 7
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 24
Arg Ala Ser Asn Leu Glu Ala
1 5
<210> 25
<211> 9
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 25
Phe Gln Gly Ser His Phe Pro Tyr Thr
1 5
<210> 26
<211> 9
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 26
Ser Gln Ser Thr His Ala Pro Leu Thr
1 5
<210> 27
<211> 8
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 27
Ser Gln Ser Val His Val Pro Thr
1 5
<210> 28
<211> 8
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 28
Gln Gln Thr Met Glu Tyr Pro Thr
1 5
<210> 29
<211> 8
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 29
Ser Gln Ser Ile His Val Pro Thr
1 5
<210> 30
<211> 139
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 30
Met Gly Arg Leu Thr Ser Ser Phe Leu Ile Leu Ile Val Pro Ala Tyr
1 5 10 15
Val Leu Ser Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln
20 25 30
Pro Ser Gln Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu
35 40 45
Asn Thr Phe Gly Met Gly Val Asp Trp Ile Arg Gln Pro Ser Gly Lys
50 55 60
Gly Leu Glu Trp Leu Ala His Ile Trp Trp Asp Asp Asp Lys Tyr Tyr
65 70 75 80
Asn Pro Ala Leu Glu Ser Arg Leu Thr Ile Ser Lys Asp Ala Ser Lys
85 90 95
Asn Gln Val Phe Leu Lys Ile Ala Asn Val Asp Thr Ala Asp Thr Ala
100 105 110
Thr Tyr Tyr Cys Ser Arg Arg Glu Leu Gly Pro Tyr Phe Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135
<210> 31
<211> 417
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 31
atgggcaggc ttacttcttc attcctgata ctgattgtcc ctgcatatgt cctgtcccag 60
gttactctga aagagtctgg ccctgggata ttgcagccct cccagaccct cagtctgact 120
tgttctttct ctgggttttc actgaacact tttggtatgg gtgtagactg gattcgtcag 180
ccttcaggga agggtctgga gtggctggca cacatttggt gggatgatga taagtactat 240
aacccagccc tggagagtcg gctcacaatc tccaaggatg cctccaaaaa ccaggtattc 300
ctcaagatcg ccaatgtaga cactgcagat actgccacat actactgttc tcgaagggaa 360
ctgggccctt acttctttga ctactggggc caaggcacca ctctcacagt ctcctca 417
<210> 32
<211> 138
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 32
Met Ala Val Leu Gly Leu Leu Leu Cys Leu Val Thr Phe Pro Ser Cys
1 5 10 15
Val Leu Ser Gln Val Glu Leu Lys Glu Ser Gly Pro Gly Leu Val Ala
20 25 30
Pro Ser Gln Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu
35 40 45
Thr Ser Tyr Gly Val Tyr Trp Val Arg Gln Pro Pro Gly Lys Gly Leu
50 55 60
Glu Trp Leu Val Val Ile Trp Ser Asp Gly Thr Thr Thr Tyr Asn Ser
65 70 75 80
Ala Leu Lys Ser Arg Leu Ser Ile Ser Lys Asp Asn Ser Lys Ser Gln
85 90 95
Val Phe Leu Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr
100 105 110
Tyr Cys Ala Arg Gln Gly Asp Asn Tyr Ser Tyr Ala Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ala Val Thr Val Ser Ser
130 135
<210> 33
<211> 414
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 33
atggctgtcc tggggctgct tctctgcctg gtgactttcc caagctgtgt cctgtcccag 60
gtggaactga aggagtcagg acctggcctg gtggcgccct cacagagcct gtccatcaca 120
tgcaccgtct caggattctc attaaccagt tatggtgtat actgggttcg ccagcctcca 180
ggaaagggtc tggagtggct ggtagtgata tggagtgatg gaactacaac ctataactca 240
gctctcaaat ccagactgag catcagcaag gacaactcca agagtcaagt tttcttaaaa 300
atgaacagtc tccaaactga tgacacagcc atgtattact gtgccagaca aggagataat 360
tactcctatg ctgtggacta ctggggtcaa ggaaccgcag tcaccgtctc ttca 414
<210> 34
<211> 139
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 34
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ser Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Met
20 25 30
Pro Gly Thr Ser Val Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Ser Tyr Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Glu Ile Asp Pro Ser Asp Thr Tyr Thr Asn Tyr Asn
65 70 75 80
Pro Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Phe Thr Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Gly Ile Tyr Tyr Asp Tyr Tyr Glu Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135
<210> 35
<211> 417
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 35
atgggatgga gctgtatcat cctcttcttg gtctcaacag ctacaggtgt ccactcccag 60
gtccaactgc agcagcctgg ggctgaactt gtgatgcctg ggacttcagt gaggctgtcc 120
tgcaaggctt ctggctacac cttcaccagc tattggatgc actgggtgaa acagaggcct 180
ggacaaggcc ttgagtggat cggagaaatt gatccttctg atacttatac taattacaat 240
ccaaagttca agggcaaggc cacattgact gtagacaaat cctccagcac agcctacatg 300
cagttcacca gtctgacatc tgaggactct gcggtctatt actgtgcaag atcgggaatc 360
tactatgatt attacgagga ctactggggc caaggcacca ctctcacagt ctcctca 417
<210> 36
<211> 139
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 36
Met Gly Trp Ser Trp Ile Phe Leu Phe Leu Leu Ser Gly Thr Ala Gly
1 5 10 15
Val Leu Ser Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Met Lys Gln Ser His Gly Lys Ser Leu
50 55 60
Glu Trp Ile Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135
<210> 37
<211> 417
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 37
atgggatgga gctggatctt tctctttctc ctgtcaggaa ctgcaggtgt cctctctgag 60
gtccagctgc aacaatctgg acctgaactg gtgaagcctg gggcttcagt gaagatatcc 120
tgtaaggctt ctggattcac gttcactgac tactacatga actggatgaa gcagagccat 180
ggaaagagcc ttgagtggat tggagatatt aatcctaaga atggtggtac tatcttcaac 240
cagaacttca ggggcaaggc cacattgact gtggacaagt cctccagcac agcctacatg 300
gaactccgca gcctgacatc tgaggactct gcagtctatt actgtgcaag atccatttta 360
actgggcctt tctactttga ctactggggc caaggcacca ctctcacagt ctcctca 417
<210> 38
<211> 139
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 38
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ser Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Met
20 25 30
Pro Gly Ala Ser Val Arg Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Trp Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Glu Ile Asp Pro Ser Asp Thr Phe Thr Asn Tyr Ser
65 70 75 80
Pro Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Thr Gly Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Phe Cys Ala Arg Ser Gly Ile Tyr Tyr Asp Tyr Tyr Glu Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135
<210> 39
<211> 417
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 39
atgggatgga gctgtatcat cctcttcttg gtatcaacag ctacaggtgt ccactcccag 60
gtccaactgc agcagcctgg ggctgagctt gtgatgcctg gggcttcagt gaggctgtcc 120
tgcaaggctt ctggctacac cttcaccaac tattggatac actgggtgaa acagaggcct 180
ggacaaggcc ttgagtggat cggagagatt gatccttctg atacttttac taattacagt 240
ccaaagttca agggcaaggc cacattgact gtagacaaat cctccagcac agcctacatg 300
cagctcaccg gtctgacatc tgaggactct gcggtctatt tctgtgcaag atcgggaatc 360
tactatgatt actacgagga ctactggggc caaggcacca ctctcacagt ctcctca 417
<210> 40
<211> 139
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 40
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ser Thr Ala Thr Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Met
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ala Gly Tyr Thr Phe
35 40 45
Thr Ser Tyr Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Glu Ile Asp Pro Ser Asp Ser Tyr Thr Asn Tyr Asn
65 70 75 80
Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Gly Ile Tyr Tyr Asp Tyr Tyr Glu Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135
<210> 41
<211> 393
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 41
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtggt 60
gttttgatga cccaaactcc actctccctg cctgtcagtc ttggagatca agcctccatc 120
tcttgcagat ctagtcagag cattgtacat agtaatggaa acacctattt agaatggtac 180
ctgcagaaac caggccagtc tccaaaactc ctgatctaca aagtttccaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcaac 300
agagtggagg ctgaggatct gggagtttat tactgctttc aaggttcaca ttttccgtac 360
acattcggag gggggaccaa gctggaaata gac 393
<210> 42
<211> 131
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 42
Met Lys Leu Pro Val Arg Leu Leu Val Leu Met Phe Trp Ile Pro Ala
1 5 10 15
Ser Ser Ser Gly Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val
20 25 30
Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile
35 40 45
Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Lys Ile Asn Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys
100 105 110
Phe Gln Gly Ser His Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu
115 120 125
Glu Ile Asp
130
<210> 43
<211> 393
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 43
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtggt 60
gttttgatga cccaaactcc actctccctg cctgtcagtc ttggagatca agcctccatc 120
tcttgcagat ctagtcagag cattgtacat agtaatggaa acacctattt agaatggtac 180
ctgcagaaac caggccagtc tccaaaactc ctgatctaca aagtttccaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcaac 300
agagtggagg ctgaggatct gggagtttat tactgctttc aaggttcaca ttttccgtac 360
acattcggag gggggaccaa gctggaaata gac 393
<210> 44
<211> 131
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 44
Met Lys Leu Pro Val Arg Leu Leu Val Leu Met Phe Trp Ile Pro Ala
1 5 10 15
Ser Ser Ser Asp Val Val Met Ile Gln Ile Pro Leu Ser Leu Pro Val
20 25 30
Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu
35 40 45
Val His Ser Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Phe Asn Arg Phe Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys
100 105 110
Ser Gln Ser Thr His Ala Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu
115 120 125
Glu Leu Lys
130
<210> 45
<211> 393
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 45
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtgat 60
gttgtgatga tccaaattcc actctccctg cctgtcagtc ttggagatca agcctccatc 120
tcttgcagat ctagtcagag ccttgtacac agtaatggaa acacctattt acattggtac 180
ctgcagaagc caggccagtc tccaaagctc ctgatctaca aggttttcaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcagc 300
agagtggagg ctgaggatct gggagtttat ttctgctctc aaagtacaca tgctccgctc 360
acgttcggtg ctgggaccaa gctggagctg aaa 393
<210> 46
<211> 130
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 46
Met Lys Leu Pro Val Arg Leu Leu Val Leu Met Phe Trp Ile Pro Ala
1 5 10 15
Ser Ser Ser Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val
20 25 30
Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ile Leu
35 40 45
Leu His Ser Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys
100 105 110
Ser Gln Ser Val His Val Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu
115 120 125
Ile Lys
130
<210> 47
<211> 390
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 47
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtgat 60
gttgtgatga cccaaactcc actctccctg cctgtcagtc ttggagatca agcctccatc 120
tcttgcagat ctagtcagat ccttctacac agtaatggaa acacctattt gcattggtac 180
ctgcagaagc caggccagtc tccaaagctc ctgatctaca aagtttccaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcagc 300
agagtggagg ctgaggatct gggagtttat ttctgctctc aaagtgtaca tgttcccacg 360
ttcggagggg ggaccaagct ggaaataaaa 390
<210> 48
<211> 130
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 48
Met Glu Thr Glu Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala
20 25 30
Val Ser Leu Gly Gln Arg Ala Ile Ile Ser Cys Lys Ala Ser Gln Ser
35 40 45
Val Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Ser
50 55 60
Gly Gln Gln Pro Lys Leu Leu Ile Ser Arg Ala Ser Asn Leu Glu Ala
65 70 75 80
Gly Val Pro Thr Arg Phe Ser Gly Ser Gly Ser Arg Thr Asp Phe Thr
85 90 95
Leu Asn Ile His Pro Val Glu Glu Asp Asp Ala Ala Thr Tyr Tyr Cys
100 105 110
Gln Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu
115 120 125
Ile Lys
130
<210> 49
<211> 390
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 49
atggagacag aaacactcct gctatgggtg ctactgctct gggttccagg ctccactggt 60
gacattgtgc tgacccaatc tccagcttct ttggctgtgt ctctagggca gagggccatc 120
atctcctgca aggccagcca aagtgtcagt tttgctggta ctggtttaat gcactggtac 180
caacagaaat caggacagca acccaaactc ctcatctctc gtgcatccaa cctagaagct 240
ggggttccta ccaggtttag tggcagtggg tctaggacag acttcaccct caatatccat 300
cctgtggagg aagatgatgc tgcaacctat tactgtcagc aaactatgga atatccgacg 360
ttcggtggag gcaccaagct tgaaattaaa 390
<210> 50
<211> 130
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 50
Met Lys Leu Pro Val Arg Leu Leu Val Leu Met Phe Trp Ile Pro Ala
1 5 10 15
Ser Ser Ser Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val
20 25 30
Ser Leu Gly Asp Gln Val Ser Ile Ser Cys Arg Ser Ser Gln Ile Leu
35 40 45
Leu His Ser Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Lys Ile Ser Arg Val Glu Ala Asp Asp Leu Gly Val Tyr Phe Cys
100 105 110
Ser Gln Ser Val His Val Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu
115 120 125
Ile Lys
130
<210> 51
<211> 390
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 51
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtgat 60
gttgtgatga cccaaactcc actctccctg cctgtcagtc ttggagatca agtctccatc 120
tcttgcagat ctagtcagat ccttctacac agtaatggaa acacctattt acattggtac 180
ctgcagaagc caggccagtc tccaaagctc ctgatctaca aagtttccaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcagc 300
agagtggagg ctgatgatct gggagtttat ttctgctctc aaagtgtaca tgttcccacg 360
ttcggagggg ggaccaagct ggaaataaaa 390
<210> 52
<211> 130
<212> PRT
<213> 小家鼠(Mus musculus)
<400> 52
Met Lys Leu Pro Val Arg Leu Leu Val Leu Met Phe Trp Ile Pro Ala
1 5 10 15
Ser Ser Ser Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val
20 25 30
Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu
35 40 45
Val His Ser Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys
100 105 110
Ser Gln Ser Ile His Val Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu
115 120 125
Ile Lys
130
<210> 53
<211> 390
<212> DNA
<213> 小家鼠(Mus musculus)
<400> 53
atgaagttgc ctgttaggct gttggtgctg atgttctgga ttcctgcttc cagcagtgat 60
gttgtgatga cccaaactcc actctccctg cctgtcagtc ttggagatca agcctccatc 120
tcttgcagat ctagtcagag ccttgtacac agtaatggaa acacctattt acattggtac 180
ctgcagaagc caggccagtc tccaaagctc ctgatctaca aagtttccaa ccgattttct 240
ggggtcccag acaggttcag tggcagtgga tcagggacag atttcacact caagatcagc 300
agagtggagg ctgaggatct gggagtttat ttctgctctc aaagtataca tgttcccacg 360
ttcggagggg ggaccaagct ggaaataaaa 390
<210> 54
<211> 466
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 鼠-人类嵌合抗体的重链氨基酸序列
<400> 54
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Met Lys Gln Ser His Gly Lys Ser Leu
50 55 60
Glu Trp Ile Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
210 215 220
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
225 230 235 240
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
450 455 460
Gly Lys
465
<210> 55
<211> 1401
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 鼠-人类嵌合抗体的重链核酸序列
<400> 55
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgag 60
gtccagctgc aacaatctgg acctgaactg gtgaagcctg gggcttcagt gaagatatcc 120
tgtaaggctt ctggattcac gttcactgac tactacatga actggatgaa gcagagccat 180
ggaaagagcc ttgagtggat tggagatatt aatcctaaga atggtggtac tatcttcaac 240
cagaacttca ggggcaaggc cacattgact gtggacaagt cctccagcac agcctacatg 300
gaactccgca gcctgacatc tgaggactct gcagtctatt actgtgcaag atccatttta 360
actgggcctt tctactttga ctactggggc caaggcacca ctctcacagt ctcctcagcc 420
tctacaaagg gcccctccgt gtttccactg gctccctgca gcaggtctac atccgagagc 480
accgctgctc tgggatgtct ggtgaaggat tacttccctg agccagtgac cgtgagctgg 540
aactccggag ctctgacatc cggagtgcac acctttcctg ctgtgctgca gagctctggc 600
ctgtacagcc tgtccagcgt ggtgacagtg ccatcttcca gcctgggcac caagacatat 660
acctgcaacg tggaccataa gcccagcaat accaaggtgg ataagagagt ggagtctaag 720
tacggaccac cttgcccacc atgtccagct cctgagtttc tgggaggacc atccgtgttc 780
ctgtttcctc caaagcctaa ggacaccctg atgatctctc gcacacccga ggtgacctgt 840
gtggtggtgg acgtgtccca ggaggatcct gaggtgcagt tcaactggta cgtggatggc 900
gtggaggtgc acaatgctaa gaccaagcct agggaggagc agtttaacag cacataccgg 960
gtggtgtctg tgctgaccgt gctgcatcag gactggctga acggcaagga gtataagtgc 1020
aaggtgagca ataagggcct gccatcttcc atcgagaaga caatctctaa ggctaaggga 1080
cagcctaggg agccacaggt gtacaccctg cccccttccc aggaggagat gacaaagaac 1140
caggtgagcc tgacctgtct ggtgaagggc ttctatcctt ctgacatcgc tgtggagtgg 1200
gagtccaatg gccagccaga gaacaattac aagaccacac cacccgtgct ggactccgat 1260
ggcagcttct ttctgtattc caggctgacc gtggataaga gccggtggca ggagggcaat 1320
gtgttttctt gttccgtgat gcacgaagca ctgcacaacc actacactca gaagtccctg 1380
tcactgtccc tgggcaagtg a 1401
<210> 56
<211> 236
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 鼠-人类嵌合抗体的轻链氨基酸序列
<400> 56
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val
20 25 30
Ser Leu Gly Gln Arg Ala Ile Ile Ser Cys Lys Ala Ser Gln Ser Val
35 40 45
Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Ser Gly
50 55 60
Gln Gln Pro Lys Leu Leu Ile Ser Arg Ala Ser Asn Leu Glu Ala Gly
65 70 75 80
Val Pro Thr Arg Phe Ser Gly Ser Gly Ser Arg Thr Asp Phe Thr Leu
85 90 95
Asn Ile His Pro Val Glu Glu Asp Asp Ala Ala Thr Tyr Tyr Cys Gln
100 105 110
Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230 235
<210> 57
<211> 711
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 鼠-人类嵌合抗体的轻链核酸序列
<400> 57
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgac 60
attgtgctga cccaatctcc agcttctttg gctgtgtctc tagggcagag ggccatcatc 120
tcctgcaagg ccagccaaag tgtcagtttt gctggtactg gtttaatgca ctggtaccaa 180
cagaaatcag gacagcaacc caaactcctc atctctcgtg catccaacct agaagctggg 240
gttcctacca ggtttagtgg cagtgggtct aggacagact tcaccctcaa tatccatcct 300
gtggaggaag atgatgctgc aacctattac tgtcagcaaa ctatggaata tccgacgttc 360
ggtggaggca ccaagcttga aattaaacga acggtggctg caccatctgt cttcatcttc 420
ccgccatctg atgagcagtt gaaatctgga actgcctctg ttgtgtgcct gctgaataac 480
ttctatccca gagaggccaa agtacagtgg aaggtggata acgccctcca atcgggtaac 540
tcccaggaga gtgtcacaga gcaggacagc aaggacagca cctacagcct cagcagcacc 600
ctgacgctga gcaaagcaga ctacgagaaa cacaaagtct acgcctgcga agtcacccat 660
cagggcctga gctcgcccgt cacaaagagc ttcaacaggg gagagtgtta g 711
<210> 58
<211> 120
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链可变区氨基酸序列
<400> 58
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe Thr Asp Tyr
20 25 30
Tyr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn Gln Asn Phe
50 55 60
Arg Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 59
<211> 110
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链可变区氨基酸序列
<400> 59
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val Ser Phe Ala
20 25 30
Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Thr Met
85 90 95
Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 60
<211> 120
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链可变区氨基酸序列
<400> 60
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe Thr Asp Tyr
20 25 30
Tyr Met Asn Trp Met Arg Gln Ser Pro Gly Gln Ser Leu Glu Trp Met
35 40 45
Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn Gln Asn Phe
50 55 60
Arg Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 61
<211> 110
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链可变区氨基酸序列
<400> 61
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val Ser Phe Ala
20 25 30
Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly Gln Gln Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Thr Met
85 90 95
Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 62
<211> 120
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链可变区氨基酸序列
<400> 62
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe Thr Asp Tyr
20 25 30
Tyr Met Asn Trp Met Arg Gln Ser Pro Gly Gln Ser Leu Glu Trp Ile
35 40 45
Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn Gln Asn Phe
50 55 60
Arg Gly Arg Ala Thr Leu Thr Val Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 63
<211> 110
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链可变区氨基酸序列
<400> 63
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val Ser Phe Ala
20 25 30
Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly Gln Gln Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Val Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Thr Met
85 90 95
Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 64
<211> 120
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链可变区氨基酸序列
<400> 64
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe Thr Asp Tyr
20 25 30
Tyr Met Asn Trp Met Lys Gln Ser Pro Gly Gln Ser Leu Glu Trp Ile
35 40 45
Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn Gln Asn Phe
50 55 60
Arg Gly Arg Ala Thr Leu Thr Val Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Leu Thr Val Ser Ser
115 120
<210> 65
<211> 110
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链可变区氨基酸序列
<400> 65
Asp Ile Val Leu Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val Ser Phe Ala
20 25 30
Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly Gln Gln Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Val Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln Thr Met
85 90 95
Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 66
<211> 466
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链氨基酸序列
<400> 66
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys
20 25 30
Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Met Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
210 215 220
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
225 230 235 240
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
450 455 460
Gly Lys
465
<210> 67
<211> 1401
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化重链核酸序列
<400> 67
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagccag 60
gtccagctgg tgcagtcagg agccgaagtc aaaaagcccg gagcctcagt caaagtgtct 120
tgtaaagcct cagggttcac attcaccgac tactatatga actgggtgcg gcaggcacca 180
ggacagggcc tggagtggat gggcgatatc aaccctaaga atggcggcac aatcttcaac 240
cagaattttc ggggcagagt gaccatgaca cgggacacca gcatctccac agcctacatg 300
gagctgtcta ggctgcgcag cgacgatacc gccgtgtact attgcgccag gagcatcctg 360
actggacctt tctactttga ttactggggg cagggaactc tggtgaccgt gagcagcgcc 420
tctacaaagg gcccctccgt gtttccactg gctccctgca gcaggtctac atccgagagc 480
accgctgctc tgggatgtct ggtgaaggat tacttccctg agccagtgac cgtgagctgg 540
aactccggag ctctgacatc cggagtgcac acctttcctg ctgtgctgca gagctctggc 600
ctgtacagcc tgtccagcgt ggtgacagtg ccatcttcca gcctgggcac caagacatat 660
acctgcaacg tggaccataa gcccagcaat accaaggtgg ataagagagt ggagtctaag 720
tacggaccac cttgcccacc atgtccagct cctgagtttc tgggaggacc atccgtgttc 780
ctgtttcctc caaagcctaa ggacaccctg atgatctctc gcacacccga ggtgacctgt 840
gtggtggtgg acgtgtccca ggaggatcct gaggtgcagt tcaactggta cgtggatggc 900
gtggaggtgc acaatgctaa gaccaagcct agggaggagc agtttaacag cacataccgg 960
gtggtgtctg tgctgaccgt gctgcatcag gactggctga acggcaagga gtataagtgc 1020
aaggtgagca ataagggcct gccatcttcc atcgagaaga caatctctaa ggctaaggga 1080
cagcctaggg agccacaggt gtacaccctg cccccttccc aggaggagat gacaaagaac 1140
caggtgagcc tgacctgtct ggtgaagggc ttctatcctt ctgacatcgc tgtggagtgg 1200
gagtccaatg gccagccaga gaacaattac aagaccacac cacccgtgct ggactccgat 1260
ggcagcttct ttctgtattc caggctgacc gtggataaga gccggtggca ggagggcaat 1320
gtgttttctt gttccgtgat gcacgaagca ctgcacaacc actacactca gaagtccctg 1380
tcactgtccc tgggcaagtg a 1401
<210> 68
<211> 236
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链氨基酸序列
<400> 68
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val
20 25 30
Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val
35 40 45
Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly
50 55 60
Gln Pro Pro Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly
65 70 75 80
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
85 90 95
Thr Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln
100 105 110
Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230 235
<210> 69
<211> 711
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化轻链核酸序列
<400> 69
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgac 60
atcgtcatga ctcagagccc cgacagcctg gccgtctcac tgggcgaaag agcaactatc 120
aactgcaaag catcacagag cgtctctttc gccggcaccg gcctgatgca ctggtaccag 180
cagaagccag gccagccccc taagctgctg atctataggg caagcaacct ggaggcagga 240
gtgccagaca gattctctgg cagcggctcc ggcacagact tcaccctgac aatcagctcc 300
ctgcaggcag aggacgtggc cgtgtactac tgtcagcaga ctatggaata ccctaccttc 360
ggaggaggca ctaaactgga aatcaaacga acggtggctg caccatctgt cttcatcttc 420
ccgccatctg atgagcagtt gaaatctgga actgcctctg ttgtgtgcct gctgaataac 480
ttctatccca gagaggccaa agtacagtgg aaggtggata acgccctcca atcgggtaac 540
tcccaggaga gtgtcacaga gcaggacagc aaggacagca cctacagcct cagcagcacc 600
ctgacgctga gcaaagcaga ctacgagaaa cacaaagtct acgcctgcga agtcacccat 660
cagggcctga gctcgcccgt cacaaagagc ttcaacaggg gagagtgtta g 711
<210> 70
<211> 466
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链氨基酸序列
<400> 70
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Met Arg Gln Ser Pro Gly Gln Ser Leu
50 55 60
Glu Trp Met Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
210 215 220
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
225 230 235 240
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
450 455 460
Gly Lys
465
<210> 71
<211> 1401
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化重链核酸序列
<400> 71
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagccag 60
gtccagctgg tccagagcgg agccgaagtg gtgaagcccg gagcaagcgt gaaggtctca 120
tgcaaagcct cagggtttac atttaccgac tactatatga actggatgag gcagtctcca 180
ggacagagcc tggagtggat gggcgatatc aaccctaaga atggcggcac aatcttcaac 240
cagaattttc ggggcagagt gaccatgaca cgggacacca gcatctccac agcctacatg 300
gagctgtcca ggctgcgctc tgacgatacc gccgtgtact attgcgccag gagcatcctg 360
acaggacctt tttactttga ctattggggg caggggactc tggtgaccgt gagcagcgcc 420
tctacaaagg gcccctccgt gtttccactg gctccctgca gcaggtctac atccgagagc 480
accgctgctc tgggatgtct ggtgaaggat tacttccctg agccagtgac cgtgagctgg 540
aactccggag ctctgacatc cggagtgcac acctttcctg ctgtgctgca gagctctggc 600
ctgtacagcc tgtccagcgt ggtgacagtg ccatcttcca gcctgggcac caagacatat 660
acctgcaacg tggaccataa gcccagcaat accaaggtgg ataagagagt ggagtctaag 720
tacggaccac cttgcccacc atgtccagct cctgagtttc tgggaggacc atccgtgttc 780
ctgtttcctc caaagcctaa ggacaccctg atgatctctc gcacacccga ggtgacctgt 840
gtggtggtgg acgtgtccca ggaggatcct gaggtgcagt tcaactggta cgtggatggc 900
gtggaggtgc acaatgctaa gaccaagcct agggaggagc agtttaacag cacataccgg 960
gtggtgtctg tgctgaccgt gctgcatcag gactggctga acggcaagga gtataagtgc 1020
aaggtgagca ataagggcct gccatcttcc atcgagaaga caatctctaa ggctaaggga 1080
cagcctaggg agccacaggt gtacaccctg cccccttccc aggaggagat gacaaagaac 1140
caggtgagcc tgacctgtct ggtgaagggc ttctatcctt ctgacatcgc tgtggagtgg 1200
gagtccaatg gccagccaga gaacaattac aagaccacac cacccgtgct ggactccgat 1260
ggcagcttct ttctgtattc caggctgacc gtggataaga gccggtggca ggagggcaat 1320
gtgttttctt gttccgtgat gcacgaagca ctgcacaacc actacactca gaagtccctg 1380
tcactgtccc tgggcaagtg a 1401
<210> 72
<211> 236
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链氨基酸序列
<400> 72
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val
20 25 30
Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val
35 40 45
Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly
50 55 60
Gln Gln Pro Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly
65 70 75 80
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
85 90 95
Thr Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln
100 105 110
Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230 235
<210> 73
<211> 711
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化轻链核酸序列
<400> 73
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgac 60
attgtgatga ctcagagccc cgatagcctg gccgtctccc tgggcgaaag agcaaccatt 120
aactgtaaag caagccagag cgtgagcttc gctggcactg ggctgatgca ctggtaccag 180
cagaagcccg gacagcagcc taaactgctg atctatcgag catctaacct ggaggcagga 240
gtgccagaca gattctctgg aagtggctca gggaccgact tcaccctgac aattagctcc 300
ctgcaggccg aagacgtggc tgtctactac tgtcagcaga ctatggaata ccccaccttc 360
ggaggaggca ccaaactgga aatcaagcga acggtggctg caccatctgt cttcatcttc 420
ccgccatctg atgagcagtt gaaatctgga actgcctctg ttgtgtgcct gctgaataac 480
ttctatccca gagaggccaa agtacagtgg aaggtggata acgccctcca atcgggtaac 540
tcccaggaga gtgtcacaga gcaggacagc aaggacagca cctacagcct cagcagcacc 600
ctgacgctga gcaaagcaga ctacgagaaa cacaaagtct acgcctgcga agtcacccat 660
cagggcctga gctcgcccgt cacaaagagc ttcaacaggg gagagtgtta g 711
<210> 74
<211> 466
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链氨基酸序列
<400> 74
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Met Arg Gln Ser Pro Gly Gln Ser Leu
50 55 60
Glu Trp Ile Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Arg Ala Thr Leu Thr Val Asp Thr Ser Ile Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
210 215 220
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
225 230 235 240
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
450 455 460
Gly Lys
465
<210> 75
<211> 1401
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化重链核酸序列
<400> 75
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagccag 60
gtccagctgg tgcagtcagg ggcagaggtg gtcaaacccg gagcaagtgt caaagtgtct 120
tgtaaggcat caggcttcac attcaccgac tactatatga actggatgag gcagtctcca 180
ggacagagcc tggagtggat cggcgatatc aaccctaaga atggcggcac aatcttcaac 240
cagaattttc ggggcagagc caccctgaca gtggacacca gcatctccac agcctacatg 300
gagctgtcca ggctgcgctc tgacgatacc gccgtgtact attgcgccag gagcatcctg 360
actggacctt tctactttga ctactggggg cagggaacac tggtgaccgt ctcctcagcc 420
tctacaaagg gcccctccgt gtttccactg gctccctgca gcaggtctac atccgagagc 480
accgctgctc tgggatgtct ggtgaaggat tacttccctg agccagtgac cgtgagctgg 540
aactccggag ctctgacatc cggagtgcac acctttcctg ctgtgctgca gagctctggc 600
ctgtacagcc tgtccagcgt ggtgacagtg ccatcttcca gcctgggcac caagacatat 660
acctgcaacg tggaccataa gcccagcaat accaaggtgg ataagagagt ggagtctaag 720
tacggaccac cttgcccacc atgtccagct cctgagtttc tgggaggacc atccgtgttc 780
ctgtttcctc caaagcctaa ggacaccctg atgatctctc gcacacccga ggtgacctgt 840
gtggtggtgg acgtgtccca ggaggatcct gaggtgcagt tcaactggta cgtggatggc 900
gtggaggtgc acaatgctaa gaccaagcct agggaggagc agtttaacag cacataccgg 960
gtggtgtctg tgctgaccgt gctgcatcag gactggctga acggcaagga gtataagtgc 1020
aaggtgagca ataagggcct gccatcttcc atcgagaaga caatctctaa ggctaaggga 1080
cagcctaggg agccacaggt gtacaccctg cccccttccc aggaggagat gacaaagaac 1140
caggtgagcc tgacctgtct ggtgaagggc ttctatcctt ctgacatcgc tgtggagtgg 1200
gagtccaatg gccagccaga gaacaattac aagaccacac cacccgtgct ggactccgat 1260
ggcagcttct ttctgtattc caggctgacc gtggataaga gccggtggca ggagggcaat 1320
gtgttttctt gttccgtgat gcacgaagca ctgcacaacc actacactca gaagtccctg 1380
tcactgtccc tgggcaagtg a 1401
<210> 76
<211> 236
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链氨基酸序列
<400> 76
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val
20 25 30
Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val
35 40 45
Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly
50 55 60
Gln Gln Pro Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly
65 70 75 80
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
85 90 95
Thr Ile Ser Ser Val Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln
100 105 110
Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230 235
<210> 77
<211> 711
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化轻链核酸序列
<400> 77
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgat 60
attgtcatga ctcagagccc cgactcactg gccgtctcac tgggcgaaag agcaaccatc 120
aactgcaaag cctcacagag cgtctctttc gccggcaccg gcctgatgca ctggtaccag 180
cagaagcccg gccagcagcc taagctgctg atctataggg caagcaacct ggaggcagga 240
gtgccagaca gattctctgg cagcggctcc ggcacagact tcaccctgac aatcagctcc 300
gtgcaggcag aggacgtggc cgtgtactac tgtcagcaga ctatggaata ccctaccttc 360
gggggcggca caaaactgga aatcaaacga acggtggctg caccatctgt cttcatcttc 420
ccgccatctg atgagcagtt gaaatctgga actgcctctg ttgtgtgcct gctgaataac 480
ttctatccca gagaggccaa agtacagtgg aaggtggata acgccctcca atcgggtaac 540
tcccaggaga gtgtcacaga gcaggacagc aaggacagca cctacagcct cagcagcacc 600
ctgacgctga gcaaagcaga ctacgagaaa cacaaagtct acgcctgcga agtcacccat 660
cagggcctga gctcgcccgt cacaaagagc ttcaacaggg gagagtgtta g 711
<210> 78
<211> 466
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化重链氨基酸序列
<400> 78
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe
35 40 45
Thr Asp Tyr Tyr Met Asn Trp Met Lys Gln Ser Pro Gly Gln Ser Leu
50 55 60
Glu Trp Ile Gly Asp Ile Asn Pro Lys Asn Gly Gly Thr Ile Phe Asn
65 70 75 80
Gln Asn Phe Arg Gly Arg Ala Thr Leu Thr Val Asp Thr Ser Ile Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Ser Ile Leu Thr Gly Pro Phe Tyr Phe Asp Tyr
115 120 125
Trp Gly Gln Gly Thr Leu Leu Thr Val Ser Ser Ala Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
210 215 220
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
225 230 235 240
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
245 250 255
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
260 265 270
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
275 280 285
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
290 295 300
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
305 310 315 320
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
325 330 335
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
340 345 350
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
355 360 365
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
370 375 380
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
385 390 395 400
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
405 410 415
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
420 425 430
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
435 440 445
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
450 455 460
Gly Lys
465
<210> 79
<211> 1401
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化重链核酸序列
<400> 79
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagccag 60
gtgcagctgg tccagagcgg agcagaggtg gtcaagcccg gagcaagcgt caaaatcagt 120
tgtaaggcat cagggttcac tttcaccgac tactatatga actggatgaa gcagtctcca 180
ggacagagcc tggagtggat cggcgatatc aaccctaaga atggcggcac aatcttcaac 240
cagaattttc ggggcagagc caccctgaca gtggacacca gcatctccac agcctacatg 300
gagctgtcca ggctgcgctc tgacgatacc gccgtgtact attgcgcccg gagcatcctg 360
accggacctt tctattttga ttattggggc cagggcacac tgctgactgt ctcttccgcc 420
tctacaaagg gcccctccgt gtttccactg gctccctgca gcaggtctac atccgagagc 480
accgctgctc tgggatgtct ggtgaaggat tacttccctg agccagtgac cgtgagctgg 540
aactccggag ctctgacatc cggagtgcac acctttcctg ctgtgctgca gagctctggc 600
ctgtacagcc tgtccagcgt ggtgacagtg ccatcttcca gcctgggcac caagacatat 660
acctgcaacg tggaccataa gcccagcaat accaaggtgg ataagagagt ggagtctaag 720
tacggaccac cttgcccacc atgtccagct cctgagtttc tgggaggacc atccgtgttc 780
ctgtttcctc caaagcctaa ggacaccctg atgatctctc gcacacccga ggtgacctgt 840
gtggtggtgg acgtgtccca ggaggatcct gaggtgcagt tcaactggta cgtggatggc 900
gtggaggtgc acaatgctaa gaccaagcct agggaggagc agtttaacag cacataccgg 960
gtggtgtctg tgctgaccgt gctgcatcag gactggctga acggcaagga gtataagtgc 1020
aaggtgagca ataagggcct gccatcttcc atcgagaaga caatctctaa ggctaaggga 1080
cagcctaggg agccacaggt gtacaccctg cccccttccc aggaggagat gacaaagaac 1140
caggtgagcc tgacctgtct ggtgaagggc ttctatcctt ctgacatcgc tgtggagtgg 1200
gagtccaatg gccagccaga gaacaattac aagaccacac cacccgtgct ggactccgat 1260
ggcagcttct ttctgtattc caggctgacc gtggataaga gccggtggca ggagggcaat 1320
gtgttttctt gttccgtgat gcacgaagca ctgcacaacc actacactca gaagtccctg 1380
tcactgtccc tgggcaagtg a 1401
<210> 80
<211> 236
<212> PRT
<213> 人工的(Artificial)
<220>
<223> 人源化轻链氨基酸序列
<400> 80
Met Gly Trp Ser Trp Ile Leu Leu Phe Leu Leu Ser Val Thr Ala Gly
1 5 10 15
Val His Ser Asp Ile Val Leu Thr Gln Ser Pro Asp Ser Leu Ala Val
20 25 30
Ser Leu Gly Glu Arg Ala Thr Ile Asn Cys Lys Ala Ser Gln Ser Val
35 40 45
Ser Phe Ala Gly Thr Gly Leu Met His Trp Tyr Gln Gln Lys Pro Gly
50 55 60
Gln Gln Pro Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ala Gly
65 70 75 80
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
85 90 95
Thr Ile Ser Ser Val Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln
100 105 110
Gln Thr Met Glu Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230 235
<210> 81
<211> 711
<212> DNA
<213> 人工的(Artificial)
<220>
<223> 人源化轻链核酸序列
<400> 81
atgggctgga gctggatcct gctgttcctc ctgagcgtga cagcaggagt gcacagcgac 60
atcgtcctga ctcagagccc cgacagcctg gcagtgagcc tgggagaaag agcaaccatt 120
aattgtaaag catcacagag cgtgtctttc gccggcaccg gcctgatgca ctggtaccag 180
cagaagcccg gccagcagcc taagctgctg atctataggg caagcaacct ggaggcagga 240
gtgccagaca gattctctgg cagcggctcc ggcacagact tcaccctgac aatcagctcc 300
gtgcaggcag aggacgtggc cgtgtactat tgtcagcaga ctatggagta tcctaccttc 360
gggggcggca ccaaactgga aatcaaacga acggtggctg caccatctgt cttcatcttc 420
ccgccatctg atgagcagtt gaaatctgga actgcctctg ttgtgtgcct gctgaataac 480
ttctatccca gagaggccaa agtacagtgg aaggtggata acgccctcca atcgggtaac 540
tcccaggaga gtgtcacaga gcaggacagc aaggacagca cctacagcct cagcagcacc 600
ctgacgctga gcaaagcaga ctacgagaaa cacaaagtct acgcctgcga agtcacccat 660
cagggcctga gctcgcccgt cacaaagagc ttcaacaggg gagagtgtta g 711
<210> 82
<211> 107
<212> PRT
<213> 智人(Homo sapiens)
<400> 82
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 83
<211> 106
<212> PRT
<213> 智人(Homo sapiens)
<400> 83
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 84
<211> 327
<212> PRT
<213> 智人(Homo sapiens)
<400> 84
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
- 使用结合白细胞介素-17A(IL-17A)的抗体的自身免疫紊乱和炎性紊乱的治疗
- 抗-IL-17A抗体及其在治疗自身免疫性和炎性病症中的用途