一种多层次筛选的长时间大范围行人再识别方法
文献发布时间:2023-06-19 09:29:07
技术领域
本申请涉及长时间大范围行人再识别技术,特别涉及一种结合WebGIS、目标属性、表观特征多层次筛选的长时间大范围行人再识别方法,属于地理信息系统和计算机视觉结合的领域。
背景技术
随着我国平安城市的迅速发展和建设,截止2018年初,我国城镇部署的摄像头数目已经超过1.7亿台,每天都能拍摄到海量的视频图像,如何将海量的视频图像数据高效、智能地应用于安防和公安侦查业务变得十分重要,例如在追踪罪犯时就涉及到如何在海量视频图像中高效地再识别出该罪犯。
当多个摄像头存在监控共同覆盖区域,或者仅需要在目标消失位置附近重新识别目标时,这种短时间小范围的搜寻操作往往是先获取目标消失周围摄像头在同一时间段的视频,然后再在这些视频中利用目标表观特征完成匹配,精度相对较高。而在长时间大范围行人再识别应用中,目标消失时间已经较为久远,或者消失目标周边并没有密集的摄像头,需要在更长时间间隔、更大范围内寻找目标,此时面对的是海量视频,要在其中将目标重新找到比较困难。目前往往由人工筛选出关联视频段再进行人工查看,工作量大,耗费了大量的人力和物力资源。对此,专利号为ZL201811239639.X的专利申请提出了一种基于WebGIS的目标关联视频快速筛选方法,用于解决时空跨度大时无法准确定位行人所在摄像头范围以及行人出现时间的问题,快速筛选出候选目标所在的视频片段,为在这些视频片段中筛选出候选目标图像奠定了基础。
然后同一行人在时间跨度长、地域跨度广的不同摄像头监控视频下的图像会受到光照、观察角度、行人姿态、物体遮挡等因素的影响,甚至有换装的可能,导致同一目标在不同图像中表观差异较大,从而降低了目标再识别的准确率。因此,为了能够快速地从海量视频中筛选出可能含有消失目标的视频段,并从这些视频段中准确地找到消失的目标,需要研究不同摄像头、不同视频段的时空关联关系,在表观特征基础上结合不易受光照、观察角度、行人姿态、物体遮挡等因素影响的稳定特征,完成快速准确的行人再识别。
现有的再识别系统往往仅利用目标表观特征进行匹配,其中,基于人工提取表观特征的方法主要提取目标的颜色、纹理特征,涉及到大量参数的手工调整,适应性差、效果不佳;而基于深度神经网络的行人再识别容易受视角差异、光照变化等复杂情况的影响,当行人换装时也不能正确匹配。因此,现有的行人再识别技术在面对长时间大范围行人再识别任务时,提取强鲁棒性、高准确性的行人特征尤其重要,一些研究者进行了相关尝试(参考2019年《Horizontal Pyramid Matching for Person Re-identification》,刊于《AAAI2019-The 33rd AAAI Conference on Artificial Intelligence》;参考2018年《CA3Net:Contextual-Attentional Attribute-Appearance Network for Person Re-Identification》,刊于《CVPR 2018-Proceedings of 2018IEEE Conference on ComputerVision and Pattern Recognition》;参考2017年《Adaptively weighted multi-taskdeep network for person attribute classification》,刊于《MM 2017-Proceedings ofthe 25th ACM international conference on Multimedia》;参考2017年《Identification of pedestrian attributes using deep network》,刊于《IECON 2017-The 43rd Annual Conference of the IEEE Industrial Electronics Society》;参考2015年《Multi-attribute Learning for Pedestrian Attribute Recognition inSurveillance Scenarios》,刊于《IAPR 2015-The 3rd Asian Conference on PatternRecognition》)。
为此,本申请提出了一种多层次筛选的长时间大范围行人再识别方法,在地理信息提供的时空关系指导下,结合目标属性、表观特征克服视角差异、光照变化、换装等影响,实现准确的行人再识别。具体来说,目标消失后首先利用WebGIS提供的路径筛选出目标可能在哪些摄像头、这些摄像头的哪些时间段里再次出现,并在这些视频段中检测行人,将检测得到的行人目标图像作为目标候选图像集;针对这些目标候选图像,提出一种同时学习行人属性和行人身份的多任务再识别网络,采用属性损失与行人身份损失加权的方式同时训练多任务再识别网络中包含的属性网络和表观网络;在进行目标查询时,先根据属性网络剔除目标候选图像集中属性特征与待查询目标图像差异较大的目标候选图像,再利用表观网络对剩余的目标候选图像进行表观再识别,找到与待查询目标最接近的行人图像,完成整个多层次筛选的行人再识别过程。其中,在属性网络中引入注意力模块机制,以提高显著性属性的准确性,同时抑制无关背景区域的影响;在表观网络部分,采用表观水平金字塔以及卷积操作获取行人表观的全局和局部特征,增强表观特征的表达能力。
发明内容
本申请旨在提供一种多层次筛选的长时间大范围行人再识别方法,为长时间、大范围下目标查找提供时空线索以及属性、表观信息,协助用户快速锁定关联视频以及准确检索行人图像。
为了实现上述目的,本申请采用如下技术方案:
一种多层次筛选的长时间大范围行人再识别方法,其特征在于,包括如下步骤:
(1.1)输入目标追踪的已知条件,包括:目标类型、目标速度、目标消失时刻、目标消失摄像头C
(1.2)构建多任务行人再识别网络模型,所述模型包含基本网络、属性网络和表观网络三部分;
采用Resnet50残差网络作为基本网络,并在ImageNet数据集上对Resnet50残差网络进行预训练,得到预训练模型,然后将待查询行人图像作为输入,将由基本网络得到的行人特征作为行人整体特征;
在属性网络部分,构建多层次自适应空间注意力模块以获取特征权重,该模块包含多级池化层、卷积层和sigmoid层,其中,所述多级池化层包含三种池化操作,分别为均值池化、最大池化以及中值池化,经上述三种池化操作对应输出三个不同注意力层次的特征;利用所述注意力模块获取的特征权重对行人整体特征进行加权,得到加权后的特征,再通过全局平均池化得到特征向量,此处全局平均池化是指在特征的每个维度进行均值池化操作;然后由卷积层对特征向量降维,全连接层充当分类器,将特征向量映射到对应的属性输出结果上,最后的损失层采用softmax计算行人的属性损失;
在表观网络部分,采用水平金字塔模型对特征进行水平分类,获取三种特征:基于Resnet50基本网络提取的行人整体特征,以及对整体特征进行水平切割得到的行人上半身和下半身局部特征;对该三种特征分别进行全局平均池化GAP和全局最大池化GMP以得到对应的三种特征经过GAP和GMP操作后的结果,此处GAP和GMP操作可并行处理,将所述三种特征经过GAP和GMP操作后的结果对应相加,分别得到行人的全局表观特征、上半身局部表观特征和下半身局部表观特征;然后,将所述三种表观特征向量进行卷积降维,并将降维之后的三种表观特征进行拼接,形成行人图像的表观特征,同时将卷积降维后的三种表观特征分别输入到全连接层,采用softmax计算行人表观的全局特征损失、上半身特征损失和下半身特征损失,并进行三部分加和得到行人身份损失;
(1.3)利用行人再识别数据集Market-1501进行所述属性网络和表观网络训练,通过计算属性网络和表观网络两个分支的联合加权损失函数完成多任务行人再识别网络模型的训练;
(1.4)将目标消失时刻的目标图像作为待查询行人图像,将其输入到上述训练好的多任务行人再识别网络模型中;通过所述属性网络提取该待查询行人图像的J个属性特征;将待查询行人图像的J个属性特征与目标候选图像集中每幅图像的属性特征进行属性相似度计算,并按属性相似度K值从大到小排序,设置筛选阈值R,将排序结果中K值小于R的对应目标候选图像集中的行人图片剔除;然后,对剩余的目标候选图像集中的行人图片,通过上述表观网络提取表观特征,根据待查询行人图像的表观特征与剩余目标候选图像集中行人图片的表观特征进行表观相似度计算,对计算出来的表观相似度进行排序,找到与待查询行人图像最相似的行人图片,完成属性特征、表观特征多层次筛选的行人再识别过程。
所述多层次自适应空间注意力模块中,均值池化是指对基本网络提取出的特征的N个通道对应的同一空间位置的值求取平均值,最大池化是指对该N个通道对应的同一空间位置的值取最大值,中值池化是指对该N个通道上对应的同一空间位置的值取中值。
所述多层次自适应空间注意力模块中的卷积操作,其卷积核尺寸优选为3×3,输入通道数为3,输出通道数与Resnet50网络提取的图片特征通道数相同;所述多层次自适应空间注意力模块的参数通过神经网络的反向传播进行更新。
所述属性特征采用二分类0-1表示;其中,属性网络中利用softmax计算行人的属性损失L
所述表观网络中全局平均池化GAP是指对每一个通道的所有空间范围的特征值取平均值,全局最大池化GMP是指对每一个通道的所有空间范围的特征值取最大值。
所述多任务行人再识别网络模型的构建进一步包括:
(2.1)Resnet50残差网络首先对输入图像进行卷积操作提取行人整体特征,然后以Resnet50残差网络的全连接层作为分支点,将全连接层之前提取到的行人整体特征复制成两份,分别对应所述属性网络和表观网络的输入;
(2.2)所述多层次自适应空间注意力模块中,三种池化操作之后对三种池化方式的结果进行通道拼接,形成一个三通道特征;对该三通道特征进行卷积,得到和输入行人整体特征相同通道数的特征图,然后将该特征图通过sigmoid层转换为特征权重;
(2.3)属性网络的损失层采用softmax计算行人的属性损失,对于每一种属性,采用一个softmax计算其对应损失,最终的属性损失值计算方式如下公式所示:
其中J表示属性的种类数,L
所述属性网络和表观网络两个分支的联合加权损失函数的构建为:所述多任务行人再识别网络模型通过将行人身份损失和行人属性损失加权求和作为最后的损失函数的方式实现两种任务的同时训练,最后的损失函数计算如下式所示:
Loss=L
其中L
根据属性相似度进行目标候选图像集中行人图片筛选,提取的J个属性特征包括:行人图片的7个属性信息,包括性别、年龄、头发长短、袖子长短、是否有背包、是否戴帽子、是否戴眼镜,J=7。
根据属性相似度进行目标候选图像集中行人图片筛选时,属性相似度的计算为对于两张行人图片P和Q,它们的属性相似度计算公式如下式所示:
其中,P
根据表观相似度进行剩余目标候选图像集中行人图片筛选的具体方法为:计算待查询行人图像表观特征与剩余目标候选图像表观特征的距离,使用欧式距离或使用余弦距离进行度量,对计算出来的距离向量进行排序,得到与待查询行人图像最接近的目标候选图像作为最终行人再识别的结果。
本申请有益效果是:提出了一种结合WebGIS、目标属性和表观特征逐层筛选、从而快速高效进行行人再识别的方案。当目标消失后,首先根据目标类型和WebGIS信息在海量视频中快速筛选出目标关联视频,在目标关联视频中检测行人图像,将这些行人图像作为目标候选图像集;构建一种属性特征和表观特征相结合的多任务行人再识别网络,通过其中的属性网络提取目标属性特征,将待查询行人图像与目标候选图像集中的所有图像进行属性相似度度量并排序,剔除与待查询行人图像的属性特征差异较大的图像;对目标候选图像集中的剩余图像,再由表观网络进行再识别,计算待查询行人图像的表观特征与目标候选图像集中剩余图像表观特征的相似度度量并排序,根据排序结果得到和待查询行人图像属于同一行人的目标图像。该方法能够为长时间大范围行人再识别提供可靠的线索,协助用户快速锁定备查目标。
附图说明
下面结合附图和具体实施方式对本申请作进一步的说明。
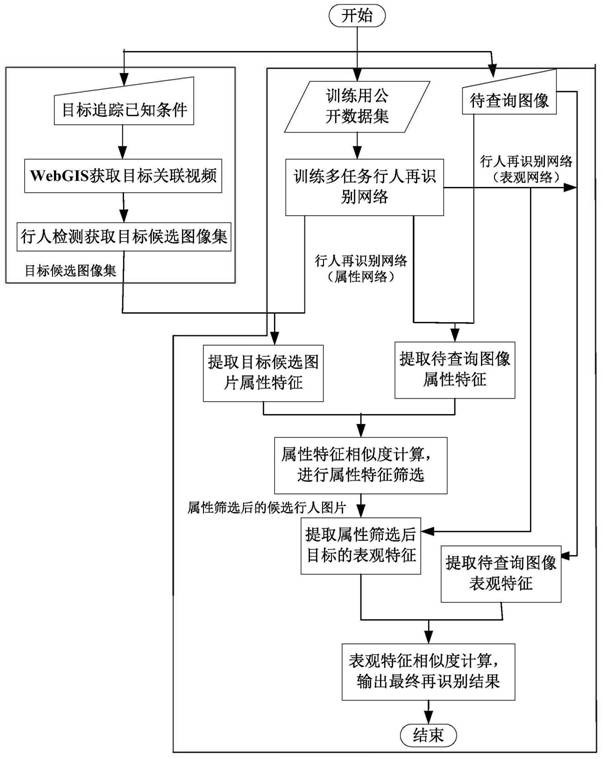
图1为本申请提供的多层次筛选的长时间大范围行人再识别方法流程示意图;
图2为通过WebGIS进行目标关联视频快速筛选流程示意图;
图3为结合属性网络和表观网络的多任务行人再识别网络模型示意图;
图4为属性网络中多层次自适应空间注意力模块的示意图;
图5为多层次自适应空间注意力模块中涉及的多级池化操作的示意图。
具体实施方式
为了使本申请的目的、技术方案和优点更加清楚,下面结合附图与实施例,对本申请进行详细描述。
图1描述了一种多层次筛选的长时间大范围行人再识别总体流程,分为两部分:第一部分通过WebGIS获取目标关联视频,并利用行人检测技术确定目标候选图像集;第二部分通过多任务行人再识别网络在目标候选图像集中查找目标。对于第一部分,首先由用户输入多摄像机目标追踪实例的已知条件,采用《基于WebGIS的目标关联视频快速筛选方法》专利中提出的方法,获取目标关联视频,然后利用行人检测技术将目标关联视频中含有行人的图片裁剪出来作为目标候选图像集。第二部分的行人再识别分为两个阶段,分别为模型训练阶段和模型测试阶段。在模型训练阶段,对提出的多任务行人再识别网络在公开数据集上进行属性网络和表观网络的训练。在模型测试阶段,用户输入待查询行人图像,首先通过多任务行人再识别网络中的属性网络自动提取待查询行人图像的属性特征,根据属性相似度排序结果对目标候选图像集中的图像进行筛选,剔除目标候选图像集中与待查询行人图像的属性特征差异较大的行人图片。然后对目标候选图像集中的剩余行人图片,通过多任务行人再识别网络中的表观网络提取表观特征,计算它们与待查询行人图像的表观相似度,根据表观相似度排序结果查找出与待查询行人图像最相似的行人图片,作为再识别的输出结果。
图2描述了基于WebGIS的目标关联视频快速筛选的流程:用户输入多摄像机目标追踪实例的已知条件(包括目标类型、目标速度、目标消失时刻、目标消失摄像机C
图3描述了本申请提出的多任务行人再识别网络模型,其网络结构主要分为基本网络(Base Network)、属性网络(Attribute Network)以及表观网络(AppearanceNetwork)三部分。以Resnet50残差网络为基本网络,全连接层为分支点,全连接层之前所提取的特征分别输入属性网络和表观网络。属性网络进行属性特征提取,表观网络进行表观特征提取,属性网络和表观网络分别构建损失函数,并采用联合加权损失的方式完成整个网络模型参数的训练更新。
在提出的多任务行人再识别网络中,首先将Resnet50残差网络在ImageNet数据集上预训练,得到预训练模型。在训练和测试时,输入一张行人图像,Resnet50网络会对输入图像进行49次卷积操作以提取行人整体特征,然后以Resnet50网络的全连接层作为分支点,将全连接层之前提取的行人整体特征复制成两份,一份作为属性网络的输入,用于属性网络的属性特征提取,另一份作为表观网络的输入,用于表观网络的表观特征提取。其中,属性网络结合多层次自适应空间注意力模块完成特征加权处理,最终将图像特征映射成属性值。
图4描述了本申请提出的多层次自适应空间注意力模块的结构示意图。多层次自适应空间注意力模块通过多级池化、卷积层、sigmoid层获取特征的权重,然后对行人整体特征进行加权以达到提高显著性属性的目的。该模块主要由多级池化、卷积层和sigmoid层组成。其中,多级池化采用三种方式,分别为均值池化、最大池化以及中值池化,三个池化操作均在通道层面进行。
图5描述了本申请提出的多层次自适应空间注意力模块中涉及的多级池化操作的示意图。该池化操作在通道层面进行,以四通道为例,图中有四个通道,即原始特征图为四通道的,以均值池化为例,均值池化操作是指对每一个通道上对应相同空间位置的值进行求和取平均。例如,图5中四个通道的特征中圆形位置代表的特征值分别为1、2、1、2,那么对该四个圆形代表的空间位置均值池化之后的结果为这四个圆形对应特征值的平均值(1+2+1+2)/4=1.5,即均值池化之后的特征图中的圆形位置特征值为1.5。其它的池化操作方式类似,最大池化是指对每一个通道上对应相同空间位置的值取最大值,中值池化是指对每一个通道上对应相同空间位置的值取中值。
三种池化方式对应输出三个不同注意力层次的特征。对三种池化结果进行通道拼接,形成一个三通道的特征。对该三通道特征卷积得到一个和行人整体特征相同通道数的特征图,然后将该特征图通过sigmoid层转换为特征权重。其中的卷积操作,其卷积核尺寸优选为3×3,输入通道数为3,输出通道数与Resnet50网络提取的行人整体特征的通道数相同。多层次自适应空间注意力模块中的参数通过神经网络的反向传播进行更新。涉及的池化、卷积和sigmoid层的计算公式如下所示:
W(n,C,H,W)=σ(f
其中f
属性网络利用上述多层次自适应空间注意力模块提取到特征权重,且特征权重的尺寸与Resnet50网络提取的行人整体特征的尺寸相同,将行人整体特征与特征权重对应位置相乘得到加权后的特征,再将加权后的特征与行人整体特征对应位置进行相加操作,从而得到加权特征图,该加权特征图的通道数为2048。再通过全局平均池化对该2048个通道进行全局平均池化操作,即对每一个通道所有空间范围的特征值求取平均值,从而得到维度为2048的特征向量。利用卷积层降维,特征向量维度由原来的2048变成512。然后,由全连接层FC充当分类器,将特征映射到相对应的属性输出结果上。最后的损失层采用softmax计算行人的属性损失。对于每一种属性,对应一个softmax计算其对应损失,最终的属性损失值如下所示:
其中J表示属性的种类数,L
在表观网络中,采用表观水平金字塔模型提取行人全局特征和具有判别性的局部特征,具体步骤为:将Resnet50基本网络提取的行人整体特征复制成两份,一份用于保留行人全局特征,一份水平切割成上下相等的两部分,得到上半身和下半身行人局部特征。对于Resnet50网络提取的行人整体特征,通道数为2048,水平切割后,通道数未发生变化,只是每个通道对应的特征值变为原来的一半。然后对行人全局特征和行人局部特征均进行全局平均池化(GAP)和全局最大池化(GMP)操作,得到特征表示。此处的GAP和GMP与属性网络中注意力模块所涉及的池化操作有所不同,GAP是指对每一个通道的所有空间范围的特征值取平均值,2048个通道得到一个2048维的特征向量,该特征向量包含了特征图的全局信息,并考虑了背景上下文。GMP是指对每一个通道所有空间范围的特征值取最大值,同样得到一个2048维的特征向量,该特征向量表示了最具判别性的信息并忽略无关信息(背景,以及和背景相似的衣服等)。
再将GAP和GMP操作后的特征对应位置相加,得到三个维度均为2048的表观特征向量,分别对应行人的全局表观特征、上半身局部表观特征和下半身局部表观特征。然后,将每个表观特征向量进行卷积降维,特征维度由原来的2048变成256。将降维之后的三个表观特征进行拼接,形成行人图像的表观特征,用于后续行人再识别的表观特征相似性度量。同时将卷积降维后的三个表观特征分别输入到全连接层,采用softmax计算行人表观的全局特征损失、上半身特征损失和下半身特征损失。最终的行人身份损失值L
L
其中,L
为了结合属性网络和表观网络实现行人再识别,本申请提出的多任务行人再识别网络模型通过将行人身份损失和行人属性损失加权求和作为最后的损失,实现两种任务的同时训练,最后的联合损失加权函数公式如下所示:
Loss=L
其中L
在训练阶段,首先在ImageNet数据集上训练Resnet50残差网络得到预训练模型,再将整个多任务行人再识别网络模型在行人再识别公开数据集Market-1501上训练。训练过程中,将输入图像的尺寸统一调整到384×128像素,设置批处理大小(batch_size)为32,使用随机水平翻转和归一化的数据增强操作,循环次数(epochs)为60,学习率初始值为0.01。经过40轮的迭代之后,学习率降为0.001,使用随机梯度下降(Stochastic GradientDescent,SGD)优化,动量(momentum)为0.9。训练过程中,当迭代次数达到40次左右时,网络模型基本趋于稳定,这时候降低学习率之后,模型的精度再次有所提升,而达到60次之后模型达到最大首位准确率。所以将网络模型的循环次数设置为60。
得到训练好的模型之后,将其用于经过《基于WebGIS的目标关联视频快速筛选方法》、行人目标检测得到的目标候选图像集,并输入目标消失时刻的图片作为测试图像(即待查询行人图像)。通过Resnet50基本网络提取测试图像的行人整体特征,然后通过属性网络提取该测试图像的属性特征,将其与目标候选图像集中各个图像的属性特征进行属性相似度度量,剔除目标候选图像集中属性特征与测试图像差异较大的行人图片。实验中,softmax计算行人的属性损失L
其中,P
将测试图像与目标候选图像集中行人图片根据提取的属性特征进行属性相似度计算,结果按属性相似度K值从大到小排序,设置筛选阈值R,将排序结果中K值小于R的候选目标图像剔除,完成属性网络筛选过程。在实验过程中,设置的参数J=7,即提取了行人图片的7个属性信息,筛选阈值取经验值R=2。
依据属性网络对目标候选图像集中的行人图片进行筛选之后,再根据表观网络提取剩余目标候选图像的表观特征,与测试图像的表观特征进行表观相似度度量,计算测试图像表观特征与剩余目标候选图像表观特征的距离,这里既可以使用欧式距离,也可以使用余弦距离等其他度量距离来衡量表观相似度。对计算出来的距离向量进行排序,得到与测试图像最接近的目标候选图像作为最终行人再识别的结果。
以上公开的仅为本申请的具体实例,根据本申请提供的思想,本领域的技术人员能思及的变化,都应落入本申请的保护范围内。
- 一种多层次筛选的长时间大范围行人再识别方法
- 一种基于行人属性自适应学习的无监督行人再识别方法