一种基于机器学习提升人脸识别精度的系统及其算法
文献发布时间:2023-06-19 09:41:38
技术领域
本发明涉及人工智能机器学习领域,尤其涉及一种基于机器学习提升人脸识别精度的系统及其算法。
背景技术
人脸识别的应用场景是非常宽泛的,现在主要两块,一个是金融行业,一个是安保行业。
在传统的视频分析中,人脸比对的往往需要一个重点人员管理的原始人脸库,通过比对原始人脸库筛查,这就有可能导致对未录入人员人脸的漏控现象,无法回溯新增人脸的历史轨迹信息。
因此急需一套对全区域地区无比对原始库的人脸库系统,系统通过对人脸的广泛采集,都每一个人构建一个人脸分组,不断完善本地人脸库样本,通过机器学习对分组样本进行自我调优,保证一个分组为同一人,为统计本地人口库,后期新增数据回溯和视频分析提供技术保障。
发明内容
本发明的目的就在于提供一种基于机器学习提升人脸识别精度的系统及其算法,基于机器学习构建本地人脸样本库系统,通过对人脸数据的积累完善本地人脸库系统和精确识别算法,为人脸识别比对分析后的应用、人脸历史数据溯源提供保障。
实现本发明目的技术方案是:本发明通过以下3种方式提升人脸库的识别精度;
亚洲人脸特征的训练模型
由于不同人种存在差异,特别是欧美等外国人脸存在差异性大,因此对于亚洲人而言,采用通用的人脸特征识别算法存在误差较大,阈值较低等问题,因此通过对亚洲人脸的不断训练,可以获取亚洲人的人脸特征平均值,再通过归一算法,实现对亚洲人脸的精确识别。
人脸识别比对算法
基于人脸样本分组集合归一值的人脸比对,可以有效解决人脸分组比对过程中的效率和准确性问题,同时对样本组的比对采用平均特征值可以提升人脸比对的效率,提升数据的准确性,同时可以减少资源消耗对硬件的要求;
基于机器学习的人脸分组样本库优化算法
人脸分组样本库[1,S]是所有新增人脸比对的基础,如何提升人脸库的精准度,过滤掉垃圾人脸数据,保留同一个人的清晰,姿势正面的图片,对于提升人脸识别的精准度至关重要。本算法通过机器学习模型,结合无向图和欧氏距离权重不断优化人脸分组样本库[1,S]的人脸特征质量,提升系统的正确性和比对性能。
本发明采用基于亚洲人脸特征的训练模型、人脸识别比对算法、基于机器学习的人脸分组样本库优化算法构建了本地人脸库系统,可以有效地提升人脸识别的精度,降低人脸误识别的风险,同时通过机器学习模型,可以不断完善人脸比对样本库,为人脸识别比对分析后的应用、人脸历史数据溯源提供保障。
具体地说:
一种基于机器学习提升人脸识别精度的系统及其算法(简称系统)
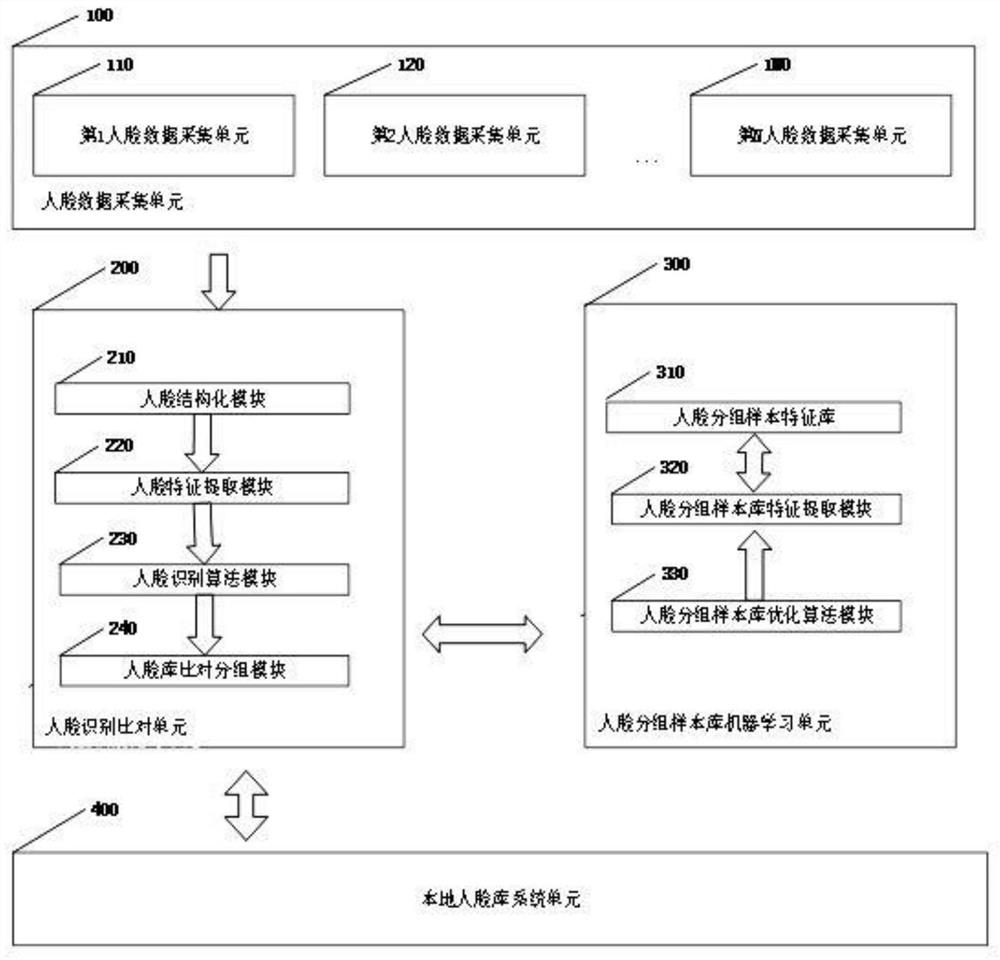
本系统包括人脸数据采集单元、人脸识别比对单元、人脸分组样本库机器学习单元和本地人脸库系统;人脸数据采集单元和人脸识别比对单元交互,人脸识别比对单元分别与人脸分组样本库机器学习单元和本地人脸库系统;人脸数据采集单元包括第1、2……N人脸数据采集单元110、220……2N0,N 是自然数,1≤N;人脸识别比对单元包括依次交互的人脸数据结构化模块210、人脸特征提取模块220、人脸特征识别算法模块230和人脸库比对分组模块 240;人脸分组样本库机器学习单元300包括依次交互的人脸分组样本特征库310、人脸分组样本库特征提取模块320和人脸分组样本库优化算法模块 (330);人脸分组样本库机器学习单元300获取的分组结果,保存到本地人脸库系统(400)中提供给用户进行数据查看和分析。
本发明具有下列优点和积极效果:
亚洲人脸分组更加精确:在无原始精准比对人脸样本下,基于卷积神经网络的人脸特征可以不断完善亚洲人的人脸特征模型,采用归一算法,提升亚洲人脸比对精度;
人脸分组采集更广泛:基于机器学习构建的人脸库,对所有人脸进行采集分析和存储,可以支持后期数据回溯和新增人脸数据检索;不漏掉任何一个人的人脸,新增人脸会自建分组,同时通过基于机器学习分组模型不断优化样本的精度,实现精准识别;
人脸分组识别算法简单高效:基于人脸样本分组集合归一值的人脸比对,可以有效解决人脸分组比对过程中的效率和准确性问题,同时对样本组的比对采用平均特征值可以提升人脸比对的效率,提升数据的准确性,同时可以减少资源消耗对硬件的要求;
系统可扩展高:基于松耦合架构技术,结合人口库系统,可以弹性扩展节点,提升系统的弹性和扩展性;
安防领域应用更广泛:可以广泛应用于智慧社区、智慧城市和公共安全领域,提升线索检索效率。
附图说明
图1是本系统的结构方框图;
图2是本系统的分组样本数据构件的无向权重图。
图中:100、人脸数据采集单元;110、第1人脸数据采集单元;120、第 2人脸数据采集单元;1N0、第N人脸数据采集单元。200、人脸识别比对单元; 210、人脸数据结构化模块;220、人脸特征提取模块;230、人脸特征识别算法模块;240、人脸库比对分组模块;300、人脸分组样本库机器学习单元; 310、人脸分组样本特征库;320、人脸分组样本库特征提取模块;330、人脸分组样本库优化算法模块;400、本地人脸库系统。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
请参阅图1,一种基于机器学习提升人脸识别精度的系统及其算法,本系统包括人脸数据采集单元100、人脸识别比对单元200、人脸分组样本库机器学习单元300和本地人脸库系统400,人脸数据采集单元100和人脸识别比对单元200交互,人脸识别比对单元200分别与人脸分组样本库机器学习单元 300和本地人脸库系统400,人脸数据采集单元100包括第1、2……N人脸数据采集单元110、220……2N0,N是自然数,1≤N;人脸识别比对单元200包括依次交互的脸数据结构化模块210、人脸特征提取模块220、人脸特征识别算法模块230和人脸库比对分组模块240,人脸分组样本库机器学习单元300 包括依次交互的人脸分组样本特征库310、人脸分组样本库特征提取模块320 和人脸分组样本库优化算法模块330,人脸分组样本库机器学习单元300获取的分组结果,保存到本地人脸库系统400中提供给用户进行数据查看和分析。
实施例2
请参阅图1,人脸识别比对单元200包括依次交互的人脸数据结构化模块 210、人脸特征提取模块220、人脸特征识别算法模块230和人脸库比对分组模块240,主要实现了对人脸数据采集单元100采集到的人脸数据的结构化过程,识别人脸,降维度分析,最终通过比对人脸分组样本库机器学习单元300 生成的分组样本库,确定人脸的身份信息,实现人脸数据的归类存储,提供给本地人脸库系统400进行应用分析。
人脸数据结构化模块210
通过和人脸数据采集单元(100)对接,可以获取摄像头获取的人脸图像信息,并通过视频格式的标准化处理、人脸图像增强算法、人脸切割实现人脸图片的精确提取,通过人脸检测(face detection),人脸对齐(face alignment),人脸校验(face verification)技术生成精准度较高的人脸图像,提供给人脸特征提取模块(220)进行人脸特征提取。
人脸特征提取模块220
通过C++工具箱中的卷积神经网络面部检测技术获取进行人脸关键点检测,首先需要检测出图片中的人脸,并估计人脸的关键点姿态。人脸关键点共有68个,分别是人脸各部位的点,如嘴角,眼睛边等,最终生成一个128 位的人脸特征向量,提供给人脸特征识别算法模块230进行人脸识别,最终确定目标人脸的分组。
人脸特征识别算法模块230
通过对人脸特征矫正,结合亚洲人脸特征训练模型,计算出符合亚洲人脸特征的特征维度,提供给人脸库比对分组模块240进行全量人脸样本库的比对。
人脸库比对分组模块240
对新增的人脸特征和人脸分组样本库计算的特征值进行相似度比对,当比对结果小于阈值判定为属于该人脸分组,当比对结果大于判定阈值,为新增人脸数据,需要在人脸分组样本库机器学习单元300和本地人脸库系统400 新增人脸分组。
该种基于机器学习模型提升人脸识别精度的人脸库系统及其算法,其工作原理如下:人脸数据结构化模块210对人脸数据采集单元100的数据进行图像增强和标准化处理,生成精准度较高的人脸图像;人脸特征提取模块220 对人脸数据结构化模块210处理后的图片通过C++工具箱中的卷积神经网络面部检测技术获取进行人脸关键点检测,并提取人脸特征值,提供给下面流程做人脸识别;人脸特征识别算法模块230通过对人脸特征矫正,结合亚洲人脸特征训练模型,计算出符合亚洲人脸特征的特征维度,提供给人脸库比对分组模块240进行全量人脸样本库的比对;人脸库比对分组模块240对新增的人脸特征和人脸分组样本库计算的特征值进行相似度比对;
a、当比对结果小于阈值判定为属于该人脸分组;
b、当比对结果大于判定阈值,为新增人脸数据。
人脸识别后,人脸数据进入入脸分组样本库机器学习单元300进行样本训练模型优化,提升分组样本的精确性;人脸识别确定分组后,数据入到本地人脸库系统400相应分组,如果没有分组的,新增人脸分组,提供给应用进行分析。
人脸分组样本库机器学习单元300
人脸分组样本库机器学习单元300主要实现了对人脸分组样本的维护功能,借助机器学习技术,实现对比对分组样本的机器学习,通过优化模型不断优化分组内的人脸图片质量,达到最优的分组结构,提供给人脸识别比对单元200进行比对分析。
人脸分组样本特征库310
人脸分组样本特征库310保存了比对样本的分组情况,用来提供给人脸识别比对单元200比对特征值信息。
人脸分组样本库特征提取模块320
新增样本后,人脸分组样本库特征提取模块320会提取样本的特征值,计算样本平均特征值,生成分组样本的比对特征值,并更新人脸分组样本特征库310。
人脸分组样本库优化算法模块330
新增样本后,人脸分组样本库优化算法模块330将触发对样本内的人脸机器学习模型。对分组样本进行优化处理,自动剔除质量差或者是错误的数据,当集合数量的值小于样本数量阈值的时候,将图片特征加入到样本中进行分析;当集合数量大于样本数量阈值的时候,取集合中欧式距离总和最大的值剔除集合。当数据量越来越多,欧式距离较远的人脸特征样本将逐渐被系统所淘汰,相似度较高的人脸特征会不断更新各个分组的样本,实现对同一人的精确比对。
人脸分组样本库机器学习单元300其工作流程是:
人脸分组样本特征库310初始化的时候,对没有人脸分组的情况下,对新增人脸图片进行新增样本分组,包括人脸分组编号、分组人脸比对特征值、人脸图片数量等,具体到每个分组包括多条记录人脸分组编号、人脸组内综合距离评分、人脸图片位置、人脸特征值、人脸组内排名等,实现对人脸分组样本特征库的初始化操作;人脸识别比对单元200分析完成的人脸数据,根据识别结果进行样本的训练学习;
a、当新增人脸分组已经不存在的情况下,新增新的分组;
b、当新增人脸分组已经存在的情况下,加入该分组进行样本学习。
新增图片在确定分组后,系统将触发人脸分组样本库优化算法模块330 进行人脸特征机器学习算法,更新分组模型的参数;
a、对新增的人脸结合亚洲人训练模型进行降维特征提取;
b、将新增的人脸图片加入该分组模型,对分组样本构建无向权重图,权重为各个节点之间的欧式距离;
c、计算分组集合内所有人脸特征所有点之间的欧式距离总和,并将该数据更新到集合中的所有节点;
d、对分组内计算的距离总和集合进行按照欧氏距离总和由小到大排序,欧式距离越小表示人脸特征越相似;
e、对分组样本N进行优化处理,自动剔除欧氏距离最大的数据集合。
人脸分组样本库特征提取模块320会提取样本分组的特征值,计算样本平均特征值;生成分组样本的比对特征值,并更新人脸分组样本特征库310。
本地人脸库系统400
本地人脸库系统400是人脸识别比对的结束位置,负责将人脸分组数据提供给其它系统调用和做业务分析。
本系统的工作机理如下:
人脸数据采集单元100负责整个系统的数据采集工作,可以对接摄像头,也可以对接国标视图库等标准数据,数据采集单元可以有多个;人脸识别比对单元200实现了对人脸数据采集单元100采集到的人脸数据的结构化过程,识别人脸,降维度分析,获取人脸特值;人脸识别比对单元200的人脸库比对分组模块240对新增的人脸特征和人脸分组样本库计算的特征值进行相似度比对,确定人脸的身份信息;比对结果分为两个部分,一部分提供给本地人脸库系统400进行应用分析,一部分提供给人脸分组样本库机器学习单元 300进行样本机器学习;新增图片在确定分组后,系统将触发人脸分组样本库优化算法模块330进行人脸特征机器学习算法,更新分组模型的参数;样本分组确定后,人脸分组样本库特征提取模块320会提取样本分组的特征值,计算样本分组平均特征值;新的样本分组信息更新到人脸分组样本特征库 310。
算法
人脸特征提取算法
特征脸反映了隐含在人脸样本集合内部的信息和人脸的结构关系。将眼睛、面颊、下颌的样本集协方差矩阵的特征向量称为特征眼、特征颌和特征唇,统称特征子脸。特征子脸在相应的图像空间中生成子空间,称为子脸空间。计算出测试图像窗口在子脸空间的投影距离,若窗口图像满足阈值比较条件,则判断其为人脸。本方法中对于人脸特征的提取采用C++工具箱来实现人脸特征检测。通过C++工具箱中的卷积神经网络面部检测技术获取进行人脸关键点检测,可以生成一个128位的人脸特征向量Ω
Ω
亚洲人脸特征的训练模型
由于不同人种存在差异,特别是欧美等外国人脸存在差异性大,因此对于亚洲人而言,采用通用的人脸特征识别算法存在误差较大,阈值较低等问题,因此通过对亚洲人脸的不断训练,可以获取亚洲人的人脸特征平均值,再通过归一算法,实现对亚洲人脸的精确识别;假设系统已经识别了人脸图片h张图片(所述的h是自然数,代表系统处理的人脸图片数量,1≤h)。通过人脸识别算法将h个人脸特征值向量T放到一个集合N里,如下式所示: h={T
人脸识别比对算法
距离方式直接计算测试图片和样本图片之间的距离来判断二者之间的相似性,在人脸识别中,我们通常采用欧氏距离和余弦距离来衡量人脸特征的相似度,判别是否为同一个人。具体流程如下:人脸特征提取,通过人脸特征提取,对新增人脸提取其128位的人脸特征值,如下式所示:Ω
人脸分组样本库平均特征算法
该算法实现了对人脸样本库的特征算法过程,通过该算法可以实现样本库特征算法,为大批量人脸比对减少比对数量,提升比对效率,可对百万级别数据进行快速运算;人脸特征样本集合初始[1,S],在无原始精准比对样本下,新增的人脸样本分组根据识别的结果自动生成新的样本集合N,已存在的人脸样本组,则将人脸数据加入该样本组,进行样本的机器学习(所述的S是自然数,代表分组样本集合数量,1≤S);人脸特征分组N的归类。通过比对结果获取单一人脸样本分组集合N。集合N为包含M张人脸图像的集合(所述的M是自然数,代表一个样本分组N的人脸图片数量,1≤M≤40)。通过人脸识别算法将M个人脸特征值向量T放到一个集合N里,如下式所示:N={T
a、通过归一算法,可以减少不同人种之间的差异,让系统通过不断机器学习,构建一套满足亚洲人的样本集合,提升系统的人脸识别率;
b、相对于分组随机抽样比对,基于人脸样本分组集合N平均值的人脸比对可以减少随机抽样人脸图片比对的问题,提升比对的准确性;
c、相对于分组全量比对,基于人脸样本分组集合N平均值的人脸比对通过对分组特征值预处理可以避免和组内每张图片进行比对,减少了比对次数和时间,减少运算成本。
基于机器学习的人脸分组样本库优化算法
人脸分组样本库[1,S]是所有新增人脸比对的基础,如何提升人脸库的精准度,过滤掉垃圾人脸数据,保留同一个人的清晰,姿势正面的图片,对于提升人脸识别的精准度至关重要。本算法通过机器学习模型,结合无向图和欧氏距离权重不断优化人脸分组样本库[1,S]的人脸特征质量,提升系统的正确性和比对性能;在人脸分组样本库平均特征算法中实现了人脸特征分组集合N的归类,集合N为包含M张人脸图像的集合(所述的M是自然数,代表一个样本分组N的人脸图片数量,1≤M≤40)。通过人脸识别算法将M个人脸特征值向量T放到一个集合N里,如下式所示:N={T
计算分组集合N内所有人脸特征所有点之间的欧式距离总和d,并将该数据更新到集合N中的所有节点,计算人脸k的欧式距离公式如下:
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于机器学习提升人脸识别精度的系统及其算法
- 一种提升FMCW雷达手势识别精度的干扰抑制算法