基于Bi-LSTM和字词融合的汉语分词方法
文献发布时间:2023-06-19 09:58:59
技术领域
本发明属于循环神经网络技术领域,涉及一种基于Bi-LSTM和字词融合的汉语分词方法。
背景技术
汉语分词,即对连续汉字序列按照一定规则进行分词,不同于印欧语系其句子中词与词之间通常使用空白进行分隔,汉语文本中通常只在句子与句子、段落与段落间使用符号隔开,单独的句子中词与词之间没有任何分隔符,书写连续,人们阅读时需按照学习到的思维模式首先对汉语句子进行划分,再理解其中包含的深层含义。同时,我们对中文资料进行检索时,计算机应首先提取出我们输入的汉语句子中的关键信息,其次才能实现检索等功能;在我们进行人机交互的过程中,计算机往往需要提取出汉语文本中包含的情感、立场以及态度等深层的、主观的信息,这同样是离不开汉语分词的工作,因此,对汉语进行分词处理是十分必要的。
现有技术中,根据分词方式的不同,可以将汉语分词技术分为三大类:查询词典式,基于数理统计式和传统机器学习式。
1.基于词典查询的中文分词技术
上世纪九十年代末期,中文分词技术普遍采用词典查询的形式,常用方法如最大匹配法、最少切分法等。这种方法可以视为在词典中寻找匹配的词语的过程,分词的精度高,操作起来较为简单,易于上手。
但是这种分词方式的缺点也显而易见,其需要维护一个庞大的词典,词典的广度、深度和质量往往直接影响到分词的准确度,例如,若词典中不存在待分词句子存在的词语时,基于词典的分词方法往往会将该词语错误地切分为其他词语,因此导致这种方法对歧义词的识别能力不足,也无法解决未登录词的问题,分词的速度一般,需要消耗大量的人力,拓展性和鲁棒性较差。
2.基于数理统计的中文分词技术
基于数理统计的中文分词方法通常要在分词前对待处理文本中的单字以及相邻多个单字做统计学方面的统计,对多次出现的连续单字做出为一个词的判断,例如常用的方法有基于最大熵模型的命名实体识别、基于隐马尔可夫模型的词性标注以及条件随机场等。
这种基于数理统计的方法对歧义词以及未登录词的识别能力强,不受语料库涉及的领域影响,但该方法需要大量的语料库作为模型的训练数据,并且若在文本中出现多次口语性的表述时,其往往会将一些多次出现的语气助词与其相邻的单字统计为一个词语,无法从深层语义层面对文本进行分词,同时,该基于数理统计的分词方法的识别速度还有待提高。
3.基于传统机器学习的中文分词技术
基于传统机器学习的中文分词技术主要是将传统的神经网络应用到待分词文本的序列标注问题上,其实质上是将分词问题转化为分类问题,即单字在句子中的标注问题。
在机器学习逐渐兴起之后,由于其只需要对文本特征进行标注,机器便可以自动学习文本中包含的深层次的特征,基于传统的机器学习的中文分词方法展现出了巨大的优势,该方法的优点是可以将词典词与未登录词作同等对待处理,但该方法的分词质量取决于人为选取的特征,存在一定的局限性。
发明内容
为解决上述问题,本发明提出的基于Bi-LSTM和字词融合的汉语分词方法属于自然语言处理类,该方法不同于上述进行分词的方法,其利用计算机自动地对汉语句子进行分词,所使用的双向循环神经网络,能提取句子中的前向语义以及后向语义,并且相比于传统的机器学习方法,其增加了遗忘门、输入门以及输出门,能够更好地提取特征,使人们从机械地、枯燥地分词工作中解放出来,同时创新性地使用字词融合方法进一步提高特征信息的获取能力,提高了分词的效率与准确度,扩大了中文分词的应用场景,能更好地辅助后续基于中文分词的工作。
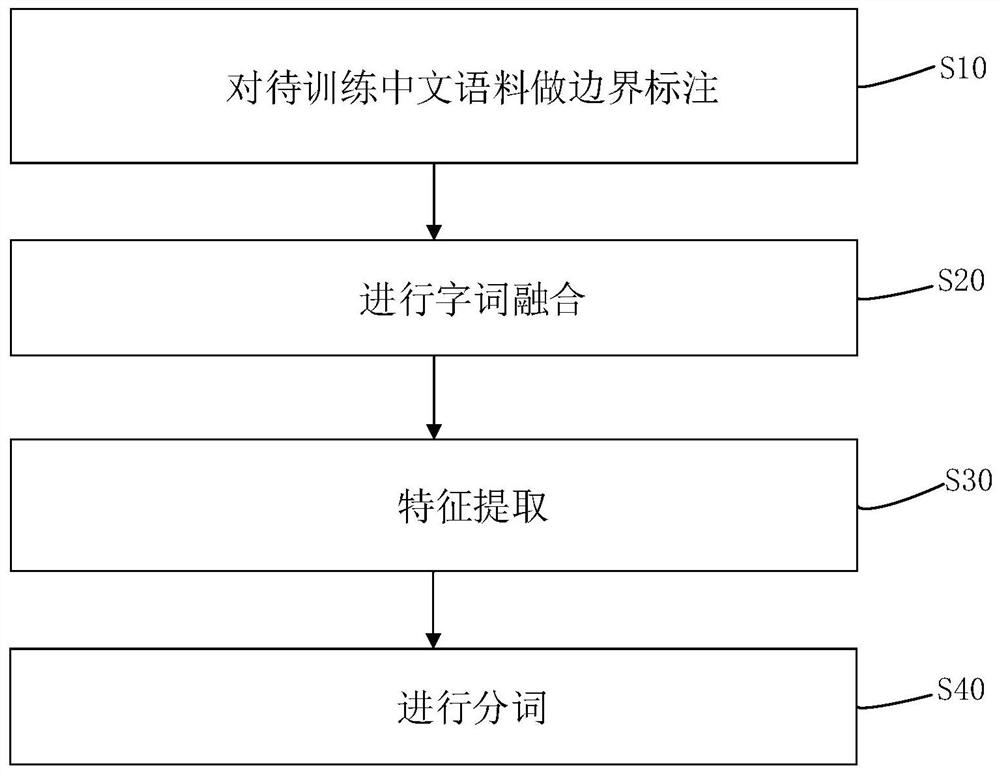
为实现上述目的,本发明的技术方案为基于Bi-LSTM和字词融合的汉语分词方法,基于Bi-LSTM和字词融合的汉语分词系统包括依次连接的边界标注模块、字词融合模块、特征提取模块和中文分词模块,采用上述系统的方法包括以下步骤:
S10,对待训练中文语料做边界标注;
S20,进行字词融合;
S30,特征提取:将字词向量序列V
S40,进行分词:将待分词的中文文本输入训练好的Bi-LSTM中,得到文本中每个字的标注信息,再根据标注信息对文本进行分词。
优选地,所述边界标注模块将训练语料中的每个字标注为4种,分别为B、E、M、S,其中B代表词的开头,E代表词的结尾,M代表词的中间字,S代表单独成词的字。
优选地,所述字词融合模块将待训练语料中的每个字或词嵌入处理转化为字向量序列V
优选地,所述特征提取模块将经过边界标注后的字词向量序列V
优选地,所述中文分词模块将待处理中文文本输入生成的分词模型,实现中文分词功能。
优选地,所述对待训练中文语料做边界标注为将训练语料中的每个字标注为4种,分别为B、E、M、S,其中B代表词的开头,E代表词的结尾,M代表词的中间字,S代表单独成词的字。
优选地,所述进行字词融合,包括以下步骤:
S21,将待训练语料中的每个字或词嵌入处理,转化为字向量序列V
S22,按照预定规则将语料分词并将每个词转化为词向量V
S23,将V
本发明提出了一种基于Bi-LSTM和字词融合的汉语分词方法,利用双向长短期记忆人工神经网络,提高了汉语分词的精确度,采用计算机自动地实现汉语句子的分词,解放了人工生产力;利用字词融合手段来获取更多的特征信息,进一步提高了分词的准确性,使该技术能更好地辅助后续例如分析文本语义等工作。
本发明至少还有以下有益效果:
1、提出将Bi-LSTM和字词融合结合成新颖的中文分词方法,通过Bi-LSTM和字词融合,能够提取句子中单字级和词语级的前向语义以及后向语义,相比于传统的中文分词技术,本发明专利提出的Bi-LSTM和字词融合的中文分词方法能够获取更充分的特征信息,提高了中文分词的准确度。
2、将字词融合应用到中文分词领域,将单字级向量序列和词语级向量序列融合起来,相比于仅使用Bi-LSTM网络的中文分词方法,Bi-LSTM与字词融合相结合的方法能够更好地实现中文分词任务,提高了分词任务的准确度,为后续基于分词的任务提供了很好的解决方案。
3、将字词融合模块与特征提取模块结合使用,实现了一套完整的中文分词系统。相比于传统的中文分词方法,本发明专利提出的Bi-LSTM和字词融合的中文分词系统可以自动地进行中文分词工作,减少了人力投入,同时增强了模块间的耦合度,提高了中文分词的效果。
附图说明
图1为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的步骤流程图;
图2为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的系统框图;
图3为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的S10实例图;
图4为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的S20实例图;
图5为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的S40模型示意图;
图6为本发明方法实施例的基于Bi-LSTM和字词融合的汉语分词方法的S40实例图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
在介绍整体方案前,对以下词组和符号进行定义:
1.Bi-LSTM:双向循环神经网络,由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同;
2.字词融合:将单字级词嵌入向量与词语级词嵌入向量融合为字词词嵌入向量。
3.分词:将一段连续中文序列按照规则自动分成单独中文词序列的过程。
4.词嵌入:是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
参见图1,为本发明实施例的本发明的技术方案为基于Bi-LSTM和字词融合的汉语分词方法的步骤流程图,基于Bi-LSTM和字词融合的汉语分词系统框图参见图2,包括依次连接的边界标注模块10、字词融合模块20、特征提取模块30和中文分词模块40,采用上述系统的方法包括以下步骤:
S10,对待训练中文语料做边界标注;
S20,进行字词融合;
S30,特征提取:将字词向量序列V
S40,进行分词:将待分词的中文文本输入训练好的Bi-LSTM中,得到文本中每个字的标注信息,再根据标注信息对文本进行分词。
S10-S3-属于模型训练阶段,S40为分词阶段。
边界标注模块10将训练语料中的每个字标注为4种,分别为B、E、M、S,其中B代表词的开头,E代表词的结尾,M代表词的中间字,S代表单独成词的字
字词融合模块20将待训练语料中的每个字或词嵌入处理转化为字向量序列V
特征提取模块30将经过边界标注后的字词向量序列V
中文分词模块40将待处理中文文本输入生成的分词模型,实现中文分词功能。
对待训练中文语料做边界标注为将训练语料中的每个字标注为4种,分别为B、E、M、S,其中B代表词的开头,E代表词的结尾,M代表词的中间字,S代表单独成词的字。实例参见图3.
进行字词融合,实例参见图4,包括以下步骤:
S21,将待训练语料中的每个字或词嵌入处理,转化为字向量序列V
S22,按照预定规则将语料分词并将每个词转化为词向量V
S23,将V
将待分词的中文文本输入训练好的Bi-LSTM中,得到文本中每个字的标注信息,再根据标注信息对文本进行分词,分词模型参见图5,分词后效果参见图6。
本发明步骤将待训练中文语料按照图3所示的方式进行单字级的标注;
将语料中的单字序列输入embedding层,得到字向量序列V
将V
将待分词中文文本输入训练好后的分词模型中,最后通过全连接层与softmax层得到每个字的预测标签结果,再根据每个字的标签对文本进行分词。
本发明基于Bi-LSTM和字词融合方法,有机地将两种方法引入中文分词任务中,既能够根据文本前后语义准确地分割文本,更进一步,本发明创新性地在中文分词任务中引入字词融合方法,不仅能够在词语级语义的指导下进行分词模型的训练,也能够在单字级语义下对分词任务做补充,提高了分词任务的准确性。
训练得到的分词模型兼顾快速性与准确性,得到的分词结果更加细致准确,对后续基于分词的任务提供了有益的预处理结果,例如自动翻译任务、搜索引擎、语音合成等,良好的分词语料是提高这些任务性能不可或缺的一步。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 基于Bi-LSTM和字词融合的汉语分词方法
- 基于标签引导的字词融合的命名实体识别方法