一种基于Kafka的埋点数据实时采集计算和存储的方法
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及数据处理技术,具体涉及一种基于Kafka的埋点数据实时采集计算和存储的方法。
背景技术
目前,随着互联网、移动互联网的快速发展和5G时代的到来,各式的产品层出不穷,客户端产品种类也变得更加多样,用以满足广大用户的需要;用户使用各类产品的同时,便产生了海量的用户行为数据。与此同时,海量的用户行为如果不能得到及时、有效的采集、挖掘、分析和应用,便失去了用户行为数据本身该有的价值。
实际生产应用中,一方面,用户行为埋点数据定义不全面、开发流程混乱、使用不规范,埋点的元事件、元数据无统一的管理,这样便无法满足全域用户行为分析、产品智能化,精细化运营等需要。另一方面,已有埋点数据采集技术中,多为异步、准实时、离线的采集、处理、存储的方式,并无在埋点数据采集的同时,针对产品运营、用户行为分析业务相关的业务指标进行实时计算、分析、挖掘,并不能及时、高效地满足埋点采集领域的实时指标分析应用、实时监控、预警的需要。
针对上述问题,目前的技术和应用中,尚无系统的、有效的解决方案。
发明内容
本发明提供了一种基于Kafka的埋点数据实时采集计算和存储的方法,采用Kafka技术实时采集用户访问行为信息,并在源头加工实时指标,解决当前技术中存在的埋点数据采集、加工实时指标效率低下,不能高效及时满足埋点数据采集领域的实时指标计算、产品运营分析、用户行为分析、实时监控和预警的需要。
本发明一种基于Kafka的埋点数据实时采集计算和存储的方法,包括:
A.定义前端埋点内容和后端接口埋点内容,并在前端和后端进行埋点;
本发明定义的前端埋点内容包括但不限于微信公众号、小程序、APP、WEB网页中所涉及的各类事件,如页面浏览事件(page_evt)、用户事件(user_evt)、启动(start_evt)和退出事件(quit_evt)、点击事件(click_evt)、崩溃事件(breakdown_evt)等。当上述的埋点内容也无法满足业务统计需要时,可对当前的操作定义为自定义事件(custom_evt),并作为埋点内容。后端接口埋点内容是后端接口调用产生的埋点数据。可对上述的前端埋点数据和后端接口埋点数据进行元数据管理,如生成、启用、停用、废除等操作。
对埋点的元事件、元数据进行统一的管理,满足全域用户行为分析、产品智能化,精细化运营等需要。
B.根据用户在操作业务系统时产生的行为,选择前端或后端与埋点采集系统建立连接;
C.建立连接后,埋点采集系统采集并接收前端埋点数据或后端接口埋点数据;
D.埋点采集系统解析接收到的埋点数据,得到基本字段和衍生字段,将得到的基本字段和衍生字段实时转发至Kafka消息队列;;
E.埋点采集系统根据步骤D中得到的基础字段和衍生字段,对产品运营、用户行为分析涉及到的业务指标进行匹配、统计、计算得到实时指标,并将上述实时指标实时转发至Kafka消息队列的topic_result中;
业务指标包括但不限于:按照不同维度,统计用户数(新注册用户、老用户、游客:未登陆用户)、PV(页面访问次数)、UV(访问用户数)、平均停留时长(每个页面的停留时长取平均值)、跳出率(没有下一页的页面访问次数除以页面访问次数)、留存率、用户画像(性别、年龄、学历、位置)、信贷产品不同环节的通过数和通过率(注册、登录、实名、绑卡、授信、借款)、电商产品不用环节的通过数和通过率(启动、注册、登录、实名,搜索、添加购物车、提交订单、支付、收藏、分享、评价)。
业务指标的统计维度包括但不限于:渠道、产品、时间(今日实时累计)、事件名称。
F.可视化系统通过实时消费步骤E所述Kafka消息队列topic_result中的业务指标,或查询实时数据仓库中的HBase业务指标表,将业务指标进行可视化展现,将步骤E中所述的业务指标、步骤D中得到的基本字段和衍生字段依次持久化存储至实时数据仓库、离线数据仓库中。
持久化存储到实时数据仓库时,将基本字段、衍生字段、业务指标,均存储到HBase表中,为保证数据查询效率、以及分区大小均衡,需要结合HBase表的列存储特点,合理地设计主键rowkey,如下
用户事件(user_evt):rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+手机号+事件id+13位随机数。
除用户事件(user_evt)外的其他事件:rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+事件id+13位随机数。
接口数据:rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+接口id+13位随机数。
G.业务指标监控与告警:在n分钟内,步骤E中的业务指标超过指标阈值上限、或低于阈值下限,两者均由埋点采集系统发送告警短信给应用负责人,n为自然数,指标阈值上下限由业务人员根据经验指定。
由于埋点整体链路较长,采集到的埋点数据从前端或者后端上送到埋点采集系统,经过加工再到kafka消息队列,再消费kafka消息队列各个topic中的数据到达实时数据仓库HBase表或者到达可视化系统,再到离线的数据仓库系统持久化,整个流程链路较长,任何一个环节出现问题,都会造成埋点数据采集、以及业务指标加工失败,因此需要对数据进行监控。
本发明是一个全面的、系统化的用户行为实时采集、分析系统,能够灵活的对用户行为涉及到的事件进行定义和管理;并且能够实时采集用户行为数据,并经过解析、统计得到目标字段和业务指标,并能够将目标字段、业务指标以毫秒级、秒级的速度进行可视化展示。
进一步的,在步骤A中,所述的前端埋点内容为用户行为触发前端事件所产生的数据,后端接口埋点内容为用户行为触发的后端接口调用所产生的数据。
所述的前端埋点内容是由前端的各类事件组成,包括每个事件的:事件id、事件名称。
所述的后端接口埋点内容是由所有接口自身信息及接口调用结果组成,包括每个接口的:接口id、接口名称、接口调用时间、接口响应时间、接口响应结果。
进一步的,步骤B包括,当用户在操作业务系统时,如果产生业务系统的前端埋点数据,则业务系统的前端和埋点采集系统接口进行参数校验,如果产生业务系统的后端埋点数据,则业务系统的后端和埋点采集系统接口进行参数校验。两者的参数校验包括:域名或者ip地址校验、接口名校验、端口号校验;根据预先设定,校验成功后,再建立socket连接。
所述连接为外网与内网的连接,此时需要外网和内网进行交互,交互时的网络策略采用Nginx或者F5的方式对公网到内网的网络进行映射,达到负载均衡、灵活配置流量的目的。
进一步的,在步骤C中,所述埋点采集系统采集并接收前端或后端埋点数据,具体为:当步骤B中与埋点采集系统进行连接的为业务系统前端时,埋点采集系统采集并接收前端埋点数据;当步骤B中与埋点采集系统进行连接的为业务系统后端时,埋点采集系统采集并接收后端埋点数据;然后将接收到的埋点数据上送传输到埋点采集系统。
所述上送传输过程为了避免在传输过程中数据被非法窃取,采用客户端(Client)到服务器端(Server)的HTTPS方法,并通过POST的请求方式上送传输采集到的用户行为数据。
进一步的,在步骤D中:
D1.埋点采集系统接收到结构化的埋点数据,并根据Key-value的形式进行解析,得到前端事件、后端接口,以及每个前端事件对应的其他字段内容,每个后端接口对应的其他字段内容;
D2.将解析到的字段实时转发至Kafka消息队列,其中前端事件对应的字段,实时转发至Kafka消息队列中名称为topic_evt的Topic,其中后端接口对应的字段,实时转发至Kafka消息队列中名称为topic_interface的Topic。
D1和D2所述的两个topic中的数据作为采集到的埋点数据基本字段、衍生字段。
进一步的,在步骤E中:
E1.通过Flink的方法实时消费kafka消息队列topic_evt、topic_interface中的字段,通过Tumbling Windows方法让数据不重叠,采用Filter方法过滤数据、keyBy方法对数据分组、join方法对数据关联、connect方法合并多个数据流为一个数据流、aggregate方法对数据聚合处理,如计数、求和、平均、加权平均,得到业务指标;
E2.通过SlipStream批量消费kafka消息队列topic_evt、topic_interface中的字段,再根据SQL对数据进行过滤、关联、分组、聚合,得到业务指标;
E3.将通过上述两种方法得到的业务指标,实时发送至Kafka消息队列的topic_result中。
进一步的,在步骤F中:
F1.通过应用程序实时消费Kafka消息队列topic_result中的业务指标,在可视化系统中将业务指标进行可视化展现,或查询实时数据仓库中的HBase业务指标表,在可视化系统中将实时数据仓库中的业务指标进行可视化展现;
F2.将步骤D和E中得到的业务指标、基本字段、衍生字段,以数据流的方式持久化存储于实时数据仓库中,持久化到实时数据仓库时,将基本字段、衍生字段、业务指标,均存储到HBase表中;
F3.通过数据仓库的ETL方法将实时数据仓库的数据持久化到离线数据仓库中。
本发明一种基于Kafka的埋点数据实时采集计算和存储的方法,通过自定义埋点数据事件,全面的定义了用户行为埋点数据,使整个开发流程清晰可见、并使埋点数据的定义规范化,对埋点的元事件、元数据进行统一的管理,满足了全域用户行为分析、产品智能化,精细化运营等的前提需要;同时,通过埋点采集系统解析埋点数据得到基本字段和衍生字段,并将得到的基本字段和衍生字段实时转发至Kafka消息队列,可视化系统通过实时消费Kafka消息队列,可视化目标业务指标;在埋点数据采集的同时,针对产品运营、用户行为分析业务相关的业务指标进行实时计算、分析、挖掘,对埋点整体链路进行监控预警让整个流程更加可控、降低风险,及时、高效地满足了埋点数据采集在实时指标分析、实时监控、预警等方面的应用。
附图说明
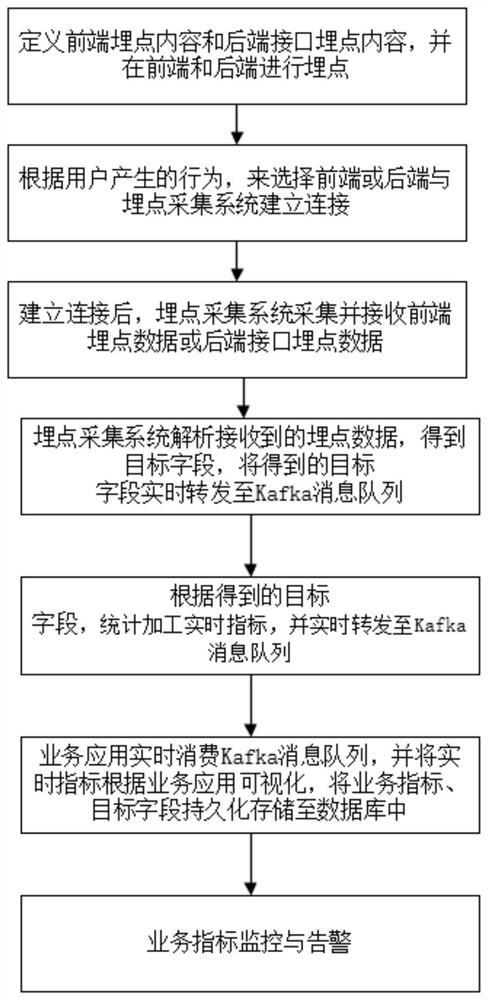
图1为本发明一种基于Kafka的埋点数据实时采集计算和存储的方法的流程图。
图2为本发明一种基于Kafka的埋点数据实时采集计算和存储的方法的架构图。
图3为本发明内网与外网交互连接时以ip映射方式的网络负载均衡图。
图4为本发明内网与外网交互连接时以域名映射方式的网络负载均衡图。
具体实施方式
以下结合实施例的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。在不脱离本发明上述技术思想情况下,根据本领域普通技术知识和惯用手段做出的各种替换或变更,均应包括在本发明的范围内。
如图1所示本发明的一种基于Kafka的埋点数据实时采集计算和存储的方法,包括:
A.定义前端埋点内容和后端接口埋点内容,并在前端和后端进行埋点;
所述的前端埋点内容是由前端的各类事件组成,包括每个事件的:事件id、事件名称。
所述的后端接口埋点内容是由所有接口自身信息及接口调用结果组成,包括每个接口的:接口id、接口名称、接口调用时间、接口响应时间、接口响应结果。
B.根据用户在操作业务系统时产生的行为,选择前端或后端与埋点采集系统建立连接;
当用户在操作业务系统时,如果产生业务系统的前端埋点数据,则业务系统的前端和埋点采集系统接口进行参数校验,建立socket连接;如果产生业务系统的后端埋点数据,则业务系统的后端和埋点采集系统接口进行参数校验,建立socket连接;所述的参数校验包括:域名或者ip地址校验、接口名校验、端口号校验,根据预先设定,校验成功后,再建立socket连接。所述连接为外网与内网的连接,此时需要外网和内网进行交互,交互时的网络策略采用Nginx或者F5的方式对公网到内网的网络进行映射。
C.建立连接后,埋点采集系统采集并接收前端埋点数据或后端接口埋点数据;
所述埋点采集系统采集并接收前端或后端埋点数据,具体为:当步骤B中与埋点采集系统进行连接的为业务系统前端时,埋点采集系统采集并接收前端埋点数据;当步骤B中与埋点采集系统进行连接的为业务系统后端时,埋点采集系统采集并接收后端埋点数据。
D.埋点采集系统解析接收到的埋点数据,得到基本字段和衍生字段,将得到的前端埋点事件、后端接口埋点内容的基本字段和衍生字段实时转发至Kafka消息队列的不同topic中,前者转发至topic_evt中,后者转发至topic_interface中。
E.埋点采集系统根据步骤D中得到的基础字段和衍生字段,对产品运营、用户行为分析涉及到的业务指标进行统计计算得到实时指标,并将上述实时指标实时转发至Kafka消息队列的topic_result中;
F.可视化系统通过实时消费步骤E所述Kafka消息队列topic_result中的业务指标,或查询实时数据仓库中的HBase业务指标表,将业务指标进行可视化展现,将步骤E中所述的业务指标、步骤D中得到的基本字段和衍生字段依依次持久化存储至实时数据仓库、离线数据仓库中。
如图2所示本发明的一种基于Kafka的埋点数据实时采集计算和存储的方法的架构图,包括:
S1.用户在外网操作业务系统时,用户行为触发产生埋点数据;如果用户行为触发前端埋点事件,则产生前端埋点数据,如果用户行为触发后端接口调用,则产生后端接口埋点数据;
S2.前后端与埋点采集系统建立连接,并将各自的埋点数据上送至埋点采集系统;
S3.埋点采集系统对接收到的结构化埋点数据,根据Key-value的形式进行解析,得到前端事件、后端接口,以及每个前端事件对应的其他字段内容,每个后端接口对应的其他字段内容。然后将解析到字段实时转发至Kafka消息队列,其中前端事件对应的字段,实时转发至名称为topic_evt的Topic中(Topic是代表着数据的类别,一个topic可以认为是一类消息。);后端接口对应的字段,实时转发至名称为topic_interface的Topic中;埋点采集系统对产品运营、用户行为分析涉及到的业务指标进行统计计算,得到相应的业务指标并实时发送至Kafka消息队列的topic_result中;
S4.通过应用程序(包括但不限于JAVA、PYTHON、SmartBI)实时消费Kafka消息队列topic_result中的业务指标,将业务指标进行可视化展现;
S5.将通过Slipstream方式消费Kafka消息队列中topic_result得到的业务指标、以及topic_evt、topic_interface得到基本字段、衍生字段,以数据流的方式持久化存储于实时数据仓库中,可视化系统通过查询HBase表,对业务指标进行可视化展现;
S6.通过数据仓库的ETL(抽取(extract)、转换(transform)、加载(load)),将实时数仓中的数据持久化到离线数据仓库中。
如图3或4所示本发明内网与外网交互连接时的网络负载均衡图,本发明为达到负载均衡,灵活配置流量的目的,系统需要对外网和内网进行映射,通过映射方式达到网络负载均衡的方法有两种:
方法一,以ip映射方式的网络负载均衡,以Nginx或者F5的负载均衡方式,将外网ip_outer,映射到内网ip_inner,端口号均为port;
方法二,以域名映射方式的网络负载均衡,以同样的负载均衡方式Nginx或者F5,将外网的“域名_outer”,映射到内网“域名_inner”,端口号均为port。
实施例:
步骤A:定义埋点内容,包括前端埋点内容和后端接口埋点内容;前端埋点内容表如下:
表1前端埋点内容表
前端埋点内容所包含的事件包括但不限于表1列出的事件。
其中,客户端类型包括:Android、IOS、H5、小程序。
另外,不同的事件包含不同的字段,如用户事件包括:事件id、用户手机号、姓名、客户端类型、渠道、经纬度、时间、代码版本号、屏幕分辨率、网络类型、ip地址、设备型号、操作系统。浏览事件除了用户事件中包含的内容外,还包括:事件id、当前页面名称、来源页名称、当前页URL、来源页URL。点击事件除了用户事件中包含的内容外,还包括:事件id、点击事件名称、点击事件含义。
后端接口埋点内容表如下:
表2后端接口埋点内容表
后端接口埋点内容所包含的接口包括但不限于表2列出的接口。
根据表1、表2,完成对前端埋点内容、后端接口埋点内容的定义。另外,可对定义的事件、接口进行元数据管理,包括启用、停用、修改。
分别对前端、后端接口进行埋点。前端埋点的方式包括但不限于代码埋点、全埋点、可视化埋点,并对定义的埋点内容进行埋点。其中,代码埋点通常将如下A01-A02的映射关系,植入目标代码,并将代码集成为埋点SDK(Software Development Kit),代码类型包括但不限于JS(JavaScript)。
前端埋点内容的映射关系A01:
后端接口埋点内容的映射关系A02:
全埋点是对以同样的方式,将全部事件、接口进行定义为A01-A02的映射关系,植入目标代码,并将代码集成为埋点SDK(Software Development Kit),代码类型包括但不限于JS(JavaScript)。
可视化埋点是通过可视化的方式,如:视图选择、列表选择,选择需要埋点内容后,生成A01-A02的埋点映射关系,植入目标代码,并将代码集成为埋点SDK(SoftwareDevelopment Kit),代码类型包括但不限于JS(JavaScript)。
步骤B:当用户产生行为时,前端代码自动和埋点采集系统接口进行参数校验,包括:域名或者ip地址校验、接口名校验、端口号校验;根据预先设定,校验成功后,建立socket连接。同理,当用户行为触发产生后端埋点数据时,后端和埋点采集系统建立连接。后端接口和埋点采集系统接口以同样的方式进行参数校验,包括:域名或者ip地址校验、接口名校验、端口号校验;根据预先设定,校验成功后,建立socket连接。由于用户行为在外网产生,而埋点数据的接收、解析、指标加工、持久化存储均在内网进行,因此为达到负载均衡,灵活配置流量的目的,系统需要对外网和内网进行映射,映射方式如图3、图4所示。
步骤C:当前端和埋点采集系统建立连接后,前端调用埋点采集系统的接口https://ip_inner:port/collect/info或者https://域名_inner:port/collect/info,将步骤A中定义的前端埋点数据,以POST的请求方式上送传输至埋点采集系统。
同理,当后端和埋点采集系统建立连接后,后端调用埋点采集系统的接口https://ip_inner:port/collect/info或者https://域名_inner:port/collect/info,将步骤A中定义的后端接口埋点数据,以POST的请求方式上送传输至埋点采集系统。
其中,以上的两种埋点内容上送,为了数据传输安全,避免在传输过程中被非法窃取,客户端(Client,此处客户端指Android、IOS、H5、小程序)到服务器端(Server,此处指埋点采集系统)的接口调用均采用HTTPS方法,数据传输均采用POST方法,非GET方法。
步骤D:埋点采集系统对接收到的埋点数据进行实时解析得到步骤A中定义的埋点数据各个基本字段,以及衍生字段;其中,埋点采集系统对接收到的结构化埋点数据,根据Key-value的形式进行解析,得到前端事件、后端接口,以及每个前端事件对应的其他字段内容,每个后端接口对应的其他字段内容。然后将解析到字段实时转发至Kafka消息队列,其中前端事件对应的字段,实时转发至名称为topic_evt的Topic中(Topic是代表着数据的类别,一个topic可以认为是一类消息。Producer在发送消息时必须指定发往哪个topic,此后,订阅了该topic的所有Consumer都能够接收到消息。);后端接口对应的字段,实时转发至名称为topic_interface的Topic中。
步骤E:根据步骤D中得到的各个基本字段和衍生字段,对产品运营、用户行为分析涉及到的业务指标进行匹配、统计、计算得到实时指标,并将上述实时指标分类别的转发至Kafka消息队列名称为topic_result的topic中。统计计算的方法包括但不限于Flink实时流计算方法(实时统计更新业务指标)、SlipStream的流处理方法(分钟级分批次统计业务指标)。具体如下:
E1.通过Flink实时流计算方法(实时统计更新业务指标)实时消费kafka消息队列topic_evt、topic_interface中的字段,通过Tumbling Windows方法(不重叠的,数据流中的每一条数据仅属于一个窗口。每一个都有固定的大小,同时窗口间彼此之间不会出现重叠的部分),采用Filter方法过滤数据、keyBy方法对数据分组、join方法对数据关联、connect方法合并多个数据流为一个数据流、aggregate方法对数据聚合处理,如计数、求和、平均、加权平均。
E2.通过SlipStream的流处理方法(批量统计业务指标)分钟级批量消费kafka消息队列topic_evt、topic_interface中的字段,再根据SQL对数据进行过滤、关联、分组、聚合,得到业务指标。
其中,业务指标的统计维度包括但不限于:渠道、产品、时间(今日实时累计)、事件名称。
业务指标包括但不限于:按照不同维度,统计用户数(新注册用户、老用户、游客:未登陆用户)、PV(页面访问次数)、UV(访问用户数)、平均停留时长(每个页面的停留时长取平均值)、跳出率(没有下一页的页面访问次数除以页面访问次数)、留存率、用户画像(性别、年龄、学历、位置)、信贷产品不同环节的通过数和通过率(注册、登录、实名、绑卡、授信、借款)、电商产品不用环节的通过数和通过率(启动、注册、登录、实名,搜索、添加购物车、提交订单、支付、收藏、分享、评价)。
E3.最终,上述E1和E2两种方法均可得到目标业务指标,后者的时效性低于前者。将通过E1方法得到的业务指标,实时发送至Kafka消息队列的topic_result中;将通过E2方法得到的业务指标持久化到实时数据仓库HBase表中。
步骤F:可视化系统通过实时消费步骤E所述Kafka消息队列topic_result中的业务指标,或查询实时数据仓库中的HBase业务指标表,将业务指标进行可视化展现,将步骤E中所述的业务指标、步骤D中得到的基本字段和衍生字段依次持久化存储至实时数据仓库、离线数据仓库中。
F1.通过可视化系统的应用程序(包括但不限于JAVA、PYTHON、SmartBI)实时消费Kafka消息队列topic_result中的业务指标,将业务指标进行可视化展现,或查询实时数据仓库中的HBase业务指标表,将实时数据仓库中的业务指标进行可视化展现,可视化系统的可视化方法包括但不限于:页面WEB、Tableau多维分析、报表、大屏、移动驾驶舱、接口查询;
F2.将步骤E中通过Slipstream方式消费Kafka消息队列中topic_result得到的业务指标、以及D中的topic_evt、topic_interface得到基本字段、衍生字段,以数据流的方式持久化存储于实时数据仓库中;通过数据仓库的ETL(抽取(extract)、转换(transform)、加载(load)),将实时数仓的数据持久化到离线数据仓库中;
持久化到实时数据仓库时,将基本字段、衍生字段、业务指标,均存储到HBase表中,为保证数据查询效率、以及分区大小均衡,需要结合HBase表的列存储特点,合理地设计主键rowkey,如下
用户事件(user):rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+手机号+事件id+13位随机数。
除用户事件(user)外的其他事件:rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+事件id+13位随机数。
接口数据:rowkey=时间(yyyyMMddHHmmss)+渠道编号+产品编号+接口id+13位随机数。
步骤G:在n分钟内,业务指标超过指标阈值上限M_max、或者低于阈值下限M_min,两者均由埋点采集系统发送告警短信,告知应用负责人,前者告警短信表明业务量超过正常水平,可能存在异常访问行为;后者告警短信表明业务量低于正常水平、或者整个埋点数据采集链路中的某个环节出现问题;两者均需应用负责人进一步核查,解决问题,其中,n为自然数,指标阈值上下限M_max、M_min可由业务人员根据经验指定。
- 一种基于Kafka的埋点数据实时采集计算和存储的方法
- 一种埋点数据的计算方法、装置、存储介质和电子设备