一种基于优化AnimeGAN的图像风格迁移
文献发布时间:2023-06-19 10:24:22
技术领域
本发明属于图像处理技术领域,具体涉及一种基于优化AnimeGAN的图像风格迁移。
背景技术
图像处理是一种具有巨大的社会和经济效益的实用技术,被广泛应用于各行各业以及人们的日常生活中。图像处理中常见的一个技术就是图像的风格迁移,图像风格迁移的目的是对图像的纹理、色彩、内容等进行定向的改变,使得图像从一种风格变化为另一种风格,例如,将照片进行风格迁移,得到宫崎骏动漫风格的图像,将光线较昏暗的条件下拍摄得到的风景照片进行风格迁移,得到光线较为明亮条件下的图像等。
现有的风格迁移技术通常存在着一些问题,比如生成的图像没有明显的目标风格纹理、生成的图像丢失了原有图像的边缘和内容、网络参数的存储容量要求太大等。生成对抗网络(Generative Adversarial Networks,GAN)被认为能够有效解决上述问题。
生成对抗网络是由Ian J.Goodfellow等人在2014年提出的,是一种非监督式的学习方法,通过两个神经网络相互博弈的方式进行学习。生成对抗网络由一个生成网络和一个判别网络组成的,其中生成网络从潜在空间中随机取样作为输入,输出的结果需要尽量模仿训练集中的样本,判别网络的输入为真实样本或者生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来,而生成网络则尽可能欺骗判别网络。两个网络通过互相对抗、不断调整参数,最终的目的是使判别网络无法判断生成网络的输出结果是否真实。
AnimeGAN(图像卡通风格迁移算法)是生成对抗网络的一个变体,AnimeGAN使用未配对的训练数据进行端到端训练,实现图片的风格迁移。
发明内容
为了解决风格迁移时生成的图像目标风格纹理不明显、内容迁移效果不佳、图像边缘不清晰等问题,本发明提出了一种基于优化AnimeGAN的图像风格迁移,将优化后的AnimeGAN(图像卡通风格迁移算法)应用于非成对图像之间的风格迁移。
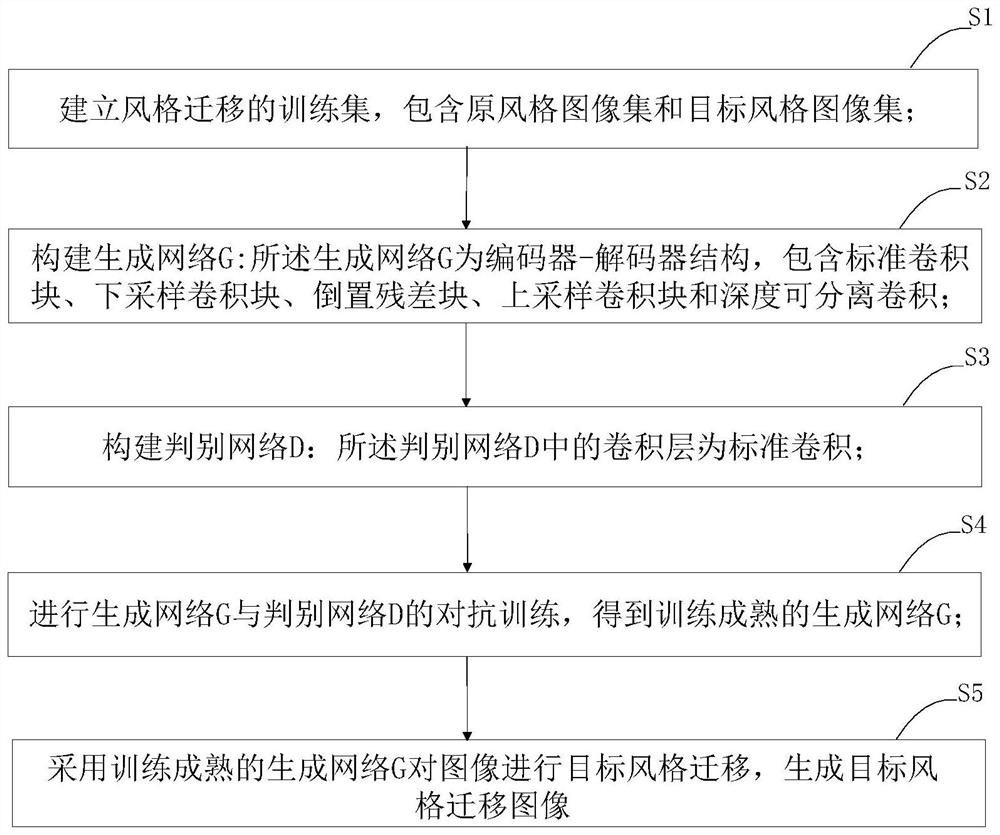
本发明提出的一种基于优化AnimeGAN的图像风格迁移,包含以下步骤:
S1、建立风格迁移的训练集,包含原风格图像集和目标风格图像集;
S2、构建生成网络G:所述生成网络G为编码器-解码器结构,包含标准卷积块、下采样卷积块、倒置残差块、上采样卷积块和深度可分离卷积;
S3、构建判别网络D:所述判别网络D中的卷积层为标准卷积;
S4、进行生成网络G与判别网络D的对抗训练,得到训练成熟的生成网络G;
S5、采用训练成熟的生成网络G对图像进行目标风格迁移,生成目标风格迁移图像。
优选地,原风格图像集包含若干第一类图像,第一类图像为原风格图像,用来进行目标风格迁移;
对第一类图像进行转化,生成第一类图像的YUV格式三通道图像。
优选地,目标风格图像集包含若干第二类图像和若干第三类图像,第二类图像为第一类图像对应的目标风格图像,第三类图像为第二类图像平滑处理后的图像;
对第三类图像进行转化,生成第三类图像的灰度图和第三类图像的YUV格式三通道图像。
优选地,所述生成网络G的编码器通过一层标准卷积块输入,将该标准卷积块与一层标准卷积块、一个下采样卷积块、一个标准卷积块、一个深度可分离卷积、一个下采样卷积块、一个标准卷积块以及8块倒置残差块依次连接,形成所述编码器;
所述生成网络G的解码器通过一个卷积层输出,依次连接一层标准卷积块、一个上采样卷积块、一个深度可分离卷积、一个标准卷积块、一个上采样卷积块、两个标准卷积块和该卷积层,形成所述解码器。
优选地,所述生成网络G通过所述标准卷积块提取图像的特征,通过所述下采样块避免池化带来的图像特征信息的丢失,通过所述倒置残差块降低训练时所需参数、提升训练速度,通过所述上采样块提高特征图的分辨率,通过所述深度可分离卷积减少计算量、加快图像的生成速度。
优选地,所述判别网络D包含七个卷积层:第一卷积层~第七卷积层;七个卷积层均为标准卷积层,第一卷积层至第七卷积层依次连接形成所述判别网络D。
优选地,所述判别网络D通过第一卷积层输入,并对第一卷积层、第二卷积层和第四卷积层分别进行LRelu激活函数操作,对第三卷积层、第五卷积层和第六卷积层分别进行实例正则化函数和LRelu激活函数操作,所述判别网络D通过第七卷积层输出。
优选地,所述生成网络G与判别网络D的对抗训练包含以下过程:
S41、所述生成网络D的预训练:
将第一类图像和第一类图像的YUV格式三通道图像,以及第三类图像和第三类图像的YUV格式三通道图像,输入所述生成网络D;
采用VGG19网络模型对所述生成网络D进行预训练,预训练过程采用L1稀疏正则化方法计算图像内容损失函数L
其中,公式(1)中G表示所述生成网络,D表示所述判别网络,p
公式(2)中
S42、训练所述判别网络D:
将与第一类图像p
其中,公式(3)中ω
S43、训练生成网络G:
将第一类图像的YUV格式三通道图像输入生成网络G,生成目标风格的图像并输出;
所述生成网络G将RGB格式的图像颜色转换为YUV格式来构建颜色重构损失L
其中,Y(G(p
S44、重复步骤S41~S43,对第i+1张第一类图像进行生成网络G与判别网络D的对抗训练;
以原风格图像集中每张第一类图像完成生成网络G与判别网络D的对抗训练,作为一个epoch。
优选地,epoch为超参数,epoch值为原风格图像集中第一类图像的个数。
与现有技术相比,本发明基于优化后的AnimeGAN进行图像风格迁移,著降低了图像训练时间;将优化后的AnimeGAN应用于非成对图像之间的风格迁移,使得生成的图像具有明显的目标风格纹理、内容迁移的效果更好,且图像边缘清晰。
附图说明
图1为本发明所述基于优化AnimeGAN的图像风格迁移流程图;
图2为本发明中优化后的AnimeGAN的生成网络结构示意图;
图3为本发明中优化后的AnimeGAN的判别网络结构示意图;
图4为风格迁移前后的图像对比图。
具体实施方式
以下结合附图,通过详细说明较佳的具体实施例,对本发明进行详细介绍。
图1为本发明所述基于优化AnimeGAN的图像风格迁移流程图。如图1所示,本发明提出的一种基于优化AnimeGAN的图像风格迁移,包含以下步骤:
S1、建立风格迁移的训练集,包含原风格图像集和目标风格图像集。
所述原风格图像集包含若干第一类图像,第一类图像为原风格图像,用来进行目标风格迁移。所述目标风格图像集包含若干第二类图像和若干第三类图像,第二类图像为第一类图像对应的目标风格图像,第三类图像为第二类图像平滑处理后的图像。第一类图像的数量与第二类图像或第三类图像的数量相等。本发明实施例中以现实生活风格图像为原风格图像,即第一类图像;以宫崎骏动漫风格图像为目标风格图像,即第二类图像;第三类图像即为宫崎骏动漫风格图像平滑处理后的图像。
对第一类图像进行转化,生成第一类图像的YUV格式三通道图像;对第三类图像进行转化,生成第三类图像的灰度图和第三类图像的YUV格式三通道图像。
S2、构建生成网络G:所述生成网络G为编码器-解码器结构,包含标准卷积块(Conv-Block)、下采样卷积块(Down-Conv)、倒置残差块(Inverted Residual Blocks,IRBs)、上采样卷积块(Up-Conv)和深度可分离卷积(DSC-Conv)。
图2为本发明中优化后的AnimeGAN的生成网络结构示意图。如图2所示,所述生成网络G结构具体结构如下:
所述生成网络G的编码器通过一层标准卷积块输入,将该标准卷积块还与一层标准卷积块、一个下采样卷积块(步长为2)、一个标准卷积块、一个深度可分离卷积、一个下采样卷积块(步长为2)、一个标准卷积块以及8块倒置残差块依次连接,形成所述编码器;所述生成网络G的解码器与上述编码器连接;所述生成网络G的解码器通过一个卷积层输出,通过依次连接一层标准卷积块、一个上采样卷积块、一个深度可分离卷积、一个标准卷积块(卷积核为3×3)、一个上采样卷积块、两个标准卷积块和该卷积层,形成所述解码器。
所述卷积层(卷积核为1×1))没有使用归一化层,激化函数采用的是tanh,公式为:
所述生成网络G中,所述标准卷积块用于提取图像的特征,所述下采样块用来避免池化带来的图像特征信息的丢失,所述倒置残差块用来降低训练时所需参数、提升训练速度,所述上采样块用来提高特征图的分辨率,所述深度可分离卷积用来减少计算量、加快图像的生成速度。
S3、构建判别网络D:所述判别网络D中的卷积层为标准卷积。
图3为本发明中优化后的AnimeGAN的判别网络结构示意图。如图3所示,所述判别网络D包含七个卷积层:第一卷积层~第七卷积层;七个卷积层均为标准卷积层(Conv);每个卷积层的权值采用谱归一化使网络训练更加稳定;第一卷积层至第七卷积层依次连接形成所述判别网络D,具体结构如下:
所述判别网络D通过第一卷积层输入,并对第一卷积层进行LRelu激活函数操作,对第二卷积层进行LRelu激活函数操作,对第三卷积层进行实例正则化函数(Instance_Norma)和LRelu激活函数操作,对第四卷积层进行LRelu激活函数操作,对第五卷积层进行实例正则化函数和LRelu激活函数操作,对第六卷积层进行实例正则化函数和LRelu激活函数操作,最后,所述判别网络D通过第七卷积层输出。LRelu激活函数公式为:
S4、进行生成网络G与判别网络D的对抗训练,得到训练成熟的生成网络G,具体过程如下:
S41、所述生成网络D的预训练:
将第一类图像和第一类图像的YUV格式三通道图像,以及第三类图像和第三类图像的YUV格式三通道图像,输入所述生成网络D。
采用VGG19网络模型对所述生成网络D进行预训练,预训练过程采用L1稀疏正则化方法计算图像内容损失函数L
其中,公式(1)中G表示所述生成网络,D表示所述判别网络,p
公式(2)中
S42、训练所述判别网络D:
将与第一类图像p
其中,公式(3)中ω
S43、训练生成网络G:
将第一类图像的YUV格式三通道图像输入生成网络G,生成目标风格的图像并输出;
所述生成网络G将RGB格式的图像颜色转换为YUV格式来构建颜色重构损失L
其中,Y(G(p
S44、重复步骤S41~S43,对第i+1张第一类图像进行生成网络G与判别网络D的对抗训练;
以原风格图像集中每张第一类图像完成生成网络G与判别网络D的对抗训练,作为一个epoch。epoch为超参数,epoch值为原风格图像集中第一类图像的个数。
S5、采用训练成熟的生成网络G对图像进行目标风格迁移,生成目标风格迁移图像。图4为风格迁移前后的图像对比图。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 一种基于优化AnimeGAN的图像风格迁移
- 一种基于风格与内容解耦的图像风格迁移方法