一种嵌入式芯片SQL语句解析方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及嵌入式芯片SQL语句解析方法,尤其涉及在嵌入式芯片内的SQL语句解析。
背景技术
嵌入式芯片是指具有嵌入式微处理器、存储器、通用设备接口和I/O接口,有一定控制功能的芯片,例如:智能卡用芯片。由于嵌入式芯片存储器的内存受限,在对嵌入式芯片内存储的数据库进行增删改查等操作时,通常使用卡外PC端中间件的方式(下文简称PCSQL)处理SQL语句,即先将结构化查询语言(以下简称SQL)处理转化成一定格式的“中间数据”,然后传入卡内,随后由芯片上的数据库进行后续的分析处理。
使用PC SQL的主要优点是:1.压缩数据量,提高传输效率,因为PC端的预处理可以将数据转化成紧凑的高效的存储格式。2.根据处理时序改变数据次序,优化芯片内缓存能力不足的处理效果,因为标准SQL的语法顺序不太适合直接的顺次处理,而非顺次处理则要求较大的缓存区对数据暂存。3. 芯片内不处理SQL语句将会使得芯片内的数据库(DB)模块复杂度降低,减小项目风险。
使用PC SQL也有缺点:1.将较多的数据预处理功能交给卡外中间件,将限制芯片内DB的功能,使得DB的易用性和通用性、可移植性下降。2.数据格式兼容性差,例如DB2.0必须兼容全部DB1.0的“中间数据格式”,而 DB2.0又需要扩展该接口以完善功能,增加诸如复杂表达式查询、连接查询等功能将使接口的定义复杂化,既做到兼容又做到复杂扩展有时候是矛盾的。
由于PC SQL操作需要占用非常大的内存,而芯片内存有限,无法在芯片内进行PCSQL相同的操作。
发明内容
本发明的目的在于解决上述问题,提供一种占用内存小,能在嵌入式芯片内实现SQL语句解析的方法。
本发明提供了一种嵌入式芯片SQL语句解析方法,包括设置在嵌入式芯片中的词法解析模块21和语法解析模块22,所述词法解析模块21用于识别SQL语句字符串中的单词,并将其转换成对应的状态符,所述语法解析模块22用于判断词法解析后的状态组合是否符合语法规范,其特征在于:针对SQL语句中的单词,建立将输入字符转换成状态符的转移函数,接受状态符集合,各个所述接受状态符分别对应于不同的单词。
所述词法解析模块21包括以下步骤:步骤S201,按照SQL语句的顺序逐个输入字符;步骤S202,判别是否是分隔符,是分隔符时,进入步骤 S203,不是分隔符时,进入步骤S204;步骤S203,按顺序将分隔符保存在静态内存中;步骤S204,每输入一个字符,按照所述转移函数,生成对应的状态符;步骤S205,生成的状态符作为新状态符,替换保存在动态内存中的旧状态符;步骤S206,判别所述新状态符是否与接受状态符集合中的任何一个所述接受状态符一致,“不一致”时,返回步骤S201,输入下一个字符,“一致”时,对所述动态内存进行清零后进入步骤S207;步骤 S207,将所述新状态符作为已识别单词的状态符保存在静态内存中;步骤 S208,判别新状态符是否为结束状态符,是结束状态符时,结束流程,不是结束状态符,返回步骤S201。
所述语法解析模块22包括以下步骤:步骤S301,按顺序读入所述状态符;步骤S302,判别状态符是否为结束状态符,是结束状态符时,进入步骤S303,不是结束状态符时,进入步骤S304;步骤S303,以状态符和分隔符组成的短语用于生成指令;步骤S304,基于所述状态符,判断前一单词是否为该单词所定义的可接收单词,“Yes”时,进入步骤S301,“No”时,进入步骤S305;步骤S305,判断语法错误,结束流程。
根据本发明的一种实施方式,所述步骤S301中,监测所述静态内存,有状态符保存时,读入所述状态符。
根据本发明的一种实施方式,所述步骤S303与S304之间还包括预处理步骤,判别所述状态符对应的是否为条件单词,如果是条件单词,对之前的状态符构成的短语进行预处理。
本发明采用CARD SQL模块,在芯片内对SQL语句进行解析,用有限自动机识别SQL语句中的各个单词,将各个单词由16位整数保存的形式转为1位状态符保存的形式,大大节约了内存。在词法解析过程中,每生成一个新状态符,之前的状态符被释放,之后的状态符不断覆盖之前的状态符,单词的字符数再多,内存(动态内存)中始终只占用一个状态符的字节,节约了内存。
附图说明
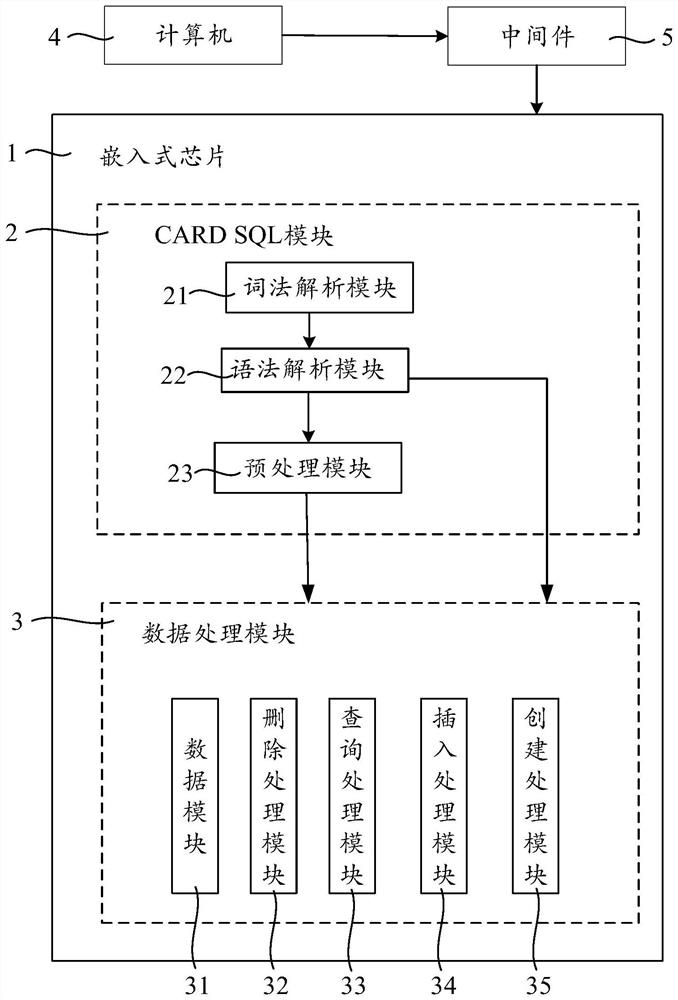
图1对嵌入式芯片中数据库进行操作的结构示意图;
图2是对嵌入式芯片中数据库进行操作的流程图;
图3是SQL语句中单词的识别和状态转换说明图;
图4是词法解析模块解析SQL语句的流程图;
图5是语法解析模块解析SQL语句的流程图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,参考标号是指本发明中的组件、技术,以便本发明的优点和特征在适合的环境下实现能更易于被理解。下面的描述是对本发明权利要求的具体化,并且与权利要求相关的其它没有明确说明的具体实现也属于权利要求的范围。
本实施方式中嵌入式芯片为安装在智能卡中,可与读卡器进行信息交互。嵌入式芯片包含中央处理器(CPU)、可编程只读存储器(EEPROM)、随机存储器(RAM)和固化在只读存储器(ROM)中的卡内操作系统COS(Chip Operating System)。
以下以安装有DB2.0的嵌入式芯片为例对本发明的实施方式进行说明。 DB2.0的特点是可以进行分帧处理,即可以对单个字符进行处理。
图1是对嵌入式芯片中数据库进行操作的结构示意图,如图1所示,嵌入式芯片1包含CARD SQL模块2和数据处理模块3,数据处理模块3采用DB2.0进行数据管理。计算机1通过中间件5与嵌入式芯片1连接。
在对嵌入式芯片1中的数据库进行操作时,首先由计算机4编译生成操作芯片内数据库用的SQL语句,例如,select f1,f2 from ta,SQL语句通过中间件5传输到嵌入式芯片1。芯片1中的CARD SQL模块2对SQL语句进行词法和语法解析生成操作指令,数据处理模块3根据操作指令对数据模块(数据库)进行相应的操作。
CARD SQL模块2中的词法解析模块21从左到右逐个地读入接收的 SQL语句字符串,从字符串中识别出一个个具有独立意义的“单词”,并将其转化为一个状态符(token),用于下一步的语法分析,识别出来的单词逐个传递到语法解析模块22。
语法解析模块22根据各个单词的属性判断语句的正确性,即,进行语法规范检查。例如select语句,正确形式为select f1,f2 from ta,若为select from f1,f2 ta,则语法解析模块22判断SQL语句为错误形式,具体判断方法以下详细说明。
预处理模块23用于某些SQL语句在正式执行之前的预处理,以便准备好数据(例如SELECT语句的WHERE条件部分)。
以下通过流程图对CARD SQL模块2解析SQL语句的流程进行说明。图2是对嵌入式芯片中数据库进行操作的流程图。
步骤S501,计算机4根据操作需要编辑SQL语句,例如编辑SELECTPersons.LastName,Persons.FirstName,Order.OrderNo FROM Persons,Orders WHEREPersons.Id_P=Orders.Id_P(含义是从Persons,Orders中找到Persons.LastName,Persons.FirstName,Order.OrderNo),生成的 SQL语句通过中间件5发送到嵌入式芯片1。
步骤S502,词法解析模块21对SQL语句进行词法解析,即,识别 SQL语句中的单词,并将其转换成对应的状态符,具体参照图4和以下详细说明。
步骤S503,语法解析模块22对单词(状态符)组成的短语进行语法进行语法解析,生成对应的指令,具体参照图5和以下详细说明。
步骤S504,数据处理模块3包括数据模块31、删除处理模块32、查询处理模块33、插入处理模块34或创建处理模块35,根据不同的指令,删除处理模块32、查询处理模块33、插入处理模块34或创建处理模块35,分别对数据模块31内的数据进行相应的删除、查询、插入或创建操作。例如,查询处理模块33,查询处理模块33执行where部分Persons.Id_ P=Orders.Id_P的细化查询操作,即在满足Persons.Id_P=Orders.Id_P条件下查询Persons和Orders内Persons.LastName、Persons.FirstName和Order. OrderNo这三部分内容,查询后将查询到的Persons.LastName、Persons. FirstName和Order.OrderNo这三部分结果通过中间件5返回计算机4。关于语法分析后的处理为现有技术,在此省略其详细说明。
本发明中词法解析模块21采用有限自动机原理对SQL语句中的单词进行识别和状态转换。首先对有限自动机原理进行说明。
有限自动机M是一个5元组(Q,q0,A,∑,δ),Q是状态的有限集合,q
有限自动机开始于状态q
a)(进行了一次转移)。每当状态q属于A时,就说自动机M接受了迄今为止所读入的字符串。没有被接受的输入称为被拒绝的输入。
通过有限自动机将SQL语句中的每个单词识别出来,并转换成状态符。通常每个单词由多个字符组成(例如select有6个字符),转换成状态符后(例如7一个字符),可以降低对内存的占用。
以下以SQL语句:select f1,f2 from ta,为例进行说明。
图3是SQL语句中单词的识别和状态转换说明图。如图3所示,
SQL语句中包含关键字select、from;表名ta;字段名f1,f2。
状态集合Q={0,1,2,3,4,5,6,7,8,9,10,11,12,13, 14,15,16,17};
初始状态q0=0;
接受状态集合A={0,7,10,11,12,14}。
初始状态为0,读取SQL语句的第一个字符s,经过有限自动机处理(函数转换),状态变为δ(1,s),读取SQL语句的第二个字符e,状态变为δ(3,e),读取SQL语句的第三个字符l,状态变为δ(4,l),读取SQL 语句的第四个字符e,状态变为δ(5,e),读取SQL语句的第五个字符c,状态变为δ(6,c),读取SQL语句的第六个字符t,状态变为δ(7,t),此时状态q为7,属于集合A,单词select被识别出来,并转换为7的状态符。同样,后续的各个字符通过有限自动机处理,单词被依次识别出来,并转换为相应的状态符。
其中,select的状态符为7,from的状态符为10,f1的状态符为11, f2的状态符为12,ta的状态符为14,将单词转换成状态符,减少了字节,降低了对芯片内存(静态内存)的占用。
即,SQL语句:select f1,f2 from ta,每个单词都有一个16位的整数对应,解析过程中,现有技术需要将五个单词转为16位的整数进行处理共占用内存容量为八十字节,本发明在解析过程,select的状态符为7, from的状态符为10,f1的状态符为11,f2的状态符为12,ta的状态符为14,各个状态符只占用内存的一字节,五个单词转换成状态符后只占用五个字符的内存容量。将各个单词由16位整数保存的形式转为1位状态符保存的形式,大大节约了内存。
并且在词法解析过程中,本发明采用读取SQL语句中的一个字符,生成对应的一个状态符,不断的读取字符,生成对应的状态符,整个过程中,之后的状态符不断覆盖之前的状态符,内存(动态内存)一直都是只占用一个状态符的字节,节约了内存。
SQL语句的单词中,包含关键字和非关键字(标识),词法解析模块 21识别出的单词为关键字时只保存其状态符,识别出非关键字时,将状态符和该单词组合保存。例如,关键字select,只保存7的状态符,非关键字 f1为“username”时,保存“11+username”。
在词法解析模块21中针对SQL语句中的单词,建立将输入字符转换成状态符的转移函数,接受状态符集合,各个接受状态符分别对应于不同的单词,
有限输入字母表Σ={a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,A,B,C,D,E,F,G,H,I,J, K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,0,1,2, 3,4,5,6,7,8,9,_}。只要输入的SQL语句中的单词由上述字母组成,各单词均可转换为对应的状态符。
以下以流程图对采用有限自动机原理的词法解析模块解析SQL语句进行说明。图4是词法解析模块解析SQL语句的流程图。
如图4所示,
步骤S201,按照SQL语句的顺序由左向右逐个输入字符。
步骤S202,词法解析模块21判别是否是分隔符,是分隔符时,进入步骤S203,不是分隔符时,进入步骤S204。
步骤S203,词法解析模块21按顺序将分隔符保存在静态内存中。
步骤S204,每输入一个字符,按照转移函数,生成对应的状态符。
步骤S205,词法解析模块21将生成的状态符作为新状态符,替换保存在动态内存中的旧状态符。
步骤S206,词法解析模块21判别所述新状态符是否与接受状态符集合中的任何一个接受状态符一致,“不一致”时,返回步骤S201,输入下一个字符,“一致”时,对动态内存进行清零后进入步骤S207。
步骤S207,词法解析模块21将新状态符作为已识别单词的状态符保存在静态内存中。
步骤S208,判别新状态符是否为结束状态符,是结束状态符,整个 SQL语句的单词解析完毕,结束流程,不是结束状态符,返回步骤S201,重复以上步骤,直至所有单词解析完毕。
通过词法解析,SQL语句中的各个单词被识别出来,并转换成对应的状态符。
语法分析模块22通过状态符,对SQL语句进行语法分析。
语法解析模块22采用自顶而下顺次分析的方法,每分析到一个单词(current TkType)的时候,判断前一个单词(保存在全局变量last token Type 中)是否为该单词所能够接收的单词,若为可接收的单词,则继续分析下一个单词,直至单词为字符结束符。如果前一个单词不是所能够接收的单词,则语法错误,报错退出。
即,建立各个状态符和该状态符可接受的前一个状态符的对照表,通过查找对照表,判断之前的状态符是否正确。
例如SQL语句:select f1,f2 from ta;
单词“select”的状态符为7,之前可接收的状态符为0,含义是“7”之前没有任何单词;“f1”的状态符为11,“f1”之前可接收的状态符为 7,含义是“f1”之前可接收的状态符为7;f2之前可接收的状态为逗号符号或空格符号;“from”的状态符为10,之前可接收的状态符为非关键词状态符;ta之前可接收状态符为10。
即,本发明中,由于采用分段处理方法,对单词进行逐字分析,下一个单词不会会和正在分析的单词同时存在,因此在语法解析的过程中采用判断之前的单词是否为可接受的单词。
由于语法解析之前,进行词法解析,各个单词转换成状态符,通过判断前一个单词是否为可接受的单词,判断语法的合法性,与先进行语法解析再进行词法解析方法相比,本发明的方法不必把各个单词的状态符全部存储下来,整个语法解析过程只占用一个状态符的字节(非关键字占用状态符与单词的字节)例如内存的一字节,减少了对内存的使用。
另外,每句SQL语句最后的结束语也转换成结束状态符,该结束状态符作为SQL语句结束的判断依据。
以下以流程图对语法解析模块解析SQL语句进行说明。图5是语法解析模块解析SQL语句流程图。
如图5所示,
步骤S301,语法解析模块22按顺序逐个读入状态符。
即,语法解析模块22监测静态内存,有状态符保存时,读入该状态符,使语法解析与词法解析同步进行,降低对内存的占用。
步骤S302,语法解析模块22判别状态符是否为结束状态符,是结束状态符时,整个SQL语句的语法分析结束,进入步骤S303,不是结束状态符时,进入步骤S304。
步骤S303,语法解析模块22将静态内存保存的单词按顺序发送到数据处理模块结束流程。
步骤S304,语法解析模块22基于状态符,判断对应单词是否为前一单词的可接收单词,“可接受单词”时,继续对下一个单词进行判断,进入步骤S301,“不可接收单词”时,进入步骤S305。
步骤S305,语法解析模块22判断语法错误,结束流程。
本发明采用CARD SQL模块,在芯片内对SQL语句进行解析,用有限自动机识别SQL语句中的各个单词,将各个单词由16位整数保存的形式转为1位状态符保存的形式,大大节约了内存。在词法解析过程中,每生成一个新状态符,之前的状态符被释放,之后的状态符不断覆盖之前的状态符,单词的字符数再多,内存(动态内存)中始终只占用一个状态符的字节,节约了内存。
与使用中间件对SQL语句进行解析相比,由于词法和语法解析在芯片内部进行,提高了嵌入式芯片内数据库的兼容性,对中间件的依赖大为减轻。例如在卡外的中间件中加入BLOB命令专用接口和UPDATE命令专用接口,调用嵌入式芯片DB2.0接口完成对于BLOB和UPDATE的操作,使得系统具有拓展性。
本发明由于采用CARD SQL模块2对SQL语句进行解析取代了中间件 5对SQL语句进行解析,中间件5只对SQL语句进行传输,使得操作嵌入式芯片1的数据库管理系统版本无需与中间件5数据库管理系统版本匹配,提高了嵌入式芯片1内数据库的兼容性,对中间件5的依赖大为减轻。
变形例
变形例中,对SQL语句包含有条件语句(条件符)时进行预处理以提高处理效率。
在步骤S304返回到步骤S301步骤时,还包括以下步骤:
步骤S3041,语法解析模块22判断状态符是否为条件符,判断为“N”,返回步骤S301,判断为“Y”,进入步骤S3042。
步骤S3042,语法解析模块22将条件单词之前的各个状态符组成的短语传入预处理模块23,预处理模块23调用底层函数解析表,对条件语句之前的内容(表名是否正确、字段名是否存在于表中)进行判断,例如, SELECT Persons.LastName,Persons.FirstName,Order.OrderNo FROM Persons,Orders WHERE Persons.Id_P=Orders.Id_P语句中,判断Persons, Orders是否存在,Persons,Orders中是否有Persons.LastName,Persons.FirstName,Order.OrderNo FROM Persons字段,判断为“N”时,没有执行的对象,进入步骤S3043,判断为“Y”时,有执行的对象,进入步骤 S3044。
步骤S3043,结束流程。
步骤S3044,预处理模块23调用底层函数解析表,查询条件语句之前的语句内容,例如,对之前的条件语句进行对Persons.LastName,Persons. FirstName,Order.OrderNoFROM Persons,Orders的查找。
变形例中,由于在整个SQL语句被全部解析前进行预处理,避免了在缓存区中暂存和传递所有状态符,节省了对内存的占用。
以下对中间件的接口扩展进行说明。
传输效率是接口设计必须考虑的重要因素,DB1.0在7816-3接口协议下的传输速率较低,例如BLOB数据平均30KB/s的传输速率还是偏低的。
对DB2.0的数据库使用CARD SQL模块2操作时,传输速率会进一步下降。原因有以下两点:
第一点,SQL语句有较多的冗余信息,结构不紧凑。自然语言风格的 SQL在命令标志、数据表示上跟“DB1.0传输接口”相比都更占用空间,此外还有很多占位标志、空格、引号等冗余符号,这些都会导致浪费空间多、传输效率降低。
第二点,二进制数据的间接表示问题。由于SQL语句只能接收字符型数据,二进制数据在SQL语句中必须间接的表示。例如表示4个字节的各位全1的数据,在SQL语句中需要如下的转意表达:
x’FFFFFFFF,其中的x’是十六进制标识。后面的8个“F”是用ASCII 码表示的十六进制数据,它们占了8个字节的空间。可见为了表示4个字节的二进制数据,使用了超过8个字节的空间。传输效率降低一半以上。而 BLOB数据一般都是二进制数据,都将使用这种间接表示的方法,并且BLOB数据的长度都很大,数以MB计,对整体的传输效率影响十分严重。
第一点“SQL语句有较多的冗余信息,结构不紧凑”,是使用SQL的不可避免的问题。对于第二点“二进制数据的间接表示问题”,本发明使用以下方法解决:
由于BLOB数据量大,通常使用二进制数据,故本发明只对BLOB数据传输进行优化:在卡外的中间件5中加入“DB1.0传输接口”式的BLOB 命令专用接口(可以称为“DB2.0-BLOB扩展接口”),使用非SQL语句方式传输二进制数据,即采用二进制数据直接传送,解决传输效率降低的问题。此时,卡内将有两种BLOB处理方式:“标准SQL(x’)转意语句”方式和“DB2.0-BLOB扩展接口”方式。用户可以视情况选择两者之一完成操作。
非BLOB数据中的二进制数据(例如BINARY类型,长度不超过255 字节)的表示只能用“标准SQL(x’)转意语句”方式实现,不在本发明考虑之内。
加入CARD SQL模块2后的DB2.0的操作流程将变得复杂,主要原因是DB1.0传输接口考虑到了卡内处理的时序,先处理的数据先传入,后处理的数据后传入,这样的次序可能跟标准SQL语意的定义有冲突,但DB1.0 可以在卡外处理的充裕内存条件下实现次序反转。当DB2.0的CARD SQL 直接处理标准SQL语句时,必须面对大量数据暂存问题。例如标准的UPDATE语句的定义是:
UPDATE<基本表名>
SET列名=值表达式[,列名=值表达式,…]
[WHERE(<行条件表达式>[<逻辑运算关系><行条件表达式>…])]
其中的SET子句是修改后的数据内容,WHERE子句是修改条件。当 SET子句传入卡内时,WHERE字句还在卡外,数据库不知道修改条件就无法确定修改的位置,所有的SET子句数据必须暂存在缓存区中,无法写入目标记录中,直到WHERE子句传输并处理完毕后,才会对SET子句进行处理。
SET子句的数据量可能是很大的,尤其是其中包括BLOB字段(最大允许长度4GB)的修改时,该子句需要的缓存区可能及其巨大。
对此问题,本发明使用以下两种方法解决:
第一方法,SET子句的长度在DB2.0是有限制的,要求用户不得输入超过约定长度的SET子句。否则报错,拒绝执行。例如可以设置为2KB最大有效数据量。需要说明的是用户输入的标准SQL SET子句数据是ASCII码表示的原始数据,暂存到SET子句缓存区的是经过预处理转化的“有效数据”,它比原始数据更紧凑,当有效数据达到2kB时,原始数据可能超过 2kB。
第二方法,在卡外的中间件5中加入类似“DB1.0传输接口”式的 UPDATE命令专用接口(可以称为“DB2.0-UPDATE扩展接口”),专门处理SET子句大数据量情形的操作问题,此时SET子句长度没有限制。那么卡内将有两种UPDATE处理方式:“标准SQL UPDATE语句”方式和“DB2.0-UPDATE扩展接口”方式。当没有卡外中间件5辅助处理的情形(例如卡内JAVA直接调用DB2.0)将只能使用受限的“标准SQL UPDATE语句方式”,否则用户可以视情况选择两者之一完成操作。
在嵌入式芯片内安装DB2.0数据库(数据处理模块)来对存储器(ROM)内的数据进行管理。DB2.0是一套关系型数据库管理系统,与 DB1.0相比,采用分帧处理数据的方式代替整体处理数据的方式,本发明利用分帧处理数据的方式进行,降低对大数据缓存区(动态内存)的依赖,使得嵌入式数据库在内存受限的嵌入式芯片(例如内存较小的智能卡用芯片)中进行SQL解析成为可能。
应该注意的是,上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。
- 一种嵌入式芯片SQL语句解析方法
- 一种SQL语句动态解析方法