一种基于规则的新能源数据分发方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明主要涉及新能源数据分发方法的技术领域,具体为一种基于规则的新能源数据分发方法。
背景技术
新能源作为基础能源转型发展的重要力量,未来又持续快速发展,并逐步成为主力电源。新能源发电与以往的煤炭发电不同,它包括风、光、水电等一系列可持续发电能源,新能源数据也包括很多来源,比如新能源发电运行数据、风机/逆变器数据、风速、辐照度等相关数据,所以这就造成了新能源数据呈现出典型的“4V”特征,即数据量巨大(volume)、数据种类多(variety)、价值密度低(value) 和处理速度快(velocity),并且伴随现代电力企业技术和装备的提升,包含大量语音、视频、图像文本等非结构化或半结构化类型的数据,如电网设备视频监控数据、移动设备GIS数据、智能电表数据等开始大规模持续涌入,单以风电数据为例,既有风机监控数据这样的时序数据,也有传统的关系型数据,更有像视频监控、记录文档、风机节点等非结构化数据,日益庞大并复杂化的数据集合使得单一模型的数据库已经不足以满足对这类新能源复杂类型数据的统一处理需求,而是需要联合多种不同类型的数据库来协同存储并管理这些多模型新能源数据。从而通过多数据库引擎的统一管理技术,来实现对数据管理效率的改善。而如果没有一个好的数据分发技术,那么就会导致新能源数据冗余存储浪费资源或者致使查询效率低下影响电网运行,所以如何将这些复杂多模型新能源数据准确的分发到多数据库引擎中,让数据的存储更加合理、查询更有效率,便成为现今亟待解决的问题。
发明内容
本发明主要提供了一种基于规则的新能源数据分发方法,用以解决上述背景技术中提出的技术问题。
本发明解决上述技术问题采用的技术方案为:
一种基于规则的新能源数据分发方法,包括新能源数据分发方法的提出及其优化方法,所述方法包括如下步骤:
步骤一:数据分发初始化规则构建,规则的初始化根据常识式和经验式两种形式来制定,常识性定义规则是指根据新能源数据库元数据以及分析各种处理引擎的优势,来初步定义数据分发规则;经验式定义规则是指根据新能源用户的查询经验、历史查询记录分析以及各类新能源数据库查询语句的特点,来初步定义数据分发规则;
步骤二:设计数据分发算法,根据分析对新能源数据库查询的规律性,推断出数据分发存储位置的规律性,进而判断出不同新能源数据的合适位置。并且记录每次查询的规律特点,进行保存。根据保存的记录,找出每种新能源数据类型以及存在关联特性的数据存储的特点,完成数据分发;
步骤三:设计查询验证算法,验证数据分发规则和数据分发算法的合理性与有效性;
步骤四:对分发规则的优化和算法的调优,循环实验或记录实际查询,对每种类别的查询结果综合分析,计算出此次数据分发准确率,并和之前已经入库的该类型的历史查询记录和查询结果分析表比对,若结果在误差允许的范围内,则证明此次执行的数据分发任务是合格的。
进一步的,一种基于规则的新能源数据分发方法,所述步骤一中常识性定义规则包括如下规则:
1)数据类型判断规则:以Y库为中心,依次查询每个字段的扩展状况,若子字段为0,则偏向X结构化存储;含有1-3个子字段,偏向Json类型Y存储;若有3个以上子字段扩展则选择Z中存储;
2)数据量判断规则:以X库为中心,计算总数据量DC、关系表量TC、字段存储大小FS、图关系GR、字段F、期望量C=10w。当DC 低于C时,若关系表<=3表则存储在X中;若判断关系表中某字段值大文本情况为True时,则将该字段F迁移至Y中;若关系表>3表,且某些字段存储在较强的关联关系,则选择存储在Z中;
3)场景判断规则:以全部库为中心,根据配电网场景来源进行判断,若属于结构化场景S则存储在X中;若属于文档型、易扩展类型场景W则存储在Y中;若属于图结构类型展示场景G则存储在Z中;
4)数据库特性判断规则:以X库为中心,判断数据事务性强弱T,若为True时,则选择在X中存储;若为False且偏分布式存储则选择在Y中存储;若数据结构呈现网状结构类N则选择Z中存储;
进一步的,一种基于规则的新能源数据分发方法,所述步骤1中经验性定义规则包括如下规则:
1)属性判段规则:以X库为中心,根据历史查询记录表和结果分析表综合性判断:若存在很少参与查询的字段LF,则该字段仍保留在X中存储;若平均每次查询的字段AF大于某期望次数W(可初始自定义一个值)时,则该字段F迁移至Z中存储;Y暂不存储,记为0;
2)索引判断规则:以X库为中心,若是单表索引类型SI且关联性强度不大则选择X中存储;若是频繁的使用组合索引GI且可能大于一表则选择Y中存储;若是多表字段之间存在很强的关联关系且通过多表索引MI建立关联则选择Z中存储;
3)连接判断规则:以X库为中心,根据历史查询记录表综合性判断,若平均每次查询总连接数AC不低于某期望次数L(初始自定义值)时则选择Z,否则推荐存储于X中;若多表之间频繁的参与嵌套连接查询QT为True时,则选择Y;若是复杂连接查询CQ,则根据参与字段PF和无关字段NF分别对应存储于X或Z数据库中;
4)综合型判断规则:以全部库为中心,根据历史查询记录表解析查询中参与聚集、分组等不同查询类型占该查询模板库中总查询的比例R,再根据各引擎执行该查询所花费时间的比较,综合判断该类查询的数据适合存到X、Y、Z哪个数据库中。此外,还可以通过解析查询结果Rq是属于面向报表rForms、面向对象Obj、面向网络Net 的哪一种结构形式,综合判断该数据应存储于X、Y、Z哪个数据库中。
与现有技术相比,本发明的有益效果为:
(1)本发明设计了一种基于规则的新能源数据分发方法,该方法基于规则将接收的复杂类型的新能源数据自适应地分发协同存储在新能源多模型数据平台中的关系和非关系型数据库,让能够更高效维护和访问这些新能源数据的数据库来加以存储和管理,从而改善数据管理的效率。为复杂类型数据管理提供了灵活、高效的解决方案,对于提升我院在大数据管理领域的影响力具有积极作用。
(2)本方法具有通用性和普适性,用户可以根据实际情况自定义规则,让规则库更加完善,使得数据分发更加准确。
以下将结合附图与具体的实施例对本发明进行详细的解释说明。
附图说明
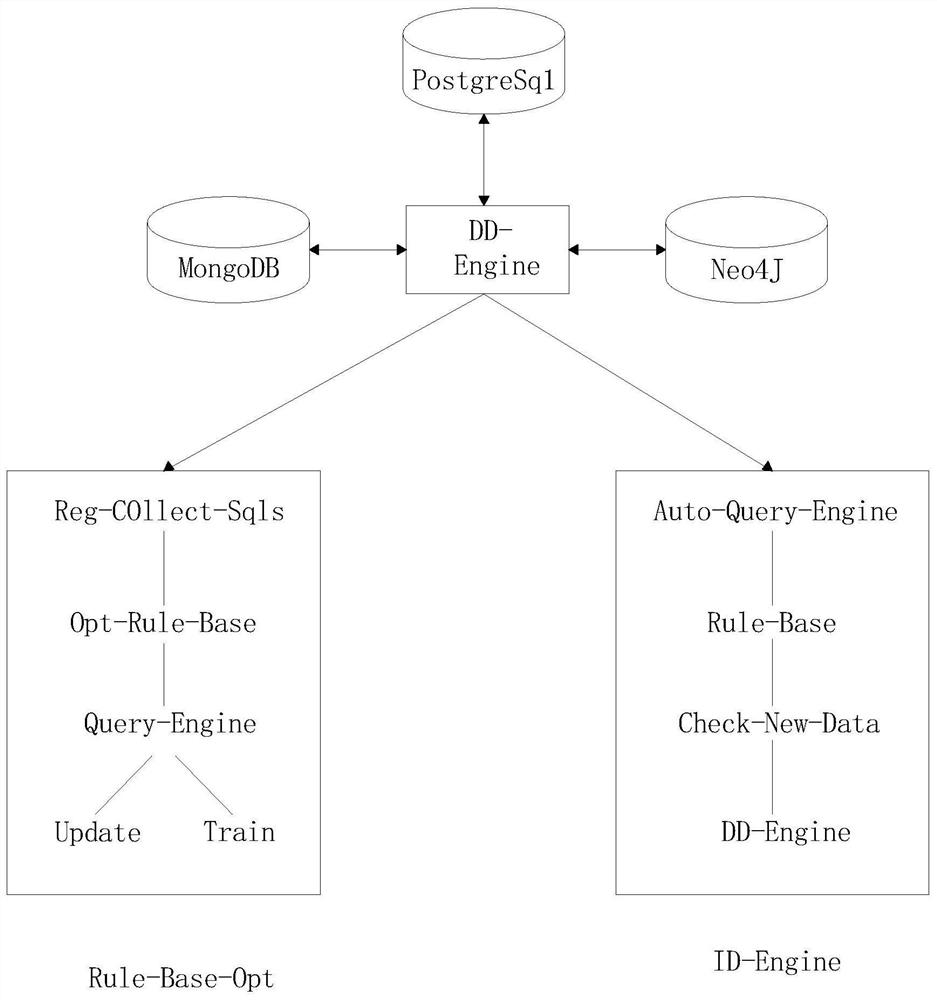
图1为本发明的新能源数据分发方法框架结构示意图;
图2为本发明的数据分发算法流程结构示意图;
图3为本发明的查询验证算法流程结构示意图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更加全面的描述,附图中给出了本发明的若干实施例,但是本发明可以通过不同的形式来实现,并不限于文本所描述的实施例,相反的,提供这些实施例是为了使对本发明公开的内容更加透彻全面。
需要说明的是,当元件被称为“固设于”另一个元件,它可以直接在另一个元件上也可以存在居中的元件,当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件,本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常连接的含义相同,本文中在本发明的说明书中所使用的术语知识为了描述具体的实施例的目的,不是旨在于限制本发明,本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
请着重参照附图1-3,一种基于规则的新能源数据分发方法,包括新能源数据分发方法的提出及其优化方法,所述方法包括如下步骤:
步骤一:数据分发初始化规则构建,规则的初始化根据常识式和经验式两种形式来制定,常识性定义规则是指根据新能源数据库元数据以及分析各种处理引擎的优势,来初步定义数据分发规则;经验式定义规则是指根据新能源用户的查询经验、历史查询记录分析以及各类新能源数据库查询语句的特点,来初步定义数据分发规则;
步骤二:设计数据分发算法,根据分析对新能源数据库查询的规律性,推断出数据分发存储位置的规律性,进而判断出不同新能源数据的合适位置。并且记录每次查询的规律特点,进行保存。根据保存的记录,找出每种新能源数据类型以及存在关联特性的数据存储的特点,完成数据分发;
步骤三:设计查询验证算法,验证数据分发规则和数据分发算法的合理性与有效性;
步骤四:对分发规则的优化和算法的调优,循环实验或记录实际查询,对每种类别的查询结果综合分析,计算出此次数据分发准确率,并和之前已经入库的该类型的历史查询记录和查询结果分析表比对,若结果在误差允许的范围内,则证明此次执行的数据分发任务是合格的。
请着重参照附图1-3,一种基于规则的新能源数据分发方法,所述步骤一中常识性定义规则包括如下规则:
1)数据类型判断规则:以Y库为中心,依次查询每个字段的扩展状况,若子字段为0,则偏向X结构化存储;含有1-3个子字段,偏向Json类型Y存储;若有3个以上子字段扩展则选择Z中存储;
2)数据量判断规则:以X库为中心,计算总数据量DC、关系表量TC、字段存储大小FS、图关系GR、字段F、期望量C=10w,当DC 低于C时,若关系表<=3表则存储在X中;若判断关系表中某字段值大文本情况为True时,则将该字段F迁移至Y中;若关系表>3表,且某些字段存储在较强的关联关系,则选择存储在Z中;
3)场景判断规则:以全部库为中心,根据配电网场景来源进行判断,若属于结构化场景S则存储在X中;若属于文档型、易扩展类型场景W则存储在Y中;若属于图结构类型展示场景G则存储在Z中;
4)数据库特性判断规则:以X库为中心,判断数据事务性强弱 T,若为True时,则选择在X中存储;若为False且偏分布式存储则选择在Y中存储;若数据结构呈现网状结构类N则选择Z中存储;所述步骤1中经验性定义规则包括如下规则:
1)属性判段规则:以X库为中心,根据历史查询记录表和结果分析表综合性判断:若存在很少参与查询的字段LF,则该字段仍保留在X中存储;若平均每次查询的字段AF大于某期望次数W(可初始自定义一个值)时,则该字段F迁移至Z中存储;Y暂不存储,记为0;
2)索引判断规则:以X库为中心,若是单表索引类型SI且关联性强度不大则选择X中存储;若是频繁的使用组合索引GI且可能大于一表则选择Y中存储;若是多表字段之间存在很强的关联关系且通过多表索引MI建立关联则选择Z中存储;
3)连接判断规则:以X库为中心,根据历史查询记录表综合性判断,若平均每次查询总连接数AC不低于某期望次数L(初始自定义值)时则选择Z,否则推荐存储于X中;若多表之间频繁的参与嵌套连接查询QT为True时,则选择Y;若是复杂连接查询CQ,则根据参与字段PF和无关字段NF分别对应存储于X或Z数据库中;
4)综合型判断规则:以全部库为中心,根据历史查询记录表解析查询中参与聚集、分组等不同查询类型占该查询模板库中总查询的比例 R,再根据各引擎执行该查询所花费时间的比较,综合判断该类查询的数据适合存到X、Y、Z哪个数据库中。此外,还可以通过解析查询结果Rq是属于面向报表rForms、面向对象Obj、面向网络Net的哪一种结构形式,综合判断该数据应存储于X、Y、Z哪个数据库中。
本发明的具体操作方式如下:
本发明首先,根据查询验证引擎的校验判断,若校验成功,则将返回结果集;然后,结合结果集和数据分发规则来完成数据分发,实现数据分发引擎(DD-Engine),即三引擎数据库之间的数据流动 (D-Flow)。在经过长期的规则训练——这一步可以做成手动触发,具体的分发验证可根据数据的查询时间来验证分发规则是否属于目前最优规则,从而实现最优化分发;数据分发算法的目标是要根据分析查询的规律性,推断出数据分发存储位置的规律性,进而判断出不同数据的合适位置。比如,哪部分数据适合存储在新能源关系数据库中;哪部分数据适合存储在新能源文档数据库中;哪部分数据适合存储在新能源图数据库中;并且记录每次查询的规律特点,进行保存。根据保存的记录,找出每种数据类型以及存在关联特性的数据存储的特点,完成数据分发;该方法的步骤是:
1)首先,输入语句进行预处理分块解析(对查询语句分块解析更有利于了解查询语句查询特点)。
2)然后根据预处理结果sections和查询类型type匹配一类查询 querys,根据querys获取不同方式的查询引擎的分析结果analysisResults进行保存(2~3行)。
3)然后依次遍历比较,合理则添加至分发结果distirbuteResults 中,否则记录失败的信息(5~12行)。
4)最终根据distirbuteResults和分发规则rule执行数据分发,输出流动字段fileds和存储位置locations(13~14行);
查询验证算法的功能主要是为了在完成数据分发之后,用以验证数据在分发之前存储与分发之后存储的查询效率的高低,再根据每次计算的数据分发的准确率验证数据分发算法的正确性,并且保存查询的对比结果,用以做综合对比分析;
该算法的步骤是:
1)首先,根据输入查询语句sqls和查询类型type获取查询验证条件。
2)其次构建查询语句模板库QLTB连接tcon,再调用查询转换工具获取定量的查询语句querySqls,以集合的方式接收(2~3行)。
3)之后,建立数据源连接con,然后逐语句执行查询,以键值方式存储(4~6行)。再与执行记录库建立连接rcon,保存R1到查询记录表中——主要指对每条语句的查询效率、查询类型、参与的数据库、表等等信息记录保存(7~9行)。
4)然后等以上查询记录保存完成之后,再调用结果分析处理程序resultAnalysisHandle,记录以上单引擎与协同存储方式综合平均查询结果并对查询记录结果进行综合整理,主要是指不同查询类型、不同存储方式下的平均效率、以及增加记录实验次数标签等,保存R2 在结果分析表中(10~11行)。
上述结合附图对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的方法构思和技术方案进行的这种非实质改进,或未经改进将本发明的构思和技术方案直接应用于其他场合的,均在本发明的保护范围之内。
- 一种基于规则的新能源数据分发方法
- 基于规则引擎的新能源汽车保险标识识别方法及装置