一种基于无锚框检测网络改进的车辆检测方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及深度学习目标检测领域,特别是涉及一种基于无锚框检测网络改进的车辆检测方法。
背景技术
随着智慧城市、智能交通系统、无人驾驶的建设与发展,其中车辆检测技术成为了关键。在交通管理、拥堵路段检测等方面应用广泛,并且在减少甚至避免交通事故具有重要的意义。
在传统方法中,首先对图像进行预处理,通过滤波器遍历图像得到车辆或者行人等目标的初步位置,再通过人工设计车辆目标的特征进行识别。其主要特征有梯度直方图(Histogram ofOriented Gradient,HOG),尺度不变特征(scale-invariant featuretransform,SIFT)和哈尔特征(Haar-link feature)等,最后通过正负样本训练支持向量机(Support VectorMachine,SVM)等分类器进行特征分类,完成最终的检测。传统方法受限于目标位置推测的效率,造成鲁棒性不强,尤其是在实时检测以及有遮挡的目标检测时有明显缺陷。
近些年来,深度学习技术不断发展并取得了巨大的突破,通过卷积神经网络自动提取出目标特征。得益于卷积神经网络强大的特征提取能力,目标检测算法的检测准确度大幅提升,并且具有更强的鲁棒性,可以适应更加复杂的识别场景。
2012年AlexNet的提出拉开了深度学习的发展大幕,之后2014年的VGGNet的提出使得深度神经网络的实现成为可能,但在网络加深的同时会出现梯度消失的问题。2015年ResNet的提出,通过残差连接的方法解决了上述问题,减少了模型收敛时间,使得网络更深而不容易出现梯度消失的问题。
现如今目标检测算法主要分为两类:onestage方法和two-stage方法。two-stage方法通过算法生成一系列候选框,然后在候选框上进行回归和分类,其特点是准确度高,但识别速度相对较低。2014年Girshick等人提出R-CNN(RegionCNN)算法,Fast-RCNN,Faster-RCNN使用了选择性搜索的方法生成候选框,之后通过卷积神经网络提取候选框的特征,最后将特征输入到SVM分类器进行分类回归操作,得到识别结果。为了克服识别速度慢的问题,提出one-stage的方法,其主要通过取消候选框生成的步骤,直接使用卷积神经网络对图像数据进行卷积操作,直接通过提取的特征进行检测和分类。该方法速度快,但是识别准确度相对two-stage方法普遍较低。2016年,YOLO系列算法的提出,在保证识别准确率的同时,解决了算法实时性的问题。该算法将检测和分类过程整合为一个过程,并且在每个特征单元上预测检测框位置和类别,最后结合图像数据中的背景信息在整个图像特征上进行预测,得到最终的识别结果。同样one-stage算法的代表,SSD检测算法结合了R-CNN算法和YOLO算法的优势,通过再多尺度的特征检图上生成不同的大小的候选框,实现对各种尺寸目标的检测。以上的两类算法属于Anchor-Base类算法,需要找到可能目标的锚框后对其进行类别预测。近年来出现了Anchor-Free类的方法,不需要锚框,直接通过关键点对目标进行检测与定位,不仅提高了检测速度,而且能更好的适应不同尺寸的目标。
基于以上问题,本发明根据无锚框网络CenterNet的基础上加入了特征融合和注意力机制模块,在保证车辆检测速度的同时,提高了检测精度,对车辆出现的叠加,小目标等都有所提高。
发明内容
为解决上述问题,本发明实例提供了一种基于无锚框检测网络改进的车辆检测方法,目的是提高车辆检测的精度和速度,包括以下形成步骤:
步骤一,将图像输入到网络中,通过特征提取模块对输入图像进行特征提取,得到特征图;
步骤二,对所述特征图输入给特征融合模块,将低维特征与高维特征进行特征融合,得到特征融合后特征图;
步骤三,对所述特征融合后的特征图输入给无锚框检测网络,进行车辆目标的检测识别,得到识别后的结果并输出,所述无锚框检测网络使用CenterNet检测网络;
步骤四,所述CenterNet网络的骨干网络使用ResNet101的结构,使用跳接方式连接各个卷积层,并在跳接中使用卷积注意力模块(CBAM);
优选的,步骤一中所述特征提取模块采用深度可分离卷积替代标准卷积操作,首先使用卷积核为3×3的卷积,对输入图像进行逐通道卷积,得到输入图像特征,然后使用卷积核为1×1的卷积对所述输入图像特征进行逐点卷积,得到最终的图像特征图,达到减少计算量和提高特征提取的能力,所述深度可分离卷积后接批归一化层增加模型的泛化能力,在所述批归一化层后接ReLU激活函数,上述三部分构成特征提取模块;
优选的,步骤二中使用特征融合模块,本发明通过将浅层特征与深层特征进行融合来增加小目标、重叠目标检测的精度,将Conv3-3层的特征图下采样到38×38的大小,特征图通道数不变;将Conv4-3层的特征图进行降维,通道数由512个降至256个,特征图大小不变;将Conv7层的特征图上采样到38×38的大小,并将特征通道数由1024个降至256个;将Conv3-3层、Conv4-3层、Conv7层。的特征图进行拼接,拼接后特征图的通道数有768个,并把特征图每个位置对应的默认框数量由4个变为6,在进行融合前对其进行下采样,以减小特征图尺寸,并扩大感受野用以减少特征损失,使用空洞卷积对其进行下采样,步长设置为2。空洞卷积的输入输出特征图关系如下:
其中p为填充像素的大小,d为扩张率,s为步长,k为卷积核的大小,W
为输入特征图的大小,W
优选的,步骤三中采用无锚框网络CenterNet进行车辆目标的检测,所述CenterNet采用无锚框的设计,在精度上相比现有的但阶段方法更好,速度也比单阶段方法更快,并且所述无锚框检测网络CenterNet网络使用ResNet结构作为骨干网络,并使用所述跳接结构。
优选的,所述ResNet网络的跳接结构中加入所述CBAM注意力模块,所述CBAM(Convolutional BlockAttentionModule)模块是一种轻量、通用的注意力模型,同时在空间和通道上进行特征的注意力机制。本发明实施例中添加了CBAM模块的模型比基准模型有着更好的性能和更好的解释性,更关注目标目标本身,计算可以用如下公式表示:
其中以F表示输入feature map,
与现有技术相比,本发明实例中在无锚框目标检测网络的基础上改进,增加了特征融合模块,并且在网络结构中使用了注意力机制模块,很好地解决了车辆检测问题中,目标较小,目标叠加出现的检测不精准的问题,并且在保证检测精准度的同时保证了实时检测效果。
附图说明
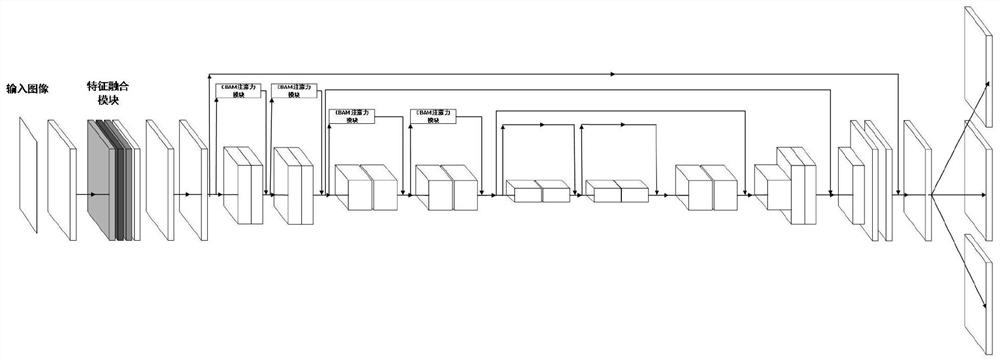
图1为本发明的一种基于无锚框检测网络改进的车辆检测方法的形成步骤的整体流程图;
图2为本发明的一种基于无锚框检测网络改进的车辆检测方法的形成步骤中的特征提取模块;
图3为本发明的一种基于无锚框检测网络改进的车辆检测方法的形成步骤中的特征融合模块;
图4为本发明的一种基于无锚框检测网络改进的车辆检测方法的形成步骤中的通道注意力示意图;
图5为本发明的一种基于无锚框检测网络改进的车辆检测方法的形成步骤中的空间注意力示意图;
图6为本发明的一种基于无锚框检测网络改进的车辆检测方法的CBMA模块示意图;
图7为本发明的一种基于无锚框检测网络改进的车辆检测方法的结果展示。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中模型方案进行完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种基于无锚框检测网络改进的车辆检测方法,该发明实例形成步骤为:
步骤一,将图像输入到网络中,通过特征提取模块对输入图像进行特征提取,得到特征图。所述特征提取模块设计如图2所示,采用深度可分离卷积设计和残差链接的结构,首先使用卷积核为3×3的卷积层,对输入图像进行逐通道卷积,得到输入图像特征,然后使用卷积核为1×1的卷积对所述特征图进行逐点卷积,得到最终的图像特征图,达到减少计算量和提高特征提取的能力。
所述特征提取模块包含两个分支一条分支使用1×1卷积,卷积和数量为2n,步长设置为s=2。另一条分支使用可分离卷积操作,首先使用1×1卷积操作,卷积核熟练为n/2,补偿设置为s=2,在其后使用3×3卷积特征提取,卷积核数量为n/2,步长设置为s=1,其后连接1×1卷积进行特征通道的升维,卷积核数量为2n,步长设置为s=1,特征图通道数变为2n,最后将两支路的输出对应位置进行叠加,得到输出特征图大小为(h/2,w/2,2n)。最后在输出后使用批归一化层来增加模型的泛化能力,并使用ReLU激活函数,构成整个特征提取模块。
步骤二,如图2所示,对所述特征图输入给特征融合模块,将低维特征与高维特征进行特征融合,得到特征融合后特征图。本发明实施例通过将浅层特征与深层特征进行融合来增加小目标检测的精度,但是浅层特征图尺寸较大,过多的引入浅层特征会对算法的实时性造成较大影响.综合考虑实时性与精度,对网络结构进行如下改进,如图4所示.将Conv3-3层的特征图下采样到38×38的大小,特征图通道数不变;将Conv4-3层的特征图进行降维,通道数由512个降至256个,特征图大小不变;将Conv7层的特征图上采样到38×38的大小,并将特征通道数由1024个降至256个;将Conv3-3层、Conv4-3层、Conv7层。的特征图进行拼接,拼接后特征图的通道数有768个;并把特征图每个位置对应的默认框数量由4个变为6个。
其中conv3-3层特征图尺寸较小,拥有更多的特征信息,在进行融合前对其进行下采样,以减小特征图尺寸,并扩大感受野用以减少特征损失,使用
空洞卷积对其进行下采样,步长设置为2。空洞卷积的输入输出特征图关系如下:
其中p为填充像素的大小,d为扩张率,s为步长,k为卷积核的大小,W
Conv4-3层和Conv7层的特征通道数较多,导致计算量增加,为了减少网络的训练参数量,增加算法的实时性,首先需要对其进行降维处理.,对Conv7层进行降维处理后,对降维后特征进行上采样操作,常用的上采样操作有两种方法,分别为使用反卷积操作和双线性插值法,其中反卷积在网络中引入了新的训练参数,会对算法的实时性造成影响,而双线性插值法在保证上采样效果的同时拥有更快的运行速度快,且操作简单,所以本文采用双线性插值方法进行上采样。
步骤三,所述无锚框检测网络CenterNet网络使用ResNet结构作为骨干网络,并使用所述跳接结构。
步骤四,所述CenterNet网络的骨干网络使用ResNet101的结构,使用跳
接方式连接各个卷积层,并在跳接中使用卷积注意力模块(CBAM),通道注意力模块结构如图3所示,首先将feature map在spatial维度上进行压缩,得到一个一维矢量以后再进行操作,对输入feature map进行spatial维度压缩时,作者不单单考虑了averagepooling,额外引入max pooling作为补充,通过两个pooling函数以后总共可以得到两个一维矢量。global average pooling对feature map上的每一个像素点都有反馈,而globalmax pooling在进行梯度反向传播计算只有feature map中响应最大的地方有梯度的反馈。
其中以F表示输入feature map,
空间注意力结构如图4所示,将Channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling和global averagepooling,然后将这2个结果基于channel做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。计算公式如下:
其中σ表示的是sigmoid激活函数,该部分显示的卷积层使用了7x7的卷积核。
本发明实例在ResNet的跳接结构中使用CBMA注意力机制模块,增加对车辆的检测识别率,该模块使用参数较少,不会影响整体的实时性。整体结构如图5所示。
通过测试,相比于传统的目标检测算法算法,本发明实例在BITVehicle_Dataset数据集上有很好的检测效果,平均精度达到了87.9%,相比改进前的网络提升了2.1%,平均帧率达到43帧/s,满足实时检测的要求。结果展示如图7所示。
综上所述,本发明实例中的一种基于无锚框检测网络改进的车辆检测方法,首先通过特征融合模块将低维特征与高维特征进行特征融合;然后将特征融合处理后的特征送入无锚框检测网络框架中;该网络中加入CBAM注意力机制模块,增加检测效果;再将识别结果输出。该方法增加了特征融合模块和注意力机制模块,无锚框检测网络采用CenterNet网络,并采用Resnet网络的跳接连接方式,能够快速进行车辆检测的同时,保证有更好的检测精度。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于无锚框检测网络改进的车辆检测方法
- 一种基于无人机及无锚框网络的车辆检测方法