一种基于图卷积神经网络的视频描述方法
文献发布时间:2023-06-19 11:32:36
技术领域
本申请涉及计算机视觉和自然语言处理的技术领域,具体而言,涉及一种基于图卷积神经网络的视频描述方法。
背景技术
随着计算机技术和互联网的不断发展,多媒体技术也得到了长足的进步,视频已成为主要的媒体传播主要形式。网络中存在着海量的视频数据,任何人都可以无约束地上传视频,这其中不可避免得存在暴力、色情等违规内容;只凭人工筛选已经很难做到审核所有的视频内容,而且工作时难免会有疏漏。除上面提到的视频审核工作外,理解视频内容、对视频内容进行描述还可以应用于机器人人机交互、为视障人士提供帮助等方面。因此如何处理和理解视频的内容显得尤为重要,但对于大规模的视频数据,计算机很难做到透彻地理解视频信息内容。
深度学习技术使计算机理解视频内容成为可能,配合自然语言处理技术构建的端到端的“编码器-解码器”算法框架,使计算机不仅可以理解视频内容,还可以使用自然语言对视频内容进行描述。在视频描述任务中,深度卷积神经网络(CNN)可以有效地提取视频的空间特征或时序特征,因此CNN常常被用作编码器;而因为长短时记忆网络(LSTM)可以有效地捕捉文本中词语的关系,且有效解决了梯度爆炸问题并缓解了长期依赖问题,因此,语言模型LSTM常被用作解码器。
而现有技术中,由于CNN仅能提取全局特征信息,常规的视频描述方法仅使用视频帧的全局信息,即视频帧被视作整体输入给CNN,而视频帧的局部信息并未被很好地挖掘、利用,存在局部特征缺失的现象,因而,在现有视频描述方法中往往存在着如下技术问题:
(1)对象的动作描述不准确,如将打球描述为跑步;
(2)视频中的对象描述不准确,如对人的性别描述错误。
因此,为了更准确地对视频进行描述,视频中局部信息的获取与处理问题以及不同特征间的融合问题亟待解决。
发明内容
本申请的目的在于:基于图卷积神经网络,分别对对视频帧中的全局特征信息、局部特征信息进行挖掘利用,并将不同的特征信息进行融合,以对视频内容进行描述,提升描述准确性。
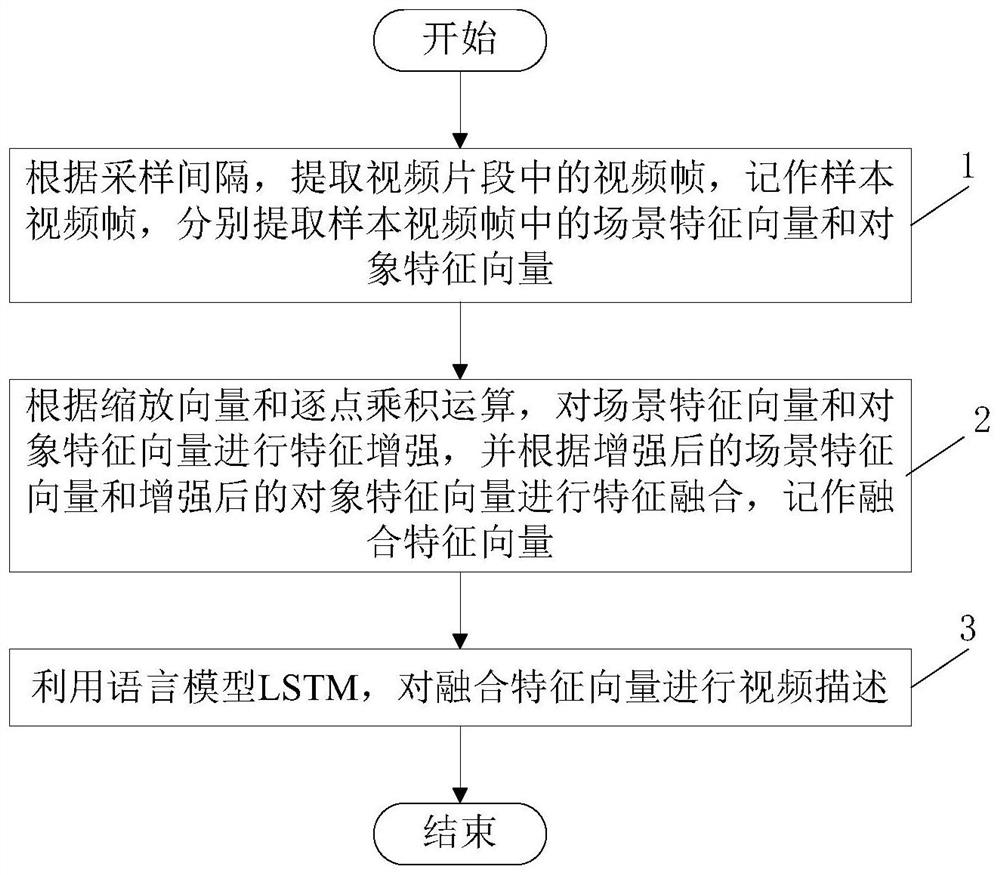
本申请的技术方案是:提供了一种基于图卷积神经网络的视频描述方法,方法包括:步骤1,根据采样间隔,提取视频片段中的视频帧,记作样本视频帧,分别提取样本视频帧中的场景特征向量和对象特征向量;步骤2,根据缩放向量和逐点乘积运算,对场景特征向量和对象特征向量进行特征增强,并根据增强后的场景特征向量和增强后的对象特征向量进行特征融合,记作融合特征向量;步骤3,利用语言模型LSTM,对融合特征向量进行视频描述。
上述任一项技术方案中,进一步地,步骤1中,提取样本视频帧中的场景特征向量,具体包括:步骤11,将样本视频帧输入至CNN网络进行特征提取运算,将CNN网络最后一层池化层的输出记作高维特征图;步骤12,对高维特征图进行二维平均池化操作,将池化结果记作第一特征向量;步骤13,将第一特征向量输入至帧GCN网络进行编码和嵌入操作,生成场景特征向量。
上述任一项技术方案中,进一步地,步骤1中,提取样本视频帧中的对象特征向量,具体包括:步骤14,将样本视频帧输入至目标检测模型,利用非极大值抑制方法,对样本视频帧中的区域进行筛选,确定物体对象的区域位置,记作对象区域;步骤15,将对象区域与高维特征图进行区域对应,并对对象区域进行剪裁和ROIAlign操作,生成第二特征向量;步骤16,对第二特征向量进行二维平均池化操作,生成第三特征向量;步骤17,将第三特征向量输入至区域GCN网络进行编码和嵌入操作,生成对象特征向量。
上述任一项技术方案中,进一步地,步骤13,具体包括:
步骤131,对第一特征向量进行线性变换,并计算线性变换后第一特征向量中各行向量之间的第一行向量关系,并根据第一行向量关系,确定第一图矩阵,其中,第一图矩阵G的计算公式为:
φ(x
式中,F(x
步骤132,根据第二学习参数矩阵,对第一特征向量X进行线性空间变换,利用第一图矩阵G对线性空间变换后的第一特征向量进行特征嵌入,生成场景特征向量,对应的计算公式为:
Y=GXW
式中,Y为场景特征向量,W为第二学习参数矩阵,X为第一特征向量。
上述任一项技术方案中,进一步地,步骤17,具体包括:步骤171,对第三特征向量进行线性变换,并计算线性变换后第三特征向量中各行向量之间的第二行向量关系,并根据第二行向量关系,确定第二图矩阵;步骤172,根据第三学习参数矩阵,对第三特征向量进行线性空间变换,利用第二图矩阵对线性空间变换后的第三特征向量进行特征嵌入,生成对象特征向量。
上述任一项技术方案中,进一步地,步骤2之前,还包括:分别对场景特征向量和对象特征向量进行一维平均池化操作。
上述任一项技术方案中,进一步地,步骤2中,根据缩放向量和逐点乘积运算,对场景特征向量进行特征增强,具体包括:
根据门控机制和一维平均池化后的场景特征向量,计算缩放向量,对应的计算公式为:
α=σ(g(v
式中,v
将一维平均池化的场景特征向量与缩放向量进行逐点乘积运算,对场景特征向量进行特征增强。
上述任一项技术方案中,进一步地,视频片段由连续的、多帧视频帧组成,采样间隔由视频帧的总数和预设的采样帧数的比值,通过向下取整运算得出。
本申请的有益效果是:
本申请中的技术方案,首先利用CNN网络和帧GCN网络结合,提取视频帧中的全局特征信息作为场景特征向量;其次,利用目标检测模型,提取准确的物体对象区域,通过区域GCN网络的特征嵌入功能,提取视频帧中的局部特征信息作为对象特征向量,可以很好地突出关键物体对象在整个视频中的作用,得以很好地挖掘出局部特征信息即视频中物体对象的信息;
再利用缩放向量和逐点乘积运算,分别对场景特征向量、对象特征向量进行特征增强,该过程由两个SE模块实现,对全局特征和局部特征的再编码,使全局和局部的特征信息可以突出各自对视频描述的作用,算法得以兼顾全局和局部特征信息,对动作的描述更加准确,生成的描述既具有全局性性又对关键物体具有针对性。
最后将融合后的特征向量利用语言模型LSTM进行描述。
此外,本申请中的描述方法对不同CNN模型均有一定的效果提升,适用于2D CNN和3D CNN,有良好的鲁棒性,这也使得晚期融合等技术可以直接使用,有很高的实用性和应用性。
附图说明
本申请的上述和/或附加方面的优点在结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是根据本申请的一个实施例的基于图卷积神经网络的视频描述方法的示意流程图;
图2是根据本申请的一个实施例的视频片段特征提取过程的示意流程图;
图3是根据本申请的一个实施例的SE模块的示意图;
图4是根据本申请的一个实施例的视频描述过程中的视频截图。
具体实施方式
为了能够更清楚地理解本申请的上述目的、特征和优点,下面结合附图和具体实施方式对本申请进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互结合。
在下面的描述中,阐述了很多具体细节以便于充分理解本申请,但是,本申请还可以采用其他不同于在此描述的其他方式来实施,因此,本申请的保护范围并不受下面公开的具体实施例的限制。
如图1和图2所示,本实施例提供了一种基于图卷积神经网络的视频描述方法,该方法包括:
步骤1,根据采样间隔,提取视频片段中的视频帧,记作样本视频帧,分别提取所述样本视频帧中的场景特征向量和对象特征向量,其中,所述视频片段由连续的、多帧所述视频帧组成,所述采样间隔由所述视频帧的总数和预设的采样帧数的比值,通过向下取整运算得出。
具体的,本实施例中的视频片段由连续的F帧视频帧组成,为了进行视频描述,设定预设的采样帧数为T,因此,采用向下取整运算,通过视频帧的总数和预设的采样帧数的比值,计算采样间隔t,对应的计算公式为:
根据计算出的采样间隔t,在视频片段中进行等间距采样,即可获得T个视频帧,记作样本视频帧。
本实施例主要通过CNN网络和GCN网络对样本视频帧进行特征提取,之后对提取出的特征进行融合,突出样本视频帧中的全局和局部特征信息,再利用语言模型LSTM对融合后的特征进行描述,进而实现对视频片段的描述。
需要说明的是,本实施例对语言模型LSTM的实现并不限定。
本实施例中,示出了一种提取所述样本视频帧中的场景特征向量的方法,具体包括:
步骤11,将所述样本视频帧输入至CNN网络进行特征提取运算,将所述CNN网络最后一层池化层的输出记作高维特征图;
本实施例中,选用的CNN网络可以是ResNet、Inception等2D CNN网络,也可以是3DResNet、Temporal Segment Networks等3D CNN网络。当选用2D CNN网络时,可以用图片分类数据库(ImageNet)进行预训练;当选用3D CNN网络时,可以用视频分类数据库(Kinetics)进行预训练。
当CNN网络完成预训练后,将T帧样本视频帧输入至CNN网络进行特征提取,将CNN网络的最后一层池化层的输出结果记作高维特征图,为T×h×w×d的特征图,其中,h为高维特征图的高度,w为高维特征图的宽度,d为高维特征图的通道数。
步骤12,对大小为T×h×w×d的所述高维特征图进行二维平均池化操作,将池化结果记作第一特征向量,即大小为
步骤13,将所述第一特征向量输入至帧GCN网络进行编码和嵌入操作,生成所述场景特征向量。
本实施例中,帧GCN网络和区域GCN网络均为图卷积神经网络GCN,本实施例对GCN网络的实现并不限定。
进一步的,帧GCN网络根据输入的第一特征向量,生成场景特征向量的过程,具体包括:
步骤131,对所述第一特征向量进行线性变换,并计算线性变换后第一特征向量中各行向量之间的第一行向量关系,并根据所述第一行向量关系,确定第一图矩阵,其中,所述第一图矩阵G的计算公式为:
φ(x
式中,F(x
具体的,根据第一可学习参数矩阵W′和可学习偏执系数b,对所述第一特征向量X进行线性变换,通过线性变换将第一特征向量X映射到另一空间,记x
φ(x
通过将第一特征向量映射到其他空间,使得映射后的第一特征向量具有更明确的关系信息,以便通过点积运算得出各行向量间的关系,将计算各行向量之间的第一行向量关系记作F(x
以帧GCN网络为例,行向量x
为方便帧GCN网络的后续运算,引入第一图矩阵G,即大小为
该过程的目的是消除计算行向量间关系F(x
步骤132,根据第二学习参数矩阵W,对所述第一特征向量X进行线性空间变换,利用所述第一图矩阵G对线性空间变换后的第一特征向量进行特征嵌入,生成所述场景特征向量,对应的计算公式为:
Y=GXW
具体的,通过第二学习参数矩阵W,对所述第一特征向量X进行线性空间变换,实现第一特征向量X的编码过程,使第一特征向量X变换到合适的线性空间,以便进行后续的计算,再通过构建出的第一图矩阵G,对线性空间变换后的第一特征向量XW进行特征嵌入。
经过编码和特征嵌入,帧GCN网络输出的场景特征向量Y与第一特征向量X相比,可以起到突出视频中某些关键帧的作用,因而帧GCN网络的输出可以更好地挖掘出视频中的信息。
在上述实施例的基础上,本实施例还示出了一种提取所述样本视频帧中的对象特征向量的方法,具体包括:
步骤14,将所述样本视频帧输入至目标检测模型,利用非极大值抑制方法,对所述样本视频帧中的区域进行筛选,确定物体对象的区域位置,记作对象区域;
本实施例中,选用的目标检测模型(RPN)可选用YOLO v3、SSD、Faster R-CNN、MaskR-CNN等主流的目标检测模型,在使用前需在目标检测数据库(MSCOCO)进行预训练。
使用目标检测模型(RPN)对T帧样本视频帧进行检测,设定可以得到的物体对象的区域位置的个数为N,即N个对象区域。并且,在提取对象区域的过程,使用非极大值抑制方法(NMS)对区域进行筛选,将筛选后的N个区域作为对象区域。
步骤15,将所述N个对象区域与所述步骤11中得到的高维特征图进行区域对应,即将N个对象区域对应到大小为T×h×w×d的高维特征图,之后,将每个对象区域对应的高维特征图进行剪裁和ROIAlign操作,生成第二特征向量,第二特征向量的大小为N×7×7×d;
步骤16,对所述第二特征向量进行二维平均池化操作,生成第三特征向量,第三特征向量的大小为
步骤17,将所述第三特征向量输入至区域GCN网络进行编码和嵌入操作,生成所述对象特征向量。
本实施例中,区域GCN网络输出对象特征向量的过程与帧GCN网络输出场景特征向量的过程基本一致,具体包括:
步骤171,对所述第三特征向量进行线性变换,并计算线性变换后第三特征向量中各行向量之间的第二行向量关系,并根据所述第二行向量关系,确定第二图矩阵;
步骤172,根据第三学习参数矩阵,对所述第三特征向量进行线性空间变换,利用所述第二图矩阵对线性空间变换后的第三特征向量进行特征嵌入,生成所述对象特征向量。
本实施例中,通过区域GCN网络可以找出N个对象特征向量中的关键信息,找出样本视频帧中物体的外观细节、动作细节、物体间的交互关系等局部特征信息,并通过编码和嵌入操作,加强局部特征信息。至此,样本视频帧中的局部特征信息先被目标检测模型RPN挖掘出来,然后区域GCN网络对局部特征信息进行增强,以便语言模型LSTM可以更好地将其利用。
步骤2,根据缩放向量和逐点乘积运算,对所述场景特征向量和所述对象特征向量进行特征增强,并根据增强后的场景特征向量和增强后的对象特征向量进行特征融合,记作融合特征向量;
本实施例中,主要利用两个独立的SE模块,分别对场景特征向量和所述对象特征向量进行特征增强,在进行特征增强之前,步骤2中还包括:
分别对所述场景特征向量和所述对象特征向量进行一维平均池化操作,其中,场景特征向量的一维平均池化操作结果为特征向量v
本实施例中,采用同样的方法对场景特征向量和所述对象特征向量进行特征增强,现以场景特征向量为例,对特征增强的过程进行说明,具体过程包括:
根据一维平均池化后的场景特征向量v
α=σ(W
式中,v
将所述一维平均池化的场景特征向量与所述缩放向量进行逐点乘积运算,对所述场景特征向量进行特征增强。
具体的,如图3所示,将一维平均池化后的场景特征向量v
α=σ(g(v
其中,缩放向量
对象特征向量进行特征增强的过程不再赘述。
本实施例中,通过引入两个独立的SE模块,在d个通道间寻找场景特征向量和对象特征向量的关键信息,并将其加强激活,实现特征增强。
之后,将两个特征增强结果
步骤3,利用语言模型LSTM,对所述融合特征向量
需要说明的是,本实施例在模型训练过程中,采用交叉墒作为损失函数,Adam作为优化算法对模型进行训练,并固定CNN网络和目标检测模型RPN的参数,仅对GCN网络和语言模型LSTM进行训练。
为了验证本实施例中视频描述方法的准确性,选用如图4所示的一网络视频进行视频描述,其中,图4(A)(B)(C)为等间距采样的3个样本视频帧截图,使用不同描述方法的描述结果如表1所示。
表1
因此,使用本实施例中的视频描述方法,不仅可以准确地找出视频帧中的对象,而且还可以将挖掘出的局部信息与全局信息很好地融合起来,从而更准确地对视频进行描述。
以上结合附图详细说明了本申请的技术方案,本申请提出了一种基于图卷积神经网络的视频描述方法,该方法包括:步骤1,根据采样间隔,提取视频片段中的视频帧,记作样本视频帧,分别提取样本视频帧中的场景特征向量和对象特征向量;步骤2,根据缩放向量和逐点乘积运算,对场景特征向量和对象特征向量进行特征增强,并根据增强后的场景特征向量和增强后的对象特征向量进行特征融合,记作融合特征向量;步骤3,利用语言模型LSTM,对融合特征向量进行视频描述。通过本申请中的技术方案,分别对对视频帧中的全局特征信息、局部特征信息进行挖掘利用,并将不同的特征信息进行融合,以对视频内容进行描述,提升描述准确性。
本申请中的步骤可根据实际需求进行顺序调整、合并和删减。
本申请装置中的单元可根据实际需求进行合并、划分和删减。
尽管参考附图详地公开了本申请,但应理解的是,这些描述仅仅是示例性的,并非用来限制本申请的应用。本申请的保护范围由附加权利要求限定,并可包括在不脱离本申请保护范围和精神的情况下针对发明所作的各种变型、改型及等效方案。
- 一种基于图卷积神经网络的视频描述方法
- 一种基于对象属性关系图的视频描述方法