模型训练方法与电子装置
文献发布时间:2023-06-19 11:35:49
【技术领域】
本发明是有关于一种模型训练方法与电子装置。
【背景技术】
在自动光学检查(AOI)领域中,若要使用机器学习或深度学习等方法,常需要使用已标记的图像来对模型进行训练。然而,模型的标记通常是由人工来进行,此情况会耗费大量的人力与时间,并且经由人工标记的图像中可能会有特征漏标和标记错误的问题。而使用有问题的图像来对模型进行训练,往往会造成模型学习效果不佳的问题。
【发明内容】
本发明提供一种模型训练方法与电子装置,可以解决人工标记图像所带来的问题以及有效地避免引发模式崩溃的问题。
本发明的其他目的和优点可以从本发明所公开的技术特征中得到进一步的了解。
为达上述的一或部分或全部目的或是其他目的,本发明提出一种模型训练方法,包括:获得第一图像;遮蔽所述第一图像中的至少一区域以获得遮蔽后图像;将所述遮蔽后图像输入至第一模型以获得第一生成图像;根据所述第一生成图像与所述第一图像训练所述第一模型;根据所述第一生成图像与所述第一图像训练所述第二模型;以及当训练所述第一模型达到第一条件且训练所述第二模型达到第二条件时,完成对所述第一模型的训练。
本发明提出一种电子装置,包括:输入电路与处理器。输入电路用于获得第一图像。处理器耦接至所述输入电路并用于执行下述操作:遮蔽所述第一图像中的至少一区域以获得遮蔽后图像;所述遮蔽后图像输入至第一模型以获得第一生成图像;根据所述第一生成图像与所述第一图像训练所述第一模型;根据所述第一生成图像与所述第一图像训练所述第二模型;以及当训练所述第一模型达到第一条件且训练所述第二模型达到第二条件时,完成对所述第一模型的训练。
基于上述,本发明的模型训练方法与电子装置可以自动地找出待测图像中的特定区域且不需要人工手动地标记图像中的特定区域(例如,瑕疵区域)来训练模型,借此解决人工标记图像所带来的问题。
【附图说明】
图1是依照本发明的一实施例所绘示的电子装置的示意图。
图2是依照本发明的一实施例所绘示的一种神经网络模块的示意图。
图3是依照本发明的一实施例所绘示的一种模型训练方法的流程图。
图4是依照本发明的一实施例所绘示的一种使用第一模型识别图像中的特定区域的方法的流程图。
图5是依照本发明的一实施例所绘示的第一图像与遮避后图像的示意图。
图6是依照本发明的一实施例所绘示的识别待测图像中的瑕疵区域的示意图。
【符号说明】
100:电子装置
20:处理器
22:输入电路
24:图像撷取电路
P1:导光板
S201~S203、S301~S309、S401~S405:步骤
MM1:神经网络模块
M1:第一模型
M2:第二模型
C1~C2:组合
O_img:第一图像
G_img:第一生成图像
501~503、601~605:图像。
【具体实施方式】
现将详细参考本发明的实施例,在附图中说明所述实施例的实例。另外,凡可能之处,在附图及实施方式中使用相同标号的元件/构件代表相同或类似部分。有关本发明的前述及其他技术内容、特点与功效,在以下配合附图的一较佳实施例的详细说明中,将可清楚的呈现。以下实施例中所提到的方向用语,例如:上、下、左、右、前或后等,仅是参考附图的方向。因此,使用的方向用语是用来说明并非用来限制本发明。
图1是依照本发明的一实施例所绘示的电子装置的示意图。请参照图1,电子装置100包括处理器20与输入电路22。其中,输入电路22耦接至处理器20。
处理器20可以是中央处理器(CPU),或是其他可编程的通用或专用的微处理器、数字信号处理器(DSP)、可编程控制器、专用集成电路(ASIC)或其他类似元件或上述元件的组合。
输入电路22例如是用于从电子装置100外部或其他来源取得相关数据的输入接口或电路。在本实施例中,输入电路22是耦接至图像撷取电路24。图像撷取电路24例如是采用电荷耦合器件(Charge coupled device,CCD)镜头、具有互补式金氧半导体晶体管(CMOS)的镜头、或红外线镜头的摄影机、照相机。图像撷取电路24用于拍摄导光板P1上的对象以获得图像。然而,在其他实施例中,输入电路22也可以是从其他的储存媒体获得图像,在此不作限制。
此外,电子装置100也可以包括存储电路(未图示),储存电路耦接至处理器20。存储电路可以是任何型态的固定或可移动随机存取存储器(RAM)、只读存储器(ROM)、闪存或类似元件或上述元件的组合。
在本实施例中,电子装置100的存储电路中存储有多个代码段,在上述代码段被安装后,会由处理器20来执行。例如,存储电路中包括多个模块,借由这些模块来分别执行应用于电子装置100中的各个运作,其中各模块是由一或多个代码段所组成。然而本发明不限于此,电子装置100的各个运作也可以是使用其他硬件形式的方式来实现。
图2是依照本发明的一实施例所绘示的一种神经网络模块的示意图。请参照图2,在本实施例中,处理器20会先配置神经网络模块MM1。神经网络模块MM1包括第一模型M1与第二模型M2。在步骤S201中,输入电路22可以获得由例如由图像撷取电路24所拍摄的图像。之后,在步骤S203中,处理器20可以使用预设尺寸大小的区块遮蔽步骤S201所获得的图像中的至少一区域以获得遮蔽后图像。而前述区块可以是由单一颜色(例如,黑色、白色、灰色或其他颜色)的多个像素所组成的区块。之后,处理器20可以将遮蔽后图像输入至神经网络模块MM1以调整第一模型M1与第二模型M2中的权重。
在本实施例中,第一模型为自编码器(auto encoder),且第二模型为猜测鉴别器(guess discriminator)。自编码器是使用神经网络的非监督式学习方法(unsupervisedlearning method)。自编码器中会包含编码器与解码器以根据输入图像来产生生成图像。在熟知此技术领域的人员可知,自编码器、变分自编码器(variational auto encoder)等架构都是由编码器与解码器所组成的非监督式神经网络。第一模型(例如,自编码器)主要用于将一输入图像转换为一生成图像。在本实施例中,假设输入图像为具有某特定区域(例如,瑕疵区域)的图像(亦称为,瑕疵图像),而自编码器主要用于将输入图像转换为不具有所述特定区域的图像(亦称为,正常图像)。
此外,在本实施例中,猜测鉴别器(guess discriminator)的输入为输入至自编码器的输入图像以及由编码器所产生的对应于前述输入图像的生成图像,并用于分辨哪张图像是输入至自编码器的输入图像且哪一张图像是由编码器所产生的生成图像。在分辨时,在本实施例中,猜测鉴别器会同时以不同的顺序叠合前述的输入图像与生成图像以产生多种组合以进行分辨。借由此方式,相较于一般的猜测鉴别器,可以有效地避免引发模式崩溃(mode collapse)的问题。除此之外,借由前述方式也可以有效地解决在图像到图像的转换(Image to Image translation)的领域中的自我对抗攻击(self-adversarial attack)的问题。
图3是依照本发明的一实施例所绘示的一种模型训练方法的流程图。
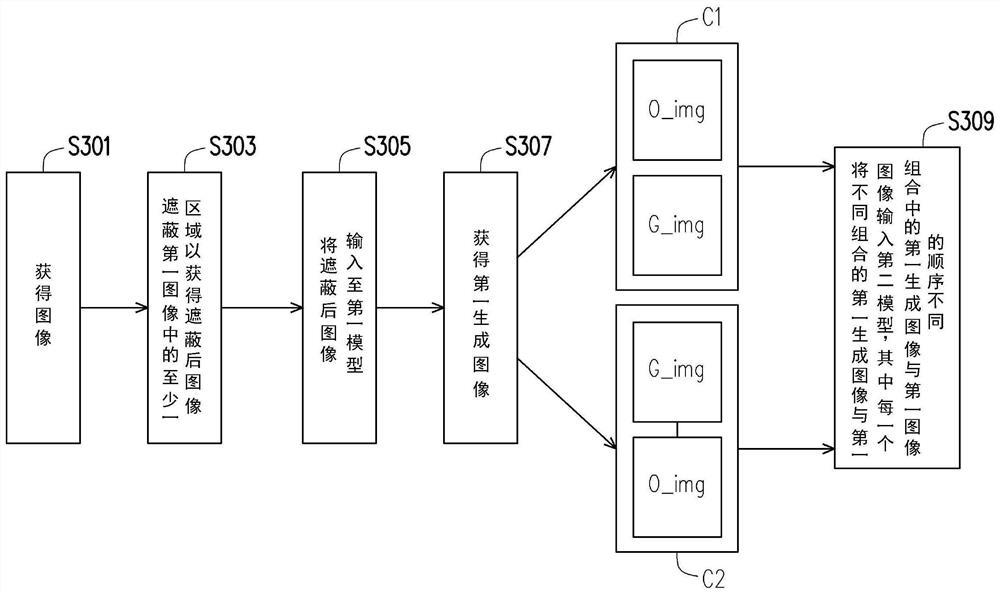
请参照图3,图3用于更详细地描述如何训练神经网络模块MM1中的以第一模型M1与第二模型M2以调整第一模型M1与第二模型M2中的权重。首先,在步骤S301中,输入电路22会获得一第一图像O_img。在实施例中,第一图像O_img的获得方式可以是处理器20通过输入电路22获得由图像撷取电路24所拍摄的原始数据(raw data)(亦称为,原始图像),并根据预先设定的大小切割此原始数据以获得第一图像O_img。然而在其他实施例中,第一图像O_img也可以是未经切割的原始数据。此外,在实施例中,处理器20可以使用不同大小任意地切割原始数据以获得多个子图像,并使用子图像的其中之一作为第一图像O_img。而不同大小任意地切割原始图像可以避免后续训练模型时模型使用相同的图案进行学习。
之后,类似于步骤S203,在步骤S303中,处理器20可以使用预设尺寸大小的区块遮蔽第一图像O_img中的至少一区域以获得遮蔽后图像,默认尺寸大小可以是设定成一定大小或不定大小。而前述区块可以是单一颜色的区块。在步骤S305中,处理器20会将遮蔽后图像输入至第一模型M1,并且在步骤S307中获得由第一模型M1所产生的对应于第一图像O_img的第一生成图像G_img。之后,处理器20会根据第一生成图像G_img与第一图像O_img训练第一模型M1与第二模型M2。当训练第一模型M1达到第一条件且训练第二模型M2达到第二条件时,处理器20会完成对第一模型M1的训练。
更详细来说,在训练第一模型M1达到第一条件的过程中,处理器20会调整第一模型M1中的多个权重(亦称为,第一权重)以使得根据所述第一生成图像G_img与第一图像O_img所计算出的一损失函数的数值(亦称为,损失函数值)达到最小值。其中,损失函数可以为均方误差(mean square error)、KL散度(Kullback-Leibler divergence)、交叉熵(cross-entropy)等,在此不作限制。
此外,在训练第二模型M2达到第二条件的过程中,在步骤S309中处理器20会将不同组合C1~C2的第一生成图像G_img与第一图像O_img输入第二模型M2。处理器20会调整第二模型M2中的多个权重(亦称为,第二权重)以使得根据第一生成图像G_img与第一图像O_img的多种组合C1~C2所计算出的一损失函数值达到最大值。特别是,前述每一个组合C1~C2中的第一生成图像G_img与第一图像O_img的顺序不同。以图3为例,组合C1例如是在第一生成图像G_img上叠加第一图像O_img,而组合C2例如是在第一图像O_img上叠加第一生成图像G_img。
特别是,当训练第一模型M1达到第一条件且训练第二模型M2达到第二条件时,第二模型M2会无法分辨出第一图像O_img与第一生成图像G_img中的哪一个图像是由第一模型M1所产生(或输出)。此时,处理器20会完成对第一模型M1的训练,且训练完成的第一模型M1可以用于识别图像中是否具有特定区域(例如,具有瑕疵的区域)。
例如,图4是依照本发明的一实施例所绘示的一种使用第一模型识别图像中的特定区域的方法的流程图。
请参照图4,在步骤S401中,处理器20会获得待测图像。此待测图像例如是处理器20通过输入电路22获得由图像撷取电路24所拍摄的原始数据,并根据预先设定的大小切割此原始数据所获得的待测图像。然而在其他实施例中,待测图像也可以是未经切割的原始数据。之后在步骤S403中,处理器20会将待测图像输入至已训练完成的第一模型M1以获得一生成图像(亦称为,第二生成图像)。之后,在步骤S405中,处理器20会根据待测图像与第二生成图像识别待测图像中的特定区域。更详细来说,以特定区域为瑕疵区域为例,处理器20会将待测图像与第二生成图像相减以识别出待测图像中的瑕疵区域。例如,在实施例中,在将待测图像与第二生成图像相减后,可以使用一般的图像处理方法来去除相减后的图像中的噪声,并将相减后的图像中的像素值大于阈值(threshold)的像素识别为瑕疵,阈值的像素(pixel)例如为5×5个像素,但不局限于此。
也就是说,借由前述的第一模型M1与第二模型M2的训练,第一模型M1可以自动地找出待测图像中的特定区域且不需要人工手动地标记图像中的特定区域(例如,瑕疵区域)来训练模型,借此解决人工标记图像所带来的问题。
图5是依照本发明的一实施例所绘示的第一图像与遮蔽后图像的示意图。
请参照图5,假设图像501为前述步骤S301所获得的第一图像,并且在经过步骤S303后可以获得图像503。如图像503所示,图像503中具有多个被白色区块遮蔽的区域,图像503可以作为前述的遮蔽后图像。
此外,图6是依照本发明的实施例所绘示的识别待测图像中的瑕疵区域的示意图。
请参照图6,假设图像601为前述步骤S401所获得的待测图像。处理器20可以将图像输入至已训练完成的第一模型M1以获得图像603(即,前述的生成图像)。之后,在识别图像601中的瑕疵区域时,处理器20会将图像601与图像603相减以获得图像605。其中,处理器20可以将在图像601中对应于图像605中白色的区域识别为图像601中的瑕疵区域。
综上所述,本发明的模型训练方法与电子装置可以自动地找出待测图像中的特定区域且不需要人工手动地标记图像中的特定区域(例如,瑕疵区域)来训练模型,借此解决人工标记图像所带来的问题。
只是以上所述内容,仅为本发明的较佳实施例而已,当不能以此限定本发明实施的范围,即大凡依本发明权利要求及发明说明内容所作的简单的等效变化与修饰,皆仍属本发明专利涵盖的范围内。另外本发明的任一实施例或权利要求不须实现本发明所公开的全部目的或优点或特点。此外,摘要部分和标题仅是用来辅助专利文件搜寻之用,并非用来限制本发明的权利范围。此外,本说明书或权利要求中提及的“第一”、“第二”等用语仅用于命名元件(element)的名称或区别不同实施例或范围,而并非用来限制元件数量上的上限或下限。
- 预测模型的训练方法、电子装置、激光器诊断装置及方法
- 模型的训练方法和装置、存储介质、电子装置