基于Boosting算法历史数据驱动的包裹交付时长预测方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于计算机数据处理与分析领域,涉及一种基于Boosting算法历史数据驱动的包裹交付时长预测方法。
背景技术
随着电子商务飞速发展的同时,物流配送体系也正在不断完善。准确的预估相关包裹的到达时间,对于提高用户购物时的体验感,提高包裹的配送效率具有重要意义。在包裹的实际配送路程中,包裹的行程时长与众多因素相关。电子商务平台在给出包裹承诺送达时效时,就具有很大的不确定性。当超过承诺送达时效时,便影响了包裹的配送效率,用户无法在规定的时间内收到包裹,降低了用户的购物体验感,进而影响到电商平台的声誉。
影响包裹交付时长的因素有许多。过去的预测行程时长的工作,大多数依赖于GPS数据以及道路交通状况等信息,但配送中心的作业效率和时间点以及订单量存在着一定的关联,这也是影响包裹交付时长的一大因素。鉴于大数据下的背景,获取到大量的历史物流信息已不是难题。我们依靠大量的历史数据,重点通过构建配送中心相关特征,结合相关Boosting算法,建立包裹交付时长预测模型。
发明内容
本发明的目的在于提供一种基于Boosting算法历史数据驱动的包裹交付时长预测方法。
本发明的技术方案如下:
一种基于Boosting算法历史数据驱动的包裹交付时长预测方法,包含以下步骤:
步骤1、获取数据,并对该数据进行整理。
对获取到的用户数据、订单数据、配送数据。
在整理过程中,对获取的用户数据、订单数据、配送数据的表进行合并处理,得到整理后的包裹配送数据。
所述的合并处理实现如下:
在对三表进行合并处理操作时,使用到的字段有用户唯一标识(user_ID)、订单唯一标识(order_ID)及包裹唯一标识(package_ID)。
首先,使用用户数据和订单数据共有的用户唯一标识(user_ID),对两表进行合并处理。
最后,将上述第一步合并表与配送数据进行合并,使用共有的订单唯一标识(order_ID)及包裹唯一标识性(package_ID)
步骤2、对获取到的包裹配送数据进行预处理。
其中针对包裹配送数据中的异常数据进行剔除,所述的异常数据为实际包裹交付时长与承诺交付时长差值在3天及3天以上的数据样本。
步骤3、对预处理后的包裹配送数据进行特征提取,依靠数据原始特征创建新特征,新特征组成特征数据集;
所述的原始特征包括用户数据、配送数据、订单数据,数据若不经过转换,创建新特征,则会降低实际预测效果。
例如对于订单数据中的时间特征数据,在原始特征中,是以年月日时分秒的格式存储的。若根据该信息创建新的特征,如提取单独月、日、时的信息,对本文预测目标更具有针对性。
所述的转换后的特征数据集包含用户信息特征、订单特征、时间特征以及配送中心特征。配送中心特征是基于Bosting算法历史数据驱动包的包裹交付时长预测模型的重要特征因子。在配送中心特征进行构建的时候,本发明给出了有关配送中心负载率的定义,其在包裹交付时长预测模型特征重要性方面发挥了重要的作用。
步骤4、将经过数据预处理和特征提取构建后得到的特征数据集,输入本发明预测模型实现包裹交付时长的预测,利用多种评价指标,对模型进行评估,得到完成训练的包裹交付时长预测模型。
采用贝叶斯优化参数的方式,指定cv=5,选择5折交叉验证,对本发明使用到Boosting算法及随机森林算法模型进行参数调优,最后得到用于包裹交付时长预测的模型。
在模型评估方面,指标包括平均绝对误差(MAE)、均方根误差(RMSE)和拟合度(R-Squared),同时给出有关本发明中准确率的定义,并以准确率大小衡量实际预测效果。在最后,设定了三组误差阈值百分比,对相关模型及配送中心特征对模型预测可信度进行衡量。
步骤5、将经过训练得到的包裹交付时长预测模型,用真实的测试数据进行测试,实现包裹交付时长的预测。
利用完成训练的模型,在测试数据集在进行验证,利用评估指标对模型效果进行评估。进行了两组对比实验,分别是1)不同模型下预测能力的对比试验;2)配送中心相关特征对预测能力的影响;
最后对可信度做出定义,并绘制不同对比实验下的可信度对照图。
本发明和现有技术相比,具有如下的创新点和优点:
结合了配送中心的相关特征,定义了负载率作为其特征之一来完成配送中心相关特征的构建,同时负载率在实际训练中发挥了较强的特征重要性。
与RandomForest相比,基于Boosting算法历史数据驱动的包裹交付时长预测模型在预测能力上具有一定优势,能提供较为可信的预测结果。
在特征工程方面,通过定义配送中心的作业能力,并将其作为特征因子融合进模型的训练过程中,建立了历史数据驱动模型来预测包裹的交付时长。解决电商平台给出承诺送达时效不够精确,无法精准预估包裹的交付时长,影响平台购物体验感的问题,同时在企业给出包裹送达承诺时效时,提供一定的参考价值。最后,对相关Boosting算法及随机森林的预测能力进行了对比总结。
附图说明
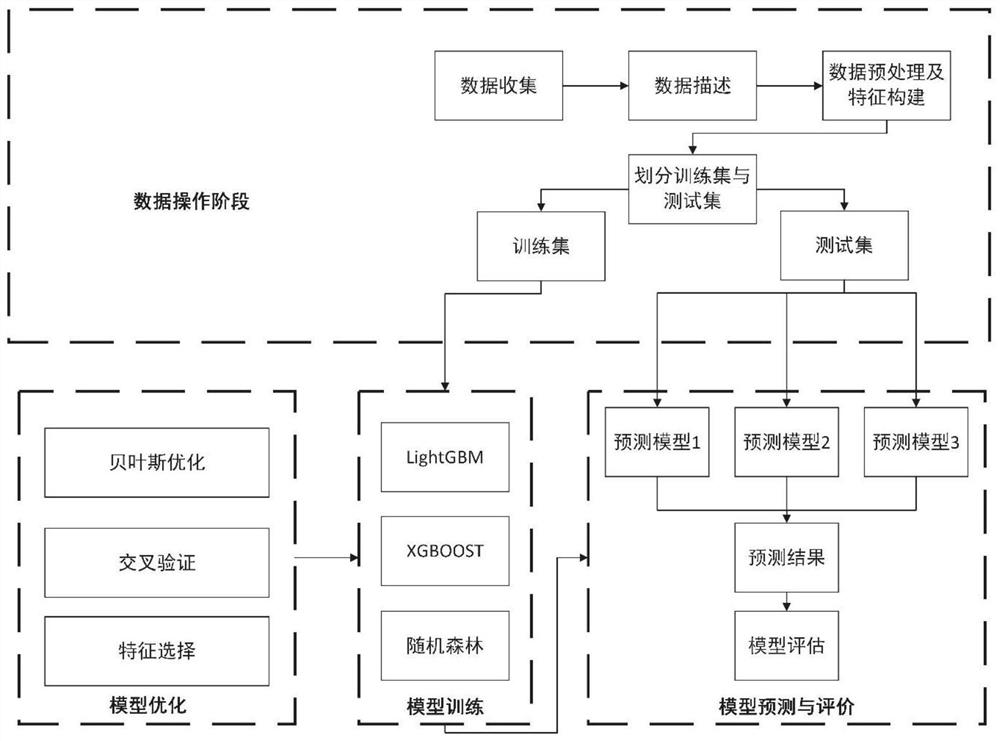
图1为本发明的建模过程详情图;
图2为数据预处理和特征工程构建的详细流程和操作图;
图3为本发明建模训练过程中特征重要性的输出图;
图4为不同模型下预测可信度的对比图;
图5为配送中心相关特征对可信度的影响对比图;
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
在图1中详细介绍了本发明的数据建模过程流程,包含了以上所述的各个步骤,图2是针对步骤2、步骤3数据预处理和特征工程构建的详细流程和操作图,下面针对每个步骤详细展开:
步骤1、获取到的数据是来自D电商平台3月份真实的下单数据,订单数据包括订单的各种属性、发货配送中心和离目标地址最近的配送中心信息。
配送中心定义为:
配送中心是送货的设施和机构,能够接受并处理末端用户的订货信息,对上游的订单货物进行分拣,同时根据用户订货要求进行拣选、加工、组配等作业。
进一步的,下单数据除了包括订单数据外,还包括用户信息数据及包裹配送数据;用户信息数据包含用户的个人信息:年龄、婚姻状态、地址所在城市的等级等。包裹配送数据包含来自59个配送中心的配送数据,涵盖了历史每一个配送环节的时间点。
通过表之间的唯一标识,对数据建立联系,得到合并后的数据。
合并操作如下:
首先使用用户数据和订单数据共有的用户唯一标识(user_ID),对两表进行合并处理。
最后,将上述第一步合并表与配送数据进行合并,使用共有的订单唯一标识(order_ID)及包裹唯一标识性(package_ID)
步骤2、数据预处理
合并后的包裹配送数据包括了众多维度,每条数据记录中包含的主要信息有:
包裹唯一标识:package_ID
用户唯一标识:user_ID
订单唯一标识:order_ID
发货配送中心ID:dc_roi,表示是哪个发货配送中心
离目标地址最近的配送中心ID:dc_des
下单时间:订单提交时间,时间格式为:年:月:日:时:分:秒;
配送中心作业时间:包裹从仓库完成拣货并发出的时间点,时间格式为:年:月:日:时:分:秒;
到达配送站点的时间:时间格式为:年:月:日:时:分:秒;
订单信息:包含商品数量、是否包含礼品等;
合并后的包裹配送数据包括了众多维度,但绝大部分对预测包裹的交付时长工作是无用的,因此针对包裹配送数据进行研究分析并构建特征属性,进行建模预测。
2-1.对合并后的包裹配送数据进行预处理,操作详细步骤:
①剔除无用数据:
删除表中package_ID为空的记录;删除order_ID重复的数据记录,保留一条记录即可(保留第一次出现的数据);删除记录中无承诺送达期限,即在记录中显示为“-”的记录;
②异常数据的处理:
部分订单包裹的配送信息是有异常的,这可能受到了包裹交付各个环节中没有及时录入相关信息或其它一些非人为限制因素的影响,对于这些异常值,本文进行了剔除处理。针对这些数据进行分析,在原始数据中,给出的承诺时效是以天计的。我们将实际交付时长和承诺时效相差在三天及三天以上的定义为异常数据,并将这些样本数据删除。
②计算实际包裹配送时长:
依据原始数据表订单提交时间(order_time)字段和包裹送达用户时间(arr_time)字段,按实际包裹配送时长=包裹送达用户时间-订单提交时间的公式计算实际时长。
定义用户成功提交订单时间t
步骤3、特征构建
特征对包裹交付时长预测模型的准确性影响非常大,针对此,我们利用包裹配送中心特征作为重要特征因子融合进模型,进行预测工作。主要的特征构建如下:
Ⅰ、用户信息特征:
在提供的数据集(user_data)当中,利用到有关用户信息的字段包括用户城市等级、用户购买等级和plus会员信息等。将这一部分内容作为用户信息特征,并进行提取。本实施例中构建的用户信息相关的特征表,如下表1所示。
表1:
Ⅱ、时间特征:
配送中心的服务能力在不同时间(一天内的不同小时)上具有一定的规律,在提取时间特征完成后,对每个时间点需要分别做月、日、小时信息的单独提取,同时配送中心相关特征也是按每个小时内处理包裹的数量或待处理的数量来进行构建的。
以下单时间(年-月-日时:分:秒)的格式为例,我们对其进行创建day(日),weekday(星期)以及hour(小时)等指标,用来完成更高质量的特征构建,挖掘潜在的联系。同理对配送中心有关时间点也需要做提取日、小时特征的操作。综上,本实施例中构建的时间特征,如表2所示;
表2:
Ⅲ、订单特征
用户所购买的商品种类、性质或数量等因素会在一定程度上影响包裹配送的时长。本实施例中构建的订单特征如表3所示。
表3:
Ⅳ、配送中心特征:
配送中心即为仓库,代表包裹将从哪个仓库发出。本实施例是以配送中心为研究对象,对包裹配送行程时间进行预测,继而达到预测包裹交付时长的目的。
配送中心的作业能力影响了包裹的发出时间(提交订单到订单包裹从仓库发出的时间),而这个时间正是组成包裹交付时长的重要组成部分。
因此,我们在本实施例中定义了平均作业能力、当前工作量及负载率的定义。
(1)平均作业能力:
是指在过去一天24小时内,每个配送中心在每个小时内发出的包裹数量。根据包裹发货信息,按配送中心、发货时间(日)特征对每个配送中心在每天内的发货量进行了统计。将最后结果进行平均处理,得出平均作业能力。
(2)当前工作量:
是指在当前一天24小时内,每小时配送中心所接受订单的包裹数量。根据发货配送中心ID、用户成功提交订单时间(日)和用户成功提交订单时间(小时)对每一天每小时的下单量进行统计,得出不同配送中心在每个小时待处理的包裹量(当前工作量)
(3)负载率:
负载率=历史平均作业能力/当前工作量。
基于平均作业能力、当前工作量及负载率,结合原有数据,选择定义中的负载率作为配送中心特征之一。配送中心相关的特征属性,如表4所示。
表4:
步骤4、采用XGBoost、LightGBM及RandomForest对包裹交付时长进行预测,获得真实交付时长预测值。
本实施例采用Boosting算法其中的XGBoost与LightGBM,Boosting算法属于集成学习,其通过构建并结合多个机器学习器来完成学习任务,首先通过训练集数据训练得到若干个个体学习器,再通过一定的结合策略,最终形成一个强学习器,达到博采众长的目的。
同时,本实施例选用Bagging算法RandomForset与Boosting算法比较预测能力。
本实施例将最后得到的特征数据集按7:3的比例划分训练集与测试集。将训练集用来训练相关模型,验证集用来测试得到的预测模型。
在训练时采用贝叶斯优化的方式,进行参数的调整优化,指定CV=5,用于5折交叉验证。基于精度最高的一组模型参数组合构成优化的单模型。得到如下表5所示贝叶斯优化后包裹交付时长预测模型的参数值;
表5:
在训练完成时,同时输出了特征重要性图,如图3所示。根据特征重要性,进行特征的选择,最后的特征如表6所示。
表6:
在预测评价指标中,采用了平均绝对误差(MAE)、均方根误差(RMSE)和拟合度(R-Squared)三种指标对模型做出评价。
MAE是指平均绝对误差,其公式是;
RMSE是指均方根误差,其公式是;
R
由于数据中承诺时效是以天为单位来计算的,基于此对准确率的概念做出定义;
准确率为转换后的预测值和实际交付时长值为同样天数的样本占全部测试样本数的比例。
E、预测结果展示,我们针对配送中心相关特征对预测结果的影响进行了比较。为了从不同的侧面评价算法的预测精度,将根据MAE、RMSE、R-Squared三项回归评价指标对三种不同模型进行综合评价,如表7所示(优值加粗显示):
表7:
针对预测样本,本实施例中,对所有预测样本在XGBoost、LightGBM及RandomForest预测模型下的准确率进行了统计计算,结果如表8所示。
表8:
除了比较不同模型下预测能力的不同,本实施例同时对配送中心相关特征对模型预测能力的影响进行了评估。表9为去除配送中心特征前后三种模型在MAE、RMSE、R-Squared指标上的表现,表10为去除配送中心特征后准确率的对比。
表9:
表10:
在测试集上,本实施例进行了可信度的分析。为了更加真实地反映输出结果的可信度,本文通过百分比误差来评估预测值和观测值之间的偏差,其计算过程如下:
其中:R表示百分比误差,y
将三种预测模型进行可信度分析。定义如下:本文定义三组误差比阈值,分别是15%,15%~30%及30%以上。输出结果与实际交付时长的百分比误差在15%以内,具有较高的可信度;输出结果与实际交付时长的百分比误差在15%~30%,为中等可信度;输出结果与实际交付时长的百分比误差在30%以上,可信度较低;
对于可信度较高的输出结果,在实际的应用中能够准确地预测包裹交付时长,具有较高的应用价值;可信度中等的输出结果,在一定程度上也能够作为包裹交付时长的参考。
由图4可知,本文提出的Boosting算法,XGBoost和LightGBM在可信度上基本一致,两者均有约为77%的输出的结果能在真实的包裹交付时长预测场景中发挥其价值,相比于RandomForset来说,RandomForest在高可信度输出结果不如Boosting算法,中等可信度上具有一定优势,但总的来说,其输出结果仅有69%具有价值,低可信度样本相比Boosting算法高出了将近8个百分点,这进一步体现了Boosting算法模型在评估准确性、可信度上的优势。
由图5可知,本文提出的配送中心相关特征对模型评估的准确性具有较大的提升作用。在去除配送中心特征后,高可信度输出结果由原来的52.27%下降到了42.26%,输出结果具有价值的样本占比也从77.04%下降到了68.94%,低可信度样本占比明显提高。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 基于Boosting算法历史数据驱动的包裹交付时长预测方法
- 基于用户历史行为的补能时长预测方法