基于k8s的工作流引擎的使用方法及装置
文献发布时间:2023-06-19 11:49:09
技术领域
本发明属于工作流引擎使用领域,具体涉及一种基于k8s的工作流引擎的使用方法及装置。
背景技术
现有技术中的工作流引擎采用的kubernetes+docker的架构,k8s自带的工作流仅能应付简单的Job(工作)和Deployment(部署)任务。
然而,面向的人工智能和大数据,就不可避免的要支持各种框架的编排,如Spark、Tensorflow等批处理,又如kafka等流处理,另外还需要支持定时任务的调度。
现有的工作流引擎并不能满足上述情况的使用需求。
发明内容
本发明所要解决的技术问题是提供一种基于k8s的工作流引擎的使用方法及装置。
本发明解决其技术问题所采用的技术方案是:提供了一种基于k8s的工作流引擎的使用方法,包括:
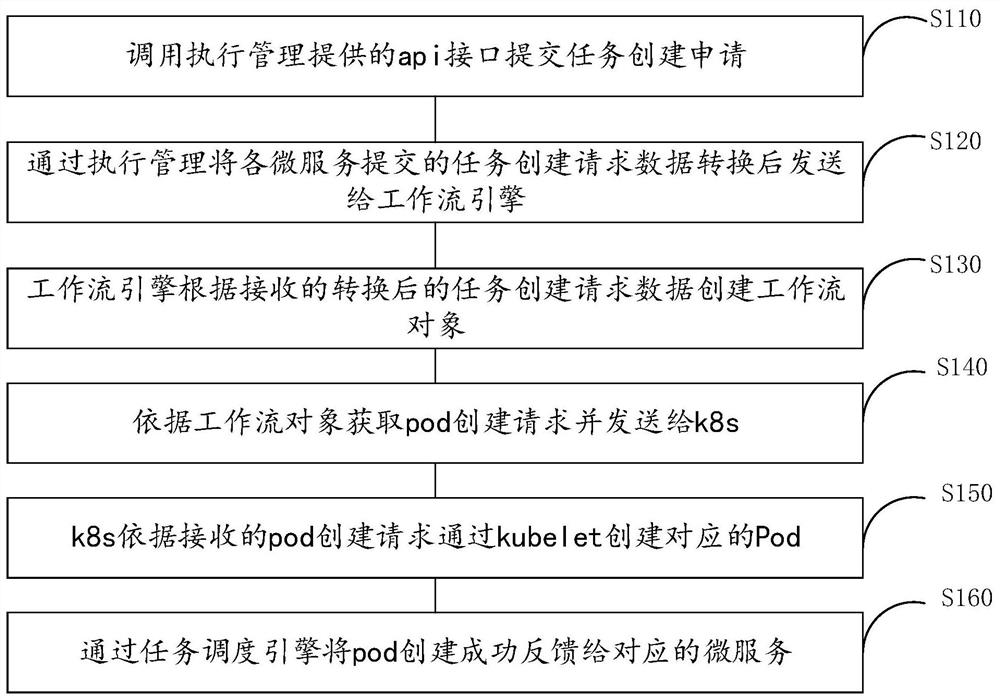
调用执行管理提供的api接口提交任务创建申请;
通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;
工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;
依据工作流对象获取pod创建请求并发送给k8s;
k8s依据接收的pod创建请求通过kubelet创建对应的Pod;
通过任务调度引擎将pod创建成功反馈给对应的微服务。
进一步的,所述工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象的方法包括:
获取任务创建请求数据;
工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象。
进一步的,所述工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象的方法,即:
工作流接收的任务创建请求数据所有触发的事件生成一个key并投递到队列中,然后多个goroutine并发的去从队列中获取key,并获取对应的Workflow进行处理,完成工作流对象的创建。
进一步的,所述工作流对象包括包括TypeMeta,ObjectMeta,Spec,Status。
进一步的,在工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象的同时,所述工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象的方法还包括:
基于Informer机制对工作流进行监听;
对所有类型的node创建相应的Informer进行监听,并将node的时间投递到与任务创建请求数据对应的事件队列。
进一步的,提交任务创建申请的微服务包括project-manager、iflow-manager以及data-manager中的一种或多种。
进一步的,所述k8s依据接收的pod创建请求通过kubelet创建对应的Pod的方法包括:
获取pod创建请求对应的资源和限制要求;
以及资源和限制要求获取满足需求的node;
通过kubelet创建对应的Pod。
本发明还提供了一种基于k8s的工作流引擎调度装置,包括:
请求提交模块,适于调用执行管理提供的api接口提交任务创建申请;
发送模块,适于通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;
工作流创建模块,适于通过工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;
Pod创建请求发送模块,适于依据工作流对象获取pod创建请求并发送给k8s;
创建模块,适于通过k8s依据接收的pod创建请求通过kubelet创建对应的Pod;
反馈模块,适于通过任务调度引擎将pod创建成功反馈给对应的微服务。
本发明还提供了一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被计算机运行时执行如上述方法中的步骤。
本发明还提供了一种电子设备,包括存储器和处理器;所述存储器中存储有至少一条程序指令;所述处理器,通过加载并执行所述至少一条程序指令以实现如上述方法中的步骤。
本发明的有益效果是:本发明提供了一种基于k8s的工作流引擎的使用方法及装置,其中,基于k8s的工作流引擎的使用方法通过调用执行管理提供的api接口提交任务创建申请;通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;依据工作流对象获取pod创建请求并发送给k8s;k8s依据接收的pod创建请求通过kubelet创建对应的Pod;通过任务调度引擎将pod创建成功反馈给对应的微服务。提供统一模式的工作流创建、调度、运行、升级、终止等功能;具有良好的项目架构,便于需求扩展和协同开发以及维护;可以扩展支持定时调度、优先级调度、事件触发机制。
附图说明
下面结合附图和实施例对本发明作进一步说明。
图1是本发明实施例提供的基于k8s的工作流引擎的使用方法的流程图。
图2是本发明实施例提供的基于k8s的工作流引擎的使用装置的原理框图。
图3是本发明实施例所提供的电子设备的部分原理框图。
具体实施方式
现在结合附图对本发明作详细的说明。此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
实施例1
请参阅图1,本发明实施例提供了一种基于k8s的工作流引擎的使用方法,实现了统一模式的工作流创建、调度、运行、升级、终止等功能,具有良好的项目架构,便于需求扩展和协同开发以及维护;可以扩展支持定时调度、优先级调度、事件触发机制等。
具体来说,基于k8s的工作流引擎的使用方法包括以下步骤:
S110:调用执行管理提供的api接口提交任务创建申请;
其中,提交任务创建申请的微服务包括pproject-manager(项目管理)、iflow-manager(工作流管理)、data-manager(数据管理)中的一种或多种。
S120:通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;
S130:工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;
具体来说,步骤S130包括以下步骤:
S131:获取任务创建请求数据;
S132:工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象。
具体来说,步骤S132,即,工作流接收的任务创建请求数据所有触发的事件生成一个key并投递到队列中,然后多个go routine(事物)并发的去从队列中获取key,并获取对应的工作流进行处理,完成工作流对象的创建。
其中,工作流对象包括TypeMeta(类型元),ObjectMeta(对象元),Spec(格式),Status(状态)四部分。
TypeMeta(类型元)表明资源的类型,API版本信息等,ObjectMeta(对象元)表明资源的名称,命名空间等.Spec(格式)则是对资源的specification(格式),Status(状态)展示资源当前的状态。
工作流对象的代码结构如下:
其中:
metav1.TypeMeta`json:",inline"`中inline说明TypeMeta(类型元)结构内嵌的字段直接作为Workflow(工作流)的字段;
metav1.ObjectMeta`json:"metadata,omitempty"
protobuf:"bytes,1,opt,name=metadata"`则表明ObjectMeta(对象元)对象在Workflow(工作流)中的字段名称为metadata(元数据);
Spec(格式),Status(状态)均为自定义的结构体,分别作为workflow(工作流)对象的spec(格式)和status(状态)字段;
Spec(格式)中存储启动pod(容器集)所需要的所有参数,包括但不限于:NodeType(节点类型)、DockerImage(docker镜像)、Resource(资源)、Command(命令)、Args(参数)、Env(环境变量)、Annotations(备注)、Ports(端口)等等。
Status(状态)在提交工作流时无需填写任何内容,展示当前工作流及各组件的状态,包括当前工作流状态(Running/运行中,pending/等待中,Failed/失败的,Succeeded/成功的)、startTime(工作流启动时间)、stopTime(工作流停止时间)、conditions(当前工作流的一些条件状态)、nodeStatus(工作流中各组件运行状态的列表)等。
在其他实施例中,工作流还包括定时工作流CronWorkflow
如下代码结构:
cronworkflow(定时工作流)和workflow(工作流)很相似,也是由metav1.TypeMeta,metav1.ObjectMeta,Spce和Status四部分组成.其中metav1.TypeMeta和metav1.ObjectMeta在工作流Workflow设计中已经描述过,下面介绍Spec和Status。
Sepc(规则)中定义的字段有concurrencyPolicy(并发处理机制)、schedule(调度器)、workflowTemplate(工作流模板)、waitingSeconds(等待时长)和startTime(开始运行时间):
concurrencyPolicy(并发处理机制),定时工作流创建的工作流的并发处理机制,有三个值,AllowConcurrent(允许并发),WaitTillTimeout(等待直到超时)和ReplaceCurrent(替换当前)。
-AllowConcurrent(允许并发)表明当需要调度新的工作流时,不处理之前的工作流。
-ReplaceCurrent(替换当前)则在需要调度新的工作流时,停止之前的工作流,再调度新的工作流。
-WaitTillTimeoutt(等待直到超时)则是配合waitingSeconds(等待时长)一起使用,当需要调度新的工作流时,检查之前的工作流是否已停止,如果没停止,则最多等待waitingSeconds(等待时长)秒,如果之前的工作流在超时waitingSeconds(等待时长)秒之前已完成,则调度新的工作流,如果在等待waitingSeconds(等待时长)秒后,之前的工作流还未停止,则先停止之前的工作流,再调度新的工作流。
schedule(调度器),使用的是cron表达式,具体跟linux系统中的crontab规则一致。
workflowTemplate(工作流模板),定时工作流的工作流模版。
waitingSeconds(等待时长),与concurrencyPolicy策略配合,配置超时时长,以秒为单位。
startTime(开始运行时间),定时工作流开始运行的时间,计算定义的cron表达式,获取下一次调度工作流的时间,如果此时间在startTime之前,则不调度工作流。
Status(状态)中定义的字段包括active(活动的)、lastScheduleTime(上个创建时间)、conditions(条件):
active(活动的),保存当前定时工作流相关的正在运行的工作流的对象。
lastScheduleTime(上个创建时间),定时工作流最近一次创建工作流的时间。
conditions(条件),当前工作流的一些条件状态。
在本实施例中,工作流的类型包括:
Job类型,正确运行一次,不局限于语言;
Deployment类型,一直运行,出现故障后会重新拉起;
SparkApplication类型,在Workflow Engine(工作流引擎)中Spark运行一次,不会重新拉起;
Tensorflow类型,在Workflow Engine(工作流引擎)中Tensorflow运行一次,不会重新拉起,可以是单机或者分布式运行;
Python类型,在Workflow Engine(工作流引擎)中Python运行一次,不会重新拉起。
在本实施例中,在工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象的同时,步骤S130还包括:
S133:基于Informer机制对工作流进行监听;
S134:对所有类型的node创建相应的Informer进行监听,并将node的时间投递到与任务创建请求数据对应的事件队列。
S140:依据工作流对象获取pod创建请求并发送给k8s;
S150:k8s依据接收的pod创建请求通过kubelet创建对应的Pod;
具体来说,步骤S150包括以下步骤:
S151:获取pod创建请求对应的资源和限制要求;
S152:以及资源和限制要求获取满足需求的node;
S153:通过kubelet创建对应的Pod。
S160:通过任务调度引擎将pod创建成功反馈给对应的微服务。
实施例2
请参阅图2,本发明实施例还提供了一种基于k8s的工作流引擎调度装置,包括:请求提交模块、发送模块、工作流创建模块、Pod创建请求发送模块、创建模块以及反馈模块。
请求提交模块,适于调用执行管理提供的api接口提交任务创建申请。其中,提交任务创建申请的微服务包括p project-manager(项目管理)、iflow-manager(工作流管理)、data-manager(数据管理)中的一种或多种。
发送模块,适于通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;
工作流创建模块,适于通过工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象,具体来说工作流创建模块适于运行以下步骤:
S131:获取任务创建请求数据;
S132:工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象。
具体来说,步骤S132,即,工作流接收的任务创建请求数据所有触发的事件生成一个key并投递到队列中,然后多个go routine(事物)并发的去从队列中获取key,并获取对应的工作流进行处理,完成工作流对象的创建。
其中,工作流对象包括TypeMeta(类型元),ObjectMeta(对象元),Spec(格式),Status(状态)四部分。
TypeMeta(类型元)表明资源的类型,API版本信息等,ObjectMeta(对象元)表明资源的名称,命名空间等.Spec(格式)则是对资源的specification(格式),Status(状态)展示资源当前的状态。
工作流对象的代码结构如下:
其中:
metav1.TypeMeta`json:",inline"`中inline说明TypeMeta(类型元)结构内嵌的字段直接作为Workflow(工作流)的字段;
metav1.ObjectMeta`json:"metadata,omitempty"
protobuf:"bytes,1,opt,name=metadata"`则表明ObjectMeta(对象元)对象在Workflow(工作流)中的字段名称为metadata(元数据);
Spec(格式),Status(状态)均为自定义的结构体,分别作为workflow(工作流)对象的spec(格式)和status(状态)字段;
Spec(格式)中存储启动pod(容器集)所需要的所有参数,包括但不限于:NodeType(节点类型)、DockerImage(docker镜像)、Resource(资源)、Command(命令)、Args(参数)、Env(环境变量)、Annotations(备注)、Ports(端口)等等。
Status(状态)在提交工作流时无需填写任何内容,展示当前工作流及各组件的状态,包括当前工作流状态(Running/运行中,pending/等待中,Failed/失败的,Succeeded/成功的)、startTime(工作流启动时间)、stopTime(工作流停止时间)、conditions(当前工作流的一些条件状态)、nodeStatus(工作流中各组件运行状态的列表)等。
在其他实施例中,工作流还包括定时工作流CronWorkflow
如下代码结构:
cronworkflow(定时工作流)和workflow(工作流)很相似,也是由metav1.TypeMeta,metav1.ObjectMeta,Spce和Status四部分组成.其中metav1.TypeMeta和metav1.ObjectMeta在工作流Workflow设计中已经描述过,下面介绍Spec和Status。
Sepc(规则)中定义的字段有concurrencyPolicy(并发处理机制)、schedule(调度器)、workflowTemplate(工作流模板)、waitingSeconds(等待时长)和startTime(开始运行时间):
concurrencyPolicy(并发处理机制),定时工作流创建的工作流的并发处理机制,有三个值,AllowConcurrent(允许并发),WaitTillTimeout(等待直到超时)和ReplaceCurrent(替换当前)。
-AllowConcurrent(允许并发)表明当需要调度新的工作流时,不处理之前的工作流。
-ReplaceCurrent(替换当前)则在需要调度新的工作流时,停止之前的工作流,再调度新的工作流。
-WaitTillTimeoutt(等待直到超时)则是配合waitingSeconds(等待时长)一起使用,当需要调度新的工作流时,检查之前的工作流是否已停止,如果没停止,则最多等待waitingSeconds(等待时长)秒,如果之前的工作流在超时waitingSeconds(等待时长)秒之前已完成,则调度新的工作流,如果在等待waitingSeconds(等待时长)秒后,之前的工作流还未停止,则先停止之前的工作流,再调度新的工作流。
schedule(调度器),使用的是cron表达式,具体跟linux系统中的crontab规则一致。
workflowTemplate(工作流模板),定时工作流的工作流模版。
waitingSeconds(等待时长),与concurrencyPolicy策略配合,配置超时时长,以秒为单位。
startTime(开始运行时间),定时工作流开始运行的时间,计算定义的cron表达式,获取下一次调度工作流的时间,如果此时间在startTime之前,则不调度工作流。
Status(状态)中定义的字段包括active(活动的)、lastScheduleTime(上个创建时间)、conditions(条件):
active(活动的),保存当前定时工作流相关的正在运行的工作流的对象。
lastScheduleTime(上个创建时间),定时工作流最近一次创建工作流的时间。
conditions(条件),当前工作流的一些条件状态。
在本实施例中,工作流的类型包括:
Job类型,正确运行一次,不局限于语言;
Deployment类型,一直运行,出现故障后会重新拉起;
SparkApplication类型,在Workflow Engine(工作流引擎)中Spark运行一次,不会重新拉起;
Tensorflow类型,在Workflow Engine(工作流引擎)中Tensorflow运行一次,不会重新拉起,可以是单机或者分布式运行;
Python类型,在Workflow Engine(工作流引擎)中Python运行一次,不会重新拉起。
在本实施例中,在工作流控制器基于client-go提供的informer机制,对工作流接收的任务创建请求数据触发的事件实用一个队列进行缓冲和处理并创建工作流对象的同时,工作流创建模块还用于运行以下步骤:
S133:基于Informer机制对工作流进行监听;
S134:对所有类型的node创建相应的Informer进行监听,并将node的时间投递到与任务创建请求数据对应的事件队列。
Pod创建请求发送模块,适于依据工作流对象获取pod创建请求并发送给k8s;
创建模块,适于通过k8s依据接收的pod创建请求通过kubelet创建对应的Pod,具体来说,创建模块用于执行以下步骤:
S151:获取pod创建请求对应的资源和限制要求;
S152:以及资源和限制要求获取满足需求的node;
S153:通过kubelet创建对应的Pod。
反馈模块,适于通过任务调度引擎将pod创建成功反馈给对应的微服务。
实施例3
本实施例提供了一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被计算机运行时执行实施例1所提供的基于k8s的工作流引擎的使用方法。
基于k8s的工作流引擎的使用方法通过调用执行管理提供的api接口提交任务创建申请;通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;依据工作流对象获取pod创建请求并发送给k8s;k8s依据接收的pod创建请求通过kubelet创建对应的Pod;通过任务调度引擎将pod创建成功反馈给对应的微服务。提供统一模式的工作流创建、调度、运行、升级、终止等功能;具有良好的项目架构,便于需求扩展和协同开发以及维护;可以扩展支持定时调度、优先级调度、事件触发机制。
实施例4
请参阅图3,本发明实施例还提供了一种电子设备,包括:存储器502和处理器501;所述存储器502中存储有至少一条程序指令;所述处理器501,通过加载并执行所述至少一条程序指令以实现如实施例1所提供的基于VUE的前端应用组件化开发方法。
存储器502和处理器501采用总线方式连接,总线可以包括任意数量的互联的总线和桥,总线将一个或多个处理器501和存储器502的各种电路连接在一起。总线还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路连接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口在总线和收发机之间提供接口。收发机可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。经处理器501处理的数据通过天线在无线介质上进行传输,进一步,天线还接收数据并将数据传送给处理器501。
处理器501负责管理总线和通常的处理,还可以提供各种功能,包括定时,外围接口,电压调节、电源管理以及其他控制功能。而存储器502可以被用于存储处理器501在执行操作时所使用的数据。
综上所述,本发明提供了一种基于k8s的工作流引擎的使用方法及装置,其中,基于k8s的工作流引擎的使用方法通过调用执行管理提供的api接口提交任务创建申请;通过执行管理将各微服务提交的任务创建请求数据转换后发送给工作流引擎;工作流引擎根据接收的转换后的任务创建请求数据创建工作流对象;依据工作流对象获取pod创建请求并发送给k8s;k8s依据接收的pod创建请求通过kubelet创建对应的Pod;通过任务调度引擎将pod创建成功反馈给对应的微服务。提供统一模式的工作流创建、调度、运行、升级、终止等功能;具有良好的项目架构,便于需求扩展和协同开发以及维护;可以扩展支持定时调度、优先级调度、事件触发机制。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关的工作人员完全可以在不偏离本发明的范围内,进行多样的变更以及修改。本项发明的技术范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
- 基于k8s的工作流引擎的使用方法及装置
- 基于K8S的服务部署方法、装置、电子设备和存储介质