一种基于局部深度图像关键性的点云匹配方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及点云匹配技术领域,尤其是涉及一种基于局部深度图像关键性的点云匹配方法。
背景技术
点云匹配就是要将单个模型点云与场景点云中存在的一个或多个该物体进行位置与姿态的对齐。目前盛行的方法有两类,一类是人工提取点云几何特征的方法,要求选取的几何特征具有旋转平移不变性,常用的有点对特征(PPF)、快速点特征直方图(FPFH)等。另一类是基于深度学习的方法,以场景深度图为输入,通过神经网络输出场景中能与模型匹配上的点云位置与姿态。前一类方法中存在的问题是人工提取点云几何特征由于维数低,故缺乏独特性,造成场景中每个点都可以与模型中的多个点有相似的特征,从而造成位姿匹配候选情况过多,降低了匹配准确性。后一类方法利用深度学习技术提取点云的高维特征,有利于各点特征之间的区分,提高匹配准确性。但由于点云为三维场景,受物体摆放姿态影响,同一物体在不同摆放姿态下的深度图会有显著差别,要想备齐各姿态下的场景深度图,工作量非常巨大,难以实现。如果以少量位姿下的深度图进行网络训练,又降低了神经网络的匹配精度。所以目前深度学习方法,在匹配精度上,相较于传统的几何特征提取方法并没有体现出优势。
中国专利CN202010100002.3公开了一种基于多特征融合的点云配准方法、装置及存储介质,所述方法包括:分别从源点云和目标点云中提取若干源点云特征点以及若干目标点云特征点;提取每一特征点的局部深度特征、法线角度特征、点云密度特征以及局部颜色特征,继而根据每一特征点的局部深度特征、法线角度特征、点云密度特征以及局部颜色特征生成每一特征点对应的特征描述子;其中,特征点包括源点云特征点和目标点云特征点;根据特征描述子,将源点云特征点与目标点云特征点进行配对,生成特征点对;根据特征点对生成变换矩阵,并根据变换矩阵对源点云进行变换,生成第二源点云,继而对第二源点云以及目标点云进行精配准。通过实施本发明实施例能够提高特征描述子的表达能力,从而提高整体配准精度。
中国专利CN201911038035.3公开了一种基于深度学习的点云匹配方法,将两片点云进行配准,包含以下步骤:步骤1,建立关键点;步骤2,构造匹配对和不匹配对;步骤3,将点云进行体素化;步骤4,计算三维彩色点云中各点的几何特征;步骤5,训练得出3D描述子;步骤6,优化描述子;步骤7,利用神经网络训练得出的计算权重;步骤8,计算得出精准的关键点的描述子向量;步骤9,完成点云匹配。
中国专利CN201910977774.2公开了点云匹配方法、装置、计算机设备和存储介质,通过降低该第一深度图集合的分辨率得到第二深度图集合;将第一深度图集合和第二深度图集合转换为第一点云和第二点云;在第一点云集合中确定第一待匹配点云和第一目标点云,在第二点云集合中确定第二待匹配点云和第二目标点云;由于第二点云的分辨率比第一点云的分辨率低,所以第二待匹配点云和第二目标点云进行最近点迭代,得到第二空间变换矩阵的过程相对更快;再在第一待匹配点云和第一目标点云进行最近点迭代之前,利用第二空间变换矩阵对第一待匹配点云进行空间变换,使得第一待匹配点云与第一目标点云对应的最近点的距离减小,最近点迭代的速度提高,从而提高第一点云的匹配速度。
以上已经公开的专利均是涉及点云匹配技术领域,其中CN202010100002.3专利是需要先提取特征点,然后根据局部深度、发现角度等特征生成对应的特征描述,最后将特征点对生成模块进行配准,存在误差性。CN201911038035.3专利是对三维点云中随机采样来获取关键点。以关键点以及关键点所在领域作为参考点,寻找对应帧中的对应关键点以及关键点所在领域,由此生成匹配对;最后获取其他帧最中的不对应点,从其他帧中随机获取距离对应点大于0.1米的点,生成不匹配对,生成数据集。一个网络输入两片点云中的两个对应点的TDF体素网格,通过训练让它们的输出越来越像,而另一个网络则输入两个非对应点的TDF体素网格,通过训练让它们的输出差距越来越大;最后输出的描述子,使匹配对的描述子的损失变小,使非匹配对的损失变大,从而得出网络的权重。专利CN201910977774.2是将两组三维点云输入到目标函数中,将目标函数中的对应矩阵进行归一化处理,再将目标函数中的旋转和平移用对偶数表示形成新的目标函数,然后通过对该新目标函数进行最小化目标,找到点云之间的对应矩阵,最后完成三维点云的匹配。以上专利处理复杂,匹配精度不高,非关键性点在匹配统计得分中的存在干扰,仍存在以上技术问题。
发明内容
基于以上技术问题,本发明提供了一种基于局部深度图像关键性的点云匹配方法。
为了实现本发明的目的,本发明的技术方案如下:
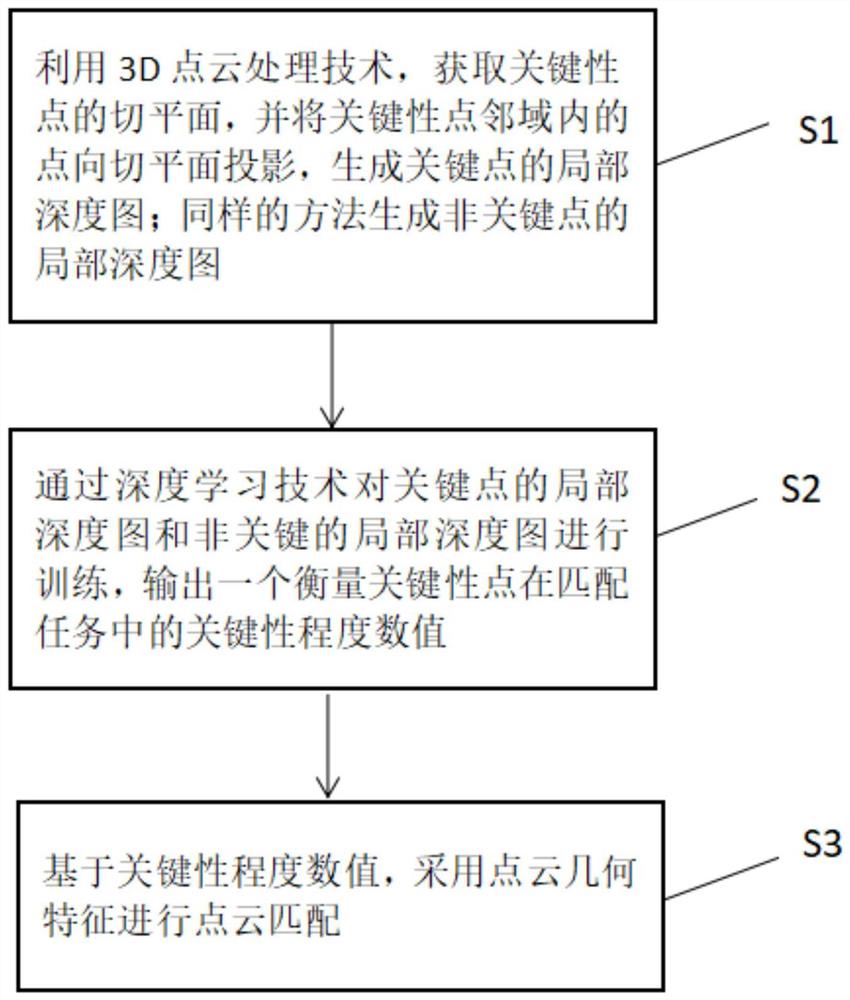
一种基于局部深度图像关键性的点云匹配方法,步骤包括:
步骤S1:选取物体模型,结构光相机拍摄物体,获得二维图片和三维点云,三维点云作为匹配模板的模型点云;
步骤S2:选取二维图片上的若干个区域标注为关键区域,根据二维图片上的关键区域对应获取模型点云的关键区域;
步骤S3:将所述模型点云中的关键区域内的若干个点作为关键点,将每个关键点的邻域在对应的每个关键点的切平面上形成投影,投影的位置坐标设为像素坐标,关键点的邻域内的各个点到投影位置的距离值作为像素点的灰度值,进而生成关键点的局部深度图;将模型点云中关键区域以外的区域作为非关键区域,非关键区域内的各个点作为非关键点,将每个非关键点的邻域在对应的每个非关键点的切平面上形成投影,投影的位置坐标设为像素坐标,关键点的邻域内的各个点到投影位置的距离值作为像素点的灰度值,进而生成非关键点的局部深度图;
步骤S4:将模型点云中获取的关键点的局部深度图和非关键点的局部深度图作为训练样本图片,采用深度学习算法,输入训练样本图片,对神经网络进行训练,得到训练好的用于判断各点关键性数值的神经网络;
步骤S5:选取场景,用结构光相机对场景进行拍摄,获得场景的三维点云作为场景点云;基于神经网络判断出的关键性数值的大小,将关键性数值作为点云几何特征的权重,结合点云几何特征匹配算法,完成模板点云和场景点云的点云匹配。
进一步地,所述步骤S2中的关键区域选择为物体的边或物体的角或物体凸起区域或物体凹陷区域,关键区域内的各点均为关键点。
进一步地,所述步骤S4中的神经网络是以卷积神经网络为基本结构搭建的,神经网络对关键性数值大小的判断是基于在网络训练时输入的关键点的局部深度图和非关键点的局部深度图,选取所述关键区域内的关键点的局部深度图作为正样本,选取不在关键区域内的点的局部深度图作为负样本。
进一步地,若输出的局部深度图为正样本,则对应的网络输出应为1,若输出的局部深度图为负样本,则对应的网络输出应为0。
进一步地,所述步骤S4中的关键性数值作为关键性权值,若关键性权值越大,则关键点越需要匹配准确,若关键性权值越小,则关键点在点对特征匹配算法中起到的作用越会被自适应地抑制,关键性权值的取值范围设为0到1。
进一步地,步骤S5中采用点云几何特征进行点云匹配,统计关键点的位姿变换出现的次数,位姿变换出现的次数采用点对特征匹配算法计算,以次数作为衡量各匹配位姿优劣的分数。
进一步地,在统计各关键点的匹配结果时,以关键性数值的累加代替次数的累加作为统计权重,使得关键点对齐的位姿拥有更高的统计得分,进而准确匹配。
与现有技术相比,本发明的有益效果具体体现在:
(1)本发明利用深度学习技术,对点云中各点在匹配任务中的关键性进行判断。着重对齐能表示物体几何外形的关键性点(例如点云的边、角、凹凸等局部特殊外形),而对关键性过低的点可以不进行匹配计算。
(2)本发明降低了非关键性点在匹配过程中的干扰,提高了匹配准确度和匹配速度。
(3)本发明采用局部深度图来训练用来判断各点关键性的神经网络,由于局部深度图不会随物体的摆放姿态而改变,因此减少了训练样本的数量,降低了网络的训练难度。
(4)本发明针对人工提取几何特征进行点云匹配时,由于特征维数低,而易出现一点有多个候选匹配点的问题,提出赋予各点不同的关键性权值,权值越大的点,越可能作为候选匹配点。这样在统计各点匹配结果时,可以确定出现次数最多的位姿来做为匹配位姿,在统计各点匹配结果时,加大关键性点的统计权重,使得最终的匹配位姿更倾向于将关键性点对齐的位姿。如果关键性点选在物体的边、角等地方,则本发明重点方法重点对齐了场景与模型点云的边、角。
附图说明
图1为本发明的示意图。
具体实施方式
为使本发明的目的和技术方案更加清楚,下面将结合实施例,对本发明的技术方案进行清楚、完整地描述。
实施例
根据图1所示的一种基于局部深度图像关键性的点云匹配方法,方法步骤包括:步骤S1:选取物体模型,结构光相机拍摄物体,获得二维图片和三维点云,三维点云作为匹配模板的模型点云;步骤S2:选取二维图片上的若干个区域标注为关键区域,根据二维图片上的关键区域对应获取模型点云的关键区域;步骤S3:将所述模型点云中的关键区域内的若干个点作为关键点,将每个关键点的邻域在对应的每个关键点的切平面上形成投影,投影的位置坐标设为像素坐标,关键点的邻域内的各个点到投影位置的距离值作为像素点的灰度值,进而生成关键点的局部深度图;将模型点云中关键区域以外的区域作为非关键区域,非关键区域内的各个点作为非关键点,将每个非关键点的邻域在对应的每个非关键点的切平面上形成投影,投影的位置坐标设为像素坐标,关键点的邻域内的各个点到投影位置的距离值作为像素点的灰度值,进而生成非关键点的局部深度图;具体流程是:将拍摄出来的三维点云转换为深度图,x轴、y轴所在平面就是拍摄区域,作为深度图的画面范围,其中每个像素位置是三维点云在xy平面上的投影,而三维点云到xy投影平面的距离z,即为深度,在深度图上用像素的灰度值来表示,所以灰度图是根据三维点云转化来的。步骤S4:将模型点云中获取的关键点的局部深度图和非关键点的局部深度图作为训练样本图片,采用深度学习算法,输入训练样本图片,对神经网络进行训练,得到训练好的用于判断各点关键性数值的神经网络;步骤S5:选取场景,用结构光相机对场景进行拍摄,获得场景的三维点云作为场景点云;基于神经网络判断出的关键性数值的大小,将关键性数值作为点云几何特征的权重,结合点云几何特征匹配算法,完成模板点云和场景点云的点云匹配,选取的几何特征具有旋转、平移不变性。
所述步骤S2中的关键区域可以选择物体的边、物体的角、物体凸起、物体凹陷等区域,也即是模板点云外形变化比较剧烈的地方标注为关键区域(法向变化较大的地方),关键区域内的所有点都可以作为关键点,关键区域可以通过人机交互的方式进行标注。本方法重点对齐了场景与模型点云的边、角,匹配结果更加准确。所述步骤S4中的关键性数值作为关键性权值,若关键性权值越大,则关键点越需要匹配准确,若关键性权值越小,则忽视关键性点的匹配精度,进而便提高了匹配速度,关键性权值的范围在0到1之间。关键性权值不需要额外判断大小,它会以系数乘子的形式,在投票累加统计的时候发挥作用。没有这个关键性权值时,在场景中找到的所有与模板中具有相似点对特征(PPF)的点对,都会全部加1票,有了这个关键性权值,每次不再是加整数1票,而是加0到1之间实数值。于是会在这些原本都加1票的点对中,对那些较大可能位于场景点云的关键区域上的点对,加上接近1的票数,而对于非关键区域的点对,则加上接近0的票数。这样按照PPF匹配算法的投票累加方法,最后会使得匹配到关键区域的位姿对应的累加票数,明显高于那些匹配到非关键区域的位姿对应的累加票数,从而实现将模板的边缘(制作训练样本时指定的关键区域)与场景中的物体边缘(在场景点云中检测出的关键区域)对齐的目的。选取所述关键区域内的关键点的局部深度图作为正样本,选取不在关键区域内的点的局部深度图作为负样本。若选取的局部深度图为正样本,则对应的网络输出应为1,若选取局部深度图为负样本,则对应的网络输出应为0。由于局部深度图不会随物体的摆放姿态而改变,因此可以减少训练样本的数量,降低网络的训练难度。
步骤S5中采用点云几何特征进行点云匹配,统计关键点的位姿变换出现的次数,以次数作为衡量各匹配位姿优劣的分数。关键点的位姿变换是指将模板点云坐标,变换到与场景中的一部分点云重合时,所需要的旋转角度与平移量,可以采用点对特征(PPF)匹配算法计算出来。在统计各关键点的匹配结果时,以关键性数值的累加代替次数的累加作为统计权重,使得关键点对齐的位姿拥有更高的统计得分,进而准确匹配。所述点云几何特征算法至少包括点对特征、快速点特征直方图。
对次数的累加是点对特征(PPF)匹配算法中的一个步骤,模板经各种不同的位姿变换后,有可能与场景中的一部分点云重合,如果重合的越多,那么就说明场景中的某部分越可能存在像模板那样的物体。在PPF算法中,每当找到模板与场景能对应上的点对,就会在能使这两个点对重合的位姿变换选项中投1票。最后对投票累加,就可以起到判断某一位姿对应的重合点多少的作用。如果在场景中要找出N个与模板相似的物体,则选择累加票数最后的N个位姿,模板经过这N个位姿的坐标变换,就会分别落在场景点云中的N个区域,这N个区域就是场景中与模板相似的物体点云。场景点云中的关键区域是用训练好的神经网络来判断的。
本发明应用的方法主要是在累加时,引入了关键性权值,使得累加结果趋向于使模板的关键区域与场景中的关键区域(边、角、凸起等)对齐,弱化非关键区域(大块平面)对于对齐结果的干扰,这样有利于提高匹配的精度和可靠性。
本发明中的模板模型上的关键点是人工标注的,将外形变化较大的区域(一般是曲率变化较大)标注为关键点。且模板上各点的局部深度图作为神经网络训练的样本图片,这样可以训练出一个判断某点是否为关键点的神经网络。本发明能自适应地使用关键性权值,但并不要求必须为0或1,越接近1,在后续匹配中发挥的作用就会越大。
以上仅为本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些均属于本发明的保护范围。
- 一种基于局部深度图像关键性的点云匹配方法
- 一种基于局部点云匹配的航发叶片陶瓷型芯在位去毛刺路径生成方法